Электронный корпус татарского языка на базе модели лингвистических графов знаний

Автор: Гатиатуллин А.Р., Мухамедшин Д.Р., Прокопьев Н.А., Сулейманов Д.Ш.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Прикладные онтологии проектирования
Статья в выпуске: 4 (54) т.14, 2024 года.
Бесплатный доступ
В статье представлена новая версия электронного корпуса татарского языка, модернизированная на основе модели лингвистического графа знаний тюркских языков. Новая версия корпуса позволяет описать информацию на разных лингвистических уровнях: морфонологическом, синтаксическом и семантическом благодаря представлению лингвистической информации в виде графов знаний. Такой способ представления повышает функциональные возможности работы с корпусом, позволяет производить поиск по запросам, содержащим синтаксическую и семантическую информацию. Особенность реализации электронного корпуса заключается в том, что использованная модель в наибольшей степени соответствует структурно-функциональным особенностям тюркских языков и используется в качестве основы для создания ряда программных продуктов, связанных с семантической обработкой текста на тюркских языках. В частности, к таким продуктам относятся лингвистический портал «Тюркская морфема» и новая версия электронного корпуса татарского языка «Туган тел».
Электронный корпус, граф знаний, система управления базами данных, лингвистическая единица, тюркские языки
Короткий адрес: https://sciup.org/170207431
IDR: 170207431 | УДК: 004.822 | DOI: 10.18287/2223-9537-2024-14-4-542-554
Electronic corpus of the Tatar language based on the model of linguistic knowledge graphs
The article presents a new version of the electronic corpus of the Tatar language, updated based on a linguistic knowledge graph model for Turkic languages. This new version of the corpus allows for information description across multiple linguistic levels: morphonological, syntactic, and semantic, through the use of knowledge graphs to represent linguistic data. This approach enhances corpus functionality, enabling searches that incorporate syntactic and semantic information. A distinctive feature of the electronic corpus implementation is that the model employed aligns closely with the structural and functional characteristics of Turkic languages and serves as a foundation for developing various software products for semantic text processing in Turkic languages. In particular, these products include the linguistic portal "Turkic Morphme" and the new version of the Tatar language electronic corpus, "Tugan Tel.".
Текст научной статьи Электронный корпус татарского языка на базе модели лингвистических графов знаний
Современные технологии искусственного интеллекта, основанные на использовании больших языковых моделей, испытывают потребность в увеличении их информационных ресурсов за счёт включения различных электронных корпусов (ЭК). Это стало фактором усиления активности разработок ЭК для тюркских языков (ТЯ) [1-4]. В таблице 1 приведён список ЭК, проанализированных в ходе модернизации ЭК татарского языка «Туган тел». ЭК двух ТЯ включены в состав лингвистической платформы Национальный корпус русского языка : башкирский национальный корпус объёмом 550 тыс. словоупотреблений и хакасский ЭК объёмом 1194 тыс. словоупотреблений. Большой набор ЭК собран на лингвистической платформе Sketch Engine, в числе которых есть тюркские ЭК (см. таблицу 2). Наибольшее количество ЭК разработано для турецкого языка, которые имеют синтаксическую или семантическую разметки: (турецкий TreeBank) и (турецкий PropBank). Для турецкого языка создан лингвистический ресурс WordNet, с помощью которого можно организовать семантический поиск. Ресурсы для турецкого языка имеют только один вид разметки - синтаксический или семантический. В турецком PropBank реализована ситуационная разметка, а в WordNet – таксономическая. Для остальных ТЯ корпусы включают только морфологическую разметку.
Таблица 1 – Электронные корпусы тюркских языков
Название Адрес Башкирский поэтический корпус Корпус башкирского языка. Проза http://212.193.132.98/bashkorp/bashkorp Устный корпус башкирского языка Алматинский корпус казахского языка Национальный корпус казахского языка http://194.146.43.249/indexru/ Национальный корпус казахского языка Крымскотатарский электронный корпус Электронный корпус тувинского языка Национальный корпус турецкого языка Корпус турецкого языка Spoken Turkish Corpus Корпус узбекского языка Электронный корпус хакасского языка Корпус шорского языка Корпус якутского языка Татарский национальный корпус «Туган тел» Письменный корпус татарского языка. Корпус татарской художественной литературы
Таблица 2 – Электронные корпусы тюркских языков на платформе Sketch Engine
Название Адрес Uzbek corpus from the web Kazakh text corpora Tatar Mixed Corpus from the web Azerbaijani text corpora Kyrgyz text corpora
В ЭК, размещаемых на платформе Национального корпуса русского языка, реализована возможность просмотра справочной грамматической информации о языковых единицах. Например, предыдущая версия ЭК «Туган тел» [5] включала только морфологическую разметку.
Проведённый анализ показал, что многие разработчики ЭК для ТЯ используют программный инструментарий и модели, реализованные для индоевропейского семейства языков, которые отличаются по своей структуре от ТЯ, обладающих богатой морфологией [6], а информация, представляемая в таких корпусах, не отображает всё богатство и полноту структурно-функциональных особенностей ТЯ.
Наиболее полное описание знаний и эффективное управление ими с использованием релевантных алгоритмов обработки с учётом специфики языка является важной и актуальной задачей при разработке лингвистических баз данных. Практика использования в портале «Тюркская морфема» представления данных в виде графа знаний (ГЗ) [7-9] способствует решению указанных задач, позволяя описывать в корпусе языка как онтологические, так и фактографические знания о мире.
