Использование библиотеки Keras для дешифрирования местообитаний животных методами глубокого обучения

Автор: Марфицына Н.А., Коросов А.В.
Журнал: Принципы экологии @ecopri
Рубрика: Методы экологических исследований
Статья в выпуске: 4 (58), 2025 года.
Бесплатный доступ
В работе рассматривается применение алгоритмов глубокого обучения из библиотеки Keras для решения задачи классификации вырубок разного возраста с помощью дистанционного зондирования в среде R. Подробно рассмотрена достаточно сложная процедура установки библиотек Keras на компьютер. Описаны этапы нейросетевого моделирования и их вариации при использовании пакета R neuralnet и среды Keras. Выполнено дешифрирование космических снимков в окрестностях д. Гомсельга (Карелия) с использованием данных полевой съемки. Типичный алгоритм дешифрирования (классификация с обучением) был дополнен совместным многомерным анализом яркостных характеристик снимка и полевыми геоботаническими описаниями. В результате были сформированы четыре набора эталонных сигнатур, соответствующие тому или иному состоянию зарастающих вырубок. Нейросеть (многослойный персептрон) настраивалась на распознавании этих типов насаждений и затем выполнила классификацию остальных пикселей снимка для всей изучаемой территории. На основе анализа геоботанических описаний и спутниковых данных была создана грид-карта с выделением четырех основных типов местообитаний: свежие вырубки, зарастающие вырубки, молодняки, лиственный лес. Обработка данных с помощью алгоритмов Keras существенно ускоряет анализ, позволяет увеличивать число слоев и нейронов и детализировать грид. В частности, в отличие от алгоритмов эталонного дешифрирования, предлагаемый подход позволил выявить неоднородность растительности в пределах одновозрастных вырубок. Результаты работы используются для выявления разнородных местообитаний животных и влияния экологических факторов на их пространственное распределение и численность.
Местообитания, ДЗ, ГИС, нейронная сеть, R, Keras
Короткий адрес: https://sciup.org/147252677
IDR: 147252677 | УДК: 57.087:528.854 | DOI: 10.15393/j1.art.2025.16622
Using the Keras library to decrypt animal habitats using deep learning methods
The paper considers the use of deep learning algorithms from the Keras library to solve the problem of classifying forest clearings of different ages using remote sensing in the R environment. A rather complicated procedure for installing Keras libraries on a computer is considered in detail. The stages of neural simulation and their variations using the R neuralnet package and the Keras environment are described. Satellite images were decoded in the vicinity of Gomselga village (Karelia) using field survey data. The typical decryption algorithm (classification with learning) was supplemented by a joint multidimensional analysis of the brightness characteristics of the image and field geobotanical descriptions. As a result, 4 sets of reference signatures were formed, corresponding to a particular state of regenerating clearings. The neural network (multilayer perceptron) was configured to recognize these types of plantings, and then performed the classification of the remaining pixels of the image for the entire studied area. Based on the analysis of geobotanical descriptions and satellite data, a grid map was created highlighting four main types of habitats: fresh cuttings, regenerating cuttings, young trees, and deciduous forest. Data processing using Keras algorithms significantly speeds up analysis, and makes it possible to increase the number of layers and neurons and detail the grid. In particular, unlike the algorithms of reference decoding, the proposed approach made it possible to identify the heterogeneity of vegetation within the same-age clearings. The results of the work are used to identify heterogeneous animal habitats and the influence of environmental factors on their spatial distribution and abundance.
Текст научной статьи Использование библиотеки Keras для дешифрирования местообитаний животных методами глубокого обучения
Биотопическая гетерогенность является ключевым фактором, определяющим распределение и динамику численности наземных позвоночных животных. В таежных эко-
Подписана к печати: 27 декабря 2025 года системах Карелии антропогенные нарушения, такие как сплошные рубки, инициируют сукцессионные процессы, формирующие мозаику вторичных лесов с уникальными микроклиматическими и кормовыми усло- виями. Эти изменения оказывают прямое воздействие на структуру популяций мелких млекопитающих и их паразитических сообществ, что подтверждено многолетними исследованиями (Коросов и др., 2003; Иешко и др., 2020). Ранние наши работы были направлены на описание трансформации местообитаний с применением методов дистанционного зондирования (ДЗ) и геоинфор-мационного анализа (Бугмырин и др., 2006; Гусева и др., 2014). Современные технологии, а именно нейросетевое моделирование, позволяют по-новому подойти к этому процессу и построить карту различающихся биотопов, отражающих роль разнообразных экологических факторов в формировании уровня и динамики численности изучаемых групп животных. Однако использование космических снимков существенно увеличивает объем входящих данных, обработка которых в среде интерпретатора R затруднена и требует много времени. Эту проблему решает библиотека глубокого обучения Keras (Шолле, 2022), позволяющая компилировать скрипты. Кроме того, в среде Keras предусмотрено использование других видов нейронных сетей, кроме персептрона.
Цель работы состоит в демонстрации построения нейросетевой модели с использованием пакета Keras на примере решения экологической задачи - классификации разновозрастных молодых вторичных насаждений на месте рубок дистанционными методами на основе натурных геоботанических описаний.
Статья носит методический характер, и любой читатель может воспроизвести расчеты с помощью представленных скриптов и наших данных, которые доступны по гиперссылкам.
Материалы
Полевые данные получены в 2023 г. в окрестностях д. Малая Гомсельга (Кондопожский район, Карелия, N 62.067, E 33.9587). Проводились геоботанические описания по упрощенной схеме только во вторичных лесах на вырубках в возрасте 2-30 лет. Фиксировались 16 характеристик: сомкнутость крон (tranc, доля белых пикселей бинарных снимков при съемке вертикально вверх с точка учета, %), полнота древостоя с помощью полнотомера Биттерлиха (c - сосна, e -ель, b - береза, os - осина, ol - ольха, i - ива, r - рябина, шт.), число поваленных деревьев в окрестностях 20 м от точки (fell, шт.), проективное покрытие в окрестностях 5 м от точки учета (Mxi - мхи, Lish - лишайники, Travi -травы, kust - кустарники, Pap - папоротники, Mal - малина, %). Получено 120 описаний на 40 площадках; все точки имеют картографическую привязку. Описания на отдельной площадке (в одном биотопе) выполнялись в трех точках, отстоящих друг от друга на 10 м. В результате была получена таблица размером 16 полей и 120 строк. Далее для каждой площадки три описания обобщались: для каждого показателя была рассчитана медиана и стандартное отклонение, всего 32 показателя для отдельной площадки. В заключение для каждого показателя были высчитаны нормированные отклонения, отношение разности между i-м показателем и средней к стандартному отклонению, (x*Mx)/Sx, что приводит разную размерность переменных к безразмерному диапазону 0 ± 3 и сохраняет уровень коррелированности между переменными. Так получили рабочую матрицу, состоящую из 32 полей (характеристик биотопа) и 40 строк (площадки в биотопах).
