Issues of Organizing the Architecture of Processes for Identifying Digital Entities and Services

Author: Viktor Vyshnivskyi, Vadym Mukhin, Vitalii Kotelianets, Yuri Kargapolov, Valerii Zavgorodnii, Oleksandr Vyshnivskyi
Journal: International Journal of Wireless and Microwave Technologies @ijwmt
Article in issue: 4 Vol.15, 2025.
Free access
The article discusses the solution to the issue of information systems architecture, which makes it possible to separate identification flows associated with the processes of managing the identification of digital entities and data flows associated with the processes of managing data describing the properties of digital entities. At the same time, a new architecture of connections between digital entities and services is proposed, which makes it possible to create a flexible system for processing the properties of identifiers that can be described in an irregular and unstructured form. In this case, the nomenclature of the parameters of the properties of a digital entity can be customized and expanded as a separate entity, which always maintaining a connection with the identifier. This allows, within the framework of the information system, on the one hand, to adapt any identification systems and ensure the solution of convergence requirements, to ensure compliance and solution of the requirements of recognition, immutability, stability in conditions of processing large volumes of data without implementing generally accepted principles of a global unique permanent identifier, and on the other hand, build flexible connections between digital entities and services.
Digital Entities, Identity Management, Services, Information Systems, Intelligent Transport System, Identification Flow, Data Flow, Identifiers Registry, Services Registry, Resolver, ENUM
Short address: https://sciup.org/15019938
IDR: 15019938 | DOI: 10.5815/ijwmt.2025.04.02
Text of the scientific article Issues of Organizing the Architecture of Processes for Identifying Digital Entities and Services
The organization of the architecture of processes for identifying digital entities and services is aimed at rationally solving problems of managing the identification of digital entities, which, in the context of the need to solve modern challenges for converged and ubiquitous networks, becomes one of the main ones.
One of the main proposed solutions is the creation of a structure of a global unique permanent identifier for digital entities including services.
Digital entities that are different in nature can use completely different identification systems used in different technological environments (technological convergence) when using different protocol stacks and access types (convergence of fixed and mobile networks), in the interests of services that are different in nature and nature (service convergence) [1].
The variety of real entities is reflected in the virtual space in the form of digital entities. The processes that occur during the interaction of real objects, in the form of models of procedures, are also carried out in virtual space. Solving the processes of information systems that implement models of procedures is possible only if the properties of interaction and support of connectivity between digital entities relative to real objects are preserved, as well as the properties of identifying digital entities are unchanged under any circumstances.
One of the main proposed solutions is the creation of a structure of a global unique permanent identifier for digital entities, including services, which meets the requirements of recognition, immutability, and stability in conditions of processing large volumes of data. Due to the fact that digital entities are generated in different places, an important requirement regarding the preservation of connections is the preservation of digital entity identifiers during subsequent stages of processing and transformation of digital entities in information systems, which is rarely implemented in practice.
2. Research Motivations
Digital entities are commonly understood as “…an entity represented as, or converted to, a machine-independent data structure consisting of one or more elements in digital form that can be parsed by different information systems; the structure helps to enable interoperability among diverse information systems in the Internet.” [2]. In a general sense, the concept of a digital entity includes any device, any actor, any service, any process of an information system. In the article, the concept of a digital entity is considered as applied to devices and actors (device owners, users, process administrators, operators, etc.) and is separated from the concept of service, although the service model within the information system is also presented as a machine-independent data structure, which contains information about its properties.
The development of the degree of complexity of information systems and network technologies, especially those related to IoT, required detailing and subjectivization of the concept of “digital entity”, which is reflected in the provisions of ITU Recommendation Y.4459 [3], which describes the architecture of digital entities for compatibility with the IoT.
Recommendation ITU Y.4459 emphasizes the need to take into account the heterogeneous nature of information systems and proposes an architecture in which any information represented in digital form can be structured as a digital entity and assigned a globally unique identifier. Metadata under such an identifier can undergo changes without changing the globally unique identifier. ITU Recommendation Y.4459 specifies that “…the identifier allows the digital entities to be identified and discovered, regardless of where they are located or stored. Digital entities are not confined within any particular application boundary and may be moved from host to host, accessed from application to application, shared from organization to organization, without losing its ownership or management control, in order to enhance interoperability. A digital entity's data model allows ownership and access control information to be defined by data owners independently of any specific applications.” [3]. This fairly complete description of the definition of compatibility properties does not contain a description of the influence of important factors that determine the connection between the functionality of digital entities and the functionality of services that can be called by a digital entity during the operation of the information system.
