Глубокое обучение в задаче прогнозирования финансовых временных рядов

Автор: Зелезецкий Д.В.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Математика
Статья в выпуске: 3 (63) т.16, 2024 года.
Бесплатный доступ
Рассматривается задача прогнозирования временных рядов цен финансовых инструментов, а также обсуждается проблематика подбора функции потерь для прогнозирования данных со спекулятивным интересом. В ходе исследования производится проверка ряда нейросетевых архитектур (LSTM, Transformer, TSMixer), затем наилучшая модель интегрируется в торговый алгоритм, который оптимизируется в дальнейшем по своим гиперпараметрам. На последнем этапе производится тестирование полученного торгового алгоритма.
Финансовые временные ряды, нейросетевое прогнозирование, алгоритмическая торговля, создание торговой стратегии
Короткий адрес: https://sciup.org/142242983
IDR: 142242983 | УДК: 339.163.4
Deep learning in financial time series forecasting
Deep learning based financial time series forecasting is considered during the work. Moreover, the problem of selecting a loss function for predicting data with speculative interest is also discussed. During the research, a number of neural network architectures (LSTM, Transformer, Tsmuxer) are tested, then the best model is integrated into a trading algorithm, which is further optimized according to its hyperparameters. At the last stage, the resulting trading algorithm is tested.
Текст научной статьи Глубокое обучение в задаче прогнозирования финансовых временных рядов
Задача прогнозирования финансовых временных рядов представляет интерес из-за ряда особенностей, которыми обладают финансовые данные, поведение которых сложно описывается классическими эконометрическими моделями, которые неспособны обобщить сложные закономерности временного ряда. Среди широкого перечня особенностей данной задачи остановимся на двух основных:
-
1) Сложность их описания. Финансовые временные ряды, в частности цены акций, сложно описываются с математической точки зрения, так как не имеют постоянного тренда, сезонной и циклической компоненты, а также постоянного среднего и дисперсии. Движение цены хаотично, а следовательно, плохо обобщаемо большинством моделей [1]. Принято считать, что поведение цены акции схоже с поведением мартингала, стохастического процесса, наилучшим прогнозом на следующий временной шаг которого является его текущее значение.
(с) Зелезецкий Д. В., 2024
(с) Федеральное государственное автономное образовательное учреждение высшего образования «Московский физико-технический институт (пациопальпый исследовательский университет)», 2024
2) Отсутствие единых стимулов для всего рынка. Рассматривая поведение ценв! акции с финансовой точки зрения, следует отметить, что игроки отличаются друг от друга своими стимулами к покупке и продаже. Разные группы игроков ориентируются на разные источники данных при принятии решения о совершении транзакции, следовательно, не существует единых подходов к выбору признакового описания временного ряда, которое в полной мере определяло бы его поведение. Среди наиболее популярных подходов можно отметить использование технических индикаторов, анализ новостей и использование фундаментального анализа. Как правило, использование технических индикаторов обусловлено высокой частотой совершения операций, в то время как анализ новостей или отчётностей применяется в среднесрочном и долгосрочном инвестировании.
3) Специфика функции потерь для обучения нейросети. В отличие от других временных рядов, прогнозирование цен акций, как правило, не носит исключительно исследовательский характер, а сопряжено со спекулятивными интересами. Следовательно, как будет показано позднее, классические подходы к выбору функции потерь не выполняют всех требований, накладываемых на них.
2. План эксперимента
Успех нейросетевых архитектур в задачах моделирования последовательностей [2] говорит об их способности обобщать данные и находить в них сложные закономерности. В частности, успехи моделей семейства Transformer в задачах обработки языка [3] вызывают интерес к их адаптации для временных рядов. Опираясь на перечисленные особенности финансовых данных, можно выдвинуть предположение о том, что при успешном подборе модели и признакового описания мы сможем совершать прогнозы с точностью, достаточной для ведения прибыльной торговли, а значит, сможем аппроксимировать некоторую часть игроков рынка, поведение которых мы косвенно предсказываем через прогноз будущей цены.
Целью эксперимента является оценка ряда нейросетевых архитектур [3, 4, 5] на способность генерации качественных прогнозов, а также создание торгового алгоритма, способного работать с этими прогнозами.
Обсуждая основные задачи эксперимента, выделим следующие:
1) выбор признакового описания,
2) разработка функции потерь,
3) поиск оптимальной архитектуры,
4) внедрение архитектуры в торговый алгоритм и его оптимизация,
5) тестирование алгоритма.
3. Разработка функции потерь
В ходе работы используются данные цен закрытия акций, входящих в Индекс Мосбиржи с частотой обновления 1 час. В качестве признакового описания используются 57 технических индикаторов. Данные получены посредством Python библиотеки Algopack, являющейся официальным продуктом Московской Биржи. Использование технических индикаторов обусловлено высокой частотой обновления цен. Метрики фундаментального анализа или анализ новостей сложно интегрируемы с часовыми данными, так как частота обновления этих признаков сильно ниже частоты обновления цен, а значит, на протяжении большого количества временных тактов признаки будут неизменны.
Разработка функции потерь для обучения нейросети является отдельной важной задачей. Как говорилось ранее, стандартные функции (Mean Squared Error, Mean Average Error), зачастую используемые при обучении нейросетей, не отвечают всем накладываемым требованиям, а значит, некорректно обучают модель.
