Hybrid artificial bee colony and tabu search based power aware scheduling for cloud computing

Author: Priya sharma, Kiranbir kaur
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 7 vol.10, 2018.
Free access
Load balancing is an important task on virtual machines (VMs) and also an essential aspect of task scheduling in clouds. When some Virtual machines are overloaded with tasks and other virtual machines are under loaded, the load needs to be balanced to accomplish optimum machine utilization. This paper represents an existing technique “artificial bee colony algorithm” which shows a low convergence rate to the global minimum even at high numbers of dimensions. The objective of this paper is to propose the integration of artificial bee colony with tabu search technique for cloud computing environment to enhance energy consumption rate. The main improvement is makespan 28.4 which aim to attain a well balanced load across virtual machines. The simulation result shows that the proposed algorithm is beneficial when compared with existing algorithms.
Cloud computing, load balancing, artificial bee colony, tabu search
Short address: https://sciup.org/15016506
IDR: 15016506 | DOI: 10.5815/ijisa.2018.07.04
Text of the scientific article Hybrid artificial bee colony and tabu search based power aware scheduling for cloud computing
Published Online July 2018 in MECS
-
I. Introduction
Cloud computing is a technology that utilizes the web and central remote servers to offer scalable services for its consumers and all the application are managed on a cloud which includes a large number of computers interlinked together in a complicated or sophisticated way (Venugopal, 2013). Cloud offers computing resources/ method a in the proper execution of virtual machine that is an abstract that runs on physical machine (Mohamed Shameem & Shaji, 2014). There are basically three services provide by cloud: - Iaas, Paas, Saas (Zuo, Zhang, & Tan, 2014).
According to different prioritized tasks selection of VM:-
T ' →Vm | min(∑T' ) ∈Vm(1)
T'M →Vm|min(∑T'H∑TM)∈Vm(2)
T'L→Vm|min(∑TM)∈Vm(3)
Table 1. Symbols Description
Vm
Т' т,
T H , T M , T L
Virtual machine
Higher, middle and lower priority cadres of tasks.
Load balancing is performed at VM stage i.e. at intra datacenter level. In cloud environment, load balancing and scheduling is the biggest challenges/issues. Load balancing methods are generally mentioned homogenous as well as heterogeneous environment like as grid (Venugopal, 2013).
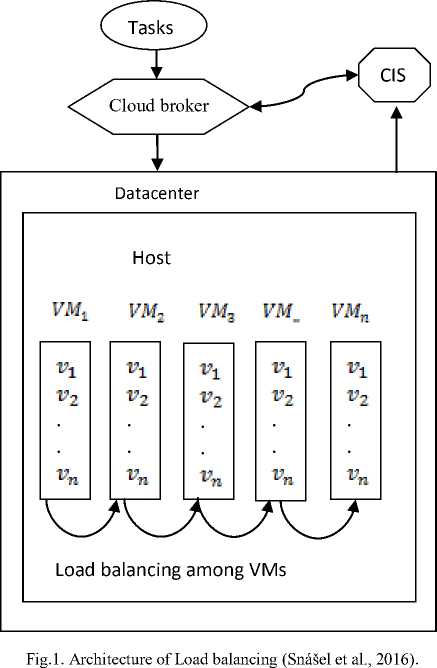
The basic architecture of load balancing process is described in fig1. Cloud information service (CIS) may be achieved which includes most of the resources obtainable in the cloud environment. It is really a register of datacenters. Each time a datacenter is establishes it’s to join the CIS.
Calculate total datacenter load on each VM:- n
LDDC = ∑ LDVM (4)
Vm =1
Calculate entire datacenter capacity:- n
CaPDC = E CaPvM (5)
Vm =1
In cloud computing these hosts are virtualized in to various quantity of virtual machines predicated on individual user request. Virtual machines can also heterogeneous features like hosts. Cloud information service (CIS) acquires detail regarding virtual machine in the datacenters that predicated on these details the cloud broker transmits these jobs to various different resources in a datacenter. In this approach, algorithm checks the overloaded VMs and then migrate tasks to under loaded VMs (Snášel et al., 2016).
