Extraction of Hidden Social Networks from Wiki-Environment Involved in Information Conflict

Author: Rasim M. Alguliyev, Ramiz M. Aliguliyev, Irada Y. Alakbarova
Journal: International Journal of Intelligent Systems and Applications(IJISA) @ijisa
Article in issue: 2 vol.8, 2016.
Free access
Social network analysis is a widely used technique to analyze relationships among wiki-users in Wikipedia. In this paper the method to identify hidden social networks participating in information conflicts in wiki-environment is proposed. In particular, we describe how text clustering techniques can be used for extraction of hidden social networks of wiki-users caused information conflict. By clustering unstructured text articles caused information conflict we create social network of wiki-users. For clustering of the conflict articles a hybrid weighted fuzzy-c-means method is proposed.
Wiki-technology, wiki-page, conflict articles, information conflict, social network, hybrid weighted fuzzy c-means
Short address: https://sciup.org/15010792
IDR: 15010792
Text of the scientific article Extraction of Hidden Social Networks from Wiki-Environment Involved in Information Conflict
Published Online February 2016 in MECS
Wikipedia developing since 2001, contributed to the appearance of new environment on the Internet – Wiki environment. When referring to the biggest search engines of the Internet among the websites proposed by the system the virtual encyclopedia Wikipedia is one of the first places. There are discussions and expressed opinions in the various fields in Wikipedia – political, social, scientific and cultural.
The escalation of information conflicts in wikienvironment and their long-term continuing have a bad impact on the development of Wikipedia projects (wikidictionary, wikicitation, wikibooks, wikisource, wikinews, wikiversity etc.), quality of encyclopedic articles, and respect between users, which is one of the basic principles of Wikipedia philosophy. For elimination of conflicts between users, protection of encyclopedic articles from vandalism, disinformation and propaganda administrators and active users worked out different rules [6].
All contents in Wikipedia projects like text, image, audio- and video- files are added into database of Wikipedia. From this point of view it is possible to control the behavior of wiki-users (discussing of pages with users, editing of particular articles on particular subjects). For defining the quality of encyclopedic articles in wiki-environment and studying the information conflicts problems the identifying of hidden social networks is important issue. According to many specialists dealing with wikimetrics research, events in society, problems and relationships reflect on wikienvironment. The behavior of wiki-users reveals their purposes and the degree of using of information war technologies in their activity [7, 8].
II. Related Work
The analysis of social network in wiki-environment and the reputation of users, also the influence of 0relationships between them on content were studied by different researchers [9, 10]. The model proposed by the professor Sara Javanmardi for identifying social relationships between wiki-users and their influence gives the opportunity for identifying vandals and inexperienced users in wiki-environment [11].
Another approach for measuring the social relationships, conflicts and cooperation in wikienvironment were proposed by Hagit Mesha-Tal and Edna Tal-Alhsid [12]. 3 criteria are used in this method:
-
1. Number of wiki-users;
-
2. Interactivity, i.e. the number of edits by wiki-users in particular time interval;
-
3. Intensity, i.e. the number of changes in wiki-pages as a result of new edits.
Edit means the changes making in wiki-pages, i.e. removing of information, replacing by other information and adding new information. On the basis of the method proposed by Mesha-Tal and Tal-Alhsid the edit warring, activity of wiki-users and the quality of their edits are defined [13]. During the edit warring, the changes in wiki-pages are not accepted by another group of users. As a result a conflict arises between one or more groups. The information added by one group are removed by another and this process continues some period of time. The existing situation is so: the number of users editing the page is huge, but the changes of the size and the quality of the encyclopedic article are small.
In some wikimetrics researches the influence of wikiusers and the social groups are identified mainly by their behavior. The idea of identifying the vandalism and the analysis of article quality by measuring the influence was firstly proposed by de Adler, Alfaro and Pye [14]. They proposed so-called method “reputation-based system” (Wiki-Trust) for analysis of the quality of encyclopedic articles in wiki-environment and the influence of users [15]. This proposed approach seems very simple from the first view and in some cases looks like the algorithm proposed by Javanmardi: the influence of users depends on the degree of acceptation of their edits [11]. WikiTrust was also focused to identify vandalized encyclopedic articles. Here the acts of vandalism are identified by the activity of anonyms (users acting without registration) and new users, who are just registered [16, 17].
