Интеграция квантовых вычислительных моделей в конвейеры анализа данных

Автор: Зрелов П.В., Иванцова О.В., Катулин М.С.
Журнал: Сетевое научное издание «Системный анализ в науке и образовании» @journal-sanse
Рубрика: Моделирование и анализ данных
Статья в выпуске: 4, 2025 года.
Бесплатный доступ
В условиях роста сложности и размерности данных традиционные методы машинного обучения сталкиваются с ограничениями в выразительной мощности, масштабируемости и вычислительной эффективности. В данной работе рассмотрен подход к построению гибридных конвейеров анализа данных, интегрирующих классические и квантовые вычислительные модели. С использованием фреймворка для квантовых вычислений PennyLane и библиотек машинного обучения PyTorch и Sciki-learn были разработаны архитектуры для задачи классификации, ключевым элементом которых являются вариационные квантовые схемы, интегрированные в классический конвейер с модулями предобработки признаков и постобработки измерений. В ходе экспериментального исследования проведён сравнительный анализ классических и гибридных моделей на выборках различного объема с использованием трех альтернативных топологий запутывания в квантовых схемах. Полученные результаты подтверждают конкурентоспособную точность гибридных моделей и свидетельствуют об их перспективности для работы со сбалансированными наборами данных и в условиях ограниченного объема выборок.
Гибридные вычисления, квантовое машинное обучение, PennyLane, вариационные квантовые схемы, конвейеры анализа данных, классификация
Короткий адрес: https://sciup.org/14134316
IDR: 14134316 | УДК: 004.41, 004.42
Integration of quantum computing models into data analysis pipelines
With the increasing complexity and dimensionality of data, traditional machine learning methods face limitations in expressive power, scalability, and computational efficiency. In this paper, we consider an approach to building hybrid data analysis pipelines that integrate classical and quantum computing models. Using the PennyLane quantum computing framework and the PyTorch and Sciki-learn machine learning libraries, architectures for classification tasks have been developed, the key element of which are variational quantum circuits integrated into a classical pipeline with feature preprocessing and measurement postprocessing modules. In the course of the experimental study, a comparative analysis of classical and hybrid models was carried out on samples of different volumes using three alternative entanglement topologies in quantum circuits. The results obtained confirm the competitive accuracy of hybrid models and indicate their promise for working with balanced datasets and in conditions of limited sample size.
Текст научной статьи Интеграция квантовых вычислительных моделей в конвейеры анализа данных
Зрелов П. В., Иванцова О. В., Катулин М. С. Интеграция квантовых вычислительных моделей в конвейеры анализа данных // Системный анализ в науке и образовании: сетевое научное издание. 2025. №4. С. 31-43. EDN: CBXRQE. URL:
Статья находится в открытом доступе и распространяется в соответствии с лицензией Creative Commons «Attribution» («Атрибуция») 4.0 Всемирная (CC BY 4.0)
Современные задачи в области анализа данных требуют обработки сложных многомерных наборов признаков, характеризующихся высокой степенью зашумлённости, нелинейной разделимостью и наличием сложных взаимосвязей между переменными. Классические алгоритмы машинного обучения, демонстрирующие высокую эффективность на задачах умеренной сложности, сталкиваются с фундаментальными ограничениями в таких условиях [1]. К ним относится, в частности, так называемое «проклятие размерности», приводящее к экспоненциальному росту вычислительной сложности и требуемого объёма данных с увеличением размерности пространства признаков. Кроме того, классические методы часто оказываются не способны эффективно аппроксимировать сложные нелинейные зависимости, что ограничивает их применимость в современных задачах анализа данных [2, 3]. В качестве альтернативы для преодоления указанных ограничений активно исследуются квантовые вычисления, которые демонстрируют потенциал в решении ряда сложных вычислительных задач [4, 5, 6]. Однако практическая реализация полностью квантовых алгоритмов на существующих квантовых процессорах, относящихся к классу noisy intermediate-scale quantum ( NISQ ) устройств, сопряжена с существенными трудностями [7]. Ограниченная глубина квантовых схем и высокий уровень шума делают невозможным выполнение ресурсоёмких алгоритмов без реализации коррекции ошибок, что остаётся одной из ключевых проблем в области квантовых вычислений [8, 9, 10].
