Identifying Dark Web Hidden Services with Novel Image Classes Using CNN and Quantum Transfer Learning

Author: Ashwini Dalvi, Soham Bhoir, Akansha Singh, Irfan Siddavatam, Sunil Bhirud
Journal: International Journal of Education and Management Engineering @ijeme
Article in issue: 2 vol.15, 2025.
Free access
The dark web is an overwhelming and mysterious place that comprises hidden services. Dark web hidden services contain illegal or offensive content. Hidden services are not accessible through regular search engines or browsers and can only be accessed via specific software. The proposed work aims to identify these hidden services by analyzing their associated images and text data. Doing so, one can better understand the types of activities on the dark web and what kind of content is available. First, a dark web crawler is developed to collect dark web services. Images are then manually classified into four categories: Cards, Devices, Hackers, and Money. Next, preprocessing the collected dataset removed irrelevant images, and a Convolutional Neural Network (CNN) was trained to identify new dark web image classes. Finally, quantum Transfer Learning (QTL) improved the model’s performance. The proposed work goes beyond conventional methods of categorizing datasets by including new categories of image classes of dark web hidden services that have not been considered before. Also, the work examines image data and related text to establish a strong correlation between them. The proposed approach will provide insights into the dark web hidden service by confirming the relationship between the image and text data of the respective hidden-services.
Dark Web, Image classification, CNN Model, Quantum Transfer Learning, TF-IDF
Short address: https://sciup.org/15019856
IDR: 15019856 | DOI: 10.5815/ijeme.2025.02.05
Text of the scientific article Identifying Dark Web Hidden Services with Novel Image Classes Using CNN and Quantum Transfer Learning
An onion service, a hidden service, is a website hosted on the Tor dark web. Hidden services have the advantage of hiding their IP addresses from the outside world, making tracking them difficult. In addition, the Tor network provides hidden services instead of a traditional domain name. Therefore, hidden services are only accessible through the
Tor network using .onion domain names. A .onion domain uses a pseudo-top-level domain, not a top-level domain like .com or .org. Hidden services are typically accessible by knowing their onion domain names (URLs), which comprise 16 random characters. Upon entering the .onion domain name, a request is encrypted and routed through the Tor network relays until it reaches the server.
Since traffic to and from the hidden site is encrypted and routed through the Tor network, locating the server hosting the site or identifying its owner is challenging [26]. Encrypted and anonymous communication on the dark web makes it an ideal platform for people who want to remain anonymous while browsing the web. However, the dark web is infamous as an online platform notorious for committing illicit activities such as selling drugs, firearms, and child sexual abuse material (CSAM) [22, 7]. It also serves as a platform for cybercriminals to conduct their activities [20]. For extremist groups, the dark web provides a platform for communication, coordination, and recruitment [33]. Several of these activities may significantly threaten public safety and national security.
With the increasing growth of dark web data, it is becoming increasingly important to classify it to make it more useful and understandable for humans and machines. However, searching thousands of dark web services for their sensitive nature would take extensive time and resources. Artificial Intelligence (AI) and Machine learning (ML) algorithms can be used to analyze large amounts of data on the dark web to identify patterns and potentially detect criminal activity [27]. Through deep learning, algorithms can be used to uncover hidden services and activities that are taking place on the Tor network. By analyzing these data points, law enforcement agencies can gain helpful insights and take necessary action against criminals in this space.
Thus, automatically identifying and classifying dark web services based on their images and content allows researchers and law and enforcement agencies (LEAs) to identify and track the potentially illegal activity on the dark web. Unfortunately, quality data for dark web data classification with ML algorithms are lacking. Also, data on the dark web is often incomplete and unreliable because of the difficulty of accessing hidden services. For example, in most studies of the Tor dark web, websites were manually categorized, and then automated crawlers were trained using those categories. However, this method cannot accomplish law enforcement tasks that require specific categories [8]. On the other hand, studies on illegal online activity tend to focus on specific types of crimes like terrorism.
Further, several research studies analyzed dark web services with text classification approaches with customized data sets. For example, for dark web illicit activities classification, machine learning algorithms were trained using laws and regulations related to various types of illegal activity [18]. The dark web crawler Crawlbot’s ANN-based classifier was trained with Pornography Text Dataset to improve accuracy and efficiency in detecting pornographic content on the dark web [30]. However, over 75% of dark market listings contain image data, highlighting the significance of considering image data for analysis [19].
