Извлечение смысла из текста с использованием глобальной матрицы для лучшего взаимодействия между человеком и машиной

Автор: Аббаси М.М., Бельтюков А.П.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Новые информационные технологии
Статья в выпуске: 4 (84) т.21, 2023 года.
Бесплатный доступ
Взаимодействие между человеком и машиной представляет собой технологическое будущее. Для взаимодействия с машинами используются различные механизмы, такие как голос, сигналы, действия, текст и т.д. Взаимодействие с машинами, использующими текст, является основной темой данного исследования. Текстовый анализ приобрел популярность за последние десятилетия. Он находит применение в различных областях, таких как прогнозирование тенденций фондового рынка, анализ общественного мнения, идентификация групп людей со схожими интересами и т.д. В этом исследовании основное внимание уделяется изучению смысла текста для достижения лучшего взаимодействия человека и машины. Это взаимодействие включает автоматическую идентификацию потребностей или намерений автора текста и соответствующую реакцию машины на намерения автора. Были предложены различные модели и алгоритмы полуавтоматического взаимодействия между человеком и машиной. Распространенные примеры полуавтоматического взаимодействия машинных агентов можно наблюдать в онлайн-системах для обслуживания клиентов банков и телекоммуникационной отрасли. Это исследование направлено на разработку полностью автоматизированной модели с целью извлечения смысла из текста и использования намерений автора для прогнозирования идей последующих текстов.
Глобальная матрица, локальная матрица, матрица ошибок, лемматизация, сегментация, текст, методы и инструменты, мнения
Короткий адрес: https://sciup.org/140306011
IDR: 140306011 | УДК: 004.915 | DOI: 10.18469/ikt.2023.21.4.11
Intent extraction from text by using global feature matrix to improve man machine interaction
Interaction between man and machine is the future of technology. Different mechanisms and mediums are used for this interaction such as voice, signals, pictures, videos, text etc. Text is one of the most popular medium of interaction and has gained popularity over past decades. It is used for making predictions of stock market, analysis of people’s opinion, identification of group of people with similar interests etc. In this research, the focus is to identify and analyze the intent of the written text and used it to preparean appropriate machine response to text. There are several system available that uses semi-automatic mechanisms for interaction with humans such as the online customer care services for banks and the telecommunication industry. Different models and algorithms are used for this semi-automatic interaction. This study works on the design of a fully automated system for extracting the intents from the text, prepare an appropriate response and use the intent to do the prediction of the text. The results of the research are detailed in the methodology and experiment sections of the paper.
Текст научной статьи Извлечение смысла из текста с использованием глобальной матрицы для лучшего взаимодействия между человеком и машиной
Взаимодействие между человеком и машиной представляет собой будущее развития технологий. Человек становится зависимым от машины в выполнении повседневных действий. Ожидается, что в будущем машины будут соответствовать уровню интеллекта человека. Для взаимодействия с машинами используются различные механизмы, такие как голос, сигналы, действия, текст и т.д. Взаимодействие с машинами, использующими текст, является основной темой данного исследования. Анализ текста ‒ это часть обработки естественного языка, которая включает модели и механизмы, используемые для идентификации и извлечения из него важной информации. Анализ текста и его классификация находят применение в различных областях. Читатель часто оказывается сбитым с толку, особенно в случаях с коммерческими организациями, когда те пытаются определить намерения своих клиентов по электронной почте или посредством обратной связи. Это стать еще более затруднительным, если с клиентом взаимодействует машина.
Извлечение смысла из текста ‒ это механизм для определения взглядов клиента. Это тип извлечения информации, который включает в себя идентификацию ограниченной части текста и сохранение ее в структурированной форме. Структурирование информации в семантической форме облегчает процесс ее дальнейшего вывода компьютерной программой. В этой работе извлечение смысла было выполнено на основе текста, используемого для взаимодействия между человеком и машинным агентом. Тема взаимодействия касалась онлайн-по-купок. Машинный алгоритм был сконструирован для извлечения смысла из текста, написанного человеком, путем проведения анализа предложений из текста по отдельности.
