Improving the accuracy of segmentation masks using a generative-adversarial network model

Author: Igor V. Vinokurov
Journal: Программные системы: теория и приложения @programmnye-sistemy
Section: Искусственный интеллект и машинное обучение
Article in issue: 2 (65) т.16, 2025.
Free access
Masks obtained using the deep learning model Mask R-CNN may in some cases contain fragmented contours, uneven boundaries, false fusions of adjacent objects, and areas with missed segmentation. The more detection objects in the image and the smaller their size, the more often various types of defects in their masks are encountered. Examples of such images include aerial photographs of cottage and garden associations and cooperatives characterized by high building density. To correct these defects, it is proposed to use a generative adversarial network model that performs post-processing of the predicted Mask R-CNN masks. A qualitative assessment of the model formed in the work demonstrated that it is capable of restoring the integrity of contours at an acceptable level, filling in missing areas, and separating erroneously merged objects. Quantitative analysis using the IoU, precision, recall, and F1-score metrics showed a statistically significant improvement in the segmentation quality compared to the original Mask R-CNN masks. The obtained results confirmed that the proposed approach allows to increase the accuracy of the formation of object masks to a level that satisfies the requirements of their practical application in automated aerial photograph analysis systems.
Computer vision, image segmentation, object masks, generative adversarial networks, Mask R-CNN, PyTorch
Short address: https://sciup.org/143184484
IDR: 143184484 | UDC: 004.932.75'1, 004.89 | DOI: 10.25209/2079-3316-2025-16-2-111-152
Повышение точности сегментирования объектов с использованием генеративно-состязательной сети
Маски, полученные с использованием модели глубокого обучения Mask R-CNN, в ряде случаев могут содержать фрагментированные контуры, неровные границы, ложные сращивания соседних объектов и участки с пропущенной сегментацией. Чем больше объектов детектирования на изображении и меньше их размер, тем более чаще встречаются различного вида недостатки их масок. Примерами таких изображений могут являться аэрофотоснимки коттеджных и садовых товариществ и кооперативов, характеризующихся высокой плотности застройки. Для коррекции указанных недостатков предлагается использовать модель генеративно-состязательной сети, выполняющую постобработку предсказанных Mask R-CNN масок. Качественная оценка сформированной в работе модели продемонстрировала, что она способна на приемлемом уровне восстанавливать целостность контуров, заполняет пропущенные области и разделять ошибочно объединенные объекты. Количественный анализ по метрикам IoU, precision, recall и F1-score показал статистически значимое улучшение качества сегментации по сравнению с исходными масками Mask R-CNN. Полученные результаты подтвердили, что предложенный подход позволяет довести точность формирования масок объектов до уровня, удовлетворяющего требованиям их практического применения в системах автоматизированного анализа аэрофотоснимков.
Text of the scientific article Improving the accuracy of segmentation masks using a generative-adversarial network model
Detecting correct property masks in dense aerial images is a challenge for deep learning models, Mask R-CNN, YOLO, and others. The main reason is that buildings are located close to each other, which makes it difficult to accurately separate objects, since their contours may intersect or merge in the image.
This is especially problematic in high-detail settings, where small architectural elements such as extensions, balconies, or common walls between buildings may be perceived by the model as a single object. In addition, complex building shapes, such as polygonal outlines or non-standard structures, require deeper analysis and adaptation from the model, which increases the likelihood of errors in mask generation. Several examples of such masks are shown in Figure 1.
Another reason is the presence of external factors, such as vegetation and shadows, which partially obscure objects in images. Trees, bushes, or even temporary ob jects such as cars can cover parts of buildings, creating gaps in the data available to the model. Shadows caused by different shooting angles or time of day also distort visual information, reducing contrast and making it difficult to distinguish clear boundaries of objects. These factors lead to the model either underestimating the area of an object, ignoring hidden areas, or overestimating it, including extraneous elements in the mask. As a result, there is an increased need for additional processing and improving the quality of predictions to ensure the correctness of the final data.