Identification of digital entities is associated with the task of compatibility properties. Even if we indicate a global identifier within the ecosystem of services in frame of the first information system, this does not mean that this identifier will be understandable to services from the ecosystem of another information system. Even if some of the services of both ecosystems form many intersections. The identifier will be unique in the context of the first information system, but not guaranteed for the second. [4]
Reducing identifiers to the form of a globally unique identifier may be a task that has no solution nowadays.
3. Problem Statement
Based on the premise of diversity of identification systems and types of identifiers, taking into account that one digital entity or one service may correspond to several identifiers of different properties, we propose to consider an approach that will shift the focus of the solution to the search and solution of mapping technology aimed at any type of identifier for any type of digital entities and type of services within any technology and application of any protocol stacks. A component of the technology will be the notation form of the identifier record.
The first step to solving a set of these tasks is the task of organizing the architecture of processes for identifying digital entities and services.
Note that current identity systems have two main shortcomings. First, they lack support for SSI (Self-Sovereign Identity), which means users do not control their own data. Second, they have poor integration with private services, which results in insufficient API and SDK support for incorporating identity into business services. The proposed architectural approach addresses these issues by allowing users to strictly control the properties and execution of the services used, as well as structure APIs for these purposes.
4. Main Research Material
In any modern information system, there is an interaction of three types of entities that are heterogeneous both in nature and properties:
-
• properly digital entities,
-
• information system services,
-
• processes of data processing and decision-making in the interaction of digital entities with each other and with services.
This applies not only to Internet of Things systems, but to all modern information systems without exception. Modern information systems must take into account the need to form adaptive mechanisms that allow digital entities to determine the criteria for calling services in accordance with external or internal circumstances that momentarily influence the behavior of a digital entity in relation to the above entities. These criteria can be predetermined by the structures included in the architecture of digital entities, and can also be dynamically formed due to the combinatorics of the properties of a digital entity described in the repository for digital entities.
ITU Recommendation Y.4459 proposes to consider the structure of a digital entity architecture, which consists of three main and fundamental components [3]:
-
• global identifier service allows the assignment of a globally unique identifier to any digital entity and provides administration through a resolution protocol to translate the identifier into information about the storage location and origin of the digital entity that can be retrieved and managed in a secure and safe way, including maintaining the integrity, authentication, confidentiality of data and managing access to any information about the state of a digital entity if the service operates without interruption.,
-
• repository service (distributed storage) facilitates the secure storage, access and distribution of digital entities based on the use of their identifiers, where the repository itself is a digital entity that may or may not contain other digital entities,
-
• registry service allows you to discover any digital entity by providing search operations and providing information in the form of any metadata or data about the digital entity, about the different types of records in different parts of the registry services, about different levels of network connectivity between different parts of the registry services, about different types of data management services and information on various types of security and access control, including trust policies, authentication and authorization of client requests.
The implementation of services depends on the data model (structure and composition) of the digital entity. ITU Recommendation Y.4459 takes as a basis the provisions of the digital entity data model of ITU Recommendation X.1255 [2]. However, the principles embedded in the modeling structure do not provide solutions for a modern understanding of the connection between a digital entity and the services and processes of the information system, because clearly do not contain indications of the presence of data that determine the behavior of a digital entity in relation to emerging circumstances of the external and internal environment, information needs, taking into account the adaptability of the functioning of a digital entity to the conditions of the current moment, compatibility and interaction with other digital entities and services. Even if we take into account that services are also digital entities, the nature of the data describing them is clearly broader compared to the capabilities offered in [2] model.
There are questions regarding the registry service in the proposed architecture, since only the function of providing digital entity discovery is considered. An equally important functionality of the registry should be the resolving of a digital entity.
Resolving a digital entity using the registry means resolving its identifier into one of the network resources where the desired digital entity is located. The service solution, in addition to resolving the identifier, must contain the implementation of a procedure for selecting methods throughout the data transmission chain and determining the sequence of their execution from end to end in the form of instructions that must be agreed upon for execution between the digital entity and the service.