The load balancing issue could be separated into two subscription issues:-
1. Entrance of new request for virtual machine provisioning and keeping of virtual machines on host.
-
2. Migration/Reallocation of virtual machines (Mohamed Shameem & Shaji, 2014).
-
A. Traditional Techniques in Load Balancing
Bee colony with scheduling and load balancing:-
Table 2. In cloud environment mapping parameters with enhanced bee colony algorithm (Snášel et al., 2016)
|
Cloud environment |
Bee hive |
|
‘Task ‘(Cloudlet) |
‘Honey bee’ |
|
‘Virtual machine’ |
‘Food source’ |
|
Loading of a task to a Virtual machine |
Honey bee foraging a some food Source |
|
Virtual machine in overloaded condition. |
Honey bee obtaining depleted at a food source |
|
Deleted task after rescheduling to an under loaded Virtual machine having highest capacity |
Foraging bee searching a newly food source |
This algorithm load balancing and scheduling criteria perform in following 4 steps [(Venugopal, 2013), (Snášel et al., 2016)]:-
-
i. Calculate current load on virtual machine:-
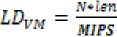
Table 3. Symbols Description
VM
Virtual machine
N
No. of tasks
Len
single task length
MIPS
Million instruction per second
-
a. Calculate capacity of virtual machine:-
- Cap,.,, = Pe' * Pe' . +FmV (7)
pVM num mips bw
Table 4. Symbols Description
cap
Then, Standard Deviation (SD )
SD ' = Л F~ LL ( PT — PT)1
N m ,=i
ii. Scheduling and Load Balancing Decision:-
standard deviation and limit value formerly determined on the basis of the load.
(8) iv. Task Scheduling:-
If the decision would be stable the load, the machine has to obtain the demand to each overloaded virtual machines. The strategy chooses the task with based on priority. In which lowest priority task selects firstly from an overloaded virtual machines and then rescheduled to an (9) under loaded virtual machines through optimum ability.
Calculated the Supply virtual machine:-
The scheduling and load balancing is performed only when calculate Standard Deviation value larger than threshold value. Basically threshold value is set 0-1 depend upon standard deviation compared.
-
iii. Virtual machine Grouping:-
- Virtual machines are arranging into 2 state of groups:- overloaded and under loaded condition. The virtual machines are assembled depending upon the
SupplyVM = LD - Cap
Again,
Calculated the Virtual machine demand by using the:-
DemandVM = LD – Cap
Pseudo code
-
1) Begin
-
2) for each task do
-
3) Determine load of virtual machine and choose balance the load or not.
-
4) Then grouping of the virtual machine based on OL and UL.
-
5) Get the way to obtain UL Virtual machine and need to OL VMs.
-
6) OL and UL VM sets are sort.
-
7) Based on the priority tasks in OL VMs are sort.
-
8) In the UL VMs set, find out the capacity.
-
9) For each task in each OL VM discovers an appropriate UL VMs predicated on capacity.
-
10) At last update the sets, OL and UL VM.
-
11) End of step 2.
-
12) End.
OL
Overloaded
UL
Under loaded
The specific contributions of this paper is organized as follows: a related work is given in Section 2; the gaps in existing work is discuss in detail in Section 3; a ABC and tabu search algorithm flow chart is presented in Section 4, describe the Simulation result and analysis in Section 5; and conclusion is explained in the last section.
