Использование рекуррентных нейронных сетей для анализа необработанного многоязычного текста

Автор: Немальцев А.С.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 6-2 (45), 2020 года.
Бесплатный доступ
В данной статье рассматриваются общие представления анализа необработанного многоязычного текста. В ходе работы была спроектирована нейронная сеть на основе долгой краткосрочной памяти (LSTM), предназначенная для разметки и дополнительного создания последовательностей символов. Нейронная сеть была обучена выделению лемм, созданию частеречной разметки и выявлению морфологических признаков. Разбивка текстов на предложения, токенизация и синтаксический анализ обрабатывались программной UDPipe 1.2. Результаты работы демонстрируют актуальность применения предложенной архитектуры в настоящее время.
Нейронная сеть, машинное обучение, рекуррентные нейронные сети, лемматизация, recurrent neural networksб softmax
Короткий адрес: https://sciup.org/170187854
IDR: 170187854 | DOI: 10.24411/2500-1000-2020-10697
Use of recurrent neural networks for analysis of unprocessed multilingual text
This article discusses general concepts of raw multilingual text analysis. A neural network based on long short-term memory (LSTM) was designed to mark sequences in order to additionally generate them at the symbol level. The network was trained to create lemmas, labels of parts of speech, and morphological characters. Sentence segmentation, tokenization and dependency analysis were handled by UDPipe 1.2. The results demonstrate the relevance of applying the proposed architecture at present.
Текст научной статьи Использование рекуррентных нейронных сетей для анализа необработанного многоязычного текста
Проект Universal Dependencies направлен на сбор последовательно аннотированных синтаксических деревьев для многих языков [1, 2]. Его текущая версия (2.2) включает общедоступные древовидные блоки для 71 языка в формате CoNLL-U. Синтаксические деревья содержат леммы, метки части речи, морфологические особенности и синтаксический анализ для каждого слова. Нейронные сети были успешно применены к большинству из задач, связанных с морфологическим разбором текста, и показали наилучшие результаты для тегов частей речи и синтаксического анализа. Поскольку проблематично размечать части речи, то для этих целей используются рекуррентные или сверточные нейронные сети с использованием выходов Softmax на уровне слов или условных случайных полей [3].
В данной статье рассматриваются общие представления анализа необработанного многоязычного текста. Автором приводится возможный вариант реализации нейронной сети, которая совместно учится предсказывать теги части речи, морфологические признаки и леммы для исследуемой последовательности слов. В основе данной системы применяется программное обеспечение UDPipe 1.2, служащее для сегментации предложений, токенизации и синтаксического анализа текстов.
Рассмотрим архитектуру описываемой системы. Система, используемая в CoNLL 2018 UD Shared Task, состоит из двух частей.
Во-первых, она берет необработанный ввод и создает файл CoNLL-U, используя UDPipe 1.2. Затем, столбцы, соответствующие лемме, части речи и морфологическим признакам, заменяются предсказанием нейронной модели. Предсказание POS-тегов и морфологических признаков выполняется с использованием сети с последовательными тегами. Для того чтобы генерировать леммы, системой применяется расширение сети несколькими декодерами, аналогичными тем, которые используются в последовательных архитектурах.
Описываемая архитектура нейронной сети состоит из трех частей: встраиваемые слои, слои извлечения объектов и выходные слои [4].
Сначала рассматриваются встраиваемые слои. Через Embd (a) мы обозначаем d-мерное вложение целого числа a. Обычно, a – это индекс слова в словаре или индекс символа в алфавите. Каждое слово wi представлено объединением трех векторов:
e(wi) =(eword (w i),ecasing (e), echar (w) )
Первый вектор, e word (wi), является 300-мерным вектором слова с предварительной подготовкой. В экспериментах использовались векторы FastText. Второй вектор, ecasing (wi), представляет собой представление восьми элементов корпуса, описанных в таблице 1. Третий вектор, echar (wi), является представлением слова на уровне символов. Мы отображаем каж- дый символ в случайно инициализированный 30-мерный вектор с■ = Emb 30 (сj) и применяем двунаправленный LSTM к этим вложениям. echar (w i), – это конкатенация 25-мерных конечных состояний двух LSTM. Результирующий e(wi) является 358-мерным вектором.
