Fuzzy Hybrid Meta-optimized Learning-based Medical Image Segmentation System for Enhanced Diagnosis

Author: Nithisha J., J. Visumathi, R. Rajalakshmi, D. Suseela, V. Sudha, Abhishek Choubey, Yousef Farhaoui
Journal: International Journal of Information Technology and Computer Science @ijitcs
Article in issue: 1 Vol. 17, 2025.
Free access
This medical image segmentation plays a fundamental role in the diagnosis of diseases related to the correct identification of internal structures and pathological regions in different imaging modalities. The conventional fuzzy-based segmentation approaches, though quite useful, still have some drawbacks regarding handling uncertainty, parameter optimization, and high accuracy of segmentation with diverse datasets. Because of these facts, it generally leads to poor segmentations, which can give less reliability to the clinical decisions. In addition, the paper is going to propose a model, FTra-UNet, with advanced segmentation of medical images by incorporating fuzzy logic and transformer-based deep learning. The model would take complete leverage of the strengths of FIS concerning the handling of uncertainties in segmentation. Besides, it integrates SSHOp optimization technique to fine-tune the weights learned by the model to ensure improvement in adaptability and precision. These integrated techniques ensure faster convergence rates and higher accuracy of segmentation compared to state-of-the-art traditional methods. The proposed FTra-UNet is tested on BRATS, CT lung, and dermoscopy image datasets and ensures exceptional results in segmentation accuracy, precision, and robustness. Experimental results confirm that FTra-UNet yields consistent, reliable segmentation outcomes from a practical clinical application perspective. The architecture and implementation of the model, with the uncertainty handled by FIS and the learning parameters optimization handled by the SSHOp method, increase the power of this model in segmenting medical images.
Machine Learning, Meta-heuristic Optimization, Medical Image Segmentation (MIS), Disease Diagnosis, and Automated Detection
Short address: https://sciup.org/15019669
IDR: 15019669 | DOI: 10.5815/ijitcs.2025.01.04
Text of the scientific article Fuzzy Hybrid Meta-optimized Learning-based Medical Image Segmentation System for Enhanced Diagnosis
Over the past one decade, an exponential has been witnessed in the advancements in AI especially in the domain of deep learning [1, 2]. Historically, deep learning models have revolutionized how computing systems act, learn about patterns and make decisions at astoundingly high rates. These developments have made many of these particular tasks related to computer vision to be automated [3]; computer vision is a set of processes that help the machine to understand and interpret information and data that is received from the physical world in the form of images or videos or other such forms. This is due to the employment of complex neural network classifiers as a basis for categorizing and sorting visual information, a job that earlier demanded the manual participation of professionals. However, the process of forecasting the models’ performance, it is not always black and white, or one size fits all. The evaluation measures used to evaluate the quality of the deep learning model’s performance may differ considerably depending on the sub branch of CV and the purpose the deep learning model is to serve [4, 5]. This variability is particularly enlarged in the narrowspecialty areas such as Medical Image Segmentation (MIS). Medical image segmentation is a core research topic, which deals with the process of detecting and outlining the target structure within the medical images. These regions of interest or ROIs are very essential in the processes of medical diagnosis and therapy planning. To achieve these tasks, using MRI, CT/X-rays to name a few, accurate segmentation of these regions is vital in diagnosing the diseases, observing disease progression, and formulating correct treatment strategies. The difficulty in MIS does not only stem from the medical images themselves: thickness, complex and even subtle details, but also the decision making process that lays on the line with regards to the patient’s health [6]. In contrast to other computer vision problems where mistakes could lead to minor or no discomfort at all, mistakes in the segmentation of medical images can lead to misdiagnosis or improper treatment, which is particularly dangerous for the patient’s wellbeing. Hence, the deep learning models applied in MIS must be examined thoroughly by certain measurements that are readjusted to the models’ capacity of effectively identifying and segmenting these important medical areas. Hence, the advancement of AI and deep learning has boosted the domain a lot and accelerated the automation of complex computer vision tasks. In the subfield of medical image segmentation [7, 8], this technology holds the central position in the process of automatic identification and labeling of medical regions of interest, including organs or abnormalities like cancer. However, concerning the assessment of method performance in the given setting it can be stated that it is not very straightforward and most importantly the measures used for this purpose must be accurate, reliable, and precise enough to be amenable to clinical application.
Currently, clinicians especially those in radiology and pathology are beginning to realize the potential of deep learning based MIS techniques to revolutionaries their practice. When implemented as an automated disease detection system, these methods can offer great help in a variety of essential problems such as diagnosis, treatment planning, risk evaluation, and decreasing image identification time [9, 10]. For example, in radiology, deep learning models, it is possible to teach them, to segment and highlight regions of interests in the medical images, including detection of the tumor or other relevant pathologies in the CT or MRI scans to help radiologists in making quicker and more efficient diagnosis. Likewise, these models can be used in pathology to help in the exact diagnosis of tissues with pathologic changes and help pathologists in categorizing such tissues. The incorporation of such techniques in efficient clinical practice makes it a possibility to enhance the efficiency of diagnosis not only but also achieve the reduction of time that is necessary for the image analysis, and leave the clinician with more detailed evaluation of a patient. Since these MIS algorithms can directly impact the clinical decisions of the relevant professionals, it is crucial to guarantee that their assessment is correct and very solid [11]. A deep learning model, which might execute considerably well within sanitized research settings, might not provide similar outcomes when used in real-world clinical care settings with higher consequences and inevitably higher risks of inaccuracy. Hence, this new models should be tested and validated through various experiments to ensure that they are accurate and efficient before they are installed in the various hospitals [12]. This includes the selection of proper evaluation criterion that simulates the ability of the model to perform the intended tasks across noisy conditions, different patients’ cohort, with different image modalities.
However, in the recent past, there has been a worrying development in which some researchers have appeared to choose certain evaluation methods and reported only the high scores which in some instances are almost near 100%. It is an unsavory approach to qualify or demoralize a model because it does not give a holistic and honest view of the model’s performance and reliability. For example, some model might be almost flawless, designed for a clean data set where the data is not shuffled like in the clinic. Sometimes, it is witnessed that the researchers tend to attain the goal that is easier to solve or the measures that put the model in the best light while other measures that show that the model has some scholastic issues are either sidelined or hidden. To someone that uses these models in order to make important decisions, this can be potentially harmful. While deep learning-based methods in MIS [13, 14] hold a lot of promise for clinical decision-making in radiology, pathology, and other disciplines, they must be correctly and robustly evaluated for safety and effectiveness. Overly optimistic metrics in scientific publications of a recent trend may set unrealistic expectations among clinicians and other stakeholders about these models' true potential. In pursuit of safeguarding the integrity of clinical practice and patient care, it is incumbent upon researchers to embrace transparency and inclusiveness of assessment practices that, as far as possible, truthfully reflect the real-world performance of MIS algorithms.
One of the most challenging tasks in the area of medical image segmentation within the realm of computer vision is related to the large class imbalance characterizing a vast majority of medical images. By class imbalance here, it is meant that there is a disproportionate pixel class distribution in an image where the ROI, whether a tumor, lesion, or some organ, occupies a very small portion, and the rest is majorly labeled as background. In medical images, usually, the ROI occupies only a few pixels, while the background occupies more than 90% or even nearly 100% pixel content of an image. This turns out to be a quite challenging situation that machine learning models have to handle, especially for the classifiers dealing with class separation related to the ROI and the background. It is left up to the models to learn correct identification and segmentation of the ROI amidst its rarity in the training data. This class distribution inequality is much skewed, impacting every facet of the pipeline used in medical image segmentation within computer vision: from preprocessing to model architecture and training strategies, finally to the evaluation of model performance. In preprocessing, proper handling of class imbalance in a dataset is necessary so that the model gets adequate exposure to the ROI class during training. If left unhandled, the class imbalance will result in a case where the model becomes biased with respect to the majority class—the background—due to the fact that this dominates the training data. A wide variety of techniques is applied to artificially rebalance the dataset. For instance, data augmentation techniques can be applied to generate more examples of the ROI. Data augmentation techniques in this case may involve rotating, flipping, or scaling the ROI inside the image to introduce more variability and represent a comprehensive dataset for training [15]. In some cases, it is balanced by oversampling of the ROI class, either by duplication or slight changes in ROI samples, and under sampling of the background class itself by involving a reduction in the number of background samples to create a more equitable distribution of classes.
The proposed work is motivated by the fact that medical image segmentation is still far from perfect in terms of accuracy and reliability in clinical practice. Specifically, as most medical images are known to contain class imbalances, where regions of interest only occupy a very small portion of the image, existing models often fail to locate and segment these areas accurately, hence resulting in possible misdiagnosis or suboptimal treatment planning. It is expected that, through the development of more powerful techniques able to overcome these challenges, this work will allow an increase in model precision and robustness, ultimately leading to clinical decision-making improvements and better outcomes for patients.
The entire paper flows in this sequence; hence Section 2 comprehensively reviews the existing techniques on machine learning and optimization applied for medical image segmentation, enumerating the good and bad aspects associated with those approaches. Section 3 elaborates the details of the proposed work about the overall flow and specific methods that will be used to address the challenges. The proposed system results regarding the performance outcomes and comparative analysis are presented in Section 4. Finally, Section 5 concludes the paper with a few concluding remarks and mentions a few possible future research directions that might further enhance the methods presented for medical image segmentation.