Под ГЗ подразумевается разновидность семантической сети, определяемая в работе [10] как структурированный набор данных, собранный из разнородных источников, совместимый с моделью данных RDF и имеющий OWL- онтологию в качестве своей структуры.
Разновидностью ГЗ для представления лингвистической информации являются лингвистические ГЗ. Их отличительное свойство в том, что они описывают наряду с картиной мира также и средства для описания этого мира в виде лингвистических единиц и структур естественных языков. Исследованные в [6] лексические и грамматические особенности ТЯ [5] позволили построить модель ГЗ ТЯ, названную TurkLang [11]. Данная модель использовалась при создании новой версии ЭК «Туган тел».
1 Реализация архитектуры модели лингвистического ГЗ ТЯ TurkLang в ЭК
В проекте создания лингвистического портала «Тюркская морфема» [12] предложена модель лингвистического ГЗ ТЯ TurkLang , которая подходит для описания потенциальных возможностей языка и фактических данных, представленных в ЭК с текстами на ТЯ. Минимальной лингвистической единицей, представленной в этой модели, являются морфемы: корневая, аффиксальная и аналитическая. Это позволяет текст каждого предложения в корпусе представлять в виде последовательности морфем. Представление словоформы в виде фрагмента ГЗ согласно данной модели показано на рисунке 1. В узлах представлена информация о типе узла, а в скобках - содержимое конкретного узла. Узлы и рёбра фрагмента ГЗ можно условно отнести к трём уровням S1, S2, S3.
Уровень S1 – поверхностный уровень, который содержит узлы графа с информацией из реальной словоформы, использованной в тексте татарского языка.
Уровень S2 – морфемный уровень, содержит узлы ГЗ с информацией об аффиксальных морфемах татарского языка. Информация уровня S2 едина для отдельного ТЯ и узлы уровня S1 ссылаются на узлы из уровня S2.
Уровень S3 – категориальный уровень, в котором представлены узлы ГЗ, общие для всех ТЯ. Это обозначения граммем, тэгов и грамматических категорий.
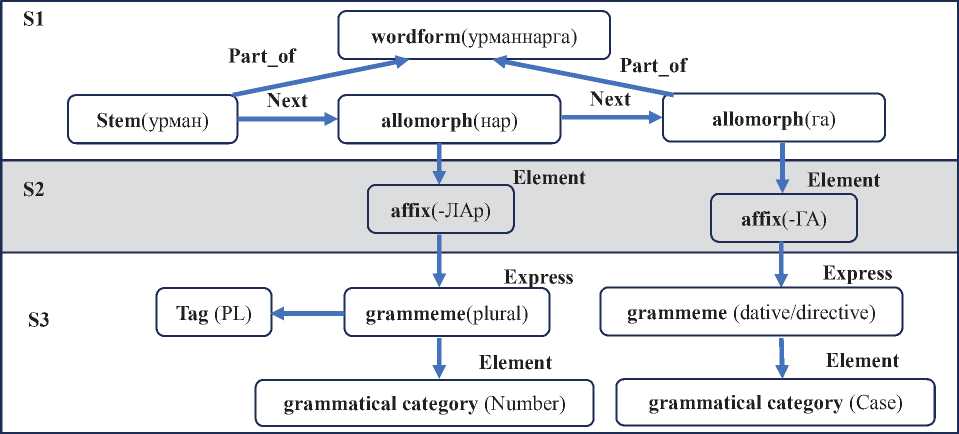
Рисунок 1 – Фрагмент графа знаний представления словоформы
Информация, представленная на уровнях S2 и S3 фрагмента ГЗ извлекается из базы знаний (БЗ) портала «Тюркская морфема», в котором специалистами по ТЯ описаны потенциальные возможности и свойства ТЯ. Такой подход позволяет использовать единую систему обозначений и обеспечить полную совместимость лингвистических ресурсов портала «Тюркская морфема» и ЭК «Туган тел». Фрагменты ГЗ с библиотеками грамматических категорий идентичны в портале и в корпусе, поэтому можно извлекать эту информацию из БЗ портала «Тюркская морфема». С целью увеличения скорости обработки поисковых запросов фрагменты ГЗ дублируются и для поддержания актуальной информации в обоих программных продуктах периодически синхронизируются.
На рисунке 1 представлен фрагмент ГЗ ЭК «Туган тел», описывающий структуру осуществления поиска в корпусе по грамматическим категориям, представленным на рисунке 2. На этом рисунке представлены все граммемы татарского языка, которые сгруппированы в грамматические категории и образуют уровень S3 ГЗ, представленного на рисунке 1.