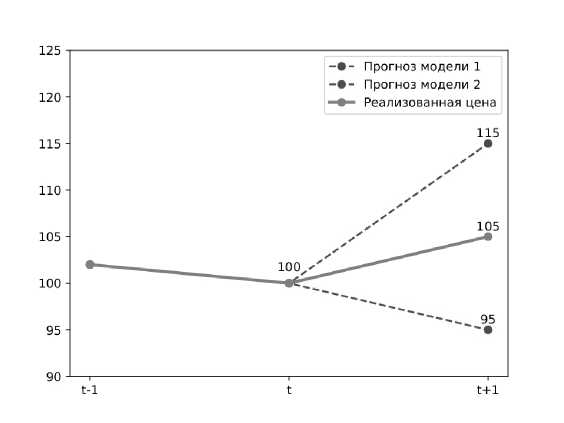
Рис. 1. Иллюстрационный пример для оценки ценности прогнозов
Рассмотрим ситуацию на рис. 1. Предположим, находясь на моменте времени t, мы прогнозируем t + 1 период времени двумя моделями, одна из которых (модель 1) прогнозирует рост цены со 100 до 115, в то время как другая (модель 2) прогнозирует падение со 100 до 95. Оценивая их ошибки через MSE, МАЕ или другие симметричные функции, мы приравниваем их, так как квадрат или модель убивают знак, в результате давая ошибку, равную 100 в случаае MSE и 10 в случае МАЕ. Однако, как только мы начинаем рассматривать их ошибки с позиции спекулятивного интереса, выясняется, что они не равны друг другу. Так, при использовании прогноза модели 2, мы займём короткую позицию, одолжим акцию у брокера, продадим за 100 рублей, однако в t + 1 периоде потеряем деньги, так как будем вынуждены выкупить её за 105 рублей. В свою очередь, используя прогнозы модели 1, мы займём длинную позицию в периоде t и в t +1 периоде заработаем на повышении цены, хотя и не таком сильном, как предсказывалось. Решением данной проблемы является подбор специфической функции потерь, учитывающей спекулятивный интерес [6].
В рамках эксперимента была разработана следующая функция потерь:
CustomLoss(yi+ 1 ,yi+ 1 ) =
yi +1 - yi +1 yi +1
- ^(yi+1 - yi)(yi +1 - yi).
Как можно видеть из формулы, часть I У г+1 .^+1
полностью соответствует функции
МАРЕ, однако далее идёт добавленный штраф с коэффициентом чувствительности А. Если знаки (yi+1 — yi) и (yi+1 — yi) совпадают, то знак этого произведения всегда будет положительный, а значит, коэффициент А должен идти со знаком минус. И наоборот, если члены произведения отличаются знаками, то предсказанное направление движения актива отличается от его истинного движения, а следовательно, это должно увеличивать функцию потерь. Коэффициент А, в свою очередь, отвечает за величину штрафа и является гиперпараметром. При слишком большом А модель будет стараться угадывать направление в ущерб точности самого прогноза, и наоборот, при слишком маленьком А модель не будет бояться ошибаться в направлениях. Следовательно, этот коэффициент должен быть таким, чтобы модель при обучении сошлась к весам, с которыми могла бы угадывать направление, однако делала это с приемлемой точностью.
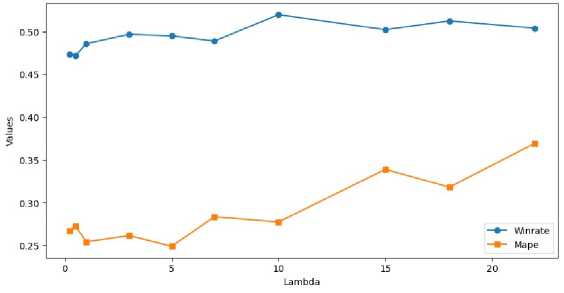
Рис. 2. Зависимость Winrate и МАРЕ от гиперпараметра А
1 N
Winrate(y,y) = — ^[sign^yi - у—) = sign(yi - yi-i)]. V i=2
Эмпирические исследования подтверждают теоретическое представление о работе штрафной компоненты функции. Как видно на рис. 2, метрика Winrate (доля правильно угаданных направлений) имеет тенденцию расти при росте гиперпараметра А, и, как следствие, это влечёт за собой динамику метрики МАРЕ, которая также растёт. Очевидно, не существует единственно правильного ответа на вопрос о том, какое значение параметра выбрать для максимизации качества прогнозов. С одной стороны, мы хотим получать достоверные прогнозы с точки зрения их точности, так как если бы мы старались максимизировать Winrate путём сильного увеличения А, то модель хоть и начинала бы чаще угадывать направление, однако из-за низкой точности цена ошибки была бы высока. И наоборот, стараясь минимизировать МАРЕ путём понижения А, мы рискуем получать низкую частоту угадываний направления и, как следствие, недостаточный Winrate для ведения прибыльной торговли.