В связи с этим, значительная часть современных исследований сосредоточена на разработке гибридных квантово-классических вычислительных моделей, которые стали ключевым направлением в преодолении ограничений современных квантовых систем [11, 12, 13]. В таких архитектурах квантовый процессор выполняет роль специализированного сопроцессора, решающего узкоспециализированные подзадачи (например, вычисление ядер или вариационных анзацев), в то время как классический компьютер управляет общей логикой алгоритма, оптимизацией и постобработкой, обеспечивая устойчивость и интерпретируемость модели.
Несмотря на активное развитие направления квантового машинного обучения ( Quantum Machine Learning, QML ) и вариационных квантовых алгоритмов [11, 14, 15], ряд методологических проблем остаётся нерешённым. К ним относятся отсутствие стандартизированных и воспроизводимых конвейеров для интеграции квантовых моделей в существующие рабочие процессы анализа данных, а также отсутствие универсальных подходов, применимых к задачам с учителем и без учителя [16].
В рамках исследования предложены подходы к проектированию гибридных квантовоклассических конвейеров анализа данных, направленные на преодоление ограничений традиционных методов машинного обучения. Основной целью работы является разработка и экспериментальная верификация масштабируемых гибридных конвейеров, адаптированных для задач обучения с учителем. Для реализации был использован технологический стек, объединяющий инструменты для квантовых вычислений (фреймворк PennyLane ) и классического машинного обучения ( PyTorch и Scikit-learn ), что обеспечило создание и оптимизацию гибридных квантово-классических архитектур.
-
1. Интеграция квантовых подходов в классические конвейеры анализа данных
1.1 Конвейеры анализа данных
Конвейер анализа данных ( data analysis pipeline ) — это формализованная последовательность вычислительных и логических этапов, предназначенная для преобразования исходных, как правило, неструктурированных или полуструктурированных данных в модели принимающие решения и любые пригодные для интерпретации результаты. Основная цель конвейера — обеспечить воспроизводимость, модульность, масштабируемость и автоматизацию анализа в рамках единого вычислительного процесса.
Существуют разные модели конвейеров анализа данных, основные различия между которыми состоят в определении того, что считается результатом на выходе из конвейера, а также в наличии обратной связи между этапами [17, 18, 19]. В обобщённом виде схему конвейера анализа данных можно представить в виде диаграммы (см. рис.1).
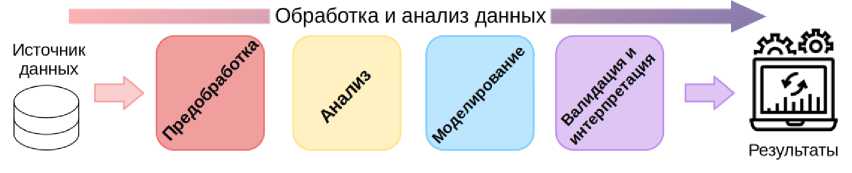
Рис. 1. Основные этапы конвейера анализа данных
Основные этапы классического конвейера анализа данных включают в себя:
-
- Сбор данных — получение данных из различных источников: базы данных, различные API, журналы событий, данные с сенсоров и другие.
-
- Предобработка — удаление пропущенных значений, исправление ошибок, фильтрация шумов, нормализация, снижание размерности и др. Предобработка также включает в себя удаление дублликатов, если они могут исказить результаты и привести к ошибкам в интерпретации данных или увеличить объём обрабатываемой информации без добавления новой ценности.
-
- Анализ — изучение очищенных и обработанных данных с целью выявления закономерностей, формирования гипотез и выбора подходящих моделей и методов дальнейшей работы с данными.
-
- Моделирование — это этап, на котором строится, обучается и настраивается вычислительная модель, способная решать поставленную задачу: классифицировать, предсказывать,
группировать или выявлять аномалии.
-
- Валидация и интерпретация — на данном этапе выполняется объективное измерение качества построенной модели, а полученные метрики преобразуются в осмысленные выводы.
В прикладных задачах, где целью разработки является внедрение модели в бизнес-процессы, можно встретить ещё один этап — «Развёртывание и мониторинг», который подразумевает интеграцию модели в продуктивную среду, отслеживание её производительности со временем. В данной работе этот этап рассматриваться не будет.
