Гомоморфизм эквивалентных преобразований грамматик, применяемый при генерации анализаторов языка

Автор: Федорченко Людмила Николаевна
Журнал: Вестник Бурятского государственного университета. Математика, информатика @vestnik-bsu-maths
Рубрика: Информационные системы и технологии
Статья в выпуске: 2, 2019 года.
Бесплатный доступ
При построении транслятора, как правило, необходимо проводить эквивалентные преобразования грамматики реализуемого языка, преобразующие синтаксическую спецификацию языка в тот вид, который допускает автоматическую или ручную реализацию исходного языка, и решающие проблемы учёта ограничений выбранного метода синтаксического анализа. Эти проблемы возникают как из-за разнообразия способов определения реализуемых языков, так и из-за языковой неоднозначности или недетерминированности распознающего автомата. Каждое преобразование, выполняемое на трансляционных КС-грамматиках, может задаваться как отношение подобия (гоморфизма), определяемое на классах грамматик. Такие отношения имеют непосредственную связь с сохранением семантического значения грамматических конструкций при эквивалентных преобразованиях синтаксиса, так как конечной целью трансляции является получение последовательности действий, предписываемых вычислительной среде. В статье представлен краткий обзор различных типов отношений подобия на грамматиках, применяемых при построении трансляторов c 1970-х гг. Представлена схема построения анализаторов LL-языков с использованием синтаксических граф-схем (СГС). Даны формальное понятие маршрута (пути) в СГС и пример автоматического преобразования КСР-грамматики формального языка CIAO, выполненный в системе эквивалентных преобразований SynGT (Syntax Graph Transformations).
Эквивалентные преобразования грамматик, отношение подобия, гомоморфизм покрытия, кср-грамматики, синтаксическая граф-схема, регуляризация грамматик
Короткий адрес: https://sciup.org/148308937
IDR: 148308937 | УДК: 681.51 | DOI: 10.18101/2304-5728-2019-2-44-60
Homomorphism of equivalent transformations of grammars in parser generation
When constructing a translator, as a rule, it is necessary to apply the equivalent transformations of grammar of the implemented language, which convert the syntactic specification of the language into a form that allows for automatic or manual implementation of the source language, and solves the problem of constraint satisfaction of the chosen parsing technique. These problems arise both because of the variety of ways of defining the implemented languages, and because of the language ambiguity or nondeterminism of the recognizing automaton. Each transformation performed on translational CF-grammars can be defined as a likelihood ratio (homomorphism), determined on classes of grammars. Such relations preserve the semantic meaning of grammatical structures in equivalent syntax transformations, since the ultimate purpose of translation is to obtain a sequence of actions prescribed by the computing environment. The article presents a brief overview of various types of likelihood ratio over grammars used in constructing translators since the 1970s. A flow chart for LL parsing with use of syntactic graph scheme (SGS) is presented. We have given a formal notion of a route (path) in the SGS and an example of the automatic CFR-grammar transformation of CIAO formal language in SynGT (Syntax Graph Transformations) system of equivalent transformations.
Текст научной статьи Гомоморфизм эквивалентных преобразований грамматик, применяемый при генерации анализаторов языка
При построении компилятора (или любого транслятора) разработчики реализуемого языка проводят эквивалентные преобразования грамматики исходного языка, необходимые, чтобы получить ту форму синтаксического определения языка, которая допускает автоматическую или ручную реализацию языка, а также учесть ограничения, диктуемые методом синтаксического анализа. Первая проблема возникает из-за разнообразия вида определений реализуемых языков, вторая — из-за языковой неоднозначности или недетерминированности распознающего автомата. Для этого следует так использовать информацию о языке, определяя его синтаксис и статическую семантику в виде специальной КС-грамматики (трансляционной) [1], чтобы помимо основной своей функции порождения цепочек языка грамматика позволяла задавать трансляции, необходимые разработчикам [1-3].
-
1 Эквивалентность КС-грамматик и гомоморфизмы
Под трансляцией из языка L i с X в язык L 2 с А называется отношение тс L 1 х L 2 . Здесь X — входной алфавит , L 1 — входной язык , А — выходной алфавит , L 2 — выходной язык. Другими словами, трансляция есть некоторое множество пар предложений ( x , у ), где x е L 1 — входное , а у е L 2 — выходное предложение .