However, discussed above methods are not effective in identifying of hidden social networks involved in information conflicts. Thus, proposed methods can be used only if there is action of anonyms and new users in acts of vandalism and information conflicts. But the studies show that not only anonyms and new users involve in information conflicts [15, 18]. Wiki-pages causing wars and conflicts take an attention also of experienced and active users. Taking this fact into account, new approach on identifying the hidden social groups in wiki-environment was proposed. This approach is effective if there is a grouping of wiki-pages by content and the analysis of activity of users involved in creation and editing of these pages.
III. The Model Extraction of Hidden Social Networks
To identify the hidden social networks involved in information conflicts in wiki-environment the phased solution is more advisable (Fig. 1).
To reach the aim first of all articles (wiki-pages) causing information conflicts are defined and grouped by content. Then the users involved in editing of these articles are identified and their activities are analyzed.
The criteria used in this research are following:
-
- volume of encyclopedic articles (in bytes);
-
- volume of discussion pages of articles (in bytes);
-
- first paragraph of the article (in our opinion the first paragraph defines the topic of the article);
-
- number of users involved in creation and edition of the article;
-
- number of edits in article;
-
- number of revertings in article;
“Reverting” is a process removing of edits after some defined time interval [18].
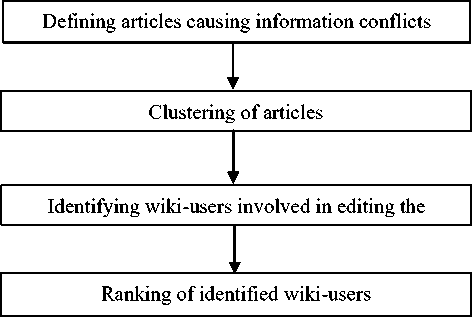
Fig.1. The model of identifying hidden social network in wikienvironment
-
A. Defining the Articles Causing Information Conflicts
To identify the articles which cause information conflicts in wiki-environment the revert operations in each article, the volume of the article and its discussion page must be taken into account. Thus, an article causes information conflicts, if:
-
1. The volume of discussion page ( twp ) of encyclopedic article is bigger than the volume of the article ( wpn ) itself, twpn > wpn ;
-
2. The revert operations in article more than three, rwp„ > 3, it is considered as anomaly. According to the common rules of Wikipedia the activity of the user blocked after 3 or more revert actions in one day (registration nickname is blocked) [13, 19].
If one of the listed above conditions is met ( twp > wpn or rwp„ > 3 ), then the article must be included into the list of the articles which caused information conflict.
-
B. Clustering of Articles
Clustering is one of the data mining techniques which try to identify groupings of the text documents. Generally speaking, clustering methods attempt to segregate the documents into groups where each group represents some topic that is different than those topics represented by the other groups [20]. It is possible to separate wiki-pages into groups under various conditions using cluster algorithms [21, 22, 23]. In this section, to group the conflict articles we propose a hybrid weighted fuzzy clustering method.
Let’s we have the n number of conflict articles and we need to group them by content. For this purpose we use the first paragraphs (stubs) of these articles, which it’s considered that first paragraphs define the content of these articles. Let P = {P.....P} be the set of first 1,..., n paragraphs of conflict articles, where P denotes the first paragraph of ith conflict article in the collection P , n is the number of conflict articles in collection. Let T = {?,...,t} represents all the distinct terms (words) occurring in P , where m is the number of terms.
Most document clustering methods are relied on the Vector Space Model (VSM). It is a widely used text representation for clustering [24]. According to VSM the document P represented as a weighting vector of the terms, , where is the weight of the i i1 id ij term t in the document P . The idea term weighting is to assign a weight to represent the importance of a term. Different weighting schemes are available. The common and popular one is the Term Frequency–Inverse Document Frequency (TF-IDF) weighting scheme.