1.2 Подходы и инструменты для создания гибридных моделей
Развитие квантовых вычислений стимулирует прогресс в области конвейеров обработки и анализа данных благодаря внедрению гибридных архитектур, которые сочетают надёжность классических методов с потенциальными преимуществами квантовых вычислений. Наиболее перспективными являются гибридные конвейеры с обучением, где квантовые модули интегрированы либо на этапе преобразования признаков, либо в качестве параметризуемой модели [11]. Выбор архитектуры зависит от типа задачи, доступных вычислительных ресурсов и требований к масштабируемости и воспроизводимости. На рисунке 2 представлены возможные архитектурные паттерны интеграции:
-
- Гибридный препроцессинг и классическое моделирование. В данной архитектуре квантовые вычисления используются на этапе предварительной обработки данных. Квантовые алгоритмы, такие как квантовое снижение размерности или вычисление квантовых ядер (quantum kernels), преобразуют данные в пространство признаков, более подходящее для последующего анализа классическими моделями машинного обучения [20, 21]. Данный подход демонстрирует эффективность в задачах с высокой размерностью, где классические методы предобработки сталкиваются с вычислительными ограничениями.
-
- Классический препроцессинг и гибридное моделирование. Эта конфигурация предполагает использование классических методов для этапов сбора, очистки и генерации признаков, в то время как квантовый компонент задействуется на этапе построения прогнозной модели. Такая схема характерна для вариационных квантовых алгоритмов, где параметризованные квантовые схемы функционируют как ядро модели, например, в вариационных квантовых классификаторах [11].
-
- Полностью гибридный конвейер. Наиболее комплексный подход, при котором квантовые и классические методы комбинируются на нескольких или всех этапах конвейера. Несмотря на повышенные требования к проектированию интерфейсов между компонентами и управлению потоком данных, эта архитектура позволяет наилучшим образом использовать синергический потенциал обеих вычислительных парадигм.
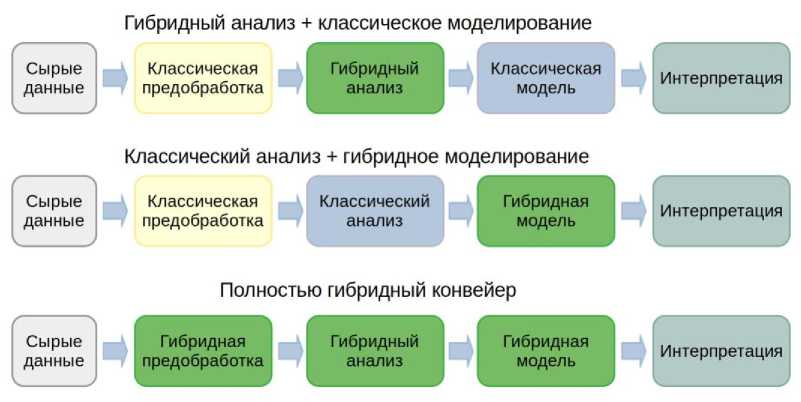
Рис. 2. Возможные варианты гибридных конвейеров анализа данных
Таким образом, интеграция квантовых методов является наиболее перспективной для этапов анализа, связанных с выявлением сложных нелинейных зависимостей и построением прогнозных моделей, что особенно востребовано в области квантового машинного обучения (QML ) [22]. Среди множества подходов в QML можно выделить несколько основных:
-
- Квантовые ядра ( Quantum Kernels ) – метод, использующий квантовые схемы для вычисления скалярного произведения в высоко- или бесконечномерном гильбертовом пространстве, что позволяет эффективно разделять нелинейные классы [12, 23].
-
- Вариационные квантовые классификаторы ( VQC ) – параметризованные квантовые схемы, оптимизируемые совместно с классическими оптимизаторами для минимизации функции потерь [12, 24].
-
- Квантовые алгоритмы кластеризации, такие как квантовый аналог K-Means или спектральная кластеризация на основе квантовых блужданий ( quantum walks ) [25, 26, 27].
Практическая реализация перечисленных подходов предполагает выбор между использованием реальных квантовых процессоров и квантовых симуляторов, работающих на классических архитектурах. Доступ к реальным устройствам через облачные платформы часто ограничен очередями задач, временными лимитами и высоким уровнем шума, что значительно усложняет итеративную разработку и отладку алгоритмов. В таких условиях квантовые симуляторы становятся основным инструментом для исследований, позволяя проводить контролируемые эксперименты в идеализированных условиях [28]. Они обеспечивают возможность избежать влияния декогеренции, шумов и ошибок гейтов, а также предоставляют полный доступ к векторам состояния и амплитудам, что невозможно при работе с физическими устройствами из-за коллапса волновой функции при измерении. Использование квантовых симуляторов позволяет проводить масштабные исследования выразительной способности и обучаемости квантовых схем, оценивать их масштабируемость и выполнять строгое сравнение с классическими аналогами до перехода к дорогостоящим экспериментам на физических квантовых процессорах [11, 28].