-
II. Related Work
(Alla, Alla, & Ezzati, 2017) introduced an Analytic Hierarchy Process (AHP) based on Dynamic PriorityQueue (DPQ) algorithm and PSO algorithm. The proposed DPQ-PSO approach provides good performances such as make span, obtain higher resource utilization and also increased quality of service significantly. (Masdari, Salehi, Jalali, & Bidaki, 2016) discussed PSO-based scheduling approach in a on the basics of this algorithm that has been utilized in the
resource accessibility, scalability and decrease the functional costs of the datacenters. Furthermore, determine more sophisticated evaluation of the way PSO algorithm has been increased and integrated in each system to resolve the workflow/task scheduling issues. (Liu, Zhang, Li, & Niu, 2015) proposed the DeMS algorithm. DeMS include basically 3 algorithms: - The first On-Demand scheduling algorithm is planned to reduce the conversation overhead between a master and slaves. Second QTM is made to balance the workload. Third STM is performed to schedule the tasks related with each other. Experimental results determine our proposed On Demand scheduling approach may considerably decrease the response time of parallel jobs. (Masdari, ValiKardan, Shahi, & Azar, 2016) analyzed the workflow scheduling approach and their numerous parameters and qualities are examined like:- ET, CT,RT,DTT. (Awad, El-Hefnawy, & Abdel_kader, 2015) considered the LBMPSO. That applied to reduce cost, decrease total time and sending time to obtain load
balancing between tasks and virtual machine, and reduce the difficulty in cloud environment and improves the consistency of cloud computing and dividing tasks on to virtual machine compared to other approaches.(Dasgupta, Mandal, Dutta, Mandal, & Dam, 2013) proposed a Genetic Algorithm (GA). This technique reduce the make span of a certain tasks set using the Cloud Analyst simulator. (Effatparvar & Garshasbi, 2014) presented algorithms in parallel heterogeneous multi-processor system which raise system utilization and minimize total time taken. Basically, to analyzed an improved solution in parallel system by considering first come first out and processing time algorithm. (Jena, 2015) focused on task scheduling based algorithm to enhanced consumption rate and running time. Thus, multi-objective PSO algorithm, could successfully resources utilization and to decrease make-span. (Domanal, Reddy, & Damanal, 2014) designed an effective algorithm which handles the load by considering the existing status of all Virtual machines. In which, proposed algorithm and existing algorithm compared on the based on resources and eliminates the inefficient usage of those Virtual machines. (Snášel et al., 2016) modified the bee colony algorithm, to perform effective and efficient load balancing within cloud environment. It tries to reduce make-span as well as the number of virtual machine migrations. (Al-maamari & Omara, 2015) proposed DAPSO to make improvements in performance from these essential (PSO) particle swarm optimization algorithm to increase a task runtime by reducing makespan associated with a specific task set and exploiting resource utilization.
-
III. Gaps in Existing Work
As discussed by (Snášel et al., 2016), it is analyzed that the enhanced bee colony algorithm performs better as compared to other nature inspired algorithms. The reason for this is that particle swarm optimization is limited to initial set of particles where wrongly selected particles can provide bad result. And artificial bee colony algorithm shows globally a low converging rate but integrating both scheduling algorithms, provides possibility of further improvements. In this paper, tried to implement the integration of artificial bee colony and tabu search algorithms to enhance the quality of service metrics and also improve the energy consumption rate.
-
IV. Methodology
In this paper, hybrid ABC with tabu search technique. This proposes technique enhance the energy consumption rate. In which consider following steps:-
-
> An employed bee holds the details regarding food source and gives details with a specific neighborhood.
-
> Based upon makespan, each onlooker bees follow employed bees.
-
> Then discard unoccupied food source and finally find out the best solution.
-
> After finding the best solutions, again start iteration and apply tabu search algorithm.
-
> Using previous best solutions, tabu search conclude the final result and return final result.
The main reason to hybridization of ABC algorithm with tabu search, basically ABC algorithm is an decision maker they provide best solution but using best solutions tabu search return a final solution. The methodology followed for the implementation is given in fig.2.