Типичное предложение состоит из информации, которая включает в себя намерение и контекст. Намерение ‒ это цель или то, что человек хочет сделать.
Контекст ‒ это остальные элементы, связанные с намерением. Человеку легче понять смысл текста, но для машин это довольно сложная задача, поскольку машины воспринимают предложение как последовательность слов. Для этого требуется, чтобы машина научилась понимать слова в предложениях и определять смысл текста. Это полезно для улучшения механизма веб-поиска и контроля автоматической обработки сообщений машинами. Текстовое сообщение обычно состоит из длинных предложений с обычным и нетрадиционным речевым содержанием.
Во время взаимодействия люди ведут себя по-разному. Некоторым требуется подробная информация, в то время как для других достаточно просто основной информации по теме. Очень распространенным методом является подготовка отдельного словаря, в котором фиксируются намерения человека, и увеличение объема данных. Увеличение объема данных ‒ это процесс искусственного генерирования новых данных из уже имеющейся информации. Цель состоит в увеличении количества данных для обучения алгоритмической программы. В таких приложениях, как классификация изображений и обработка сигналов, увеличение объема данных удовлетворяет потребность в большом количестве данных. В рамках разработанной методологии была создана глобальная матрица признаков, которая послужила словарем для обучения программы.
Научные труды, связанные с данной работой
История анализа намерений на основе текста восходит к началу 60-х годов. В 1963 году Ф. Мо-стеллер и Д. Уоллес изучали проблему авторства в тексте. Они заметили, что лингвистические особенности текста предоставляют информацию об авторе текста. Стиль текста помогает определить намерения автора текста [1]. В 1989 году Г. Альтман и Х. Швиббе проанализировали текст и заметили разницу между количеством слов при формулировании вопросов и ответов. Они предположили, что разница в семантике вопросов и ответов является причиной разницы в количестве слов [2]. В 1997 году С. Хохрайтер и Ш. Юрген использовали методы глубокого обучения и долговременную и кратковременную память для анализа текста на уровне предложений с целью распознавания сущностей и моделирования языка [3].
В 2005 году И. Грейвс и Ш. Юрген проанализировали смысл текста с использованием прямой и обратной модели LSTM (Long short-term memory). Они заметили, что обратная модель LSTM генерирует правильный контекст после добавления в текст не- которой важной параметрической информации [4]. Позже, в 2008 году, Сяо Ли и соавторы использовали методы, основанные на графах, чтобы узнать намерения пользователя из текстового документа [5].
В 2010 году Р. Рехурек и П. Сойка проанализировали намерение в трех различных корпусах текста, которые включают вопросы, ответы и их совокупность. Они отфильтровывали слова с частотой повтора менее 5. Аналогичным образом из текста были отфильтрованы ненужные цифры, знаки препинания и другие символы, чтобы уменьшить его объем перед проведением анализа намерений [6]. В 2011 году Р. Коллоберт и соавторы использовали нейронную сеть для встраивания последовательности слов со слоем СRF в верхней части сети [7].
Позже, в 2012 году, Ч.К. Джеки и Сяо Ли проанализировали намерение из текста, используя методы кластеризации. Они автоматически обнаружили шаблоны намерения в тексте [8]. В 2013 году для идентификации намерений в тексте пользователей приложения был применен семантический разбор [9]. В 2014 году В. Гупта и соавторы классифицировали текстовое сообщение на такие классы, как намерение совершить покупку и классы намерений, не связанных с покупкой текста [10]. В 2015 году Ц. Ванг и др. изучили намерения пользователей по тексту Twitter. Они использовали полууправляемый подход для категоризации твитов пользователей [11]. В том же году Ф. Кути и др. проанализировали реакцию людей на похожие вопросы. Они наблюдали за чрезмерной нагрузкой вопросов на поведение пользователей, рассчитали время ответа и спрогнозировали характеристики их поведения [12]. В 2016 году Х. Хашеми и др. создал систему обнаружения намерений с использованием метода глубоких нейронных сетей [13]. Позже, в 2016 году, Д.Д. Кастро и др. проанализировали четыре распространенные реакции клиента во время взаимодействия, такие как чтение, ответ, удаление без прочтения и просто удаление сообщения [14].
