Интеллектуальная система вопросов-ответов: интеграция баз знаний и языковых моделей для повышения эффективности обработки информации

Автор: И. М. Яхонтова, Н. М. Нетребин, А. Д. Стрелецкий
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (1), 2025 года.
Бесплатный доступ
В статье рассматриваются современные подходы к созданию интеллектуальных систем вопросов-ответов (Q&A), ориентированных на повышение эффективности обработки информации за счет интеграции баз знаний и языковых моделей. Основное внимание уделяется методу Retrieval Augmented Generation (RAG), который объединяет извлечение данных из базы знаний с генерацией ответов с использованием мощных языковых моделей. Данный метод позволяет улучшить качество ответов, повышая их релевантность за счет обработки предварительно найденной информации. В статье анализируются и сравниваются различные методы векторизации текста, включая One-hot encoding, TF-IDF, Word2Vec и BERT, с целью их адаптации к системам Q&A. Отдельное внимание уделено отечественным языковым моделям, таким как YandexGPT и GigaChat, которые демонстрируют высокую точность и производительность в условиях отечественного рынка и в контексте тенденций импортозамещения. В рамках работы проведены эксперименты на основе конфигурации 1С:Бухгалтерия предприятия 8, в ходе которых оценивались точность, релевантность и производительность различных систем вопросов-ответов. Результаты экспериментов показали, что предложенные подходы способны значительно повысить качество обработки запросов и предоставления информации. Новизна работы заключается в интеграции современных языковых моделей с базами знаний для создания эффективных систем Q&A, что открывает новые возможности для автоматизации бизнес-процессов и улучшения взаимодействия с информационными системами.
Retrieval Augmented Generation (RAG), языковые модели, векторизация текста, YandexGPT, GigaChat, 1С:Бухгалтерия, интеллектуальные системы вопросов-ответов, базы знаний
Короткий адрес: https://sciup.org/14133004
IDR: 14133004 | УДК: 004.934 | DOI: 10.47813/2782-2818-2025-5-1-1020-1026
Текст статьи Интеллектуальная система вопросов-ответов: интеграция баз знаний и языковых моделей для повышения эффективности обработки информации
DOI:
В эпоху стремительного роста объемов данных эффективный доступ к информации становится критически важным для решения широкого спектра задач – от научных исследований до повседневной жизни. Традиционные поисковые системы, основанные на ключевых словах, зачастую не способны адекватно обрабатывать сложные запросы, сформулированные на естественном языке, и не всегда предоставляют релевантную информацию, особенно при работе с неструктурированными данными.
Интеллектуальные системы вопросов-ответов, использующие методы искусственного интеллекта (ИИ), предлагают качественно новый подход к поиску и обработке информации. Они способны анализировать смысл запросов пользователей, искать релевантную информацию в обширных базах знаний и генерировать готовые, понятные человеку ответы. В последние годы на российском рынке наблюдается активное развитие таких систем [1].
Другим примером является исследование развитие глубокого обучения привело к широкому использованию различных нейронных сетей для решения задач обработки естественного языка (NLP), включая свёрточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), нейронные сети на основе графов (GNN) и механизмы внимания [2].
Данная статья посвящена анализу современных подходов к разработке таких систем, с особым акцентом на метод Retrieval Augmented Generation (RAG).
МАТЕРИАЛЫ И МЕТОДЫ
Создание эффективных систем вопросов-ответов требует интеграции баз знаний, содержащих необходимую информацию, и языковых моделей, способных понимать и генерировать текст на естественном языке [3]. Существует несколько подходов к реализации такой интеграции. Один из них – fine-tuning языковых моделей на базе знаний. Этот подход предполагает дообучение предварительно обученной языковой модели на данных из конкретной базы знаний. В результате модель «усваивает» специфику предметной области и генерирует более точные и релевантные ответы. Однако данный подход требует значительных вычислительных ресурсов и времени на обучение [4].
Другим подходом является создание специальных нейронных архитектур, которые одновременно обрабатывают запрос пользователя и информацию из базы знаний. Такие модели могут быть более эффективными, чем просто дообученные языковые модели, но их разработка требует глубоких знаний в области обработки естественного языка (NLP) и машинного обучения [5].
Наиболее перспективным подходом на сегодняшний день является метод Retrieval Augmented Generation (RAG). RAG комбинирует преимущества алгоритмов поиска информации (Information Retrieval) и языковых моделей (Language Models). Вместо того, чтобы «скармливать» языковой модели всю информацию из базы знаний, RAG сначала ищет наиболее релевантные фрагменты, а затем передает их модели для генерации ответа. Пример работы RAG представлен на рисунке 1.