4. Поиск оптимальной архитектуры
На первом этапе необходимо найти оптимальную архитектуру, которая наиболее точно обобщает данные.
|
И.1 |
И. 2 |
И.З |
|
|
LSTM |
• |
• |
• |
|
Transformer(encoder часть) |
• |
• |
• |
|
Transformer(encoder + decoder) |
• |
• |
• |
|
TSMixer |
• |
• |
• |
Рис. 3. Испытания моделей
На рисунке 3:
И.1 - Одномерный ряд (без признаков), прогноз на 1 час вперёд.
И.2 - Многомерный ряд (признаки - технические индикаторы), прогноз на 1 час вперёд.
И.З - Многомерный ряд (признаки - другие активы на рынке), прогноз на 1 час вперёд.
Как видно из рис. 3, исследуются 4 модели, две из которых являются представителями семейства Transformer, отличающимися лишь наличием декодера в своём составе.
В рамках испытания мы проверяем 4 модели на трёх видах данных: одномерном ряду без признаков, с использованием технических индикаторов и с использованием других активов в качестве признаков для прогноза целевого. Посколькуго А является гиперпараметром, то каждая из моделей будет обучаться на каждом из испытаний для всех А G [0,1, 5,10,12, 25, 35,45, 50], с последующим усреднением.
4.1. Итерация 1
В рамках первой итерации мы работаем на данных 2020 и 2021 годов. Набор данных имеет размер 172.129 строк и (1/58/42) столбцов, где 1 столбец - это цена закрытия (целевая переменная), а остальные - признаковое описание.
|
И.1 |
И. 2 |
И.З |
|
|
LSTM |
24.55 |
19.47 |
21.7 |
|
Transformer (encoder часть) |
20.11 |
12.19 |
16.33 |
|
Transformer(encoder + decoder) |
20.00 |
13.17 |
16.4 |
|
TSMixer |
21.00 |
15.71 |
16.52 |
Рис. 4. Результаты испытаний для итерации 1
Как можно заметить из рис. 4, наилучшего результата смогла достигнуть Transformer (Encoder) архитектура в испытании 2, где в качестве признаков выступают технические индикаторы. Это значит, что следующий этап (оптимизация гиперпараметров стратегии) будет проходить на её основе и с применением данного признакового пространства. Наглядно видно, как модели начинают ухудшать свой результат при отсутствии признаков. Это наблюдение подтверждает гипотезу о том, что признаки несут в себе информационную пользу для модели и помогают прогнозировать будущие цены точнее.
4.2. Итерация 2
В рамках второй итерации мы работаем на данных 2020, 2021 и 2022 годов. Набор данных имеет размер 241.978 строк и (1/58/42) столбцов, где 1 столбец - это цена закрытия (целевая переменная), а остальные - признаковое описание.
|
И.1 |
И.2 |
И.З |
|
|
LSTM |
28.67 |
22.46 |
24.85 |
|
Transformer (encoder часть) |
24.54 |
17.2 |
18.26 |
|
Transformer(encoder + decoder) |
24.4 |
18.55 |
19.00 |
|
TSMixer |
25.64 |
18.9 |
20.09 |
Рис. 5. Результаты испытаний для итерации 2
Усреднённые по всем А 6 {0,1, 5,10,12, 25, 35, 45, 50} значения функции потерь для каждой модели и каждого испытания изображены на рис. 5. Как можно заметить, снова наилучшего результата смогла добиться Transformer(Encoder) архитектура в испытании 2, где в качестве признаков выступают технические индикаторы. Это значит, что следующий этап (оптимизация гиперпараметров стратегии) также будет проходить на её основе и с применением данного признакового пространства. Результаты 1 этапа данной итерации подтверждают результаты этого же этапа предыдущей итерации, где модели продемонстрировали схожее поведение. Во время второй итерации видно, что каждая из моделей ухудшила свой средний loss на каждом из испытаний. Причиной этому может служить появление данных 2022 года. Данные 2022 года были обрезаны по 1 марта и причиной данного решения является тот факт, что рынок того времени не отражал типичное поведение игроков. На тот момент на рынке преобладал несистематический риск, а следовательно, данные того периода не содержат в себе полезной информации для модели. Однако стоит заметить, что, несмотря на обрезанные по начало апреля данные, фондовый рынок имел высокую волатильность и дальше. Это могло послужить причиной повышенного значения усреднённой функции потерь.
5. Оптимизация портфеля
В рамках данного эксперимента наши модели прогнозируют будущую цену актива, а значит, из ожидаемой цены возможно получить ожидаемую доходность путём следующей элементарной операции:
^+1 =
№+1 - yi
Vi
где yi известна, a yi +i - это ожидаемая цена.
Из этого следует, что в каждый момент времени, при условии прогнозирования N активов на рынке, мы можем получить вектор размерности N, каждой координатой которого будет являться прогнозируемая доходность определённого актива на следующий момент времени. Данный вектор позволяет нам переходить к задаче оптимизации портфеля, где целевой переменной может выступать вектор весов портфеля, вектор вложений портфеля, вектор торговых операций и так далее.
Используемая в ходе эксперимента задача оптимизации является адаптацией задачи, предложенной Стивеном Бойдом в работе [7], и представляет собой однопериодную оптимизацию портфеля. Однопериодная задача оптимизации инвестиционного портфеля заключается в правильном выборе распределения средств, которые направляются на покупку и продажу активов. Данная задача решается путём оптимизации выпуклой или вогнутой функции.