Таблица 1. Элементы, используемые в слое внедрения
|
Numeric |
Все символы являются числовыми |
|
mainly numeric |
Более 50% символов являются числовыми |
|
all lower |
Все символы в нижнем регистре |
|
all upper |
Все символы имеют верхний регистр |
|
initial upper |
Первый символ-верхний регистр |
|
contains digit |
По крайней мере один из символов является цифрой |
|
other |
Ни одно из вышеперечисленных правил не применяется |
|
padding |
Это используется для заполнения заполнителей для коротких последовательностей |
Далее идут слои извлечения объектов. Обозначим рекуррентный слой со входами х 1 ,…,хn и скрытыми состояниями һ 1 ,…,һn через һi = RNN(хi,һi-1). Используется два типа рецидивных клеток: LSTM
Sepp Hochreiter и GRU [5]. В работе применяется три слоя LSTM с 150-мерными скрытыми состояниями на векторах вложения:
һ| = LSTM (һi 1,һLi), j=1,2,3 (2)
Где һ° = e(wi). Также применяется 50%-ное выпадение перед каждым слоем LSTM. Полученные 150-мерные векторы представляют слова с их контекстами и, как ожидается, будут содержать необходимую информацию о лемме, POS-теге и морфологических признаках [6].
И наконец, выходные слои. Пометка части речи, и прогнозирование морфологических признаков являются задачами классификации на уровне слов. Для каждой из этих задач мы применяем линейный слой с активацией softmax [7].
pi = softmax(Wpһf +bp) (3)
f ik = softmax(Wfk һf +bfR) (4)
Размеры матриц Ԝfk и Ԝp векторов bp, b fk зависят от обучающего множества для данного языка: Ԝp ∈ ℝ| p |×150 , Ԝ fk ∈
ℝ| Fk|×150, k = 1,. , 21. Таким образом, мы получаем 22 функции кросс-энтропийной потери:
Lр= ∑Р=1 сe(pi,pi ) (5)
L fk = ∑P=1 сe(fiR,fiR) k=1,…,22 (6)
Чтобы сгенерировать леммы для всех слов, добавляется один декодер на основе GRU для каждого слова. Эти декодеры делят веса и работают параллельно. -й деко-
T1 Tmi
дер выводит l ■,…, lj предсказанные сим- волы леммы і-го слова. Обозначим входы в -й декодер x * ,…,xi . Каждый из x ■ является объединением четырех векторов:
x
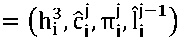
-
1. һ f - представление і -го слова после LSTM экстрактора признаков. Это единственная часть вектора x ■ , которая не зависит от j. Этот прием важен для того, чтобы информация на уровне слов всегда была доступна в декодере
-
2. сj = Emb 30 (сj ) — это то же самое вложение j-го символа слова, которое используется в BiLSTM уровня символов
-
3. π■ — это некоторая форма позиционного кодирования. Указывает количество символов, оставшихся до конца входного слова: π ■ =EMb5 (ni-j++1). Позици-
- lr1
-
4. l ■ - показатель предыдущего символа леммы. Во время обучения: l = oneһot(l i X) . Во время вывода - это вывод GRU в предыдущем временном шаге l = lГ1 .
Здесь s j ∈ ℝ 150,Ԝ0 ∈ ℝ| C |×150, где |C|-это количество символов в алфавите. Начальным состоянием GRU является выход онные кодировки были введены и успешно применялись в машинном переводе на слух [8].
Эти входы передаются на один уровень сети GRU. Выходной сигнал декодера формируется путем нанесения другого плотного слоя на состояние GRU:
-
s i = GRU(x i ,s i ) (8)
=Ԝ0s i +bо (9)
экстрактора признаков LSTM: sp =һ P . Все GRU разделяют веса. Функция потерь для вывода леммы:
Li= ∑^=1 П; ∑ Pl сe(l I ,l I )
Объединенная функция потерь является средневзвешенным значением функций потерь, описанных выше:
L=λ1L1 +λpLp +∑k=l λ fk L fk (11)
Окончательная версия системы использует λp=0.2 и λ1 =λfk=1 для каждого k.
В таблице 2 показаны основные показатели общей задачи анализа необработанного многоязычного текста для девяти синтаксических деревьев, которые использовались для обучения моделей. Метрика
LAS оценивает сегментацию предложений, токенизацию и синтаксический анализ, поэтому номера для моделей должны быть идентичны UDPipe 1.2. Метрика MLAS дополнительно учитывает POS-теги и морфологические признаки, но не леммы. Метрика BLEX [9] оценивает разбор и лемматизацию.