Identifying illegal or illicit activities such as illicit drug selling, child pornography, or other criminal activity would be efficient by observing the visual content of a hidden service. Accordingly, some studies analyzed dark web image content. For example, the TOR Image Categories (TOIC) dataset with five illegal classes was presented and categorized using the Bag of Visual Words model, merging Edge-SIFT and dense SIFT features [14]. However, most are restricted to specific domains, such as child abuse or weapons, leaving out images associated with other categories.
Most automated techniques with natural language processing (NLP) and text analysis analyze and process textual data. However, these techniques do not enable the analysis of non-textual objects, such as images, videos, or audio recordings, as effectively as they do for textual objects. However, computer vision, which develops algorithms and techniques to analyze and interpret visual data, such as images and videos, has progressed. Integrating computer vision and natural language processing techniques will enable a more comprehensive multimedia data analysis.
In the presented study, authors proposed using image data to label dark web services. This research aims to determine hidden services by analyzing their images by correlating textual data of respective hidden services. The contributions of the proposed research are as follows:
• Identifying four new image classes of hidden services - Card, Device, Hacker, and Money As a result of this contribution, these four image classes have been identified and labeled, which can be used as training data for image classification algorithms.
• Extending the concept of transfer learning to hybrid classical-quantum neural networks for image classification. The proposed hybrid model used transfer learning techniques to learn classical and quantum neural networks to outperform better than traditional CNN.
• Confirming the correlation between textual data and image data of a particular hidden service Using textual and image data together allowed authors to confirm gathered insights into hidden service. In addition, the authors hypothesized that new insights and discoveries might emerge that would not otherwise be possible by analyzing text and image data types.
2. Review of Previous Studies
The paper is organized as follows: Section 2 reviews the existing literature on the topic, highlighting the contributions and limitations of previous studies. Section 3 presents the methodology, including image classification using the CNN model, quantum transfer learning models, and text feature engineering approaches. Section 4 provides the results and discussion. Section 5 outlines the limitations of the current approach. Finally, Section 6 concludes the paper and suggests directions for future research.
Dark Web sites are secret parts of the internet that are not indexed by search engines and are available only through specialized software or configurations. Hackers and cybercriminals often use the platform to sell stolen data, traffic drugs, and engage in other illegal activities. Dark web content is analyzed by researchers for Cyber Threat Intelligence (CTI) in order to identify these illegal activities [3]. In addition to manual analysis, automated tools can identify patterns and anomalies in the data using machine learning and natural language processing algorithms. The dark web has been scraped and mined for threat intelligence purposes using web scraping and data mining techniques.
The data repositories and crawling are preferred techniques to collect dark web hidden services for labeling and classification. For example, researchers created a dataset containing Darknet domain names referred to as “Darknet Use Text Addresses (DUTA)” [2]. The text data was classified using three different classifiers (SVM, LR, and NB) and two text rep- resentation methods (TF-IDF and BOW). The tool BlackWidow collects HTML-based forum data to extract unstructured dark web data [28]. The BlackWidow tool collected and analyzed large amounts of unstructured dark web data. A study of seven popular Deep and Dark Web services was conducted in three different languages with the help of BlackWidow.
Researchers discussed methods to label dark web services. Researchers extended the scope of content labeling of hidden services with a keyword extraction method where relevant keywords were extracted from hidden service content [9]. In addition, the graph degeneracy method was applied to identify their most significant ones. To overcome the limitation of the requirement of labeled content to identify and characterize the dark web, which is often expensive and difficult to obtain, researchers proposed an unsupervised model for identifying and describing dark web forums combining clustering and decision tree algorithms [25].