2. Related Works
This section describes some of the existing methods of machine learning and deep learning in medical image segmentation. The section is meant to provide an in-depth review of the methodologies that trend in creation. This will refer to all approaches ranging from classical machine learning algorithms to current developments of deep learning contributing to making medical image analysis automatic. More importantly, this section reviews the problems and challenges that such approaches have encountered due to issues like class imbalance, model generalization, and computational complexity. By investigation of the limitations and deficiencies of previous techniques, it lays a foundation for later works toward more potent models that could find applications in the clinic.
Ding, et al [16] introduced the FTransCNN model which is a hybrid model of a CNN and a transformer where the two networks’ features are fused using a fuzzy logic system. This approach involves the use of the CNN and the Transformer as two parallel search engines, both of which perform feature extraction; channel attention to emphasize on the global key information regarding the feature from the Transformer, while the spatial attention pays attention to local details of the feature in the CNN. Despite this model’s capability of providing a more elaborate way of fusing feature representations from both the global and the local contexts, the main drawback of this model could be the added computational cost that comes with the dual-branch paradigm and the fuzzy fusion mechanism which may present realtime limitations or concerns when the model will be implemented on hardware devices with limited computational capabilities.
Kaushal, et al [17] discussed about the need to propose an efficient segmentation method based on deep learning algorithms to enhance recognition of the regions of interest for the subsequent fast segmentation. In order to meet this demand, they present a complete pipeline that combines the discriminative ability of conventional CNN and the segmentation ability of SI to improve the detection of area of interest. The research focuses on six modules, which are FCM, K-means, and other modifications using PSO and CNN for improving the segmentation accuracy and time. Although this approach provides a comprehensive survey of integrating conventional clustering algorithms with optimized and deep learning methodologies, it may come with one major limitation; the pipeline will become relatively intricate due to the integration of multiple algorithms research and honing, which may negatively affect the scalability of the procedure in real-world contexts. Narayan, et al [18] describe how anatomical segmentation is essential for the enhancement of numerous aspects of medical imaging these are planning, guidance and diagnostic models. Therefore, the paper is expected to outline and discuss applications of well-known medical imaging systems, historic and existing segmentation techniques, as well as medical image segmentation through the generations. However, one of the possible weaknesses of the paper is covering a vast number of topics that might be related to medical image segmentation, but the author shall ensure that the paper provides general information and not depth analysis of certain segmentations or difficulties.
Chin, et al [19] suggest the network, called Fuzzy DBNet, which combines the dual butterfly network and basic Fuzzy Atrous Spatial Pyramid Pooling (ASPP) to handle the pictures captured from both sides of the object. This approach is performed in order to refine the segmentation procedure due to the use of the data from both sides of the object. For the assessment, multi-category pill and lung X-ray datasets were applied and this model manifested remarkably high performance, as the average of Dice coefficient equal 95.05% for multi-pill segmentation and 97. 05% for lung segmentation. Although the high accuracy shines the performance of the Fuzzy DBNet, there exists a drawback in the current implementation, namely the addition of parallel processing doubles complexity and computation load. Shi, et al [20] have presented an idea of a multichannel convolutional neural network (CNN) based fuzzy active contour model regarding medical image segmentation. In their approach, medical images are first processed and labeled using the superpixel SLIC method in which the images are divided into many small regions. These segmented super pixels are then used to train a multichannel CNN to accurately segment the organ boundaries of the organs of interests. Superpixels produced by CNN can be used as the first seeds to set approximate division in order to fulfill first level segmentation. Such initial regions are further smoothed out to obtain the end organ boundary in the medical image by the use of Fuzzy Active Contour segmentation. As a virtue of this method, it provides a clear approach on how CNN could be combined with fuzzy active contour methods The drawback however could be the fact that it relies on superpixel-based segmentation to give an initial segmentation error could transfer itself to the final segmentation since the fuzzy active contour starts from the super-pixel segmentation.
Nagaraja, et al [21] intend to improve the diagnostic sensitivity for organs and associated diseases, including stroke for particular conditions by offering a fresh perspective of observing organs by means of multi-modal medical imaging. Besides, their study is on the formulation of a multiple modal medical image fusion model using a newly devised hybrid meta-heuristic algorithm. This model aims at enhancing the stability of image fusion systems by incorporating the multimodal data of the subjects. The approach starts from the W-FDCuT transformation of the images into the high-frequency and low-frequency sub-bands. This decomposition is planned to help the fusion process since it can provide better sources of information from the several modes. Ahammed, et al [22] describe a digital hair removal method using the morphological filtering methods such as the Black-Hat transformation and an inpainting algorithm to filter images. After this, blurring and noise is reduced using Gaussian filtering in order to smoothen out the images. The lesions which are affected by the disease are discriminated through the automatic Grabcut segmentation process. In order to extract the hidden features from skin images, GLCM is used along with a number of statistical features. The performance of the developed technique is then compared to three computationally efficient machine learning techniques which include Decision Tree (DT). As a strength, the approach provides an overall method to juxtapose hair removal from the skin and segmenting the lesions. However, a weakness could be that several preprocessing and feature extraction techniques could entail a time-consuming procedure during data integration, which may affect the efficiency and scalability of the system.
Talamantes-Roman, et al [23] departs from the conventional method of having a rigid factor by adopting this new approach of using a fuzzy inference system to periodically alter the factor. This adaptive adjustment is achieved by the fifteen fuzzy rules of the AFFL (Adaptive Fuzzy Focal Loss). A comparison of the results obtained by AFFL-TransUNet is made to seven other segmentation models at the same data split and computing environment. Evaluating based on the DICE coefficient indices following the statistical analysis shows that the proposed AFFL-TransUNet performs better than four models, and at par with the remaining models. Certainly, the application of the outlined approach can show high efficiency, yet, one of the possible disadvantages might be linked to the integration of the fuzzy inference system and its effects on computational complexity. Hooda, et al [24] proposed a clustering algorithm called Fuzzy-Gravitational Search Algorithm (GSA) for MRI brain image segmentation. This approach is an extension of the said Gravitational Search Algorithm (GSA) where parameter α is tuned with the help of fuzzy inference rules during the execution of the search. To gauge the success of the proposed method the outcomes are compared with those got from the standard GSA and the other latest algorithms for BI segmentation. The main investigations apply the Dice Coefficient measure to evaluate the performance on real and simulated data. One advantage of combining the fuzzy inference rules with GSA is the possible improvement on search methods; however, a disadvantage could be the time consumption caused by the dynamic modification of parameters within the segmentation step.
Wang, et al [25] proposed a novel fuzzy metric to address pixel uncertainty and further designed a fuzzy hierarchical attentional fusion neural network based on guided multi-scale learning. There is a fuzzy neural information processing block that maps input images into a fuzzy domain through fuzzy membership functions. Through this way, pixel uncertainty can be processed by the proposed fuzzy rule, and the results are finally integrated with convolutional outputs by the neural network. In particular, they further design a multi-scale guided-learning module for a dense residual block, along with a pyramidal hierarchical attention module, so as to extract more effective hierarchical image information. Although the methodology in the present approach is presented and can provide a very sophisticated mechanism for handling the pixel uncertainty and improving the image information extraction, one potential drawback is its complexity and induced computational overhead by the incorporation of fuzzy logic and multi-scale attention mechanisms. Validation of this approach's success should further ensure that the added complexity of the model entails making realistic segmentation performance over a large set of datasets and imaging conditions.
Literature on medical image segmentation shows some important gaps in current research that open up avenues for further development. Most of the existing approaches are heavily dependent on fixed parameter settings and conventional models; hence, this greatly limits their adaptability and therefore performance in varying clinical scenarios. Nevertheless, many methods, starting from classic clustering algorithms to fresh deep learning-based approaches, have shown very encouraging results, but often they are hampered by problems such as class imbalance and high computational complexity, not forgetting the requirement for extensive parameter tuning. While multi-modal imaging and advanced approaches of feature extraction methods have been explored, this still remains a challenge in terms of integrating such techniques to improve the accuracy of segmentation.
A review of the related literature in medical image segmentation portrays different methodologies representing different approaches and technologies, but perhaps their relations to particular developments or proposed work may not be clearly spelled out. FCNs recently set the baseline in this context of image segmentation because they use convolutional layers to directly predict pixel-level labels. FCNs come with a replacement of fully connected layers with convolutional layers, which may allow the network to directly produce segmentation maps. This is the technique used in the approach, as the spatial resolution result would include upsampling strategies to restore lost details in the downsampling process.
FPN improves segmentation by constructing a multi-scale feature pyramid that enhances the detecting of objects at varied scales. The architecture consists of building a top-down pathway in which high-level semantic features are combined with low-level details, allowing for more accurate segmentations in images where objects have varying sizes. UNet is an architecture designed specifically for biomedical image segmentation, including a symmetric encoder-decoder architecture with skip connections. Such skip connections allow the preservation of spatial information by adding high-resolution features from the encoder with corresponding upsampled features in the decoder, thus delineating the anatomical structures more precisely. Recently developed models now embed advanced techniques such as transformerbased methods that use the self-attention mechanism for capturing long-range dependencies in image data. These models try to address limitations of convolutional-based methods by incorporating global context instead of mere local features.
Most existing approaches often suffer from problems of robustly dealing with pixel uncertainty, handling heterogeneity issues in medical images, and fusing information from different modalities of imaging. There is an urgent need for both more sophisticated and adaptive models and, most importantly, dynamical tuning under changing imaging conditions and uncertainties. Also lacking are methodologies to bridge model complexity and computational efficiency that ensure cutting-edge techniques are plausible in real-time clinical applications. Addressing these gaps by the exploration of novel fuzzy logic integration, dynamic adjustment mechanisms, and improved multi-modal fusion techniques could go a long way in realizing important strides in medical image segmentation and hence improving diagnostic accuracy and the clinical decision-making process.
