Градиентные методы для минимизационных задач с условием Поляка - Лоясиевича: относительная погрешность градиента и адаптивный подбор параметров

Автор: Пучинин С.М., Стонякин Ф.С.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Математика
Статья в выпуске: 1 (61) т.16, 2024 года.
Бесплатный доступ
Рассматривается класс задач минимизации функций с условиями Липшица градиента и Поляка - Лоясиевича (градиентного доминирования). Оптимизационные задачи с условием Поляка - Лоясиевича актуальны, поскольку встречаются в самых разных важных приложениях, включая нелинейные системы с параметризацией в глубоком обучении. Естественно, возможна ситуация наличия погрешностей доступной методу информации, и возникает вопрос исследования влияния таких погрешностей на качество выдаваемого методом решения. В работе исследуется постановка задачи минимизации в предположении доступности во всякой текущей точке градиента целевой функции с относительной погрешностью. Предлагаются адаптивные (самонастраивающиеся) методы градиентного типа. Если в первом из них адаптивность подбора размеров шагов реализована только по параметру гладкости целевой функции, то во втором методе - ещё и по величине, связанной с относительной погрешностью градиента. Для каждого метода получена теоретическая оценка качества выходной точки. Адаптивность методов позволяет, в частности, применить полученные результаты к задачам с целевыми функциями, которые не удовлетворяют условию Липшица градиента на всём пространстве. Это проиллюстрировано результатами вычислительных экспериментов для функций Розенброка и Нестерова - Скокова.
Адаптивный метод, градиентный метод, условие поляка - лоясиевича, неточный градиент, относительная неточность
Короткий адрес: https://sciup.org/142241780
IDR: 142241780 | УДК: 519.85
Gradient-type method for optimization problems with Polyak - Lojasiewicz condition: relative inexactness in gradient and adaptive parameters setting
In this paper we consider the class of minimization problems with Lipschitz-continuous gradient and the well-known Polyak - Lojasiewicz condition. Optimization problems with the Polyak - Lojasiewicz condition are relevant because they are found in a wide variety of important applications, including non-linear systems with parameterization in deep learning. The presence of an inexactness in information available to a method is naturally possible, and the question of investigating the influence of such an inexactness on the quality of the solution given by the method arises. In the paper we investigate a formulation for the assumption of availability at any current point of the gradient of the target function with a relative inexactness. We propose some adaptive (self-tuning) gradient-type methods. If in the first of them the adaptivity of step size selection is realized only by the smoothness parameter of the target function, in the second method it’s also realized by the value related to the relative inexactness in the gradient. For each method, a theoretical estimate of the quality of the output point is obtained. The adaptive approach makes it possible, in particular, to apply the obtained results to problems with target functions which do not satisfy the Lipschitz condition of the gradient over the whole space. This is illustrated by the results of computational experiments for Rosenbrock and Nesterov - Skokov functions.
Текст научной статьи Градиентные методы для минимизационных задач с условием Поляка - Лоясиевича: относительная погрешность градиента и адаптивный подбор параметров
С ростом набора прикладных задач, которые сводятся к оптимизационным задачам большой или даже огромной размерности (некоторые из таких приложений возникают в машинном обучении, глубоком обучении, оптимальном управлении, обработке сигналов, статистике и т.д.), исследование различных методов первого порядка привлекает большое внимание научного сообщества [1]. Градиентные методы можно рассматривать как одно из ключевых направлений развития численных методов оптимизации в настоящее время. Преимущественно это связано с малозатратностыо их итераций с точки зрения используемой памяти, а также с независимостью оценок скорости сходимости от параметров размерности пространства.
Для задачи минимизации гладкой функции / хорошо известно, что если / сильно выпукла, то метод градиентного спуска имеет глобальную линейную скорость сходимости [2], причём её оценки не зависят от размерности пространства. Однако многие фундаментальные задачи машинного обучения, такие как регрессия методом наименьших квадратов или логистическая регрессия, приводят к задачам минимизации функций, которые не сильно выпуклы и даже не выпуклы. Это привело к исследованию приемлемых для возникающих в такого типа приложениях аналогов свойств выпуклости и сильной выпуклости для целевой функции оптимизационной задачи. Одно из наиболее известных таких свойств — условие градиентного доминирования Поляка - Лоясиевича [3]. Хорошо известно [3], что этого условия достаточно, чтобы показать глобальную линейную скорость сходимости градиентного спуска для достаточно гладких задач без предположений о выпуклости. Недавно в [4] показана оптимальность этого результата.
Как правило, для методов первого порядка делается предположение о доступности в произвольной точке допустимого множества задачи точного оракула первого порядка, т.е. оракул должен выдавать в каждой запрашиваемой точке точные значения целевой функции и её градиента. Но, к сожалению, во многих приложениях нет возможности получить точную информацию о градиенте и/или целевой функции на каждой итерации метода. Это привело исследователей к изучению поведения методов первого порядка, которые могут работать с неточным оракулом. В работе [5] (которую можно считать фундаментальной в этом направлении) авторы вводят понятие неточного оракула первого порядка, которое естественно возникает во многих ситуациях. При этом вопросы исследования влияния погрешностей доступной информации на гарантии сходимости численных методов, по-видимому, впервые были поставлены в книге [6].