Частная постановка задачи:
Max г?ht + г?ut - стut - 7t • ((ht + ut)X(ht + ut)),
Ut subject to ut G Rn+1, ht + ut >= 0, (4)
1? ut + ст ut = 0, где с - вектор комиссий брокеру и бирже, ht - портфель до торговых операций, ut - вектор торговых операций, rt - ожидаемые доходности всех торгуемых активов,
7t - коэффициент принятия риска(гиперпараметр),
X - ковариационная матрица доходностей.
По завершению первого этапа в обеих итерациях, мы смогли определить наиболее качественную модель с точки зрения усреднённой функции потерь, а также подобрать то признаковое описание, которое позволяет нам добиться наименьшего значения функции потерь для данной модели. В ходе проведения испытаний мы выяснили, что в обеих итерациях модель Transformer (Encoder) показала наилучший результат на испытании 2, где признаками выступают 57 технических индикаторов. Следовательно, следующей задачей будет являться интеграция модели в торговый алгоритм и оптимизация последнего по гиперпараметрам A, risk aversion (далее RA).
Имея 9 весов Трансформера, обученного на A G {0,1, 5,10,12, 25, 35,45, 50}, мы переходим к проведению бектеста и поиску оптимальных параметров на обрезанных по март данных 2022 года для первой итерации и данных 2023 года для второй итерации. Также стоит напомнить, что параметр RA определяется как 7 в теле целевой функции, при решении задачи оптимизации и отвечает за чувствительность к риску при поиске оптимальных торговых операций.
Require:
Л= {0,1,5,10,12,25,35,45,50}, Г = {0.5,1, 2,3,4, 5, 8};
Ensure:
Sharpe Ratio - значение коэффициента Шарпа для получившегося портфеля
1: for A G Л,у G Г do
2: Проводим почасовое прогнозирование всего года трансформером, обученным на Л.
3: На полученных данных проводим бектест с RA = у
4: Фиксируем полученный Sharpe Ratio
5: end for=0
5.1. Итерация 1
Рис. 6. Обобщённая схема проведения бектестов для всех А, у
Схема алгоритма на рис. 6 показывает общий вид проведения бектеста с фиксирован ными параметрами.
В рамках первой итерации сбор результатов бектеста и поиск оптимальных параметров А, у производится на данных 2022 года, обрезанных по 1 марта. Общий размер данных составляет 69 849 строк. Транзакционные издержки равны 0, 02%, что является наиболее выгодным предложением для частного трейдера на момент проведения исследования.
Lambda=0,RA=0.5,Sha rpe=- 2.205 Lambda=0,RA=1,Sha rpe=-2.217 Lambda=0,RA=2,Sha rpe=-2.207 Lambda=0,RA=3,Sha rpe=-2.218 Lambda=0,RA=4,Sha rpe=-2.276 Lambda=0,RAM,Sha rpe=-2.326 Lambda=0,RA=8,Sha rpe=- 2.408 Lambda=l,RA=0.5,Sha rpe=- 2.484 Lambda=l,RA=1,Sha rpe=-2.443 Lambda=l,RA=2,Sha rpe=-2.432 Lambda=l,RA=3,Sha rpe=-2.336 Lambda=l,RA=4,Sha rpe=-2.26 Lambda=l,RA=5,Sha rpe=-2.201 Lambda=l,RA=8,Sharpe=-2.104 Lambda=5,RA=0.5,Sha rpe=-2.647 Lambda=5,RA=1,Sha rpe=- 2.585 Lambda=5,RA=2,Sha rpe=-2.529 Lambda=5,RA=3,Sha rpe=-2.491 Lambda=5,RA=4,Sha rpe=-2.472 Lambda=5,RA=5.Sha rpe=-2.496 Lambda=5,RA=8,Sha rpe=-2.427 Lambda=10,RA=0.5,Sha rpe=-1.128 Lambda=10,RA=1,Sha rpe=-1.098 Lambda=10,RA=2,Sha rpe=-1.054 Lambda=10,RA=3,Sha rpe=-1.042 Lambda=10,RA=4,Sha rpe=-1.098 Lambda=10,RA=5,Sha rpe=-1.212 Lambda=10,RA=8,Sha rpe=-1.478 Lambda=12,RA=0.5,Sharpe=-1.614 Lambda=12,RAM,Sha rpe=-1.621 Lambda=12,RA=2,Sha rpe=-1.62 Lambda=12,RA=3,Sha rpe=-1.674
Lambda=12,RA=3,Sha rpe=-1.674 Lambda=12,RA=4,Sharpe=-1.713 Lambda=12,RA=5,Sharpe=-1.731 Lambda=12,RA=8,Sha rpe=-1.773 Lambda=25,RA=0.5,Sha rpe=-2.575 Lambda=25,RA=1,Sharpe=-2.565 Lambda=25,RA=2,Sha rpe=-2.577 Lambda=25,RA=3,Sha rpe=-2.567 Lambda=25,RA-4,Sha rpe=- 2.565 Lambda=25,RA=5,Sha rpe=-2.553 Lambda=25,RAM,Sha rpe=- 2.538 Lambda=35,RA=0.5,Sharpe=-0.908 Lambda=35,RA=1,Sha rpe=-0.9 Lambda=35,RA=2,Sha rpe=-0.828 Lambda=35,RA=3,Sha rpe=- 0.825 Lambda=35, RAM, Sha rpe=- 0.865 Lambda=35,RA=5,Sharpen - 0.903 Lambda=35,RA=8,Sha rpe=-0.984 Lambda=45,RA=0.5,Sha rpe=-1.901 Lambda=45,RA=1,Sha rpe=-1.893 LambdaM5,RA=2,Sha rpe=-1.878 Lambda=45,RA=3,Sha rpe=-1.878 LambdaM5, RAM, Sha rpe= -1.888 LambdaM5, RA=5, Sha rpe=-1.868 LambdaM5, RA=8, Sha rpe= -1.802 Lambda=50,RA=0.5,Sha rpe=-3.322 Lambda=50,RA=1,Sha rpe=- 3.354 Lambda=50,RA=2,Sha rpe=-3.35 Lambda=50,RA=3,Sha rpe=- 3.347 Lambda=50, RAM, Sha rpe= -3.34 Lambda=50,RA=5,Sharpe=-3.385 Lambda=50,RA=8,Sha rpe=-3.387