Table 1. Dark Web Hidden Service Identification with Images
|
Sr No. |
Referred Dataset |
Contribution |
Limitations of the study |
|
1 |
Darknet Market Archives 20132015 (dnmarchives) [19, 6] |
The research focused on the effectiveness of using image hashing for identify- ing similar images between dark marketplaces for ven- dor identification |
The scope of research is limited to vendor profiling |
|
2 |
Authors crawled the dark web to create TOIC (TOr Image Categories) [14] |
The research classified images into the following classes:
|
Requirement of improvement in the efficiency of Compass Radius Estimation for Image Classification (CREIC) algorithm closer to the Ideal Radius Selection algorithm |
|
3 |
TOIC (TOr Image Cate gories) [13] |
Classification of images with SAKF - Semantic Attention Keypoint Filtering algorithm to detect foreground objects of interest |
The images extracted from the dark web do not always show an ob- ject of interest in the ideal situation (without blur or similar distorting effects in images) for the proposed method. |
|
4 |
TOIC (TOr Image Categories) and other public datasets* [12] |
On a custom dataset, CNN features MobileNet v1, Resnet50, and BoVW utilizing dense SIFT descriptors compared against SAKF. SAKF outperformed alter- native approaches. |
Seeking foreground objects with the removal of background noise could be challenging in dark web crawled images |
|
5 |
DUSI (Darknet Usage Ser- vice Images) [4] |
Perceptual hashing (pHash) and Bag of Visual Words have been used to recognize the service domains on TOR dark net. The research clas- sified images into the fol- lowing classes:
|
There was no mention of text data correlation with images. The dataset used is not available pub- licly. |
|
6 |
circl-ail-dataset-01 [24] |
Analyzing data is divided into two modalities. First, using Convolutional Neural Networks (CNN) to process image-based data and incorporate Grad-CAM to ex- plain the findings. The sec- ond modality analyzed text- based. |
Work done on the existing data set. |
Text-based data scraped from the dark web has been used for most related work. However, artifacts from the dark web that rely on images rather than text have not fully been considered in studies on hidden services. In addition, the dark web could be better monitored and prosecuted if law enforcement agencies also analyzed image artifacts. For example, the study suggested that analyzing product photos can help connect multiple accounts of the same darknet vendor [34]. Also, researchers employed image processing techniques to automate systems to recognize and decipher the characters in the CAPTCHA image to enter the dark web marketplace [35].
Researchers used image classification to identify violent extremist organizations that post real-time visual propaganda on social networks [16]. Video or image propaganda promoting violent extremism was to be identified using surveillance techniques to monitor online activity.
For Tor dark web image research, researchers introduced DUSI-2K, a dataset including 2500 snapshots of Tor domains [5]. The dataset is divided into illicit services and not illicit services images. Furthermore, researchers introduced a robust image hashing scheme called F-DNS to classify Tor domains. Perceptual Hashing did not require training in the model; thus, the time investment is less than Bag of Visual Word (BOVW). Also, Perceptual Hashing provided higher accuracy than BOVW for the given dataset.
Table I offers summarized findings of dark web hidden service identification with images.
The analysis of dark web image data has become an increasingly important area of research in recent years. However, from related work, it is reflected that several gaps in the existing literature still need to be addressed. The authors highlight some of the key gaps in the literature related to the analysis of dark web image data.
-
• Limited scope : Most existing methods and techniques that consider analyzing dark web image data are focused on a particular domain, such as Child Sex Abuse (CSA) or Weapons. This limited scope means that much dark web image data related to other categories is left out.
-
• Incomplete coverage : Even when some research considers content from more than one class, the focus is often on some specific classes, leaving other classes out of consideration. For instance, TOR Image Categories (TOIC) and Darknet Usage Service Images (DUSI) consider some categories while leaving others out.
-
• Lack of publicly available data : The datasets used in these research are not public, which limits the
ability of other researchers to build upon previous work. This lack of publicly available data is a significant barrier to developing more comprehensive and inclusive approaches to analyzing dark web image data.
• Lack of correlation analysis: The analysis of text data related to respective image data to confirm the
3. Proposed Method3.1. Dataset Overview
correlation is not much done. This correlation between text and Image data can help accurately identify the type of hidden service. However, this lack of correlation analysis can limit the ability to identify the type of hidden service accurately.
To address the gaps in the existing literature related to the analysis of dark web image data, the authors propose a methodology that involves a combination of techniques. This methodology includes dataset preparation, training the CNN model, and applying quantum transfer learning. Further, Tf-Idf is applied to confirm the type of hidden services identified with the image label. First, the authors labeled image classes using the CNN model. Then they leveraged the work of the CNN model using quantum transfer learning to improve accuracy and enable the analysis of previously unexplored dark web image data classes. Finally, after quantum transfer learning, the authors label classes of the textual data using Tf-Idf to confirm the image classification model’s accuracy further. The following subsections detail each step of the proposed methodology.