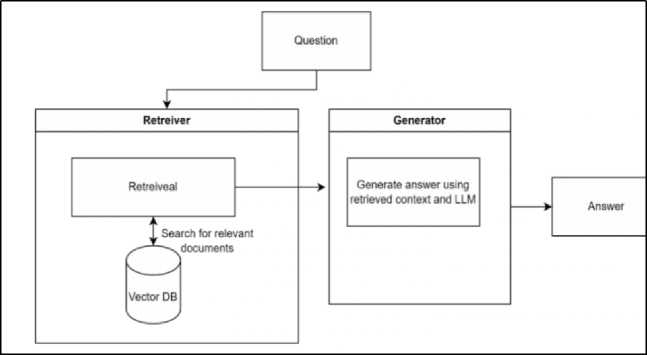
Рисунок 1. процесс работы метода RAG.
Figure 1. RAG method working process.
Метод RAG основан на поиске релевантных фрагментов текста в базе знаний, семантически близких к запросу пользователя. Для реализации такого поиска необходимо преобразовать текстовую информацию в числовые векторы, отражающие ее смысл [6]. Этот процесс называется векторизацией [7].
Существует широкий спектр методов векторизации, от простых до сложных, основанных на нейронных сетях. Рассмотрим некоторые из них:
-
• One-hot encoding: этот метод представляет каждое слово в виде вектора, где все элементы равны 0, кроме одного, который соответствует номеру слова в словаре и равен 1. One-hot encoding прост в реализации, но не учитывает смысловые связи между словами и неэффективен для больших словарей [8].
-
• Bag of Words (BoW): этот метод
представляет текст в виде «мешка слов», подсчитывая частоту встречаемости каждого слова в документе. BoW не учитывает порядок слов и грамматическую структуру текста, но достаточно эффективен для некоторых задач, таких как классификация текстов.
• BERT (Bidirectional Encoder
Representations from Transformers): BERT – одна из самых современных и эффективных моделей векторизации, основанная на архитектуре трансформера. BERT учитывает контекст слова как слева, так и справа, что позволяет ему генерировать более точные и контекстуализированные векторные представления. BERT показал отличные результаты во многих задачах NLP, таких как классификация текстов, вопросно-ответные системы и машинный перевод.
Выбор метода векторизации зависит от конкретной задачи и доступных ресурсов. Для метода RAG важно выбрать метод, который обеспечивает достаточно точное и эффективное представление смысла текста.
РЕЗУЛЬТАТЫ
Языковые модели играют ключевую роль в методе RAG, генерируя ответы на запросы пользователей на основе информации, извлеченной из базы знаний. Современные языковые модели – это сложные нейронные сети, обученные на огромных объемах текстовых данных. Они способны понимать естественный язык, генерировать связный и грамматически корректный текст, переводить с одного языка на другой, писать различные виды творческого контента и отвечать на вопросы в информативном виде [9].
В контексте данного исследования особый интерес представляют большие языковые модели (Large Language Models, LLM), такие как GPT-3, YandexGPT, GigaChat и другие. LLM обладают высокой способностью к пониманию и генерации естественного языка, что делает их идеальным инструментом для создания систем вопросов-ответов.
В условиях импортозамещения приоритетным является использование отечественных разработок. YandexGPT и GigaChat – это мощные языковые модели, разработанные российскими компаниями. Они демонстрируют конкурентоспособные результаты и активно развиваются, что делает их перспективным инструментом для создания систем вопросов-ответов на русском языке.
Для эмпирической оценки эффективности метода RAG и сравнения различных языковых моделей был проведен ряд экспериментов с использованием базы знаний по конфигурации 1С:Бухгалтерия. База знаний представляла собой документ «Покупки.pdf», содержащий инструкцию по работе с разделом «Покупки» в программе. Этот документ был выбран в качестве репрезентативного примера технической документации, характеризующейся специфической терминологией и сложной структурой изложения.
Для тестирования была разработана серия вопросов, охватывающих различные аспекты работы с разделом «Покупки». Вопросы были сформулированы на естественном языке, имитируя типичные запросы пользователей [10].
В эксперименте были сравнены три системы вопросов-ответов, основанные на различных языковых моделях:
-
• YandexGPT (lite): упрощенная версия
YandexGPT с методом векторизации TF-IDF.
-
• SaluteBot: чат-бот, интегрированный с
GigaChat, с автоматической настройкой метода векторизации.
-
• FractalGPT (демо): демоверсия системы FractalGPT с собственными алгоритмами поиска и обработки информации.
Полученные ответы были оценены по следующим критериям: точность, релевантность и скорость генерации ответа. Результаты эксперимента представлены в таблице 1.