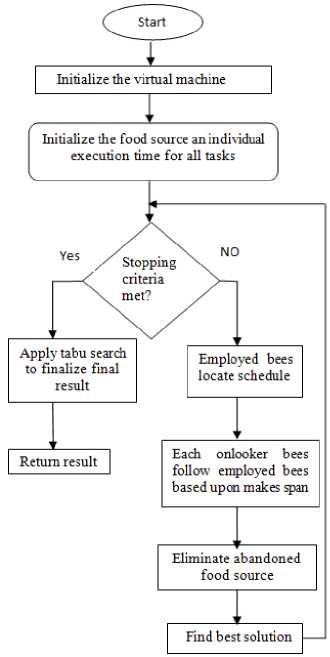
Fig.2. Flowchart of the propose technique
Pseudo code:-
Step 1: Bees_tabu_sol: - "get random bees/positions for i in range (be)
ty = ran. rant (O.LB)
tb. append^float^, floaty)) return tb
Step 2: Develop best_bees:- "makes a best_bees from randomly selected alleles." b^=[]
-
l .t = [i for t in range(sf. Zen)]
for i in range(sf. len)
ch = гап.сЬ(1д)
1st- re(ch)
return b-M
Step 3: rank_Scouts:-
Fl = M)
return pLp2
Step4: employed_bees (sf):- "swap two elements
Step 5: food_mtrix:- far i (at b^in enumerate (ty) for j (a2 b)tn enumerate (ty) tty d^ — a^ — g 2 > b ^ — o2 d' = sqrt (da* da + db* db) m' [t,/] = d'
return m'
Step 6: exploitation_phase (matrix, queue):- """ Returns the total length of the queue """ tl = 0
n-oe = len(que)
for i in range (n^)
; = (i + i)%nbe
S; = que[t]
Sj = que[fl tZ+= m[S[ ,Sj]
return (to/n-De ,0)
i»n

chd. append(cdf)
for i in range (0, nf d^f) tlsien = 0
else re turn rand. rant(sf. sz * sf. nfd3r\sf. sz — 1)
Step 10: evaluate metrics:- sp = sr It/mks, 2
77T = 1. 1 0 — int ,2
ut = (sqrt(srit/mks),2)
Eff = (srlt/mks, 2)
C0Tlengy = ((.mks) *Tx + engy * (t. tQ — int ,4))
Experimental setup:-
Various variables along with respected value or range are shown in the table below .These variable are required to successfully simulate the proposed technique.
Table 5. Nomenclature used
|
Symbol |
Meaning |
|
random.randint |
ran. rant |
|
tabu_bees.append |
tb. append |
|
tabu_bees |
th |
|
Lower bound , upper bound |
LB,UB |
|
best_bees |
Че |
|
self.length |
sf.len |
|
random. Choice |
ran. ch |
|
Choice |
ch |
|
best_bees.append |
bbe. append |
|
lst.remove |
1я.ге |
|
left, right |
lft, rgt |
|
self._bst_food |
sf._bstfd |
|
Food |
Fd |
|
self.best_bees |
sf.bstbe |
|
other.best_bees |
o. bstbe |
|
Temp |
T |
|
Matrix |
M |
|
square root |
Sqrt |
|
Distance |
D |
|
Total |
Tl |
|
Num_bees |
nbe |
|
Queue |
Que |
|
Slot |
S |
|
Size |
sz |
|
self.size |
sf. sz |
|
self.deadline |
sf.dd |
|
self._Stopping_criteria |
|
|
Maxgenerations |
mg |
|
newfood_Srcrate |
nfd^ |
|
rank_Scouts_rate |
ri^rt |
|
eigenvctr_rate |
evrt |
|
food_Src.objective_fn |
fd2rc.objfnQ |
|
self.minschedule_length |
sf.mslen |
|
sys.maxint |
sj^s. mt |
|
curschedule_length |
csdlen |
|
self.minfood_Src |
sf. mfdgrc |
|
Selectrank |
srk |
|
Selected |
Sel |
|
Parent |
Par |
|
Deadline |
Dl |
|
Child |
Cd |
|
Children |
Chd |
|
randschedule_length |
™ton |
|
addschedule_length |
adsien |
|
employed_bees |
empbe |
|
Choosebest |
Chbst |
|
Sort |
So |
|
Speedup |
Sp |
|
Serial time |
Srlt |
|
Total time taken |
TTT |
|
Initial time |
™t |
|
Time |
T |
|
Utilization |
Ut |
|
Efficiency |
Eff |
|
Consumed energy |
conEna. |
Table 6. Experiment setup
|
Variable |
Value/Range |
|
Tx |
0.078 |
|
UB |
1000 |
|
LB |
200 |
|
Len |
30 |
|
Size |
100 |
|
mg\ nfd^.,r^rt \ №Tt |
170\0.9,0.6\0.8 |
|
Chbst |
0.9 |
-
V. Simulation Result and Analysis
-
A. Makespan
The total period of time required to finish a several tasks is called makespan. Minimizing makespan reduces the performance time.
Makespan = Max ( SL )
Where i = 1to no. of processor SL = schedule length
The above result shows that the proposed algorithm decrease the makespan as compared to the existing algorithm.
