Измерение тепловых потоков в лабораторной модели термоэлектрического холодильника

Автор: Яковлев А.А., Кузин Д.А., Свердлов Е.
Журнал: Журнал Сибирского федерального университета. Серия: Техника и технологии @technologies-sfu
Рубрика: Информационно-коммуникационные технологии
Статья в выпуске: 5 т.18, 2025 года.
Бесплатный доступ
Классификация звуков окружающей среды (Environmental Sound Classification – ESC) – это область исследований, которая привлекает к себе все большее внимание, потому что большинство научных исследований сосредоточены на изучении речевых и музыкальных сигналов. Звуки окружающей среды, входящие в эту классификацию: звон битого стекла, звук летящего вертолета, плач ребенка и т.д., могут помочь в системах видеонаблюдения, системах оперативного реагирования на происшествия, а также в расследованиях преступлений. Цель данной работы состоит в анализе широкого спектра литературы в области классификации звуков окружающей среды, включающей в себя описание методов предварительной обработки данных, извлечения признаков в моделях машинного обучения. Исследователи использовали методы удаления шума и улучшения качества для предварительной обработки сигнала. В данной работе описываются различные наборы данных, которые использовались в недавних исследованиях с указанием максимальной достигнутой точности классификации моделями машинного обучения. Глубокие нейронные сети зачастую превосходят традиционные модели машинного обучения. В данной работе также рассматриваются задачи и перспективные исследования в области классификации звуков окружающей среды.
Классификация звуков окружающей среды, извлечение признаков из текста, отбор признаков, классификаторы машинного обучения, глубокие нейронные сети
Короткий адрес: https://sciup.org/146283157
IDR: 146283157 | УДК: 621.9
Environmental Sound Classification: A Descriptive Review of the Literature
Automatic environmental sound classification (ESC) is one of the upcoming areas of research as most of the traditional studies are focused on speech and music signals. Classifying environmental sounds such as glass breaking, helicopter, baby crying and many more can aid in surveillance systems as well as criminal investigations. In this paper, a vast range of literature in the field of ESC is elucidated from various facets like preprocessing, feature extraction, and classification techniques. Researchers have used various noise removal and signal enhancement techniques to preprocess the signals. This paper explicates multitude of datasets used in recent studies along with the year of publication and maximum accuracy achieved with the dataset. Deep Neural Networks surpass the traditional machine learning classifiers. The future challenges and prospective research in this field are proposed. Since no recent review on ESC has been published, this study will open up novel ways for certain business applications and security systems.
Текст научной статьи Измерение тепловых потоков в лабораторной модели термоэлектрического холодильника
Цитирование: Яковлев А. А. Измерение тепловых потоков в лабораторной модели термоэлектрического холодильника / А. А. Яковлев, Д. А. Кузин, Е. Свердлов // Журн. Сиб. федер. ун-та. Техника и технологии, 2025, 18(5). С. 688–707. EDN: YTWLZU соотношение сигнал/шум из-за того, что источник звука может быть не расположен в непосредственной близости с источником звука. Окружающая среда содержит множество накладывающихся друг на друга звуков, что создает проблемы для классификации звуков окружающей среды. Хотя видеокамеры можно использовать для распознавания окружающей обстановки, они не являются всенаправленными, как микрофоны.
Классификация звуков окружающей среды включает сбор данных, предварительную обработку, извлечение признаков, а также выбор признаков и классификацию данных (рис. 1). Настраивая любой из этих этапов и внедряя новые методы, исследователи могут значительно повысить производительность. Существует небольшое количество стандартных наборов данных, которые используются в различных исследованиях. Предварительная обработка имеет решающее значение для устранения фонового шума и подготовки данных к извлечению признаков.
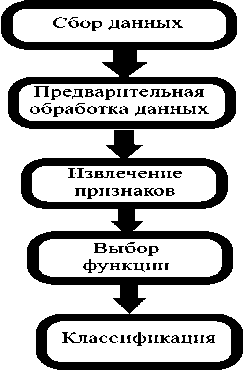
Рис. 1. Этапы классификации звуков окружающей среды
Fig. 1. Stages of Environmental Sound Classification
Исследователи работали с различными типами признаков, благодаря которым можно точно классифицировать источник звука. Примерами таких признаков являются временные, спектральные и динамические временные рамки. Для уменьшения количества признаков звуковых сигналов можно выбрать наиболее важные признаки. Это может позволить оптимизировать работу алгоритма без потери точности классификации. Исследователи в своих работах используют различные методы отбора признаков. Наконец, различные исследования показали, что для анализа классификации звуков окружающей среды используются следующие классификаторы машинного обучения: метод опорных векторов (Support Vector Machine – SVM), метод K-ближайших соседей (K-Nearest Neighbour – K-NN), дерево решений (Decision Tree learning – DT) и скрытые марковские модели (Hidden Markov Models – HMM). Сверточные нейронные сети (Convolution Neural Nework – CNN), многослойные персептроны (Multilayer Perceptron – MLP) и рекуррентные нейронные сети (Recurrent Neural Networks -RNN) открыли новые возможности в анализе классификации звуков окружающей среды [4].