This scheme combines the definitions of term frequency and inverse sentence frequency, to produce a composite weight for each term in each sentence. This weighting scheme assigns to term a weight in document given by
-
w.. = IF x IDF ; i = 1,..., n , j = 1,..., m , (1)
ij ij j where IF is the term frequency and IDF is the inverse document frequency of term t over the collection P .
The term frequency is calculated as the ratio of number of times the term ccurs in the document to the total number of terms in the documnet. It measures the importance of a term within a document:
m
IF = —j ; i = 1,...,n, j = 1,...m,(2)
ij where m is the number of occurrence of term in ijj document P , m is the number of terms in document P . ii
This formula assigns a higher weight to terms that occur often in a document.
The IDF measures the importance of a term within the document collection. It is obtained by dividing the total number of documents by the number of documents containing the term, and then taking the logarithm of that quotient:
IDF = log( n / n ), (3)
where n is the number of documents in the collection P and n denotes the number of documents in which term t appaers.
The IDF factor accounts for the global weighting of term t . The IDF factor has been introduced to improve the discriminating power of terms in the traditional information retrieval. A term that occurs in every document of the collection gets a lower IDF value. This reflects the fact that it is not as significant for the distinction between documents as the terms that rarely occur throughout the document collection.
Once each document vector is represented, in this study the Euclidean distance is used to calculate the distance between pair of documents. Then the Euclidean distance between vectors P = [ w , w ] and P = [ w p..., wlm ] is calculated as:
d u =1 P - P l = J2( W - W j ) 2 , i , 1 = 1,..., n . (4)
V j = 1
The fuzzy clustering algorithm allows one piece of data to belong to more one cluster according to a membership function. The value of a fuzzy membership function belongs to any number between 0 and 1, and is meant to be a mathematical characterization of a “set” which may not be precisely defined [25].
Let U = [ uik ] be a partition matrix where u^ is the membership value of P belonging to class C , and V = { V ,..., V } is a set of cluster centers, where V e Rm , V k = ( vn 1 .™. v m ).
The goal of clustering is to assign data points P (i = 1,..., n) into c partitions. Assume that the c centers are V... Vand in cluster there exist N points. So 1, , c k k we can calculate its center by averaging its members:
N k
V = 2 S ,’ k = 1,..., c . (5)
N k , = 1
In this paper, a novel hybrid weighted fuzzy c-means (HWFCM) clustering method is proposed which integrates the properties of the density weighted fuzzy c-means and the cluster-dependent fuzzy c-means clustering methods [26, 27, 28, 29]:
cn
F hwfcm ( U , V ) = 22 «Xk d-k +
+У У au^d2 + У У a u^d\ ^ min (6) i ik ik k ik ik k=1 i=1 k=1 i =1
Subject to
0 < uik < 1, i = 1,...,n; k = 1,...,c,(7)
c
2uk = 1, i = 1,...,n, k=1
n
0 <2u.k < n, k = 1,...,c,(9)
i = 1
where ц > 1 is the degree of fuzziness associated with the partition matrix. If we consider ц to be one, the soft clustering will be changed into hard one. Let u satisfy the above conditions Eqs.(7)-(9) represented by a n x c matrix U = [u^ ]. The proposed clustering method aims to determine cluster centers V and fuzzy partition matrix U by minimizing the objective function F (U,V) .
The method provides the fuzzy membership matrix U and the fuzzy cluster center vector V = [ V ] .
