Fuzzy Clustering Data Given in the Ordinal Scale

Author: Zhengbing Hu, Yevgeniy V. Bodyanskiy, Oleksii K. Tyshchenko, Viktoriia O. Samitova
Journal: International Journal of Intelligent Systems and Applications(IJISA) @ijisa
Article in issue: 1 vol.9, 2017.
Free access
A fuzzy clustering algorithm for multidimensional data is proposed in this article. The data is described by vectors whose components are linguistic variables defined in an ordinal scale. The obtained results confirm the efficiency of the proposed approach.
Computational Intelligence, Machine Learning, Categorical Data, Ordinal Scale, Fuzzy Clustering
Short address: https://sciup.org/15010894
IDR: 15010894
Text of the scientific article Fuzzy Clustering Data Given in the Ordinal Scale
Published Online January 2017 in MECS
That’s a very common situation for sociological, medical and educational tasks when initial data is given not in a numeric scale but rather in a rank (ordinal) scale [1-5]. This information (for the one-dimensional case) is given in the form of an ordered sequence of linguistic variables x1,x2,...,xi,...,xm, 1 <... < j-1 < j < j + 1 <... < m where xj is a linguistic variab le and j is its corresponding rank.
A typical example is a traditional (for Ukraine and some other ex-USSR countries) educational grading system like "poor", "fair", "good", "excellent". Let’s note that a person in its daily activities is much more likely to use an ordinal scale rather than a numerical one.
The simplest approach for solving these clustering problems on an ordinal scale is based on replacement of linguistic variables with their ranks but this method is incorrect in most cases because it assumes equal distances between neighboring numerical ranks [6-12]. It is intuitively clear that a distance between "poor" and "fair" is much longer than a distance between "fair" and "good" while assessing students' knowledge. Many similar examples can be found in medicine.
That’s a more natural approach that is based on fuzzification of input data and further usage of fuzzy clustering methods. Thus, an initial set of linguistic variables x1,x2,...,xi,...,xmis replaced with a set of membership functions д(x),д(x),...,д(x) defined in the interval [0, 1] . This method was used in [13] where clustering (based on the Fuzzy C-means (FCM) algorithm [14]) was not performed for the initial data but for parameters describing corresponding membership functions, although a method for determining these parameters was not specified.
There’s an approach that looks more natural. It's developed by R.K. Brouwer [15-21] and based on the frequency distribution analysis of the specific values ’ occurrence of linguistic variables. A limitation of this approach is an assumption about the Gaussian distribution of the initial data. This assumption is not usually met in many real-world applications.
The initial data for solving the task is a sample of observations which contains N n — dimensional feature vectors X = { x (1), x (2),..., x ( k ),..., x ( N )}, k = 1,2,..., N ,
x ( k ) = { x j ( k )}, i = 1,2,..., n; j = 1,2,..., m is a rank of a specific value of a linguistic variable in the i — th coordinate of the n — dimensional space for the k — th object to be clustered.
A result of this algorithm is partition of the initial dataset X into m classes (clusters) as well as calculation of a membership level Wj ( k ) k — th feature vector to the j — th cluster.
The remainder of this paper is organized as follows: Section 2 describes a procedure of the initial data fuzzification. Section 3 describes. a fuzzy clustering method for ordinal data. Section 4 describes experimental results. Conclusions and future work are given in the final section.
-
II. T HE INITIAL D ATA F UZZIFICATION
A fuzzification process for a sequence of rank linguistic variables may be considered by an example of the one-dimensional sample x (1), x (2),..., x ( N ) where each observation x ( k ) may be ascribed one of the j ranks, j = 1,2,..., m .