Стремление к изучению явления
Распознавание звуков окружающей среды имеет несколько потенциальных применений. Системы видеонаблюдения работают на основе концепции распознавания звуков окружающей среды (Environmental Sound Recognition – ESR). Распознавание звуков окружающей среды также используется в навигации роботов. Распознавание звуков окружающей среды можно настроить для обнаружения преступной деятельности и использовать в различных других системах безопасности. Мониторинг дикой природы, такой как классификация птиц, животных, лягушек и летучих мышей, стал возможен благодаря распознаванию звуков окружающей среды. Распознавание звуков окружающей среды может быть использовано для разработки систем мониторинга шума, чтобы можно было разработать и применять алгоритмы оперативного реагирования на возникшие ситуации. В одном из исследований спектрально-временной анализ звуков улья помог контролировать его здоровье.
Значительный вклад в проведение исследования
Майкл Каулинг и Рената Ситте стали первыми, кто изучил методы классификации звуков окружающей среды. В исследовании, представленном в этой статье, подробно объясняется каждый этап процесса классификации звуков окружающей среды. Используемые наборы данных, методы для предварительной обработки, различные методы извлечения объектов и звуковых характеристик, а также классификация методов, использовавшихся исследователями в прошлом, проиллюстрированы в данной работе.
Набор данных
Первым этапом в классификации звуков окружающей среды является сбор данных. На этом этапе обсуждаются как общедоступные, так и самостоятельно собранные наборы данных, которые используются исследователями для классификации звуков окружающей среды. Большинство исследователей использовали три общедоступных набора данных – ESC-10, ESC-50 и UrbanSound8K. ESC-10 содержит 400 записей, разделенных на 10 категорий (лай собаки, дождь, морские волны, плач ребенка, тиканье часов, чихание человека, звук вертолета, бензопилы и треск огня), каждая из которых содержит 40 записей продолжительностью 5 секунд. ESC-50 содержит 2000 записей, разделенных на 50 категорий, которые сгруппированы в 5 основных категорий: животные, звуки природы и воды, невербальные звуки человека, звуки интерьера и бытовые шумы, а также внешние и городские шумы. Каждая категория содержит 40 записей, продолжительностью 5 секунд. ESC-10 является подвидом ESC-50. UrbanSound8K состоит из 8732 звуковых записей, сгруппированных в 10 категорий: кондиционер, автомобильный гудок, играющие дети, лай собаки, работа дрели, работающий на холостом ходу двигатель, выстрел, отбойный молоток, полицейская сирена, уличная музыка. Продолжительность каждой записи в наборе данных составляет менее 4 секунд. Эти звуки были собраны из бесплатного звукового хранилища и вручную отсортированы и помечены для создания набора данных Urbansound8K для распознавания звуков окружающей среды. Другой набор данных для распознавания звуков окружающей среды, BDLib, был собран авторами в Bountourakis из серии звуковых эффектов Sony Pictures, полной библиотеки звуковых эффектов BBC (British Broadcasting Corporation – Британская Вещательная Корпорация) и того же бесплатного звукового хранилища, которое использовалось для создания – 691 –
Urbansound8K. BDLib содержит 120 записей, разделенных на 10 категорий, каждая из которых содержит 10 аудиофайлов продолжительностью десять секунд.
Предварительная обработка
Предварительная обработка необходима для устранения шума или усиления и сглаживания звукового сигнала. Сложность сбора звуков окружающей среды заключается в том, что на записи звука интересующего объекта могут присутствовать шумы, которые могут иметь сопоставимый с полезным сигналом уровень громкости. Из-за шума снижается точность классификации звуков окружающей среды. Таким образом, аудиосигналы необходимо предварительно обработать, чтобы они были готовы к использованию для выделения признаков и классификации. В этом разделе обсуждаются методы предварительной обработки, используемые исследователями в области классификации звуков окружающей среды.