Ещё один тип лингвистических единиц, который представлен в ГЗ ЭК «Туган тел» – это аналитические формы (analytic form). Аналитические формы – это формы слова с самостоя- тельным значением в сочетании со служебными словами. Пример фрагмента ГЗ, описывающего структуру аналитической формы, представлен на рисунке 3. Аналитическими морфемами в ТЯ являются такие части речи, как послелоги, частицы или вспомогательные глаголы. Аналитические морфемы в тексте так же, как и аффиксальные морфемы, выражают грамматическую роль, что в графе определяется связью типа Express с узлами типа граммемы.
|
Части речи и аффиксы |
X |
||||
|
Части речи |
Падежи |
Залог |
Формы императива |
||
|
0 Именительный |
0 Действительный (основной) |
0 Императив 1 л. (гортатив) ед. ч. |
|||
|
Q Существительное |
|||||
|
□ Прилагательное |
□ Родительный (генитив) |
□ Страдательный (пассив) |
О Императив 1 л. (гортатив) мн. ч. |
||
|
0 Глагол |
0 Направительный (директив) |
0 Возвратный (рефлексив) |
0 Императив 2 л. ед. ч. |
||
|
Q Наречие |
Q Направительный с огранич. знач. |
Q Понудительный (каузатив) |
0 Императив 2 л. мн. ч. |
||
|
□ Числительное |
□ Винительный (аккузатив) |
□ Взаимно-совместный (реципрок) |
0 Императив 3 л. (юссив) ед. ч. |
||
|
0 Местоимение Q Союз |
0 Исходный (аблатив) Q Местно-временной (локатив) |
Формы поссесива |
0 Императив 3 л. (юссив) мн. ч. 0 Просит, имп. (прекатив) на-чы |
||
|
□ Послелог □ Междометие Q Модальное слово |
Число |
□ 1 л., ед. ч. 01л, мн. ч. |
0 Просит, имп. (прекатив) на -сана |
||
|
О Единственное |
□ 2 л.. ед. ч. |
Разряды числительных |
|||
|
□ Звукоподражательное слово |
□ Множественное |
Q 2. л., мн. ч. |
0 Собирательное |
||
|
Время |
Лицо |
О 3 л, ед. ч. |
0 Порядковое Q Разделительное 0 Приблизительного смета |
||
|
□ 1л,ед.ц. 0 1 л., мн. ч. |
Деепричастия |
|||
|
□ 2л,ед. ч. |
О Сопутствующего действия |
Общий вопрос |
|||
|
0 Буд. категоричн. |
0 2 л.. мн. ч. |
0 Сопутствующего действия (Отриц.) |
0 Вопросит., неопред. |
||
|
□ Буд. неопред. |
□ Зл,ед.ч. |
0 Деепричастие на -гач |
0 Вопросит, формана -мыни |
||
|
0 Отриц. форма б уд. неопред. |
Q 3 л., мн. ч. |
О Деепричастие на -таимы |
О Вероятк., предположит. |
||
|
Элементы словообразования |
Причастия |
Модальные формы глаг. |
Q Уподобление 1 0 Уподобление 2 |
||
|
— |
|||||
|
0 Уменьшит, форма |
О Настоящего времени |
0 Условная модальность (кондиционалис) |
0 Уподобление 3 |
||
|
Q Ласкат. форма □ Лицо деятеля по роду занятий |
0 Прошедшего времени □ Будущего времени |
0 Необходимость О Возможность |
Атрибутивные формы |
||
|
□ Абстрактное сущ. |
0 Регулярно совершаемого действия |
0 Намерение |
0 Атрибутив на-лы (мунитатив) |
||
|
□ Мера □ Распределение |
Инфинитивы |
0 Предостережение |
0 Атрибутив на -сыз (Абессив) О Локативный аттри бути в 0 Генитивный аттрибутив |
||
|
О Инфинитив на -ырга 0 Инфинитив на -мак |
Способы глаг. действия |
||||
|
Имена действия |
0 на-тала |
||||
|
□ Имя действия на -у Q Имя действия на -ш (-ыш, -еш) |
Аспект глагола |
0 Раритив на-ыштыр |
Сравнит, степень |
||
|
0 Сравнит, степень |
|||||
|
□ Отрицание |
|||||
|
Рисунок 2 |
– Интерфейс для поиска в корпусе «Туган тел» по грамматическим категориям |
||||
В разных ТЯ одни и те же морфемы, выражающие одно и то же значение, могут являться как аффиксальными, так и аналитическими морфемами. Например, в татарском языке роль инструмента в тексте выражается с помощью аналитической морфемы белән ‘с’ - чүкеч белән ‘с молотком’, в казахском она выражается с помощью аффиксальных алломорфов -бен/-мен/-пен – балғамен ‘с молотком’, а в турецком с помощью аффиксальных алломорфов -la/-le – çekiçle ‘с молотком’. Данная особенность написания связана с различием в правилах грамматики разных ТЯ, что выражается различием в связях между узлами ГЗ, представляющих аффиксальные и аналитические алломорфы.
Графовая структура БЗ ЭК «Туган тел» позволяет хранить в БЗ семантическую, синтаксическую и морфологическую информацию, а также осуществлять семантические поисковые запросы. Для этого в БЗ ЭК хранятся подграфы с двумя видами семантических универсалий.
Первый вид – это подграф знаний с ситуационными фреймами, который является объединением ресурсов FrameNet и FrameBank [13]. Frame-Net разработан для английского языка и не учитывает морфологию лингвистических единиц, с помощью которых выражаются значения семантических универсалиев, но в нём содержится наиболее полная база типовых ситуаций. FrameBank создан для русского языка с формализацией грамматических структур, используемых для описания ролей в ситуационных фреймах с учётом морфологии. Поскольку ТЯ – это языки с богатой морфологией, в них необхо- димо учитывать морфологическую информацию. Новая структура БЗ использует полноту базы FrameNet и морфологические элементы FrameBank.
