Классификация определений в математических latex статьях

Автор: Огурцов Д.А.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Математика
Статья в выпуске: 1 (61) т.16, 2024 года.
Бесплатный доступ
Рассмотрено построение классификатора «определений» в математических научных статьях формата LaTeX на основе различных векторных представлений для задачи распознавания «областей интереса» и задачи MIR. Составлен корпус документов, содержащих определения. Исследованы визуальные отображения векторных представлений для данной задачи, а также качество работы классификаторов на них.
Обработка естественного языка, latex, математические тексты, векторные представления
Короткий адрес: https://sciup.org/142241779
IDR: 142241779 | УДК: 004.855.5
Classification of definitions in mathematical latex articles
The paper discusses the construction of a classifier of «definitions» in mathematical scientific articles LaTeX format based on various vector representations for the problem of recognizing «areas of interest» and the MIR problem. A corpus of documents containing definitions has been compiled. Visual displays of embeddings for this task, as well as the quality of classifiers work, have been studied.
Текст научной статьи Классификация определений в математических latex статьях
Математический текст представляет собой сильно структурированный язык, где взаимодействие между словами и символами не похоже ни на что из любого другого вида языка, естественного или искусственного, так как является более сложным. Также язык обладает сравнительно небольшим набором лексем, используемых повсеместно, особенно это касается символов, поскольку именно эти единицы текста часто используются в произвольном контексте. Так, например, «X» может означать: независимую переменную, координату на оси абсцисс и так далее. Поведение, взаимодействие и свойства такого символа могут сильно отличаться, в зависимости от природы объекта. То же самое относится и к словам. Рассмотрим это на примере слова «группа»: в зависимости от контекста оно может обозначать как «совокупность чего-либо», так и конкретный термин, относящийся к теории групп. Анализ математических текстов интересен тем, что позволяет выделять представляющие интерес участки в математическом тексте, например: брать математические предложения, определять их синтаксическую структуру и извлекать лежащее в их основе значение в соответствующей логике [1].
Математические статьи и документы чаще всего редактируются с помощью формата LaTeX [2], который является общепринятым стандартом для технической литературы и научных текстов. На текущий момент рассмотрена общая применимость, качество работы, а также сложности и подходы при применении методов машинного обучения для анализа
(с) Огурцов Д. А., 2024
-
(с) Федеральное государственное автономное образовательное учреждение высшего образования
«Московский физико-технический институт (пациопальпый исследовательский университет)», 2024
естественного языка при обработке математических текстов формата LaTeX на примерах некоторвк задач: составления глоссария терминов, машинного перевода [3,4]. Также интерес к изучению различных структур математического языка проявляется в исследовании и построении моделей машинного обучения в данном домене для задач: извлечения пар идентификатор-определение, извлечения формул, извлечения релевантных утверждений для доказателвства из естественного языка, задаче MWP[5-7], неформальному доказательству теорем [8].
В прошлом были попытки построения классификатора определений для LaTeX статей, но данный анализ не давал качественной оценки данному подходу, а также не являлся исчерпывающим из-за использования ограниченного набора инструментов для анализа [9]. В данной работе приведен анализ для математических LaTeX текстов и рассмотрена задача построения модели, которая классифицирует предложения на «определение» и «не определение», основанной на методах машинного обучения, для LaTeX документов со служебными словами. Данный анализ и предложенные модели могут быть полезны для улучшения информационного поиска в наукометрических базах, а также для задачи извлечения пар идентификатор-определение, как решение более абстрактной задачи, позволяющей рассматривать «области интереса» в корпусе документов, а не документы целиком, и в задаче MIR (Math Information Retrieval) для текстов на естественном языке [8, 10, 11], что может быть, в свою очередь, использовано для разработки приложения, направленного на удобство пользователей при работе с такими документами. На рис. 1 представлен наглядный пример работы такого приложения для отображения возможностей работы с «областями интереса» в математических документах.
Select highlight type:
| All [ | Definition | j Identifier Ц Text Definition
A random variable X is a measurable function X : fi-»E from a sample space ft as a set of possible outcomes to a measurable space E. The technical axiomatic definition requires the sample space ft to be a sample space of a probability triple (ft, F, P).
The probability that X takes on a value in a measurable set S £ E is written as:
P(xes) = P({«ef>|XO)es})
Is example of ft
Where ft is sample space (Link)
ft is set of possible outcomes (Link)
Properties:
The outcomes must be mutually exclusive (Link)
(from Wikipedia)
Рис. 1. Пример выделения «областей интереса» в математических текстах
2. Методы
В применении к данной задаче были рассмотрены следующие модели для проведения анализа:
1. BOW [12].
2. TF-IDF [13, 14].
3. USE [15].
4. BERT [16].
5. MathBERT [17].
6. t-SNE [18].