Эффективная разработка гибридных квантово-классических моделей, таких как вариационные квантовые схемы ( VQC ), интегрированных с классическими нейронными сетями, требует обеспечения сквозной дифференцируемости всего вычислительного графа, включая квантовые компоненты. Фреймворк PennyLane 1 реализует архитектуру, основанную на принципах дифференцируемого квантового программирования. Его главными преимуществами являются:
- Поддержка кроссплатформенных вычислений: единый код может быть запущен на различных квантовых симуляторах (default, Lightning, Qiskit Aer и др.), а также на реальных устройствах от IBM, Rigetti, IonQ и других провайдеров без внесения изменений в логику алгоритма.
- Гибкие методы дифференцирования: PennyLane реализует специализированные техники для дифференцирования квантовых схем.
- Глубокая интеграция с экосистемой машинного обучения: фреймворк обеспечивает бесшовную совместимость с популярными библиотеками, включая PyTorch2, TensorFlow3 и JAX4, что позволяет конструктивно встраивать квантовые компоненты в сложные гибридные архитектуры, используя знакомые инструменты и API.
- Широкий набор встроенных функций и инструментов для квантовой визуализации и анализа.
- Эти характеристики делают PennyLane важным инструментом для исследований и разработок в области квантовых вычислений, особенно в контексте гибридных архитектур.
2. Разработка гибридного конвейра для задачи классификации
2.1. Данные для анализа
Экспериментальная оценка предложенных архитектур гибридных квантово-классических конвейеров для классификации проводилась на двух наборах данных. Первый набор – CIC-Darknet20205 – содержит данные сетевого трафика, размеченные на четыре класса: Tor, VPN, Non-Tor и Non-VPN (распределение классов представлено на рис. 3). Выборка состоит из 154 058 наблюдений, описываемых 28 признаками.
2.2. Гибридный конвейер для задачи классификации
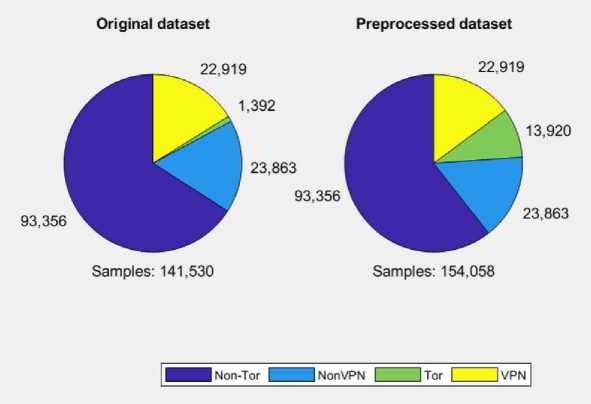
Рис. 3. Распределения классов в наборе данных Darknet2020
Второй набор данных, Forest Cover Type 6, включает 581 012 наблюдений с 54 признаками и характеризуется существенным дисбалансом классов (см. табл. 1).
Табл. 1. Процентное содержание элементов каждого класса в выборке
|
Класс |
% содержание элементов |
|
Class 1 |
36,46% |
|
Class 2 |
48,76% |
|
Class 3 |
6,15% |
|
Class 4 |
0,47% |
|
Class 5 |
1,63% |
|
Class 6 |
2,99% |
|
Class 7 |
3,53% |
Предложенная архитектура гибридного конвейера для задачи классификации состоит из трёх последовательных компонентов (см. рис. 4, верхняя схема). Первый компонент реализует классическую предобработку данных, включающую нормализацию признаков и снижение размерности методом главных компонент ( PCA ). Для обоих наборов данных сокращение признакового пространства до 7 компонент позволило сохранить более 85% объяснённой дисперсии. Эта размерность напрямую определяет число кубитов в квантовом модуле.
