Интеллектуальные технологии слияния данных при диагностировании технических объектов

Автор: Ковалев С.М., Колоденкова А.Е., Снасель В.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Методы и технологии принятия решений
Статья в выпуске: 1 (31) т.9, 2019 года.
Бесплатный доступ
Слияние разнородных данных, полученных в реальном времени от различных датчиков, является важной задачей при диагностировании технических объектов. В статье рассмотрены вопросы терминологии слияния данных на основе обзора литературы, предложено новое определение термина «слияние данных». Обобщены и систематизированы научные взгляды на проблему слияния данных при диагностировании технических объектов в условиях множества разнотипных датчиков и разнородной информации. Приведена адаптированная классификация слияния данных с учётом различных критериев (отношения между датчиками, уровень абстракции данных, тип архитектуры), а также классификация структурных моделей слияния данных, разработанных для построения интеллектуальных систем слияния данных. Проведён сравнительный анализ моделей процесса слияния данных, представлены их структуры, выявлены достоинства и недостатки моделей. Отмечено, что для эффективного сбора исходных данных, поступающих от множества разнотипных датчиков, и их обработки можно использовать несколько моделей слияния данных или их комбинации. Все основные аспекты, касающиеся интеллектуальных технологий слияния данных, рассмотрены в столь полном объёме на русском языке впервые.
Разнородные данные, модели слияния данных, диагностирование технических объектов, множество разнотипных датчиков
Короткий адрес: https://sciup.org/170178810
IDR: 170178810 | УДК: 004.891 | DOI: 10.18287/2223-9537-2019-9-1-152-168
Intellectual technologies of data fusion for diagnostics of technical objects
Fusion of heterogeneous data in real time is an important task in the diagnosis of technical objects. This is due to the need of taking into account not only the data coming from the sensors, but also external factors affecting the technical object. The article addresses problems of data fusion terminology on the basis of a review of the national and foreign literature. New definition of the term "data fusion" is proposed. Different scientific views of domestic and foreign experts on a problem of data fusion for diagnosing of technical objects in presence of different types of sensors and heterogeneous information are generalized and systematized. The adapted classification of data fusion, taking into account various criteria (the relations between sensors, the level of abstraction of data, architecture type), is presented. Classification of structural models of data fusion, developed for creation of intellectual systems of data fusion is given. Models of process of data fusion are investigated, their structures are presented, model merits and demerits are revealed. It is noted that for effective collecting of the basic data, arriving from of different types of sensors, and its processing it is possible to use several models of data fusion or their combination. It will allow making scientifically based management decisions when diagnosing difficult technical objects. While a lot of works of foreign researchers are devoted to separate sections of data fusion technologies, the paper presents the first full research in Russian where all the main aspects that belong to the intellectual technologies of data fusion are considered.
Текст научной статьи Интеллектуальные технологии слияния данных при диагностировании технических объектов
С развитием сложности, масштабности, многофункциональности технических объектов (ТО) первостепенное значение приобретает проблема эффективной и безопасной эксплуатации ТО. Это связано с тем, что ухудшение технического состояния на этапе эксплуатации ТО приводит к нарушению его работоспособности (отказу), выражающемуся в изменении значений параметров его работы за пределами, регламентируемыми нормативно-техническими документами, или к полной его остановке, что может привести к значительному материальному ущербу, а также нарушению экологической обстановки.
Одним из способов решения данной проблемы является автоматизация и информатизация процессов контроля и диагностирования, в ходе которых решают такие задачи, как определение вида технического состояния, обнаружение неисправностей, прогнозирование технического состояния в условиях использования различных типов датчиков. Увеличение количества различных типов датчиков, разнородных диагностических данных привело к необ- ходимости применения технологии слияния данных. Разработка этой технологии для диагностирования ТО даёт выигрыш по сравнению с раздельной обработкой за счёт расширения объёма получаемых диагностических данных и синергетического эффекта. Достоинствами данной технологии являются: сохранение надёжности ТО в случае отказа какого-либо датчика; рост вероятности обнаружения нештатных ситуаций; уменьшение времени принятия решений при диагностировании ТО в силу получения более полной и точной информации о ТО, поступающей от множества разнородных датчиков.
Цель статьи - дать анализ существующих технологий слияния данных для решения задач технического диагностирования ТО. Авторы попытались не только обобщить научные взгляды на проблему слияния данных [1-5], но и представить свой опыт, полученный при диагностировании ТО.
1 Проблемы слияния данных
С увеличением количества типов датчиков данных и объёма информации возникла необходимость в обработке разнородных данных для последующего анализа. Обработку таких данных понимают как соединение, комплексирование, интеграцию, объединение, сращивание (в англоязычной литературе часто называют «слияние данных» - data fusion ) [3-7].
В настоящей работе под слиянием данных понимается совместная обработка разнородной информации, полученной в реальном времени от множества различных датчиков, в информацию, легко воспринимаемую человеком, на основе которой можно контролировать ТО, проводить оценку ситуации и принимать научно-обоснованные управленческие решения [8]. Несмотря на многочисленные применения технологии слияния разнородных данных при диагностировании ТО, остаётся ряд основных проблем.