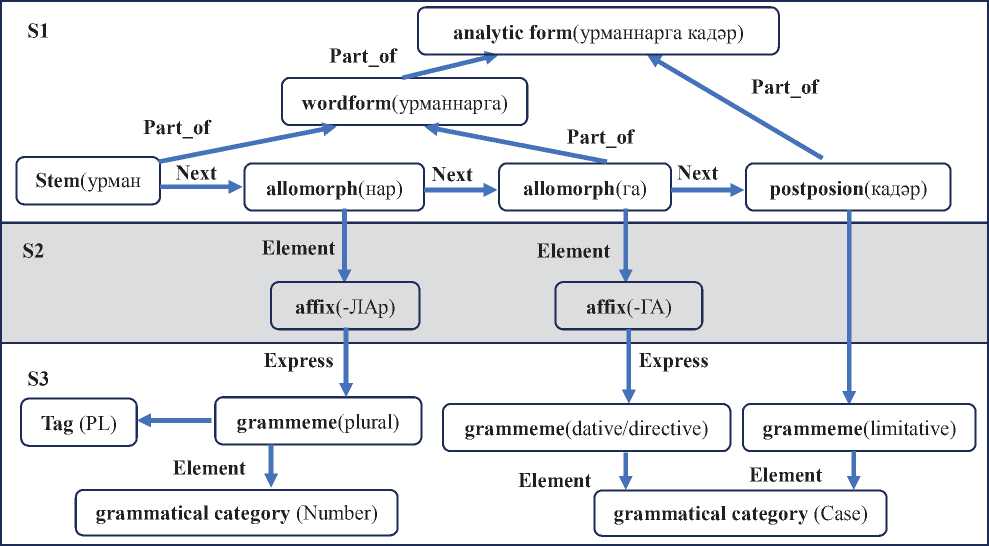
Рисунок 3 - Фрагмент графа знаний представления аналитической формы
Второй вид подграфа семантических универсалий - это таксономический подграф, реализованный в виде тезауруса типа WordNet . Фрагмент лингвистического ГЗ портала «Тюркская морфема» является точной копией ГЗ типа WordNet . Таксономическая часть графа для ТЯ представлена с помощью узлов графа концепт ( concept ), связываемых с помощью направленных рёбер. На рисунке 4 представлен фрагмент ГЗ с описанием таксономической информации, где область U ГЗ содержит семантические универсалии, которые представляют собой множество концептов и таксономические отношения между ними.
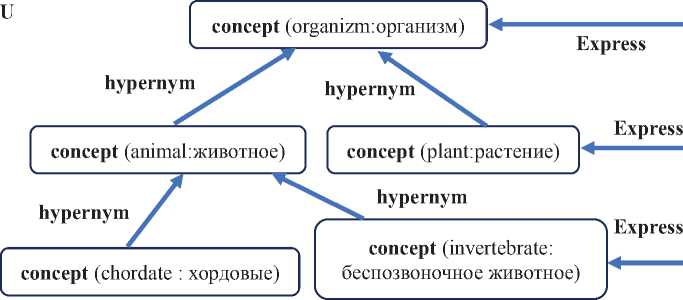

lexeme (умырткасыз хайван )
Рисунок 4 - Фрагмент графа знаний с таксономической структурой
Семантические универсалии, представленные в данной части ГЗ, в совокупности образуют семантический тезаурус. В области L1 представлены примеры лексем, которые встречаются в текстах ЭК языка ( в данном примере это татарский язык). Таким образом, все лексемы ‘ Yсемлек’ ( ‘рус.: растение’) , которые встречаются в корпусе, имеют связь типа
Express с концептом ‘plant:растение’. Все лексемы, которые обозначают разные виды растений, имеют связь с концептами тезауруса, которые в тезаурусе находятся с концептом ‘plant:растение’ в цепочке отношений гипонимии. Такая структура ГЗ ЭК позволяет производить семантический поиск.
Система управления корпусными данными работает с ЭК текстов на татарском языке и позволяет подключать лингвистические корпусы на других агглютинативных и флективных языках (к языкам агглютинативного типа относятся ТЯ, а к языкам флективного типа – славянские языки). Поисковые технологии реализованы на базе общедоступных программных средств: реляционной системы управления базой данных (СУБД) MariaDB и хранилища данных Redis . Для реализации предлагаемой структуры БЗ используется графовая СУБД Memgraph .
2 Реализация структуры БЗ ЭК «Туган тел» с помощью СУБД Memgraph
Первичной задачей в процессе реализации БЗ ЭК «Туган Тел» является перенос сущест- вующего ЭК в структуру ГЗ. На рисунке 5 показана итоговая схема графа, реализованная с помощью СУБД Memgraph, достаточная для переноса существующего ЭК в структуру БЗ.