Table 7. Makespan
|
Iterations |
Existing |
proposed |
|
1 |
212 |
184 |
|
2 |
231 |
192 |
|
3 |
200 |
188 |
|
4 |
229 |
186 |
|
5 |
208 |
199 |
|
6 |
220 |
197 |
|
7 |
223 |
195 |
|
8 |
230 |
198 |
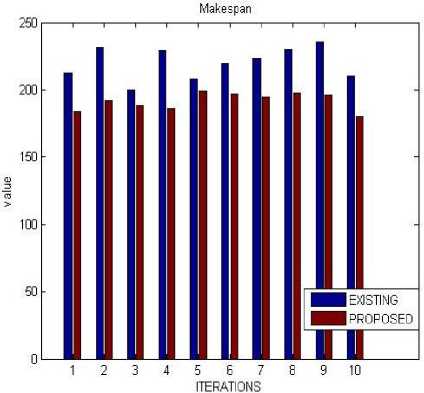
Fig.3. Makespan
-
B. Speed up
Speedup is an activity for raising the performance between two systems processing the same problem.
speedup = — mk
Where st = serial time mt = Makespan
In this table, shows that the proposed technique increases the speed as compared to existing technique.
Table 8. Speedup
|
Iterations |
Existing |
proposed |
|
1 |
0.94 |
1.04 |
|
2 |
0.86 |
0.98 |
|
3 |
0.83 |
1.01 |
|
4 |
0.87 |
1.06 |
|
5 |
0.86 |
1.08 |
|
6 |
0.83 |
0.99 |
|
7 |
0.85 |
1.03 |
|
8 |
0.80 |
1.01 |
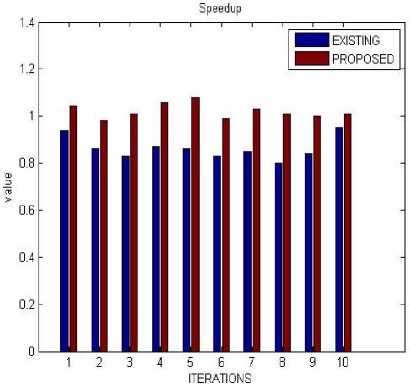
Fig.4. Speedup
-
C. Total time taken
The total time required for start to finish an entire tasks.
ttt = f -1,
Where
Ft = finishing time
It = Initial time
In this experiment shows that the less time taken requires to complete the task as compare to existing technique.
Table 9. Total Time Taken
|
Iterations |
Existing |
Proposed |
|
1 |
5.21 |
4.54 |
|
2 |
5.27 |
4.32 |
|
3 |
5.70 |
5.10 |
|
4 |
5.32 |
4.41 |
|
5 |
5.35 |
4.27 |
|
6 |
5.12 |
4.11 |
|
7 |
5.26 |
5.04 |
|
8 |
5.65 |
4.57 |
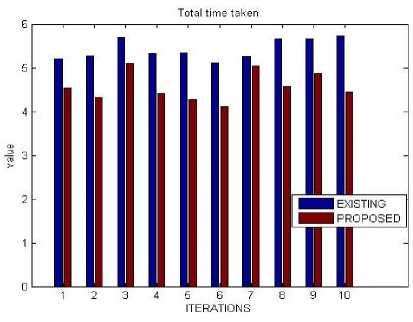
Fig.5. Total Time Taken
D. Utilization
Utilization is an action which gives the detail regarding effective use of resources.
Utilization =
serial time makespan
In this table shows that the utilization improves as compare to existing technique.
Table 10. Utilization
|
Iterations |
Existing |
Proposed |
|
1 |
0.55 |
0.61 |
|
2 |
0.50 |
0.58 |
|
3 |
0.49 |
0.59 |
|
4 |
0.51 |
0.63 |
|
5 |
0.54 |
0.63 |
|
6 |
0.50 |
0.58 |
|
7 |
0.50 |
0.6 |
|
8 |
0.59 |
0.65 |
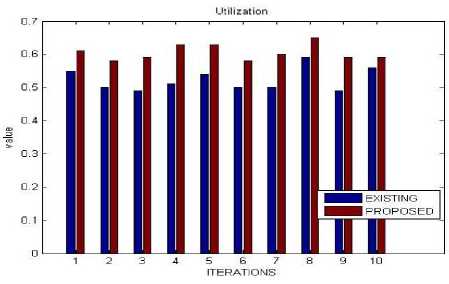
Fig.6. Utilization
several tasks.