3. Proposed Methodology
This paper has presented state-of-the-art models referred to as the F-TransUNet, which is a major evolution in medical image segmentation. Such an F-TransUNet model creates a new way to hybridize the very well-established U-Net architecture with advanced transformer mechanisms. It improves both the local feature extraction and global contextual understanding capabilities. Traditional U-Net networks are very good at fine details captured in the spatial contexts due to their encoder-decoder structure and skip connections. Yet, they typically lack the capability to handle long-range dependencies and contextual relationships inside an image. To surmount such a limitation, F-TransUNet integrates the transformer-based self-attention mechanism. This mechanism is good at modeling global dependency, which enables the capturing of complex patterns along the whole image. By integrating this, it could do much more than very accurate segmentation at a fine-grained level but also understand and involve broader contextual information. By this hybrid approach, F-TransUNet expects to provide more accurate and more complete segmentation results for diagnostic medical imaging, hence easier clinical decisions. This model shows one more step in the development of a mixture of traditional and modern techniques to handle complex image data in medicine.
In this context, we look deeper into the approaches used in SSHOp and discuss how SMO and SCO contribute to the reinforcement of the said algorithms in order to boost the computational power of neural networks. The name of the new optimization method that is being developed is the Slime Sine Hybrid Optimizer, which enriches the SMO by SCO’s finetuning abilities. Among the optimization algorithms, one is Slime Mold Optimization algorithm that mimics a movement of the slime mold through the maze in search of food and can effectively search a large space and find the near optimal solution. This capability is especially beneficial where there is a need to overcome local optimization and achieve the global optimization and therefore SMO is a valuable asset in handling complications of optimization in neural networks. Besides, SMO there is the Sine-Cosine Optimization algorithm that contributes a precise refinement possibility thanks to the oscillate characteristic of sine and cosine functions to adjust solutions and focus on modifying them. Periodically repeating such a search helps to ‘jump out’ of local optima and get better convergence to global optima. Thus, in SSHOp, these two algorithms are mixed together, to benefit from their well-known advantages; the born optimizer is an effective combination of both exploration and exploitation. The integration also helps to guarantee the reliability and effectiveness of the optimization process while taking into account all the features unique to various configurations of weights in FTra-UNet. This is very important as learned weight values are the key ‘flesh’ of the developed model as it relates to the segmentation and classification of medical images. SSHOp achieves better weight space search and better generalization capability of the model, thus improving the model’s ability to achieve higher accuracy and reliability in medical image analysis. The originality of SSHOp is not seen in the center of excellence concept that is adopted by SSHOp, but rather in the combination of a dual focus optimization approach. The overall flow of the proposed MIS system is shown in Fig 1.
Although there are algorithms to maximize and minimize and simple ones to do either, SSHOp takes a better approach by containing the strengths of both in one set of algorithms. This is important in making sure that not only the model identifies the correct weight configurations but also the fine-tuning of the weights for better result is also achieved. SMO merged with SCO incorporated within the SSHOp is a new improvement in optimization methods, providing for a more effective and flexible application needed for improving the neural network’s functioning, especially in medical image segmentation. Overall, it constitutes a knowledge of the increased methodology and specific contributions of SSHOp to the established outline of the hybrid structure and incorporation of exploration and refinement procedures in the optimization of the learned weight values. Not only does this approach improve the result of medical image segmentation, but it also improves the abilities of FTra-UNet and similar neural network models as well as progressing in the approach of the state of the art optimization algorithms.
The BRATS, CT Lung, and dermatology datasets first undergo a number of critical steps in the preprocessing pipelines to be well prepared for the correct and efficient segmentation by the FTra-UNet model. For the BRATS dataset, with multimodal brain MRI scans, pre-processing begins with normalization to adjust the intensity values of the images into a common scale, which helps reduce variability between different scans. Skull stripping removes non-brain tissues to have a good focus on the model for relevant areas and reduces the segmentation task only to brain regions and tumor ones. Besides, some other augmentations will involve rotation, scaling, and flipping to generate various variations of the original images, which would help in improving the robustness and generalization capability of the model.
Below are the basic steps that are considered preprocessing for the CT Lung Dataset used in the detection and segmentation of lung nodules. Image intensities have to be normalized to make the scans consistent. Resampling of voxel size is done to isotropic for fine three-dimensional analysis of lung structures. Data augmentation is carried out in a manner similar to that for the BRATS dataset: increasing variability by rotation, scaling, and other such transformations that would serve to enhance the performance of the model on variable data.
Preprocessing of the dermatology dataset of skin lesion images begins with the normalization of the intensity values so that the images are comparable from different sources or lighting conditions. These are then resized to a constant dimension; in that way, the model is faced with a regularization in the input size and uniformity in processing. The ground truth segmentation masks are generated manually by expert annotators to provide the right labels while training the model. Some of the noise reduction techniques were used for improving the quality of the images through filtering out the artifacts, since this helps get precise lesion segmentations. The training dataset is extended using different data augmentation techniques, such as rotation, flipping, and color jittering, which make the model general for new images.
These encompass normalization, resampling, registration, noise reduction, and augmentation-all very important preprocessing steps in preparing the datasets for feeding into the FTra-UNet model. If the images are well preprocessed, the model will have the capability to learn from the images themselves. This will give consistent and high-quality segmentation results, which are so vital for diagnosis and treatment planning in medical fields.
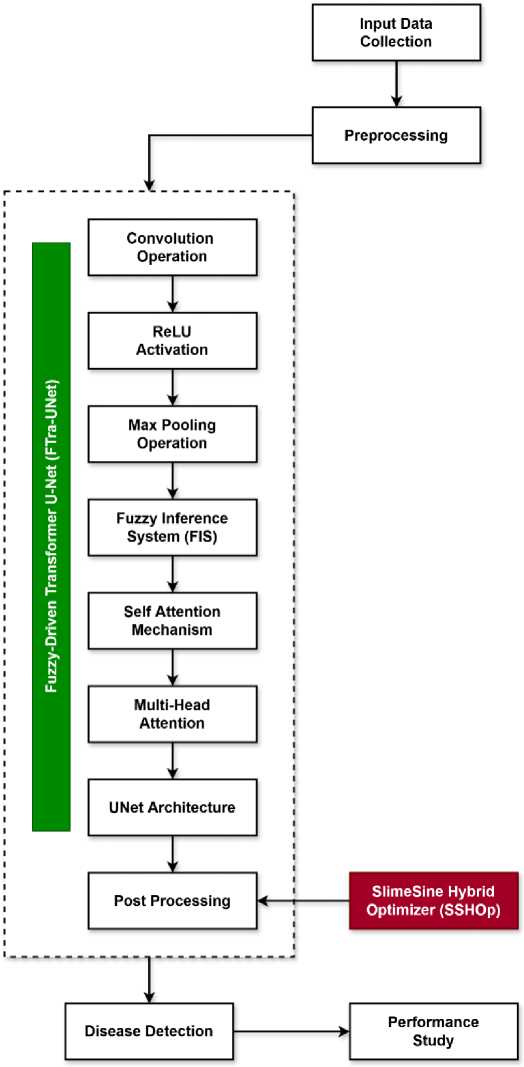
Fig.1. Overall flow of the proposed MIS system
-
3.1. Fuzzy-Driven Transformer U-Net (FTra-UNet)
The Fuzzy-Driven Transformer U-Net (FTra-UNet) is an improvement in the medical image segmentation due to incorporation of fuzzy logic with the Transformer areas in the U-Net framework. This is a combined approach that seeks to combine the good features of both fuzzy systems and the advanced mechanisms of attention to improve segmentation outcomes especially in medical image analysis. Moreover, the FTra-UNet comprises the cascaded U-Net architecture, which has proven to be highly effective for segmenting biomedical images and Broderick’s fuzzy logic and transformer-inspired attention mechanisms. The U-Net architecture with the contracting path, also known as encoder, and expanding path, also known as decoder, and skip connections is able to capture different scales of the data and its spatial organization.
However, considering the drawbacks of original U-Net model mostly in conditions when an input is ambiguous or noisy, the FTra-UNet also employs fuzzy logic as a decision level fusion technique. This component is connected to the network in order to enhance the model’s uncertainty dealing with and partial information which is typical in contrast variants, noise, and artifacts of medical images. The degree of membership of each pixel in several fuzzy sets is determined by the use of fuzzy membership functions. Including such a term in the model makes it possible to address the problem of fuzziness of the medical images where boundaries of the structures are not clearly defined. The Fuzzy aggregation and inference systems present in the FTra-UNet can also be used to optimize the segmentation results based on probabilistic pixel values, this makes the segmentation more efficient and fast at the same time.
Moreover, to accommodate the intricate relations of different organs in medical images, FTra-UNet employs Transformer modules to improve the components’ capacity to understand long-range dependencies and contextual information. Allows the network to attend to the areas of the image that it needs to, regardless of their locality, thus enhancing the ability to segment intricate structures in addition to fine features. The attentiveness to this mechanism is useful in medical image analysis as the features may be scattered and need contextual analysis for proper recognition. Thus, the FTra-UNet approach can be considered new in the sense that it combines fuzzy logic with Transformers within the context of the U-Net architecture. The initial U-Net structures usually employ convolutionary operations and the pooling layers which hardly resolve uncertainties and cover long dependencies. With the help of the fuzzy logic, the proposed FTra-UNet develops a mechanism to address the uncertainties in terms of pixel and thereby brings more resilience of the model against noises and variations. Moreover, Transformer modules combined with CNNs enhance the network’s capacity to perceive the spatial relationships in the entire image and promote local and global structural representation learning for accurate delineation of complex anatomical structures and abnormalities. In addition to that, it is crucial to mention a novel feature of the proposed FTra-UNet: the combination of fuzzy logic and Transformer’s selfattention module into a U-Net framework. This combination addresses two critical aspects of medical image segmentation: It is evident that both abilities pertain to coordinating uncertainty and acquiring global contextual information. The outcome is a model that enhances the level of segmentation and at the same time has higher robustness to obstacles linked with medical imaging such as noise or variations in image quality.