Использованы космические снимки за март и июль 2023 г., из которых вырезали фрагменты по экстенту: 546015, 6877965, 553785, 6887535 (WGS 84 / UTM zone 36N). Взяты 7 каналов из летнего снимка: 1_sum23. tif , 2 sum23.tif , 3 sum23.tif , 4 sum23.tif , 5 sum23.tif , 6 sum23.tif , 7 sum23.tif и 2 канала из зимнего снимка: 1_win23.tif , 2_win23. tif . Разрешение снимков составило 30 м на пиксель. Для каждого канала проводили предобработку - нормализацию значений в пределах от 0 до 255. Полный набор данных по яркости всех пикселей для 9 каналов спутниковых снимков в пределах изученного экстента поместили в массив fuldata .
Далее были подготовлены массивы с яркостными характеристиками для выполнения анализа. Используя координаты точек описания, определили пиксели, покрывающие участки описания (120 участков для 40 площадок). Сформирована таблица bancl.csv размером 9 полей и 120 строк для обучения нейронных сетей. Яркостные характеристики этих пикселей по всем каналам снимков использовали для составления обучающих и тестовых массивов (тензоров). Данные были случайным образом разбиты на два массива (два тензора). Обучающий тензор, train_ data , содержал 70 % данных (28 площадок). Тестовый тензор, test_data , включал оставшиеся 30 % (12 площадок).
Подготовку массивов данных ({terra}), кластерный анализ (hclust {stats}) и нейросетевое моделирование (neuralnet {neuralnet}, compile{keras}) выполнили в среде R (The R Project..., 2023).
Традиционные методы исследований
Традиционная схема дешифрирования с обучением использует данные полевых описаний и космические снимки (Геоинформатика, 2005). По имеющимся натурным данным намечаются эталонные участки с заведомо разными типами природных объектов (для которых типология уже известна). Тем самым пиксели разных областей снимка обретают определенное качество, а именно тип природного объекта. Далее выполняется тот или иной вариант классификации пикселей (с помощью дискриминантного, кластерного или нейросетевого анализа). Вначале отыскивается уравнение, которое связывает значения яркости пикселей (сигнатуры) с разными типами указанных природных объектов (этап обучения). Затем это уравнение используется для экстраполяции (прогноза) заданных классов объекта на изучаемую область космического снимка.
Иногда эталонные участки назначаются с использованием карты лесоустроительных выделов (Ильючик, Цай, 2010; Кузменко и др., 2015). В одних случаях она служит для построения прямоугольных участков в рамках выдела, которые применяются для считывания яркостных характеристик со спутниковых снимков, в других случаях в качестве маски используются некоторые выделы целиком в своих границах. Для автоматизации этого процесса в один блок могут объединяться данные векторной карты лесоустройства и яркостные характеристики спутниковых снимков, что позволяет вычислить статистические характеристики для каждого выдела на основе множества пикселей растровых слоев спутникового изображения, попадающих в границы выдела (Данилова и др., 2017).
В нашем случае типология объектов была изначально непонятна, и мы применили другой алгоритм для построения схемы классификации типов растительного покрова. Сначала в полевых условиях выполнили серию геоботанических описаний. Далее в одну матрицу объединили натурные полевые данные и яркостные характеристики пикселей снимка, покрывающих пробные участки. Затем выполняли классификацию (кластеризацию) объектов по объединенным данным, получив небольшое число классов, тем самым выявив типологию изучаемых объектов.
Процедура выделения типов биотопов (кластеров clu) подробно изложена в работе по дешифрованию местообитаний животных (Коросов, Марфицына, 2025). Она включает совместный кластерный анализ массива данных по 41 показателю (9 спектральных каналов и 32 геоботанические характеристики) для 40 площадок. Сначала с помощью алгоритма k -средних и «метода локтя» выявляется минимальное число «естественных» кластеров (Шитиков, Мастицкий, 2017), затем процедура кластеризации методом Варда делит все множество площадок на принятое число кластеров. Результатом стали 4 интерпретированных кластера, соответствующих стадиям сукцессии: свежие вырубки (кластер 1 для 4 площадок), лиственный лес (кластер 2 для 9 площадок), молодняки (кластер 3 для 7 площадок), зарастающие вырубки (кластер 4 для 16 площадок). Кластерные метки (clu) площадок далее используются как целевые входные переменные для обучения нейронной сети на основе спектральных характеристик (9 каналов).
Поскольку каждому типу биотопа соответствуют определенные значения яркостей пикселей, выполнили обучение сети для прогноза типа объекта по растровым данным. Затем выполнили экстраполяцию полученных зависимостей на весь снимок. В результате получили цветной грид, где отдельные одноцветные пятна соответствуют тому или иному типу природных объектов (биотопов). Используя нейронную сеть, для каждого пикселя геоизображения изучаемой территории рассчитали свой номер кластера. Пятна, сформированные пикселями одного цвета, рассматривали как отдельные типы биотопов.
Описанная процедура в какой-то мере справлялась с поставленными задачами, если объем баз данных, площадь изучаемых территорий, размеры космических снимков и число нейронов сети относительно невелики. Для более точного прогноза нами предпринята большая серия попыток существенно увеличить число слоев и нейронов в персептроне (пакет neuralnet). При этом резко увеличивается время обучения сети и число сбоев в расчетах, причем без существенного роста качества полученной модели, которая зачастую оказывается переученной. Для таких задач (тем более с bigdata) средств пакетов neuralnet недостаточно и требуются более мощные библиотеки, такие как Keras.