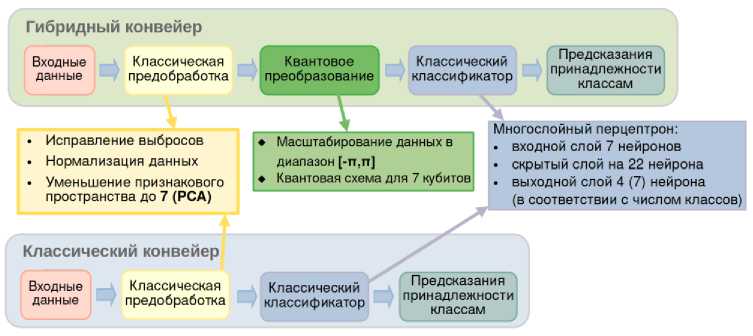
Рис. 4. Архитектуры гибридного (сверху) и классического (снизу) конвейеров для задачи классификации
Второй компонент — параметризованная квантовая схема, реализованная на основе шаблонов PennyLaine . Данная схема выполняет нелинейное преобразование входных данных, кодируя классические признаки в квантовое состояние и применяя параметризованные вариационные слои, обеспечивающие запутывание кубитов. Были разработаны три архитектуры квантовых схем (рис. 5):
-
1) QAOAEmbedding (7 слоёв): чередование данных и обучаемых параметров в каждом слое.
-
2) AngleEmbedding + StronglyEntanglingLayers (6 слоёв): обеспечивает полносвязное
запутывание.
-
3) AngleEmbedding + BasicEntanglerLayers (6 слоёв): чередование вращений RX / RY для повышения выразительности.
Результатом работы квантовой схемы являются квантовые признаки, извлекаемые путём измерения ожидаемых значений операторов ПаулиX на каждом кубите, что обеспечивает совместимость с классическим постпроцессором.
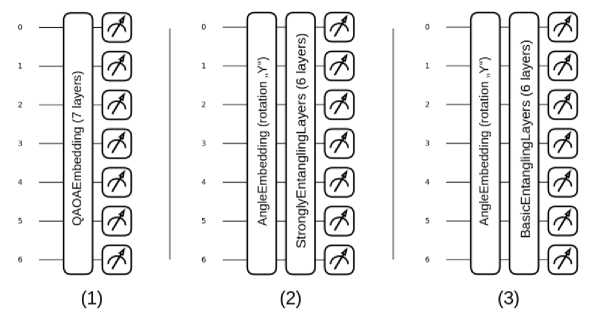
Рис. 5. Варианты квантовых схем используемых в гибридных конвейерах: (1) QAOAEmbedding7; (2) AngleEmbedding + StronglyEntanglingLayers; (3) AngleEmbedding + BasicEntanglerLayers
Третий компонент – классический многослойный перцептрон ( MLP ), который интерпретирует 7-мерный вектор квантовых признаков и формирует вероятностное распределение по целевым классам (4 класса для Darknet 2020 и 7 классов для Forest Cover Type ).
Шаблон QAOAEmbedding основан на QAOA анзатце, предложенном в работе [29]. Описание шаблона на сайте PennyLane:
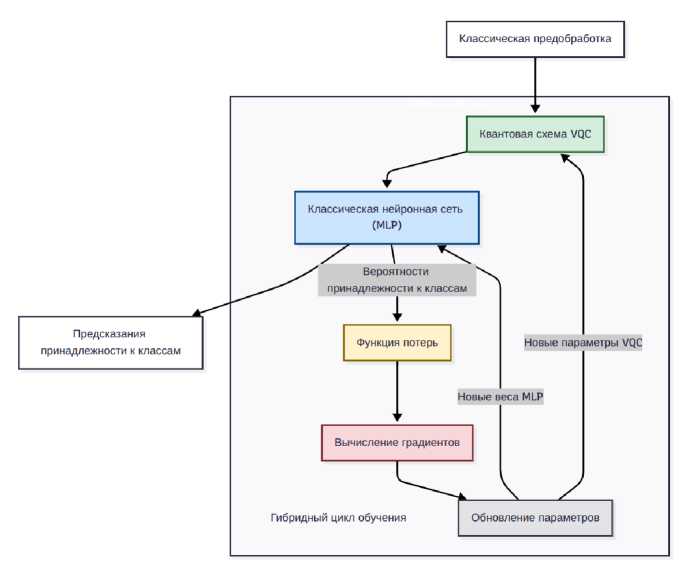
Рис. 6. Схема обучения вариационного квантово-классического алгоритма
Обучение гибридной модели осуществляется в едином end-to-end процессе (рис. 6). В прямом проходе данные последовательно проходят квантовую схему и классификатор, а градиенты вычисляются сквозным образом с помощью автоматического дифференцирования. Оптимизатор Adam одновременно обновляет параметры квантовых вращений и веса MLP . Для предотвращения переобучения применялась стратегия ранней остановки при отсутствии улучшения функции потерь на валидационной выборке (20% от обучающих данных) в течение 15 эпох.
