K-Nearest Neighbors Bayesian Approach to False News Detection from Text on Social Media

Author: Ogunsuyi Opeyemi J., Adebola K. OJO
Journal: International Journal of Education and Management Engineering @ijeme
Article in issue: 4 vol.12, 2022.
Free access
Social media usage has increased due to the rate at which technologies are emerging and it is less likely to detect false news/information manually as it aims to capture the human mind. The spread of false news can cause havoc; therefore, detection of false news becomes paramount where almost everyone has access to social media. Our proposed system optimizes the false news detection process. The system combines advantages of two textual feature extraction methods and two machine learning algorithms for text classification. Basic pre-processing methods were employed. Feature extraction was carried out using Term Frequency-Inverse Document Frequency with Word2Vector. K-Nearest Neighbour (KNN) and Naïve Bayes (NB) algorithms are combined to give KNN Bayesian. The most available systems made use of a single feature extraction method but in our system, two feature extraction methods are combined. The evaluation metrics used were accuracy, precision, recall, f1score and KNN Bayesian performed better than KNN. To further evaluate our model, the Area under the Curve-Receiver Operator Characteristics (AUC-ROC) revealed that AUC of KNN Bayesian ROC curve is higher than that of KNN.
False News/Information Detection, K-Nearest Neighbours, Bayesian, Word2Vector, Term Frequency-Inverse Document Frequency
Short address: https://sciup.org/15018483
IDR: 15018483 | DOI: 10.5815/ijeme.2022.04.03
Text of the scientific article K-Nearest Neighbors Bayesian Approach to False News Detection from Text on Social Media
Social media has a great impact on our lives. It can either affect us negatively or positively by what we see. Social media has given rise to a new way in which information is being conveyed since 2017. Therefore, information is sourced for on social media rather than the traditional means which are television and newspaper. Due to this, false news and rumors spread like fire rapidly affecting lives [1]. False news or Fake news can be defined as news that is portrayed to be true but is not true. ‘False news detection’ can be defined as the task of categorizing news as truthful, having the aim to deceive readers with an iota of truth [2].
In Nigeria, false news adverse effects can either be mild or severe causing confusion, tension, or even death. One of such effects was the spread of the news in 2014 which stated how Ebola can be prevented, and this led to the death of two people from excessive drinking and bathing with saltwater. A recent example was Chloroquine poisoning during the Covid-19 pandemic which stated that President Donald Trump of the United States claimed hydroxychloroquine had been approved to treat Covid-19. Therefore, false news detection has become a significant research area.
In 2015, a bill was first passed in Nigeria to dictate policy as regards social media however, this was not passed into law as a result of public cry stating that it would violate international law protecting freedom of speech. Thus, the real impact of the need to detect false news has emerged from the awareness that it is very likely to spread quickly and cannot be easily identified by the readers [3].
Several feature extraction methods and algorithms have been proposed to detect false news. Term frequencyinverse document frequency (TF-IDF) has been used by some researchers and has been successful to extract textual features but, it sees two words having the same meaning as independent words and also, do not put in place the position of words in a sentence. TF-IDF measures how important a word is to a corpus of the document depending on how common such word is to the corpus. Word2vector (Word2Vec) sees the two words as the same and also, takes into consideration the position of a word but was not successful totally when used independently, as it gave a lower accuracy than when TF-IDF was used. In detecting false news, it is very important to know the context in which words are being used therefore, there is a need to combine the advantage of word2vector with TF-IDF. Machine learning algorithm like the K-Nearest Neighbors (KNN) algorithm, does better with finding similarities between observations and this is an important factor needed for false news detection. As the complexity of the decision boundaries grows, the accuracy of KNN is reduced. This leads to acquiring more data thereby increasing accuracy. Real-time predictions cannot be made using KNN but in Naïve Bayes (NB) algorithm, real-time predictions can be made. However, as to improve performance model, there is need to ensemble KNN algorithm with NB algorithm to build a K-Nearest Neighbor Bayesian model.
This paper proposes a K-Nearest Neighbors Bayesian Approach to detect fake news from text. The main contributions of this paper are as follows.
-
• A model is developed which can be used to classify textual features as false or true.
-
• The model is implemented using K-Nearest Neighbors (KNN) and Naïve Bayes (NB) for the classification of
data features.