Taking into account the above logic and target functions of a digital entity in information systems, its architecture can be considered as combining many components that contain information in the form of data, services and procedures aimed at identifying a digital entity, defining the properties of a digital entity, determining the information needs of a digital entity in parts of services that determine the behavior of a digital entity in an information system depending on the conditions in which it is located at the moment, determining its compatibility and interaction with other entities of the information system.
This article proposes to consider the architecture of an information system, which should have a functional division:
-
• registration and management of properties of digital entity identifiers,
-
• registration and managing properties of service identifiers,
-
• management of identification processes and processes of service provision in the information system,
-
• custom applications,
-
• servers with software of services.
User applications and servers with service software can be in the external loop of the information system. In this case, the information system acquires the properties of extensible, scalable and nomenclature-independent services that can be used by actors or devices, and considering the architecture of only a digital entity is not enough. It is necessary to consider the architecture of the ecosystem, which consists of digital entities, services and data processing and decisionmaking processes and which integrates:
-
• structures of properties and values of subject data about a digital entity and service and their management,
-
• managing properties of identifiers and identification processes of a digital entity and service,
-
• information on the management of service provision processes that are related to the needs of a digital entity,
-
• information on managing the processes of ensuring the interaction of a digital entity with other entities of the information system,
-
• information about the behavior of a digital entity depending on the changing circumstances of the external and internal environment of the information system.
The proposed digital entity ecosystem architecture (Figure Fig. 1) is divided into four layers:
-
• level of data and process elements aimed at managing digital entities and services,
-
• level of services responsible for the target functions of information system components when processing data
and elements,
-
• level of implementation that determines which component of the information system is responsible for implementing management and data processing processes,
-
• level of functionality in accordance with the reference model [3], which describes four levels of management and security capabilities and is aimed at developing practical information systems architecture.
The level of data and elements describes blocks of information about the identification of a digital entity, the properties of a digital entity, the properties of a service, the needs of a digital entity for services and services, which are determined by the policies of the behavior of a digital entity depending on the circumstances of its current situation, the policies of interaction of a digital entity with other entities (digital entities, actors, services, processes) of the information system. This data set defines the set and structure of properties, as well as values or a range of values (where possible). The initial data base is being formed to move to the next level of ecosystem architecture.
The service layer describes the procedures for performing operations on a digital entity:
-
• service for identification service of the digital entity and user services allows to assign a unique identifier to digital entities and user services and ensure the processing of identification properties both in the single information space of the information system and when interacting with other information systems,
-
• service for resolving the properties of a digital entity allows to create a set of properties of a digital entity and provide their resolving depending on the needs regarding the user service in the processes of which the digital entity is involved,
-
• service for registering and resolving user service properties allows to create a set of user service properties, set the sequence of execution of the corresponding user service methods and scenarios for their execution, provide their resolving relevant to the situation specified by the digital entity,
-
• service for resolving the information needs of a digital entity in terms of user services allows to personalize the implementation of many user services for a digital entity,
-
• service for resolving the behavior of a digital entity in an information system allows to set and determine criteria for the behavior of a digital entity in the circumstances of the place, time and situation in which the digital entity is located, and solve the problems of providing user services under the conditions “here and now”,
-
• service for resolving compatibility and interaction with other entities of the information system allows to decide on the set and sequence of execution of user services that are required under the conditions “here and now” for the interaction of a digital entity with the entities of the information system.
Ecosystem “Digital entities, services and processes”
Components by architecture level of the ecosystem “Digital entities, services and processes”
|
Data and Element Layer |
Identification of digital entity and user service |
Properties of a digital entity |
User services properties |
Needs of a digital entity for user services |
Digital entity behavior policies |
Policies for interaction with other entities of the information system |
|||||
|
Services level |
Service for identifying digital entities and user services |
Service for resolving the properties of a digital entities |
Service for registering and resolving user service properties |
Service for resolving the information needs of a digital object in terms of user services |
Service for resolving the behavior of a digital object in an information system |
Service for resolving compatibility and interaction with other entities of the information system |
|||||
|
Implementation level |
Identifiers Registry |
Identifiers Registry, Resolver |
Services Registry |
Client Applications |
Services Registry, Resolver |
Resolver |
|||||
|
Model level according to Rec. Y.2060 |
Identity management layer (absent) |
Device layer |
Service support and Application support layer |
Application layer |
Service support and Application support layer |
Network layer |
|||||
Fig. 1. Architecture of the ecosystem “Digital entities, services and processes”
For the digital entity identification service, it should be noted that there is an approach focused on creating a global universal identifier [6]. Taking into account that the structure of a global universal identifier is very difficult to describe and build (if it can be done) due to the heterogeneous nature of digital entities, user services, protocol stacks used, methods of organizing access in electronic communications networks and other factors that determine the convergence of the working environment of information systems. It is proposed to consider an approach aimed not at creating a universal identifier, but at creating a notation with which one can create a universal acceptance and resolving of any identifier for a digital entity and user service of any nature.