Уменьшение размерности – это метод предварительной обработки, позволяющий уменьшить размер спектрограмм произвольной длины. Спектрограммы сглаживаются и в них устраняются шумы с помощью этого метода предварительной обработки. Шумы устраняются с помощью определенных методов улучшения сигнала. В исследованиях Цзя-Цзин Вана (Факультет электротехники, Национальный университет Чэнгун, Тайнань, Тайвань) аудиосигналы усиливаются с помощью набора фильтров восприятия и метода, основанного на подпространстве [82].
Извлечение признаков
Признаки – это отличительные характеристики звуков, которые извлекаются и вводятся в классификаторы машинного обучения. Извлечение признаков является одним из важнейших этапов классификации звуков окружающей среды. В литературе используются различные методы выделения признаков. В этом разделе подробно описаны различные функции и методы извлечения признаков, используемые исследователями при изучении набора звуковых явлений. На эффективность распознавания звуков окружающей среды в значительной степени влияет тип извлекаемых признаков.
Различные исследователи подробно изучили звуковые характеристики. Признаки, используемые для классификации звуков, в основном подразделяются на четыре категории: кеп- – 692 –
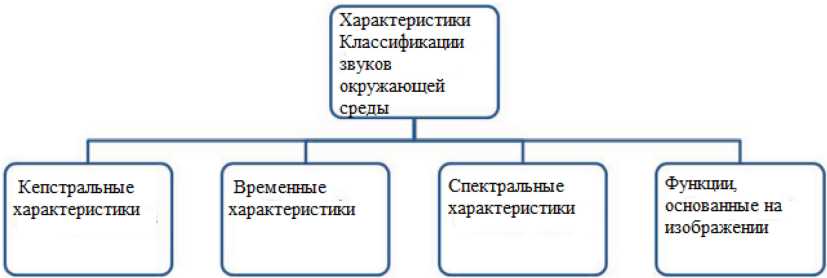
Рис. 2. Признаки, используемые при классификации звуков окружающей среды
Fig. 2. Features used in Environmental Sound Classification стральные (MFCC Сумайр Азиз, 2018), временные (Янг и Кришнан, 2017), спектральные (Ма и др., 2018) и признаки, основанные на изображении (Амирипариан и др., 2017) (рис. 2) [5].
Кепстральные характеристики
Мел-частотные кепстральные коэффициенты (MFCC – Mel Frequency Cepstral Coefficients) широко используются при классификации звука в таких областях, как музыка, человеческая речь и окружающая среда. MFCC вычисляются путем предварительного вычисления преобразования Фурье звукового сигнала, сопоставления мощностей по шкале mel, вычисления логарифма из степеней и применения дискретного косинусного преобразования в шкалах mel log. Амплитуда этих спектров называется MFCC. Аудиосигналы в основном представлены с использованием MFCC. Они широко используются в классификации звуков окружающей среды (Environmental Sound Classification – ESC). В работе Ван Цзя-Цзин (Национальный центральный университет, Тайвань) используется вариант MFCC, называемый независимым компонентным анализом (ICA – Independent Component Analysis), преобразованный в MFCC, который обеспечивает устойчивый прирост производительности. Исследователи утверждают, что MFCC не работают, если аудиосигналы зашумлены, и, соответственно, они не могут отражать нестационарные свойства звуков окружающей среды. Основные характеристики линейного предсказания возбуждения кода (CELP – Code Excited Linear Prediction) превосходят функции MFCC над ESC. Комбинация функций на основе CELP и MFCC помогает достичь точности в 95,1 % [81].
Временные характеристики
Временные характеристики также называются характеристиками временной области. Они извлекаются непосредственно из звуков. Скорость пересечения нуля (ZCR – Zero-Crossing Rate), автокорреляция, линейное прогнозирующее кодирование (LPC – Linear Predictive Coding), энергетическая энтропия (EE - Energy Entropy), кратковременная энергия (STE – Short Time Energy) и среднеквадратичное значение (RMS – Root Mean Square) – вот некоторые из характеристик, которые относятся к временной области. Скорость пересечения нуля – это частота изменения знака сигнала. Скорость пересечения нуля, энергетический диапазон применяются – 693 – в области распознавания звуков окружающей среды (Environmental Sound Recognition – ESR), как описано в исследовании Селины Чу (NASA). Особенности узкополосной автокорреляции (NB-ACF – Narrowband Autocorrelation features) могут обеспечить более высокую точность по сравнению с MFCC и дискретными вейвлет-коэффициентами. Линейное прогнозирующее кодирование (LPC) – это линейное представление аудиосигнала, оно не учитывает нелинейные аспекты аудиосигнала.