Let the value x(k) (which corresponds to the j — th rank) be seen in the sample N times. Then a relative frequency of occurrence of the j - th rank can be introduced
N
f = — fj N as well as cumulative frequencies f f j-I
F 1 = , F j= j^ + Z /, , j = 2,3,..., m
-
2 2 I = 1
m
Z = 1.
i = 1
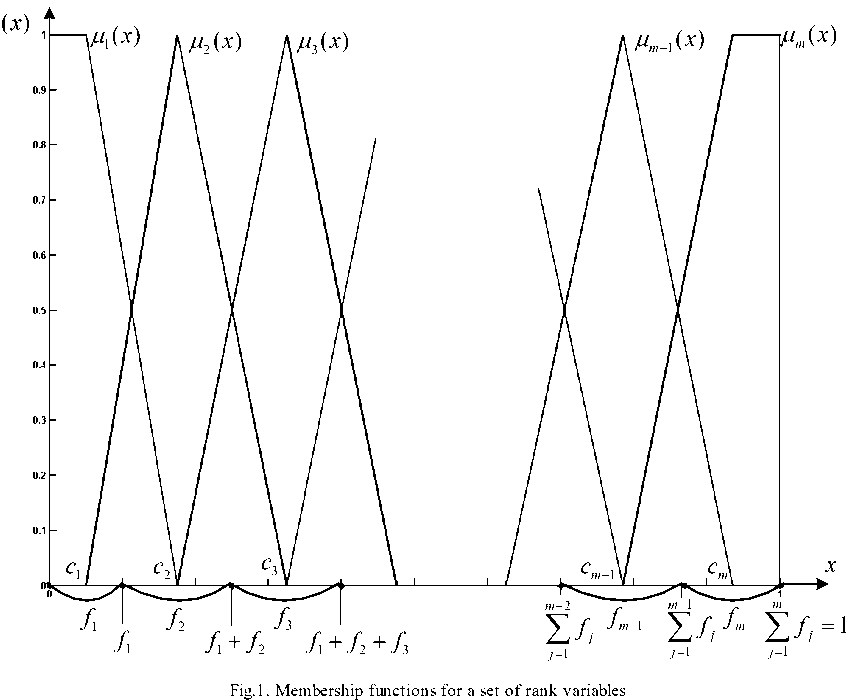
Based on these cumulative frequencies, membership functions’ ц ( x ) centers are formed (Fig.1). At the same time, it’s convenient to use a recurrence relation to compute centers
C = 0,5f1,Cj = Cj-1 + 0,5(j + fj), j = 2,3,...m , and to set membership functions in the form while naturally there’s a condition
д ( x ) = 1, x e [0, C i ] ,
M j ( x ) = '
x - C j - 1 c j - c j - 1 c j + 1 - x c j + 1 - c j
, x e [ c c j ],
, x € [ C j , C j + 1 ],
0, x g [ CL
c j + 1 ],
This method of setting membership functions automatically provides the unity (Ruspini) partition which means that the following condition is fulfilled
m
Z F i ( x ) = 1.
j = 1
Although it’s possible to use functions of some other view with a finite support
M m ( x ) = 1, x e [ C m , 1].
SUPP M j( x ) = [ C j - 1 , C j + 1] .
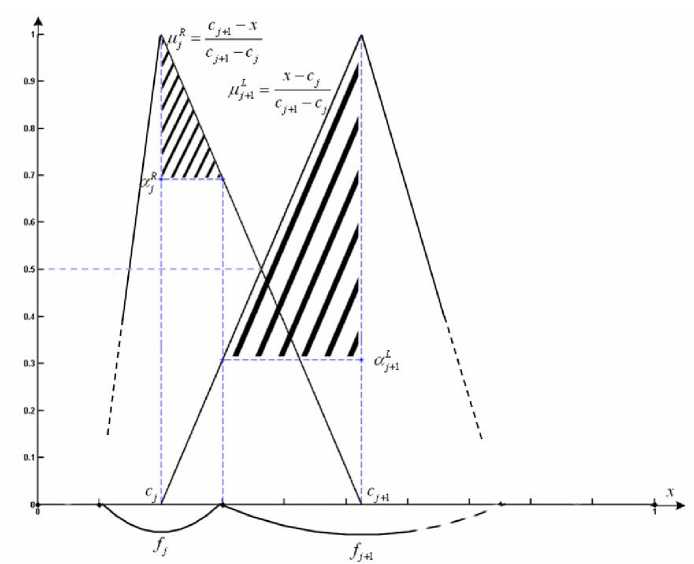
Fig.2. The areas of influence for neighboring ranks.