-
■ Разнородность данных . Данные от датчиков могут быть представлены в виде разнородных данных и характеризоваться [9]: разнообразием шкал измерения (номинальной, числовой и др.); различными типами данных (целый, вещественный, логический и др.); различной структурой представления (статистические, темпоральные, нечёткие, экспертные данные, изображения и др.); различными типами моделей баз данных (реляционные, иерархические, сетевые и др.); различной степенью достоверности, полноты и точности данных, измеряемых в различных масштабах и единицах измерения.
-
■ Точность датчиков. Часто применяются многопараметрические датчики, которые способны измерять одновременно несколько физических величин, характеризующих контролируемый объект или процесс. Объединяя данные от нескольких одинаковых датчиков, можно улучшить их качество, а также повысить
их точность и достоверность.
-
■ Выбор метода слияния данных . Не существует универсального метода слияния данных, который был бы оптимален при всех условиях.
-
■ Терминология . Спецификации данных выполняются различными экспертами, которые могут использовать одинаковые термины в различном смысле и, наоборот, для одного и того же понятия могут использовать различные названия. Для решения данной проблемы целесообразно использовать единый словарь терминов предметной области.
-
■ Идентификация сущностей . Информация об одной и той же сущности (ситуации, состоянии объекта, процессе и т.п.) представляется в распределённой форме [6, 9]. Для решения проблемы целесообразно установить однозначное соответствие между описаниями, которые находятся в различных локальных датчиках, но относятся к одному экземпляру сущности предметной области.
2 Классификация слияния данных
Ввиду многодисциплинарности области исследований предлагается слияние данных классифицировать по нескольким критериям (рисунок 1 адаптирован по материалам [10-12]). Слияние данных по критерию отношений между датчиками представлено на рисунке 2 (адаптирован по материалам [2, 13, 14]).
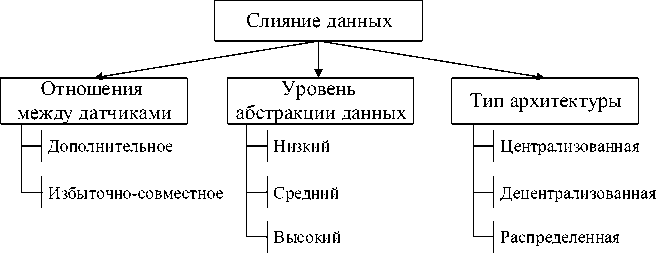
Рисунок 1 - Классификация слияния данных
Достижения
Точность и надежность
Полнота, формирование взгляда
Результаты слияния данных
Слияние данных
Данные
Датчики
Окружающая среда
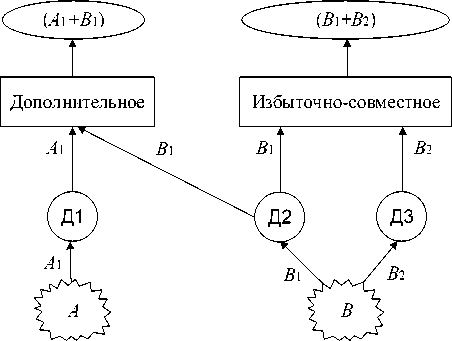
Рисунок 2 - Типы слияния данных на основе отношений между датчиками
Дополнительное ( complementary ) слияние - это слияние, при котором независимые датчики (Д 1 и Д2, принадлежащие различным частям пространства окружающей среды) могут быть объединены ( A 1 + B 1 ) для того, чтобы дать более полное представление наблюдаемому явлению (ситуации). Данные от независимых датчиков легко объединяются.
Избыточно-совместное ( competitive-cooperative ) слияние - это слияние, где каждый датчик (Д2 и Д з ) поставляет информацию об одной и той же характеристики ТО, в результате которого достигается более точное представление этой информации ( B 1 + B 2). Различают две возможные конфигурации избыточно-совместного слияния данных: с разных датчиков или слияние измерений с одного датчика, сделанных в разные моменты времени. Избыточносовместное слияние используется для отказоустойчивых и надёжных систем.
Согласно уровню абстракции данных ( level of abstraction ) слияние данных может быть классифицировано на три уровня (см. таблицу 1) [13].
-
■ Низкий уровень слияния ( low-level fusion ), именуемый часто уровнем необработанных данных ( raw data level), поступающих от датчиков. На данном уровне может применяться нечёткий фильтр Калмана.
-
■ Средний уровень слияния ( medium-level fusion ), именуемый часто уровнем свойств (feature level ). На данном уровне происходит слияние свойств (форма, рёбра, углы, линии, положение), в результате которого получаются новые объекты, используемые для других задач, например, сегментации и распознавания. Также происходит фильтрация, нормализация, корреляция, классификация данных с использованием методов «мягких вычислений» и методов интеллектуального анализа данных.
-
■ Высокий уровень слияния ( high-level fusion ), именуемый часто уровнем решения ( decision level ). Слияние на уровне решения происходит с использованием интеллектуальных методов: теории нечётких множеств, нейронных сетей, теории Демпстера-Шефера ( Dempster-Shafer ), Байесовского подхода, гибридных подходов, в результате которых получается совместное решение о диагностировании ТО с учётом разнородных данных, полученных от нескольких датчиков, а также мнений и решений нескольких экспертов.