Оригинальные методы исследований
Рассмотрим решение поставленной выше задачи с помощью библиотеки Keras. Установка Keras на компьютере требует кропотливой работы. В литературе и в интернете можно найти ряд разрозненных описаний, как это сделать (Шолле, 2022; PythonRu, 2021; GeeksforGeeks, 2021), ниже рассмотрен наш опыт по установке и использованию Keras. Библиотеку следует устанавливать на компьютеры не старше 8 лет, выпущенные после 2017 г. На старых устройствах могут возникнуть ошибки, связанные с невозможностью виртуальной среды найти совместимую версию TensorFlow для текущей версии Python. В таких случаях необходимо скачать дополнительные пакеты, такие как Rtools, которые требуются для сборки пакетов R. Также могут возникнуть проблемы с загрузкой динамической библиотеки TensorFlow. Библиотека имеет определенные системные требования, включая наличие Microsoft C++ Redistributable for Visual Studio 2015, 2017 и 2019. Важно убедиться в совместимости версий Python и TensorFlow, чтобы избежать проблем с установкой и работой системы.
Установка Keras
Библиотека Keras работает в относительно обособленной виртуальной среде, созданной в компьютере с помощью дополнительных программ. Мы использовали следующие программы: Python (на нем напи- сан Keras), Rstudio (оболочка для работы со скриптами R), Tensorflow (библиотека программ), Nampy (библиотека программ). Во время установки этих программ необходимо пользоваться командной строкой Windows. Программы инсталлируются по определенному алгоритму в искомой виртуальной среде. Рекомендуется выполнять их загрузку от имени администратора.
Первый этап. Подготовка системы
Скачиваем загрузочные файлы и производим одновременно инсталляцию. Скачивание файлов производится с открытых официальных серверов, поскольку все программы условно бесплатны. Программа R должна быть инсталлирована заранее.
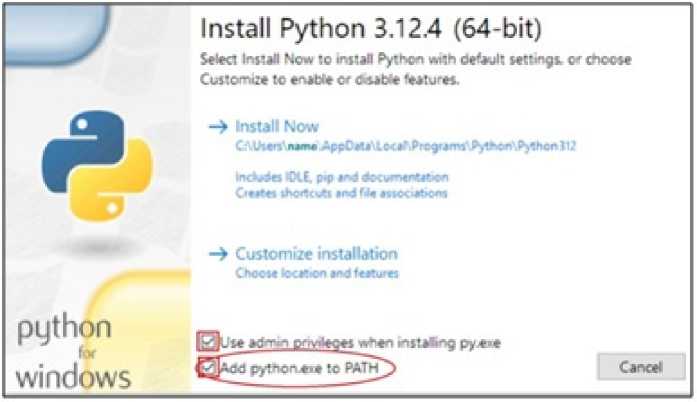
Загружаем инсталлятор Python 3.12.4 с сайта Важно: на сегодняшний день остальные библиотеки корректно устанавливаются только с версией Python не выше 3.12; современным читателям необходимо скачать не последнюю версию, а именно Python 3.12. Запускаем инсталлятор. В открывшемся окне установщика Install Python внизу необходимо отметить обе опции «Use admin privileges when installing » и «Add to PATH». Это позволит добавить путь к установленному Python в системную переменную PATH и завершить процесс установки программы. Нажимаем кнопку Install Now. В окне Setup was successful нажимаем кнопку Close.
Загружаем инсталлятор Rstudiо 2024.09.1 desktop/ и запускаем установку (оба процесс сайта са занимают много времени).
Второй этап. Настройка виртуальной среды
Вызываем окно Выполнить, нажав соче- тание клавиш Win + R, вводим с клавиатуры команду powershell, OK. Появляется окно командной строки.
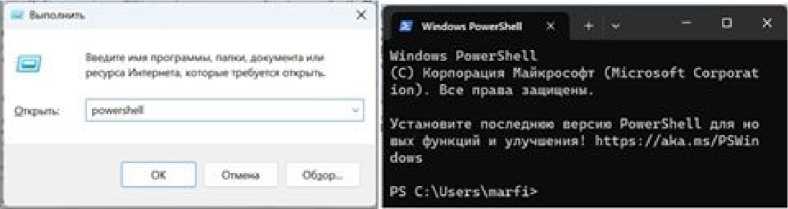
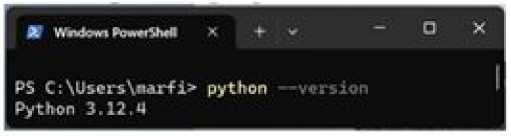
Проверяем успешность установки Python. Для этого в командной строке вводим команду python --version , жмем клавишу Enter.
Если Python установлен корректно, появится строчка: Python 3.12.4 (с версией программы).
Проверяем наличие программы pip, которая устанавливается вместе с Python. В командной строке вводим команду pip --version, Enter. Должна появиться строчка с версией программы и путем до нее: pip 25.0.1 from С:\Python 312\Lib\site-packages\ pip (python12).
CAUj«rs\B>rfi=- pip • p 21." fron C:\Pythoi HSYLib^sit^-pdchA-ge^ ip [python 3.131
C ■ \Uiflri 'i ПЛ L" f i ^
риев. Вновь вызываем окно Выполнить (Win
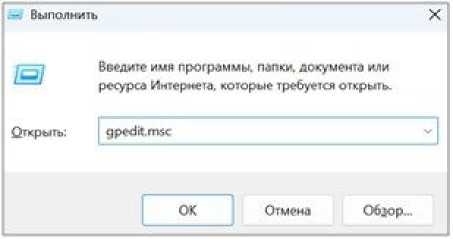
В появившемся окне Редактор локальной групповой политики необходимо включить выполнение сценариев. Для этого в левой части окна поочередно отрываем вкладки Конфигурация компьютера \ Администра- тивные шаблоны \ Компоненты Windows \ Windows PowerShell и в правой части окна дважды кликаем на пункте Включить выполнение сценариев.