Let’s consider two neighboring membership functions ц; ( x ) and ^ +j( x ) (Fig.2). Using a term of the a - cut
Aa = {x e X: ^(x) > a}, an area of influence for two neighboring ranks (shaded in Fig.2) can be introduced in the form of
A R = { x e [ C j , C j + 0,5 fj ]: ^ ( x ) > a j } =
f
= 1 - 0,5 , cj+1 - cj
A L + 1 = { x e [ c j + 1 - 0,5 f j + 1 , c j + 1 ]: j ( x ) > a L + 1 } =
f
= 1 - 0,5 j + 1
cj+1 - cj where L and R stand for the left and right sides of neighboring membership functions. If there’s a hit of some observation in the area of influence of a particular rank, we can talk about crisp belonging to this rank.
-
III. A F UZZY C LUSTERING M ETHOD FOR O RDINAL D ATA
Since we have a multidimensional data sample of observations (vectors) to be clustered, the fuzzification procedure should be performed in every coordinate of the n - dimensional feature space similarly to the previous example. nm membership functions are formed (they have centers c ) during this procedure like it’s shown for a two-dimensional case (Fig.3). Here comes an object x(k) to be clustered with coordinates x ( k ) =
x 2 ( k ) ^ a v x 4 ( k ) ^ e
.
As one can see in Fig.3, membership functions д 2( x 1 ), Д з ( x 1 ), Д 4 ( x 1 ), ^ 2 2( x 2), ^ 2з ( x 2), ^ 24 ( x 2) work in this case in such a way that it’s rather hard to make an immediate decision about belonging of x ( k ) to one of the classes «Poor», «Fair», «Good» and «Excellent» (Fig.3). A process of fuzzy clustering for rank variables is carried out at the same example that is shown in Fig.4. After nm membership functions (in our example, 2 x 4 = 8 membership functions) have been formed, n - dimensional vectors (cluster centroids)
Cj = ( c , c2j,...,cnj ) T , j = 1,2,..., m are taken into consideration (in our example,
C 1 = ( C 11 , C 12 ) , C 2 = ( C 21 , C 22 ) , C 3 = ( C 31 , C 32 ) , C 4 = ( C 41 , C 42 ) )
with their areas of influence which are described by ratios (1) (shaded areas in the picture). If an object gets into these regions, we can say that there’s crisp membership of an object x ( k ) to a specific cluster. We have an object x ( k ) = ( e , a ) T to be classified which is represented in a numerical form with coordinates c and c after fuzzification..
Then distances d ( x ( k ), c, ) = || x ( k ) - c, || between x ( k ) and all centroids c are calculated. Membership levels Wj ( k ) of a vector x ( k ) to the j - th cluster should be
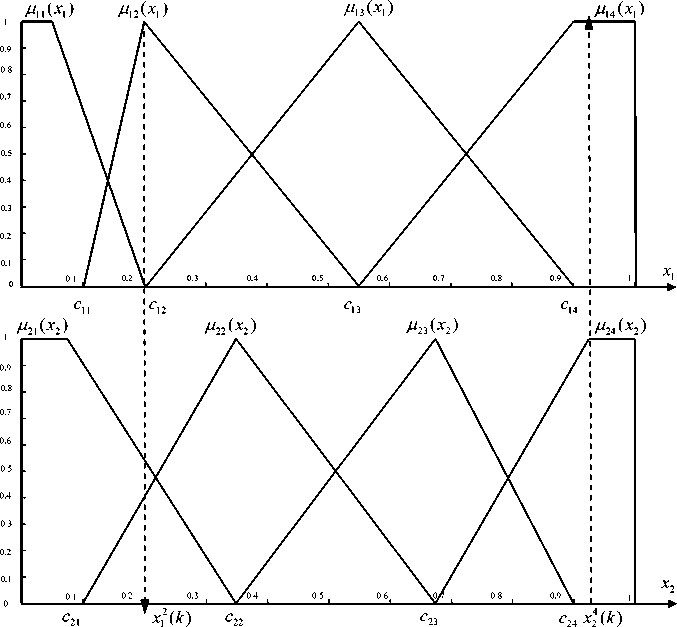
Fig.3. Membership functions of a 2D feature space
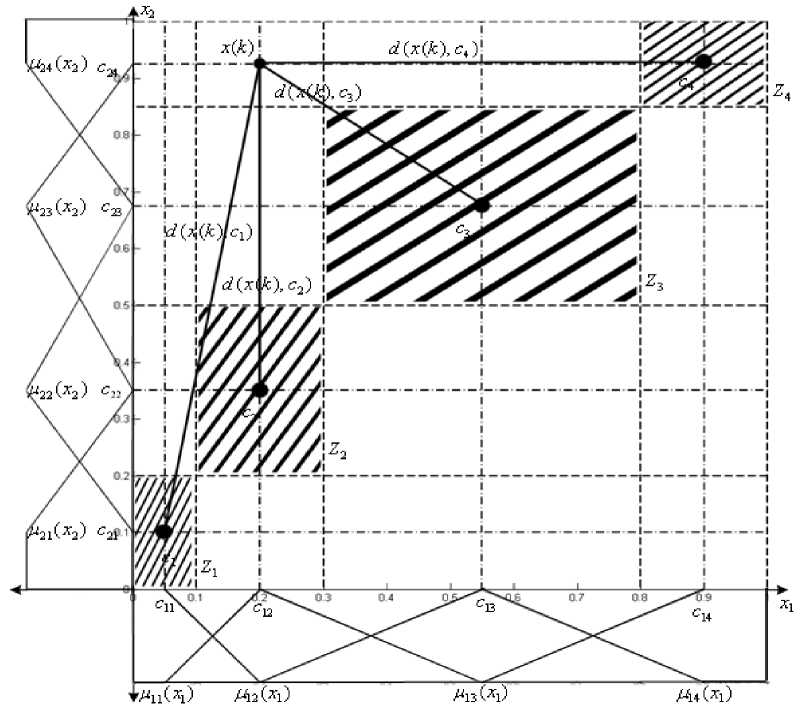
Fig.4. Fuzzy clustering for rank variables defined according to the FCM procedure [22]