The problem of refining the boundaries of ob jects is especially relevant for the «Roskadastr» PLC information system (IS), where increased requirements are placed on the accuracy of spatial data. Traditional post-processing methods, such as morphological operations or active contour algorithms, are often not effective enough for complex cases of dense development. In this regard, there is a need to solve the problem of automatic correction of segmentation results, while maintaining the topological correctness of ob jects.
The presented work proposes one of the possible solutions to this problem, based on the use of a generative adversarial network (GAN) for post-processing the segmentation results obtained using Mask R-CNN. The main idea of the study is that the GAN architecture, properly trained on a representative sample of development ob jects, typical for the «Roskadastr» PLC software package, will be able to effectively restore the integrity of broken boundaries, eliminate internal gaps in masks, separate erroneously merged objects and maintain the exact position of corner (turning) points of buildings.
The research implementation consisted of the following stages:
-
(1 ) Formation of a representative and balanced dataset containing correspondences of the original masks from Mask R-CNN to reference masks extracted from files with object annotations and masks obtained as a result of their expert correction.
-
(2) Development of a GAN architecture that takes into account the features of dense development in cottage and garden associations and cooperatives, requirements for the accuracy of boundaries for cadastral registration and the need to preserve the topology of ob jects.
-
(3 ) Conducting experimental studies with an assessment of the qualitative characteristics of the resulting masks and quantitative indicators (IoU, precision, recall, F1-score).
1. Overview of work on using GAN to improve objects detection
There is currently a significant amount of research devoted to the use of generative adversarial networks (GANs) to improve the efficiency of image recognition and transformation.
The paper [3] discusses conditional GAN (cGAN) models that can be used to transform images of one type into another. For example, segmentation masks can be transformed into realistic images, or vice versa. The described models demonstrate high accuracy of ob ject segmentation and improve the quality of their masks.
The Pix2Pix model described in [4] and based on cGAN is used to synthesize high-quality images based on input data such as segmentation masks. The paper shows that GAN can improve the quality of masks by training on (mask, exact mask) pairs.
The study [5] presents the MaskGAN model designed for interactive editing of face images using masks. The model improves the quality of masks and allows manipulation of segmented areas of images.
In [6] , a SegAN model with a multi-level discriminator and L1 loss is proposed for medical segmentation. The model uses a multi-level discriminator to improve the quality of masks, especially in tasks with fuzzy object boundaries. The GAN model improves object boundaries, reduces noise, and eliminates object detection inaccuracies.
The attention mechanism for generating masks in Attention-GAN described in [7] is applied to transform objects in wildlife photographs. The model can eliminate noise and detection inaccuracies while preserving fine object details.
In [8] , an image transformation method is proposed using CycleGAN and cyclic loss during training. The model can be adapted to improve segmentation masks, especially in tasks with inconsistent data. It eliminates noise and detection inaccuracies while preserving fine ob ject details.
The Boundary-Aware GAN model with a multi-level discriminator described in [9] is designed to improve object boundaries in semantic segmentation problems. The discriminator is trained to distinguish between real and predicted boundaries. Improvements in ob ject detection include identifying clear boundaries, reducing noise, and eliminating inaccuracies.
The paper [10] explores the application of GANs for binary semantic segmentation on imbalanced datasets. The authors propose a new architecture and approach to training GANs to improve the quality of ob ject mask prediction under conditions of strong class imbalance. The main focus is on the problems of low prediction accuracy for the minority class, loss of fine object details, noise, and artifacts in the predicted masks. The authors demonstrate that GAN can improve the quality of masks due to more accurate modeling of ob ject boundaries and restoration of fine details.
The article [11] describes the Power-Line GAN (PLGAN) model for segmentation of thin and long objects against a background of complex textures and noise. The main goal is to improve the accuracy of power line detection, which is important for infrastructure monitoring, mapping, and environmental analysis. The key ideas proposed in the paper include adapting GAN for thin object segmentation, improving detail, handling imbalanced data, and smoothing edges using active contours and spline interpolation.