В отличие от схемы, реализованной с помощью СУБД MariaDB , в графе дополнительно появляются узлы типов «Clause» («Клауза»), «Syntax-eme» («Синтаксема»), «Punctua-tionMark» («Знак препинания»), «Morpheme» («Морфема»), «PartOfSpeech» («Часть речи»), необходимых для дальнейшего представления словоформ, клауз и синтаксем. Также в графе появляются узлы «Lan-guage» («Язык»), «Person» («Человек»), «Source» («Источник»), «DocumentName» («Название документа»), «Place» («Место»), «Building» («Здание»), необходимые для дальнейшего представления
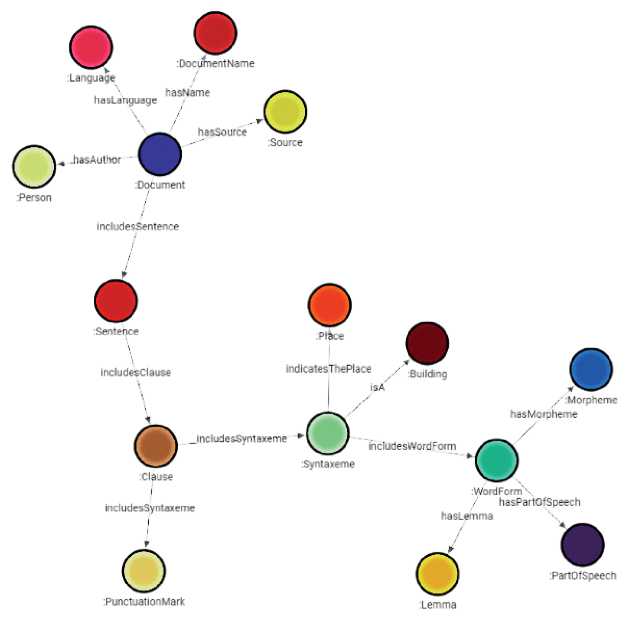
Рисунок 5 – Схема графа, реализованного с помощью СУБД Memgraph
семантических связей с соответствующими объектами. Количество типов таких узлов неограниченно, и их набор может быть расширен без внесения изменений в основной ГЗ.
В качестве примера в представленную структуру можно поместить предложение: «Дөрес, әле Казанда моңа кадәр картлар йорты юк иде» («И вправду, до сих пор в Казани не было дома престарелых») с морфологической разметкой, извлечённой из существующего ЭК. Для узлов типа «Sentence» предусмотрено два свойства, в которых хранятся данные о предложении в целом: «name» (предложение без морфологической разметки), «full» (предложение с морфологической разметкой). Добавление предложения осуществляется при помощи запроса на языке Cypher :
CREATE (s:Sentence {name: "Дерес, але Казанда моца кадар картлар йорты юк иде.”, full: "Дерес (И вправду) дөрес+Adj; Type2 әле (ещё) әле+CNJ;әле+PART; Казанда (в Казани) казан+N+Sg+LOC(ДА); казан+PROP+LOC(ДА); моңа (этого) моңа+PN; кадәр (до) кадәр+Adv; кадәр+POST; картлар (старики) карт+Adj+PL(ЛАр)+Nom;карт+N+PL(ЛАр)+Nom; йорты (дом) йорт+N+Sg+POSS_3SG(СЫ)+Nom; юк юк+MOD; иде и+V+PST_DEF(ДЫ); . Type1”});
Далее необходимо добавить узел типа «Document». Для таких узлов предусмотрено использование трёх свойств, в которых хранятся данные о документе: «name» (наименование файла документа), «length» (длина документа в словах), «publicationDate» (дата публикации). Представление метаданных о длине документа и дате публикации в виде свойств узла обусловлено необходимостью реализации поиска по интервалам длин документов и интервалам дат. Добавление узла документа при помощи запроса на языке Cypher имеет вид: CREATE (d:Document {name: “1_17890_1_1.txt”, length: 445, publicationDate: date(“2010-07-08”)});
Для добавления узлов и связей, связанных с другими метаданными документа, необходимо добавить узлы соответствующих типов («Language», «DocumentName», «Source», «Person») и рёбра между узлом документа и добавленными узлами соответствующих типов («hasLanguage», «hasName», «hasSource», «hasAuthor»). Сделать это можно одним запросом на языке Cypher :
MERGE (d)-[:hasLanguage]->(l:Language {name: “Tatar”})
MERGE (d)-[:hasName]->(n:DocumentName {name: "Казанда да картлар йорты ачылачак”}) («В Казани откроется дом престарелых»)
MERGE (d)-[:hasSource]->(s:Source {name: “”})
MERGE (d)-[:hasAuthor]->(p:Person {name: “Наил Алан”});
Чтобы указать, что созданный документ включает предложение, необходимо добавить ребро между узлом документа и узлом предложения типа «includesSentence». При этом у такого ребра есть дополнительные свойства «position» (порядковый номер предложения в документе) и «startPosition» (порядковый номер первого слова предложения в документе). Так как в добавляемом примере только одно предложение, оба свойства примут значение «1». Если предложений несколько, то указанные свойства в дальнейшем помогут построить контекст вокруг предложения и найти это предложение в нужном документе. Запрос на языке Cypher для добавления ребра выглядит так:
MATCH (s:Sentence {name: “Дөрес, әле Казанда моңа кадәр картлар йорты юк иде.”)