d is the Euclidean distance from document vector ik
P = [ wn,...,wta ] to the cluster center V k = [ V k p..., V km ]
Using the Lagrange multiplier method, the problem is equivalent to minimizing the following equation satisfying the constraint Eq.(8):
cncn
L (U , V , 2 ) = £Ы£ + УУ au^ k + k = 1 i = 1 k = 1 i = 1
cn nc
+У TaYd, + У 2I 1 -Уик I k ik ik iik k=1 i=1 i=1 к k=1
d * =i P - V k ii =J £ ( w, - j , i =1,..., n ; k =1,..., c . (10)
V j = 1
aik is a weighting of P belonging to cluster Ck . It is the cluster-dependent weight, which can change and be updated during the clustering process. The weights a. ( a is a density measurement of input data) are independent of a particular cluster and are constants during the clustering process. a is the weight which depends on cluster cardinality. Contrary to a , the weights a can change during the clustering process. For computing the weights a , a and a , we utilize the following equations [27, 30, 31, 32]:
For the sake of simplicity in computations, we use an assumption that d a I d vk = 0 , d a I d vt = 0 and d a / d vk = 0. Therefore, setting d LI dulk = 0 , we will obtain the following equation for u :
d L (U , V , 2 ) „-,,2
—----- = Ц ■ a. uk d, + Ц- auk d, + ik ik ik i ik ik
+ k ■ a k u ik dik - 2 = 0 > u ik k ( a ik + a i + a k ) dik =
= 2 > l
uik
- \ 1I( k - 1)
2 I i2
k ( a. + a + a ) d 2 2 J ik i k ik
Replacing uik in Eq. (8) we obtain:
a., ik
1 In - dk) ik
, i = 1,..., n ; k = 1,..., c ,
c ( x \/( k - 1)
y |--------- 2 1 ---------1 = 1
k = 1 к k ( a ik + a i + a k ) d i k k j
^
А в -1
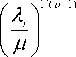
a
di
£ d,
, i = 1
n ,
c f , v/( k -1)
y|_________1_________I k=11 (aft+a+ ak) dik J
Further replacing Eq.(16) in Eq.(15), uik can be
rewritten as follows:
f 1 У — 1
a = — , k = 1,..., c .
k к nk J
uik
1I( k - 1)
a is a weight indicating the importance of distance between the data P and cluster center V . The difference ik between a and u obtained by FCM algorithm is that there is no limitation to “ У a = 1 V k and У a = 1 ik ik i=1 k=1
V i .” So, the a has more representative than uik in reflecting correlation between data and clusters. Especially, the noises do not need to satisfy the limitation. Hence, the influence of noises is reduced by aik [26].
Here n > 1 is a parameter depending on the variation of outliers, p > 1 and у > 1 are the user-defined parameters, V is the center of input data and d is the distance between data point S and the center V , d.=\ Si-V I, where V =1tS-" n i=1
■
k( a ik + a + a. ) d ik ^ X 1I( k - 1)
( a t + a + a. ) d ii
( a t + a + a k ) d ik
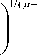
c
У q=1
. X 1I( k - 1)
2 i k J
■
---------------- • 1I( k -1)
(a + a + a ) d2
iq i q iq
у I (a,k + a, + ak )d, q^1 к (aq + a, + aq )d.
1I( k - 1)
Furthermore, by setting d L I d V = 0, we obtain the following updating equation for the centroids:
d L (U , V , 2 ) k /c kkv
---gy ----= 0 > 2 У a ik u ik ( S i - V k ) - 2 У a i u ik ( S i - V ) - n
-2У atuk (Si- Vk) = 0 > i =1
> V у (a + a + a)uk = У (at + a + a)ukS > k ik i k ik ik i k ik i i=1 i=1
n z (aik+ a+ak) ukkSi
V = ------------ kn
У (a, + a + a)u k ik i k ik i=1
Determination of the optimal number of clusters in a data set is a difficult issue and depends on the adopted validation and chosen similarity measure, as well as on data representation. For clustering of documents, customers can’t predict the latent topic number in the document collection, so it’s impossible to offer the number c of clusters effectively. The strategy that we used to determine the optimal number of clusters (the number of topics in a document collection) is based on the distribution of words in the documents [33]:
c - n
n
Pi i=1
n
LIP i =1
where P denotes the number of terms in the document
P .
Based on Eqs.(4)-(19) we describe the main steps of the proposed HWFCM algorithm as follows:
Step 1 : By using Eq.(19) define the number c of clusters. HWFCM then randomly initializes the centroids. Let в - 2 Compute a ( i - 1,..., n ) according to Eq.(12). Choose a threshold value 8 . Let k = 2 . Initialize the fuzzy partition matrix U by generating c x n random numbers in the interval [0,1] .
Step 2 : Let n - Y - 2 . Compute ak and a
( г - 1,..., n ; k - 1,..., c ) by using Eqs.(11) and (13), respectively.
Step 3 : Compute V according to Eq.(18).