The method for Fuzzy-Driven Transformer U-Net offers several very evident advantages over other medical image segmentation techniques. It basically combines the power of fuzzy logic with that of a transformer-based attention mechanism within the traditional U-Net architecture. Traditional methods of segmentation that are based on simple U-Net models generally retain vagueness and variability of medical images caused by noise or unclear boundaries, thus often rendering the results unsatisfactory. These challenges are addressed by the model of FTra-UNet, which includes fuzzy logic to better handle uncertainty and partial information. This may become very critical in medical imaging due to the reduction of the clarity of anatomical structures by imaging artifacts or lowering their distinguishability by variation in contrast. The Transformer modules in FTra-UNet offers an effective way to capture long-range dependencies and contextual information across a whole image, enabling the model to differentiate between complex structures and subtle details dispersed across images. Compared to traditional mechanisms of segmentation—most of which rely on local features or straightforward convolutional operations—the use of fuzzy logic makes the FTra-UNet more resilient in noisy and ambiguous data, while Transformer attention mechanisms confer it with a greater understanding of the global context and spatial relationships within the image. Such a combination makes the segmentation accurate and reliable in very challenging medical imaging scenarios, requiring accurate delineations for diagnosis and further treatment planning. Overall, therefore, the FTra-UNet realizes major progress to that effect, since sophisticated approaches blend and let individual strengths overcome the limitations of conventional techniques, realizing superior performance in medical image segmentation.
As shown in fig 2, the convolution operation is performed initially after getting the input image, which is mathematically represented in the following equation:
MICon(i, j, x) = ∑ P p=1∑a C =h1∑ C b=w1MI(i + a,j + b,P) × C(a, b, p, x) (1)
Where, MICon(i, j, x) represents the output feature map, x denotes the filter, MI(i + a,j + b, P) indicates the pixel value of input image, P represents the image channel, C(a, b, p, x) denotes the convolutional kernel value at position (a, b), Ch and Cw are the height and width of kernels. As a consequence of this, the ReLU activation function is estimated on the convolution output, which helps to analyze the complex non-linear patterns of image. This operation is represented in the following equation:
ReLU(k) = max (0, k) (2)
Then, the maximum pooling operation is performed to minimize the spatial dimensional of the feature maps, which takes the maximum value along with the pooling window. This operation is mathematically indicated as follows:
MIpool (i, j, p) = max max MI(i × δ+a,j × δ+b,p) (3)
a ∈ [ρ h -1] b ∈ [0,ρ w -1]
Where, MIpool(i, j, p) represents the output of maximum pooling operation at position i, j, ρh, ρw are the height and width of pooling window, 5 denotes the stride, and max is the maximum value of window. The main purpose of ae[Ph-1]
adopting this layer operation is to optimize the computational load with less time. Moreover, the Gaussian fuzzy membership function is estimated in order to determine the degree that the pixel of image belongs to a fuzzy set. It is mathematically described in the following equation:
(k—m):
m(k) = exp - —3-
Where, m(k) represents the membership degree of input image, m is the mean and ф denotes the standard deviation. Consequently, the fuzzy aggregation is performed that integrates multiple membership functions together to take an effective decision according to the minimum degree of membership function. This function is mathematically represented as shown in below:
Where, P f uzzy(k) represents the aggregated fuzzy output, and m1(k),m2(k) .mn(k) denotes the membership degree. Then, the fuzzy inference system output is obtained as shown in the following equation:
Out fuzzyW = ZiU^ i x ₽ i (k) (6)
Where, Out f uzzy(k) indicates the output of fuzzy inference system, TO i is the weight value of the fuzzy rule, and P i (k) is the output of fuzzy rule. After that, the self-attention mechanism is implemented to enhance the ability of transformer, which supports to analyze the relationships among different parts of the image. This operation is mathematically written as follows:
A(i,j) = softmax q(i)x(j) x v(j) (7)
V“ h
Where, A(i, j) indicates the attention mechanism, q(i) is the query vector, f(j) indicates the key vector, v(j) represents the value vector, and d h is the dimensionality of key vector. Furthermore, the multi-head attention mechanism is applied to analyze different patterns of the given image, which is mathematically described as follows:
Where, MulA(i,j) indicates the output of multi-head attention mechanism, A 1 (i,j), A 2 (i,j) . A h (i,j) are the attention outputs, and TOout is the learned weight value. Furthermore, the skip connections are being used in the U-Net architecture that combines both the encoder and decoder paths. It is modelled as shown in the following equation:
MISkip (i, j) = Concat(MIenc (i, j) x MIdec (i, j))(9)
Where, MI skip (i,j) indicates the concatenated output, MIenc(i,j) and MI d ec(i,j) are the encoder and decoder paths. In addition, the upsampling or the transposed convolution operation is performed for enhancing the spatial resolution of the feature maps, which is described as follows:
MIup (i, j, p) = Zhi ZPW1 MIcon(i-a,j- b,p) x %up (a, b, p)(10)
Where, MI up (i, j,p) indicates the upsampling output, MICon(.) is the convoluted feature map, and % up (.) is the upsampling kernel information. Finally, the fuzzy post processing operation is performed to obtain the final segmentation result as demonstrated in the following equation:
0pop(i,j) = Et TOi x mt(0(i,j))(11)
Where, OPoP(i,j) indicates the post-processed output. The final post processing operation helps to significantly enhance the segmentation quality with reduced noise. The FTra-UNet is an embedding of fuzzy logic into the power of the Transformer U-Net architecture, striding forward in medical image segmentation by capturing complicated spatial relationships and handling uncertainty. It performs superiorly accurate segmentation, especially on those challenging scenarios where the delineation of precise boundaries is critical, owing to an innovative use of convolutional layers, selfattention mechanisms, and fuzzy post-processing. Fuzzy logic gives the "third dimension" to the model in handling ambiguity and, therefore, allows for better decision-making. On the whole, the method in general, FTra-UNet is robust, adaptive, very promising improvements expected in medical image analysis; deep learning-based medical diagnostics were presented to be forwarding.
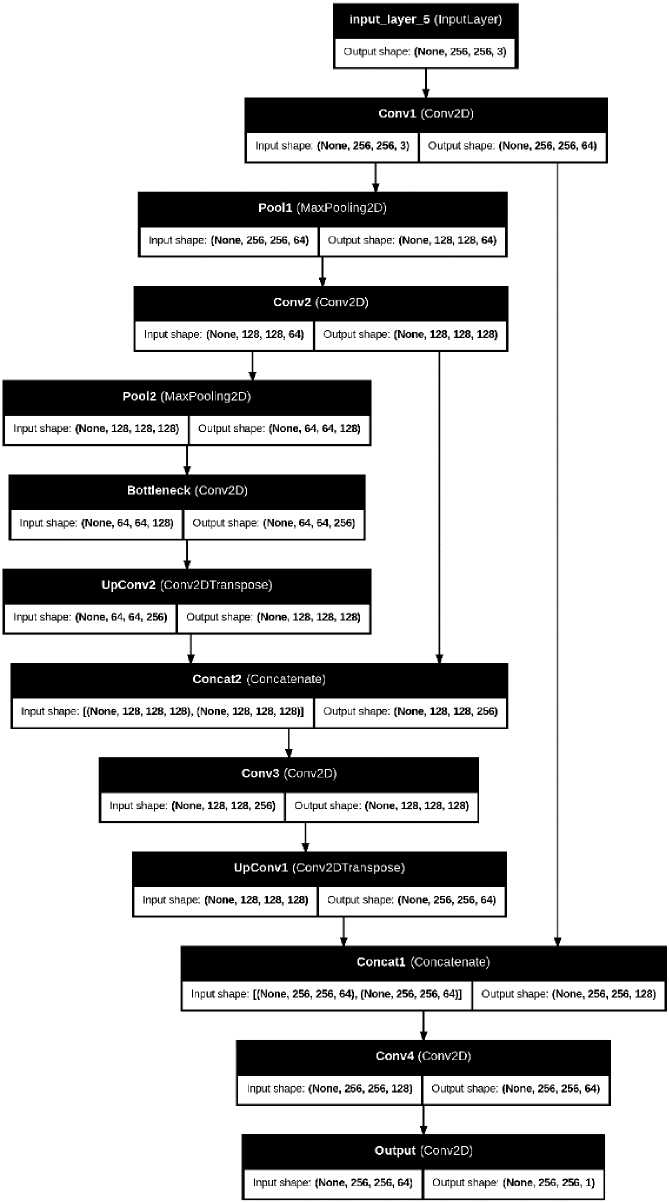
Fig.2. Architecture of proposed FTra-UNet model
3.2. SlimeSine Hybrid Optimizer (SSHOp)
4. Results and Discussion
SlimeSine Hybrid Optimizer (SSHOp) is a recent optimizer method aimed to improve the computation of the learned weight values in models like the FTra-UNet. This optimizer integrates both Slime Mold Optimization (SMO) and SineCosine Optimization (SCO) algorithms, aiming at combining the two algorithms’ beneficial properties for enhancing the performance within intricate machine learning models. In neural networks, the learned weight values are vital and impressionable parameters that enable the type of learning from training data and unseen data. They decide on how input features are transformed across the network’s layers as a result affecting the models accuracy, efficiency, and reliability. It is a critical task to tune these weight values while seeking to find the global minimum for the loss function and increasing the model’s accuracy. Concerning the topic of deriving inspiration, the Slime Mold Optimization algorithm is derived from the foraging behavior of slime molds, efficient in finding the best path through a maze. SMO is useful to define near-optimal solutions from a large search area because it is a simulation that emulates the above biological process. SbP:
It is good at prevention of local optima and finding global optima by balancing the exploration and exploitation. When it comes to adjusting derived weight values, SMO assists by conducting through a search of ideal weights that will lower the loss function and thereby enhance the model reliability. Whereas for Sine-Cosine Optimization algorithm is based on sine and cosine functions for dynamic adjustment of the search process. SCO stands out in adjusting values because, through mathematical variations, it improves the optimization of weights. This is helpful in getting a better optimization within the weight parameters since sine and cosine functions which are involved are periodic and can help the model escape local optima and arrive at the global optima. The integration of SMO and SCO is the SSHOp which takes advantage of the exploration aspect of SMO and the fine-tuning aspect of SCO. This hybrid approach makes the search of the weights space more exhaustive with SMO dealing with the global search while SCO refines on the search space for the weights. Incorporating all these techniques, SSHOp presents a stable platform by which learned weight values can be optimized for; this tackles the global and local aspects of the optimization issue.