• Term frequency-inverse document frequency (TF-IDF) + Word2vector (Word2Vec) are used for feature extraction to substitute the single feature extraction methods known. Feature extraction is the process of changing textual data into numbers representations for the algorithm(s) to work on without losing information in the given data set.
2. Background
The proposed model is tested and performance is evaluated on test data. The model was evaluated based on the percentage of correct classification of true and false news using Accuracy, Precision, Recall, F1-Score. Accuracy is a measure of the correct number of predictions to the total number of predictions in the data. So the higher the accuracy of the false news detection, the better. The precision score is a measure of the truly predicted number of positive classes that is, how many of the classes are actually positive. Recall score is the measure of all the truly predicted positive classes by the model. F1 score combines the precision score and recall score and takes their harmonic mean. The harmonic mean is the measure for ratios and rates. To further evaluate our model, the Area under the Curve-Receiver Operator Characteristics (AUC-ROC) was employed. It indicates that the higher the AUC value of a classifier, the better it is at distinguishing between positive and negative classes. The value of AUC closer to 1 in a model, tells that such model has a good measure of separability. To reveal better performance, the proposed model is compared to a model with single machine learning algorithm and performed better.
Text mining is a process of extracting information that has meaning for exploring knowledge from data sources in form of text [5]. Text mining is in form of semi-structured and unstructured text under natural language [6]. Text mining is a field that cuts across many others fields like machine learning, data mining, information retrieval, computational linguistics, and statistics [7] (this is shown in fig. 1). Data mining is similar to text mining except that data mining tools only handle structured data from databases [8]. The unstructured text contains statistical and meaningful information therefore, there is a need for some techniques to extract such information from the text [9]. Text mining consists of such techniques, information Extraction, Text Classification, Natural Language Processing, Information Retrieval [5], document clustering, text summarization, and so on, to extract knowledge (Fig. 2). Text mining is being used for feature extraction, sentiment analysis, trend analysis, opinion mining in areas of fraud detection, social media analytics, search engine, filter emails, product suggestion analysis, and customer relationship management systems [10].
Machine learning for classifying text can be grouped into supervised, semi-supervised, and unsupervised learning tasks. In supervised learning, training set samples are needed though, samples may be inadequate or insufficient as well as available. Such a problem is referred to as semi-supervised text classification. Supervised and semi-supervised text classification techniques rely on already classified data samples to learn classifiers. Unsupervised learning requires unlabeled data and finds hidden structures in them [11].
False news differs from true news in writing style and quality, quantity such as word counts [12], and sentiments [13]. Therefore, the detection of fake news relies heavily on news content. False news writers aim to keep readers glued to a piece of news by getting such readers’ attention or to increase traffic on their profiles or blogs (Fig. 1). The features extracted from news contents are lexical features, syntactic features [14], psycholinguistic features, and semantic features [15].
-
i. Lexical features: this includes character and word-level features. The example includes some of the words, characters per word, unique words, and their frequency [14].
-
ii. Syntactic features: this includes sentence-level features (the frequency of function words and phrases) such as bag-of-words approaches, “n-grams” [16], and part-of-speech (POS) tagging.
-
iii. Psycholinguistic features: Linguistic Inquiry and Word Count (LIWC) lexicon are used to extract the proportions of words that are of type, psycholinguistic. LIWC is based on large lexicons of word categories
that represent psycholinguistic processes (e.g., positive emotions, perceptual processes), part of speech categories (e.g., articles, verbs) and summary categories (e.g., words per sentence) [15].
iv. Semantic features: these are elements of meaning. For example, damsel, maid, female are semantic features of the word, ‘girl’. These features determine the lexical relationship between words.