Признаки, основанные на анализе изображения
Спектрограмма – это временно-частотное представление образца аудиосигнала. Признаки, основанные на анализе изображений, доказали свою эффективность для классификации звуков окружающей среды. В исследовании Чжана Хаоминя используются спектрограмма и рекуррентная диаграмма (CRP – Cross Recurrence Plot). Спектрограмма представляет собой звуковой сигнал, визуально изображенный на различных частотах. CRP визуализирует моменты времени, когда состояния в двух динамических системах возникают одновременно.
Признаки логарифмической спектрограммы (LMS) показали хорошие результаты по сравнению с мел-частотными кепстральными коэффициентами (MFCC). Признаки функции логарифмической спектрограммы вычисляются путем простого расчета преобразования Фурье аудиосигнала, затем рассчитывается логарифм этих частот и отображается в мел-шкалу для создания спектрограмм. Признаки логарифмической спектрограммы генерируются для каждого аудиоклипа. Признак логарифмической спектрограммы можно объединить со спектрограммой Log Gammatone для достижения хорошей точности 83,80 % по сравнению со случаем, когда используется только функция логарифмической спектрограммы (81,00 %). Признак логарифмической спектрограммы объединен с признаками ввода необработанных сигналов, и для классификации звуков окружающей среды достигается значительное улучшение точности. Статические признаки дельта-логарифмического преобразования и статические признаки логарифмического изменения передаются в качестве входных данных в сверточную нейронную сеть (CNN – Convolutional Neural Network), и точность повышается по сравнению с современной статической дельта-логарифмической сверточной нейронной сетью.
Спектральные характеристики
Спектральные характеристики получаются из временных характеристик путем преобразования временных характеристик. Могут быть применены следующие преобразования: дискретное чирплет-преобразование, дискретное преобразование кривых, дискретное преобразование Гильберта, а также быстрое преобразование Фурье. В исследованиях Энджуна Хвана и Бена Чжуна Хва (Университет Корё, Сеул, Республика Корея 2009) с помощью преобразований достигается точность 86,09 %. Некоторые спектральные признаки, такие как спектральный контраст, спектральный центроид, спектральная полоса пропускания, спектральная асимметрия, спектральная плоскостность, спектральные динамические функции, набор признаков MPEG-7, широко используются в классификации звуков окружающей среды. Используя три признака MPEG-7: расширение спектра, спектральный центроид и спектральную плоскостность, достигается точность 85,10 %. Применение некоторых признаков MPEG-7 позволяет достичь высокой точности классификации при использовании вместе с MFCC. Признакам – 694 –
MPEG-7 сначала присваивается приоритет с использованием коэффициента дискриминанта Фишера, а затем PCA (Principal Component Analysis – Метод главных компонент) применяется к 30 основным признакам MPEG-7, чтобы получить 13 признаков. Эти 13 признаков объединены с мел-частотными кепстральными коэффициентами для классификации звуков окружающей среды [28].
Выбор признаков
Существует несколько признаков, которые можно извлечь из записей звуков, но не все из них являются информативными для всех приложений. Для разных приложений требуются разные наборы признаков, и важно выбрать оптимальное подмножество, чтобы снизить вычислительную сложность. Расчет высших размерностей особенностей приводит к увеличению времени вычислений. Признаки, которые не способствуют классификации, или признаки, которые коррелируют, могут быть отброшены. Исследователи экспериментировали с различными наборами признаков классификации звуков окружающей среды. В этом разделе обсуждаются заметные методы выбора признаков и комбинации признаков, использованные исследователями в прошлом для классификации звуков окружающей среды.
Анализ главных компонентов можно использовать для выбора признаков. Василейос Ба-унтоуракис (Университет Аалто, Хельсинки, Финляндия, 2015) экспериментировал с тремя наборами признаков. Комбинация мел-частотных кепстральных коэффициентов (Mel Frequency Cepstral Coefficients – MFCC), линейного прогнозирования кепстральных коэффициентов (Linear Predictive Cepstral Coefficients – LPCC), измерения спектральной плоскостности (Spectral Flatness Measure – SFM), cпектральный коэффициент усиления (Spectral Crest Factor – SCF), скорости перехода через нуль (Zero Crossing Rate – ZCR), спектральной центроиды, спектрального расширения, спектрального спада, спектральной асимметрии, спектральной резкости и спектральной гладкости обеспечивает высочайшую точность классификации с помощью классификаторов: k-NN (К-классификатор ближайших соседей), метод опорных векторов (SVM -Support Vector Machine) и искусственная нейронная сеть (ANN – Artificial Neural Network). В исследовании Ю Су (Северо-Западный политехнический университет, Сиань, Шэньси, Китай, 2019) из пяти слуховых характеристик создаются два набора функций: логарифмическая спектрограмма (LM), MFCC, цветность, спектральный контраст и Тоннетц (CST). Признаки логарифмической спектрограммы (LM) и функции цветности, спектрального контраста и тоннетца (CST) объединены (набор функций LMC) и функции MFCC и CST объединены (набор функций MC). Оба набора признаков помогли достичь точности 95,20 % и 95,30 % соответственно. В Исследовании Астмы Рабауи (Институт Френеля, Марсель, Франция 2008) выбираются наборы векторов признаков, а не наборы признаков [67].