MERGE (d)-[:includesSentence {position: 1, startPosition: 1}]->(s);
Выполнение всех описанных запросов создаёт подграф, показанный на рисунке 6. Каждое предложение в корпусе может быть разделено на клаузы. Если предложение является простым, то оно состоит из одной клаузы, сложное предложение - из двух клауз. Для добавления клауз необходимо создать узлы типа «Clause» и соединить их с узлом предложения при помощи ребра с типом «includesClause». В добавляемом предложении клауза только одна, но их может быть несколько, поэтому у рёбер типа «includesClause» должны быть указаны свойства «position» (порядковый номер клаузы в предложении) и «startPosition» (порядковый номер первого слова клаузы в предложении). Добавление клаузы при помощи запроса на языке Cypher может быть выполнено следующим образом:
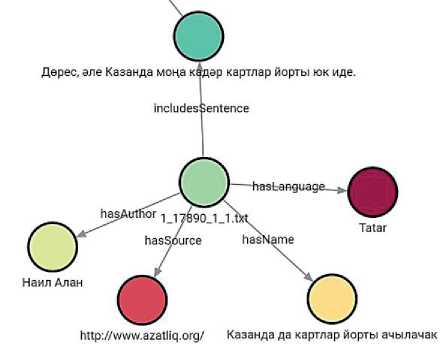
Рисунок 6 – Подграф, включающий узлы предложения, документа и метаданных документа
MATCH (s:Sentence {name: "Дерес, але Казанда моца кадар картлар йорты юк иде.”)
MERGE (s)-[:includesClause {position: 1, startPosition: 1}]->(c:Clause {name: "Дерес, але Казанда моца кадар картлар йорты юк иде.”});
Каждая клауза в ЭК может быть разделена на синтаксемы. Синтаксема - это минимальная, неделимая семантико-синтаксическая языковая единица, выступающая одновременно как носитель элементарного смысла и как конструктивный компонент более сложных синтаксических построений. Синтаксеме может соответствовать как отдельная словоформа, так и словосочетание или знак препинания. Таким образом, для представления синтаксем в БЗ используются узлы типов «Syntaxeme» для синтаксем, состоящих из словоформ, и «PunctuationMark» для синтаксем, состоящих из знаков препинания. Для представления связей между клаузами и синтаксемами используются рёбра типа «includesSyntaxeme», у которых должны быть указаны свойства «position» (порядковый номер синтаксемы в клаузе) и «startPosition» (порядковый номер первой словоформы или знака препинания синтаксемы в клаузе). Запрос для добавления синтаксем на языке Cypher представлен ниже:
MATCH (c:Clause {name: “Дөрес, әле Казанда моңа кадәр картлар йорты юк иде.”)
MERGE (с)-[:includesSyntaxeme {position: 1, startPosition MERGE (с)-[:includesSyntaxeme {position: 2, startPosition MERGE (с)-[:includesSyntaxeme {position: 3, startPosition MERGE (с)-[:includesSyntaxeme {position: 4, startPosition MERGE (с)-[:includesSyntaxeme {position: 5, startPosition MERGE (с)-[:includesSyntaxeme {position: 6, startPosition
MERGE (с)-[:includesSyntaxeme {position: 7, startPosition MERGE (с)-[:includesSyntaxeme {position: 8, startPosition
1}]->(:Syntaxeme {name: “дөрес”})
2}]->(:PunctuationMark {name: “,”}) 3}]->(:Syntaxeme {name: “әле”})
4}]->(:Syntaxeme {name: “казанда”})
5}]->(:Syntaxeme {name: “моңа кадәр”})
7}]->(:Syntaxeme {name: “картлар йорты”})
9}]->(:Syntaxeme {name: “юк иде”})
11}]->(:PunctuationMark {name: “.”});
Выполнение запросов на добавление клауз и синтаксем создаёт подграф, показанный на рисунке 7. Узлы типа «PunctuationMark» являются конечными в текущей версии БЗ. Синтаксемы, состоящие из словоформ, должны быть разделены на словоформы. Словоформы представлены в графе БЗ узлами типа «WordForm», а связи между синтаксемами и словоформами – рёбрами типа «includesWordForm» со свойствами «position», указывающими порядковый номер словоформы в синтаксеме. В качестве примера показаны запросы для синтаксем “Казанда” («в Казани») и “картлар йорты” («дом престарелых»). Запрос, добавляющий в граф БЗ словоформы и связи с указанными синтаксемами, на языке Cypher выглядит следующим образом:
MATCH (s1:Syntaxeme {name: “казанда”})
MATCH (s2:Syntaxeme {name: “картлар йорты”})
MERGE (s1)-[:includesWordForm {position: 1}]->(:WordForm {name: “казанда”})
MERGE (s2)-[:includesWordForm {position: 1}]->(:WordForm {name: “картлар”})
MERGE (s2)-[:includesWordForm {position: 2}]->(:WordForm {name: “йорты”});
Морфологическая разметка каждой словоформы содержит лемму, часть речи и набор морфологических свойств (морфем) словоформы. Причём в части корпуса у каждой словоформы может быть несколько вариантов морфологической разметки.