Часто при анализе сходимости метода градиентного спуска подразумевается постоянная величина размера шага, которая зависит от константы Липшица градиента целевой функции (константы гладкости). Однако во многих прикладных задачах эту константу трудно оценить. Например, известная функция Розенброка и ее многомерные аналоги (например, функция Нестерова - Скокова) имеют только локально липшицево-непрерывный градиент. Для того чтобы преодолеть трудности с определением значения константы Липшица градиента, были разработаны различные методы, одним из которых является градиентный спуск с адаптивной политикой размера шага.
Недавно в [7] для рассматриваемого в настоящей работе класса задач (с достаточно гладкой целевой функцией, удовлетворяющей условию Поляка - Лоясиевича) предложены неадаптивный и адаптивный градиентные методы, использующие понятие неточного градиента. В [7] проанализированы предложенные алгоритмы и влияние помех в градиенте на скорость сходимости. Однако в их работе адаптивность имеет место лишь в отношении константы Липшица градиента; по-прежнему необходимо точно знать оценку величины абсолютной погрешности градиента. В [8] предложен и проанализирован адаптивный алгоритм, который предполагает настройку не только константы гладкости функции L, но и величины абсолютной погрешности градиента А. Но в обеих работах [7,8] рассматривался лишь случай доступности градиента с абсолютной погрешностью. Пример выбора размера шага неадаптивного градиентного метода в случае относительной погрешности задания градиента в случае известного значения L приведён в параграфе 1 пособия [9].
В настоящей работе продолжаются исследования по адаптивным методам градиентного типа [7, 8] для гладких задач с условием Поляка-Лоясиевича в случае доступности методу в произвольной текущей точке информации о градиенте с относительной погрешностью. Предложены два адаптивных алгоритма (различающихся набором настраиваемых параметров) для задач с целевыми функциями, удовлетворяющими условию Поляка -Лоясиевича, при наличии относительной неточности задания градиента, с подробным анализом их скоростей сходимости и поведения образуемых ими траекторий. Если в первом из этих алгоритмов (алгоритме 1) адаптивность реализована только для параметра L, то во втором (алгоритме 2) имеется адаптивность по обоим параметрам: константе Липшица градиента целевой функции L и величине относительной погрешности градиента а. Таким образом, второй из предложенных алгоритмов полностью адаптивен.
2. Постановка задачи и основные понятия
Рассматривается минимизационная задача (в общем случае невыпуклая):
min f (ж), (1)
■'
где целевая функция является L-гладкой и удовлетворяет условию Поляка - Лоясиевича.
Определение 1. Дифференцируемая функция f : Rn ^ R называется L-гладкой относительно нормы Цф. если для некоторой константы L > 0 выполнено
№f(У) -Vf
(ж)|
Норма в данной работе всюду подразумевается евклидовой. Как хорошо известно, условие L-гладкости (2) влечёт следующее неравенство f (У) < f (ж) + ^f(ж),у — ж) + L\\у -ж|2. (3)
Определение 2. L-гладкая функция f удовлетворяет условию Поляка - Лоясиевича (или, для краткости, PL-условию), если выполнено следующее неравенство:
f (ж) -f * < 1- \Vf (ж) ||2 Уж е R, 2Р
где р > 0 — некоторая константа, a f * := f (ж*), где ж* е А * (А * — множество точных решений рассматриваемой минимизационной задачи).
В литературе условие (4) также иногда называется условием градиентного доминирования.
В данной работе предлагается рассмотреть проблему поведения методов градиентного типа для задачи (1) в случае относительных помех информации о градиенте. Недавно в [7,8] были детально исследованы адаптивные методы градиентного типа при наличии абсолютных помех. Мы же рассматриваем ситуацию, когда градиент известен с относительной погрешноствю, то есть
||V/(х) -V/(х)| < a^Vf Д)||, (5)
где V/(ж) — неточный градиент (доступен методу), a a G [0, 0.5) — некоторая константа, отвечающая за величину помех в градиенте. Данное условие на неточный градиент было введено и изучено в работах [6,10]. Обычно рассматриваются a из большего полуинтервала [0,1), однако по причинам, описанным в разделе 3, нами рассматривается усеченный полуинтервал [0, 0.5). Отметим, что относительные помехи в градиенте могут возникать из-за приближенного его вычисления, например, в безградиентной оптимизации (см. [11]).
Как легко видеть из (5),
(1 -a)hV/(х)Ц < IV/ (х)| ^ (1 + a)|Vf(х)|, (6)
откуда можно получить условие типа Поляка - Лоясиевича (4) для неточного градиента
/(х) - /* <
2ц(1 — a)2
|V/(х)|2.