3. Methodology
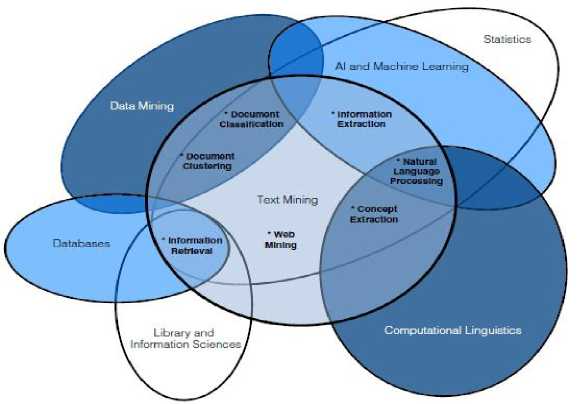
Fig.1. Text Mining and other Related Fields [6]
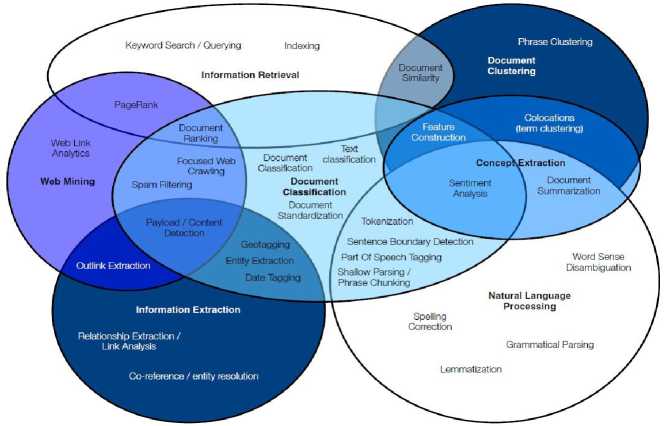
Fig.2. Relationship between Text Mining Techniques and their Functionalities [10]
Fig. 3 shows the proposed methodology for the detection of false news. The involved dataset samples consist of unstructured labeled news having ‘0’as false and ‘1’ as true. Data were collected online from zenodo.org. Zenodo.org has dataset samples from four news dataset merged together and this includes Kaggle, McIntire, Reuters and BuzzFeed Political. We acquired correctly 72,047 labeled texts out of 72,134. The total dataset used for both training and testing were 10,035 labeled texts out of the 72,047 because, the previous took approximately 12 hours to run and the latter may take approximately 84 hours to run. From the 10,035 labeled texts, 5,054 are true news, 4,795 are false news and 186 gave null value in one of the cells in each row. The textual data are preprocessed using some preprocessing methods such as null value removal, punctuation removal, lower case token conversion, stop word removal, part of speech tagging, wordnet tagging and lemmatization (Fig. 4).
The preprocessed texts are put back into sentences and the features are extracted using Term Frequency- Inverse Document Frequency + Word2Vector (TF-IDF+Word2Vec). TF-IDF sees two words having the same meaning as two different words for example, ‘project’ and ‘protrude’ (and separating words with the same meaning will result in the loss of partial information when text features are extracted.) while Word2vec sees both words as the same by identifying the center word and context or surrounding words.
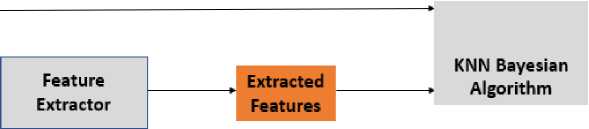
In classifying news as false or true, the dataset is randomly split into training and testing set by using sklearn.model selection package’s train-test-split method. 80 percent of the dataset was used for training and 20 percent was used for testing. The feature sets which are now in vectors of real numbers, are passed through the machine learning algorithm. The machine learning algorithms, K-Nearest Neighbors and Naïve Bayes are combined to classify the text as false or true (Fig. 5). K-Nearest Neighbors is used first to calculate Euclidean distance then, Naïve Bayes is used to calculating the class of the query.
Fig.3. The Methodology
Removing punclueton
Ramoveng nufl values

persistent coughing
Chtofoquine cures CoronaWus
The President of Nigeria.
M(4.tnimed BuhaH
Converting tees to lower ease tokens I [chkxoqu>ne.
with, persistent, toughing
Removing tokens of length les» then four

1. [(chlcxoqiene, n). (cures, (corona, n), (virus, nJ)
2. [(president, n). (nigeria. (mohammed, n). (buhari, (very, r), (sick, v), (persistent r). (coughing, v)J
Wordnet tagging

POS tagging
((chkiroqulrte. NN|, (cures, VBZ), (corona. NNL (virus, NN)| [(president. NN|, (nigeria, NN), (mohammed, NN), (buharl, NN), (very. RB|, (sick. VBP), (persistent. RB), (coughing. VBG)]
Fig.4. The process of pre-processing textual data
Training Stage [ LABEL ^

INPUT
Testing Stage


Fig.5. K-Nearest Neighbors Bayesian Classification Model
For evaluating the proposed model on textual data, five metrices were used which are, Accuracy measures, Precision, Recall, F1-Score, Area Under the Curve- Receiver Operator Characteristics (AUC-ROC Curve). These metrics are described below.