The problem of unbalanced data distribution between the source domain (a set of images) and the target domain in the tasks of semantic segmentation of aerial photographs is considered in [12] . The authors propose a method for training a model without using labels for the target domain. For this purpose, a GAN is used that adapts the stylistic features of the source domain to the target one. The main goal of this work is to improve the segmentation accuracy on the target domain, minimizing the influence of differences between domains, such as changes in lighting, shooting angles, or object textures. The authors note the following improvements achieved using the proposed approach: better generalization of the model, eliminating the influence of differences between domains, preserving fine details, and reducing noise.
In [13] , the application of cGAN to the task of semantic segmentation of medium-resolution satellite images is investigated. The authors focus on improving the accuracy of ob ject extraction in such images, which often suffer from noise, lack of detail, and complex textures. The main goal of the work is to demonstrate how cGAN can be used to improve the quality of segmentation compared to traditional approaches such as U-Net or DeepLab. Particular attention is paid to the tasks of land use monitoring, urban planning, and environmental change analysis. The improvements achieved by the proposed approach include high accuracy for minority classes, sharp object boundaries, preservation of fine details, and noise removal.
In [14] , the authors propose a new approach that uses GAN to improve the quality of predicted masks by more accurately modeling object boundaries and restoring fine details. The main focus is on tasks related to the analysis of high-resolution images such as aerial photographs, medical images, and urban landscapes. The aim of the work is to show that using
GAN can significantly improve the accuracy and detail of object instance segmentation compared to traditional methods such as Mask R-CNN or DeepLab. Improving the detail and smoothing the contours of masks are the main results of this work.
2. Dataset generation
The dataset used in the experimental studies is a set of (predicted mask, exact mask) pairs. The predicted mask is a binary mask of an object obtained using the Mask R-CNN model. The exact mask is a binary mask formed from a polygon of the same object extracted from a json file.
The types and quantities of objects presented in the dataset, as well as the features of forming json files for image files, are described in [1] . For polygons of objects missing from the json files, the corresponding exact masks were formed (corrected) manually. This made it possible to create a representative and consistent dataset, including both automatically generated and manual masks. All masks in the dataset were reduced to a size of 256 x 256 pixels. Larger mask sizes lead to a sharp increase in computational load and, accordingly, computation time, smaller ones lead to uneven contours of predicted masks, after increasing their size. Increasing to the size of an image with real estate objects is necessary at the stage of visualization of the result in order to combine the mask of the object and the image containing it.
3. Model creation and exploration 3.1. GAN architecture features
GANs consist of two main components, a generator and a discriminator, which operate in an adversarial mode. The main goal of a GAN is to train the generator to produce data that is indistinguishable from real data.
The generator takes random noise (usually from a normal distribution) as input during training and transforms it into some data, such as an image. The generator’s task is to produce data that looks real. To do this, it learns to minimize the losses that occur when the discriminator tries to detect a fake. The main generator architectures are the following:
DCGAN (Deep Convolutional GAN) [15] is simple and effective, but may produce less detailed results on complex data. The generator uses transposed convolutions to gradually increase the image resolution. It starts with a random vector (latent space) and successively increases the dimensionality of the data to the target resolution.
U-Net [16] is suitable for tasks where it is important to preserve spatial details, such as segmentation or mask enhancement. The generator is based on the U-Net architecture, which includes an encoder for dimensionality reduction and a decoder for image restoration. It uses a skip connection mechanism, which allows preserving fine details.
StyleGAN [17] provides high detail and control over style, but requires large computational resources. Allows control over different levels of image detail (e.g. overall shape and textures). The generator is divided into two parts for style matching and synthesis.
The discriminator evaluates the quality of the generated data. The goal of the discriminator is to help the generator generate more reliable data (images) by providing correct error signals. The main discriminator architectures are:
PatchGAN [3] is effective for tasks where object boundaries and fine details are important. It analyzes the image by small local areas ("patches") instead of the entire image. Each patch is classified as real or fake, which allows focusing on local details.
Multi-level discriminator [18] improves the quality of generation due to a more comprehensive assessment of the data. It uses multiple discriminators, each operating at different levels of resolution. This allows evaluating both global and local image characteristics.
Conditional GAN (cGAN) [19] is the most effective for tasks that require directed generation, such as translating images between groups. The discriminator accepts additional information (such as class labels or conditional data) along with the image, allowing control over the type of data generated.