Для представления в БЗ лемм используются узлы типа «Lemma», для представления частей речи – узлы типа «PartOfSpeech», для представления морфологических свойств – узлы типа «Morpheme». Последние имеют справочное свойство «affix», в котором указывается словообразующий аффикс, соответствующий морфеме. Связи между узлами словоформ и узлами лемм представлены в графе рёбрами типа «hasLemma», связи между узлами словоформ и узлами частей речи – рёбрами типа «hasPartOfSpeech», а связи между узлами словоформ и узлами морфем – рёбрами типа «hasMorpheme». Так как в ЭК может иметься разметка с морфологической неоднозначностью, у всех указанных рёбер присутствуют свойства «variant», указывающие на порядковый номер морфологической разметки словоформы. Для рёбер типа «hasMorpheme» дополнительно указывается свойство «position», указывающее на порядковый номер морфемы
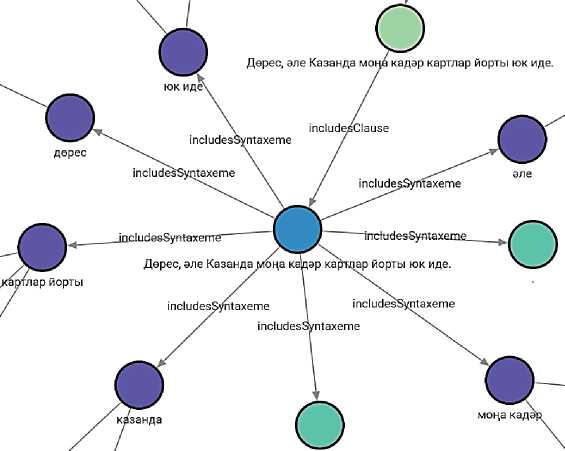
Рисунок 7 – Подграф, включающий узлы предложения, клауз и синтаксем
в цепочке. Добавление указанных узлов и рёбер в граф БЗ при помощи запроса на языке Cypher может быть представлено следующим образом:
MATCH (w1:WordForm {name: “казанда”})
MATCH (w2:WordForm {name: “картлар”})
MATCH (w3:WordForm {name: “йорты”})
CREATE (:Morpheme {name: “SG”, affix: “”}), (:Morpheme {name: “LOC”, affix: “да”}), (:Morpheme {name: “PL”, affix: “ЛАр”}), (:Morpheme {name: “NOM”, affix: “”}), (:Morpheme {name: “POSS_3SG”, affix: “СЫ”})
MERGE (w1)-[:hasLemma {variant: 1}]->(:Lemma {name: “казан”})
MERGE (w1)-[:hasPartOfSpeech {variant: 1}]->(:PartOfSpeech {name: “N”})
MERGE (w1)-[:hasMorpheme {variant: 1, position: 1}]->(:Morpheme {name: “SG”})
MERGE (w1)-[:hasMorpheme {variant: 1, position: 2}]->(:Morpheme {name: “LOC”})
MERGE (w1)-[:hasLemma {variant: 2}]->(:Lemma {name: “казан”})
MERGE (w1)-[:hasPartOfSpeech {variant: 2}]->(:PartOfSpeech {name: “PROP”})
MERGE (w1)-[:hasMorpheme {variant: 2, position: 1}]->(:Morpheme {name: “LOC”})
MERGE (w2)-[:hasLemma {variant: 1}]->(:Lemma {name: “карт”})
MERGE (w2)-[:hasPartOfSpeech {variant: 1}]->(:PartOfSpeech {name: “ADJ”})
MERGE (w2)-[:hasMorpheme {variant: 1, position: 1}]->(:Morpheme {name:“PL”)
MERGE (w2)-[:hasMorpheme {variant: 1, position: 2}]->(:Morpheme {name: “NOM”)
MERGE (w2)-[:hasLemma {variant: 2}]->(:Lemma {name: “карт”})
MERGE (w2)-[:hasPartOfSpeech {variant: 2}]->(:PartOfSpeech {name: “N”})
MERGE (w2)-[:hasMorpheme {variant: 2, position: 1}]->(:Morpheme {name:“PL”)
MERGE (w2)-[:hasMorpheme {variant: 2, position: 2}]->(:Morpheme {name: “NOM”)
MERGE (w3)-[:hasLemma {variant: 1}]->(:Lemma {name: “йорт”})
MERGE (w3)-[:hasPartOfSpeech {variant: 1}]->(:PartOfSpeech {name: “N”})
MERGE (w3)-[:hasMorpheme {variant: 1, position: 1}]->(:Morpheme {name:“SG”)
MERGE (w2)-[:hasMorpheme {variant: 1, position: 2}]->(:Morpheme {name: “POSS_3SG”);
Необходимо также добавить семантические связи между лексемами и объектами. Указанные синтаксемы обозначают здание “картлар йорты” (“дом престарелых”) (в графе узел типа «Building») и место “Казан” (“Казань”) (в графе узел типа “Place”). Добавление семантических связей при помощи запроса на языке Cypher выглядит так:
MATCH (s1:Syntaxeme {name: “казанда”})
MATCH (s2:Syntaxeme {name: “картлар йорты”})
MERGE (s1)-[:indicatedThePlace]->(:Place {name: “Казан”})
MERGE (s2)-[:isA]->(:Building {name: “картлар йорты”});
На рисунке 8 показан подграф, созданный после выполнения указанных запросов для синтаксем “Казанда” и “картлар йорты”. На этом подграфе уже видны общие вершины графа для различных типов узлов и рёбер, например, все три словоформы из примера имеют связь с частью речи “N” (существительное), так как для всех трёх словоформ существует морфологическая разметка с указанием этой части речи.