wj ( k ) =
d ,—2nmin ( x ( k ), C j )
II x ( k ) - c j || - 2 d - 2( x ( k ), c j)
wj ( k ) = -m -------------- = -m-------------
Z || x ( k ) - c i || - 2 E d - 2( x ( k ), c i )
d m2nmin ( x ( k ), C j ) + d ,—2n ( x ( k ), C l ) ’
w,(k) = ------d "x(k>-C-)--------- dminmin (x(k), Cj ) + d.min (x(k), Cl )
.
A drawback of the estimate (2) is the fact that an object (except the case when x ( k ) gets into an area of influence of a centroid) equally belongs to all the existing clusters which leads to loss of a physical sense in the rank scale. So, an object under consideration x ( k ) = ( e , a ) T with a non-zero membership level may belong both to the «Excellent» cluster and to the «Poor» cluster. Obviously, that doesn’t make any sense.
It seems reasonable in this regard to rank all the distances d(x(k),c ) (which have been previously computed) in an ascending order and to choose the minimum distance and the one min min , j following it d (x(k), c ) . Then we can use the expression (2) with the only difference that we take into account only the two minimum distances. Finally, x(k) belongs to two neighboring clusters with centroids c and c (or c ) with some membership levels w(k) and w(k) (or w(k)).
Thus, the fuzzy clustering algorithm for multidimensional observations given in the ordinal scale is implemented as a sequence of steps:
-
1. Calculation of relative f and cumulative F frequencies in a dataset x (1), x (2),..., x ( k ),..., x ( N ) ;
-
2. Fuzzification of an initial data set of linguistic variables by forming mn membership functions ^ ( x ), j = 1,2,..., m ; i = 1,2,..., n and m vectors -centroids Cj = ( C , C2 ,..., cnj ) T for the clusters to be formed;
-
3. Building areas of influence Z for centroids c in the form of an orthotop with edges Cy ± 0,5 fy ;
-
4. Checking a possibility of crisp clustering in the form: if x ( k ) e Zy , this observation can be unambiguously classified, i.e. w y( k ) = 1 and
-
5. If the previous condition is not fulfilled, calculation of all distances
-
6. Choosing two minimal distances d ( x ( k ), c )
-
7. Computing membership levels for x ( k ) to find out its belonging to two neighboring clusters:
Wj ( k ) = 0 for all other l * k ;
d(x(k),Cj) = ||x(k) — cy. || is performed;
and d (x(k), c ) where l may take on a value of j —1 or j +1;
-
IV. E XPERIMENTS
To check the efficiency of the proposed method, we have gathered data about students' academic performance at one faculty at Kharkiv National University of Radio Electronics. A dataset contains s tudents ’ grades in 6 subjects for 135 persons.