-
• Accuracy: It is a measure of the correct number of predictions to the total number of predictions in the data. So the higher the accuracy of the false news detection, the better.
True Positive (TP): True Positive represents the value of correct predictions of positives out of actual positive cases.
False Positive (FP): False positive represents the value of incorrect positive predictions.
True Negative (TN): True negative represents the value of correct predictions of negatives out of actual negative cases.
False Negative (FN): False negative represents the value of incorrect negative predictions.
Accuracy =
Correct Predictions
Total Predictions
TP+TN
TP+FN+TN+FP
-
• Confusion Matrix – Precision, Recall, F1-Measure Scores: A confusion matrix is a performance measurement table having four compartments of predicted and actual values of a classifier model. It displays the number of correct and incorrect predictions gotten by the model (Fig. 6).
The precision score is a measure of the truly predicted number of positive classes that is, how many of the classes are actually positive.
_ . . TP
Precision score = (2)
FP + TP v 7
Recall score is the measure of all the truly predicted positive classes by the model. It is also known as True Positive Rate.
Recall score = ———
FW + TP
F1 score combines the precision score and recall score and takes their harmonic mean. The harmonic mean is the measure for ratios and rates.
F1 score =
2*Precision *Recall Score
Precision Score + Recall Score the appropriate threshold for models. ROC plots the True Positive Rate (TPR) against False Positive Rate (FPR). The AUC-ROC curve measures the performance of classification problems at different thresholds. The higher TPR and the lower FPR for each threshold, the better. This indicates that the model or models which have curves that are more to the top-left side are better. As the curve moves more to the top-left side, the area of the curve increases, and hence the ROC score increases. Fig. 7 shows the AUC-ROC curve.
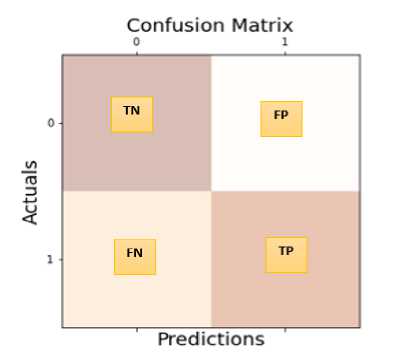
Fig.6. Confusion Matrix
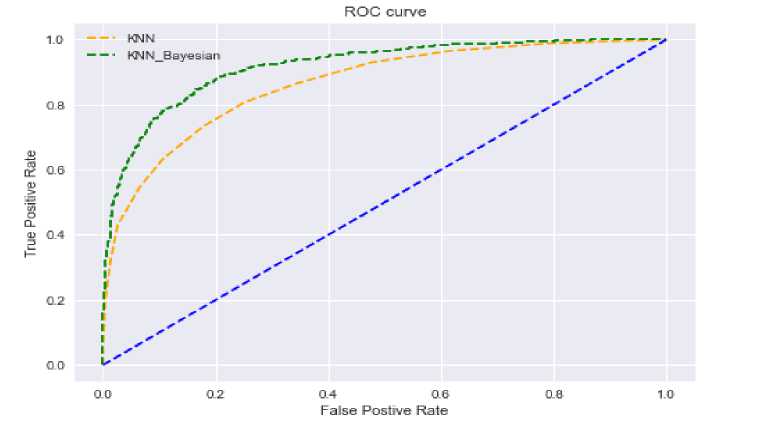
Fig.7. AUC-ROC Curve Showing K-Nearest Neighbors and K-Nearest Neighbors Bayesian
4. Result Analysis and Discussion
In this section, the results were discussed. Fig. 8 shows the exploratory data analysis and this reveals that the final dataset samples used contains an approximately equal portion of both true and false news. Table 1 shows the screenshot of the preprocessed stages in this study.