Step 4 : Compute all d according to (10) and then all uik ( i - 1,..., n ; k - 1,..., c ) according to (17). Thus update the fuzzy partition matrix U by the new computed u .
Step 5: Compute the objective function F by using Eq.(6). If it converges or the difference between two adjacent computed values of objective function F^™ is less than the given threshold 8 then stop. HWFCM
Otherwise go to step 2.
-
C. Identifying and Ranking of Wiki-Users Involved in Editing the Articles
After identifying of articles which cause information conflicts and their separation into groups the problem of identifying of social networks involved in the creation and editing of these articles must be solved.
The stage after clusterisation is identifying and ranking of users of social networks involved in editing the articles. For this purpose we identify users involved in the editing of one article, then users involved in the editing the articles within each cluster, and finally the users involved in the editing the articles collected in all clusters. In this task the theory of graphs is used.
Relations in cluster can be regarded as a social network, and as it be shown in Fig.2 each article has been described as a graph: S(U, E), where U – set of vertices, E – set of edges that describe the interaction of agents. Let's imagine the article as an agent of the user group. The relations between agents are provided by users. Let,
-
• Ak = { A , A k ,...<} - the set of articles in
cluster C , where m – the number of articles kk in cluster C, к - 1,...,c;
U ( A ) - < U‘ .1 - Uk 2..... U «) - the group of
Ak C users who edited the article j in cluster k ;
j - 1,..., m k ; к - 1,..., c.
;
– the group of users
C n who edited articles in cluster k ; k – the
C number of users in cluster k . It is clear that, mk
U ( C k ) - U u ( A k )
j - 1
Then,
Q k - U ( Ak ) n U ( A k )
-
• jl j l - the group users who
edit articles ^j E ^ k and Al E Ck ;
l Ф j - 1,..., mk ; k - 1,..., c .
R - U ( C ) n U ( C ) .
-
• kp k p - the group of users who
CC edited the articles in cluster k and p .; k ^ p - 1,..., c.
P k , p - U ( Ak ) n U ( Ap )
-
• jl j l - the group of users
who edited the articles ^j E ^k and ^ l E ^ p ; p ^ k - 1,..., c j - 1,..., m k l - 1,..., m p ;
If Q k ^0 , then there is would be edge (internal) between the majority of elements (users) Qk . If P k , p ^ 0 , then there is would be edge (external) between the majority of elements (users) P k , p .
As can be seen there are two types of contact between the elements of network: internal and external. To set up internal (topic) network internal edges are used. The edge weight in the topic network is assigned by the numbers of edges between the tops [34].
The following formula is used to rank users in the topic network:
nk
« i = 2 « (20)
s = 1
s * i
Here, mk -1 mk
« = 2 2 1(U. e Q i & Us e Q i ) (21)
J = 1 l = J + 1
Where
I(x ) = ft ifXX true (22)
0, otherwise
Users in the topic network are ranked by the value of « . General social network can be gotten by the synthesis of topic networks. This network is synthesised by the following way:
-
• to assign the group of users involved in the all topic networks. For this the majority, U ( C ) = n U ( C ) is found and edges between them is calculated. Two tipes of this edges can be: internal and external. Edges weight between the two tops (users) are gotten as the sum of internal and external edges;
-
• after that the weight of each vertex in the network is found. The weights of the vertexes (users) are calculated as the sum of the weights of edges connecting to other tops. The users are ranked according to their weight.