Statistical analysis showed that a hypothesis for each variable (subject) about the estimates ’ normal distribution was not confirmed (Fig.5).
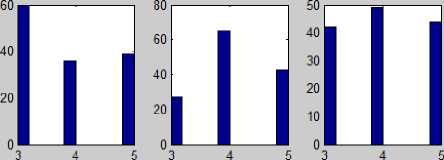
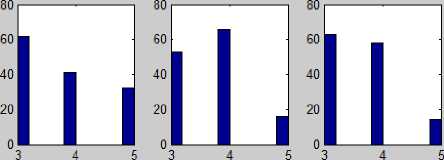
Fig.5. A histogram of grades’ distribution for six subjects
Having applied the proposed method, we calculated centroids for each rank (grades) for each variable and built membership functions with areas of influence (shown in Fig.6-11).
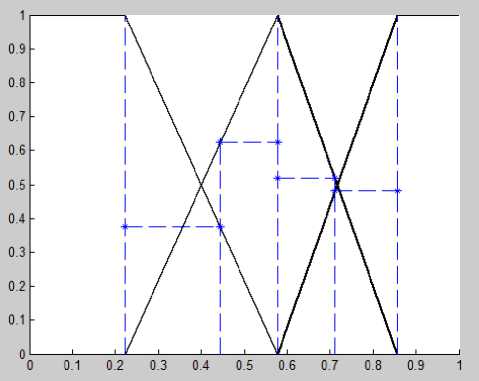
Fig.6. Membership functions with а — cuts for 6 subjects (case 1)
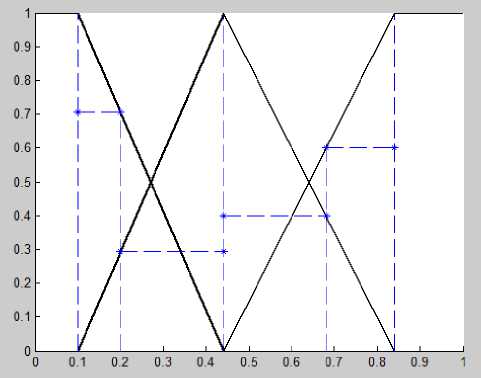
Fig.7. Membership functions with a — cuts for 6 subjects (case 2)
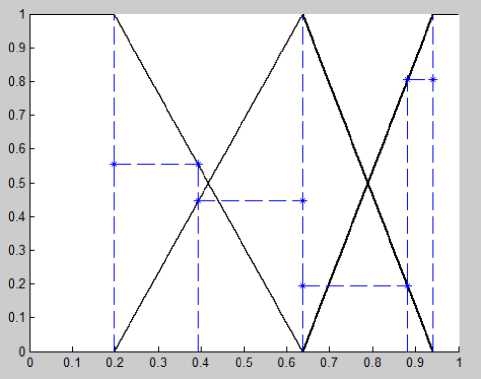
Fig.10. Membership functions with a — cuts for 6 subjects (case 5)
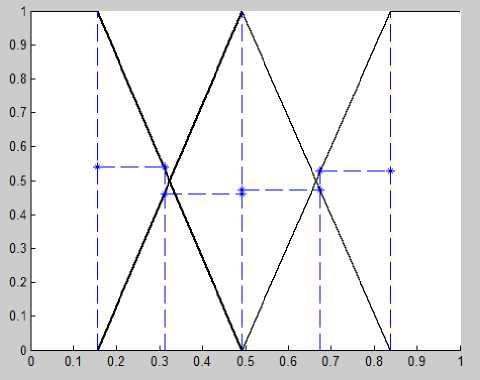
Fig.8. Membership functions with a — cuts for 6 subjects (case 3)
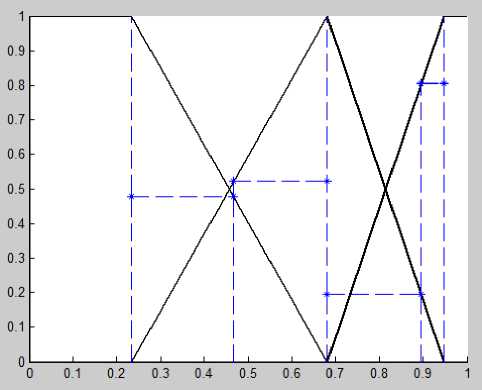
Fig. 11. Membership functions with a — cuts for 6 subjects (case 6)
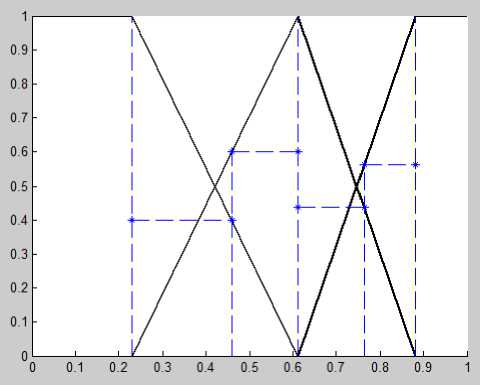
Fig.9. Membership functions with a — cuts for 6 subjects (case 4)
The proposed algorithm was compared to the FCM procedure ( в = 2 ) and the clustering method for ordinal data by R.K. Brouwer (BFCM) [15]. Since classes weren’t initially given in the dataset, it’s quite difficult to talk about a clustering accuracy of each method. Although analyzing the computed membership functions for some observations (Tables 1 and 2), it should be noticed that the proposed approach performs data processing in a more correct manner. It’s clear that the demonstrated observations (Tables 1 and 2) may belong to the "Good" and "Excellent" clusters with a certain membership level but there’s no way for them to belong to the “Fair” cluster. It’s proven by the FCM and BFCM methods (Table 3).