Energy consumption = mk * Tx + F, * It
Where mk = Makespan
Ft = finishing time
I = Initial time
Tx = Transformed energy
In this table shows that the less energy consumes as compare to existing technique.
-
E. Efficiency
Efficiency is a measurable parameter, which reduce the amount of energy required to entire system.
Sp
Efficiency =--- Nop
Where
Sp = Speedup
Nop = no of processor
In this experiment shows that the efficiency increases as compare to existing technique.
Table 11. Efficiency
|
Iterations |
Existing |
Proposed |
|
1 |
0.31 |
0.34 |
|
2 |
0.28 |
0.33 |
|
3 |
0.27 |
0.32 |
|
4 |
0.29 |
0.33 |
|
5 |
0.25 |
0.30 |
|
6 |
0.27 |
0.31 |
|
7 |
0.28 |
0.30 |
|
8 |
0.29 |
0.33 |
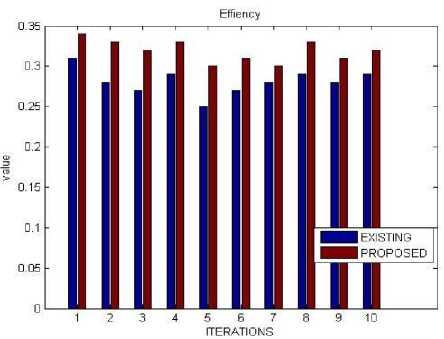
Fig.7. Efficiency
-
F. Consumed energy
The amount of energy or power used to complete the
Table 12. Consumed Energy
|
Iterations |
Existing |
proposed |
|
1 |
20.21 |
18.19 |
|
2 |
20.24 |
18.97 |
|
3 |
21.14 |
18.62 |
|
4 |
21.61 |
17.79 |
|
5 |
20.09 |
17.32 |
|
6 |
21.06 |
18.66 |
|
7 |
21.88 |
18.01 |
|
8 |
21.20 |
17.27 |
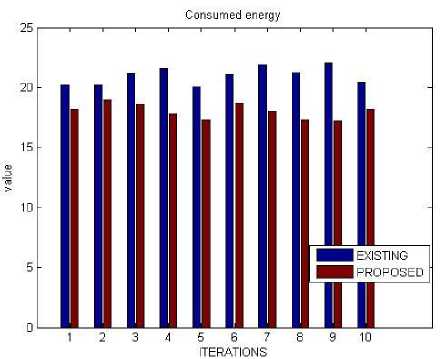
Fig.8. Consumed Energy
-
VI. Conclusions and Future Work
0.858, utilization is 1.15, efficiency is 0.038 and energy consumed is 2.97.
This paper proposes a hybrid ABC and tabu search scheduling algorithm for cloud environment. As a decision maker ABC is used in different areas and it takes the correct decision using the tabu search. So this technique designed and implemented it applying cloud simulator tool with help of CloudSim using python language, which goal to balance the load of virtual machines. The comparison has been drawn with the existing and proposed technique using parameters: - speedup, utilization, total time taken, efficiency, energy consumption and makespan. The experimental result has shown that it increases the convergence rate. So that the improvement between results clearly shown as the speedup is 0.158, total time taken is
This work has not focused on fault tolerance therefore in near future we will proposed fault aware meta-heuristic scheduling technique which initially monitor active nodes then try to schedule available jobs on available servers only. In case any failures of server exit during runtime then propose technique can move the jobs running or waiting on that severs to others.
References Hybrid artificial bee colony and tabu search based power aware scheduling for cloud computing
- Ajit, M., and G. Vidya, “VM level load balancing in cloud environment,” Computing, Communications and Networking Technologies (ICCCNT), 2013 Fourth International Conference on. IEEE, 2013.