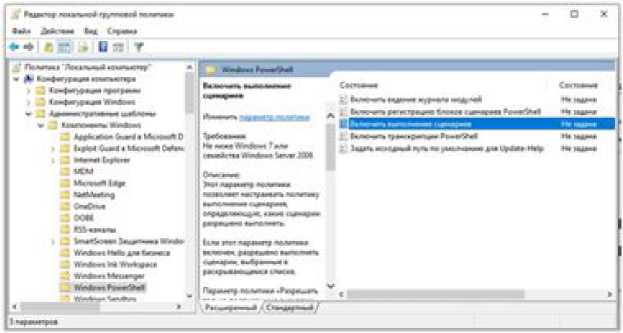
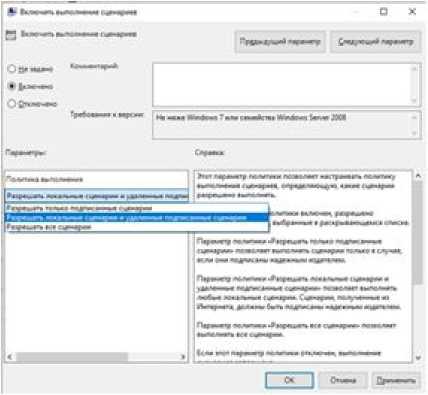
В появившемся окне Включить выполне- выбрать Разрешать локальные сценарии и ние сценариев выбрать пункт Включено и, удаленные подписанные сценарии, OK. нажав на серую полосу в левой части окна,
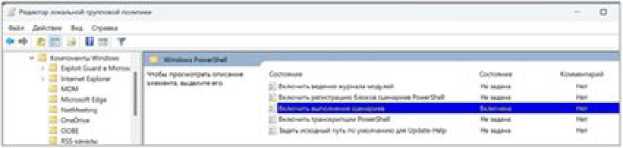
В появившемся окне Редактор… состоя- риев» изменится на «Включено». Закрывание работы «Включить выполнение сцена- ем окно.
Третий этап. Создание виртуального выше: Win + R, powershell, OK). Вводим ко- окружения манду pip install virtualenv , Enter.
Вновь вызываем командную строку (см.

По выполнении должна появиться строчка
Installing collected packages: distlib, platformdirs, filelock, virtualenv
Successfully installed distlib-0.3.9 filelock-3.18.0 platformdirs-4.3.7 virtualenv—20.30.0
В следующей строке ввести команду python - m venv r - reticulate , Enter.
PS C:\Users\marfi> python -m venv r-reticulate
И, наконец, активировать окружение ко- Успешная активация будет обозначаться зе-мандой r - reticulate\Scripts\activate , Enter. леной надписью «r-reticulate».
PS C:\Users\marfi> r-reticulate\Scripts\activate (г-reticulate) PS C:\Users\marfi> |
Четвертый этап. Установка библиотек для установки необходимых библиотек: pip В командной строке ввести команды install tensorflow keras matplotlib pandas numpy .
. ; ■ > ' PS C:\Users\Mrfi» pip instill, tensorflow
, keras natplotlib pandas nunpy___________________________
Начнется процесс инсталляции. По завер- ответствующая текстовая строка. шении процесса должна быть выведена со-

Чтобы проверить наличие установленных tensorflow и pip list . библиотек, используем команды pip show
PS C:\Users\marfi> pip list Package Version absl-py 2,1.6 astunparse 1.6.3 certifi 2624.7.4 charset-normalizer 3.3.2 flatbuffers 24.3.25 gast 6.6.6 google-pasta 0.2-0 grpcio 1.65.1 h5py 3.11.0 idna 3.7 keras 3.4.1 PS C:\Users\marfi» pip show tensor-flow Name: tensorflow Version: 2.17.0 Summary: TensorFlow is an open source machine lea ming framework for everyone. Home-page: Author: Google Inc. Author-email: License: Apache 2.0 Location: C:\Python 312\Lib\$ite-packages Requires: tensorflow-intel Required-by: PS C:\Users\marfi>
Если все пройдет без ошибок, закроем окно Windows PowerShell.
Пятый этап. Построение виртуального окружения
Запустим программу Rstudio, играющую роль оболочки для R, где создаются и выполняются скрипты. Для оптимизации работы периодически необходимо перезапускать сессию R (команда главного меню Session \ Restart R).
В открывшемся окне создадим скрипт командой File \ New File \ R-script.
Запишем серию команд, формирующих среду для работы:
packages("reticulate")
packages("keras")
packages("keras3")
library(keras)
library(keras3)
library(reticulate)
Последовательно выполним команды, нажимая сочетание клавиш Ctrl + Enter.
В поле Console (консоль) результатом установки будут следующие строки:

Л*»|Т 'reticulate' боМ собрал под ft ««PCмм 4.4.:
> 11№гу<к«гм>
Registered Я aetfiods overwritten by 'koras': •ethod fro*
as. data. frawe.keras_trainifvg^ii story koras) plot.keras_tra1nin^_Mstory karat)
r.to^y.ftlclasscenerator koras)
Пред у про где мне: ча<ет •koras' tan собран под ft вором 4.4.2 » ИOrагу(koras)) fteetstored Я methods overwritten by 'koras)' ■etnod fro«
При выполнении команды в R консоль возвратит значение, которое отобразится в поле команд.
пакет R О кж*мЛ © IHMMW © kecasiR О toraeZA ©
। Source on So*r \ / •
1 venv_path <■ file path getwci ). "r•reticulate*)
Записываем следующую команду, которая активирует виртуальную среду: use_ virtualenv(venv_path, required = TRUE), Ctrl +
Enter. Параметр «required = TRUE» позволяет выявить ошибку, если среда не будет успешно активирована.
2 use_virtualonv(venv_path, required trle)
Последней командой проверяем, установлены ли необходимые библиотеки и связи: py_confing (), Ctrl + Enter.
В консоли выводится список с указанием информации об установленных программах и библиотеках. В случае успешной установки среды Keras все 9 строк должны быть заполнены текстом без указания ошибки.
pythonboa*: C ?tser s^warfi/Pocuaewts/.vlrtualenvs/r«tensorfloa version: 3.12.4 (*фЛЭ.12.4:«в«а40а. Jun 6 2024. IS: JO:IS) [MSC v.lMO 44 bit (Д*Н))
Architecture: stoic nuepy: C: /’Vsers/aarfi/Pocueents/. vtrtualenvs/r«t*nsorf1ow/Lie/si te-packapes/AHpy пиару.verstow: 2.0.2
keras: C:\user s\aarf1\jDOCNMt-l\YlJl1M-lVl*TIM-X\LHAa1t«-p*ckaees\keras\_1w1t_.p vert: Python version was forced bv lasertr'kerat'J
Если к этому этапу установка прошла успешно, можно сразу перейти к этапу «Использование Keras».