3. Градиентный спуск с адаптивной политикой размера шага
Задачу (1) предлагается решать методом градиентного спуска в виде xk+1 = xk — hkVf (хк), hk > 0, (8)
где размер шага hk может зависеть от L и a, а также, в случае, когда точное значение одного из них или их обоих неизвестно, от Lk+i и ak+i-
Если при реализации метода (8) градиент доступен с известной относительной погрешностью a € [0,1) и известен параметр L > 0, то выбор постоянного размера шага hk = h =
1 (1 — a) L (1 + a)2
приводит к следующему результату (см. параграф 1 из пособия [9] и имеющиеся там ссылки) :
f (Xk+1) - f (Xk) < -2L ...(Xk Д
Пользуясь условием Поляка - Лоясиевича (4), имеем следующую оценку на скорость сходимости по функции:
f (х’>-/* < (1 - L [1+02)’ (/(х0) -/Щ
Однако цель данной работы — предложить аналог алгоритмам 1 и 2 из [8] для случая относительной погрешности градиента с адаптивной настройкой параметров L и a. По сути, необходимо предложить критерий выхода из итерации, содержащий норму неточного градиента |Vf (xk)|. Это обстоятельство затрудняет использование подхода с оценками типа (9) для нормы точного градиента. Поэтому рассмотрим альтернативный вариант выбора размера шага для метода (8) с относительной погрешностью задания градиента, который позволит получить приемлемый аналог оценки (9) для квадрата нормы неточного гради- ента. Используя (5), (6), выпишем следующий аналог неравенства (3):
/ ( у ) < / ( ж ) + (V/ ( х ) ,у - х) + 1||у - х|2 =
= / ( х ) + (V/ ( х ) . у - х) + 1 Цу - х|2 + (V/ ( х ) - V/ ( х ) . у - х) <
< / ( х ) + (V/ ( х ) . у - х) + 1 Цу - х|2 + |V/ ( х ) - V/ ( х ) ||||у - х| <
< / ( х ) + (V/ ( х ) ,у - х) + 1|у - х|2 + a|V/ ( х )|||| у - х| <
< / ( х ) + (V/ (х),у - х) + 1 1у - х|2 + 1-^ IV/(х)ЦЦу - х|.
т.е.
/ и ■ .«/ у ) + (V / у )Щ +1 - х ) + 1Ц.^1 - х ||2 +
+гК hИНК1 - ' 1 1. <10>
На базе неравенства (10) ниже будут предложены критерии выхода из итерации в алгоритмах 1 и 2. Это неравенство гарантирует отсутствие зацикливания (выход из итерации в некоторый момент) соответствующих алгоритмов для L-гладких задач.
3.1. Алгоритм с адаптивной настройкой параметра гладкости
Ниже приведен адаптивный алгоритм 1 с настройкой параметра гладкости L при из вестном а € [0; 0 . 5).
Алгоритм 1 Градиентный спуск с адаптивной настройкой L
Вход: х . Lmin ^ Д > 0. L 0 ^ Li nm- а € [0, 0.5)-
-
1. к = 0.
-
2. Lk+i =max{ ^ . L min}.
-
3.
-
4. Если
/ (Н+1 ) «/ у ) + (V/ у ) .н+1 - н) + !ш |р +1 - Д2 +
+ гКК<х‘ > lll?+1 - К. 1121
-
5. Если правило остановки не выполнено, то к := к + 1 и переходим на шаг 2. Выход: хк.
х к +1 = хк - , 1 1 2а V/ ( х к) . (11)
Lk +1 1 - а
то переходим на шаг 5. Иначе L^+i := 2L^+i и возвращаемся на шаг 3.
Проведем анализ скорости сходимости и траектории для предложенного алгоритма. Из (8) имеем
| | х к +1 - хк | | = ^| | V/ (хк )||
и
(V/ ( х к) . х к +1 - хк ) = -hk ||V/ ( х к) ||2 .
Объединяя полученные выражения с (12), получаем
/ у-щ - f у-)c(-hk + ^^^ + ^) || v /(xk) ||2. аз»
Так как hk не может быть отрицательным, минимум выражения, стоящего в скобках, до стигается при
hk
1 1 - 2а] ^“УГУ т-х .
Если a € [0.5,1), то минимум выражения, стоящего в скобках в (13), равен 0 пр и hk = 0, что говорит об отсутствии гарантий сходимости метода (8) вне зависимости от выбора hk- Поэтому в (5), как и в алгоритмах 1 и 2, рассматриваются лишь a € [0, 0.5).
При a G [0, 0.5) и задании размера шага согласно (11) имеем f ^ - f ^ ) С - 2_k_ 2 '- ^ f ^ )|2 .
Объединив последнее неравенство с (7), получаем где
f (xk+1
) - f * С (1
-
(1 - 2a)2) (fУ) - f >) =
-
Д
Lk+1
e) (f (xk) - f *),
e := (1 - 2a)2.
Можно считать, что
Lo
С L, поэтому maxk
N—1 TV f (xN) - f* c n (1 - (f (^o) - f*) c (1 - CM (f (ж°) - f*),
V Lk+1 / \ Lmax /
где
Lmax = 2L.