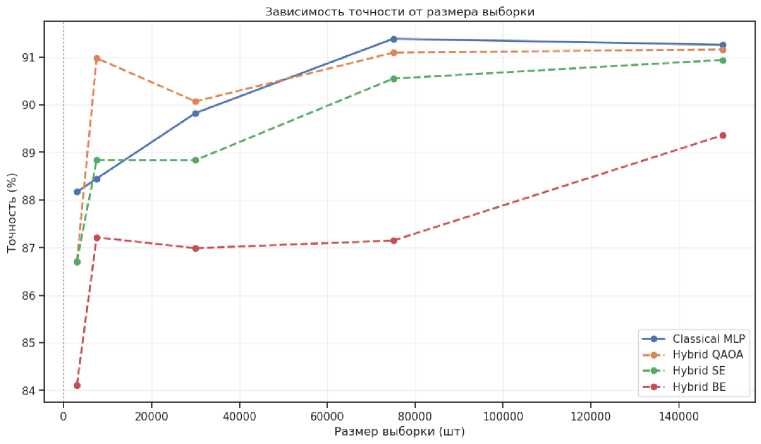
Рис. 7. График зависимости точности работы конвейера от числа элементов в выборке данных (для набора Darknet2020). Обозначения: Hybrid QAOA — квантовая схема на основе QAOAEmbedding; Hybrid SE — квантовая схема на основе AngleEmbedding + StronglyEntanlingLayers; Hybrid BE — квантовая схема на основе AngleEmbedding + BasicEntanglerLayers
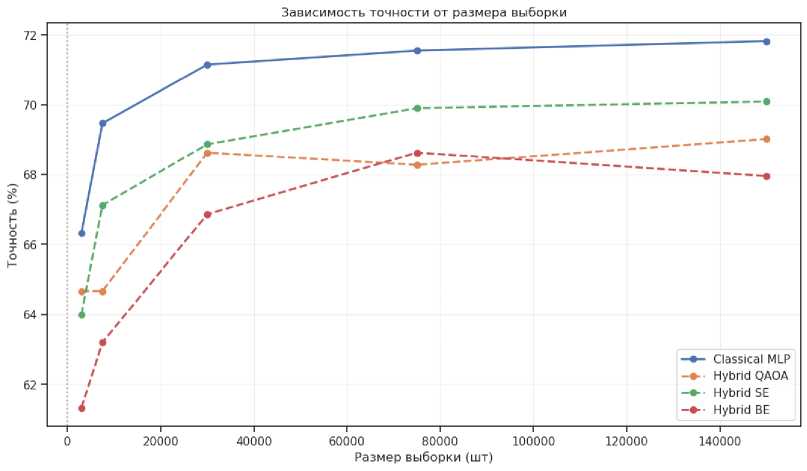
Рис. 8. График зависимости точности работы конвейера от числа элементов в выборке данных (для набора Forest Cover Type). Обозначения: Hybrid QAOA – квантовая схема на основе QAOAEmbedding;
Hybrid SE – квантовая схема на основе AngleEmbedding + StronglyEntanlingLayers; Hybrid BE – квантовая схема на основе AngleEmbedding + BasicEntanglerLayers
Сравнительный анализ проводился на наборах данных с разной степенью дисбаланса классов: Darknet 2020 (умеренный дисбаланс) и Forest Cover Type (сильный дисбаланс). Для каждого набора были сформированы 5 подвыборок объёмом от 3 000 до 150 000 элементов. Результаты (рис. 7, рис. 8) показали, что гибридные модели демонстрируют условное преимущество на умеренно сбалансированных данных ( Darknet 2020), где схема QAOAEmbedding превзошла классический MLP на выборках в 7 000 – 40 000 элементов. На сильно данных с сильным дисбалансом ( Forest Cover Type ) классические модели показали более устойчивое качество, особенно для редких классов. Финальная оценка на 150 000 объектов подтвердила конкурентоспособность подхода:
-
- Для Darknet 2020 на выборке 150 000 элементов точность гибридной ( QAOAEmbedding ) и классической моделей составила 91.2% и 91.3% соответственно (см. рис. 9 и рис. 11).