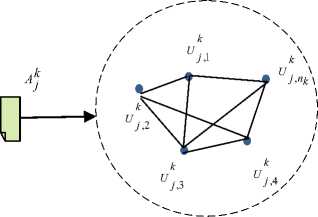
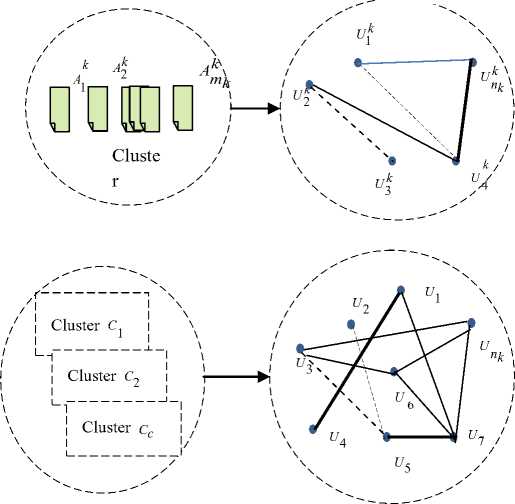
Fig.2. Social networks of wiki-users involved in editing the article, cluster and all articles
IV. Conclusion
The proposed approach for identification of the hidden social network controling encyclopedic articles causing conflicts, can be helpfull in preventing information conflicts in virtual encyclopedia Wikipedia and in solution of the problem of information security in wikienvironment. By identifying articles, which are used in information conflicts, and groups, which propagand some ideology, it is possible to increase the quality of encyclopedic articles, provide the Wikipedia with correct and independ information.
The approach proposed for identifying the hidden social networks is not only for wiki-technologies but may be used also for analys many social networks based on web2.0 technology.
References Extraction of Hidden Social Networks from Wiki-Environment Involved in Information Conflict
- P. Shachaf, N. Hara, “Beyond vandalism: wikipedia trolls”. Journal of Information Science, vol. 36, no. 3, 2010, pp. 357-370.
- T. Yasseri, R. Sumi, A. Rung, A. Kornai, J. Kertész, “Dynamics of conflicts in wikipedia”. PLoS ONE, vol. 7, no. 6, 2012, e38869.
- A. G. West, S. Kannan, I. Lee, “STiki: an anti-vandalism tool for wikipedia using spatio-temporal analysis of revision metadata”, in Proceedings of the 6th International Symposium on Wikis and Open Collaboration, New York, ACM, 2010, pp. 47-48.
- B. Leuf, W. Cunningham, “The wiki way: quick collaboration on the web”, Laflin, PA: Addison-Wesley, 2001, 200 pp.
- B. Luyt, D. Tan, “Improving wikipedia’s credibility: references and citations in a sample of history articles”, American Society for Information Science and Technology, Vol. 61, No. 4, 2010, pp. 715-722.
- T. Iba, K. Nemoto, B. Peters, P. A. Gloor, “Analyzing the creative editing behavior of wikipedia editors: through dynamic social network analysis”, Procedia – Social and Behavioral Sciences, vol. 2, no. 4, 2010, pp. 6441-6456.
- T. Holloway, M. Bo?icevic, K. B?rner, “Analyzing and visualizing the semantic coverage of wikipedia and its Authors”, Journal Complexity, Vol. 12, No. 3, 2007, pp. 30-40.
- N. Hara, P. Shachaf, K. F. Hew, “Cross-cultural analysis of the wikipedia community” American Society for Information Science and Technology, vol. 61, no. 10, 2010, pp.2097-2108.
- J. Moskaliuk, J. Kimmerle, U. Cress, “Collaborative knowledge building with wikis: the impact of redundancy and polarity”, Computers & Education, 2012, vol. 58, No. 4, pp. 1049-1057.
- S. Javanmardi, C. Lopes, P. Baldi, “Modeling user reputation in wikis”, Statistical Analysis and Data Mining, vol. 3, no. 2, 2010, pp. 126-139.
- S. Javanmardi, D. W. McDonald, C. V. Lopes, “Vandalism detection in wikipedia: a high-performing, feature-rich model and its reduction through lasso”, in Proceedings of the 7th International Symposium on Wikis and Open Collaboration, New York, ACM, 2011, pp. 82-90.
- H. Meishar-Tal, E. Tal-Elhasid, “Measuring collaboration in educational wikis – a methodological”, Emerging Technologies in Learning, vol. 3, 2008, pp. 46–49.
- http://en.wikipedia.org/wiki/Wikipedia:Edit_warring
- B.T. Adler, L. de Alfaro, I. Pye, “Detecting wikipedia vandalism using wikitrust”, Lab Report for PAN at CLEF, 2010, (http://ceur-ws.org/Vol-1176/CLEF2010wn-PAN-AdlerEt2010.pdf).