Каждое преобразование, выполняемое на трансляционных КС-грамматиках [1-4] может задаваться как отношение подобия (гоморфиз-ма) [6], определяемое на классах грамматик. Такие отношения имеют непосредственную связь с сохранением семантического значения грамматических конструкций при эквивалентных преобразованиях синтаксиса (теорема Флойда), так как конечной целью трансляции является получение последовательности действий, предписываемых вычислительной среде (Environment), как одного из разделов спецификации трансляционной грамматики.
Из грамматик наиболее простыми для разработки являются регулярные грамматики типа 3 (по иерархии Хомского) [3], которые порождают регулярные языки, обрабатываемые конечными автоматами. На практике широко применяется грамматики типа 2- контекстно-свободные грамматики (КСГ), относительная простота которых позволяет применять для анализа КС-языков эффективные полиномиальные алгоритмы. Например, алгоритм Эрли (Early) [5] для КСГ имеет вычислительную сложность O ( n ), где n — длина входной цепочки. Более сильные ограничения на КС-языки классов LL , LR, LALR дают возможность синтезировать анализаторы, имеющие линейную сложность разбора.
Перевод грамматик из одного класса в другой — это задача эквивалентных преобразований синтаксического описания языка.
Грамматика Эквивалентное Грамматика Анализатор для
типа X
преобразование
типа Y
грамматики типа Y
Разбор для грамматики
типа X
Рис. 1. Схема применения эквивалентного преобразования при разборе
Таким образом, разработчики трансляторов и инструментальных систем, автоматизирующих процесс разработки, при настройке синтаксиса всегда стремятся преобразовать его таким образом, чтобы получить грамматику, принадлежащую к наиболее простому классу иерархии Хомского или к тому подклассу КСГ, для которого есть используемый в системе автоматического построения трансляторов метод синтеза анализатора языка.
При автоматизированном построении транслятора дополнительно к задаче приведения грамматики к необходимому способу спецификации приходится решать задачу разрешения конфликтов, связанных с языковой неоднозначностью или недетерминированностью распознающего устройства. Снять эти проблемы можно только с помощью эквивалентного преобразования грамматики или такого преобразования , которое восстановит первоначальную семантику с помощью гомоморфизмов (отношений на грамматиках).
В работах [7], [8], [9], [10], [11], [12], [13] подробно рассмотрены различные типы эквивалентных отношений — слабая и структурная эквивалентность, сильная структурная эквивалентность. Показано, что проблема сильной структурной эквивалентности алгоритмически разрешима, так как существует только конечное число нумераций, а для всякой такой нумерации скобочная версия G [ ] определяет простой детерминированный язык ( S -язык). Преобразование G [ ] в S -грамматику прямое. Кореньяк, Хопкрофт в [14] и Саломаа в [15] доказали, что проблема, порождают ли две S -грамматики один и тот же язык, алгоритмически разрешима. Все эти и другие типы эквивалентных преобразований рассмотривались с точки зрения сложности грамматического разбора. С целью выразить отношение грамматического подобия более точно появилось много новых формальных понятий. В работах [16; 17] даны определения и описаны результаты для грамматических гомоморфизмов , изоморфизмов, слабых покрытий и т. д. В работах [18-21] даны определения и описаны результаты для грамматических гомоморфизмов, изоморфизмов, слабых покрытий и покрытий по Рейнольдсу. В этих определениях сделан акцент на правила грамматик, а не на множества выводов или грамматических разборов. Так, отношение гомоморфной эквивалентности КС-грамматик, являясь более тонким, чем отношение структурной, сильно структурной и частично структурной эквивалентности, может быть определено следую -щим образом:
КС-грамматика G = ( N , T , P , S ) называется гомоморфно эквивалентной грамматике G ' = ( N ', T', P', S '), если существует гомоморфизм
-
V : G ^ G* и L ( G ) = L ( G ‘ ). В этом случае гомоморфизм у представляется тройкой отображений у | : G ^ G ‘ , у 2 : T ^ T' , V 3 : P ^ P' и V 1 ( ^ ) = 5 ‘ .
В работе [20] Грей и Харрисон определили понятие грамматического покрытия (разновидность гомоморфизма), которое описывает отношение между множествами деревьев вывода двух КС-грамматик. Интерес авторов к этому понятию был основан исключительно на его применении в области синтаксического анализа языков.