Получаем сходимость по функции со скоростью геометрической прогрессии. Это означает, что для достижения --точности по функции требуется не более м
N * = ГL log ( ^ (f (ж ° ) f * )
Е
итераций. С другой стороны, в силу PL-условия (7), эта же точность по функции может быть гарантирована при выполнении следующего правила остановки:
|Vf (хк )|2 С 2 е (1 - а)2.
Далее, получим ограничение на траекторию {xk}k=°, образуемую алгоритмом 1:
1 (1 - 2а)2
2Lk+i (1 - а)2
| | Vf (xk) | | 2 С f (xk) - f (xk+1)
и, следовательно, согласно (11),
11xk+1 -xk 11 2 = (ГУ•'У11 vf(xk) 11 2 c ry(f(xk) -f(xk+1))c
С M (f (xk) - f*) С M (1 - CM k (f (x°) - f*) .
Lk+1 4 / Lmin \ Lmax /
Наконец,
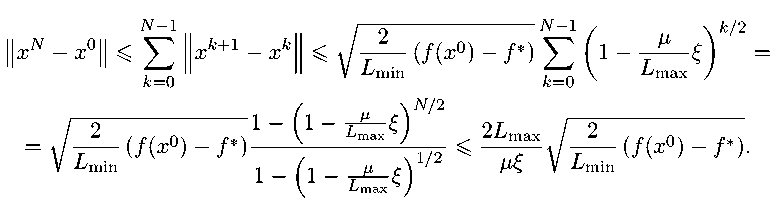
xN — х0 || < £ ||х/г + 1
V ^ min
N -1
I о N 1 / \ k/ 2
J — (f(х0) — f*) £ (1 — min max k=0
м ^max м Lmax
N/2
1 / 2 ^
min
(f (х0) - f*)
Таким образом, верна следующая
Теорема 1. Пусть функция f удовлетворяет условию Липшица градиента (2) и условию Поляка - Лоясиевича (4). И пусть при работе алгоритма 1 выполнилось одно из следующих двух условий:
-
1) алгоритм 1 проработал N* итераций, где
N*
Lmax . /
los(
^(f(х0) - f
Е
)︀
-
2) для некоторого N < N* выполнено правило остановки в виде
\\?f(xN)||2 < 2е(1 — о)2, где Lmax задается формулой (14). Тогда верны следующие оценки на выходную точку X алгоритма 1 (X = xN* и ли X = xN соответственно):
f (X) - f * < Е
^
и
|| х — х0
< ^хI v^(f (х0) — f *) № V L min
Замечание 1. Оценка (15) не зависит ни от N, ни от невязки по функции на N-м шаге. Поэтому для L-гладких задач траектория рассмотренного алгоритма лежит в некотором шаре фиксированного радиуса с центром в х0. Данная особенноств позволяет в какой-то мере сохранятв полезные свойства началвной точки х0. Также она позволяет расширитв областв применимости рассматриваемого подхода на другие классы функций. Например, на класс функций, удовлетворяющих FT-условию лишь локально на некотором множестве. Это продемонстрировано ниже, в вычислительных экспериментах в разделе 4.
Замечание 2.
Во всех приведённых в настоящем подразделе статьи результатах Lmax, оценивающее максимально возможное значение для
Lk+i,
может быть заменено на maxk
Замечание 3. Алгоритм 1 применим и для случая точного градиента при а = 0. В этом случае просто £ = 1.
Алгоритм 2 Градиентный спуск с адаптивной настройкой Тиа
Вход: X , T min 3 Т > °! Т 0 3 Т т1ш a min € [° , 0 . 5), a o G [a min , 0 . 5).
1. k = 0; ftmax = 0.5 - amin 3o = 0.5 - ao.
4. Если
5. Если правило остановки не выполнено, то k :— k + 1 и переходим на шаг 2. Выход: xk.
3.2. Алгоритм с адаптивной настройкой параметра гладкости и величины относительной погрешности градиента
2' Lk+1 — Шах-^ “2^ ,T min}, Pk+1 — Ш1П {23k , /i max}- ak+1 — 0.5 Pk+1' 3.
тk+1 - Tk —1—^Ok+lv k(Tk} x — x — ------------V j (X ) .
Tk +1 1 — ak +1
f ( xk+1 ) С f (xk ) + (Vf (xk ) , xk+1 — xk^ + T + 1 ||xk+1 — xk||2 +
+ a^ll^ f ( xk ) ||||xk+1 — xk|| , 1 — ak +1
то переходим на шаг 5. Иначе Tk+1 :— 2Tk+1, 3k+1 = 0.53k+1> ak+1 :— 0.5 — 3k+1 и возвращаемся на шаг 3.