В том же году П. Рамарао и др. разработали поисковую систему для идентификации электронной почты и содержания текста в ней [15]. Следуя той же области исследований, М. Саппелли и др. определил неполную категорию для извлечения намерений из текста, относящуюся к обмену информацией, составлению расписания, планированию и социальной коммуникации [16]. В 2017 году Л. Янг и др. представили модель извлечения намерений из документов в корпорации. Они прогнозировали поведение пользователя при получении текста и его интенсивность [17]. М.М. Аббаси и др. проанализированы логические характеристики текста, выявлена роль эмоций для определения полярности текстового документа и предложены различные методы анализа текста и его обобщения [18-27]. В 2018 году С. Нисиои и др. проанализировали содержание словаря, используемого заказчиком в среде планирования ресурсов предприятия (ERP). Он предоставляет модель для очистки и извлечения соответствующего намерения из текста [28].
В 2021 году Альджуайд Х. и др. применили методы анализа настроений для выявления важных цитат в статье. Они предложили механизм цитирования статей в хронологическом порядке, основанный на их важности и релевантности документу [29]. В 2022 году С. Сурана и др. использовали технологии машинного обучения в документе для идентификации изображений в нем и извлечения текста, который отражает намерение представить эти изображения в документе [30]. В 2023 году Ихсан И. и др. использовал метод опорных векторов для понимания и извлечения причин цитирования исследовательских статей в разделе литературы новой статьи и для классификации цитат в различных группах на основе их ранга [31].
Методология
Анализ начинается с определения основных компонентов и особенностей текста. Компьютерная программа, созданная в ходе этой работы, использует метод обучения под наблюдением, чтобы извлечь смысл, который автор вложил в текст, сгенерировать признаки намерения и затем классифицировать их под разными названиями. Методы обучения под наблюдением требуют некоторых предварительных знаний о содержании текста для первоначального обучения программе.
Hапример, если текст посвящен онлайн-по-купкам, то основными темами, представляющими интерес для взаимодействия клиентов с машиной, могут быть их заказы, жалобы, платежи и другая информация о продуктах. Знание слов, часто используемых для демонстрации конкретного смысла текста автора, является предварительным условием для разработки алгоритма, способного автоматически извлекать этот смысл и классифицировать текст на основе его извлечения.
Наш контролируемый алгоритм обучения (supervised learning algorithm) начинается с набора данных D = {(Xi,yi),............,(Хп,Уп)} , где каж дый хі является «входным вектором особенности», а уі ‒ соответствующей «выходным вектором категории». Мы предположили, что эти точки данных взяты из некоторого неизвестного распределения Р, поэтому(xi,yi)~ Р, где мы имеем (xi,yi) независимыми и одинаково распределенными. Формально мы можем заключить, чтo:
D = {( Х1,У1 ),............, ( Хп,Уп )}^ Rd X C , где n ‒ размер нашего набора данных, Rd представляет d-мерное пространство особенности, xi представляет вектор объектов itһ примера, yi представляет категорию или выходные данные itһ примера, а C ‒ это пространство всех возможных меток или категория пространства.
Нашу цель контролируемого машинного обучения можно резюмировать как нахождение функции h : Rd ^ C , такой, чтобы для каждой новой пары ввода/вывода ( х,у ) , выбранной из P , мы имели h ( x > у .
Чтобы проверить эффективность предложенной нами модели извлечения смысла из текста с использованием глобальной матрицы, мы использовали алгоритм контролируемого обучения под названием «матрица ошибок», результаты которого подробно описаны в разделе «Результаты и обсуждение» этой статьи. Четырьмя основными компонентами для обработки матрицы ошибок являются ТР (Истинно положительный результат), FN (Ложно отрицательный результат), FP (Ложно положительный результат) и ТΝ (Истинно отрицательный результат).