Таблица 1. Результат эксперимента по тестированию языковых моделей.
Table 1. Result of the experiment on testing language models.
|
Вопрос |
YandexGPT (lite) |
SaluteBot |
FractalGPT (демо) |
|
Верных ответов |
3.5 из 6 |
6 из 6 |
5 из 6 |
|
Счет от поставщика создается автоматически? |
+ Счет создается при электронном документообороте |
+ Счет создается при электронном документообороте |
+ Счет создается при электронном документообороте |
|
Настройка для работы со счетами |
+ Настройки → Функциональность → Документы → Счета |
+ Включена настройка «Счета, акты и накладные» |
- Настройка «Функциональность Документы» включена |
|
Как отразить доп. расходы? |
+ Открыть раздел «Документы», создать «Поступление доп. расходов», распределить расходы |
+ Открыть «Документы», создать «Поступление доп. расходов», распределить расходы |
+ Создать «Поступление доп. расходов», распределить расходы |
|
Как исправить ошибку поставщика? |
- Нет информации в тексте |
+ Создать «Корректировка поступления», указать исправление |
+ Создать «Корректировка поступления», выбрать исправление в первичных документах |
|
Изменение стоимости товара поставщиком |
- Создать документ Счёт-фактура полученный |
+ Создать «Корректировка поступления», выбрать «Корректировка по согласованию сторон» |
+ Создать «Корректировка поступления», выбрать тип операции |
|
Передача товара принципалу |
- Использовать документ «Передача товаров комиссионеру (агенту)» |
+ Использовать документ «Передача товаров комитенту» |
+ Использовать документ «Передача товаров комитенту» |
Представленная таблица построена с целью наглядного сравнения эффективности трёх различных систем вопросов-ответов по ключевым параметрам: точности предоставляемых ответов, релевантности информации и времени генерации ответа. Из данных таблицы видно, что система SaluteBot демонстрирует наилучшие показатели – она отвечает правильно на все тестовые вопросы, обеспечивает высокую релевантность ответов и, судя по дополнительным параметрам, работает быстрее по сравнению с альтернативными решениями.
Такой подход к сравнительному анализу позволяет не только оценить текущее состояние технологий в сфере интеллектуальных систем вопросов-ответов, но и выявить ключевые направления для их дальнейшего совершенствования. Полученные результаты подтверждают, что интеграция отечественной модели GigaChat в платформу SaluteBot является эффективной стратегией, позволяющей повысить качество обработки запросов, что особенно актуально в условиях импортозамещения.
ОБСУЖДЕНИЕ
Проведенное исследование подтвердило эффективность метода Retrieval Augmented Generation (RAG) для создания интеллектуальных систем вопросов-ответов. RAG позволяет комбинировать сильные стороны алгоритмов поиска информации и языковых моделей, обеспечивая высокую точность, релевантность и скорость генерации ответов. Выбор оптимальных методов векторизации текста и языковой модели является ключевым фактором для создания эффективной системы [11].
В условиях импортозамещения особое значение приобретают отечественные разработки в области ИИ. Эксперименты показали, что российская языковая модель GigaChat, интегрированная в платформу SaluteBot, демонстрирует высокую эффективность и является перспективным инструментом для создания интеллектуальных систем вопросов-ответов на русском языке. Простота использования, гибкость и доступность SaluteBot делают эту платформу привлекательным решением для широкого круга пользователей.
ЗАКЛЮЧЕНИЕ
В результате проведённого исследования было установлено, что интеграция баз знаний с современными языковыми моделями посредством метода Retrieval Augmented Generation (RAG) существенно повышает качество формирования ответов в системах вопросов-ответов. Экспериментальная оценка, проведённая на материале технической документации (документ «Покупки.pdf» в конфигурации 1С:Бухгалтерия), продемонстрировала, что применение предварительного отбора релевантных фрагментов текста позволяет добиться более высокой точности, релевантности и скорости генерации ответов. Кроме того, сравнительный анализ методов векторизации показал, что современные подходы (такие как BERT) обеспечивают более глубокое семантическое представление текста, а отечественные языковые модели (например, GigaChat, интегрированная в SaluteBot) демонстрируют конкурентоспособные результаты в условиях импортозамещения.
Дальнейшие исследования в данной области могут быть направлены на совершенствование методов векторизации текста, разработку новых архитектур языковых моделей, специализированных для задач вопросов-ответов, а также на создание автоматизированных механизмов оценки качества генерируемых ответов и обнаружения «галлюцинаций». Реализация этих направлений позволит не только повысить эффективность обработки запросов, но и расширить спектр применения интеллектуальных систем для автоматизации бизнес-процессов и улучшения взаимодействия с информационными системами.