2.1. Universal Sentence Encoder
2.2. BERT
2.3. MathBERT
2.4. t-SNE t-SNE — статистический нелинейный метод визуализации данных большой размерности в пространстве низкой размерности (двух или трехмерном), таким образом, что близкие объекты представляются близко расположенными точками, а различные объекты, с большой вероятностью, представляются точками, далеко расположенными друг от друга [18]. Данный метод активно используется для снижения размерности и представления данных в обработке естественного языка [22].
3. Результаты3.1. Подготовка данных
Для построения векторных представлений использовались модели 1-5, модель б для их визуализации. Данные методы предлагают различные подходы и решения к задаче анализа и обработки текста: основанные на статистике 1-2 и нейронных сетях 3-5. Все представленные модели имеют между собой ключевые отличия, в репрезентации текста или в обучающем наборе данных, как в случае с 4 и 5.
Ниже рассмотрены наиболее важные для анализа модели.
Универсальный кодировщик предложений — модель для получения векторных представлений предложений, использующая идею переноса знаний для кодировщиков векторного представления (путем обучения на разнообразных задачах). Данная модель опирается на два подхода к кодированию векторов предложений (документов): архитектуру кодировщика трансформера [19] и DAN [20].
Модель, используемая для различных классов задач в обработке естественного языка, изначально обученная на задачу маскирования текста и показывающая высокие результаты во многих задачах обработки естественного языка. Данная архитектура, развивая идею кодировщика трансформера, позволяет механизму внимания [19] брать контекст как из левой, так и из правой части (в обе стороны), что позволяет улучшить результаты векторизации [16]. Не используя часть декодировщика, данная модель умеет улавливать общую семантику языка и переводить их в векторное представление, благодаря чему существует большое количество предобученных моделей данной архитектуры, натренированных на различных текстовых корпусах для разных языков и различных задач (извлечения имено-ваных сущностей, анализ тональностей и др.).
MathBERT — модель архитектуры BERT, натренированная на корпусе математических формул, охватывающих часть их контекста (не менее 400 символов), в том числе и LaTeX документов. MathBERT достигает высоких результатов в задаче информационного поиска для математических формул и текста [17, 21].
Для подготовки к анализу статей, написанных с помощью пакета LaTeX, была произведена разметка 40 статей с сайта arxiv.org по тематике «комбинаторика». В качестве инструмента разметки был выбран Brat [23]. Основными выделяемыми сущностями являлись «определения» и «определяемое понятие» вместе с «идентификатором», используемые для валидации разметки «определений».
Примеры разметки:
-
1. Определение: Given a positive integer п G Z+, we use Sn to denote the symmetric group on the set [n] = {1, 2,..., n}.
-
2. Определение: In other words, Sn is the set of all bijective functions on [n]. Определяемое понятие: set of all bijective functions
Определяемое понятие: symmetric group
Идентификатор: Sn
Идентификатор: Sn
Правила, используемые для разметки:
1. Не выделялись предложения, в которые ничего не вводится, или дана конкретная реализация, или пример объекта.
2. При разметке не выделяются объекты, которые описаны в предложениях с подсписками, таблицами и так далее, так как сложно описать их структуру линейно (существуют сложные взаимосвязи в объявлении объектов).
3. В случае, когда существует двойственность в обозначении объекта, выбирается то, что более емко его описывает.
3.2. Визуализация векторных представлений
Количество данных после разметки составило 3991 предложение. Распределение меток по классам составило: 77 меток класса «определений» и 3914 меток класса «не определений».
В данном разделе представлена визуализация результатов работы алгоритма снижения размерности t-SNE для векторных представлений набора данных, составленных с помощью моделей: BOW, TF-IDF, Word2Vec, GloVe, USE, BERT и MathBERT.
Модели BOW и TF-IDF были обучены на корпусе предложений, составляющим около 80 тысяч единиц с сайта arxiv.org по тематике «комбинаторика» (лучшими были выбраны модели на основе унограмм и биграмм). Для борьбы с недостатком обучающего набора данных для остальных моделей был использован перенос знаний [22, 24].