The dataset is created by combining images from two sources.
Source 1: Custom crawled hidden service dataset: The dataset for the research consists of a set of crawled hidden services. The designed crawler collected different hidden Services [10]. The dataset had 50000 dark web hidden service pages weighing 12.2 GB. Each collected hidden service had a folder comprising several HTML, CSS, JavaScript, Image, and other files. Figure 1 depicts file types of crawled hidden service.
Dataset cleaning was performed in preparation for analysis. First, the hidden services folders containing images were separated from the rest of the dataset in data set creation. Image files could be identified by analyzing the file paths. Further, it was necessary to fetch images from hidden services folders once those folders were identified. Therefore, python libraries were used to separate hidden services folders with images from the dataset. The dataset contains 2884 images after the image filtering process.
The next step involved removing any irrelevant images after fetching the images. For example, there were duplicates, images of poor quality, or images irrelevant to the analysis. Manual inspection by human experts conducted the image exclusion. As a result, 76 images were rejected from the dataset as deemed irrelevant. As a result, the refined dataset contained 2808 images relevant for analysis. Still, not all images belonged to categories useful for dark web service labeling. For example, images with the ‘Food’ label were irrelevant for dark web service classification. Thus, four classes were identified to label dark web services: Cards, Devices, Hackers, and Money.
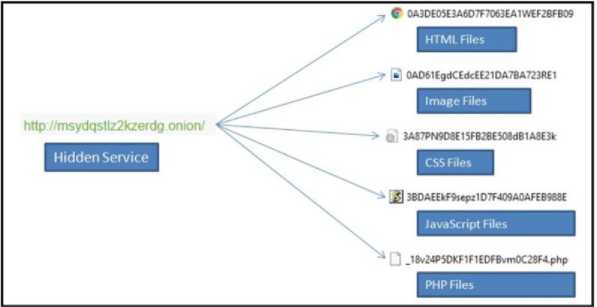
Fig. 1. Overview of crawled hidden service
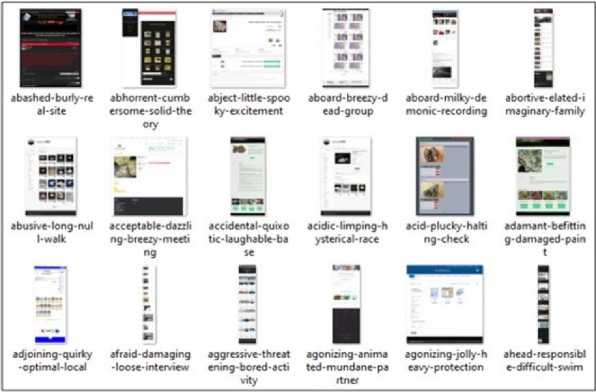
Fig. 2. CIRCL (Computer Incident Response Center Luxembourg) data source [10]
The dataset size of images belonging to the mentioned classes in crawled dark web services was 1090. The dataset size attempted to be further enhanced with an existing dataset of dark web snapshots.
Source 2: Dark Web Snapshots: CIRCL(Computer Incident Response Center Luxembourg)[1] is an open-source dataset comprising 8000 dark web hidden services snapshots, as in figure 2. To add images to the crawled hidden services dataset, images in dataset CIRCL were selected, mapping to Card, Device, Hacker, and Money classes. The newly created image dataset was named “Darkset”. Darkset has manually labeled 1650+ dark web images into four categories: Card, Device, Hacker, and Money.
The number of images per class is shown in Table 2.
Table 2. Number of Images per Class
|
Sr no. |
Class Name |
Number of images |
|
1 |
Card |
303 |
|
2 |
Device |
958 |
|
3 |
Hacker |
143 |
|
4 |
Money |
295 |
-
3.2. Creating CNN Model
The authors used the Darkset dataset to train the CNN for the next step of the proposed methodology. The CNN model is designed as a sequential model that starts with a re-scale layer to standardize the input images. Re-scale layer enhances the image data and makes it more suitable for further processing. Next, four convolution layers follow the rescale layer with an activation function called ReLU to help the model learn more complex representations of the input data.