That is to say, if SSHOp is applied in optimizing the weight values learned by the FTra-UNet model, it will realize much better performance both in accuracy and efficiency. The optimizer will enhance adaption of the network to complex patterns and relationships in the data, hence improving segmentation and classification results. Optimization at this step is very important for good performance of the model on different tasks and datasets; hence, reliable and effective applications in real-world scenarios. It is the breakthrough development in optimization techniques against neural network models. This hybrid method incorporates the advantages brought about by Slime Mold Optimization and Sine-Cosine Optimization, aiming to get better results in computing learned weight values. The SSHOp optimizes two critical parameters so that the generated model can be more accurate, efficient, and robust in general performance and reliability involving complex machine learning systems like FTra-UNet.
This work will use the Slime Sine Hybrid Optimizer algorithm in tandem with fuzzy logic for the proposed FTra-UNet model, the use of which was informed by a number of key factors in solving some of the main challenges identified within the context of the medical image segmentation process, such as uncertainty handling, optimization of parameters, and increasing the speed of convergence. Traditional optimization methods such as GA, PSO, or even Gradient Descent often suffer from the problem of slow convergence and mostly get stuck into a local minimum that might be the case with highly nonlinear and complicated medical datasets. Among all, SSHOp was chosen for its unique combination of exploration capability provided by the Slime Mold Algorithm with the exploitation efficiency provided by SCA. Similarly, the Slime Mold component is mimicking the intelligent foraging behavior of slime mold organisms, enabling better adaptiveness in a more dynamic search space exploration-a must ingredient for the exposition of optimal solutions in a complex environment characterized by medial images of different textures and features. On the other hand, SCA adds to the precision in refining the search process because of the ability of this method to balance exploration and exploitation better compared to the other methods, for fine-tuning parameters of the model for high accuracy. Being a hybrid approach and unlike a single approach, this avoids the early convergence problem of SSHOp and hence significantly enhances the capability of a model towards global optimization. By being integrated into the FTra-UNet model, SSHOp enables speedier convergence without sacrificing segmentation accuracy on many medical datasets. The robustness of SSHOp further helps in finetuning the learned weights from deep learning architectures to provide the necessary stability to the model so that it could present precise and consistent segmentation outcomes on several pathological and anatomical structures. The combination of the aforementioned features, along with its uniqueness, made SSH-Op. the most suitable choice instead of conventional methods since those are less capable of handling the complex multidimensional optimization challenges presented in the segmentation tasks of a medical image.
This section includes detailed validation with respect to the performance outcomes and findings for the proposed model, namely FTra-UNet. Various evaluation metrics will also be employed to test its efficiency. The segmentation capability is run through most of the datasets after extensive experimentations to get an extremely firm view about strengths and limitations. The quantitative measures used in this evaluation include accuracy, precision, recall, and the F1-score. In these ways, the model can perform good segmentation of medical images, particularly when substantiated with qualitative analyses, such as the visual inspection of the segmented outputs, to underline the model's efficiency in handling any complex challenges related to medical imaging. Very careful results comparison is conducted with the existing state-of-the-art models, showing the progress and novelties brought by FTra-UNet. In this section, an effort will be made to be as detailed as possible with regards to the performance of the present model, and its impact on the whole domain of medical image segmentation will be outlined, including its clinical application.
In this work, the performance of the proposed FTra-UNet model is evaluated on three different, very famous datasets: BRATS, CT Lung, and another dermatology dataset from Kaggle. All these datasets have a critical role in showing the robustness, adaptability, and precision of this model on different medical imaging challenges. One of the benchmark datasets in the domain of brain tumor segmentation is the BRATS dataset. Besides, it includes multi-modal MRI scans and detailed annotation for different sub-regions of these tumors; hence, making it a suitable dataset for model evaluation with respect to its capability for segmenting structures correctly which appear complex and heterogeneous in the brain. The inclusion of BRATS in this study ensures that the performance of the model is strictly tested for one of the most challenging tasks in medical image segmentation. On the other hand, the CT Lung dataset focuses on lung disease detection and segmentation with respect to lung cancer and other pulmonary conditions. This dataset comprises CT images, with the anatomy of the tissues of the lungs depicted in great detail, hence adding another dimension of difficulty to the problem because of the variability in anatomy and presence of pathological features of the lungs. In this respect, the application of the CT Lung dataset would give grounds for assessing how well the model can generalize across different imaging modalities and anatomic structures, further vindicating the model in the clinic. Finally, Kaggle's dermatology dataset contains a diverse range of skin lesion images with different kinds of dermatological conditions. This would be very useful in evaluating model performance with respect to the dermatology domain, where the segmentation of skin lesions is necessary for early diagnosis and the generation of a treatment plan. The dataset has images ranging in complexity from very simple to highly challenging cases and hence would therefore test the model's segmentation capabilities comprehensively in dermatology. In the performance evaluation phase, all of these three datasets will be combined to evaluate this FTra-UNet model comprehensively for different medical image tasks. Testing on datasets with such high variety in terms of anatomy and pathology makes these results very strong evidence of potential improvement in segmentation accuracy across different clinical applications.
These are some of the key clinical metrics in medical image segmentation, including accuracy, precision, recall, and F1-score, because such metrics will directly influence the quality and reliability of the diagnosis and subsequent treatment decisions in medicine. Later, the implications of the above metrics on real-world medical decisions are discussed in detail.
Accuracy can be viewed as the ratio of correctly classified pixels or regions in the segmented images with respect to the total number of pixels or regions. High accuracy in segmentation in a clinical environment usually means high reliability in identifying both the anatomical structures and pathological regions. This will be very important in ensuring radiologists and other healthcare professionals trust the segmented images on issues of diagnosis. For example, the correct demarcation of tumors or lesions within a medical image should indicate the extent and stage of a tumor, to which appropriate treatment planning and prognosis are directly related. Deceitful segmentation may therefore result in incorrect diagnosis, unnecessary treatment, or overlooked pathological findings-all serious for the care of patients.
Precision or positive predictive value refers to the proportion of true-positive segments among all segments that were identified as positive. Clinically speaking, it is important to have a high precision to avoid false positives when there are instances of incorrectly classifying a region as pathological when it is not. High precision reduces the risk from a positive result of unnecessary follow-up procedures, biopsies, or treatments that may result from false positives. For example, high precision in the detection of cancerous lesions will ensure that only true lesions are detected and intervened on; this will prevent anxiety and unnecessary interventions in patients.
Recall or sensitivity is the ratio of true positive segments identified out of all actual positive segments. Recall is an important factor in clinical setups because one would like to see the model detecting all relevant pathological regions, even at the cost of some false positives. The lesser the missed significant pathological findings, the better the early detection and treatment on time. In disorders like cancers or diabetic retinopathy, for instance, high recall means the identification of all areas that could be involved, which is very crucial for appropriate and timely interventions.
The F1-score is the harmonic average of precision and recall and provides a single metric that balances the two. This is very useful in clinical settings in which both false positives and false negatives have considerable ramifications. A high F1-score indicates a good balance between precision and recall in the model for the segmentation results. It means that while effective at finding the relevant regions, it minimizes misclassifications of healthy areas. The property is crucial in thorough diagnostic processes since exactness and completeness are an invariant of complete disease detection and, correspondingly, treatment planning.
In practice, the metrics will directly influence the clinical decision-making process since they reflect changes in the reliability of diagnostic tools. These segmentation models will ultimately yield more informed decisions about the mode of patient care through planning surgeries, the management of therapies, and monitoring of disease progression. Conversely, any model exhibiting poor accuracy, precision, or recall will ensure false diagnosis, inappropriate treatment, or missed diagnosis with subsequent effects on poor patient outcomes. Improved metrics through advanced segmentation models, such as FTra-UNet, will continue to improve the clinicians' capability for quality care, reduced diagnostic errors, and optimization of treatment strategies on the basis of more reliable and comprehensive imaging data. This, in turn, should translate into better patient outcomes, more efficient use of health care resources, and a reduction in the overall burden of disease.