Considering the features of the above-described generator and discriminator architectures, the U-Net and PatchGAN architectures were chosen to improve the accuracy of small real estate masks, respectively.
-
3.2. Model creation
The generator, implemented on the basis of the U-Net architecture, implements two main stages: compression (downsampling) and expansion (upsampling).
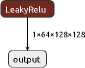
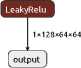
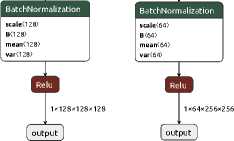
The compression stage reduces the spatial resolution of the data. Each of the 5 groups of elements reduces the image size by 2 times and consists of a convolutional layer (Conv2d) with a kernel size (kernel_size) of 4x4, a stride (stride) of 2 and a padding (padding) of 1. Then a BatchNorm2d layer can follow with the activation function LeakyReLU and a coefficient of 0.2.
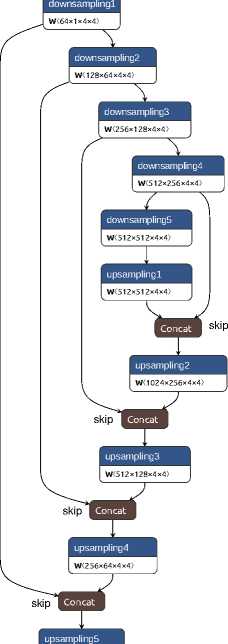
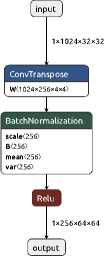
Dilation elements, on the contrary, increase the spatial resolution of the data. There are also 5 expansion elements in the proposed generator. Each such element increases the image size by 2 times by performing a transposed convolution (ConvTranspose2d) with a kernel size of 4x4, a stride of 2, and a padding of 1. Then a BatchNorm2d layer follows (except for the last block) with the activation function ReLU (except for the last block, which uses Tanh to limit the output to the range [-1, 1]). The organization of the GAN generator is shown in Figure 2.
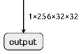
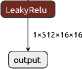
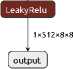
The expansion element combines its output data with the data from the corresponding image compression element via skip connectors. This allows preserving details and improving the quality of generation. The generator output is a single-channel image of the same size as the input. The compression and expansion elements of the level 1 generator described above are shown in Figure 3 and Figure 4, respectively.
input
1x1x256x256
W < 128x1x4x4 >
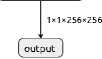
Figure 2. GAN generator
As noted above, the discriminator based on the PatchGAN architecture analyzes the image by small local regions (patches). Each patch is classified as real or fake, which allows focusing on local details. The discriminator input
input
input
input
input
Conv
1×1×256×256
Conv
1×64×128×128
Conv
1×128×64×64
Conv
1×256×32×32
Conv
1×512×16×16
W 〈 64×1×4×4 〉
W 〈 128×64×4×4 〉
W 〈 512×256×4×4 〉
W 〈 512×512×4×4 〉
BatchNormalization
BatchNormalization
scale 〈 64 〉
B〈64〉 mean〈64〉 var〈64〉
т
scale 〈 128 〉
B〈128〉 mean〈128〉 var〈128〉
т
W 〈 256×128×4×4 〉

BatchNormalization
BatchNormalization
( a ) downsam-
-
( b ) downsam-
pling1
pling2
scale 〈 512 〉
B〈512〉 mean〈512〉 var〈512〉
scale 〈 512 〉
B〈512〉 mean〈512〉 var〈512〉
-
( c ) downsam- ( d ) downsam- ( e ) downsam-
pling3
pling4
pling5
-
Figure 3. GAN generator compression elements
input
1×512×16×16
ConvTranspose
W 〈 512×512×4×4 〉
BatchNormalization
scale 〈 512 〉
B 〈 512 〉 mean 〈 512 〉 var 〈 512 〉


1×512×64×64
1×256×128×128
input
1x128x256x256
( a ) upsampling1
ConvTranspose
W 〈 512×128×4×4 〉
ConvTranspose
W 〈 256×64×4×4 〉
ConvTranspose
W < 128x1x4x4 >
( b ) ( c ) ( d ) ( e )
upsampling2
upsampling3 upsampling4 upsampling5
-
Figure 4. GAN generator extension elements
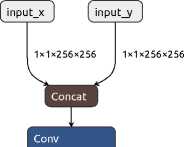
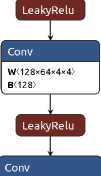
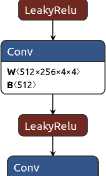
takes two input images: the predicted image (generated by the generator) and the real image (in our case, they are accurate object masks). Then these images are concatenated by channels. The next few convolutional layers (Conv2d) with a kernel size of 4x4, a stride of 2, and a padding of 1 reduce the spatial dimensions of the data.