Если ограничиться моделью анализа, в которой каждое предложение исходного языка даётся описанием его деревьев вывода в виде строки правил грамматики (или меток, идентифицирующих эти правила), то соответствие двух КС-грамматик, которое описывается грамматическим покрытием, является отношением между такими описаниями деревьев вывода для данного предложения.
Результат синтаксического анализа можно считать аргументом семантического отображения. В случае когда КС-грамматика G ' покрывает КС-грамматику G , разбор предложения w относительно G ' может быть отображён гомоморфизмом на разбор той же w относительно G . Отсюда следует вывод, что язык L ( G ) можно анализировать относительно преобразованной грамматики G ' , а затем использовать первоначальное семантическое отображение, как на рис. 1.
Неформально говоря, основная идея в том, что та КС-грамматика G , которая «трудна» для анализа или не удовлетворяет определённым огра -ничениям, диктуемым методом синтаксического анализа, преобразуется в КС-грамматику G ' , которую можно анализировать более простым анализатором. Последующий синтаксический анализ проводится относительно преобразованной G ' , а после этого результат анализа (разбора) отображается покрывающим гомоморфизмом на соответствующий разбор относи -тельно G .
Эквивалентное
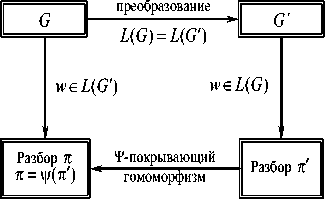
Рис. 2. Схема эквивалентного преобразования с использованием покрытий
Подводя итог вышесказанному, можно сказать, что в том случае, если синтаксические правила, которые подаются на вход инструментальной системе, не специфицируют грамматику, для которой выбранный тип анализатора может быть построен, возникают следующие ситуации:
-
- система диагностирует о своей неспособности построить анализатор и выдает информацию, почему она терпит неудачу; эта информация может быть использована разработчиком языка для того, чтобы изменить (не обязательно эквивалентно преобразовать) эти правила (и связанные с ними семантики) с целью сделать их подходящими для системы;
-
- система может применить эквивалентные преобразования к входной грамматике для того, чтобы сделать её адекватной методу. Но это должно делаться так, чтобы первоначальные семантики сохранялись;
-
- синтаксические правила на входе системы не специфицируют грамматику, которая годится для метода анализа, заложенного в инструментальной системе, но у разработчика есть возможность обеспечить систему дополнительной информацией (например, пополнить новыми правилами), достаточной для построения правильного анализатора.
Если синтаксические правила (с дополнительной информацией) не специфицируют грамматику желаемого типа, то система может принять решение, которое ведёт к успешному построению анализатора. Но эквивалентные преобразования могут изменять структуру грамматики. Это означает то, что преобразованная грамматика не обязательно выполняет тот же самый перевод к семантическим действиям, что и первоначальная (исходная грамматика). Для этого необходим покрывающий гомомор -физм, при котором, если преобразование делается таким образом, что можно провести разбор в терминах исходной грамматики, можно как бы «обмануть» пользователя инструментальной системы. Эта идея была проиллюстрирована на рис. 2.
-
2 Обобщение регулярной модели
Можно отказаться от модели с деревьями вывода в КС-грамматиках и обратиться к модели с вычислением значений регулярных выражений.
Формальной базой для построения трансляторов является методика, основанная на использовании КС-грамматик с обобщёнными регулярными выражениями и атрибутами в виде семантик для представления контекстных ограничений. Эта методика развивается в курсе лекций студентам СПбГУ и поддерживается пакетом программных приложений, реализованных на платформе Delphi. В качестве основы взят код специального инструментального средства SynGT, разрабатываемого с 2000 г. [2].
Формальной моделью методики построения языковых процессоров, описанной в [1-2], являются регулярные выражения и конечный автомат — в качестве адекватного средства их обработки.
Данная модель обобщена до применения для класса КСР-языков с использованием специальных магазинных автоматов [19; 21; 22]. КСР-язык порождается КСР-грамматикой — обобщением КС-грамматики. Основные определения были даны в работах [1; 2; 4]. Из теории [2] формальным языком является набор цепочек языковых токенов (лексем или терминалов) в соответствии с грамматикой языка.