***
Однако при построении виртуальной среды в RStudiо могут возникнуть ошибки, связанные с отсутствием «установленных» библиотек. В этом случае рекомендуется создать новую виртуальную среду с нуля и повторить процесс установки библиотек. Если команда py_confing () не предоставляет полную информацию об установленных библиотеках, можно использовать следующий алгоритм. В новом скрипте прописываем команду автоматической установки самых необходимых библиотек и выполняем ее ( Ctrl + Enter ):
py_install(c("numpy", "keras"), env = venv_ path)
py_config()
Если после выполнения py_config() в R отображается, что библиотеки не найдены, это может быть связано с использованием R другой интерпретации Python или несоответствием виртуальных путей. В этом случаем необходимо явно указать свой путь, где находятся установленные библиотеки, добавив в новый скрипт команду:
py_config()
и выполнить ее (Ctrl + Enter).
С помощью дополнительной команды py_run_string("import numpy; import keras") следует проверить наличие библиотек.
Отметим, что создание виртуальной среды с указанием пути в форме C:\Windows\ system32\ может быть некорректным, т. к. этот путь зарезервирован для системных файлов Windows. Запуск интерпретатора или установка пакетов в этом каталоге могут привести к проблемам с правами доступа или конфликтам. Рекомендуется создать отдельную виртуальную среду или использовать установленный Python в другом каталоге (например, в AppData), чтобы избежать возможных проблем.
Если в остальных случаях программа не обнаруживает библиотеки, то существует еще один алгоритм, который также поможет создать, активировать другую среду и установить библиотеки. Вызываем командную строку (см. выше: Win + R, powershell, OK). Вместо команды python -m venv r-reticulate вводим python -m venv myenv , Enter.
Активируем окружение командой myenv\ Scripts\activate , Enter.
Устанавливаем библиотеки pip install numpy keras tensorflow , Enter. Начнется процесс инсталляции.
В Rstudio в скрипте последовательно выполним команды сочетанием клавиш Ctrl +
Enter для активации новой виртуальной среды и проверки установленных библиотек.
library(reticulate)
use_virtualenv("D:/myenv", required = TRUE)
py_config()
и выполнить ее (Ctrl + Enter).
С помощью дополнительной команды py_run_string("import numpy; import keras") следует проверить наличие библиотек.
Отметим, что создание виртуальной среды с указанием пути в форме C:\Windows\ system32\ может быть некорректным, т. к. этот путь зарезервирован для системных файлов Windows. Запуск интерпретатора или установка пакетов в этом каталоге могут привести к проблемам с правами доступа или конфликтам. Рекомендуется создать отдельную виртуальную среду или использовать установленный Python в другом каталоге (например, в AppData), чтобы избежать возможных проблем.
Если в остальных случаях программа не обнаруживает библиотеки, то существует еще один алгоритм, который также поможет создать, активировать другую среду и установить библиотеки. Вызываем командную строку (см. выше: Win + R, powershell, OK). Вместо команды python -m venv r-reticulate вводим python -m venv myenv , Enter.
* Window (WnSWI X + - -OX
PS C:\Us«M\Hrfi> python vcnv nyonv
Активируем окружение командой myenv\Scripts\activate , Enter.

Устанавливаем библиотеки pip install цесс инсталляции. numpy keras tensorflow, Enter. Начнется про- hS C:\Users\marfi> pip install numpy keras tensorflow
В Rstudio в скрипте последовательно выполним команды сочетанием клавиш Ctrl + Enter для активации новой виртуальной среды и проверки установленных библиотек.
library(reticulate) use_virtualenv("D:/myenv", required = TRUE) py_config()
Использование Keras
Установленные программы и библиотеки необходимо загружать при выполнении любого скрипта R c помощью функции library().
Подготовка данных
В среде Keras массивы данных принято называть тензорами . Смысл такой замены терминов здесь не важен, поскольку в прикладном плане ничего не меняется. По-прежнему задачей моделирования является классификация пробных площадок ‒ строк двумерного массива (объектов тензора).
Обучающий тензор, train_data , содержал 70 % данных (28 площадок, 84 строки). Тестовый тензор, test_data , включал оставшиеся 30 % (12 площадок, 36 строк). Разные показатели имели отличающиеся диапазоны значений; для них выполнили преобразование в безразмерные величины из интервала [0, 1] с помощью формулы z<-(max(x)-x)/ (max(x)-min(x)). Трансформация каждого признака проведена отдельно для обучающей и тестовой выборок.
В среде Keras индексы массивов начи- наются с нуля. Для преобразования меток классов в формат, пригодный для обучения моделей, номера кластеров от 1 до 4 были уменьшены на единицу и стали номерами от 0 до 3. Далее с помощью функции категориального кодирования to_categorical() создана бинарная матрица train_labels, состоящая из 4 столбцов (идентифицирующая индекс кластера) и 84 строк (соответствующих объектам, 28 площадкам). Столбец 1 соответствует классу 0, столбец 2 ‒ классу 1 и т. д. Для каждого объекта (строки) назначается индекс 1 в том столбце, который соответствует номеру его кластера, и 0 ‒ в остальных столбцах (табл. 1).
Таблица 1. Фрагмент-матрица train_labels для идентификации точек с площадок по кластерам. Преобразованные номера кластера
|
Номер точки площадки |
Номер кластера |
Индекс кластеров |
|||
|
0 |
1 |
2 |
3 |
||
|
1 |
2 |
0 |
0 |
1 |
0 |
|
2 |
1 |
0 |
1 |
0 |
0 |
|
3 |
2 |
0 |
0 |
1 |
0 |
|
4 |
2 |
0 |
0 |
1 |
0 |
|
5 |
2 |
0 |
0 |
1 |
0 |
|
6 |
3 |
0 |
0 |
0 |
1 |
|
7 |
3 |
0 |
0 |
0 |
1 |
|
8 |
0 |
1 |
0 |
0 |
0 |
|
9 |
1 |
0 |
1 |
0 |
0 |
|
10 |
1 |
0 |
1 |
0 |
0 |
|
11 |
0 |
1 |
0 |
0 |
0 |
|
12 |
1 |
0 |
1 |
0 |
0 |
Процедура моделирования
Работа с сетью проходила в несколько этапов: подготовка данных, создание модели, подготовка к обучению (компиляция), обучение (Коросов, 2023).