The result of the whole process is presented in Table 2 and Fig. 9. It has been previously established that K-Nearest Neighbors (KNN) algorithm does better with finding similarities between observations therefore, the comparison made are between our proposed model, K-nearest neighbor Bayesian model built using TF-IDF with Word2Vec and K-nearest neighbor model built using TF-IDF with Word2Vec. Our proposed methodology performed better in terms of precision, recall, accuracy and f1-score. We obtained approximately 83% accuracy using KNN Bayasian when classifying false news to real news which is better than the 76% accuracy acquired by KNN. The recall, precision, f1-score values are 74%, 90%, 82% respectively for KNN Bayesian and, 63%, 86% and 73% for KNN.
Table 2. Precision, Recall, Accuracy, and F1 score for KNN and KNN Bayesian
|
Precision |
Recall |
Accuracy |
F1 |
|
|
KNN |
0.860811 |
0.633831 |
0.760914 |
0.730086 |
|
KNN_NB |
0.902292 |
0.744279 |
0.828426 |
0.815703 |
0ut[35]:
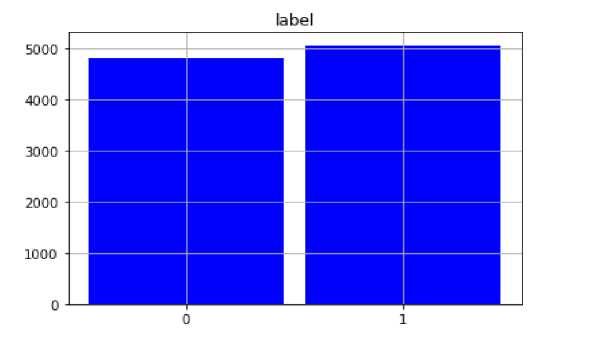
Fig.8. A Bar Chart showing the nearly Balanced Distribution of False and True Classes
Table 1. Preprocessing Stages of the Dataset Sample
|
id ex |
text |
label |
removed_punc |
tokens |
large Moke ns |
clean_tokens |
stem_words |
pos_tags |
wordnetjos |
lemmatized |
preprocessed |
|
0 |
No comment is expected from Barack Obama Membe... |
1 |
No comment is expected from Barack Obama Membe... |
[no, comment, is, expected, from, barack, obam... |
[comment, expected, from, barack, obama, membe... |
[comment, expected, barack, obama, members, fy... |
[comment, expect, barack, obama, member, fyf91.. |
[(comment, NN), (expected. VBN), (barack, RB),... |
[(comment, n}, (expected, v), (barack, r), (ob... |
[comment, expect, barack, obama, member, fyf91... |
comment expect barack obama member fyf911 fuky... |
|
2 |
Now, most of the demonstrators gathered last |
1 |
Now most of the demonstrators gathered last |
[, now, most, of, the, demonstrators, gathered... |
[most, demonstrators, gathered, last, night, w... |
[demonstrators, gathered, last, night, exercis... |
[demonstr, gather, last, exercis, |
[(demonstrators. NNS), (gathered. VBD), (last,... |
[(demonstrators, n), (gathered, v), (last, a),... |
[demonstrator, gather, last, exercise,... |
demonstrator gather last night exercise consti... |
|
3 |
A dozen politically active pastors came here f... |
0 |
A dozen politically active pastors came |
[a, dozen, politically, active, pastors, came,... |
[dozen, politically, active, pastors, came, he... |
[dozen, politically, active, pastors, came, pr... |
[dozen, polit, activ, pastor, came, privat, di... |
[(dozen, NN), (politically, RB). (active, JJ),... |
[(dozen, n}, (politically, r), (active, a), (p... |
[dozen, politically, active, pastor, come, pri... |
dozen politically active pastor come private d... |
|
4 |
The RS-28 Sarmat missile, dubbed Satan 2, will... |
1 |
The RS28 Sarmat missile dubbed Satan 2 will re... |
[the, rs28, sarmat, missile, dubbed, satan, 2,... |
[rs28, sarmat, missile, dubbed, satan, |
[rs28, sarmat, missile, dubbed, satan, replace... |
[rs28, sarmat, missil, dub, satan, replac, ss1... |
[(rs28, NN), (sarmat, NN), (missile, NN), (dub... |
[(rs28, n), (sarmat, n), (missile, n), (dubbed... |
[rs28, sarmat, missile, dub, satan, replace, s... |
rs28 sarmat missile dub satan replace ss18 fly... |