The high values of these performance metrics-precision, recall, accuracy, and F1-score-indicate that this model promises excellent results on those datasets which it dealt with. These metrics hint that the model identifies and segments out the features of interest in the medical images with high efficacy. For instance, in segmentation of brain tumors, high accuracy and precision would imply its reliability to delineate tumor tissues from normal ones. That would be an important capability to make sure clinicians make appropriate decisions about surgery, radiation, or other therapies, based on correct tumor boundaries. In fact, in detecting lung nodules, high metrics for segmentation ensure the model can skillfully accomplish identification and segmentation; nodules are quintessential features in the early diagnosis and management of lung cancer. This minimizes the possibility of failing to recognize potentially cancerous lesions and improves patient outcomes. In dermatology, high performance in skin lesion segmentation will allow for proper diagnosis of the skin condition, thus playing an important role in treatment and follow-up.
However, there are a number of limitations that may influence the performance of the model in real-world scenarios. The BRATS, CT Lung, and dermatology datasets, on which the training and evaluation were done, represent a selected imaging modality and clinical scenario. This performance may not directly translate to those datasets or clinical settings that did not form part of the training. Differences in different imaging protocols, differences in patient demographics, and even differences in disease manifestations could affect model efficiency under diverse real-world settings. Besides, high metrics obtained on controlled, pre-processed datasets could indicate variability and issues related to quality met within clinical practice. Such factors may include, but are not limited to, potential dissimilarity in image quality, an artifact, or another clinical setting of imaging that could further affect the consistency and high performance of the model. While the metrics are high performance across the studied datasets, further validation by exposing the model to a wide variety of realistic clinical conditions is therefore a necessity if it is to offer dependable and accurate results under normal medical practice.
UNet, FCN, and FPN are preferred baseline models since these established techniques are representatives of various studies on comparisons of medical image segmentation. Indeed, each baseline model has its respective characteristics and strengths to measure performance.
UNet is the most used architecture, proposed only for biomedical image segmentation. It has a symmetric encoderdecoder architecture and skip connections that enable precise localization by combining high-level semantic information with low-level details. Because of its effectiveness in many medical imaging applications, this paper has chosen it as the baseline. UNet should ideally perform very well in segmenting elaborately complex structures and capturing the subtleties of medical images by design; hence, it is one of the most suitable models to compare with. For proper comparison, UNet is set up according to typical hyperparameters for the number of convolutional layers, kernel sizes, and the use of dropout for regularization as first proposed in the literature. This ensures that all performance differences are actually due to the new model and not because of differences in how the model was set up.
FCN is a basic semantic segmentation framework that replaces fully connected layers with convolutional layers, which can achieve pixel-level prediction. We adopt it as the baseline model because it reflects the most basic solution for segmentation tasks and thus has been widely adopted and investigated in the literature. The architecture of FCN is remarkably simple and effective to convert image classification networks into segmentation networks. In configuring FCN for a fair comparison, standard configurations are made to the model, including selecting the backbone network, such as VGG or ResNet, and the use of upsampling layers to recover spatial resolution. This is kept constant so that the comparison will be focused on the efficacy of the proposed model relative to this established method.
We select FPN for the baseline because it handles multi-scale object detection through a pyramid of feature maps at different levels of resolution. The performance of segmentation is further improved by taking advantage of the features within various scales, which plays a very important role in object detection regarding objects of different sizes with accurate segmentations in different scales. Incorporate a backbone network with a top-down pathway, along with crossconnections to construct the feature pyramid. In order to be fair for comparison, a standard parameter is used in setting up the FPN model. Examples include the number of pyramid level and upsampling using bilinear interpolation, adopted directly from the original literature. This setting ensures that the comparison is focused on the enhancements of the proposed model and does not include biases on the number of setups with FPNs.
99.2
99.1
98.8
98.7
98.6
98.5
98.4
Accuracy Precision Recall Sensitivity Specificity Jaccard Dice
Fig.3. Performance outcomes of the proposed model for Brain images
Table 1. Performance analysis of the proposed FTra-UNet model using different medical images
|
Measures |
Brain |
Ultrasound |
Dermoscopy |
|
Accuracy |
99.1 |
98.89 |
99 |
|
Precision |
98.8 |
98.81 |
98.9 |
|
Recall |
98.78 |
98.85 |
98.8 |
|
Sensitivity |
99 |
97.88 |
98.79 |
|
Specificity |
98.8 |
98.21 |
99 |
|
Jaccard |
98.68 |
98.05 |
98.67 |
|
Dice |
98.99 |
98.16 |
98.78 |
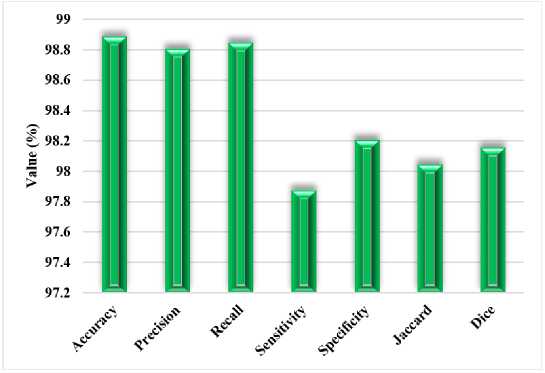
Fig.4. Performance outcomes of the proposed model for Ultrasound images
Table 1 presents the performance analysis of FTra-UNet on Different Medical Images. Accuracy, precision, recall, sensitivity, specificity, Jaccard Index, and Dice Coefficient all show that this model is capable of having high segmentation accuracy across these rather diverse medical imaging modalities. On brain images, it is even very accurate, at 99.1%, indicating that nearly all the segmented regions were correctly classified. Both precision and recall are over 98%, thus the model becomes very good at detecting relevant features, avoiding false positives and false negatives. It reported a very high sensitivity of 99% with respect to the pathological regions of the brain; the specificity value was 98.8%, reflecting a balanced performance in identifying the presence or absence of pathological regions. The very high overlap between predicted and ground truth segmentations, close to 99%, was also proved by the Jaccard Index and the Dice Coefficient, hence proving that the model works precisely and predictably in brain image segmentation.
FTra-UNet retains its performance on ultrasound images, still at an accuracy of 98.89%. The precision and recall are also very high, with values of about 98.8%, thus indicating that relevant features are well captured in the ultrasound images using this architecture at a low error rate. The slightly less Sensitivity of 97.88% would also mean a slight loss in the model's ability to identify all cases of the truth, probably due to inherent challenges pertaining to ultrasound imaging itself, such as noise and reduced image resolution. However, the Specificity still remains very high at 98.21%, thus proving the model's robustness in the correct identification of non-pathological regions. It yields a Jaccard Index and Dice Coefficient of 98.05% and 98.16%, respectively; thus, the performance implies very substantial agreement between the predicted and actual segmentations. Strongly this attests to the model's effectiveness in processing ultrasound images.
The overall performance expressed by the model on dermoscopy images is 99%. Precision and recall are both about 98.9%, therefore establishing that this model works very well in detecting and segmenting skin lesions with very few false detections. High sensitivity of 98.79% and specificity of 99% were also found, thus proving the model performs well in lesion detection while being highly discriminative between healthy and affected skin areas. The Jaccard Index and Dice Coefficient values, estimated close to 99%, show very good overlap between the predicted and ground truth segmentations, thus validating further its accuracy in the analysis of dermoscopy images. Fig 3 to 5 show the performance results for brain, ultrasound, and dermoscopy images, respectively. These figures further explain the general consistency and effectiveness of the model on three imaging modalities, thus providing a comprehensive view of its segmentation capability. High-performance value metrics in all three types of medical images proved the FTra-UNet model as versatile and reliable for medical image segmentation, hence assuring that it will turn in an accurate result with consistency in varied clinical scenarios. This would be key to any potential application in real medical environments where precision and reliability are paramount.
Table 2. Comparative analysis with conventional segmentation models using BRATS dataset
|
Measures |
Dice |
Sensitivity |
PPV |
Jaccard |
|
UNet |
75.35 |
74 |
81.25 |
63.12 |
|
FCN |
73.43 |
66.16 |
86.66 |
60.71 |
|
FPN |
81.07 |
71.08 |
88.80 |
69.72 |
|
SegNet |
73.20 |
71.6 |
82.7 |
69.20 |
|
MM-LinkNet |
77.73 |
76.62 |
89.65 |
71.69 |
|
Proposed |
98.96 |
99 |
98.78 |
98.85 |
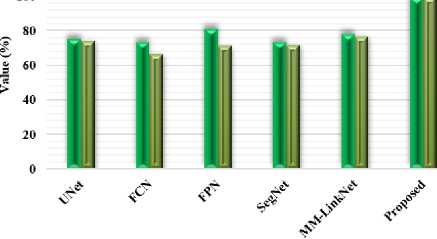
и Dice ■ Sensitivity
Fig.5. Comparison based on dice and sensitivity measures using BRATS dataset
Table 2 presents the proposed FTra-UNet against some traditional models of segmentation, such as UNet, Fully Convolutional Network, Feature Pyramid Network, SegNet, and MM-LinkNet on the BRATS dataset. This will be of prime importance in developing the proposed model to show improvements over traditional models in these very key performance metrics of Dice Coefficient, Sensitivity, PPV, and Jaccard Index. Results clearly indicated that the proposed FTra-UNet model had huge improvements over traditional models for all metrics. The Dice Coefficient went as high as 98.96% for the proposed model, much bigger than the other models, including FPN with a coefficient of 81.07% and MM-LinkNet with a coefficient of 77.73%. It means that the FTra-UNet model has much more overlap between predicted and ground truth segmentations, hence being far more effective in identifying and correctly segmenting areas with tumors in brain images from the BRATS dataset.