Таблица 2. Производительность модели по сравнению с базовой версией UDPipe 1.2
|
Метрика |
LAS |
MLAS 1 1 |
BLEX |
|||||||||
|
Представление |
Local |
TIRA |
Local |
TIRA |
Local |
TIRA |
||||||
|
Модель |
Приведенная |
UDPi pe |
Приведенная |
UDPi pe |
Приведенная |
UDPi pe |
Приведенная |
UDPi pe |
Приведенная |
UDPi pe |
Приведенная |
UDPi pe |
|
модель |
модель |
модель |
модель |
модель |
модель |
|||||||
|
English EWT |
77.12 |
77.1 |
84.57 |
77.5 |
62.12 |
68.2 |
76.33 |
68.70 |
66.35 |
70.53 |
78.44 |
71.02 |
|
English GUM |
74.21 |
74.2 |
85.05 |
74.2 |
56.43 |
62.6 |
73.24 |
62.66 |
58.75 |
62.14 |
73.57 |
62.14 |
|
English LinES |
73.08 |
73.08 |
81.97 |
73.10 |
55.25 |
64.00 |
72.25 |
64.03 |
57.91 |
65.39 |
75.29 |
65.42 |
|
French Spoken |
65.56 |
65.5 |
75.78 |
65.5 |
51.50 |
53.4 |
64.67 |
53.46 |
50.07 |
54.67 |
65.63 |
54.67 |
|
French Sequoia |
81.12 |
81.12 |
89.89 |
81.12 |
64.56 |
71.34 |
82.55 |
71.34 |
62.50 |
74.41 |
84.67 |
74.41 |
|
Finnish TDT |
76.45 |
76.4 |
88.73 |
76.4 |
62.52 |
68.5 |
80.84 |
68.58 |
38.56 |
62.19 |
81.24 |
62.19 |
|
Finnish FTB |
75.64 |
75.6 |
88.53 |
75.6 |
54.06 |
65.2 |
79.65 |
65.22 |
46.57 |
61.76 |
82.44 |
61.76 |
|
Swedish LinES |
74.06 |
74.0 |
84.08 |
74.0 |
50.16 |
58.6 |
66.58 |
58.62 |
55.58 |
66.39 |
77.01 |
66.39 |
|
Swedish Talbanken |
77.72 |
77.7 |
88.63 |
77.9 |
58.49 |
69.0 |
79.32 |
69.22 |
59.64 |
69.89 |
81.44 |
70.01 |
|
Arabic PADT |
65.06 |
65.06 |
N/A |
66.41 |
51.79 |
53.81 |
N/A |
55.01 |
2.89 |
56.34 |
N/A |
57.60 |
|
Korean GSD |
61.40 |
61.4 |
N/A |
61.4 |
47.73 |
54.1 |
N/A |
54.10 |
0.30 |
50.50 |
N/A |
50.50 |
Таким образом, в данной статье описана методика анализа необработанного многоязычного текста. Разработанная нейронная сеть способна совместно создавать леммы, частиречные разметки и выявлять морфологические признаки. Обучение нейронной архитектуры производилось на девяти синтаксических деревьях. Система была оценена на виртуальной машине Ubuntu на платформе TIRA [10] и на локальных ма- шинах с использованием тестовых наборов. Были получены результаты, показывающие, что данная архитектура работает корректно и с высокой точностью. Программа дальнейших исследований включает в себя разработку полностью многозадачной нейронной архитектуры, которая позволит проводить наиболее точный анализ текстов по ряду параметров.
Список литературы Использование рекуррентных нейронных сетей для анализа необработанного многоязычного текста
- Программное обеспечение UDPipe 1.2. - [Электронный ресурс]. - Режим доступа: https://github.com/ufal/udpipe
- Сайнбаяр Сух-Батор, Джейсон Уэстон, Роб Фергюс и др. Сквозные сети памяти, 2015. - С. 2440-2448.
- Графов Ф.М, Гамильянов Ф.М. Искусственные нейронные сети и их приложения, 2018. - С. 78.
- Tariq Rashid, Neural Networks and Deep Learning, 2016. - С. 139-150.
- Джейсон П. К. Чиу и Эрик Николс. Распознавание именованных сущностей с помощью двунаправленных lstmcnns // Труды Ассоциации компьютерной лингвистики. - 2016. - C. 357-370.
- Simon S Haykin, Pattern Recognition and Machine Learning, 2007. - С. 219-222.
- Думачев В.Н., Родин В.А. Эволюция антагонистически-взаимодействующих популяций на базе двумерной модели Ферхюльста-Пирла, 2005. - С. 11-22.
- Йонас Геринг, Майкл Аули, Дэвид Гранжье, Денис Яратс и Ян Н Дофин. Сверточная последовательность для обучения последовательности. Электронные отпечатки ArXiv, 2017.
- Ашиш Васвани, Ноам Шазеер, Ники Пармар, Якоб Ушкорейт, Ллион Джонс, Эйдан Н Гомес, Лукаш Кайзер и Илья Полосухин. Внимание - это все, что вам нужно в достижениях в области нейронных систем обработки информации, 2017. - С. 5998-6008.
- Бояновский П., Грейв Э., Жулин А., Миколов Т. Обогащая слово векторов с полсловом информации // Труды Ассоциации компьютерной лингвистики. - 2017. - №5. - С. 135-146.