|
5 |
All we can say on this one is it s about time |
1 |
All we can say on this one is it s about time... |
[all, we, can, say, on, this, one, is, it, s,... |
[this, about, someone, southern, p... |
someone, sued, southern, poverty, cente... |
someoni su, southern, poverti, centeron... |
[(time, NN), (someone, NN), (sued, VBD), |
[(time, n}, (someone, n), (sued, v), (southern... |
someone, sue, southern, poverty, center... |
time someone sue southern poverty centeron tue.. |
|
< |
> |
||||||||||
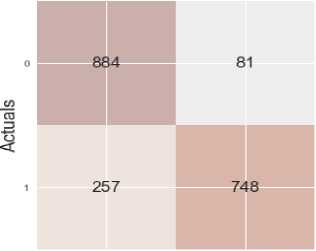
From the confusion matrices in Fig. 10 and Fig. 11, the KNN model classified correctly 637 news out of the actual number of True Positives (TP) and our KNN Bayesian model increased the number by 111 to make 748 news classified correctly. 862 were correctly classified out of the actual number of True Negatives (TN) in the sample for KNN model and an increase occurred in our model giving rise to 884 news classified correctly out of the actual number of True Negatives (TN).
The incorrect positives and negatives for KNN model are 103 and 368 respectively and that of our KNN Bayesian model reduced to 81 and 257 respectively. These accurately show that our model is better than the KNN model.
-
■ KNN
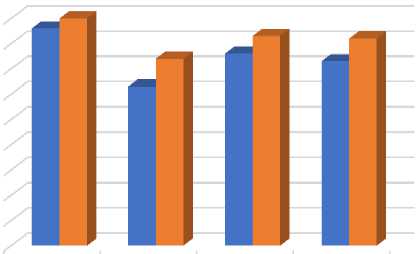
Precision Recall Accuracy F1 Score
86 63 76 73
-
■ KNN Bayesian 90
83 82
■ KNN ■ KNN Bayesian
Fig.9. A Chart Showing the Percent of Precision, Recall, Accuracy, and F1 score for KNN and KNN Bayesian
The ROC curve in Fig. 7 was able to distinguish between the two models. The AUC for KNN and KNN Bayesian are 0.86 and 0.91 respectively. The value of AUC closer to 1 in a model says that such model has a good measure of separability. It was observed that KNN Bayesian is closer to the upper left corner and this reveals that it is more efficient in the test being performed.
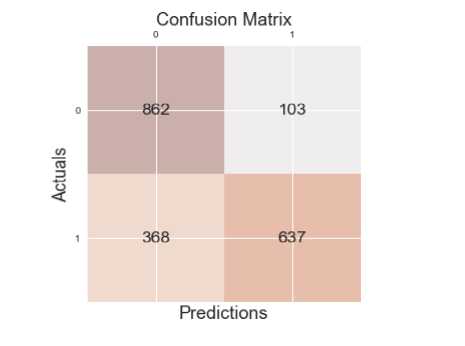
Fig.10. Confusion Matrix for K-Nearest Neighbors Model
Confusion Matrix
Predictions
Fig.11. Confusion Matrix for K-Nearest Neighbors Bayesian Model
5. Related Work
In [17], there was a study on the impact of the size of n-grams such as uni-gram, bi-gram, tri-gram, four-gram. This was done on two different feature extraction methods TF-IDF and TF and varied the size of n-gram. Online fake news was detected using six different machine learning algorithms and the Linear Support Vector Machine (LSVM) classifier gave the highest accuracy.
-
[18] also conducted two experiments in detecting opinion spam and fake news: two existing dataset samples were used in the first experiment and achieved slightly high accuracy. In the second experiment, a new dataset was collected and used and this achieved higher accuracy than the initial. Six different single classifiers were investigated to predict the class of the documents.
A fake news detection model that is implemented using a hybrid text classification technique of K-Nearest Neighbor (KNN) and Random Forest (RF) was developed by [19]. Three processes of detecting fake news which are; pre-processing, feature extraction, and classification were carried out. The results were compared with a single classifier, Support Vector Machine (SVM) and it was observed, the hybrid classification gave an increased accuracy of 8 percent than the single classifier. No redundancy in the dataset used [19].