Для реализации адаптивной настройки не толвко параметра гладкости Т, но и величины относителвной погрешности градиента а введем дополнительный параметр 3 € (0, 0.5] следующим образом: 3 :— 0.5 — а. Предлагаемый алгоритм приведен ниже как алгоритм 2. Можно считать, что To С Т и ao С а (то есть 3о 3 3)> поэтому шахТ С Т шах k ( „ Anax1 [2, 0.53 J L 0.5 — amin 1 — 2Т шах 1, [ ’ 0.5 — a J и ЩаАш k >____3____ шахЬ, 72М bmin J 0.5 — a Anin 1 -г-™”!1-— И, следовательно, шах ak+1 — 0.5 — min3k+1 С 0.5 — k 0.5 — a. 13 Anin 1 _—шт| ,_ J. Введем соответствующие обозначения: Ттах :— 2Т шах 1, 0.5 — a 0.5 — min a , 0.5 — a Amini amax :— 0.5--2---ш.П 1, — . Проведем анализ получаемой алгоритмом 2 выходной точки в рамках следующего предположения, аналогичного используемому авторами [8] для случая абсолютной погрешности. Предположение 1. Алгоритм 2 может запрашивать значение градиента в любой текущей точке xk с произвольной относительной точностью, которая не выше, нем amin. а конкретно с точностью ak+1. Это позволяет записать PL-условие для неточного градиента в точке xk, заменив а на ak+i f (xk) - f* < 2T(1 - ak+i)2 |Vf(xk)|2 . Условие (18), в свою очередь, позволяет, аналогично полученным в предыдущем подразделе результатам, записать следующую оценку скорости сходимости по функции для алгоритма 2: N—1 х \ /\ N f (XN) — f* < П (1 — T^^k+1 ) (f (X0) - f*) < (1 - y^max ) (f (X0) - f*) ,(19) k=0 Lk+1 V Lmax' где £k+i :=(1 - 2ak+i)2 И ^max :=(1 - 2amax)2,(20) а также получить следующий основной результат этого раздела. Теорема 2. Пусть функция f удовлетворяет условию Липшица градиента (2) и условию Поляка - Лоясиевича (4). И пусть при работе алгоритма 2 выполнилось одно из следующих двух условий: 1) алгоритм 2 проработал N** итераций, где N.. = (^x. log (УЛх°ЬГ))Р | TQmax \ 2) для некоторого N < N*. выполнено правило остановки в виде ||Vf (xN)|2 < 2е(1 - aN+1)2, где emax задается формулой (20), a Lmax и amaxзадаются формулами (16) и (17) соответственно. Тогда верны следующие оценки на выходную точку X алгоритма 2 (X = xN** или X = xN соответственно): f (X) -f * < £ Т и x - x0| ⩽ 2L max Те max V Lmin (f (x0) -f*). Замечание 4. Предположение 1 довольно естественно для случая относительной погрешности, так как одной из основных областей её возникновения является безградиентная оптимизация, где зачастую можно регулировать точность вычисления приближенного значения градиента в запрашиваемой точке. Замечание 5. В силу оценки (22) из теоремы 2 для алгоритма 2 справедливы все выводы замечания 1, сделанного выше для алгоритма 1. Это продемонстрировано ниже, в вычислительных экспериментах в разделе 4. Замечание 6. Исходя из предположения 1, алгоритм имеет доступ к градиенту с относительной погрешностью amin. Тем не менее понижение запрашиваемой точности до ak+i ведет к ускорению вычисления неточного градиента, а также к возможному уменьшению второго настраиваемого параметра Lk+i, что имеет положительный эффект на оценку (19) и оценки (21), (22) из теоремы 2. Замечание 7. Предположение 1 не обязательно для получения линейной скорости сходимости. В случае, когда алгоритм не может регулировать величину погрешности градиента, имеют место аналоги оценки (19) и теоремы 2 для 2 (1 — °)2 6г+1 := (1 - 2^+1) -------ж (1 - ak+i)2 И ^max — (1 2amax) (1 - а)2 (1 - Omax)2 соответственно. Замечание 8. Во всех приведённых в настоящем подразделе статьи результатах Lmax и amax, оценивающие максимально возможные значения для L^+i и a^+i, могут быть заменены на max^<^ L^+i и max^<^ a^+i соответственно. Замечание 9. Алгоритм 2 (как и алгоритм 1) за счёт адаптивности применим даже для задач, не обладающих глобально свойством L-гладкости на всём пространстве. Это продемонстрировано ниже в вычислительных экспериментах для некоторых задач в разделе 4. Замечание 10. Можно оценить число повторений отдельно взятых шагов алгоритма 2. Если L^+i ^ Ln a^+i ^ a (то есть /Д+i С Д, то повторения 4-го шага заканчиваются. 0.5-aminU 0.5-a J Д Поэтому повторений 4-го шага за все итерации не более 2V + log2 ^2 max ^^ , Таким образом, можно, например, оценить число обращений к оракулу на протяжении работы алгоритма.