Классификация
После извлечения и выбора признаков акустические записи классифицируются по различным категориям. Существует множество подходов к классификации. На рис. 3 показаны основные классификаторы, используемые в классификации звуков окружающей среды в литературе. В этом разделе рассматриваются различные классификаторы машинного обучения и глубоких нейронных сетей, используемые для классификации звуков окружающей среды.
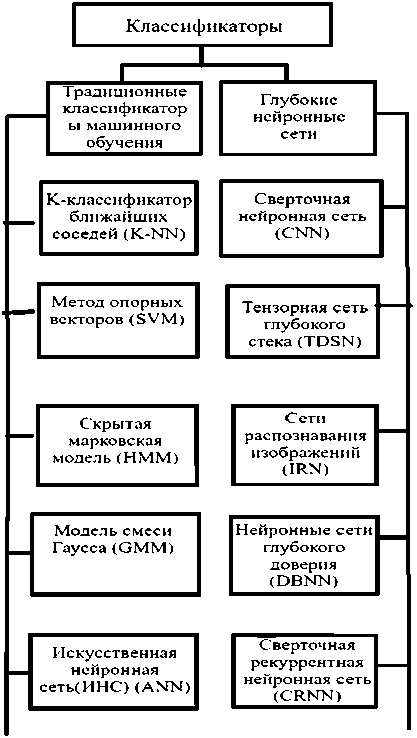
Рис. 3. Алгоритмы классификации, используемые в классификации звуков окружающей среды Fig. 3. Classification algorithms used in Environmental Sound Classification
Традиционные классификаторы машинного обучения
Исследователи сравнивают несколько алгоритмов машинного обучения для классификации городского звука.
Метод опорных векторов (SVM)
Метод опорных векторов – самый популярный классификатор машинного обучения с учителем, используемый для звуковых приложений. Существуют определенные типы методов опорных векторов в зависимости от используемых ядер: двоичные, линейные, полиномиальные, радиальные базисные функции и гауссовы ядра. Методы опорных векторов также можно разделить на многоклассовые методы опорных векторов и методы опорных векторов одного класса. Метод опорных векторов помог достичь высокой точности в различных прошлых исследованиях по классификации звуков окружающей среды. Многоклассовый метод опорных векторов использовался в исследовании Ван Цзя-Цзина (Национальный университет Чэнгун, Тайнань, Тайвань, 2008), и была получена значительная точность (91,10 %). Метод опорных – 696 – векторов одного класса использовался для классификации звуков окружающей среды в исследовании Астмы Рабауи (Институт Френеля, Марсель, Франция 2008) [53].
Метод опорных векторов в сочетании с K-ближайшими соседями превосходит скрытую марковскую модель для классификации звуков окружающей среды с использованием трех низкоуровневых аудиодескрипторов набора функций MPEG-7.
K‑классификатор ближайших соседей (K‑NN)
K-NN в основном используется для распознавания образов. Здесь k – количество ближайших соседей. Новая звуковая запись присваивается классу, к которому принадлежит большинство ближайших соседей. K-NN широко используется в ESC. Исследователи пытались варьировать значение k. Значение из k как 8 дал самый высокий уровень классификации – 87,52 %.
Искусственная нейронная сеть (ANN)
Искусственная нейронная сеть – это классификатор, который работает как биологический нейрон. Он состоит из набора нейронов. Первоначально входной слой получает случайные веса и входные данные. Результат сравнивается с желаемым результатом. Если оба значения различны, веса корректируются. В искусственной нейронной сети скорость обучения варьируется. Скорость обучения регулирует смещение и изменения веса, чтобы алгоритм обучался адекватно. Уровень распознавания даст результат 87,30 %, если установленное значение скорости обучения будет равно 0,5.
Скрытая марковская модель (HMM)
Скрытая марковская модель успешно использовалась для распознавания звуков окружающей среды (Environmental Sound Recognition – ESR). Исследователи Йи Чжан и Тадахиро Курода (Университет Кейо и Университет электрокоммуникаций, Токио, Япония, 2014 г.) заявили, что скрытая модель Маркова обеспечивает хорошую точность классификации (96,90 %) и потребляет меньше энергии по сравнению с другими алгоритмами. Скрытая марковская модель на основе гауссовской смеси обеспечивает меньшую точность классификации звуков окружающей среды по сравнению с нейронными сетями (54,80 %).