- Al-maamari, Ali, and Fatma A. Omara, “Task scheduling using PSO algorithm in cloud computing environments,” International Journal of Grid and Distributed Computing, vol: 8, issue: 5, pp: 245-256, 2015.
- Awad, A. I., N. A. El-Hefnawy, and H. M. Abdel_kader, “Enhanced particle swarm optimization for task scheduling in cloud computing environments,” International Conference on Communication, Management and Information Technology, vol: 65, pp: 920-929,2015.
- Babu, K. R., P. Mathiyalagan, and S. N. Sivanandam, “Pareto based hybrid Meta heuristic ABC–ACO approach for task scheduling in computational grids,” International Journal of Hybrid Intelligent Systems, vol: 11, issue: 4, pp:241-255, 2014.
- Dasgupta, Kousik, et al, “A genetic algorithm based load balancing strategy for cloud computing,” International Conference on Computational Intelligence: Modeling Techniques and Applications (CIMTA), vol: 10, pp: 340-347, 2013.
- Domanal, Shridhar G., and G. Ram Mohana Reddy, “Optimal load balancing in cloud computing by efficient utilization of virtual machines,” Communication Systems and Networks (COMSNETS), Sixth International Conference on. IEEE, 201).
- Effatparvar, M., and M. S. Garshasbi, “A genetic algorithm for static load balancing in parallel heterogeneous systems,” International Conference on Innovation, Management and Technology Research, pp: 358-364, 2014.
- Ge, Fatemeh Rastkhadiv and Kamran Zamanifar, “A Task Scheduling Algorithm Based on Load Balancing in Cloud Computing,” International Journal of Advanced Biotechnology and Research, Vol: 7, Issue: 5, pp: 1058-1069,2016.
- Jena, R. K, “Multi objective task scheduling in cloud environment using nested PSO framework,” Procedia Computer Science 57, pp: 1219-1227, (2015).
- Karaboga, Dervis, and Bahriye Akay, “A comparative study of artificial bee colony algorithm,” Applied mathematics and computation, vol: 214, issue: 1, pp: 108-132, 2009.
- Karaboga, Dervis, and Bahriye Basturk, “A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm,” Journal of global optimization, vol: 39, issue: 3, pp: 459-471, 2007.
- K.R. Remesh Babu and Philip Samue, “Enhanced Bee Colony Algorithm for Efficient Load Balancing and Scheduling in Cloud,” Innovations in Bio-Inspired Computing and Applications. Springer International Publishing, pp.:67-78, 2016.
- LD, Dhinesh Babu, and P. Venkata Krishna, “Honey bee behavior inspired load balancing of tasks in cloud computing environments,” Applied Soft Computing, vol: 13, issue:5, pp: 2292-2303, 2013.
- Liu, Yu, et al, “DeMS: a hybrid Alla, Hicham Ben, et al, “An Efficient Dynamic Priority-Queue Algorithm Based on AHP and PSO for Task Scheduling in Cloud Computing,” Springer International Publishing AG International Conference on Hybrid Intelligent Systems Springer, Cham, pp: 134-143, 2016.
- Masdari, Mohammad, et al, “A Survey of PSO-Based Scheduling Algorithms in Cloud Computing,” Journal of Network and Systems Management, pp: 1-37, 2016.
- Masdari, Mohammad, et al, “Towards workflow scheduling in cloud computing: A comprehensive analysis,” Journal of Network and Computer Applications, vol: 66, pp: 64-82, 2016.
- Science, C, & Engineering, S, “Differential Evolution Based Optimal Task Scheduling in Cloud Computing,” International Journal of Advanced Research in Computer Science and Software Engineering, vol: 6, issue: 6, pp:340–347, 2016.
- Shaw, Subhadra Bose, and A. K. Singh, “A survey on scheduling and load balancing techniques in cloud computing environment,” Computer and Communication Technology (ICCCT), 2014 International Conference on. IEEE, pp: 87-95, 2014.
- Zuo, Xingquan, Guoxiang Zhang, and Wei Tan, “Self-adaptive learning PSO-based deadline constrained task scheduling for hybrid IaaS cloud,” IEEE Transactions on Automation Science and Engineering, vol: 11, issue: 2, pp: 564-573, 2014.