4. Вычислительные эксперименты Для проведения экспериментального анализа работы итогового для настоящей статьи алгоритма 2 были выбраны функция Розенброка, а также функция Нестерова - Скокова. Обе эти функции невыпуклы и удовлетворяют PL-условию (4) на любом компакте (см., например, [7]). При этом для них нет возможности гарантировать условие L-гладкости на всём пространстве. Все вычислительные эксперименты проводились на платформе Google Colab . Для генерации равномерного шума из многомерного шара использовался инструмент из библиотеки nengo .
4.1. Функция Розенброка Функцией Розенброка называется следующая функция двух переменных: /(#1, #2) — 100 (#2 - #2)2 + (#i - 1)2. Как легко видеть, ее глобальный минимум находится в точке (#i,#2) — (1,1), и /* — 0. На вход алгоритму подавались следующие входные данные: ж0 — (0, 0), Lmin — 0.01, Lo — 1, amin — 0.001, ao — 0.01. В качестве неточного градиента рассматривалось значение градиента V/(#i,#2), зашумленное равномерно распределенным в 2-мерном шаре радиуса a^V/(#i,#2)^ относительным шумом, где параметр a варьировался. Результаты эксперимента приведены на рис. 1, а также в табл. 1 и 2. Таблица 1 Результат работы алгоритма 2 после V — 1000 итераций для функции Розенброка a 0.001 0.01 0.1 0.3 0.5 1 / (®w) 0.0074 0.0075 0.0060 0.0021 0.0018 0.0017 Рис. 1. График зависимости значения функции от номера итерации в зависимости от параметра помех а для функции Розеиброка Таблица 2 Результат работы алгоритма 2 после N = 10 000 итераций для функции Розеиброка а 0.001 0.01 0.1 0.3 0.5 1 f (xn ) 1.5 х 10-19 1.3 х 10-19 1.6 х 10-19 2.6 х 10-16 2.7 х 10-15 7.3 х 10-17 Для всех рассмотренных а метод уже к 10 000-й итерации сходится по функции и, следовательно, по аргументу к глобальному минимуму с машинной точностью. Отметим, что предполагаемое замедление сходимости при увеличении а не наблюдается как минимум до 1000-й итерации (см. табл. 1), однако по итогу при сильном приближении к минимуму это начинает незначительно сказываться, что видно из табл. 2. В том числе, оказалось приемлемым значение а =1, которое в теоретических рассуждениях нами отбрасывалось.
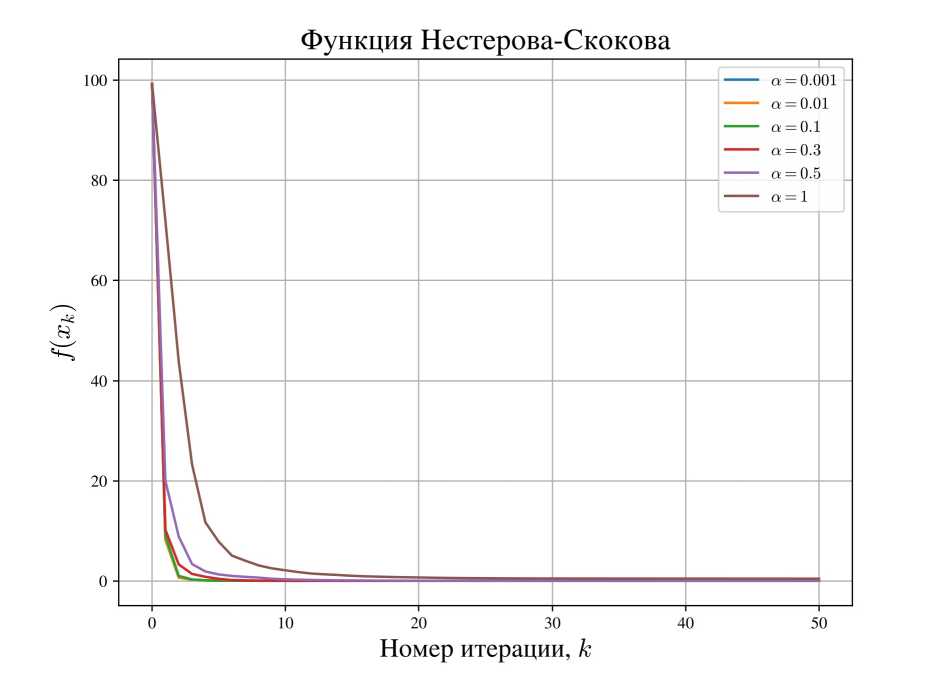
4.2. Функция Нестерова - Скокова Функцией Нестерова - Скокова называется следующая функция п переменных: 1 п—1 f Д1Щ2, ... ,яп) = 4(1 - щ)2 + (ар+1 - 2x2 + 1) . г=1 Эту функцию также называют обобщением функции Розеиброка на многомерный случай. Как легко видеть, ее глобальный минимум находится в точке (xi, Х2,..., xn) = (1,1,..., 1), и f * = 0- На вход алгоритму подавались следующие входные данные: Lmin = 0.01, amin = 0.001, «о = 0.01. В качестве неточного градиента рассматривалось значение градиента V/(ад, а2,... , ап), зашумленное равномерно распределённым в п-мерном шаре радиуса a^V/(si,T2,...,in)^ относительным шумом, где параметр а варьировался. Также варьировались а0 и Lo. Размерность п выбрана равной 100. Результаты эксперимента приведены на рис. 2, а также в табл. 3-6. Рис. 2. График зависимости значения функции от номера итерации в зависимости от параметра помех а для функции Нестерова - Скокова (а0 = (0, 0,..., 0). Lo = 1) Таблица 3 Результат работы алгоритма 2 после N = 10 итераций для функции Нестерова - Скокова (а0 = (0, 0,..., 0), Lo = 1) a 0.001 0.01 0.1 