The implementation level describes the composition of the basic components of the information systems architecture:
-
• Identifiers Registry is a distributed storage with backup support and allows to register any number of digital entity identifiers and service identifiers that are different in nature, forming a network structure of these identifiers. The Identifiers Registry contains information about the properties of digital entities and user services. The Identifiers Registry determines the parameters for personalizing the execution of a user service for a digital entity, the parameters for authenticating a digital entity, authorizing its access rights to the user service and the security of the user service execution,
-
• Services Registry represents a distributed storage with backup support and allows you to register user services, create and change structures of incoming and output data, form associations of user services with digital entities, create and describe user service execution scenarios for digital entities in the form of smart contracts. Smart contracts contain the conditions and sequences of processes and methods for executing user services,
-
• Resolver is a tool that, during the conversion of identifiers of digital entities and user services, allows one to discover their network addresses in the format of any protocol stack, followed by searching and providing information about digital entities and user services. The Resolver solves problems of compatibility and interaction of digital entities with each other and user services in a converged environment. The Resolver ensures the execution of smart contracts by generating instructions when digital entities access user services,
-
• Client Applications are a tool responsible for interaction with the user without reference to the execution environment, allowing the user to perform actions to register digital entities under his control, assign user services necessary to implement technological processes related to the functioning of digital entities, and create both a data structure and values of parameters of a digital entity
The model level describes solutions for the interaction architecture of organizing control flows and data flows in information systems in accordance with management and security capabilities.
In accordance with ITU-T Recommendation Y.2060 [4], an IoT reference model with four layers is proposed for consideration:
-
• Application layer;
-
• Service support and Application support layer;
-
• Network layer;
-
• Device layer.
Applying this model to other areas of digital entity and user service management that differ from the IoT area did not reveal any difference. Therefore, this model is usually considered as a generalized reference model when constructing the architecture of interaction between the components of information systems. As was shown in [6], four levels of the reference model are not enough to describe the processes of interaction between information system components for management and security aspects. Therefore, in the proposed architecture of the ecosystem of digital entities, user services and processes for the digital entity identification service, it is necessary to provide for a fifth level in the reference model - the identification management level, the main function of which is the resolving of identifiers and the separation of identification flows and subject data flows during the processing of information system data.
Identifier resolution operations must provide a solution to the problem of separate management of the properties of identifiers, management of identification processes, management of the provision of access to the user service and operations with the subject data of the service. Otherwise, identifier data becomes associated with subject data about the digital entity and user services assigned to the digital entity.
If for a digital entity is needed to involve new user services in the request process according to the technological process, all of the above data will always be transmitted in a single package and will require the presence in the information system architecture of a central switching node through which all requests containing subject data will pass from all digital entities to any user services and/or other digital entities. Processes involved in routing request will have a topology with a single point of failure, as presented in [6, 7].
The organization of the information system architecture with combined flows of subject and identification data is shown in Figure 2.
The central system of the “intermediary”, which ensures the interaction of digital entities and user services recorded and described in the central database (CDB), serves requests from client applications (1) and forwards these requests to the user service servers corresponding to the requests at the moment (2.1, 2.i). Processed requests are returned to the central system (3.1, 3.i) and sent to the client application (4). The disadvantages of the architecture include the presence of a central database, which can form a cache of user service databases, which is clearly not beneficial for the services, and also the fact that routing and processing requests from the client application is only possible through the information system platform.
Incorporating new user services in the information system will require (at a minimum) writing an API software, changing the structure of the CBD tables and their re-indexing. It is rare that the nature of the identifiers and properties of new digital entities and/or user services allows these operations to be carried out without modifying the platform software.
From a security point of view, the request routing scheme when gaining access to one of the transactions allows the fraudster to obtain all the information about the digital entity and its actions with the service or about all digital entities in the CDB as well as their authentication parameters.