-
- Для Forest Cover Type на выборке 150 000 элементов точность гибридной ( StronglyEntanling ) и классической моделей – соответственно 70.1% и 71.8% (см. рис. 10 и рис. 12).
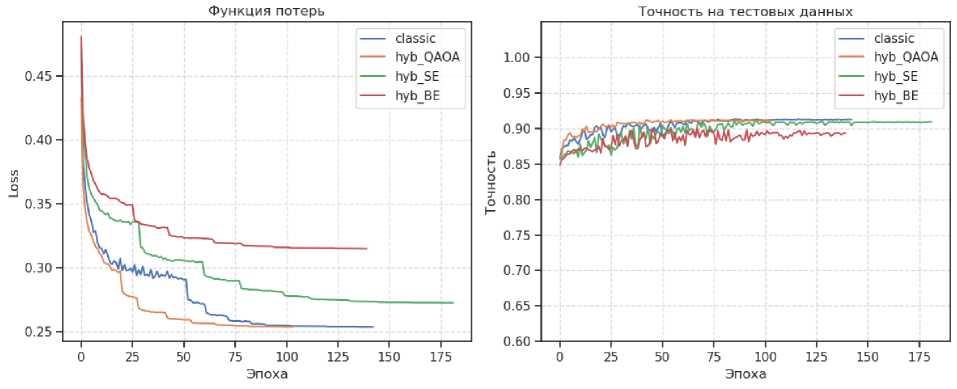
Рис. 9. Графики обучения классической и гибридной моделей для выборки из 150000 элементов для данных Darknet2020. Обозначения: hyb_QAOA — квантовая схема на основе QAOAEmbedding; hyb_SE — квантовая схема на основе AngleEmbedding + StronglyEntanlingLayers; hyb_BE — квантовая схема на основе AngleEmbedding + BasicEntanglerLayers
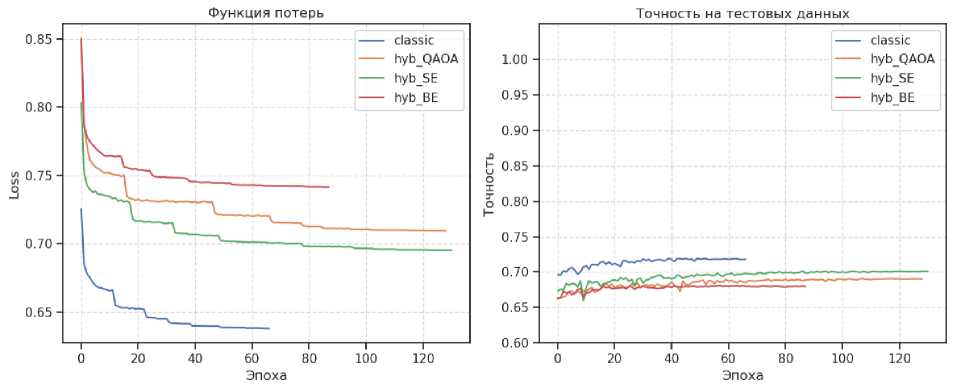
Рис. 10. Графики обучения классической и гибридной моделей для выборки из 150000 элементов для данных Forest Cover Type. Обозначения: hyb_QAOA — квантовая схема на основе QAOAEmbedding; hyb_SE — квантовая схема на основе AngleEmbedding + StronglyEntanlingLayers; hyb_BE — квантовая схема на основе AngleEmbedding + BasicEntanglerLayers
Отчёты о классификации (рис. 11, рис. 12), включающие метрики Precision , Recall и F 1-меру на контрольной выборке (20% данных), подтвердили сопоставимое качество гибридных и классических моделей.