0.3 0.5 1 / (а^у) 0.058 0.058 0.059 0.073 0.261 2.631 Таблица 4 Результат работы алгоритма 2 после N = 50 итераций для функции Нестерова - Скокова (а0 = (0, 0,..., 0), Lo = 1) a 0.001 0.01 0.1 0.3 0.5 1 / (а^у) 0.058 0.058 0.058 0.058 0.058 0.058 Для случая а0 = (0, 0,..., 0). Lo = 1 метод для всех рассмотренных а быстро сходится к минимуму, но не глобальному, а только локальному, который, однако, относительно близок к глобальному по функции. Для случая а0 = (-1,1,..., 1), L0 = 0.1 при a = 0.001 и а = 0.01 метод быстро сходится уже к глобальному минимуму, однако при остальных рассмотренных а метод почти сразу сваливается в локальный минимум с далеким от оптимального значением функции. В обоих случаях, в отличие от функции Розенброка, здесь отчётливо заметно снижение скорости сходимости при увеличении параметра а, пусть и не значительное. Таблица 5 Результат работы алгоритма 2 после У = 10 итераций для функции Нестерова - Скокова (ж0 = (-1,1,..., 1), Lo = 0.1) а 0.001 0.01 0.1 0.3 0.5 1 f (xn ) 1.2 x 10-6 6.7 x 10-5 0.98 0.98 0.98 0.98 Таблица б Результат работы алгоритма 2 после N = 50 итераций для функции Нестерова - Скокова (ж0 = (-1,1,..., 1), Lo = 0.1) а 0.001 0.01 0.1 0.3 0.5 1 f (xn ) 4.4 x 10-11 3.2 x 10-9 0.98 0.98 0.98 0.98
5. Заключение В статье продолжены начатые недавно в работах [7,8] исследования по анализу поведения траекторий адаптивных методов градиентного типа для задач с условием Поляка -Лоясиевича в предположении доступности методу в текущей точке информации о целевой функции. Интерес к этому классу задач обусловлен тем, что к нему сводятся важные вопросы исследования нелинейных систем с перепараметризацией в глубоком обучении [12] и многие другие прикладные задачи [13]. Такие задачи могут быть невыпуклыми [14], но при этом можно гарантировать для них сходимость методов градиентного типа со скоростью геометрической прогрессии в случае L-гладкости. Если в статьях [7, 8] исследовался случай аддитивной неточности градиента и аддитивной неточности задания целевой функции, то в настоящей работе рассмотрена ситуация доступности в текущей точке градиента с относительной погрешностью, что актуально, например, с точки зрения безградиентных методов [11]. Принципиальное отличие полученных результатов от [7,8] — доказательство сохранения сходимости предложенных вариаций градиентного метода со скоростью геометрической прогрессии при некоторых предположениях об уровне относительной погрешности. В случае абсолютной неточности информации о градиенте в [7, 8] удалось лишь оценить (показана оптимальность таких оценок) степень отклонения от сходимости со скоростью геометрической прогрессии в случае известной оценки параметра погрешности информации о градиенте и предложить правила ранней остановки методов, гарантирующие достижение оптимального уровня качества приближённого решения по функции. При этом адаптивность рассмотренных методов открывает возможности их применения в задачах, для которых нет глобального свойства L-гладкости, в том числе и в негладких по аналогии с подходом универсальных градиентных методов Ю.Е. Нестерова [15]. Работа выполнена при поддержке гранта Российского научного фонда и города Москвы № 22-21-20065 .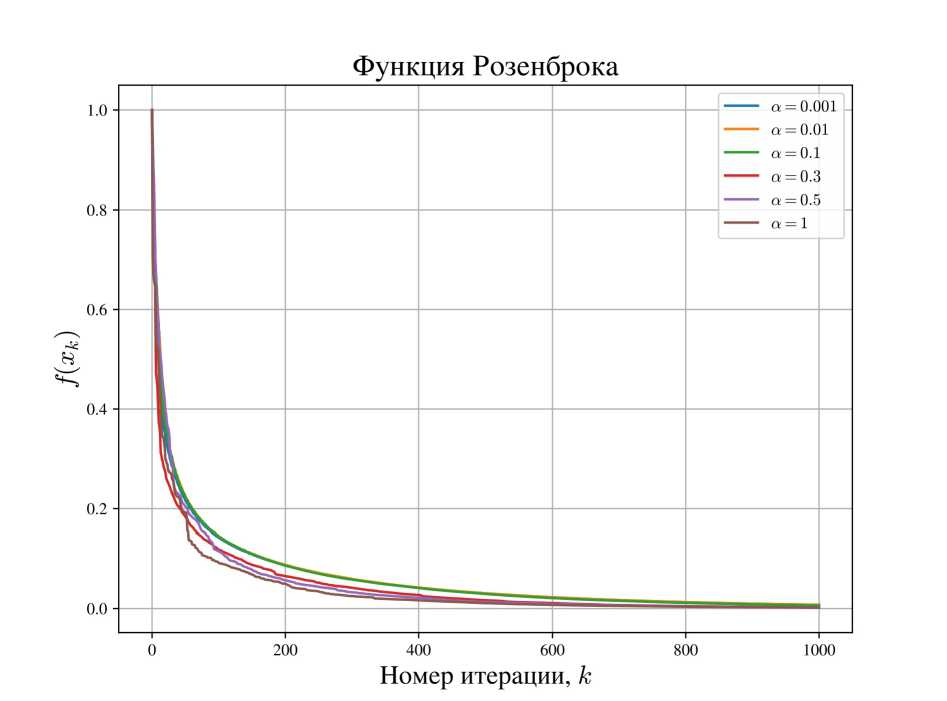