Заключение
Описанная концептуальная модель лингвистического ГЗ применяется для представления данных ЭК «Туган Тел». Реализация функционала модернизированной системы управления корпусными данными поддерживает функционал поиска по
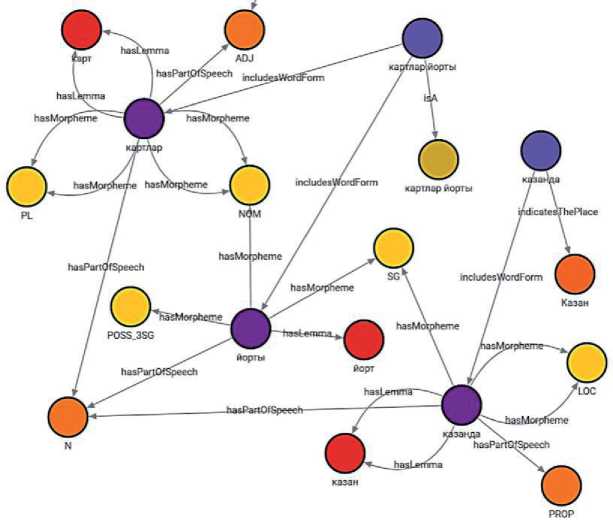
Рисунок 8 – Подграф, включающий узлы синтаксем, словоформ, лемм, морфем, частей речи и семантических связей с объектами
словоформам и леммам, а также поиск по морфемам. Применение новой модели лингвистического ГЗ и возможностей графовой СУБД позволяет расширить функционал системы, добавляя новые инструменты для исследования ТЯ.
Использование системы семантических универсалий в виде фреймовых и таксономических ГЗ позволяет объединять все корпусы в единый многоязычный корпус и производить многоязычный поиск и исследования ТЯ. Эта возможность позволит повысить эффективность деятельности лингвистов и типологов, работающих с ЭК на основе предложенной модели лингвистического ГЗ ТЯ TurkLang .
Список литературы Электронный корпус татарского языка на базе модели лингвистических графов знаний
- Aksan M., Aksan Y. Linguistic Corpora: A View from Turkish. In: Oflazer, K., Saraçlar, M. (eds) Turkish Natural Language Processing. Theory and Applications of Natural Language Processing. 2018. Springer, Cham. DOI:10.1007/978-3-319-90165-7_14.
- Салчак А.Я. Электронный корпус текстов тувинского языка. Новые исследования Тувы. 2012. №3. С.110-114.
- Bazarbayeva Z.M., Zharkynbekova Sh.K., Amanbayeva A.Zh., Zhumabayeva Zh.T., Karshygayeva A.A. The National Corpus of Kazakh Language: Development of Phonetic and Prosodic Markers. Journal of Siberian Federal University. Humanities and Social Sciences. 2023. Т. 16. № 8. P.1256-1270. EDN: IVPVAN.
- Sirazitdinov, Z. Buskunbaeva L., Ishmukhametova A. About linguistic corpora of the Bashkir language // Proceedings of the International Conference "Turkic languages processing" Turklang-2015 / Tatarstan Academy of Sciences L.N. Gumilyov Eurasian National University Ministry of Education and Science of the Republic of Kazakhstan Kazan Federal University Institute of Philology and Intercultural Communication. – Казань, Россия: Академия наук Республики Татарстан, 2015. P.269-275. EDN ZDGYTR.
- Mukhamedshin D., Gilmullin R., Khakimov B. Search Engine Capabilities in the Corpus Data Management System // UBMK 2023 - Proceedings: 8th International Conference on Computer Science and Engineering, Burdur; Turkey; 13-15 September 2023, p.449–452. DOI: 10.1109/UBMK59864.2023.10286648.
- Сулейманов Д.Ш., Гильмуллин Р.А., Гатиатуллин А.Р., Прокопьев Н.А. Когнитивный потенциал естественных языков агглютинативного типа в интеллектуальных технологиях // Онтология проектирования. 2023. Т.13, №4(50). С.496-506. DOI:10.18287/2223-9537-2023-13-4-496-506.
- Hogan A, Blomqvist E, Cochez M, d’Amato C, de Melo G, Gutierrez C, Gayo JEL, Kirrane S, Neumaier S, Pollere A. Knowledge graphs. ACM Computing Surveys (CSUR). 2021; 54(4): 1-37. DOI: 10.1145/3447772.
- Fensel D, Şimşek U, Angele K, Huaman E, Kärle E, Panasiuk O, Toma I, Umbrich J, Wahler A. Knowledge Graphs: Methodology, Tools and Selected Use Cases. Cham: Springer Cham, 2020. 164 p. DOI: 10.1007/978-3-030-37439-6.
- Ji S, Pan S, Cambria E, Marttinen P, Yu PS. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Transactions on Neural Networks and Learning Systems. 2021; 33(2): 494-514. DOI: 10.1109/TNNLS.2021.3070843.
- Pan JZ, Vetere G, Gomez-Perez JM, Wu H. Exploiting Linked Data and Knowledge Graphs in Large Organizations. Cham: Springer Cham, 2017. 266 p. DOI: 10.1007/978-3-319-45654-6.
- Гатиатуллин А.Р., Прокопьев Н.А., Сулейманов Д.Ш. Модель лингвистических графов знаний тюркских языков // Онтология проектирования. 2024. Т.14, №3(53). С.366-378. DOI: 10.18287/2223-9537-2024-14-3-366-378
- Gatiatullin A., Suleymanov D., Prokopyev N., Khakimov B. About turkic morpheme portal // CEUR Workshop Proceedings, 2020, 2780. P.226–243. EDN: ZNIQUO.
- Lyashevskaya, O. and Egor Kashkin, FrameBank: A Database of Russian Lexical Constructions // International Joint Conference on the Analysis of Images, Social Networks and Texts, 2015. M.Y. Khachay et al. (Eds): AIST 2015, CCIS 542. P.1–11. DOI: 10.1007/978-3-319-26123-2_34.