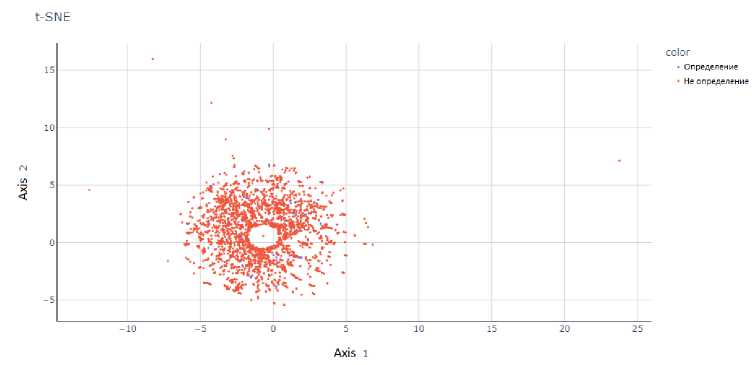
Рис. 2. Результаты работы t-SNE па векторных представлениях модели BOW при проекции па двумерную плоскость
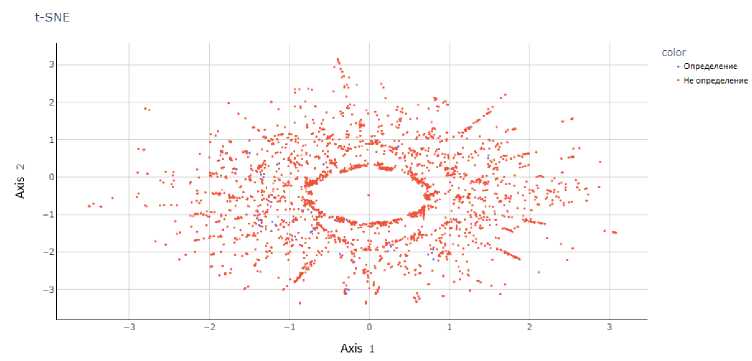
Рис. 3. Представление результатов работы t-SNE па модели TF-IDF при проекции па двумерную
плоскость
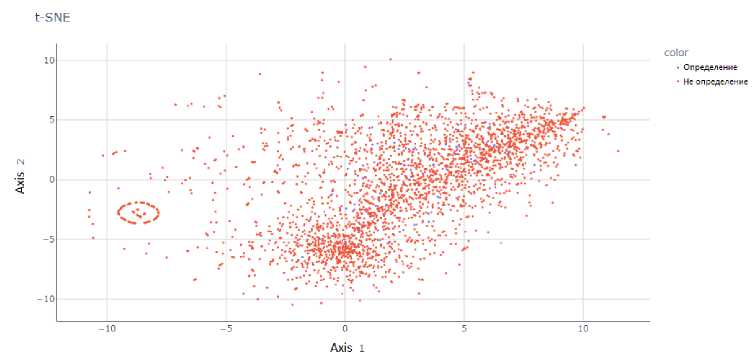
Рис. 4. Представление результатов работы t-SNE па модели Word2Vec при проекции па двумерную
плоскость
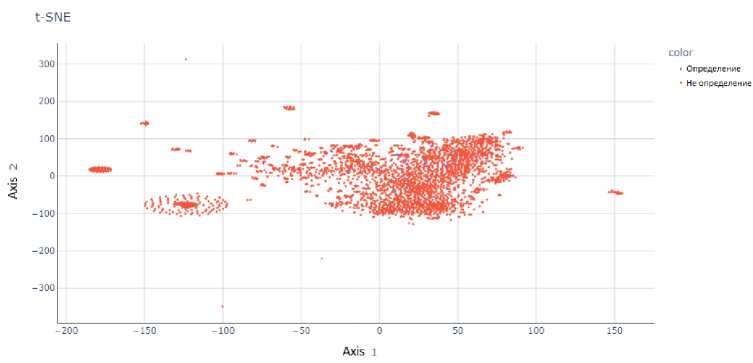
Рис. 5. Представление результатов работы t-SNE па модели GloVe при проекции па двумерную
плоскость
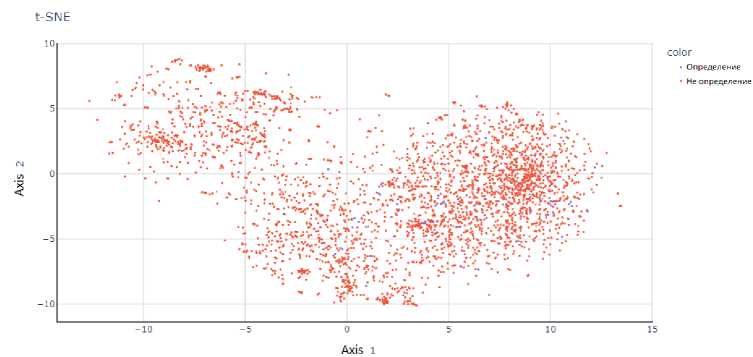
Рис. 6. Представление результатов работы t-SNE па модели Universal Sentence Encoder при проекции па двумерную плоскость
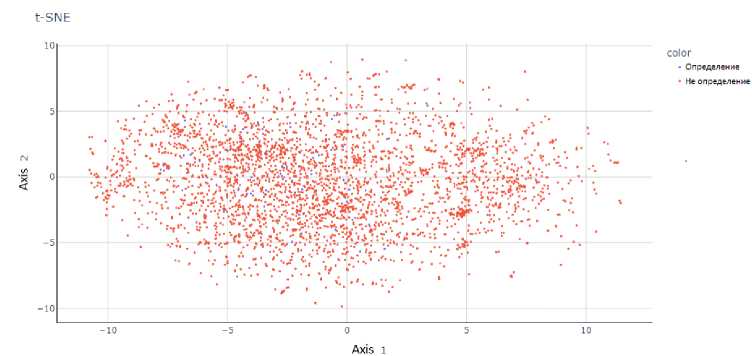
Рис. 7. Представление результатов работы t-SNE па модели BERT при проекции па двумерную плоскость t-SNE
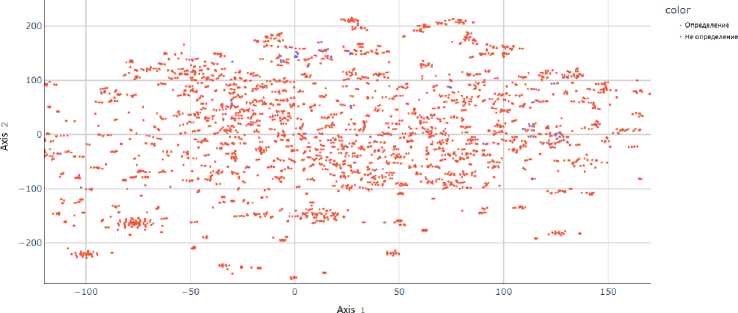
Рис. 8. Представление результатов работы t-SNE па модели MathBERT при проекции па двумерную плоскость
На рис. 2-8 представлены результаты работы t-SNE на векторных представлениях. Данные рисунки показывают, что метки классов четко не разделяются ни одним из предложенных векторных представлений, что делает затруднительным построение модели с хорошей обобщающей способностью.
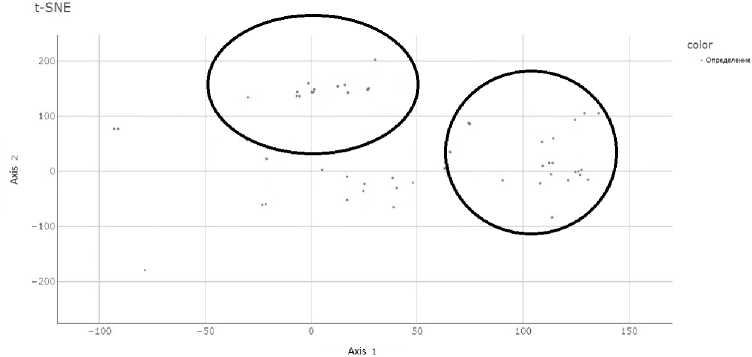
Рис. 9. Пример концентрации точек, полученных с помощью MathBERT при проекции па двумерную плоскость