Таблица 1 - Основные характеристики уровней слияния данных
|
" "—-—— Уровни Характеристики " "—-—---------- |
Низкий |
Средний |
Высокий |
|
Объём передаваемой информации |
очень большой |
средний |
очень маленький |
|
Информационные потери |
без потерь |
немного |
средние |
|
Математические вычисления |
простые |
средние |
сложные |
Как видно из таблицы 1, потеря информации увеличивается по мере её передачи с низких уровней на более высокие. При этом информации на низком уровне больше, чем на высоком, что делает методы низкого уровня дорогостоящими за счёт требований, предъявляемых к точности их вычислений.
На рисунках 3-5 показаны три типа архитектур слияния данных с несколькими датчиками (рисунки 3-5 адаптированы по материалам [14-16]).
-
■ Централизованная архитектура ( centralized architecture ) (рисунок 3).
x 1,1 , —, x 1, p
x 2,1, —, x 2, q

x n ,1 ,- —, x n , m
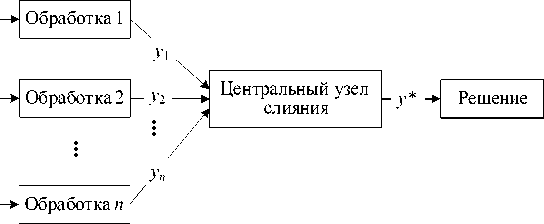
Рисунок 3 - Централизованная архитектура
Все собранные данные от датчиков (Д 1 , Д2,..., Д n ) будут обработаны и отправлены в центральный узел слияния, который способен эффективно обрабатывать большие объёмы данных. Если данные правильно выровнены и связаны, а объём передаваемой информации не ограничен, то централизованная архитектура позволяет дать теоретическое оптимальное решение для оценки состояния ТО. Однако обработка всей информации на центральном узле создаёт проблемы, такие как большая вычислительная нагрузка на центральный узел, возможность сбоя работы центрального узла, негибкость изменений в архитектуре [1, 11].
Если данные представляют собой изображения, то это приводит к низкой пропускной способности отправки необработанных данных и задержки с выводом данных.
-
■ Децентрализованная архитектура ( decentralized architecture ) (рисунок 4).
Данная архитектура состоит из нескольких локальных процессоров, которые в соответствии со своим наблюдением вычисляют параллельно локальные оценки. Центральный центр слияния отсутствует, поэтому сначала каждый локальный процессор вычисляет локальную оценку, а затем корректирует её путём интегрирования локальных оценок других процессоров для получения точной и полной оценки. Результатом применения децентрализованной архитектуры является множество решений, из которых выбирается одно наилучшее. Увеличение числа узлов приводит к увеличению стоимости связи, что является одним из недостатков децентрализованной архитектуры.
x 2,1
x n ,1
, x 1, p
, x 2, q
, x n , m
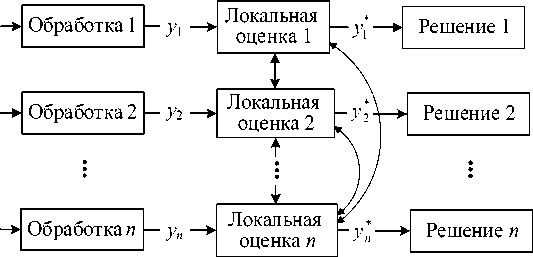
Рисунок 4 – Децентрализованная архитектура
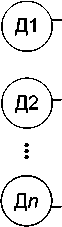
x1,1,…, x1,p x2,1,…, x2,q xn,1,…, xn,m
■ Распределённая архитектура ( distributed architecture ) (рисунок 5).
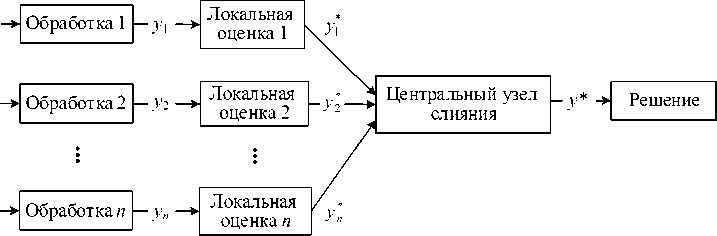
Рисунок 5 – Распределённая архитектура
Данная архитектура состоит из нескольких локальных процессоров, вычисляющих параллельно локальные оценки. Затем все собранные локальные оценки отправляются для обработки в центральный узел слияния с целью получения совместного решения. При этом локальные процессоры не сливают свои оценки с оценками, полученными от других процессоров, как в децентрализованной архитектуре, а передают их сразу в центральный узел слияния. При распределённой архитектуре за счёт распределения нагрузки достигается низкая нагрузка на каждый локальный процессор при вычислении оценки; более низкая стоимость связи, гибкость к изменениям и устойчивость к неудачам.