Исследователи, использующие в качестве источника исследование Хаоминга Чжана (Научно-технический университет Китая, Хэфэй, Аньхой, 2015), утверждают, что основанные на скрытых марковских моделях частотные кепстральные коэффициенты Mel для классификации звуков окружающей среды терпят неудачу в случае зашумленных акустических записей [87].
Модель смеси Гаусса (GMM)
Модель смеси Гаусса представляет собой параметрический классификатор. Модель смеси Гаусса – это подход, в котором модель состоит из нескольких гауссовских компонент. Модель смеси Гаусса доказала свою эффективность для классификации звуков окружающей среды.
Модели на основе глубоких нейронных сетей (DNN)
Нейронные сети (NN) показали хорошие результаты в классификации звуков окружающей среды. Двухслойные нейронные сети превзошли по эффективности скрытую модель Мар-– 697 – кова, основанную на модели гауссовой смеси, как утверждает Огужан Генчоглу (Университет Тампере, Тампере, Финляндия, 2014) [27].
Сверточная нейронная сеть (CNN)
Сверточная нейронная сеть – это нейронная сеть с глубоким обучением. Различные предлагаемые сверточные нейронные сети превзошли по точности классификацию в распознавании звуков окружающей среды. Первое использование сверточной нейронной сети было сделано PiczackCNN, в котором было продемонстрировано, что сверточная нейронная сеть превосходит модель машинного обучения, основанную на частотно-кепстральных коэффициентах Mel.
Различные гиперпараметры, такие как заполнение, размер слоя максимального пула и длина шага, изменяются, чтобы найти лучшую комбинацию и получить хорошую точность. Точность 92,90 % достигается на UrbanSound8k с использованием сверточных нейронных сетей. В исследованиях Хосе Марии Мендосы (Филиппинский университет, Кесон-Сити, Национальный столичный регион, Филиппины, 2018) используются последовательные, параллельные и сквозные сверточные нейронные сети, причем параллельные сверточные нейронные сети дают самую высокую точность (83,79 %). Для распознавания звуков окружающей среды предлагается двухпотоковая сверточная нейронная сеть с моделью объединения на уровне принятия решений (TSCNN-DS) [39].
Два набора признаков вводятся в две сверточные нейронные сети, а выходные данные слоев softmax обеих сетей объединяются с использованием теории доказательств Демпстера-Шейфера, что приводит к точности 97,20 %. Было также показано, что этот подход повышает точность при объединении сквозной обученной сверточной нейронной сети и сверточной нейронной сети, основанной на обучении. Двухслойная сверточная нейронная сеть обеспечивает точность 77 % в наборе данных ESC-10 и 49 % в наборе данных ESC-50. Сквозная сверточная нейронная сеть (64 %) объединяется со статической логарифмической сверточной нейронной сетью mel или статической дельта-логарифмической сверточной нейронной сетью mel для достижения высокой точности 69,3 и 71 % соответственно.
Саджад Абдоли, Патрик Кардинал и Алессандро Л. Коер (2019) использовали одномерную сквозную сверточную нейронную сеть, которая обучается непосредственно на представлении звука и обеспечивает точность 89,00 %. Авторы заявили, что эта архитектура использует меньшее количество параметров, поскольку по сравнению с двумерными представлениями и двумерной сверточной нейронной сетью. В другом исследовании, проведенном в 2021 году, одномерная сквозная сверточная нейронная сеть используется наряду с байесовской оптимизацией и ансамблевым обучением. Модель изучает функции непосредственно из аудиопредставления, а не из функций, созданных вручную. В исследовании Сяоху Чжана, Юэсянь Цзоу и Вэй Ши (Пекинский университет, Пекин, Китай, 2017 г.) функции активации (ReLu (выпрямленная линейная единица), PReLu (параметрическая выпрямленная линейная единица), SoftPlus, LeakyReLu (выпрямленная линейная единица), ELU (экспоненциальная линейная единица) варьируются для определения лучшей функции активации для классификации звуков окружающей среды. Leaky Rectified Linear Unit обеспечивает высочайшую точность классификации с использованием расширенных фильтров, поскольку восприимчивое поле сверточных слоев будет хранить больше контекстной информации [1].