- B. T. Adler, L. de Alfaro, “A content-driven reputation system for the wikipedia”, in Proceedings of the 16th International Conference on World Wide Web, New York, ACM, 2007, pp. 261-270.
- B. T. Adler, L. de Alfaro, S. M. Mola-Velasco, P. Rosso, A. G. West, “Wikipedia vandalism detection: combining natural language, metadata, and reputation features”, in Proceedings of the 12th International Conference on Intelligent Text Processing and Computational Linguistics, Berlin, Springer-Verlag, 2011, pp. 277-288.
- L. de Alfaro, A. Kulshreshtha, I. Pye, B. T. Adler, “Reputation systems for open collaboration”, Communications of the ACM, vol. 54, no. 8, 2011, pp. 81–87.
- I. Y. Alakbarova, “Analysis factors influencing on ranking of papers in wiki environment”. Problems of Information Society, vol. 2, no. 6, 2012, pp. 27-32. (in Azerbaijani)
- http://en.wikipedia.org/wiki/Wikipedia: Reviewing
- S. Shedata, F. Karray, M. Kamel, “An efficient-based mining model for enhancing text clustering”, IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, 2010, pp. 1360-1371.
- R. M. Alguliev, R. M. Aliguliyev, I. Y. Alekperova, “Cluster approach to the efficient use of multimedia resources in information warfare in wikimedia”, Automatic Control and Computer Sciences, vol. 48, no 2, 2014, pp. 97-108.
- A. Skabar, K. Abdalgader, “Clustering sentence-level text using a novel fuzzy relational clustering algorithm”, IEEE Transactions on Knowledge and Data Engineering, vol. 25, no. 1, 2013, pp. 62-75.
- N. Ye, S. M. Emran, Q. Chen, S. Vilbert, “Multivariate statistical analysis of audit trails for host-based intrusion detection”, IEEE Transactions on Computers, vol. 51, no. 7, 2002, pp. 810-820.
- J. Jayabharathy, S. Kanmani, “Correlated concept based dynamic document clustering algorithms for newsgroups and scientific literature”, Decision Analytics, vol. 1, no. 3, 2014, pp. 1-21.
- H. L. Shieh, “A hybrid fuzzy clustering method with a robust validity index”, Fuzzy Systems, vol. 16, no.1, 2014, pp. 39-45.
- J. L. Chen, J. H. Wang, “A new robust clustering algorithm-density-weighted fuzzy c-means”, in Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, vol. 3, 1999, pp. 90-94.
- A. H. Hadjahmadi, M. M. Homayounpour, S. M. Ahadi, “Bilateral Weighted Fuzzy C-Means Clustering”, Iranian Journal of Electrical & Electronic Engineering, 2012, Vol. 8, No. 2, pp. 108-121.
- M. Nazari, J. Shanbehzadeh, A. Sarrafzadeh, “Fuzzy C-Means Based on Automated Variable Feature Weighting”, in Proceedings of the International MultiConference of Engineers and Computer Scientists, 2013, pp.1-5.
- N. R. Pal, K. Pal, J. C. Bezdek, “A mixed c-means clustering model”, in Proceedings of the IEEE International Conference on Fuzzy Systems, vol. 1, 1997, pp.11-21.
- R. M. Aliguliyev, “Performance evaluation of density-based clustering methods”, Information Sciences, vol. 179, no. 20, 2009, pp. 3583-3602.
- R. M. Aliguliyev, “Clustering of document collection – a weighting approach”, Expert Systems with Applications, vol. 36, no. 4, 2009, pp. 7904-7916.
- M. El. Agha, W.M. Ashour, “Efficient and fast initialization algorithm for k-means clustering”, International Journal of Intelligent Systems and Applications, vol.4, no.1, 2012, pp. 21-31.
- R. M. Aliguliyev, “A new sentence similarity measure and sentence based extractive technique for automatic text summarization”, Expert Systems with Applications, vol. 36, no. 4, 2009, pp. 7764-7772.
- P. Wadhwa, M.P.S. Bhatia. Discovering hidden networks in on-line social networks // International Journal of Intelligent Systems and Applications, vol. 6, no. 5, 2014, pp.44-54.