This means that by compromising one digital entity the fraudster gains access to all digital entities, which is confirmed by the practice of personal data leaks.
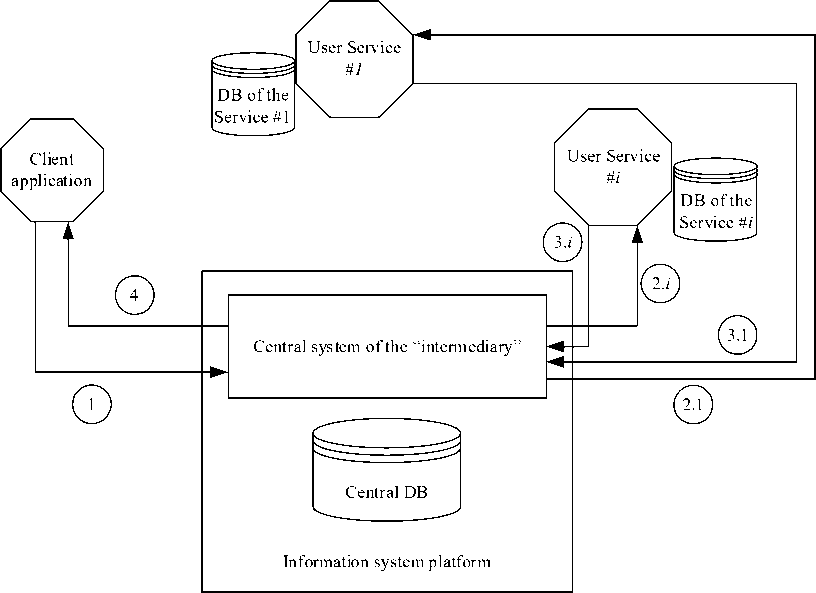
Fig. 2. Scheme of organization of information system architecture without separating identification flows and data flows
Separation of identifier property management and identification process management allows to separate data flows and identification data flows while maintaining the functionality of a single process (Figure 3).
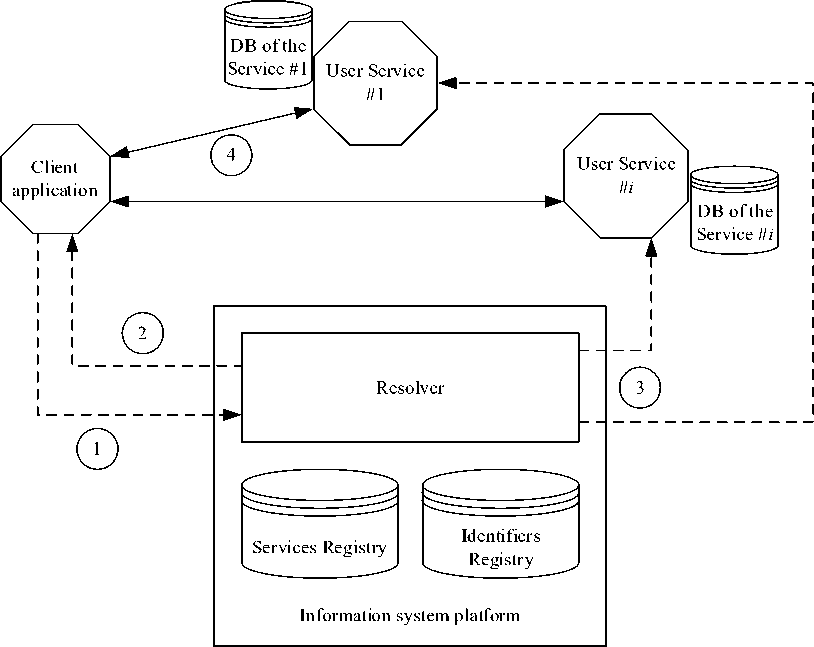
Fig. 3. Scheme of organization of information system architecture with separating identification flows and data flows
The fundamental difference from the point of view of the composition of the subsystems is the absence of a central database, which determines the impossibility of caching the contents of the service database, the presence of two Registries designed to registration and store the properties of digital entities and user services, the presence of a Resolver that determines the addresses of service servers, matches them to the addresses of digital entities, determines the sequence of user service execution in accordance with the structure of its methods and the conditions of the request from the digital entity, transmits this data for direct contact between the client application and service servers.