3 Структурные модели слияния данных
Получение нового качества данных, а именно полных, точных, своевременных данных, которые поддаются интерпретации, является наиболее сложным этапом преобразования данных интеллектуальных систем. Одним из путей решения данной проблемы явилась разработка моделей слияния данных. В настоящее время предложено несколько моде-
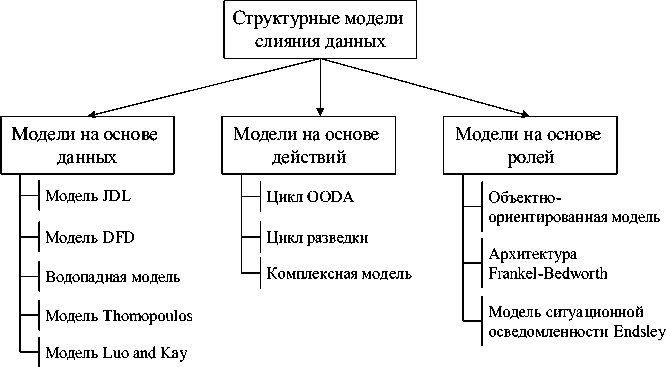
Рисунок 6 – Классификация моделей слияния данных
лей слияния данных, разработанных для выделения спецификаций, предложений и использования слияния данных в беспроводной сенсорной сети, которая представляет собой распределённую самоорганизующуюся сеть множества датчиков и исполнительных устройств, объединённых между собой посредством радиоканала. Модели слияния данных можно разделить на три основных вида: модель на основе данных, модель на основе действий и модель на основе ролей, как показано на рисунке 6 (адаптирован по материалам [17, 18]).
-
3.1 Модели на основе данных (data-based model)
-
3.1.1 Модель JDL (Joint Directors of Laboratories)
-
Самой известной моделью в области слияния данных является модель JDL , предложенная исследовательской группой Joint Directors of Laboratories совместно с Министерством обороны США [18]. Модель рассчитана на связи между исследователями слияния данных и инженерами по внедрению [19-21].
На рисунке 7 представлена структура модели слияния JDL . Модель JDL включает следующие уровни обработки данных.
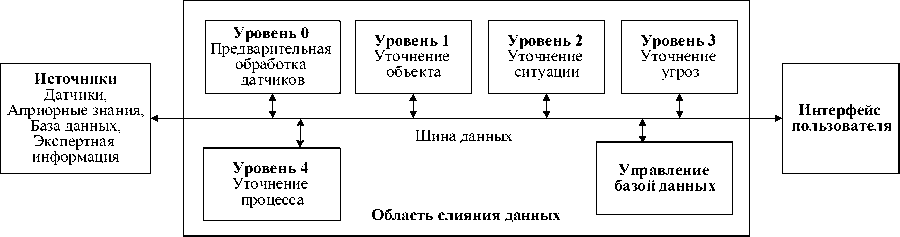
Рисунок 7 – Структура модели слияния JDL
-
■ Уровень 0 (предварительная обработка датчиков, source preprocessing ) направлен на уменьшение объёма данных для последующих уровней обработки за счёт распределения данных между подходящими процессами и выбора подходящих датчиков.
-
■ Уровень 1 (уточнение объекта, object refinement ) преобразует данные в согласованную структуру. На данном уровне происходит идентификация данных с применением, например, методов классификации или распознавания, а также локализация датчика; применяются алгоритмы отслеживания местонахождения объекта.
-
■ Уровень 2 (уточнение ситуации ( situation refinement )) обеспечивает контекстное описание отношений между объектами и исследуемым (наблюдаемым) событием. На данном уровне используется априорная информация, знания и сведения об окружающей среде.
-
■ Уровень 3 (уточнение угроз ( threat refinement )) оценивает текущую ситуацию и на её основе выявляет возможное возникновение угроз, уязвимостей и возможностей для оперативных действий.
-
■ Уровень 4 (уточнение процесса (process refinement )) отвечает за мониторинг работы системы, распределение ресурсов в соответствии с заданными целями. Могут использоваться, например, теория полезности, линейное программирование, методы, основанные на знаниях.
-
3.1.2 Модель DFD (Data-Feature-Decision)
Модель JDL рассматривает слияние данных с точки зрения системного подхода и даёт целостное представление о структуре системы. При этом она фокусируется на данных (ввод/вывод), а не на обработке; роль человека в процессе слияния не представлена [1, 19]. Методы и алгоритмы слияния данных модели JDL, рассмотрены в работе [16].
Предложенная В. Дасараты ( V. Dasarathy [22]) модель DFD (рисунок 8) определяет элементы процесса слияния данных, которые задаются на основе входных (необработанных данных) и выходных данных (некоторого решения) и способствует установлению связей между данными и задачами. Подробное описание модели DFD дано в работах [21, 22].