W 〈 64×2×4×4 〉
B 〈 64 〉
“Г
W 〈 256×128×4×4 〉
B 〈 256 〉
W 〈 1×512×4×4 〉
B 〈 1 〉
Sigmoid
1×1×30×30
output
-
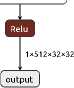
Figure 5. GAN discriminator
-
3.3. Model Study Results
Starting from the second layer, BatchNorm2d is applied with the activation function LeakyReLU and a coefficient of 0.2. The last layer with the activation function Sigmoid calculates the probability that the input data is real. The structure of the discriminator is shown in Figure 5.
The generator uses the standard loss function for binary classification problems BCEWithLogitsLoss and L1 Loss to minimize the pixel difference between the generated and real masks. The first of these functions is used to “fool” the discriminator, the second helps the generator create masks that are close to the real ones in pixel values. An important parameter for L1 Loss is λ L1 , which controls the importance of the pixel difference between the generated and real masks. This allows you to balance between “fooling” the discriminator and the accuracy of detail reproduction. The generator loss function is BCEWithLogitsLoss.
Training GANs is associated with certain problems, such as instability of the training process, mode collapse, and low generation quality, which require the use of special methods to address them. One such approach is spectral normalization, which limits the spectral norm of the weights in the generator and discriminator layers, thereby stabilizing training and preventing gradient explosion [20] . Another method is to use a gradient penalty, which adds regularization to the discriminator outputs, providing a smoother distribution of values and improving model convergence [21] . Self-attention, which allows the model to take into account global dependencies in the data, is also widely used, which is especially useful when working with high-dimensional images [22] . However, since restoring simple binary masks is a relatively simple task, and as the results of the study of the GAN model described above showed, the use of these approaches in this case is redundant.
The GAN model was developed and studied using the PyTorch framework in Google Colab Pro. The Jupyter notebook (MIT License) is available at this link– . The main accuracy metrics were studied for different values of learning rate, number of epochs, and batch sizes. The accuracy metrics of the GAN generator were studied at λ L1 = 100, since
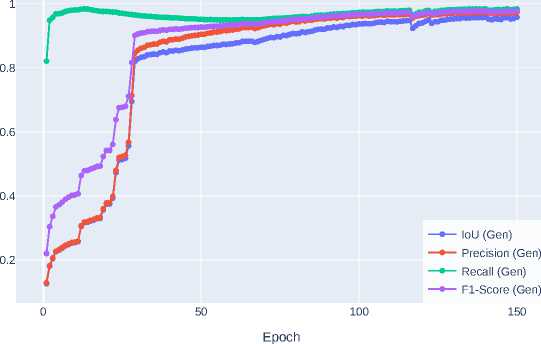
Figure 6. GAN generator accuracy metrics for λ L1 =80
at this value their curves have a sufficient degree of smoothness, which indicates the absence of explosive or decaying gradients. In Figure 6 , Figure 7, and Figure 8 show the accuracy metrics curves for λ L1 = 80, 100 and 120.
Table 1 present the results of studies of the main accuracy metrics IoU, IoU0.5-95, Precision, Recall and F1-Score. As the studies have shown, the use of GAN can significantly improve the accuracy of real estate segmentation masks obtained using the Mask R-CNN [1] model.
Let’s look at some examples of improving real estate masks obtained using the Mask R-CNN model. Figure 9 shows masks predicted by the Mask R-CNN model and improved masks generated by GAN. Based on the accuracy metrics, it can be concluded that using GAN can significantly improve the quality of masks by correcting errors such as contour discontinuities, noise, and inaccuracies in the boundaries of objects.