Среди них два компонента, ТР (Истинно положительный) и ТΝ (Истинно отрицательный), разъясняют, что значения истинности и что результаты классификации, полученные с помощью нашей модели, релевантными или правильными, тогда как FN (Ложно отрицательный) и FP (Ложно положительный) детализируют ошибки или неправильную классификацию, допущенные матрицей ошибок при классификации текста. Эти четыре компонента используются для расчета показателя эффективности и классификационной способности алгоритма. Этими показателями эффективности являются Точность измерений (Accuracy), Отзыв (Recall), Точность результата измерений (Precision) и F- Mеру (F-Measure).
Эксперимент
Для эксперимента был выбран текст на тему онлайн-покупок. Были загружены текстовые документы из разных онлайн-блогов, таких как: «», «покупки%20в%20интернете/hot», «», «», « /blog/» и т.д..
На таблице 1 ниже представлена глобальная матрица особенности характеристик текста об он-лайн-покупках. Она содержит наиболее часто используемые слова для онлайн-покупок вместе с их синонимами.
Таблица 1. Глобальная матрица особенности он-лайн-покупок
Глобальная матрица особенности для онлайн-покупок
|
Особенность (Features) |
Синоним слова |
Категория |
|
Желаю Быстро Качество |
сЛ О Ъ Оч Й 2 £ g ей сЛ р 2 |
W я р W |
|
Карта Ошибка Сделки Успешным Неудачной |
Платеж |
|
|
Пожалуйста Любезно Предоставьте |
Информация |
|
|
Опаздываю Не работаю Плохо |
Жалоба |
Вектор особенности (feature vector) на рисунке выше представляет список слов, используемых покупателями во время онлайн-покупок. Вектор особенности (feature vector) включает краткий список слов, обычно используемых для представления конкретных намерений клиента в письменном тексте об онлайн-покупках. Глобальный словарь содержит синонимы слов из вектора особенности (feature vector). Эти синонимы были извлечены из онлайн-базы данных « » и « ruthes/» использование АРІ’ѕ.
Затем программа была обучена извлекать и классифицировать слова из письменного текста по назна- ченным классам или категориям, с использованием содержимого глобальной матрицы особенности.
На этапе тестирования текст был предварительно обработан перед определением его смысла. Предварительная обработка включает в себя удаление из него знаков препинания и стоп-слов. Затем предварительно обработанный текст был сегментирован на последовательности предложений, и каждое предложение было дополнительно разделено на слова с применением алгоритма максимального объединения (Мах Рооӏіng).
Выделенные слова были лемматизированы. Лемматизация ‒ это процесс преобразования слов в их корневую или начальную форму. Обученная программа создала новую локальную матрицу признаков, которая содержит список предложений, список слов в каждом предложении и частоту встречаемости слов векторов признаков в тексте. Каждый раз, когда алгоритм обучает следующий текст, матрица локальных особенностей обновляется. Программа сравнивает содержимое матрицы локальных признаков с глобальными.
Результаты и обсуждение
Как объяснялось ранее, для эксперимента по извлечению смысла текста были выбраны тексты из разных блогов об онлайн-покупках. Цель тестирования разных текстов разными пользователями - определить производительность и точность предложенного алгоритма на разных текстах. Возможность классификации и точность алгоритма для пяти различных текстов об онлайн-покупках представлены ниже в таблице 2.
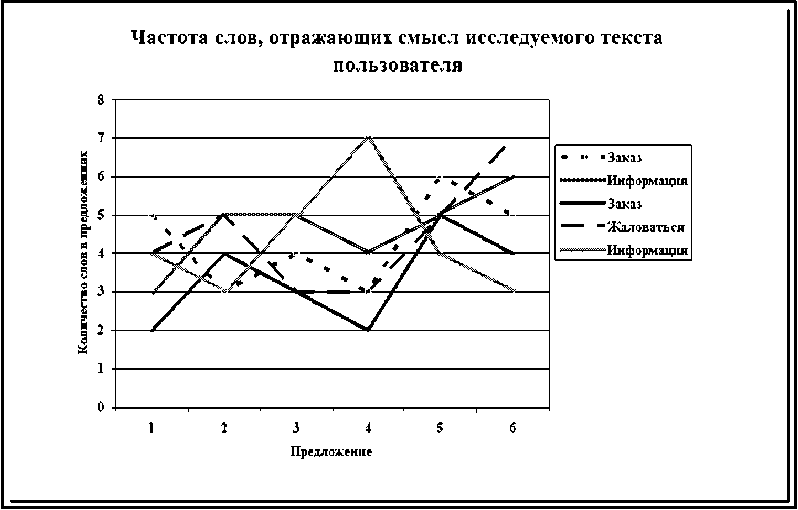
Рисунок 1. Частота слов, отражающих смысл исследуемого текста пользователя
Где «Кол. пред.» представляет количество предложений в тексте, «Кат.» представляет классификацию, «Т» представляет точность измерений (Accuracy), «R» представляет отзыв (Recall), «Р» представляет точность результата измерений (Precision) и «F-Mep» представляет F- Mepy (F-Measure).