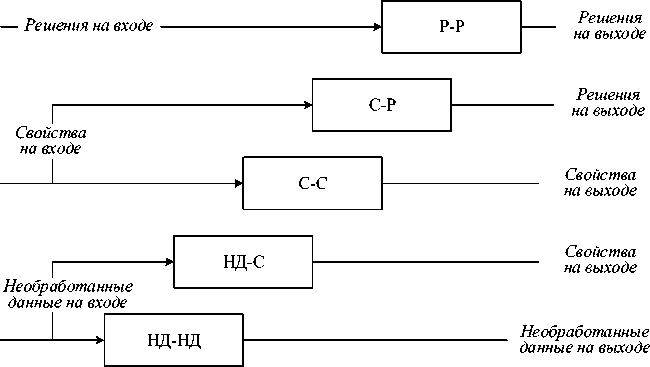
Рисунок 8 - Структура модели DFD
Модель DFD имеет пять уровней.
-
■ Необработанные данные на входе - Необработанные данные на выходе (НД-НД) ( Data In-Data Out ( DAI-DAO )). Слияние осуществляется сразу после того, как данные получены с датчиков. Результатом слияния необработанных данных являются такие же данные, только более точные или надёжные.
-
■ Необработанные данные на входе - Свойства на выходе (НД-С) ( Data In-Feature Out ( DAI-FEO )). На данном уровне для слияния используются необработанные данные, полученные от датчиков, для извлечения свойств, описывающих ТО либо ситуацию.
-
■ Свойства на входе - Свойства на выходе (С-С) ( Feature In-Feature Out ( FEI-FEO )). На данном уровне происходит работа над набором свойств для получения нового набора свойств с целью их улучшения/уточнения или извлечения новых.
-
■ Свойства на входе - Решения на выходе (С-Р) ( Feature In-Decisions Out ( FEI-DEO )). Для получения решений используются наборы свойств ТО или ситуации.
-
■ Решения на входе - Решения на выходе (Р-Р) ( Decisions In-Decisions Out ( DEI-DEO )). Данный уровень объединяет входные решения для получения новых решений.
-
3.1.3 Водопадная модель (Waterfall model)
Модель DFD полезна для разработки алгоритмов слияния в беспроводной сенсорной сети, однако не предоставляет системного представления, как модель JDL. Вместо этого модель DFD предоставляет детальный подход к определению задач слияния с помощью ожидаемых входных и выходных данных.
Модель, предложенная С. Харрисом ( C.J. Harris ) [23], представляет собой иерархическую структуру, где информация, произведённая одним модулем, используется в следующем модуле. Последний модуль (принятие решений) передаёт достаточное количество информации в модуль контроля для калибровки и настройки датчиков.
На рисунке 9 представлена структура водопадной модели, имеющая 3 уровня, каждый из которых включает два модуля и замкнутый цикл для работы в системе [24, 25].
Уровень 3
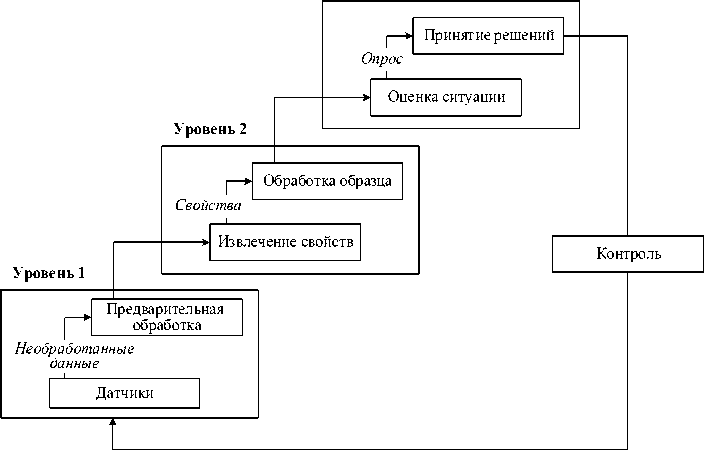
Рисунок 9 – Структура водопадной модели
-
■ Уровень 1. Данные из окружающей среды собираются и обрабатываются. На следующий уровень поступают не только обработанные данные, но и информация о датчиках.
-
■ Уровень 2. Извлекаются основные свойства ТО, а затем сливаются, тем самым снижая количество передаваемых данных и увеличивая их информационную насыщенность.
-
■ Уровень 3. Разрабатываются различные сценарии ситуаций, а также действия для конкретных ситуаций, действий в понятной форме, осуществляются оценки ситуаций. Принимается решение на основе информации, собранной с предыдущих уровней, составляются возможные пути действий для определённой ситуации.
-
3.1.4 Модель Томопулоса (Thomopoulos Model)
Водопадная модель является более точной в анализе процесса слияния данных, чем другие модели. Однако она имеет ряд недостатков: отсутствие описания обратной связи потока данных; указаний на то, должны ли датчики быть параллельными или последовательными, хотя обработка информации – последовательная [24, 26].
В работах [4, 27] предложен механизм обратной связи с тем, чтобы информация, поступающая к датчикам из модуля принятия решений, постоянно обновлялась.
Данная модель была предложена С. Томопулосом ( S.C. Thomopoulos , 1989) [28] и представляет трёхуровневую модель, сформированную на основе уровня сигнала ( signal level ), уровня доказательств ( evidence level ) и уровня динамики ( dynamics level ) (рисунок 10).