Синтаксис языка описывается его контекстно-свободной составляющей в виде КС-правил и контекстно-зависимой (ограничения).
КС-правила представлены в виде обобщённых регулярных выражений (КСР-правила):
Нетерминал : обобщённое регулярное выражение .
Регулярные выражения состоят из токенов (лексем), нетерминалов, регулярных операций (конкатенация, альтернативный выбор и обобщённая итерация), пустой цепочки ("") и скобок ("(" и ")").
-
- Конкатенация (“,”): A,B = AB.
-
- Альтернативный выбор (“;”): A;B = либо A, ли6ог B.
-
- Обобщённая итерация ( “#“): A#B = A; ABA; ABABA; ABABABA;
-
- Унарная итерация Клини (“*“): А* =_; A; AA; AAA;...
-
- Возможно пустое множество цепочек X: [ X ] = (X;)
Обобщение конечно автоматной модели обработки языков сводится к следующему:
-
- вводится итерация с разделителем (#) или обобщённая итерация, или итерация, которая не расширяет множество регулярных слов и может быть определена через традиционную (одноместную) операцию Клина (*) как (P#Q)=P,(Q,P;
-
- КСР-грамматика — обобщение КС-грамматики. Класс языков не расширяет, но снимает лишнюю структурированность языка;
-
- синтаксическая граф-схема (СГС) — графический аналог КСР-грамматики, стартовый объект для синтеза распознавателя (анализатора) языка, в терминах вершин которой удобно формулировать свойство детерминированности языка и возможные типы конфликтов (Shift/Reduce). СГС является промежуточной моделью между порож-дающей структурой, грамматикой и распознающей машиной, МП-автоматом.
-
3 Синтаксическая граф-схема (СГС)
Регулярные выражения в правых частях КСР-правил определяют бесконечное множество слов (регулярные множества), которые удобнее представлять в виде конечного ориентированного графа с метками в вершинах.
Такой граф считается порождающей конечно-автоматной схемой. В нём каждая вершина соответствует состоянию конечного автомата, а ее метка специфицирует порождаемый символ .
В синтаксической граф-схеме (СГС) каждому нетерминалу соответствует одна компонента — граф для нетерминала или одно правило КСР-грамматики, правая часть которого является обобщённым регулярным выражением над символами объединенного алфавита грамматики. В объединённый алфавит грамматики входят алфавиты терминалов, нетерминалов, семантик и, возможно, предикатов. СГС создается рекурсивно из графов для элементарных регулярных выражений и бинарных операций, подробно описанных в [1].
Одним из основных понятий в данной модели является понятие достижимости, с помощью которого формулируется вычисление множества слов (язык), порождаемых СГС. Дадим определения.
-
4 Достижимые вершины и понятие маршрута (пути) в синтаксической граф-схеме
Пусть дан алфавит V = {^, ^ 2, . „. Е, n }, n > 0.
Определение 4.1 . Граф-схемой над алфавитом V называется конечная совокупность ориентированных графов Г = { Г 1 , Г 2 , к , Г k }, ( k = 1,2, к , n ), удовлетворяющая следующим условиям:
-
- в каждом графе Г i , V i е {1,2,..., k }, выделены две вершины — входная и выходная , причем во входную вершину не входит, а из выходной вершины не выходит ни одна из дуг, а каждая из вершин, отличных от этих двух, помечена буквой из алфавита V ;
-
- графы Г i для V i е {1,2,..., k } не имеют между собой общих вершин и называются компонентами граф-схемы .
Входную и выходную вершины в каждом графе Г i V i е {1,2,..., k } обозначим E i и F i соответственно. Пусть вершина а принадлежит графу Гг е Г .
Определение 4.2. Буква ^ из алфавита V , которой помечена вершина a , называется меткой вершины а и обозначается m ( a ), ^ = m ( a ).
Каждой вершине а такой, что ( a * F i ), V i е {1,2,..., k }, в граф-схеме Г поставим в соответствие множество вершин succ ( a ), смежных с данной вершиной: succ ( a ) = { в | в е Г }, причем существует дуга, началом которой является вершина a , а концом — вершина в }.