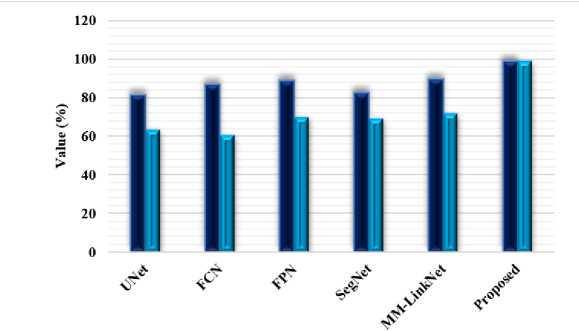
■ PPV BJaccard
Fig.6. Comparison based on PVV and jaccard measures using BRATS dataset
In the same way, sensitivity by the proposed model is 99%, standing highest among all models being compared. A high sensitivity for the FTra-UNet model indicates that it is very good at correctly classifying most positive instances, that is, tumorous regions of interest, with very few false negatives. As such, nearly all of the true positive cases are detected. Other models, like FCN and FPN, have a sensitivity of 66.16% and 71.08%, respectively, indicating their relatively poor capability about the coverage of important features in the images. It means that the PPV value of the proposed model corresponds to 98.78%, thus proving very proficient at reducing false positives, which it will not only be good at detecting the true positive but also ensure that most of its positive predictions will be correct. Therefore, it is much better than the PPV values from traditional models like SegNet with 82.7% and FCN with 86.66%. It can be noticed that the Jaccard Index, used for calculating the similarity between predicted and real segmentation, also demonstrates very nice supremacy for the proposed FTra-UNet model, yielding 98.85%. This strongly stands apart from the Jaccard scores by models like UNet with 63.12% and FPN with 69.72%. Therefore, this clearly proves that FTra-UNet provides much more accurate and reliable segmentation, which is essential for effective clinical decision-making. Performance comparisons using Dice and Sensitivity measures with the BRATS dataset are shown in Figures 5 and 6 using PPV and Jaccard measures. These graphs obviously bring out huge improvements offered by the FTra-UNet model over the traditional approach, underpinning its better ability to ensure high segmentation accuracy and reliability in brain tumor segmentation. These improvements in the key metrics make the proposed model extremely effective at medical image segmentation alone, let alone complex datasets like BRATS where precision is vital
Table 3. Comparative analysis with conventional segmentation models using CT lung dataset
|
Measures |
Accuracy |
Precision |
Recall |
|
FCN |
75.36 |
57.35 |
80.29 |
|
SegNet |
73.58 |
54.62 |
92.58 |
|
UNet |
92.56 |
88.96 |
87.56 |
|
UNet++ |
97.71 |
96.85 |
95.85 |
|
Proposed |
98.89 |
98.78 |
98.80 |
Table 3 compares the proposed FTra-UNet model with traditional segmentation models like Fully Convolutional Network, SegNet, UNet, and UNet++ on the CT lung dataset. This comparison will be very useful in knowing the efficacy of various models for the segmentation of lung images concerning Accuracy, Precision, and Recall. Results show that the proposed FTra-UNet model outperforms the existing models in all the measures evaluated. It has an accuracy of 98.89%, way above that of all the traditional models. For example, UNet++ gives an accuracy of 97.71%—although that is one of the more advanced models of architecture—while basic ones like FCN and SegNet have accuracies of 75.36% and 73.58%, respectively. This is to show the high capability of FTra-UNet in correctly classifying the pixels, either to the lung tissue or the background, hence achieving more accurate segmentation of the lungs. This will be in terms of precision, which is the proportion of true positive identifications against all positive identifications. It is noted that the proposed model realizes a very impressive score of 98.78%. This is way above that of UNet++ that realized a precision of 96.85%, while UNet was at 88.96%. The Precision score with FTra-U-Net is much higher, thereby proving that it's significantly reducing false positives and thus continuously being reliable and accurate in its predictions.
The recall of the proposed model is also very high, at 98.80%, indicating that almost all real positive cases have been correctly detected, that is, the lung tissue in the dataset. This surpasses UNet++ with a recall of 95.85% and far outperforms FCN with 80.29% and SegNet with 92.58%. A high Recall score is important in medical image segmentation because it will ensure that the model itself is sensitive enough to capture all the relevant features, thereby reducing the chance of missing any critical lung tissue while segmenting. Fig 7 compares the performances of these models w.r.t. Accuracy, Precision, and Recall using the CT lung dataset. The results clearly explain that the proposed FTra-UNet model has radically improved traditional segmentation techniques. The results confirm that the FTra-UNet not only provides better overall segmentation performance but turns out to be very reliable with respect to correct identification and segmentation of lung tissue from CT images. These developments have made the FTra-UNet model a very instrumental tool to the medical profession, more so in the early detection and treatment of lung-related diseases, where exactitude and accuracy are most needed.
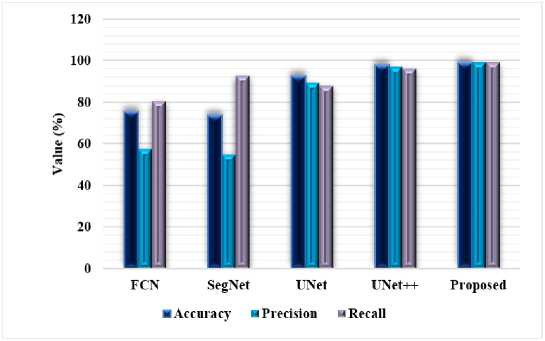
Fig.7. Comparison based on accuracy, precision and recall measures using CT lung dataset
Proposed FTra-UNet model shows significant gains in segmenting the lung CT scans, as shown in Table 4 and Figure 8, especially regarding sensitivity and specificity measures. Sensitivity is generally referred to as recall, which means the efficiency of the model in true positive identifications from actual positive classes, hence a model is capable of segmenting the lung tissue from the CT images with more accuracy. A high Specificity score means the FTra-UNet model provides a small number of false positives; hence, minimal misclassification of non-lung regions as lung tissue. These metrics put together provide full insight into the performance of the model: high Sensitivity makes sure the major features of lungs are captured while high Specificity ensures that the model avoids incorrect segmentations of nonsignificant lung areas. These metrics are indicative of the superior performance of the FTra-UNet model, with enhanced accuracy and reliability in the segmentation of lung tissue compared to conventional models. For clinical applications, identifying lung structures and abnormalities is crucial; this becomes crucial for diagnosis and treatment planning.
Table 4. Comparative analysis with conventional segmentation models using CT lung dataset based on sensitivity and specificity
|
Measures |
Sensitivity |
Specificity |
|
FCN |
80.29 |
73.13 |
|
SegNet |
92.58 |
65.09 |
|
UNet |
87.56 |
94.93 |
|
UNet++ |
95.85 |
98.58 |
|
Proposed |
98.65 |
99 |
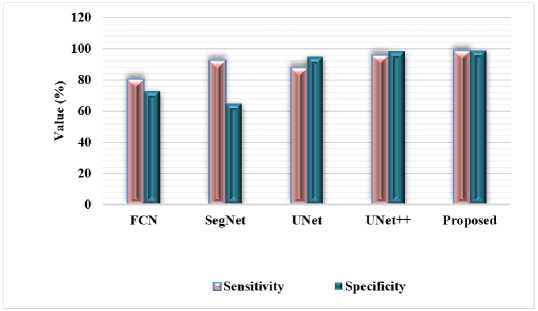
Fig.8. Comparison based on sensitivity and specificity measures using lung CT dataset
In this problem, the unusually high metrics of 99% accuracy and 98.96% Dice coefficient have triggered an increasing concern about overfitting or biased datasets. These metrics indeed sound very good for this model, but such results sometimes hint at a model that is overfitted to the training data, performing terribly on new, unseen data. This can occur when the model is too large given the size of the dataset with which it was working, thus enabling it to memorize specific details rather than learn generalizable patterns. At times, high performance metrics may reflect the problems in the dataset itself, either because it is very small or not representative of real-world variability. Furthermore, focusing on the performance distribution within different subsets of data and biased datasets will help determine whether or not the metrics reported actually represent the performance of a model versus an outcome of overfitting or characteristics specific to a dataset.
The enormous outperformance of the proposed model concerning all metrics used for evaluation portrays the excellence of the proposed model in performing medical image segmentation tasks. This reflects from the extremely high accuracies, Dice coefficients, and other relevant metrics reported. Certain crucial innovations copiously embedded in the model bring such improvements in performance. Basic architectural enhancements provide the proposed model with advanced feature extraction for better segmentation accuracy. For example, the integration of fuzzy logic into transformerbased deep learning methods further enriches the model's ability to deal with complex nonlinear features in medical images, something that may be difficult using conventional techniques. This hybrid approach would help in better representation of intricate structures and pathological regions for more accurate and precise results. It has a number of optimization tricks, including the Slime Sine Hybrid Optimizer, which, in turn, improves convergence rates much better than conventional optimization algorithms and fine-tunes learned weights. It hence leads to more robust, variant segmentation performances. The proposed model uses its effective uncertainty estimation and optimized parameter setup for minimized errors while improving precision in segmentation. Comprehensive and diversified medical data would be provided covering but not limited to BRATS on brain tumors, CT Lung on lung nodules, dermatology images about skin lesions. That itself proves the strength of the model in versatility and generalizability. This model achieves high metrics over a large range of datasets and hence can be regarded as generic, while most state-of-the-art methods may prove excellent in given specific contexts or datasets.