Each convolution layer is followed by a max-pooling layer, which reduces the output data’s spatial dimensions and helps improve the model’s efficiency. After the convolution and pooling layers, a flatten layer converts the output data into a one-dimensional vector. Next, this vector is fed into dense, fully connected layers that perform nonlinear transformations on the input data. The last dense layer has classes equal to four, corresponding to the number of image categories in the dataset.
For the compilation of the model, the authors used the Adam optimizer. Adam is a gradient-based optimization algorithm that is used to update the parameters of the model during training. It combines the best features of two other optimization algorithms, stochastic gradient descent (SGD) and Adagrad, to provide better performance and faster convergence. The authors trained the model for a total of 30 epochs. An epoch is defined as one complete pass through the entire training dataset. Using multiple epochs, the model can learn more complex patterns in the data and improve its accuracy over time. The implemented algorithm to label the hidden service with is represented below as algorithm 1.
Algorithm 1 Image Class Prediction with CNN
Require: Input image x
Ensure: Output class probabilities y
-
1: Rescale x
layer
-
2: Conv2D(32, (3,3), activation=’relu’)
layer 1
-
3: MaxPooling2D((2,2))
layer 1
-
4: Conv2D(64, (3,3), activation=’relu’)
layer 2
-
5: MaxPooling2D((2,2))
layer 2
-
6: Conv2D(128, (3,3), activation=’relu’)
layer 3
-
7: MaxPooling2D((2,2))
layer 3
-
8: Conv2D(256, (3,3), activation=’relu’)
layer 4
-
9: MaxPooling2D((2,2))
layer 4
-
10: Flatten()
layer
-
11: Dense(128, activation=‘relu’)
layer 1
-
12: Dense(64, activation=‘relu’)
layer 2
-
13: Dense(4, activation=‘softmax’)
classes = 4 14: Compile(loss=‘categoricalCrossentropy’, optimizer=‘adam’) optimizer 15: Fit(x, y, epochs=30)
epochs
-
16: y ← Predict(x)
probabilities
-
17: return y
▷ Rescale
▷ Convolution
▷ Max-pooling
▷ Convolution
▷ Max-pooling
▷ Convolution
▷ Max-pooling
▷ Convolution
▷ Max-pooling
▷ Flatten
▷ Dense
▷ Dense
▷ Dense layer with number of
▷ Compilation with adam
▷ Training for 30
▷ Prediction of output class
-
3.3. Evaluating the performance of the CNN model
-
3.4. Quantum Transfer Learning
During the training process, training and validation datasets were used. Validation datasets were used to evaluate the model’s performance during training, and training datasets were used to train the model. The proposed approach used a ratio of 80:20 for the training and validation dataset to prevent over-fitting by optimizing the model’s performance.
In this section, the authors discuss the accuracy and loss graphs to evaluate the CNN model, as shown in 3 and 4. The results showed that the CNN model could accurately classify images from the dark web dataset into their respective categories. Furthermore, the combination of convolutional, pooling, and dense layers in the model allowed it to learn complex representations of the input data and achieve high accuracy. To enhance the CNN model for images with multiple objects or regions of interest and images with occlusions or missing information, the authors propose leveraging quantum transfer learning methodology, which is discussed in the following section.
The authors propose a novel approach to extend the concept of transfer learning to hybrid classical-quantum neural networks to enhance the CNN model for image classification. The proposed methodology builds upon the general structure of transfer learning but with a crucial difference of using a quantum circuit to perform the final classification task. Figure 5 depicts the flow of quantum transfer learning. The following subsection presents a discussion on transfer learning.