На каждом уровне собранные данные сталкиваются с ранее обработанными и сохранёнными данными, сохраняя при этом заданный порядок, что означает необходимость решения проблем с задержкой или ошибками в передаче данных. В зависимости от применения эти уровни слияния могут быть реализованы последовательно или поочередно [4, 25].
После того, как датчики проследили за ТО, они выводят свои измерения. Затем
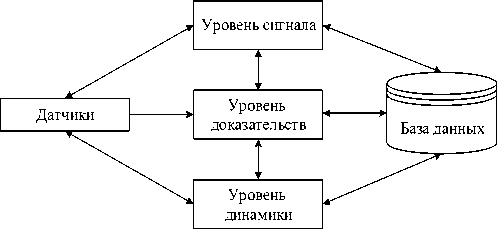
Рисунок 10 – Структура модели Thomopoulos
уровень сигнала обрабатывает эти данные, выполняя корреляции из-за отсутствия математической модели. Поэтому в процессе обучения собранные данные соотносятся с информацией, ранее сохранённой в базе данных. На уровне доказательств данные объединяются на различных уровнях вывода на основе статистической модели и оценки, требуемой пользователем (например, принятие решений или тестирование гипотез). Недостатком данной модели является отсутствие математической модели, описывающей процесс сбора данных.
-
3.1.5 Moдель Ло и Кей (Luo and Kay)
-
3.2 Модели на основе действий (activity-based model)
-
3.2.1 Цикл OODA
Данная модель представлена Ло и Кей ( Luo & Kay , 1998) [29] как общая структура слияния данных, основанная на иерархической модели, но отличающаяся от водопадной модели (рисунок 11). В данной модели данные от датчиков попадают на различные центры слияния, тем самым повышая уровень представления от необработанных данных к решениям.
Из рисунка 11 видно, что в системе присутствуют три функции, которые обычно используются в процессе слияния: выбор датчика, модель ситуации, преобразование данных. Линии от системы к каждому узлу слияния представляют собой любой из возможных сигналов [4, 24, 27]. Данная модель предполагает параллельный ввод и обработку данных, которые могут входить в систему на разных уровнях слияния. Модель основана на децентрализованной архитектуре и не предполагает контроля обратной связи [24].
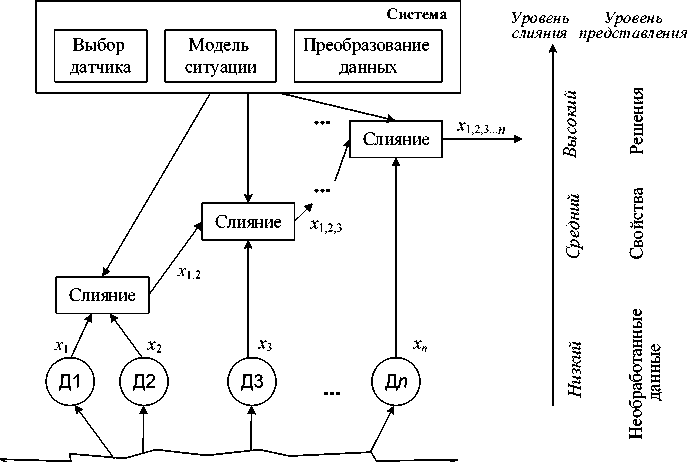
Окружающая среда
Рисунок 11 – Структура модели Luo и Kay
Данные модели определяются на основе определённой последовательности действий, которые указываются и должны выполняться интеллектуальной системой слияния данных.
Цикл OODA (O – observe , O – orient , D – decide , A – act ), предложенный Дж. Бойдом ( J.R. Boyd ) [30], рассматривается в качестве единой типовой модели цикла принятия решений для систем командования и управления.
На рисунке 12 представлен цикл OODA , предполагающий многократное повторение четырёх последовательных взаимосвязанных действий [17, 20, 21].
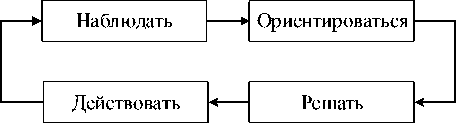
Рисунок 12 – Цикл OODA
-
■ Наблюдать ( observe ). Осуществляется сбор данных из доступных различных
датчиков.
-
■ Ориентироваться ( orientate ). Осуществляется слияние собранных данных с тем, чтобы получить интерпретацию текущей ситуации.
-
■ Решать ( decide ). Определяется план действий в ответ на понимание ситуации.
-
■ Действовать ( act ). Выполняется план.
-
3.2.2 Цикл разведки (intelligence cycle)
Данный цикл имеет обратную связь, позволяет проводить полный обзор и разделять системные задачи. Однако из-за своей структуры не обеспечивает надлежащее представление слияния данных [20], а также не показывает результат этапа «действовать» на других этапах.
Цикл разведки описывает процесс от сбора необработанных данных до выдачи готовых обработанных данных, которые могут использоваться при принятии решений [31]. На рисунке 13 представлены
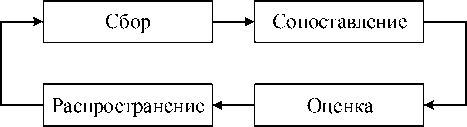
четыре этапа цикла разведки . Рисунок 13 – Этапы цикла разведки
-
■ Сбор ( collection ). Собираются необработанные данные от датчиков.