Вначале задали архитектуру нейронной сети (полносвязный персептрон) с помощью функции keras_model_sequential() %>%. В разных вариантах модели задавали от 1 до 3 слоев и от 10 до 60 нейронов, в примере показана двухслойная модель с 20 и 10 нейронами. Функция активации нейронов принята relu, которая широко применяется благодаря своей простоте (Балута и др., 2023). Поскольку решается многоклассовая задача, на последнем (выходном) слое в модели за- дается функция активации softmax. На выходе получаем 4-мерный вектор вероятности принадлежности каждого образца к каждому из 4 кластеров.
model <- keras_model_sequential() %>% layer_dense(units = 20, activation = ‘relu’) %>% layer_dense(units = 10, activation = ‘relu’) %>% layer_dense(units = 4, activation = ‘softmax’)
Визуализация структуры модели и потоков информации через слои нейронной сети в виде схемы выполняется с помощью команды plot(model, show_shapes = TRUE) (рис. 1). В примере 9 входных нейронов (None, 9) передают данные в 20 нейронов второго (скрытого) слоя (None, 20), а те - в 10 нейронов третьего слоя (None, 10).
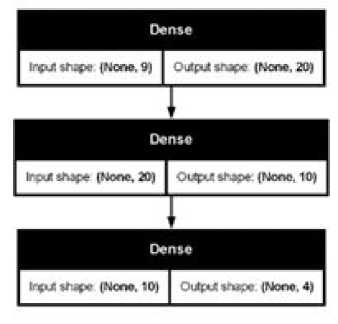
Рис. 1. Вариант графа модели с 3 полносвязными слоями Dense с информацией о размере Fig. 1. A variant of the model graph with 3 fully connected Dense layers with size information
Далее загружается код в память компьютера (компиляция) для последующей настройки. Для этого в функции compile() задаются следующие аргументы: функция потерь categorical crossentropy, алгоритм оптимизации adam и метрика точности (успешности) accuracy классификации. Функция потерь categorical crossentropy применяется именно для решения многоклассовых задач. model %>% compile( optimizer = 'adam', loss = 'categorical_crossentropy', metrics = c('accuracy'))
Обучение сети (training) проводилось на входных данных тензора train_data (яркостные характеристики 9 каналов), в качестве целевых переменных служили метки кластеров train_labels (4 кластера). В процессе настройки подбиралось число эпох (лучший вариант ‒ 40) и число итераций (10). Применялся метод fit() с аргументом validation_data = 0.2 (20 %). Для оценки степени ее обобщ-ности, т. е. способности модели работать с новыми данными, принято определенную часть обучающих данных использовать только для вычисления метрики потерь (Шолле, 2022). Оценку (validation) обученной модели проводили, используя метод evaluate() . Сначала модель была оценена на тестовых данных test_data с соответствующими метками классов test_labels . Далее были получены метрики точности ( accuracy ) и функции потерь ( loss ) для всего тестового набора.
history<-model%>% fit(train_data, train_la-bels, epochs = 40, batch_size = 10, validation_ split = 0.2)
plot(model, show_shapes = TRUE) plot(history)
model %>% evaluate(test_data, test_labels)
В ходе обучения параметры модели нейронной сети стабилизируются уже через 30 эпох (рис. 2., plot(history) ). Точность моделей на обучающихся и тестовых выборках варьировалась в диапазонах от 55 до 90 %. Увеличение размеров сети (с 5 до 30 нейронов) существенно улучшило прогнозные свойства модели; точность превышает 80 %.
Полученная модель использовалась для расчета типа кластера (местообитания) для каждого пикселя геоизображения (спутниковые снимки) всей изучаемой территории.
Построение прогноза и экстраполяция
Как было описано выше, полный преобразованный набор яркостных характеристик геоизображения содержится в массиве fuldata . Используя сигнатуру (соотношение 9 значений яркости) отдельного пикселя, модель рассчитывает для него четыре значения вероятностей принадлежности к одному из 4 классов: predinew<-model%>% predict(as.matrix(fuldata)) . Эти вероятности в сумме дают 1. Далее из них с помощью функции preclas выбирается максимальное значение и данному пикселю приписывается номер столбца как класс наиболее вероятного типа биотопа. Каждый образец получает единственный предсказанный класс (от 1 до 4) (табл. 2). Например, для пикселя 10 получили вектор [0.112, 0.702, 0.151, 0.048] и назначаем класс 1, это разреженные вырубки.
В качестве визуализации предсказаний используется растр с исходной геопривязкой (например, первый канал, ma ), в который переносятся предсказанные значения типов местообитания values(ma) . Далее построили растровый слой по категориям (функция classify обеспечивает раскраску значений).