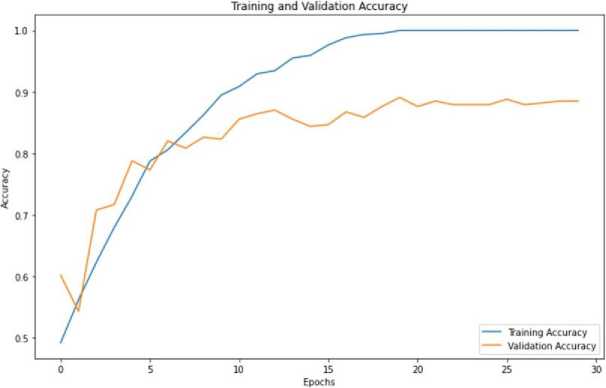
Fig. 3. Accuracy graph for training and validation set given to CNN model
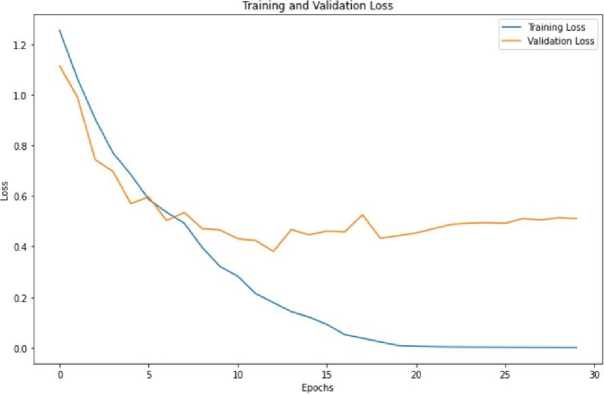
Fig. 4. Loss graph for training and validation set given to CNN model

Fig. 5. Flow of quantum transfer learning
-
3.4.1 Selection of Pre-trained network
-
3.4.2 Defining the structure of the variational quantum circuit
The authors utilized the ResNet18 architecture as the pre-trained network due to its exceptional performance in various computer vision tasks, including object recognition, detection, and segmentation. ResNet18 is a deep residual network introduced in [17]. The ResNet18 architecture has 18 layers and is smaller than other state-of-the-art deep learning models, making it computationally efficient. In addition, its ability to extract high-level features from the input images makes it an ideal choice for the transfer learning task.
Variational quantum circuits have been suggested as a potential quantum generalization of feedforward neural networks [11, 21, 23, 15, 29, 31, 32]. Like the classical case, a quantum layer can be defined as a unitary operation that acts on the input state of nq quantum subsystems and generates the output state. A low-depth variational circuit can physically realize this quantum layer.
Z: |x) ^y = U(w) |x)
The array of classical variational parameters is denoted by w. The array of classical variational parameters is denoted by w. Quantum layers can take on various forms, such as a sequence of single-qubit rotations followed by a fixed sequence of entangling gates [31, 32], or a combination of active and passive Gaussian operations followed by single-mode non-Gaussian gates for optical modes [21]. It’s important to note that, unlike classical layers, quantum layers maintain the Hilbert-space dimension of the input states. This is a result of the fundamental unitary nature of quantum mechanics, and should be considered when designing quantum networks.
To incorporate classical data into a quantum network, it is necessary to encode a real vector x into a quantum state represented as x.
A variational embedding layer can also be utilized for this purpose, which relies on x and is applied to a reference state like the vacuum or ground state.
ξ: | X 〉 ⟶ X = ( X ) |0〉 (2)
The embedding layer E is a map from a classical vector space to a quantum Hilbert space. The following paragraph discusses the layers used to create the variational quantum circuits.
M | X 〉 ⟶〈 X | { У } | х 〉 (3)
Embedding Layer : The first step in a quantum algorithm is the embedding layer. At this stage, all qubits are initially prepared in a state of balanced superposition between the up and down states. This allows the qubits to be manipulated in a way that can represent and process the input data. Following initialization, the qubits are rotated based on the input parameters using a local embedding technique. This process is critical for the success of the quantum machine learning algorithm as it allows the input data to be encoded into the state of the qubits.
Variational Layers : After the embedding layer, a sequence of variational layers is applied in a quantum algorithm. The variational layers consist of trainable rotation and constant entangling layers, enabling the quantum computer to compute the encoded data. The rotation layers modify the state of the qubits to solve the problem at hand, while the entangling layers enable the qubits to become correlated.
Measurement Layer : The final step in a quantum algorithm is the measurement layer. At this stage, the local expectation value of the Z operator is measured for each qubit. The Z operator measures the spin of a qubit in the zdirection. This measurement produces a classical output vector, which can be further processed to obtain the final result. The output vector is suitable for additional post-processing, such as classical optimization techniques or machine learning algorithms. This measurement step is critical as it enables the quantum computer to output a result that can be compared to the expected output of the problem.