The request routing process is divided into three components:
-
• identification request (2) aimed to receive of network addresses of user service servers and instructions for their implementation for a digital entity in accordance with the request (1) [identification flow],
-
• identification request (3) aimed at receive network addresses of digital entities for user service servers. These digital entities will access to servers and obtain instructions for executing the service relevant to the request (1) of the digital entity [identification flow],
-
• subject request (4) when exchanging data according to instructions of smart contracts between a digital entity and user service servers [data flow].
Several services can be mapped to a single digital entity, and several scenarios of its execution can be described within a single service. Resolver performs the function of finding relevant resource records for a computable service to be performed at a given time, place and under given circumstances for a digital object. Parameters of service execution are calculated, which may be variable depending on the conditions of the situation in which the digital entity is located.
From a security point of view, the data will be separated and gaining access to identification flow will not provide access to data about object; for this it is necessary to perform actions directly from the client application, the Resolver and the server itself on which the user service software is located. Security of access to subject data is ensured by means selected by the client in accordance with the set of such tools provided by the user service.
This means that by compromising one digital entity the fraudster gains access to only one digital entities, and not all.
For an architecture using a CBD, separating identification flow and data flows is not possible. Therefore, in the architecture presented in Figure 3, two Registries are introduced- an Identifiers Registry for registering and resolving identifiers and a Services Registry for registering and resolving technological operations for providing services.
An important element of the architecture is a smart contract, which acts as a scenario plan for the execution of chains of technological operations in which a digital entity and an ecosystem of user services take part, in the environment of which the digital entity is located in the circumstances of place, time and situation.
The reliability of fault tolerance and redundancy solutions in the system is based on standardized solutions for toplevel domain name Registry systems in accordance with ICANN/PTI (IANA) requirements. These solutions are the de facto standard for ensuring the reliability of such systems, and have been adopted as BCPs.
Unlike a centralized database architecture, where new digital entities and services must be included in existing and described properties and characteristics, there is no need to modify CDB tables or rearrange table structures with subsequent re-indexing operations. The proposed solution uses a system of domain name identifiers and resource records to quickly and dynamically describe new digital entities and new services. It also organizes interrelationships between them based on the properties fixed in the resource record structures. This is a standard and common practice for DNS and makes these technologies as flexible and adaptive as possible to new contexts.
The structure of smart contracts is the subject of a separate consideration and will be described in detail in the next article.
5. Practical Implementation
The proposed architecture was tested when creating an intelligent transport system for monitoring and managing traffic on the highways of one of the regions of Ukraine.
The solution initially included subsystems:
-
• meteorological monitoring of the situation on the roads,
-
• weight and dimensional complexes,
-
• video and photo recording of offenses on the roads,
-
• informing users about the situation on road sections.
In the future, it was necessary to integrate additional subsystems:
-
• creation of a road graph,
-
• V2X infrastructure elements, including OBUs and RSUs.
As for the transfer of information between subsystems, the developers proposed a technology for creating an API based on the methods that are used for each of the above subsystems.
Each method had its own data structures, which were not originally designed as the basis of a centralized database of an intelligent transport system. Therefore, the integration tasks included the need to supplement and clarify the database tables of the intelligent transport system with new attributes.
As a result of an analysis of the costs of performing integration work using standard technology (indicated in Figure 2), values were obtained that took the project beyond the approved financial and time frame by 45-53%. This was especially true for problems associated with the implementation of V2X infrastructure elements.
According to the results of implementation of the proposed architecture based on two registries (Service registry and Identifiers registry) in the traffic flow management system of the Odessa region of Ukraine, the possibility of introducing new transport services with labor costs less by 16% compared to the costs when the traditional architecture with a centralized database was used has been achieved.
It was decided to use it as an integration architecture to combine the solution subsystems according to the Figure 3.
The solution made it possible to implement seamless interaction of digital entities of various properties with the set of functions of each subsystem. At the same time, digital entities used identifiers with different characteristics, for example, the state registration plate of the vehicle, MSISDN, VIN code, information about vehicle drivers, station number, etc.
NAPTR and TXT domain name resource records were used as intelligent transport system records that made it possible to create and store associations between digital entities and user services.
To organize the interaction of domain names and user services, ENUM technology was used. A description of the technology is given in [10 - 14].
Information about the properties of digital entities and the properties of their identifiers is stored in the Identifiers Registry in the form of domain name records. Information about the properties of user services is stored in the Services Registry, in the same way that information about the telecommunications services used is stored in the IANA repository.