|
Отчет о классификации модели ‘hyb QAOA': |
Отчет о классификации модели ’classic': |
||||
|
precision |
recall fl-score |
precision |
reca LI |
Tl-score |
|
|
label_3 |
0.92 |
0.85 0.89 |
label_3 0.95 |
0.86 |
0.90 |
|
label_l |
0.81 |
0.80 0.80 |
label_l 0.78 |
0.80 |
0.79 |
|
label 4 |
0.96 |
0.99 0.97 |
label 4 0.97 |
0.99 |
0.98 |
|
label_2 |
0.81 |
0.76 0.78 |
label_2 0.78 |
0.75 |
0.76 |
|
accuracy |
0.91 |
accuracy |
0.91 |
||
|
macro avg |
0.87 |
0.85 0.86 |
macro avg 0.87 |
0.85 |
0.86 |
|
weighted avg |
0.91 |
0.91 0.91 |
weighted avg 0.91 |
0.91 |
0.91 |
|
Точность: 0.9116 |
Точность: 0.9126 |
||||
Рис. 11. Сравнение результатов классификации гибридной (QAOAEmbedding) и классической (справа) моделей, обученных на Darknet2020 для выборки из 150000 элементов
|
Отчет о классификации модели ’hyb_5E': |
score |
Отчет о классификации модели 'classic': |
|||
|
precision |
recall fl- |
precision |
recall |
fl-score |
|
|
label_2 0.69 |
0.70 |
0.69 |
label_2 0.70 |
0.71 |
0.70 |
|
label_l 0.73 |
0.78 |
0.75 |
labell 0.74 |
0.79 |
0.76 |
|
label_6 0.63 |
0.76 |
0.69 |
label_6 0.69 |
0.76 |
0.72 |
|
label_3 0.59 |
0.07 |
0.12 |
label_3 0.73 |
0.42 |
0.53 |
|
label_5 1.00 |
0.00 |
0.00 |
label_5 0.73 |
0.11 |
0.20 |
|
label_7 0.39 |
0.08 |
0.13 |
label_7 0.43 |
0.21 |
0.28 |
|
label_4 0.71 |
0.38 |
0.50 |
label_4 0.75 |
0.50 |
0.60 |
|
accuracy |
0.70 |
accuracy |
0.72 |
||
|
macro avg 0.68 |
0.40 |
0.41 |
macro avg 0.68 |
0.50 |
0.54 |
|
weighted avg 0.70 |
0.70 |
0.68 |
weighted avg 0.71 |
0.72 |
0.71 |
|
Точность: 0.7009 |
Точность: 0.7182 |
||||
Рис. 12. Сравнение результатов классификации гибридной (StronglyEntanlingLayers) и классической (справа) моделей, обученных на Forest Cover Type для выборки из 150000 элементов
Таким образом, проведенное экспериментальное исследование демонстрирует практическую реализуемость методологии построения гибридных квантово-классических конвейеров и подтверждает их конкурентоспособную производительность. Хотя универсального превосходства гибридных моделей не выявлено, они проявляют структурные предпосылки, благоприятствующие расширенным возможностям обобщения, что наиболее выражено на структурированных данных с умеренным дисбалансом классов. В этих условиях гибридная архитектура продемонстрировала точность, сопоставимую с классическим MLP на выборках среднего объема.
Заключение
Проведенное исследование подтвердило эффективность предложенного подхода к интеграции квантовых вычислений в классические конвейеры анализа данных. Важным результатом является успешная реализация сквозного дифференцируемого конвейера обучения, обеспеченная интеграцией фреймворка для квантовых вычислений PennyLane с классическими библиотеками машинного обучения. На двух различных наборах данных с использованием трех альтернативных топологий запутывания была продемонстрирована способность гибридных моделей достигать качества классификации, сопоставимого с традиционными методами. Эксперименты выявили особенности применения различных схем запутывания: архитектура QAOAEmbedding показала наилучшие результаты на сбалансированных данных, в то время как другие конфигурации демонстрировали разную эффективность в зависимости от объема и структуры данных. Эти результаты создают основу для дальнейшего исследования оптимальных конфигураций гибридных моделей под специфические типы аналитических задач. Полученные результаты формируют методологическую основу для многопланового развития исследований в области гибридных квантово-классических вычислений. Перспективным направлением представляется комплексное изучение масштабируемости архитектур, включая анализ зависимости производительности от количества кубитов и глубины схем, а также разработку адаптивных методов подбора топологии запутывания под специфику решаемых задач. Существенный потенциал связан с расширением методологической базы через сравнительный анализ различных парадигм квантового машинного обучения и исследование влияния альтернативных схем кодирования классических данных. Значительное внимание следует уделить прикладным аспектам, в частности апробации данного подхода для наборов данных из различных предметных областей и интеграции разработанных решений в промышленные конвейеры анализа данных. Важным направлением развития данного исследования является совершенствование методов оптимизации, включая создание специализированных оптимизаторов для вариационных квантовых алгоритмов и разработку стратегий преодоления проблемы затухания градиентов. Реализация указанных направлений будет способствовать последовательному переходу от демонстрационных экспериментов к практическому применению гибридных квантово-классических моделей в реальных задачах анализа данных.