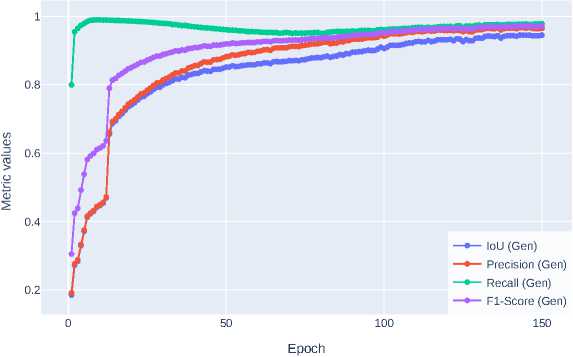
Figure 7. GAN generator accuracy metrics for λ L1 =100
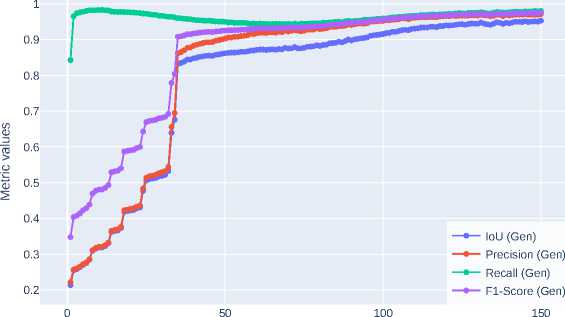
Epoch
Figure 8. GAN generator accuracy metrics for λ L1 =120
Table 1. Evaluation of accuracy metrics for predicted GAN masks under different values of model training parameters
|
Learning Speed |
Batch Size |
Learning Epochs |
IoU (Pred) |
Precision (Pred) |
Recall (Pred) |
F1-Score (Pred) |
IoU0.5-95 (Pred) (Mask R-CNN) |
IoU0.5-95 (Pred) (GAN) |
|
1e-6 |
10 |
500 |
0.87 |
0.92 |
0.91 |
0.91 |
0.67 |
0.90 |
|
5e-6 |
10 |
400 |
0.85 |
0.90 |
0.89 |
0.90 |
0.65 |
0.88 |
|
5e-6 |
20 |
350 |
0.84 |
0.89 |
0.88 |
0.88 |
0.64 |
0.87 |
|
1e-5 |
10 |
300 |
0.83 |
0.88 |
0.87 |
0.87 |
0.63 |
0.86 |
|
1e-5 |
20 |
250 |
0.84 |
0.89 |
0.88 |
0.88 |
0.64 |
0.87 |
|
5e-5 |
8 |
200 |
0.79 |
0.84 |
0.83 |
0.83 |
0.59 |
0.81 |
|
5e-5 |
10 |
300 |
0.82 |
0.87 |
0.86 |
0.86 |
0.62 |
0.85 |
|
5e-5 |
16 |
250 |
0.81 |
0.86 |
0.85 |
0.85 |
0.61 |
0.84 |
|
4e-5 |
8 |
150 |
0.80 |
0.85 |
0.84 |
0.84 |
0.60 |
0.82 |
|
4e-5 |
16 |
200 |
0.78 |
0.83 |
0.82 |
0.82 |
0.58 |
0.80 |
|
1e-4 |
8 |
100 |
0.75 |
0.80 |
0.78 |
0.79 |
0.55 |
0.78 |
|
1e-4 |
16 |
150 |
0.77 |
0.82 |
0.81 |
0.81 |
0.57 |
0.80 |
|
1e-4 |
20 |
200 |
0.78 |
0.83 |
0.82 |
0.82 |
0.58 |
0.81 |
|
2e-4 |
8 |
80 |
0.70 |
0.75 |
0.73 |
0.74 |
0.50 |
0.73 |
|
2e-4 |
16 |
100 |
0.72 |
0.78 |
0.76 |
0.77 |
0.52 |
0.76 |
Using GAN to improve the accuracy of segmentation masks 125

Figure 9. The results of GAN enhancement are shown under the Mask R-CNN predicted real estate object masks
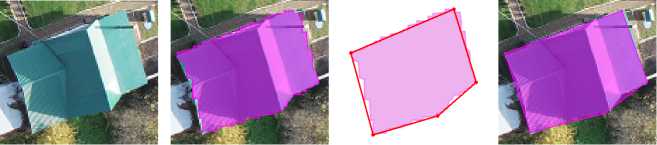
An example of improving object masks on an aerial photograph, where the complexity of the task increases due to the high density of objects and their diversity, is shown in Figure 10 .