-
[20] carried out basic preprocessing steps and Word2Vec for extracting features in fake news detection. They compared Long Short-Term Memory (LSTM) with three other algorithms but it had the highest accuracy.
In [14}, text features based on fake news detection were developed. Feature extraction was done using a hybrid CNN-LSTM model as a combination of a convolution layer. Two dataset samples, Liar and News articles were acquired and in the Liar dataset, Convolutional Neural Networks-Long Stort-Term Machines (CNN-LSTM) outperformed SVM and Convolutional Neural Networks (CNN) with an accuracy of 62.34%. in the News articles dataset, CNN-LSTM also had the highest accuracy of 72.50%.
[22] implemented a fake news classifier using LSVM Classifier built on traditional text feature representation technique TD-IDF of Ahmed et al. [17], against an LSVM classifier built ‘word2vec’ word embedding and ‘Universal Sentence Encoder’ sentence embedding text feature representation technique. LSVM classifier built on TF-IDF gave a higher accuracy as the latter was not successful totally. Since reliable news is written with the neural sentiment, Sriram decided to add an experiment to decide whether the negative sentiment was in any way attached to fake news. Afinn, Text Blob and Vader were the sentiment lexicons used to classify the news as positive, negative, and neutral using the Kaggle news dataset. Reliable articles had a higher number of positive sentiments and in fake articles, Afinn gave the highest number of negative sentiments.
[23] developed a fake news detection on social media model having two different steps. The first step consists of preprocessing and feature extraction of the dataset. Term Frequency (TF) alongside Document-Term Matrix (DTM) was used in the feature extraction stage. DTM according to the weights of the words was formed. In the second step, twenty-three different single supervised artificial intelligence algorithms were used.
6. Conclusion and Recommendations
Four steps were involved in detecting fake news in [24]. Firstly, calculation of the similarities between features and secondly, division of the features into clusters with the help of K-means. Thirdly, selection of the final feature sets using Fisher Score (FS). Fourthly, the SVM method was used for classification based on the final feature set. Three different dataset samples were used and evaluation was carried out by comparing the SVM classifier with two other classifiers, NB and Decision Tree (DT) with SVM having the highest accuracy.
In this work, the advantage of two different textual feature extraction methods and also, two different machine learning algorithms were combined for text classification. In the above methods, single feature extraction method was used, no available system has been developed as at the time of this research to extract textual features combining the two methods. This model creates an effective detection of false news using combined textual feature extraction methods and machine learning algorithms.
In recent years, it has become difficult to access news without an element of false news. Some false news detection model has been developed in times past using TF or TF-IDF or Word2Vec and others to extract features. The proposed model is aimed at improving model performance to classify text features and to detect false news using K-nearest Neighbor (KNN) Bayesian algorithm. This is achieved by sourcing for news dataset online at zenodo.org and the useable dataset is preprocessed. The preprocessed texts were passed through the feature extraction stage that was used for false news detection. The feature extraction stage consists of both TF-IDF and Word2Vec combined. In this stage, the texts are changed to vectors before they can be passed to the classification algorithm. Then, comparison is made between KNN and KNN Bayesian to classify the text as true and false. The model developed was trained with a percent of the labeled texts and tested with the remaining percent.
From this research, KNN Bayesian model has been validated using accuracy, recall, precision, F-measure values, and AUC-ROC curve. High percent of KNN Bayesian model showed that it performed better than KNN in terms of accuracy, recall, precision, F-measure values, and AUC-ROC curve. We suggest that the dataset samples collected, be accessed and run to further train and test the system. Also, the proposed methodology in this study should be considered for fake news contents from videos.
References K-Nearest Neighbors Bayesian Approach to False News Detection from Text on Social Media
- Zhang, Y., Su, Y., Weigang, L. and Liu, H. (2018). Rumor and authoritative information propagation model considering super spreading in complex social networks. Physica A: Statistical Mechanics and Its Applications, 506, pp. 395-411.
- Conroy, N. J., Rubin, V. L. and Chen, Y. (2015). Automatic deception detection: Methods for finding fake news. Proceedings of the Association for Information Science and Technology, 52(1), pp. 1-4.