Очень глубокая сверточная нейронная сеть с 34 весовыми слоями повышает точность до 71,80 %, что на 15,56 % больше, чем сверточная нейронная сеть с 2 весовыми слоями. Значительное улучшение точности (79,00 %) наблюдается, когда глубокая сверточная нейронная сеть работает с дополненными данными. Чжэн Фан, Бо Инь, Зехуа Ду, Сяньцин Хуан (Китайский океанический университет, Циндао, Китай, 2022 г.) предложили ресурсно-адаптируемую сверточную нейронную сеть (RACNN), которая может снизить требования к оборудованию традиционной сверточной нейронной сети и повысить скорость и точность [24].
Тензорная сеть глубокого стека (TDSN)
Тензорная сеть глубокого стека похожа на сеть глубокого стека (DSN), но она имеет параллельные скрытые уровни в каждом модуле по сравнению с последовательными скрытыми слоями в случае сети глубокого стека. Сеть Tensor Deep Stacking достигает точности 56,00 % в наборе данных ESC-10.
Сверточная рекуррентная нейронная сеть (CRNN)
Сверточная нейронная сеть сочетается с рекуррентной нейронной сетью (RNN) для классификации звуков окружающей среды. Функции извлекаются с помощью сверточной нейронной сети, а временная агрегация извлеченных функций выполняется с помощью рекуррентной нейронной сети. Сверточная рекуррентная нейронная сеть доказала свою эффективность для классификации звуков окружающей среды. В исследовании Бенхаза Бахмеи, Элины Бирмингем и Сиамака Арзанпура (Университет Саймона Фрейзера, Бернаби, Британская Колумбия, Канада, 2022 г.) признаки извлекаются с использованием глубокой сверточной генеративной состязательной сети, а дальнейшая классификация выполняется с использованием сверточной рекуррентной нейронной сети [7].
Сети распознавания изображений
Очень глубокая сверточная нейронная сеть, первоначально разработанная для классификации изображений, может быть использована для классификации звуков окружающей среды. В исследовании Венкатеша Боддапати, Андрея Петефа, Джима Расмуссона и Ларса Лундберга (Sony Corporation, Токио, Япония, 2017 г.) AlexNet и GoogLeNet используются для функций на основе изображений для классификации звуков окружающей среды, и достигается значительная точность. Используется глубокая нейронная сеть в стиле Visual Geometry Group (VGG) [11].
Нейронные сети глубокого убеждения (DBNN):
Нейронная сеть глубокого убеждения стала популярной, поскольку традиционная глубокая нейронная сеть имела такие проблемы, как медленное обучение и необходимость большого количества обучающих данных. Нейронная сеть глубокого убеждения превосходит скрытую марковскую модель на основе модели гауссовой смеси и нейронные сети с двумя или пятью уровнями для классификации звуков окружающей среды.
Некоторые другие классификаторы, такие как самоорганизующиеся карты, глубокий классификатор на основе самостоятельного обучения и байесовские сети убеждений, изучаются исследователями в области распознавания звуков окружающей среды.
В литературе используется множество классификаторов для классификации звуков окружающей среды. Выбрать подходящий классификатор становится непросто. При классификации, такой как извлечение признаков, существует компромисс между производительностью и вычислительными затратами. Не существует исследования, в котором сравнивалась бы эффективность всех классификаторов, использованных в прошлых исследованиях. В исследовании Сиддхарта Сигтиа, Адама М. Старка, Саши Крстуловича и Марка Д. Пламбли (Университет Суррея, Гилфорд, Суррей, Великобритания, 2016 г.) были описаны три алгоритма классификации: нейронные сети глубокого обучения, метод опорных векторов и модели гауссовой смеси. сравниваются с точки зрения производительности и вычислительных затрат для распознавания звуков окружающей среды. Нейронные сети глубокого обучения обеспечивают значительную точность, но требуют высоких вычислительных затрат. Метод опорных векторов обеспечивает компромисс между точностью и вычислительными затратами. Модели гауссовой смеси обеспечивают приемлемую точность при низких вычислительных затратах [64].
При выборе классификатора можно учитывать следующие параметры:
– Вычислительная сложность – хороший классификатор должен обладать низкой вычислительной сложностью. Это относится к времени и мощности, требуемым классификатору для получения результатов. Чем меньше времени требуется классификатору для обработки данных и чем меньше энергии он потребляет, тем лучше.
– Точность распознавания – классификатор должен иметь высокую точность. Он должен иметь возможность точно классифицировать векторы признаков.
-
– Устойчивость к шуму – хороший классификатор устойчив к шуму. Он должен игнорировать изменения, вызванные масштабированием амплитуды или полосы пропускания аудиосигнала.