Любым двум вершинам a и в , принадлежащим графу Г i - е Г в граф-схеме Г , ( a , в * F i ), можно поставить в соответствие множество слов L i ( a , в ), порождаемых маршрутами от вершины a к вершине в .
Определение 4.3. Множество слов L i ( a , в ) , порождаемых маршрутами от вершины a к вершине β , – это:
-
1. Пустое слово е е L i ( a , в ), если a = в ;
-
2. Слово x Е е 1 ^ ( a , в ), если x е L i ( a , у ), и существует вершина в графа F i - такая, что в е succ ( у ) и m ( в ) = Е .
Лемма 4.1. Слово x е V принадлежит множеству слов L i ( a , в ) тогда и только тогда, когда существует последовательность вершин a o , a 1 , K , a k , ( k > 0), графа Г i , такая, что a = a o , в = a k , a i е succ ( a i - 1 ), m ( a i ) = E i , V i е {1,2,..., k } и x = E 1 E 2 .K E k .
Обозначим через L i - множество слов, порождаемых всеми маршрутами в графе Г i е Г , начинающихся из входной вершины E i графа Г i ,
L i = U L ( E i , в ).
F i e succ (в)
Следствие 4.1. Слово x в алфавите V принадлежит множеству Li тогда и только тогда, когда существует последовательность вершин графа Г i , a g , a i , K , a k ( k ^ 0) такая, что a g = E i , F i e succ ( a k ), a i e succ ( a i — 1 ), m ( a i ) = ^ i , V i e {1,2,..., k } и x = ^2 k .
Очевидно, что для любого графа Г i множество слов L i регулярно.
В работе [1] есть строгие доказательства этих утверждений и подробно рассмотрен вопрос однозначности регулярных выражений.
Далее построим граф-схему для нетерминала в КСР-грамматике G . Для этого условимся в дальнейшем алфавитом V считать объединение алфавитов нетерминалов, терминалов и пустой буквы, то есть V = N и T и { X }. В дальнейшем алфавит V будет расширяться за счет добавления новых символов-понятий — вспомогательных нетермина-лов, семантик, предикатов и других.
Тогда если метка вершины a , m ( a ) из алфавита N , то a называется нетерминальной вершиной ; если m ( a ) из алфавита T , то a — терминальная вершина ; если m ( a ) = X , то a — пустая вершина .
Определение синтаксической граф-схемы для KCP -грамматики G будем вести последовательно: сначала опишем способ построения графа Г а для всякого регулярного выражения A над алфавитом V , затем определим граф для нетерминала из алфавита N KCP -грамматики G .
Построение графа Г а проводится индуктивно следующим образом: для элементарных выражений ( е и 2 е V ) соответствующие графы показаны на рис. 3, 4. Семантики будем отображать на дугах, для них графическое представление дано на рис. 5.
В работе [1] дан рекуррентный алгоритм построения синтаксической граф-схемы. В начале строится граф Г а для регулярных выражений с операциями конкатенации, объединения и обобщённой итерации , формулируются леммы о равенстве множества слов (языка), порождаемого регулярным выражением A и графом Г а .
Введение синтаксической граф-схемы в качестве механизма порождения цепочек языка вызвано следующими соображениями:
-
- являясь адекватным регулярному выражению (Лемма 2.2.) в [1], граф нагляднее отражает синтаксическую структуру KC -языка и не вводит лишнюю рекурсивность (структурированность) в его спецификацию;
-
- из граф-схемы проще извлекать информацию о порождающих цепочках, рассматривая маршруты в графах, а не деревья вывода в традиционных грамматиках;
-
- в терминах вершин удобней описать состояния автомата (анализатора) языка, порождаемого синтаксической граф-схемой;
-
- с дугами граф-схемы удобно связать вызовы процедур из специального раздела(Епу1гоптсп1) спецификации грамматики;
-
- использовать более простую структуру, чем вывод в KC -грамматике, а именно маршрут или путь в синтаксической граф-схеме, в терминах которого формулируются и проверяются ограничения на класс грамматик с эффективным анализом (линейной сложности разбора).
Определим множество слов (язык) — L G , порождаемых синтаксической граф-схемой Г G для КСР-грамматики G = { N, T, P, S }.