An example of recording associations between digital entities and services in the Identifiers Register is shown in Figure 4.
Domains > Domain Viewer
General information Contacts Nome сервера Linked services
Selecting and attaching services to a domain name. These services will be listed as the proper resource records for the services in that domain.
| In order to oonnect/configure the service, specify the region, city where the service will be used.
All Areas
Region
Enter an area enter meaty

In order to connect a service th at will be in the specified region/city, enter the name of the service in the field below to select it.
Service Name
Linked services
Provider
Service Name
Add service
Service Type
LLC Cobvergent Systems
Detector transport Voice-link DETECTOR-TRANSPORT-VOCE-
2 LINK-2
LLC Cobvergent Systems
Router ROUT955 2
ROUTER-RUT955-2
LLC Cobvergent Systems
360 TRASSIR 2 Survey Camera
0BZORNAYA-CAMERA-360-
TRASSIR-2
LLC Cobvergent Systems
Roadway Sensor 2
DATCHIK-DOROZHJCGO-POLjOTNA- 2
LLC Cobvergent Systems
Weather Station 2
METEOSTANCIYA-2
Fig. 4. Example of record of association between digital entity and user services
An example of organizing of records of associations between digital entities and user services is given in Figure 5
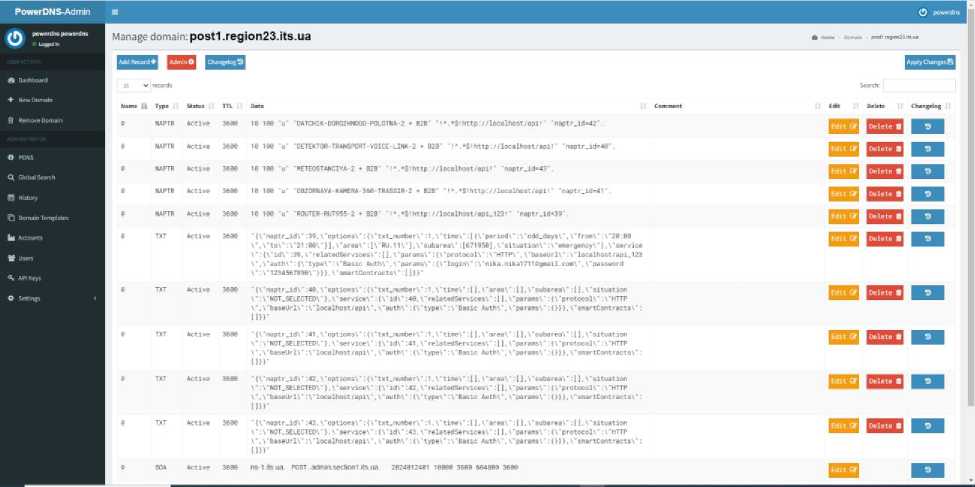
Fig. 5. Example of organization records of association between digital entity and user services
Regarding the above example in Figure 5, it should be noted that the location of user services described by the local URL was determined by the internal contour of the local network of the intelligent transport system. This was done to improve the security level of the system. It is acceptable that global URIs can be specified for user services.
6. Conclusions
The material presented in the article allows to formulate the principles of a new architecture for the processes of identifying digital entities and user services as a single process that allows to separate:
-
1) management of properties of identifiers of the digital entity and user service,
-
2) management of identification processes,
-
3) management of the execution of processes for providing user services based on requests from digital entities.
This separation allows to organize a flexible system for processing identifiers, focusing not only on the structure of the identifier itself, but on its properties. Identifier properties can be described in an irregular, unstructured form, customizable and expandable in its nomenclature, the composition of property parameters as a separate entity, but always maintaining a connection with identifier. An example of such a description of identifier properties is domain name resource records.
At the same time, domain names as identifiers have a structure that can adapt any identification system and provide solutions to convergence requirements, for example, the use of ENUM technologies.
This creates the prerequisites for meeting and solving the requirements of recognition, immutability, and stability in conditions of processing large volumes of data without implementing the generally accepted principles of a global unique permanent identifier, described, for example, in [8, 9], in particular, the mandatory presence of a strict structure of the body of the identifier.
Management of identification processes can begin with resolving domain names of digital entities and user services, followed by decision-making in accordance with the parameter values prescribed for a specific situation, which will be transferred to service management processes.