In general, the complete quantum network, which involves both the initial embedding layer and the final measurement, can be expressed as:
Q = ∘ Q ∘ ε (4)
Algorithm 2 provides the algorithm to define the quantum layers.
Algorithm 2 Defining quantum layers in quantum circuit
1: function HLAYER(nqubits) ▷ Layer of single-qubit Hadamard gates 2: for idx ← 0 to nqubits - 1 do 3: qml.Hadamard(wires = idx) 4: end for5: end function 6: function Ry Layer(w) ▷ Layer of parametrized rotations around the y-axis 7. for IDX ← 0 TO length(w) - 1 do 8: qml.RY (w[idx], wires = idx) 9: end for10: end function 11: function EntanglingLayer(nqubits) ▷ Layer of CNOTs followed by another shifted layer of CNOT ▷ Loop over even indices: i = 0, 2, ..., nqubits - 2 ▷ Loop over odd indices: i = 1, 3, ..., nqubits - 3 12: for i ← 0 to nqubits - 2 by 2 DO 13: qml.CNOT (wires = [i, i + 1]) 14: end for 15: for i ← 1 to nqubits - 2 by 2 DO 16: qml.CNOT (wires = [i, i + 1]) 17: end for 18: end function
Fig. 6. Six variational layers quantum circuit
The authors used the quantum layers to design a custom quantum network for image classification tasks by replacing the fully connected final layer of the ResNet18 pre-trained model with a 4-qubit quantum layer. The quantum layer takes 512 features as input and performs the classification task, outputting four features. The quantum network consists of a classical preprocessing layer, a classical activation function, a constant scaling, the quantum circuit, and a classical postprocessing layer. The quantum circuit has a depth of 6 variational layers and was evaluated using both local simulation using intel i7 11th generation processor and NVIDIA RTX 3050 Ti and on IBM quantum computer with 1024 shots per epoch. The circuit outputs the Pauli Z expectation values. Figure 6 represents the four qubit circuits and six variational layers used.
The quantum net defining algorithm as defined in algorithm 3, describes the formulation of 6 layers variational circuit.
The authors further discuss designing dressed quantum net using variational circuits.
-
3.4.3 Dressed quantum net for image classification
In this section, the authors present their custom quantum network for dark web image classification, which utilizes transfer learning to leverage the benefits of both classical and quantum computing. To enable transfer learning across the classical-quantum interface, it is necessary to establish a connection between classical neural networks and quantum variational circuits. Given that classical and quantum networks may vary significantly in size, a more flexible quantum circuit model is preferable. Specifically, we consider a variational circuit based on nq subsystems, as defined in Equation
-
(4) . To incorporate basic pre-processing and post-processing of the input and output data, a classical layer is introduced at the outset and culmination of the quantum network. This arrangement yields a dressed quantum circuit, which offers enhanced versatility and adaptability for transfer learning purposes.
Algorithm 3 Defining quantum net
-
1: function QuantumNet(input_features, qWeights)
▷ Layer of single-qubit Hadamard gates
-
2: Reshape weights
-
3: qWeights ← qWeightsFlat.reshape(qDepth,nqqubits)
-
4: Start from state | +) , unbaised w.r.t 10) and 11)
-
5: call function HLAYER(nqqubits)
-
6: call function Ry Layer(input_features) ▷ Embed features in quantum node
-
7: for k ← 0 TO qDepth - 1 do ▷ Entangling layer (nqubits)
-
8: call function R y Layer(qWeights[k])
-
9: end for
-
10: Expectation ← [expect(PauliZ(position)) for position(n q qubits)]
-
11: Return tuple(Expectation)
-
18: end function
The variational circuit specified in Equation (4), which is based on nq subsystems. To facilitate the addition of rudimentary pre-processing and post-processing of the input and output data, authors introduced a classical layer at the beginning and end of the quantum network, respectively. This augmentation produces a dressed quantum circuit, denoted by Q, which is expressed as a composite function of the bare quantum circuit Q and the classical layers Lnin → nq and Lnq → nout. Here, Ln → n0 is derived from Equation (5)
Lx ^0 : x ^y = ф( Wx + b )