Анализ параметров основных ссылок
Применение множества алгоритмов к задаче до выбора используемого алгоритма непрактично. Сравнивая алгоритмы машинного обучения, используемые в зарождающихся исследованиях, мы анализируем их со следующих аспектов. Читатели могут выбрать подходящий алгоритм соответственно своим наборам данных и задачам.
Определенные параметры находятся путем анализа прошлой литературы. Алгоритм можно выбрать с учетом следующих аспектов в зависимости от наборов данных и задач.
-
1. В статье Чжичао Чжан, Сюгун Сюй, Шуньцин Чжан, Тяньхао Цяо (Шанхайский университет, Шанхай, Китай, 2021) используется частота дискретизации 44,1 кГц и импульс 0,8. Используется размер пакета из 64 сегментов и 300 эпох со скоростью обучения 0,01 [88]. Скорость обучения уменьшается путем деления ее на 10 на каждые 100 эпох. В данной работе рассматриваются следующие параметры.
– Функция масштабирования: эксперименты проводились с использованием двух различных функций масштабирования, softmax и sigmoid. Мы обнаружили, что функция sigmoid обеспечивает лучшую точность, поскольку фокусируется на кадрах с большим весом.
– Применение особого внимания на разных уровнях сверточно-рекуррентной нейронной сети: внимание обращено на разные уровни сверточно-рекуррентной нейронной сети от уровня I 2 до I 10 . Обнаружено, что обращение к слою I 10 дает наибольшую точность.
– Эффект увеличения объема данных: авторы опробовали только сверточнорекуррентную нейронную сеть, сверточно-рекуррентную нейронную сеть с дополнением, сверточно-рекуррентную нейронную сеть с вниманием и сверточно-рекуррентную нейронную сеть с вниманием и дополнением. Установлено, что сверточно-рекуррентная нейронная сеть с вниманием и дополнением дает наилучшие результаты.
-
2. Исследования Фатих Демир, Дабан Абдулла, Абдулкадир Сенгур (Университет Фират, Элязыг, Турция, 2020)
-
3. Исследования доктора Райхана Ахмеда, доктора Товидула Ислама Робина и Ашфака Али Шафина (Стэмфордский университет, Бангладеш, Дакка, Бангладеш, и Международный университет Флориды, Майами, Флорида, США, 2020)
В этой статье используются размер окна Хэмминга 1024, размер перекрытия 256 и 3000 параметров быстрого преобразования Фурье. Изображения спектрограмм изначально имеют размер 875 x 656 x 3, а их размер изменяется до 100 x 100 x 3 для поддержки модели сверточной нейронной сети. Модель сверточной нейронной сети имеет три сверточных слоя, три слоя максимального пула и три полносвязных слоя (Fully Connected – FC). При проведении экспериментов учитываются следующие параметры:
– Размеры полностью связанных слоев: размер полностью связанных слоев варьируется. Размер FC 1 варьируется от 100 до 650, а размер FC 2 – от 50 до 600, увеличиваясь на 50 в каждом эксперименте. Установлено, что FC 1 из 500 и FC 2 из 450 дают наилучшие результаты для обоих наборов данных.
– Влияние размера ввода: берутся разные размеры ввода: 20 x 20, 50 x 50, 100 x 100 и 200 x 200. Входной размер 100 x 100 обеспечивает высочайшую точность для обоих наборов данных.
– Перекрестная проверка: для набора данных UrbanSound8K используются два типа перекрестной проверки: 5-кратная и 10-кратная, причем 10-кратная перекрестная проверка превосходит 5-кратную перекрестную проверку [21].
Особенности логарифмической спектрограммы размером 128 x 128 подаются в сверточную нейронную сеть. Сверточная нейронная сеть состоит из четырех сверточных слоев, четырех слоев максимального пула, двух полностью связанных слоев и функции активации выпрямленного линейного блока, используемой для экспериментов. 5-кратная перекрестная проверка используется для ESC-10 и ESC-50, а 10-кратная перекрестная проверка используется для UrbanSound8K. Учитываются следующие аспекты:
-
– Типы заполнения: рассматриваются два типа заполнения – одинаковые и допустимые. Один и тот же тип заполнения обеспечивает высочайшую точность для всех трех наборов данных.
-
– Оптимизаторы: два типа оптимизаторов – Адам и Исправленный Адам (RAdam) используются для экспериментов, и Адам превосходит Исправленный Адам для всех наборов данных [2].
Заключение
В статье представлены различные алгоритмы моделей машинного обучения, предназначенные для определения шумов городской инфраструктуры. Также в данной статье приведены примеры исследований различных ученых с разных университетов мира и компании, которые – 701 – занимаются исследованиями в области машинного обучения с последующим применением данной технологии в своих будущих проектах.