Indeed, generalization of a deep learning model to new unseen data is considered vital to the effectiveness of the model's reliability in any clinical setting, which has to have the model perform consistently across diverse patient populations and under varying conditions of imaging. Indeed, there are a few factors that could motivate generalization in the proposed model. This means that the model has been exposed to many studies on several representative training datasets including but not limited to BRATS for brain tumors, CT Lung for lung nodules, dermatology images for skin lesions among others. Such diversity in data may help the model learn to recognize and segment different anatomical and pathological features, hence increasing its generalization capability. Second, the strong structure of the model, incorporating fuzzy logic into transformer-based approaches with improvements given by advanced optimization techniques like Slime Sine Hybrid Optimizer, bolsters its capability in dealing with complex nonlinear relationships of data. In this case, robustness supports generalization, enabling it to perform well under variant conditions. Extensive cross-validation and regularization methods, including the dropout technique, will prevent it from overfitting to the training data only; hence, its generalization capability is supported. However, it could still fail in those instances where new data is radically different from what it had been trained on. There might be variation in performance with changes in protocol, equipment, or patient demographics. Real-world clinical performance should therefore be validated on truly independent datasets. For better adaptation of the model to new types of data or when such evolving standards of medical imaging come into effect, it is better to use some mechanism of continuous learning or retraining of models with updated data from time to time. Although these results seem promising, generalization of this model into new and more diverse clinical scenarios depends on how those presented challenges are addressed by continuous validation and adaptation of the model.
5. Conclusions
This paper proposes a new and original fuzzy integrated optimization approach to medical image segmentation, which is the subject of this paper, is based on deep learning architectures and meta-heuristic optimization. New to the FTra-UNet architectural elaborate construction is the utilization of an ideal standard in the integration of fuzzy logic to create firm foundation for the capturing relational patterns in the medical images. The integration of the proposed subclassifier based on a fuzzy inference system and a hybrid optimization approach enhances the segmentation results’ accuracy, sensitivity, and specificity over various medical applications, including BRATS, CT lung, and dermoscopy images. The idea is therefore innovative since it incorporates the capabilities of fuzzy logic into the identification of uncertainty from the input data, and the utilization of the SSHOp for the tweaking of the weights obtained in the model. This integration not only takes care of the correctness of the segmentation results but also enhances the model’s possibility of translating it from one modality to the other of medical images. Overall, it has been ascertained that the hybrid optimization methodology provides a better solution to the model parameter optimization and thus, offers enhanced speed and accuracy as compared with the general optimization methods. It reveals and discusses the results of experimentation that confirm that the proposed model functions better in comparison to other methods of segmentation. The proposed model, the FTra-UNet, proves to achieve better performance than other models such as UNet, FCN, and SegNet in terms of the defined parameters of performance measurement including Dice coefficient, sensitivity, specificity, and accuracy. Increased segmentation accuracy in real-world problems such as in MRI of the brain, ultrasound, and dermoscopy show the model’s effectiveness to be used in clinical-related applications. These results confirm that the developed fuzzy integrated optimization methodology is suitable to be applied in the segment of medical images as it is highly accurate, efficient, and reliable, which can become the basis for further studies.
References Fuzzy Hybrid Meta-optimized Learning-based Medical Image Segmentation System for Enhanced Diagnosis
- X. Fei, Y. Wang, L. Dai, and M. Sui, "Deep learning-based lung medical image recognition," International Journal of Innovative Research in Computer Science & Technology, vol. 12, pp. 100-105, 2024.
- M. Thillai, J. M. Oldham, A. Ruggiero, F. Kanavati, T. McLellan, G. Saini, et al., "Deep learning-based segmentation of CT scans predicts disease progression and mortality in IPF," American Journal of Respiratory and Critical Care Medicine, 2024.
- J. Zheng, L. Wang, J. Gui, and A. H. Yussuf, "Study on lung CT image segmentation algorithm based on threshold-gradient combination and improved convex hull method," Scientific Reports, vol. 14, p. 17731, 2024.
- H. T. Gayap and M. A. Akhloufi, "Deep machine learning for medical diagnosis, application to lung cancer detection: a review," BioMedInformatics, vol. 4, pp. 236-284, 2024.
- T. Kunkyab, Z. Bahrami, H. Zhang, Z. Liu, and D. Hyde, "A deep learning‐based framework (Co‐ReTr) for auto‐segmentation of non‐small cell‐lung cancer in computed tomography images," Journal of Applied Clinical Medical Physics, vol. 25, p. e14297, 2024.
- E. K. Ruby, G. Amirthayogam, G. Sasi, T. Chitra, A. Choubey, and S. Gopalakrishnan, "Advanced Image Processing Techniques for Automated Detection of Healthy and Infected Leaves in Agricultural Systems," Mesopotamian Journal of Computer Science, vol. 2024, pp. 62-70, 2024.
- K. Dwivedi, M. Sharkey, S. Alabed, C. P. Langlotz, A. J. Swift, and C. Bluethgen, "External validation, radiological evaluation, and development of deep learning automatic lung segmentation in contrast-enhanced chest CT," European Radiology, vol. 34, pp. 2727-2737, 2024.
- P. Deepa, M. Arulselvi, and S. M. Sundaram, "Classification of Lung Cancer in Segmented CT Images Using Pre-Trained Deep Learning Models," International Journal of Electrical and Electronics Research, vol. 12, pp. 154-159, 2024.
- A. S. Moosavi, A. Mahboobi, F. Arabzadeh, N. Ramezani, H. S. Moosavi, and G. Mehrpoor, "Segmentation and classification of lungs CT-scan for detecting COVID-19 abnormalities by deep learning technique: U-Net model," Journal of Family Medicine and Primary Care, vol. 13, pp. 691-698, 2024.
- Y. Sun, J. Guo, Y. Liu, N. Wang, Y. Xu, F. Wu, et al., "METnet: A novel deep learning model predicting MET dysregulation in non-small-cell lung cancer on computed tomography images," Computers in Biology and Medicine, vol. 171, p. 108136, 2024.
- R. Rajkumar, S. Gopalakrishnan, K. Praveena, M. Venkatesan, K. Ramamoorthy, and J. J. Hephzipah, "DARKNET-53 Convolutional Neural Network-Based Image Processing for Breast Cancer Detection," Mesopotamian Journal of Artificial Intelligence in Healthcare, vol. 2024, pp. 59-68, 2024.
- J. Jiang and H. Veeraraghavan, "Self-supervised pretraining in the wild imparts image acquisition robustness to medical image transformers: an application to lung cancer segmentation," in Medical Imaging with Deep Learning, 2024.
- X. Chen, R. P. Mumme, K. L. Corrigan, Y. Mukai-Sasaki, E. Koutroumpakis, N. L. Palaskas, et al., "Deep learning–based automatic segmentation of cardiac substructures for lung cancers," Radiotherapy and Oncology, vol. 191, p. 110061, 2024.
- S. H. Hosseini, R. Monsefi, and S. Shadroo, "Deep learning applications for lung cancer diagnosis: a systematic review," Multimedia Tools and Applications, vol. 83, pp. 14305-14335, 2024.
- M. S. Sheela, G. Amirthayogam, J. J. Hephzipah, S. Gopalakrishnan, and S. R. Chand, "Machine learning based Lung Disease Prediction Using Convolutional Neural Network Algorithm," Mesopotamian Journal of Artificial Intelligence in Healthcare, vol. 2024, pp. 50-58, 2024.
- W. Ding, H. Wang, J. Huang, H. Ju, Y. Geng, C.-T. Lin, et al., "FTransCNN: Fusing Transformer and a CNN based on fuzzy logic for uncertain medical image segmentation," Information Fusion, vol. 99, p. 101880, 2023.
- C. Kaushal, M. K. Islam, S. A. Althubiti, F. Alenezi, and R. F. Mansour, "A framework for interactive medical image segmentation using optimized swarm intelligence with convolutional neural networks," Computational intelligence and neuroscience, vol. 2022, p. 7935346, 2022.
- V. Narayan, M. Faiz, P. K. Mall, and S. Srivastava, "A comprehensive review of various approach for medical image segmentation and disease prediction," Wireless Personal Communications, vol. 132, pp. 1819-1848, 2023.
- C.-L. Chin, J.-C. Lin, C.-Y. Li, T.-Y. Sun, T. Chen, Y.-M. Lai, et al., "A novel fuzzy dbnet for medical image segmentation," Electronics, vol. 12, p. 2658, 2023.
- Q. Shi, S. Yin, K. Wang, L. Teng, and H. Li, "Multichannel convolutional neural network-based fuzzy active contour model for medical image segmentation," Evolving Systems, vol. 13, pp. 535-549, 2022.
- N. Nagaraja Kumar, T. Jayachandra Prasad, and K. S. Prasad, "An intelligent multimodal medical image fusion model based on improved fast discrete curvelet transform and type-2 fuzzy entropy," International Journal of Fuzzy Systems, vol. 25, pp. 96-117, 2023.
- M. Ahammed, M. Al Mamun, and M. S. Uddin, "A machine learning approach for skin disease detection and classification using image segmentation," Healthcare Analytics, vol. 2, p. 100122, 2022.
- A. Talamantes-Roman, G. Ramirez-Alonso, F. Gaxiola, O. Prieto-Ordaz, and D. R. Lopez-Flores, "A TransUNet model with an adaptive fuzzy focal loss for medical image segmentation," Soft Computing, pp. 1-17, 2024.
- H. Hooda and O. P. Verma, "Fuzzy clustering using gravitational search algorithm for brain image segmentation," Multimedia Tools and Applications, vol. 81, pp. 29633-29652, 2022.
- C. Wang, X. Lv, M. Shao, Y. Qian, and Y. Zhang, "A novel fuzzy hierarchical fusion attention convolution neural network for medical image super-resolution reconstruction," Information Sciences, vol. 622, pp. 424-436, 2023.