When generating masks using GAN, the problem of uneven and stepped edges often arises, see Figure 9. This is due to the specifics of GAN operation, which is associated with the discreteness of pixels when forming images and the complexity of accurately reproducing small details of object boundaries. To improve the contours of segmentation masks, various morphological smoothing functions can be applied, which allow you to eliminate noise, fill in gaps and make object boundaries smoother.
One of the basic approaches is to use morphological opening and closing operations with a given structuring element (for example, a square matrix (5 x 5). Opening helps to remove small noise artifacts, and closing fills small gaps inside the mask. For additional smoothing of contours, you can apply Gaussian blur (GaussianBlur) , which softens sharp transitions between the background and the object.

( a ) Results of detecting real estate masks using the Mask R-CNN model

( b ) The masks are improved by GAN generator
Figure 10. Improvement of objects masks
( a ) Real estate
( b ) Jagged edges ( c ) Aligned edges ( d ) Resulting mask
Figure 11. Eliminating mask aliasing using the Douglas-Peucker algorithm
Another effective method is to use active contours (snakes), which adaptively adjust to the shape of the object by minimizing the elastic energy and smoothness. To achieve even smoother contours, spline interpolation can be used, which approximates the original contour using cubic splines, ensuring uniform distribution of points and smooth boundaries.
Another effective way to eliminate aliasing is to use the Douglas-Peucker algorithm, which specializes in simplifying polylines and smoothing contours [23] . The peculiarity of this algorithm is its ability to analyze each point of the mask boundary and evaluate its significance for the overall shape of the object. Points that make a minimal contribution to the contour configuration are removed, which allows you to get smoother and more natural boundaries without losing key geometric features. An example of using the Douglas-Peucker algorithm is shown in Figure 11.
These methods or their combinations allow in some cases to improve the quality of masks, making them more suitable for subsequent analysis or visualization. As studies have shown, the use of morphological smoothing methods and improvement of mask boundaries using the Douglas-Peucker algorithm in post-processing of masks makes it possible to increase the accuracy of their formation by an average of 5–7%, which is especially important for computer vision tasks and segmentation of ob jects on aerial photographs in particular.
Conclusion
In this paper, a GAN model was proposed and investigated to improve the accuracy of segmentation masks obtained using the Mask R-CNN model. Experiments have shown that the use of GAN can significantly improve the quality of detected real estate masks by correcting errors such as gaps in masks, noise artifacts, and jagged edges. The improvement is achieved by using the L1 loss function to minimize pixel differences between the target and generated masks, as well as by using a discriminator that contributes to more realistic mask generation.
The results of the studies demonstrate an improvement in accuracy metrics such as IoU, Precision, Recall, and F1-Score for the improved masks compared to the original Mask R-CNN predictions. The average IoU0.5-95 value increased by an average of 30-35%, which confirms the effectiveness of the proposed approach. It was additionally noted that the use of morphological operations and contour smoothing methods will further improve the smoothness and accuracy of mask boundaries.
The obtained results are of great practical importance and will be used in the «Roskadastr» PLC IS for automatic conversion of raster images with real estate objects into vector maps. This will improve the accuracy and speed of digital map generation, which is especially important for cadastral registration and territory management tasks. The proposed approach can be adapted for other applications related to image processing and computer vision, where high accuracy of ob ject segmentation is required. The study conducted in the work confirms the prospects of using GAN to improve the quality of real estate masks, which allows it to be effectively used to automate the processes of data analysis and transformation in geographic information systems. Further research can be aimed at optimizing the model parameters, introducing new methods of mask post-processing and expanding the scope of GAN.