-
■ Сопоставление ( collation ). Собранные данные анализируются, сравниваются между собой, проводится корреляция. Неважные и ненадёжные данные отбрасываются.
-
■ Оценка ( evaluation ). Собранные данные обрабатываются, а затем анализируются.
-
■ Распространение ( dissemination ). Результаты слияния предоставляются пользователям для выработки решений и действий в ответ на выявленные ситуации.
-
3.2.3 Комплексная модель (Omnibus Model)
В отличие от цикла OODA, цикл разведки не делает явными этапы решения и исполне- ния, которые включены в этапы оценки и распространения. Цикл разведки является общим и может быть использован в любой области применения. Однако он не выполняет конкретные задачи, касающиеся слияния данных.
Комплексная модель, предложенная М. Бедворсом ( M.D. Bedworth ) и Дж. Брайном ( J.C. Brien ) [32], организует этапы слияние данных точно так же как цикл разведки и OODA . Подробное описание модели представлено в работах [17, 21, 25, 33]. На рисунке 14 представлена структура комплексной модели, состоящая из четырёх этапов.

Рисунок 14 – Структура комплексной модели
|
Слияние данных |
Извлечение свойств |
|
|
Слияние свойств |
||
|
Слияние решений |
Принятие решений |
-
■ Восприятие и обработка данных, поступающих от различных датчиков.
-
■ Извлечение свойств из собранных данных, которые затем сливаются.
-
■ Принятие решений о наиболее подходящем плане действий.
-
■ Действие по выполнению выбранного плана.
-
3.3 Модели на основе ролей (role-based model)
-
3 .3.1 Объектно-ориентированная модель (object-oriented model)
Комплексная модель является циклической по структуре, при этом может быть использована несколько раз для одного и того же приложения. Однако она не поддерживает декомпозицию задач на модули, поэтому её необходимо реализовывать и использовать отдельно для различных применений.
Данные модели определяются на основе ролей слияния и взаимосвязей между ними, тем самым обеспечивая более детальную модель для интеллектуальных систем слияния данных и системный подход к слиянию данных, однако при этом не указываются задачи слияния. Вместо этого для слияния данных они предоставляют набор функций и определяют отношения между ними [21].
Для слияния данных М. Кокар ( M. Kokar ) предложил воспользоваться объектноориентированной моделью, состоящей из четырёх ролей [21, 34] (рисунок 15).
|
Директор |
Обработанная информация
|
Получатель |
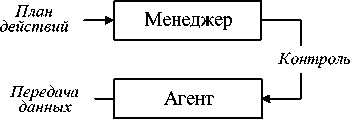
Рисунок 15 – Структура объектно-ориентированной модели
-
■ Агент ( actor ) взаимодействует с окружающей средой, собирает данные.
-
■ Получатель (perceiver ) проводит анализ, оценивает полученные данные после сбора данных, а затем передаёт директору.
-
■ Директор ( director ) строит план действий с указанием целей системы на основе анализа, предоставленного получателем.
-
■ Менеджер ( manager ) контролирует агентов для выполнения планов, разработанных директором.
-
3 .3.2 Архитектура Франкеля-Бедворта (Frankel-Bedworth)
Данная модель описывает различные роли системы, однако при этом не рассматривает системные задачи.
Б. Франкель предложил архитектуру, состоящую из двух саморегулирующихся процессов, у которых разные цели и роли [17, 35] (рисунок 16):
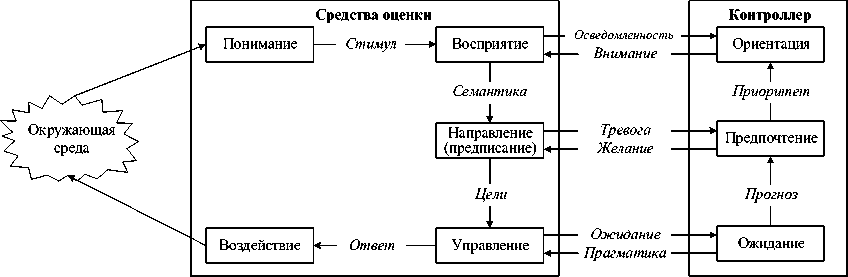
Рисунок 16 – Архитектура Frankel-Bedworth
-
■ локальный процесс пытается достичь целей, предусмотренных глобальным процессом, и обладает ролью средства оценки, которая подобна предыдущим моделям слияния данных;
-
■ глобальный процесс обновляет цели в соответствии с обратной связью, предоставленной локальным процессом.
-
3.3.3 Модель ситуационной осведомлённости (Situation Awareness Endsley)
Модель Эндсли ( M.R. Endsley ) [36] является наиболее известной моделью оценки обстановки . Она разрабатывалась для анализа деятельности операторов сложных динамических систем (самолетов, АЭС, заводов и т.п.), включая сравнительную оценку эффективности их работы, поиск причин ошибок и выработку рекомендаций по обучению для автоматизации процесса управления [20, 37].