Рис. 7. Результаты серии бектестов для первой итерации
Как видно из рис. 7, ни на одной из комбинаций гиперпараметров алгоритм не смог достичь положительной доходности. Как говорилось ранее, в течение всего 2022 года российский фондовый рынок страдал от высокой волатильности вследствие сильного несистематического риска, вызванного санкционным давлением на российскую экономику. Данные факторы могли внести негативный вклад в успех торгового алгоритма, однако нашей задачей по-прежнему является поиск параметров, дающих максимальный коэффициент Шарпа. Как видно на рис. 7, оптимальными параметрами являются А* = 35, RА* = 3, именно на них мы будем тестировать торговую стратегию на следующем шаге.
5.2. Итерация 2
В рамках второй итерации сбор результатов бектеста и поиск оптимальных параметров А, у производится на данных 2023 года. Общий размер данных составляет 77 043 строк. Транзакционные издержки также равны 0, 02%.
Lambd а=0,RA=0.5,Sha гре=-0.736 Lambda=0,RA=1,Sha rpe=-0.786 Lambda=0,RA=2,Sha rpe=-G.798 Lambda=0,RA=3,Sha rpe=-0.784 Lambda=O,RA=4,Sha rpe=- 0.822 LambdaM,RA=5,Sha rpe=-0.873 Lambd a=0,RA=8,Sha rpe=-1.004 Lambda=l,RA=0.5,Sharpe=-l.01 Lambda=l,RA=1,Sha rpe=-0.985 Lambda=l,RA=2,Sha rpe=-0.918 Lambda=l,RA= 3,Sha rpe=-0.885 Lambda=l,RA=4,Sha rpe=-0.9 Lambda=l,RA=5,Sha rpe=-0.894 Lambda=l,RA=8,Sha rpe=-0.869 LambdaM,RA=0.5,Sha rpe=0.215 Lambda=5,RA=1,Sha rpe=O.242 LambdaM,RA=2,Sha rpe=O.271 Lambda=5,RA=3,Sha rpe=O.276 LambdaM, RAM, Sha rpe=O. 275 Lambd a=5,RA=5,Sha rpe=0.345 Lambda=5,RA=8,Sha rpe=0.334 Lambda=10,RA=O.5,Sharpe=-2.291 Lambda=10,RA=1,Sha rpe=-2.285 Lambd a=10,RA=2,Sha rpe=-2.245 Lambd a=10,RA=3,Sha rpe=- 2.209 Lambda=10,RAM,Sha rpe=-2.189 Lambda=10,RAM,Sharpe=-2.16 Lambda=10,RAM,Sha rpe=-2.21 Lambda=12, RAM. 5,Sha rpe=- 2.435 Lambda=12,RA=1,Sha rpe=-2.438 Lambda=12,RA=2,Sha rpe=-2.443 Lambd a=12, RAM, Sha rpe= -2.445
Lambda=12,RAM,Sha rpe=- 2.456 Lambda=12,RA=5,Sha rpe=-2.466 Lambda=12,RAM,Sha rpe=-2.502 Lambda=25,RAM.5,Sha rpe=-1.821 Lambda=25,RA=1,Sha rpe=-1.798 Lambda=25,RA=2,Sha rpe=-1.785 Lambda=25, RAM, Sha rpe=-1.791 Lambda=25,RAM,Sha rpe=-1.814 Lambda=25, RAM, Sha rpe= -1.833 Lambda=25,RAM,Sha rpe=-1.868 Lambda-35, RA=0.5, Sha rpe= -1.819 LambdaM5, RA=1, Sha rpe= -1.827 Lambda=35,RAM,Sha rpe=-1.861 Lambda=35,RA=3,Sha rpe=-1.9 LambdaM5, RAM, Sha rpe= -1.923 Lambda=35,RA=5,Sha rpe=-1.947 Lambda=35, RAM, Sha rpe= -1.894 Lambda=45, RAM. 5, Sha rpe= -1.221 Lambda=45,RA=1,Sha rpe=-1.224 LambdaM5, RAM, Sha rpe=-1.254 LambdaM5, RA=3, Sha rpe=-1.279 LambdaM5, RAM, Sha r pe= -1.283 Lambda=45, RA=5, Sha rpe=-1.279 LambdaM5, RAM, Sha rpe=-1.265 Lambda=50, RAM. 5, Sha rpe= -1.067 LambdaMO, RA=1, Sha rpe=-1.063 LambdaMO, RA=2, Sha rpe=-1.081 LambdaMO, RA=3, Sha rpe= -1.1 Lambda=50, RAM, Sha rpe= -1.144 LambdaMO, RAM, Sha rpe=-1.168 LambdaMO, RAM, Sha rpe= -1.246
Рис. 8. Результаты серии бектестов для второй итерации
На рисунке 8 можно наблюдать, что наибольший коэффициент Шарпа достигается при А* = 5,RА* = 5. Именно на них будет проводиться тестирование торговой стратегии. Следует заметить, что, по сравнению с первой итерацией, оптимальные А и RA поменялись, а значит, мы можем констатировать факт того, что стратегия адаптируется в зависимости от рынка, на котором происходит торговля. Нестабильный рынок 2022 года требовал увеличивать параметр А из-за высокой нестабильности и непредсказуемости рынка, в то время как растущий рынок 2023 года позволил снизить А, больше концентрируясь на точность прогноза, а не доле правильно угаданных направлений.