Table 1. Observations from the dataset. Examples (Subjects #1 - #3)
|
# obs |
Subject #1 |
Subject #2 |
Subject #3 |
|
1 |
Fair |
Excellent |
Excellent |
|
2 |
Fair |
Excellent |
Fair |
Table 2. Observations from the dataset. Examples (Subjects #4 - #6)
|
# obs. |
Subject #4 |
Subject #5 |
Subject #6 |
|
1 |
Excellent |
Excellent |
Excellent |
|
2 |
Good |
Fair |
Fair |
Table 3. Membership levels of observations’ belonging to clusters
|
Models |
# obj. |
Fair |
Good |
Excellent |
|
FCM |
1 |
0.13 |
0.37 |
0.5 |
|
2 |
0.35 |
0.48 |
0.17 |
|
|
BFCM |
1 |
0.14 |
0.26 |
0.6 |
|
2 |
0.31 |
0.49 |
0.2 |
|
|
MBFCM |
1 |
0 |
0.38 |
0.62 |
|
2 |
0.56 |
0.44 |
0 |
-
V. C ONCLUSION
The task of fuzzy clustering ordinal data has been solved with the help of the proposed method. The most peculiar feature of this procedure is the fact that it can work under conditions when objects belong to different clusters at the same time.
A CKNOWLEDGMENT
This scientific work was supported by RAMECS and CCNU16A02015.
References Fuzzy Clustering Data Given in the Ordinal Scale
- R. Kruse, C. Borgelt, F. Klawonn, C. Moewes, M. Steinbrecher, and P. Held, Computational Intelligence. A Methodological Introduction. Berlin: Springer, 2013.
- J. Kacprzyk and W. Pedrycz, Springer Handbook of Computational Intelligence. Berlin- Heidelberg: Springer-Verlag, 2015.
- K.-L. Du and M.N.S. Swamy, Neural Networks and Statistical Learning. London: Springer- Verlag, 2014.
- T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning. Data Mining, Inference, and Prediction. N.Y.: Springer Science & Business Media, LLC, 2009.
- C.C. Aggarwal, Data Mining. Cham: Springer, Int. Publ. Switzerland, 2015.