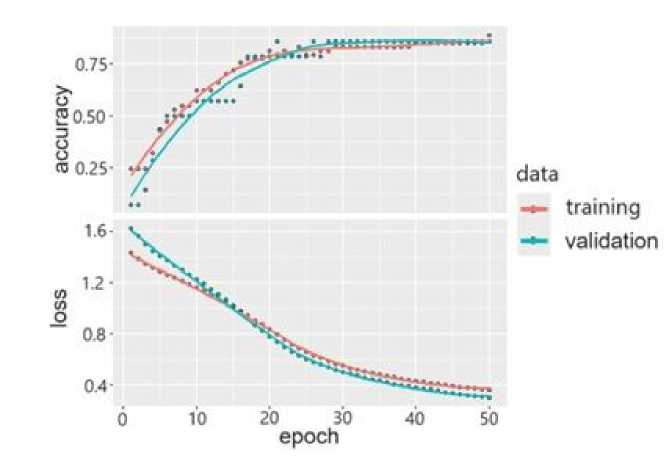
Рис. 2. Динамика оценок потерь (loss) и точности (accuracy) нейросетевой модели при обучении
Fig. 2. Dynamics of loss and accuracy estimates of the neural network model during training
Таблица 2. Фрагмент матрицы прогнозов для построения карты
|
Номер |
Номер кластера |
|||
|
пикселя |
0 |
1 |
2 |
3 |
|
1 |
0.247 |
0.188 |
0.384 |
0.18 |
|
2 |
0.204 |
0.244 |
0.419 |
0.132 |
|
... … … … |
||||
|
10 |
0.112 |
0.702 |
0.151 |
0.048 |
|
... … … … |
||||
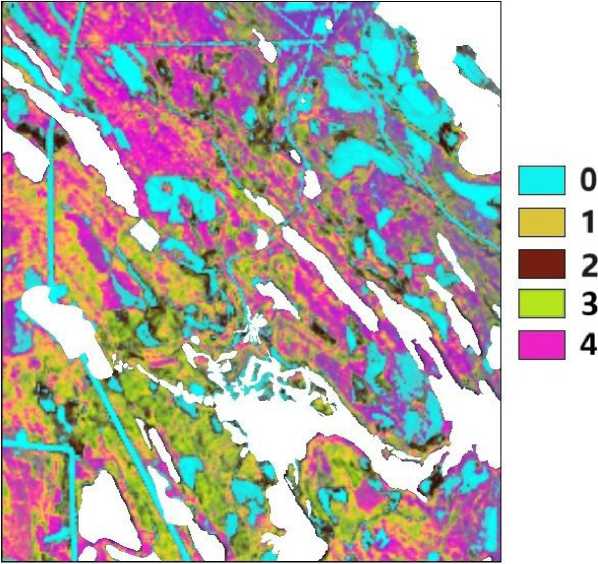
В результате создается карта, отображающая предсказанные классы биотопов (рис. 3).
Однородные области, сформированные пикселями одного кластера, интерпретируются как отдельные типы биотопов. На итоговой псевдоцветной карте показано 5 кластеров: четыре соответствуют изученным в полевых условиях типам, пятый объединяет неисследованные объекты, которые соответствуют спелым и приспевающим древостоям. Крупные элементы антропогенного и природного происхождения (озера, болота, луга, населенные пункты) закрыли маскирующими белыми полигонами.
Типичная процедура верификации результирующих карт в основном выполняется при сопоставлении их с разными источниками данных. В первую очередь с полевыми геоботаническими описаниями, сопровождаемыми GPS-привязкой и фотографированием местности; с космическими снимками высокого разрешения (Лавриненко, 2015; Раевский и др., 2022). Помимо полевых данных, для верификации используют лесоустроительные материалы. Также создание векторных карт на основе дешифрирования ДЗ с применением алгоритмов контролируемой классификации, например таких, как метод минимального расстояния, метод Махаланобиса, метод максимального правдоподобия, к спектрозональным снимкам среднего разрешения с последующей углубленной постклассификационной обработкой, с применением обучаемых алгоритмов Random Forest (Раевский и др., 2022; Семакина и др., 2025). Использование аэрофотоснимков и данных БПЛА тоже служит одним из верификационных показателей. Особенно перспективным является использование сверточных нейронных сетей для автоматического распознавания на снимках растительных сообществ, которые на порядки повышают точность создаваемых карт, что, в свою очередь, кардинально улучшает качество оценки актуального состояния и динамики растительного покрова (Лавриненко, 2023; Элешкевич и др., 2023). Поскольку наша статья носит методический
О 0.25 0.5 км
Рис. 3. Грид типов биотопов, построенный на основе двухслойного персептрона (20 > 10 > 5); 0 - открытые вырубки, 1 - разреженные вырубки, 2 - молодняки, 3 - лиственные леса, 4 - хвойные и смешанные леса; белыми полигонами закрыты болота, луга, озера, населенные пункты
Fig. 3. Grid of biotope types constructed on the basis of a two-layer perceptron (20 > 10 > 5); 0 - open clearings, 1 - sparse clearings, 2 - young forests, 3 - deciduous forests, 4 - coniferous and mixed forests); white polygons indicate swamps, meadows, lakes, and populated areas
характер и относится в основном к практике применения пакета Keras, мы не стали применять сложные процедуры верификации, требующие развернутой интерпретации.
Проверку соответствия грид-карты реальных объектов выполнили визуально, сопоставляя с космическими снимками высокого разрешения , фотографиями местности и полевыми описаниями. Используя последний вариант сети, контуры ландшафтов удалось выделить достаточно хорошо. Четко идентифицировались свежие и разреженные вырубки (0, 1), лиственный лес (3) с молод-няками (2), спелые хвойные и смешанные леса (4). Из-за отсутствия объемного массива данных провели приблизительную верификацию на основе трех точек, отобранных из новых геоботанических описаний, выполненных в июне 2025 г. Сравнение карты с этими описаниями показало, что она довольно хорошо отражает реальность. Первая точка соответствовала хвойным лесам с пребладанием сосны (плотность ‒ 24.5), вторая ‒ свежим вырубкам с нулевой плотностью, третья ‒ лиственным лесам с преобладанием березы и ели (14.5 и 8.5).
Обсуждение
Использование библиотеки Keras оказалось более эффективным, чем пакета neuralnet. В наших вычислительных экспериментах, включавших сотни прогонов с различными схемами сетей (от 3 до 50 нейронов в слоях, от 1 до 3 скрытых слоев) и комбинациями летних и зимних каналов (от 3 до 11), Keras обеспечил сокращение ошибки классификации на 20 % при существенном сокращении времени обучения (табл. 3).