Список литературы Градиентные методы для минимизационных задач с условием Поляка - Лоясиевича: относительная погрешность градиента и адаптивный подбор параметров
- Beck A. First-Order Methods in Optimization. Society for Industrial and Applied Mathematics. Oct 2017. https://doi.org/10.1137/1.9781611974997
- Nesterov Y. Introductory Lectures on Convex Optimization. Springer US, 2004. https://doi.org/10.1007/978-1-4419-8853-9
- Polyak B.T. Gradient methods for the minimisation of functionals // USSR Computational Mathematics and Mathematical Physics. 1963. V. 3(4). P. 864–878. https://doi.org/10.1016/0041-5553(63)90382-3
- Yue P., Fang C., Lin Z. On the lower bound of minimizing Polyak – Lojasiewicz functions. The Thirty Sixth Annual Conference on Learning Theory // Proceedings of Machine Learning Research. 2023. V. 195. P. 2948–2968. https://proceedings.mlr.press/v195/yue23a/yue23a.pdf
- Devolder O., Glineur F., Nesterov Y. First-order methods of smooth convex optimization with inexact oracle // Mathematical Programming. 2013. V. 146(1–2). P. 37–75. https://doi.org/10.1007/s10107-013-0677-5
- Поляк Б.Т. Введение в оптимизацию. Москва: Наука, 1983.
- Polyak B.T., Kuruzov I.A., Stonyakin F.S. Stopping rules for gradient methods for nonconvex problems with additive noise in gradient // Journal of Optimization Theory and Applications. 2023. V. 198. P. 531–551. https://doi.org/10.1007/s10957-023-02245-w
- Kuruzov I.A., Stonyakin F.S., Alkousa M.S. Gradient-type methods for optimization problems with Polyak– Lojasiewicz condition: Early stopping and adaptivity to inexactness parameter / Olenev N., Evtushenko Y., Jacimovic M., Khachay M., Malkova V., Pospelov I. (eds) // Advances in Optimization and Applications. OPTIMA 2022. Communications in Computer and Information Science. 2022. V. 1739. P. 18–32. https://doi.org/10.48550/ARXIV.2212.04226
- Гасников А.В. Современные численные методы оптимизации. Метод универсального градиентного спуска. Москва: МЦНМО, 2021.
- Carter R.G. On the global convergence of trust region algorithms using inexact gradient information // SIAM Journal on Numerical Analysis. 1991. V. 28(1). P. 251–265. https://doi.org/10.1137/0728014
- Berahas A.S., Cao L., Choromanski K., Scheinberg K. A theoretical and empirical comparison of gradient approximations in derivative-free optimization // Foundations of Computational Mathematics. 2021. V. 22(2). P. 507–560. https://doi.org/10.1007/s10208-021-09513-z
- Belkin M. Fit without fear: remarkable mathematical phenomena of deep learning through the prism of interpolation // Acta Numerica. 2021. V. 30. P. 203–248. https://doi.org/10.1017/S0962492921000039
- Karimi H., Nutini J., Schmidt M. Linear convergence of gradient and proximalgradient methods under the Polyak – Lojasiewic condition. Springer, 2016. P. 795–811. https://doi.org/10.1007/978-3-319-46128-1_50
- Polyak B., Tremba A. New versions of Newton method: step-size choice, convergence domain and under-determined equations // Optimization Methods and Software. 2020. V. 35(6), P. 1272–1303. https://doi.org/10.1080/10556788.2019.1669154
- Nesterov Y. Universal gradient methods for convex optimization problems // Mathematical Programming. 2014. V. 152(1–2). P. 381–404. https://doi.org/10.1007/s10107-014-0790-0