Пусть Г A — граф для нетерминала А из словаря N . Определим рекурсивно множество Н( А ) — начальных вершин графа Г A :
Определение 4.1
-
1 . Если а — вершина графа Г A и а е succ (Е A ), то а — начальная вершина графа Г A для нетерминала А , а е Н( А );
-
2. Если аеН( A ) — нетерминальная вершина в Г G , m(a)= В ив — начальная вершина графа Г В , то есть в еН(В), то в — начальная вершина графа Г A , т.е. в е Н( A ).
Аналогично определим множество конечных вершин K ( А ) графа Г а :
Определение 4.2
-
1 . Если a — вершина графа Г а и выходная вершина F a е succ (a), то a — конечная вершина графа Г а для нетерминала А , a e K ( А );
-
2. Если a е K ( А ), a — нетерминальная вершина в r G , m ( a ) = B и вершина в е K ( B ), то вершина в е K ( А ).
Введем понятие пути (маршрута) , соединяющего две вершины в синтаксической граф-схеме Γ G и определим отношение достижимости на множестве терминальных вершин.
Определение 4.3
Между терминальными вершинами a j и a 2 в синтаксической граф-схеме r G , существует путь (маршрут), если выполняется одно из следующих условий:
-
1. Вершины a j , a 2 — смежные, принадлежат одной и той же компоненте Г а для некоторого А е N , и a 2 е succ (a j ). Тогда путь Pa^ от вершины a1 к вершине a2 имеет вид:
-
2. Существует нетерминальная вершина в , смежная с вершиной a1 , в е succ (a j ), такая, что m ( в ) = B , а терминальная вершина a 2 — начальная вершина в графе для нетерминала B , a 2 е H ( B ).
P a j a 2 = { a 2 } .
В этом случае путь P a j a 2 от вершины a j к вершине a 2 имеет вид:
p a ^ a 2 = {в} " Р в , где
-
а) если a 2 принадлежит графу Г в , то есть a 2 е succ ( Е в ), то
Рв = РЕ B a2 = {ю H a2,}, где юн — специальный символ, обозначающий след прохождения через входную вершину графа для нетерминала;
-
b) если существует нетерминальная вершина y e Г в , m ( у ) = C , у е succ ( Е в ), и вершина a 2 е H ( C ), то
-
3. ai — конечная вершина графа Г в , и a 2 е succ (в), где в — нетерминальная вершина и m ( в ) = в . Тогда путь от вершины a i к вершине a 2 имеет вид:
Рр=РЕв у'Ру= {ю H У}'Ру .
-
p a 1 a 2 = Р a 1 ' {a 2 } , где
-
а) если a i — вершина графа Г в , т. е. F в е succ (a i ), то путь
Р? = {ю K в}, a1
где ю к — специальный символ, обозначающий след прохождения через выходную вершину графа для соответствующего нетерминала ;
-
b) если a i — вершина графа Г с , т. е. F c е succ (a i ) и существует нетерминальная вершина у , m ( у ) = C и у е K ( в ), то
-
4. Вершина a i — конечная в графе Г в , то есть a i е K ( в ), a 2 — начальная вершина графа Г с , т. е. a 2 е H ( C ) и существуют нетерминальные вершины в и у в графе Г a , такие что m ( в ) = в , m ( у ) = C и у е succ ( в ) , тогда путь между вершинами a i и a 2 имеет вид:
p a 1 = { ю к у } -р? .
Список литературы Гомоморфизм эквивалентных преобразований грамматик, применяемый при генерации анализаторов языка
- Fedorchenko L. Regularization of Context-Free Grammars. Saarbrucken: LAP LAMBERT Academic Publishing, 2011. 180 p.
- Fedorchenko L., Baranov S. Equivalent Transformations and Regularization in Context-Free Grammars // Cybernetics and Information Technologies (CIT). Sofia, 2015. Vol. 14, No. 4. P. 11-28.
- Ахо А. В., Сети Р., Ульман Д. Д. Компиляторы: принципы, технологии и инструменты. М.: Вильямс, 2001. 768 с.
- Федорченко Л. Н. Регуляризация контекстно-свободных грамматик на основе эквивалентных преобразований синтаксических граф-схем // Труды СПИИРАН. 2010. Вып. 4(15). С. 213-230.
- Early J. Ambiguity and precedence in syntax description // Acta Informatica. 1975. Vol. 4, Iss. 2. P. 183-192.