- BBC News. (2015). Nigeria storm over social media bill. [online] Available at: www.bbc.com/news/world-africa-35005137.amp (Accessed 7 January 2022).
- Hassan, I. (2020) The other COVID-19 pandemic: Fake news | African Arguments. [online] Available at: www.africanarguments.org/2020/03/the-other-covid-19-pandemic-fake-news (Accessed 16 June 2021).
- Goel, N. (2020). A study of text mining techniques: Applications and Issues. Pramana Research Journal, 8(12), pp. 307–316.
- Weiss, S. M., Indurkhya, N., Zhang, T. and Damerau, F. (2010). Text mining: predictive methods for analyzing unstructured information. Springer Science and Business Media.
- Fan, W., Wallace, L., Rich, S. and Zhang, Z. (2006). Tapping the power of text mining. Communications of the ACM, 49(9), pp. 76-82.
- Navathe, S. B. and Elmasri, R. (2000). Data Warehousing and Data Mining. In Fundamentals of Database System, Pearson Education pvt Inc, Singapore, pp. 841-872.
- Sumathy, K. and Chidambaram, M. (2013). Text mining: Concepts, applications, tools and issues-an overview. International Journal of Computer Applications, 80(4), pp. 29-32.
- He, W. (2013). Examining students’ online interaction in a live video streaming environment using data mining and text mining. Computers in Human Behavior, 29(1), pp. 90-102.
- Zhou, X., Gururajan, R., Li, Y., Venkataraman, R., Tao, X., Bargshady, G., Barua, P. D. and Kondalsamy-Chennakesavan, S. (2020). A survey on text classification and its applications. Web Intelligence, 18(3), pp. 205-216.
- McCornack, S. A., Morrison, K., Paik, J. E., Wisner, A. M. and Zhu, X. (2014). Information Manipulation Theory 2: A Propositional Theory of Deceptive Discourse Production. Journal of Language and Social Psychology, 33(4), pp. 348-377.
- Zuckerman, M., DePaulo, B. M. and Rosenthal, R. (1981). Verbal and Nonverbal Communication of Deception. Advances in experimental social psychology, 14, pp. 1–59.
- Drif, A., Ferhat Hamida, Z. and Giordano, (2019). Fake News Detection Method Based on Text-Features. The Ninth International Conference on Advances in Information Mining and Management, pp. 26-31.
- Pérez-Rosas, V., Kleinberg, B., Lefevre, A. and Mihalcea, R. (2018). Automatic detection of fake news. COLING 2018 - 27th International Conference on Computational Linguistics Proceedings.
- Fürnkranz, J. (1998). A study using n-gram features for text categorization. Austrian Research Institute for Artificial Intelligence.
- Ahmed, H., Traore, I. and Saad, S. (2017). Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 10618 LNCS, pp. 127–138.
- Ahmed, H., Traore, I. and Saad, S. (2017). Detecting opinion spams and fake news using text classification. Security and Privacy, 1(1), p. e9.
- Kaur, P., Boparai, S. and Singh, D. (2019). Hybrid Text Classification Method for Fake News Detection. International Journal of Engineering and Advanced Technology (IJEAT), (5).
- Jain, G. and Mudgal, A. (2019). Natural language Processing Based Fake News Detection using Text Content Analysis with LSTM. International Journal of Advanced Research in Computer and Communication Engineering, 8(11).
- Bharadwaj, P. and Shao, Z. (2019). Fake News Detection with Semantic Features and Text Mining. International Journal on Natural Language Computing, 8(3), pp. 17–22.
- Sriram, S. (2020). An Evaluation of Text Representation Techniques for Fake News Detection Using: TF-IDF, Word Embeddings, Sentence Embeddings with Linear Support Vector Machine.
- Ozbay, F. A. and Alatas, B. (2020). Fake news detection within online social media using supervised artificial intelligence algorithms. Physica A: Statistical Mechanics and Its Applications, 540.
- Yazdi, K. M., Yazdi, A. M., Khodayi, S., Hou, J., Zhou, W. and Saedy, S. 2020. (2020). Improving Fake News Detection Using K-means and Support Vector Machine Approaches. World Academy of Science, Engineering and Technology International Journal of Electronics and Communication Engineering, 14(2), pp. 38-42.