Оптимизация архитектуры сети и предобработка данных выявили специфические методологические проблемы, характерные для экологических исследований с ограниченным числом репрезентативных площадок. Увеличение сложности сети до формата 20-10-4 снижало ошибку обучения. Лучший результат с помощью Keras достигнут при наборе данных № 4 (см. табл. 3) – обучающая точность составила 85 %, тестовая – 83 %; продолжительность обучения ‒ всего около 0.09 минуты (~5.4 секунды). Однако дальнейшее усложнение сети привело к переобучению, что выразилось в расхождении точности прогноза на тренировочной (> 90 %) и
|
Таблица 3. Характеристики процесса обучения нейронных сетей для двух библиотек |
|||||
|
Средняя доля |
Средняя доля совпадений для тестовой выборки |
||||
|
№ |
Число слоев |
Число нейронов |
Среднее время обучения, мин |
совпадений для обучающей выборки |
|
|
neuralnet |
|||||
|
1 |
1 |
5 |
0.53 |
0.39 |
0.43 |
|
2 |
1 |
20 |
1.45 |
0.61 |
0.75 |
|
3 |
1 |
30 |
3.83 |
0.65 |
0.67 |
|
4 |
2 |
20, 10 |
6.67 |
0.99 |
0.88 |
|
5 |
3 |
34, 12, 4 |
7 |
0.99 |
0.75 |
|
Keras |
|||||
|
1 |
1 |
5 |
0.08 |
0.54 |
0.79 |
|
2 |
1 |
20 |
0.07 |
0.82 |
0.72 |
|
3 |
1 |
30 |
0.08 |
0.79 |
0.72 |
|
4 |
2 |
20,10 |
0.09 |
0.85 |
0.83 |
|
5 |
3 |
34, 12, 4 |
0.08 |
0.91 |
0.79 |
|
тестовой (< 70 %) выборках. Использовалось да приводило к ожидаемому улучшению различное число (от 3 до 11) и соотношение классификации вторичных лиственных биочисла каналов (от 1 до 5) летних и зимних топов; в некоторых конфигурациях происхо-снимков (табл. 4). Увеличение количества дило «размывание» спектральных сигнатур зимних каналов, чувствительных к наличию для кластеров (биотопической картины) (Со-хвои и структуре снежного покрова, не всег- чилова, Ершов, 2012). |
|||||
Таблица 4. Влияние архитектурных гиперпараметров на точность модели
|
Количество |
Средняя точность |
||
|
летних и зимних каналов |
Слои |
Нейроны |
на тестовой и обучающей выборках |
|
7 |
1 |
30 |
80 и 72 |
|
7 и 1 |
2 |
30 и 20 |
85 и 81 |
|
7 |
2 |
20 и 10 |
78 и 70 |
|
7 и 2 |
2 |
20 и 10 |
87 и 87 |
На наш взгляд, это обусловлено доминированием лиственных пород на изучаемых вырубках и относительно высокой выраженностью сигнала хвойных в зимних каналах Landsat 8 на данной стадии сукцессии, что подчеркивает необходимость подхода к выбору важных сезонных каналов под конкретные экологические задачи. Комбинация 7 летних и 2 зимних каналов оказалась оптимальной, т. к. летние каналы несли основную информацию о состоянии растительного покрова, критически важную для различения стадий сукцессии, а ограниченное число зимних каналов добавляло умеренный контраст, не перегружая модель избыточными или конфликтующими сигналами.
Существенной стороной наших исследований явились выявления естественной типологии изучаемых местообитаний на основе совместной классификации полевых и спутниковых данных. Как справедливо отмечают авторы: «Метод управляемой классификации является... субъективным» (Данилова и др., 2017, с. 12), поскольку назначение типа биотопа (насаждений) выполняется самим исследователем, исходя из интуитивных представлений о типологии и наличных (часто фрагментарных, разновременных, устаревших...) данных. Закрепление за определенным выделом того или иного статуса всегда будет контекстуальным из-за ограниченного объема доступной информации, а также связано с большими временными потерями.
Вследствие этого мы задались вопросом, если при дешифрировании объективность априори недостижима, нельзя ли упростить, ускорить и автоматизировать процедуру выявления природной типологии на основе любой имеющейся информации. Таким приемом стала совместная обработка материалов полевого описания и спутниковых данных. Существенным моментом выполненной кластеризации и выявления типов биотопов стала возможность статистического обобщения характеристик для каждого из выявленных типов. Тем самым мы получили основание для содержательной интерпретации выявленных типов местообитаний, для определения их «естественного» типологического статуса. Рассчитанная на этой основе экстраполяция типов биотопов на всю изучаемую территорию в определенной степени сохраняет природную континуальность свойств среды, не искаженную априорными соображениями исследователя. Эта особенность анализа проявилась, в частности, в том, что на территории одновозрастных вырубок обнаружилась внутренняя неоднородность насаждений. Улавливание таких скрытых закономерностей принципиально важно в экологии животных, где точность описания гетерогенности местообитаний напрямую влияет на понимание закономерностей пространственного распределения и динамики популяций.
Мы рассчитываем, что наша публикация перенесет применение библиотеки Keras в экологических исследованиях из узкой области прикладных задач (таких как мониторинг антропогенных выбросов ‒ Косулин, 2023) на более широкое поле поиска биолого-экологических градиентов.
Заключение или выводы
Библиотека алгоритмов глубокого обучения Keras практически не используется в работах по экологии животных, хотя она позволяет существенно усилить вычислительные способности пакета R при обработке пространственной и спутниковой информации с целью изучения местообитаний животных. Наш опыт выявления типологии разнородных биотопов и создания грид-карты привел к следующим выводам.
-
1. Одновременное использование яркостных характеристик спутниковых снимков и полевых геоботанических описаний в процессе кластеризации пробных площадок позволяет в автоматическом режиме построить «естественную» типологию местообитаний (биотопов).
-
2. Степень дифференциации и точность полученной грид-карты определяются полнотой доступных эколого-биотопи-ческих и дистанционных характеристик местообитаний.
-
3. Результат классификации космического снимка, точность выявления типа растительности зависят от сочетания использованной комбинации каналов зимних и летних снимков, которые в разной степени отражают физиономические свойства растительности. В наших условиях минимально необходимая комбинация из семи летних и двух зимних каналов дала лучший результат.
-
4. Эффективность классификации определяется структурой нейронной сети, количеством нейронов в скрытых слоях, которые приходится подбирать вручную. Небольшое число нейронов, которым оперирует функция neuralnet, не позволяет за разумное время получить точную настройку. Использование слишком больших сетей в моделях Keras приводит к переобучению.
-
5. Явным преимуществом пакета Keras является возможность обработки больших массивов данных за короткое время.