Ситуационная осведомлённость означает возможность получения достаточно полной и точной информации о ситуациях в реальном режиме времени, необходимой для принятия решения и прогнозирования состояний. Согласно модели Эндсли состояние ситуационной осведомлённости является результатом процесса анализа и оценки ситуации и включает три уровня [38] (рисунок 17).
-
■ Уровень 1 - восприятие данных и обстановки. Быстро и эффективно осуществляется сбор необходимых данных с целью получения знаний того, что происходит вокруг;
-
■ Уровень 2 - понимание значения и важности ситуации. Осуществляется процесс слияния данных от разнородных источников с целью понимания значения собственных действий и действий других участников ситуации.
-
■ Уровень 3 - прогнозирование будущих состояний и событий. Представление собранных и проанализированных данных в необходимой форме с целью представления сценария развития ситуации.
Модель Эндсли может применяться в различных областях, которые характеризуются высокой динамикой, большими объёмами и структурной сложностью обрабатываемых данных, необходимостью одновременного решения нескольких задач в условиях ограниченных субъективных возможностей (например, рабочей памяти), высокой степенью риска, т.е. где неудачное решение может привести к тяжелым последствиям.

Рисунок 17 – Структура модели ситуационной осведомлённости
Главные требования, которые предъявляются к системам ситуационного осведомления о состоянии сети, это: масштабируемость и возможность интеграции с существующей инфраструктурой безопасности; возможность централизованного сбора, корреляции, анализа и отображения разнородных данных от всех компонентов инфраструктуры; возможность взаимодействия специалистов различных служб; предоставление всесторонних комплексных отчётов в режиме реального времени, уведомления об угрозах, высокий уровень визуализации; возможность получения данных из внешних источников [38].
Отметим, что достаточно сложно определить универсальную модель слияния данных для конкретного использования датчика. Проектирование и разработка интеллектуальных и сенсорных систем и сбор данных с нескольких разнотипных датчиков является сложной зада- чей. По этой причине для эффективного сбора данных и их обработки можно использовать несколько моделей слияния или их комбинации. Типичным примером является Комплексная модель, которая представляет собой сочетание трёх моделей слияния данных: цикл OODA, водопадная модель и DFD.
Проведённый анализ показал достаточно большое количество моделей слияния данных, которые могут найти широкое применение при диагностировании ТО любых отраслей промышленности и транспорта. Однако при выборе той или иной модели необходимо учитывать ряд аспектов, например: какие собраны будут данные и на каком этапе; какая преследуется цель использования той или иной модели с точки зрения требований и будущего использования; на каком этапе будут приниматься решения.
В связи с этим предлагаются следующие рекомендации: например, JDL модель и водопадную модель использовать для работы на высоком уровне, однако не исключено их использование и на низком уровне; модель OODA целесообразно применять для деятельности отдельных лиц и организаций в условиях конкурентной среды (соперничества); модель ситуационной осведомлённости использовать в случае, когда специалист, обеспечивающий эффективное управление безопасностью организации, глубоко владеет текущей обстановкой (ситуационной осведомленностью).
Заключение
Слияние данных играет важную роль при диагностировании ТО, поскольку это увеличивает вероятность обнаружения неисправностей ТО в условиях множества разнотипных датчиков, а также уменьшает время реакции экспертов на различные ситуации.
Исследованы различные структурные модели слияния данных и их принципы работы. Проведено сравнение рассмотренных моделей между собой, выявлены их преимущества и недостатки. Отмечено, что для эффективного сбора исходных данных, поступающих от множества разнотипных датчиков, и их обработки можно использовать несколько моделей слияния данных либо их комбинации.
Работа выполнена при поддержке РФФИ, проекты № 19-07-00263, 19-07-00195,
19-08-00152.
Список литературы Интеллектуальные технологии слияния данных при диагностировании технических объектов
- Bahador Khaleghi Multisensor data fusion: A review of the state-of-the-art / Bahador Khaleghi, Alaa Khamis, Fakhreddine O. Karray, Saiedeh N.R. // Information Fusion. 2013. - Vol.41. - No.1. - P. 28-44.
- Fouad, M. Data mining and fusion techniques for WSNs as a source of the big data / M.M. Fouad, N.E. Oweis, T. Gaber, M. Ahmed, V. Snasel // Procedia Computer Science. - Elsevier, 2015. - Vol.65. - P. 778-786.
- Valet, L.A. A statistical overview of Recent Literature in Information Fusion / L.A. Valet, G. Mauris, P. Bolon // 3rd International Conference on Information Fusion. France. 2001. - P.532-536.
- Esteban, J. A review of data fusion models and architectures: Towards engineering guidelines / J. Esteban, A. Willetts, R. Hannah, P. Bryanston-Cross // Neural Computing & Applications. 2005. - Vol.14. - No.4. - P.273-281.
- Bleiholder, J. Data Fusion and Conflict Resolution in Integrated Information Systems / J. Bleiholder. - Potsdam: Hasso-Plattner-Institut, 2010. - 184 p.