6. Тестирование алгоритма
Наконец, последним этапом проверки торговой стратегии является её тестирование на тестовых данных, которых она не видела прежде. Дойдя до этого этапа, мы уже выбрали оптимальную нейросетевую архитектуру, а также оптимальные гиперпарамерты торговой стратегии А* и RA*. Зафиксировав архитектуру и гиперпарамерты, мы проводим бектест на тестовых данных, в ходе которого собираем результаты торговли.
Ключевой метрикой оценки качества стратегии является Return - доходноств стратегии за тестируемый период. Кроме того, результат стратегии сравнивается с результатом доходности бенчмарка (Индекс Мосбиржи) для ответа на вопрос о том, может ли она перегнать бенчмарк в виде индекса, торгуя лишь активами из него самого.
6.1. Итерация 1
Тестирование стратегии с параметрами А* = 35, RА* = 3 в рамках первой итерации производится на данных 2023 года, имеющих 77 043 наблюдения. Транзакционные издержки по-прежнему равны 0, 02%.
Таблица!
Результаты тестирования для А = 35, RА = 3 (с = 0.0002)
|
Metric |
Value |
|
Initial value (cash) |
1.000e+06 |
|
Final value (cash) |
9.585e+05 |
|
Profit (cash) |
4.151e+04 |
|
Avg. return (annualized) |
-0.1% |
|
Volatility (annualized) |
32.1%, |
|
Avg. excess return (annualized) |
-0.1% |
|
Avg. active return (annualized) |
-0.1%, |
|
Excess volatility (annualized) |
32.1%, |
|
Active volatility (annualized) |
32.1%, |
|
Avg. growth rate (annualized) |
-5.2% |
|
Avg. excess growth rate (annualized) |
-5.2% |
|
Avg. active growth rate (annualized) |
-5.2% |
|
Sharpe ratio |
-0.00 |
|
Information ratio |
-0.00 |
|
Avg. drawdown |
-9.2% |
|
Min. drawdown |
24.9%, |
|
Avg.leverage |
101.4%, |
|
Max. leverage |
106.8%, |
|
Avg. turnover |
95.9%, |
|
Max. turnover |
104.1%, |
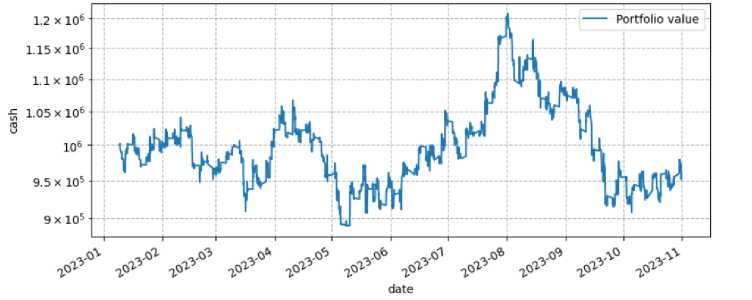
Рис. 9. График стоимости портфеля А = 35, RА = 3 (с = 0.0002)
Как таблица 1, так и рисунок 9 содержат результаты тестирования стратегии. Мы можем наблюдать, что алгоритм не смог реализовать положительную доходность, хотя период с 2023-06 по 2023-08 можно охарактеризовать периодом уверенного рост цены портфеля.
Разбираясь в причинах такого неудовлетворительного результата, следует обратить внимание на общую стоимость транзакционных издержек, которые мы заплатили в ходе торговли: 712 796 рублей. Как можно увидеть, на комиссию брокеру уходит достаточно большая доля, а значит, что алгоритм, чрезмерно часто перебалансируя портфель, теряет на этом большие суммы.
6.2. Итерация 2
Тестирование стратегии с параметрами А* = 5,RА* = 5 в рамках второй итерации производится на данных 2024 года (01.01.2024 - 01.04.2024), имеющих 20 803 наблюдения. Транзакционные издержки по-прежнему равны 0, 02%.