Таблица 2. Анализ результатов с использованием матрицы ошибок
|
Кол. пред. |
Кат. |
T |
R |
P |
F-Mep |
|
85 |
Заказ |
85% |
75% |
71% |
80% |
|
50 |
Информация |
81% |
68% |
72% |
69% |
|
110 |
Заказ |
70% |
77% |
69% |
72% |
|
52 |
Жаловаться |
75% |
81% |
77% |
69% |
|
120 |
Информация |
71% |
65% |
74% |
71% |
Для дальнейшего анализа и определения производительности машинной программы рассчитывается матрица ошибок и ее параметры, их результаты представлены в таблице 2 с использованием таких характеристик матрицы ошибок, как точность, прецизионность, отзыв и F-мepa. Эти особенности матрицы ошибок отражают высокий процент истинной классификации намерений пользователей в тексте машинным алгоритмом. Машинный алгоритм хорошо работает при классификации намерений пользователя по различным классам глобальной матрицы особенностей. Частота употребления слов, отражающих намерения клиента, в различных предложениях текста представлена на рисунке 1 ниже.
На рисунке 1 выше показано извлечение намерений и их классификация во время анализа предложений программой. Некоторые предложения содержат больше слов, которые представляют намерения пользователя, другие предложения - меньше. Например, для классификации текста в категории «Жаловаться», представленной на графике желтым цветом, первые три предложения содержат больше намерений пользователя, затем в последующих предложениях наблюдается их небольшое уменьшение, а потом к концу текста намерение в предложениях снова возрастает. На приведенном выше графике прослеживается механизм классификации намерений пользователя в тексте с помощью машины.
Заключение
В статье представлена модель улучшеннного взаимодействия между человеком и машиной. Модели, ранее предложенные исследователями, в основном, касаются извлечения смысла из электронных писем или из статического текста. Алгоритм, представленный в этом исследовании, работает с динамическим текстом, и по мере роста текста способность алгоритма к классификации совершенствуется. Модель обеспечивает основу для перевода машины из полуавтоматического в полностью автоматизированный режим с использованием методологии контролируемого обучения. Результаты эксперимента демонстрируют высокую точность извлечения намерений и их отнесения к соответствующему классу. Результаты матрицы локальных особенностей можно наблюдать во время каждой итерации алгоритма над предложением. В будущем программа будет протестирована на разнородных типах текста, и акцент будет смещен с контролируемых механизмов обучения на неконтролируемые.
Список литературы Извлечение смысла из текста с использованием глобальной матрицы для лучшего взаимодействия между человеком и машиной
- Mosteller F., Wallace L.D. Inference in an authorship problem // Journal of the American Statistical Association. 1963. Vol. 58, no. 302. P. 275-309.
- Altmann G., Schwibbe H. Das Menzerathsche Gesetz in Informations verarbeitenden Systemen. Hildesheim: Georg Olms Verlag, 1989. 132 p.
- Hochreiter S., Jrgen S. Long short term memory // Neural Computation. 1997. Vol. 9, no. 8. P. 1735-1780.
- Graves I., Jrgen S. Frame wise phoneme classification with bidirectional LSTM and other neural network architectures // Neural Networks. 2005. Vol. 18, no. 5. P. 602-610.
- Li X., Ye-Yi W., Alex A. Learning query intent from regularized click graphs // Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2008. P. 339-346.