- Zh. Hu, Ye.V. Bodyanskiy, and O.K. Tyshchenko, “A Cascade Deep Neuro-Fuzzy System for High-Dimensional Online Possibilistic Fuzzy Clustering”, Proc. of the XI-th International Scientific and Technical Conference “Computer Science and Information Technologies” (CSIT 2016), 2016, Lviv, Ukraine, pp.119-122.
- Zh. Hu, Ye.V. Bodyanskiy, and O.K. Tyshchenko, “A Deep Cascade Neuro-Fuzzy System for High-Dimensional Online Fuzzy Clustering”, Proc. of the 2016 IEEE First Int. Conf. on Data Stream Mining & Processing (DSMP), 2016, Lviv, Ukraine, pp.318-322.
- Ye. Bodyanskiy, O. Tyshchenko, and D. Kopaliani, “An evolving neuro-fuzzy system for online fuzzy clustering”, Proc. Xth Int. Scientific and Technical Conf. “Computer Sciences and Information Technologies (CSIT’2015)”, 2015, pp.158-161.
- Ye. Bodyanskiy, O. Tyshchenko, and D. Kopaliani, “Adaptive learning of an evolving cascade neo-fuzzy system in data stream mining tasks”, in Evolving Systems, 2016, vol. 7(2), pp.107-116.
- Ye. Bodyanskiy, O. Tyshchenko, and D. Kopaliani, “An Extended Neo-Fuzzy Neuron and its Adaptive Learning Algorithm”, in I.J. Intelligent Systems and Applications (IJISA), 2015, vol.7(2), pp.21-26.
- Ye. Bodyanskiy, O. Tyshchenko, and D. Kopaliani, “A hybrid cascade neural network with an optimized pool in each cascade”, in Soft Computing. A Fusion of Foundations, Methodologies and Applications (Soft Comput), 2015, vol. 19(12), pp.3445-3454.
- Zh. Hu, Ye.V. Bodyanskiy, O.K. Tyshchenko, and O.O. Boiko, “An Evolving Cascade System Based on a Set of Neo-Fuzzy Nodes”, in International Journal of Intelligent Systems and Applications (IJISA), vol. 8(9), 2016, pp.1-7.
- Ye.V. Bodyanskiy, V.A. Opanasenko, and А.N. Slipchenko, “Fuzzy clustering for ordinal data”, in Systemy Obrobky Informacii, 2007, Iss. 4(62), pp.5-9. (in Russian)
- Bezdek J C. Pattern Recognition with Fuzzy Objective Function Algorithms. N.Y.: Plenum Press, 1981.
- Brouwer R K. Fuzzy set covering of a set of ordinal attributes without parameter sharing. Fuzzy Sets and Systems, 2006, 157(13): 1775 – 1786.
- R.K. Brouwer, “Clustering feature vectors with mixed numerical and categorical attributes”, in International Journal of Computational Intelligence Systems, 2008, vol. 1(4), pp.285-298.
- R.K. Brouwer, “Fuzzy clustering of feature vectors with some ordinal valued attributes using gradient descent for learning”, in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2008, vol. 16(2), pp.195-218.
- M. Lee and R. K. Brouwer, “Fuzzy Clustering and Mapping of Ordinal Values to Numerical”, IEEE Symposium on Foundations of Computational Intelligence (FOCI 2007), 2007, pp.538-543.
- L. Mahnhoon, “Mapping of Ordinal Feature Values to Numerical Values through Fuzzy Clustering”, in IEEE Trans. on Fuzzy Systems, 2008, pp.732-737.
- Mahnhoon L, Brouwer R K. Likelihood based fuzzy clustering for data sets of mixed features. IEEE Symp. on Foundations of Comput. Intell. FOCI 2007: 544-549.
- Brouwer R K, Pedrycz W. A feedforward neural network for mapping vectors to fuzzy sets of vectors. Proc. Int. Conf. on Artificial Neural Networks and Neural Information Processing ICANN/ICOMIP 2003, Istanbul, Turkey, 2003: 45-48.
- J.C. Bezdek, J. Keller, R. Krisnapuram, and N. Pal, Fuzzy Models and Algorithms for Pattern Recognition and Image Processing. N.Y.: Springer Science and Business Media, Inc., 2005.