Т а б л и ц а 2
Результаты тестирования для А = 5,RА = 5 (с = 0.0002)
|
Metric |
Value |
|
Initial value (cash) |
1.000e+06 |
|
Final value (cash) |
1.081e+06 |
|
Profit (cash) |
8.062e+04 |
|
Avg. return (annualized) |
39.5% |
|
Volatility (annualized) |
28.7% |
|
Avg. excess return (annualized) |
39.5(% |
|
Avg. active return (annualized) |
39.5(% |
|
Excess volatility (annualized) |
28.7% |
|
Active volatility (annualized) |
28.7% |
|
Avg. growth rate (annualized) |
35.4%, |
|
Avg. excess growth rate (annualized) |
35.4%, |
|
Avg. active growth rate (annualized) |
35.4%, |
|
Sharpe ratio |
1.37 |
|
Information ratio |
1.37 |
|
Avg. drawdown |
-4.1% |
|
Min. drawdown |
-12.3% |
|
Avg. leverage |
100.5%, |
|
Max. leverage |
108.5%, |
|
Avg. turnover |
87.2% |
|
Max. turnover |
104.2%, |
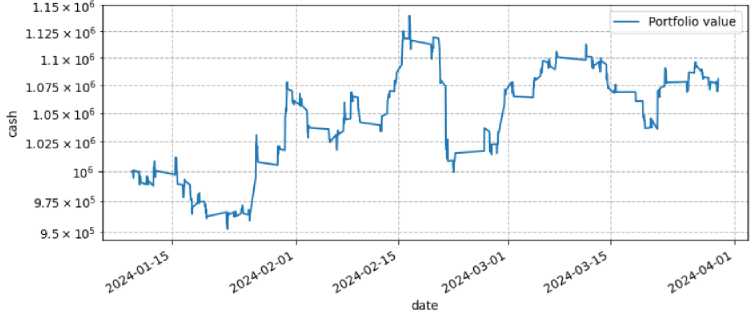
Рис. 10. График стоимости портфеля А = 5, RА = 5 (с = 0.0002)
Результаты таблицы 2 и рисунка 10 говорят об эффективности торгового алгоритма при транзакционных издержках в 0, 02%. Начиная с января 2024 и по начало апреля этого же года, стоимость портфеля выросла на 8.1%. За аналогичный период времени бенчмарк (Индекс Мосбиржи) вырос на 5,6%, что свидетельствует об эффективности алгоритма. Общие издержки на комиссию составили 88 629 рублей.
7. Обсуждение результатов
После проведения эксперимента и фиксации полученных результатов, мы можем переходить к их интерпретации и обсуждению.
7.1. Обсуждение результатов поиска оптимальной архитектуры
Приведём основные выводы данного этапа:
1) Оценивая исследуемые архитектуры по результатам первой и второй итерации, мы можем заметить, что наихудшую производительность показывает архитектура LSTM, дающая наивысший средний Loss среди всех испытуемых моделей. Причиной такого результата может служить ограничение модели на объём удерживаемой памяти внутри себя, что является известной проблемой всех рекуррентных нейросетевых архитектур [8].
2) Говоря об TSMixer архитектуре, следует отметить её высокую скорость обучения по причине того, что она состоит из полносвязных слоёв, однако данный факт сыграл негативную роль в результатах модели, из-за чего её точность не смогла сравняться с точностью трансформеров, хотя и обогнала LSTM.
3) Трансформеры (оба варианта) смогли показать наилучший результат среди всех исследуемых моделей, благодаря блокам памяти (Attention Layer) и позиционному кодированию (Positional Encoding). Данные нововведения позволяют захватывать более сложные взаимосвязи во входящих последовательностях, а значит, совершать более качественные прогнозы.
4) Говоря о признаковом описании ряда, мы можем наблюдать наихудший результат у всех четырёх моделей, работающих с одномерным рядом (ряд цен без дополнительных признаков). Полученные результаты вполне очевидны, так как, используя данные одних лишь цен, трудно обнаружить сложную структуру во входящей последовательности. На втором месте по результативности идёт постановка, в которой признаками являются цены закрытий других активов. Данное описание целевой переменной позволило понизить средний Loss у всех моделей. Исходя из этого, можно выдвинуть гипотезу о том, что модель использовала значения цен сильно коррелированных активов для предсказания поведения цен. Сама по себе корреляция активов не является гипотезой и давно исследуется научным сообществом [9]. Наконец, наилучший результат с точки зрения точности на обеих итерациях дали 57 технических индикаторов, которые были получены вместе с ценой через API Мосбиржи. Данные индикаторы позволили всем моделям добиться оптимальных результатов в прогнозировании, а значит, предоставили скрытую в них информацию о поведении цены.
7.2. Обсуждение результатов поиска оптимальных гиперпараметров торговой стратегии
Обсуждая результаты поиска оптимальных гиперпараметров, следует обратить внимание на то, что они отличаются от итерации к итерации, а значит, адаптируются под конъюнктуру рынка и данных, на которых обучается модель. Попробуем проинтерпретировать полученные результаты.
1) Первая итерация показала, что оптимальными параметрами торговли на рынке 2022 года оказались А* = 35, RА* = 3. Напоминаем, что в рамках эксперимента A G {0,1, 5,10,12, 25, 35,45, 50}, RA G {0.5,1, 2, 3,4, 5, 8}, а значит, пслученная А* имеет достаточно высокое значение, a RA* имеет среднее значение. Можно предположить, что данная необходимость обоснована высокой волатильностью и непредсказуемостью рынка 2022 года, когда санкционное давление на экономику России вызвало высокий несистематический риск на всех её рынках. Этот факт заставляет нашу модель обращать особое внимание на направление движения предсказанного актива (большой А*), так как цены ведут себя нехарактерным для спокойного времени образом. В свою очередь, средний RA* сигнализирует нам о необходиомости учёта рисков со средней силой. Иными словами, алгоритм должен вести торговлю с умеренной агрессией, хотя и не совсем консервативно.
2) Вторая итерация показала, что оптимальными параметрами торговли на рынке 2023 года оказались А* = 5,RА* = 5. Можно сказать, что в условиях растущего рынка с положительной динамикой модель начинает меньше опасаться непредсказуемого поведения цен, проявляя это в снижении параметра А*. Однако параметр RA* возрос по сравнению с первой итерацией, что означает, что теперь требуется вести более-менее рискованную торговлю.
7.3. Обсуждение результатов тестирования стратегии
Можно заключить, что оптимальные параметры в большинстве своём неплохо соотносятся с реальностью.
Результаты тестирования стратегий сообщают об одной основной уязвимости нашего алгоритма, которая в некоторых случаях мешает ему вести прибыльную торговлю - высокие издержки на комиссию брокеру. Обсудим это подробнее.
-
1) Согласно наблюдаемым результатам, алгоритм первой итерации торгует либо в минус, либо не догоняет бенчмарк, по причине высоких издержек на комиссию и лишь с комиссии, равной 0.009%, наш алгоритм начинает обгонять бенчмарк на тестовых данных. Данные издержки происходят из-за частых перебалансировок портфеля, которые приводят к большому количеству сделок на рынке, не все из которых могут покрыть комиссию. Решением данной проблемы может служить переход на данные большей фракции, например на двухчасовые или дневные диапазоны.
-
2) Более того, гипотетической причиной неудачи на первой итерации может служить то, что оптимальный параметр Loss функции, а также коэффициент RA подбирались на рынке 2022 года, который кардинально отличался от рынка 2023 года, на котором эти параметры тестировались. Данное различие двух рынков предположительно могло спровоцировать негативный результат при тестировании. Частично эта гипотеза подтверждается результатами второй итерации, в которой наша стратегия, оптимизировавшись на растущем рынке 2023 года, смогла продемонстрировать положительный результат на части 2024 года, обогнав бенчмарк примерно в два раза (индекс +5.6%, стратегия +8.1%).
Исходя из проделанной работы можно заключить, что архитектуры типа Transformer, обученные на разработанной функции потерь, способны производить прогнозы, достаточные для ведения прибыльной торговли. В свою очередь, разработанный торговый алгоритм позволяет обрабатывать прогнозы и производить перебалансировку портфеля с достаточной скоростью и точностью.
Однако, как было сказано ранее, существенным недостатком данного подходя являются большие расходы на комиссии брокеру, которые мешают ведению прибыльной торговли в некоторых случаях. Причиной таких расходов является частая перебалансировка портфеля (раз в час). Одним из возможных способов устранения данных недостатков является переход на данные с более низкой частотой обновления.
Список литературы Глубокое обучение в задаче прогнозирования финансовых временных рядов
- Zinenko A. Forecasting financial time series using singular spectrum analysis // Business Informatics. 2023. V. 17, N 3. P. 87 100.
- Junyoung C., Caglar G., KyungHyun C., Yoshua B. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling // Deep Learning and Representation Learning Workshop. 2014.
- Vaswani A., Shazeer N., Parmar N., Vszkoreit J., Jones L., Gomez A.N., Kaiser L., Polosukhin I. Attention is all you need // Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS'17, Red Hook, NY, USA. Curran Associates Inc. 2017. P. 6000 6010.
- Hochreiter S., Schmidhuber J. Long short-term memory // Neural Computation. 1997. V. 9, N 8. P. 1735-1780.
- Zeng A., Liu X., Lin Z. Xu J., Tao D. TSMixer: An All-MLP Architecture for Time Series Forecasting // arXiv preprint arXiv:2303.06053. 2023.
- Lee T. Loss Functions in Time series forecasting // University of California, Riverside. 2007.
- Boyd S., Busseti E., Diamond S., Kahn R.N., Koh K, Nystrup P., Speth J. Multi-Period Trading via Convex Optimization // Foundations and Trends in Optimization. 2017. V. 20, N 20. P. 1-74.
- Landi F., Baraldi L., Cornia M., Cucchiara R. Working Memory Connections for LSTM // Neural Networks. 2021. P. 334-341. EDN: XQQDVD
- Song D.-M., Tumminello M., Zhou W.-X., Mantegna R.N. Evolution of worldwide stock markets, correlation structure, and correlation-based graphs // Physical Review E. 2011. V. 84, N 2.