На рис. 9 можно увидеть, что выделенные кругами места представляют собой наибольшие по сравнению с другими моделями скопления точек, полученные при использовании векторного представления модели MathBERT.
3.3. Построение классификатора
Ввиду несбалансированности классов в ходе работы были применены:
1. стратифицированная перекрестная проверка [24];
2. оценка качества по F 1-мере — с целью контроля качества по несбалансированным классам [22].
3. оценки качества через Accuracy — с целью контроля качества по всей выборке и оценке в паре вместе с Fl-мерой [22].
4. Выводы
Для предсказания использовался градиентный бустинг [25], а в качестве конкретной реализации был использован Xgboost [26]. Полносвязный слой был использован для модели MathBERT как классификатор на выходе с скрытого слоя [19]. Был произведен автоматический подбор гиперпараметров моделей градиентного бустинга (глубина деревьев, политика построения дерева, шаг обучения, количество деревьев, регуляризация и др.) с помощью фреймворка Optuna [27].
Таблица!
Результаты работы классификаторов
|
Векторное представление |
Модель классификатора |
F 1-мера |
Accuracy |
|
BOW |
Градиентный бустинг |
0.44259 |
0.97605 |
|
TF-IDF |
Градиентный бустинг |
0.36139 |
0.97314 |
|
Word2Vec |
Градиентный бустинг |
0.20350 |
0.97419 |
|
GloVe |
Градиентный бустинг |
0.26854 |
0.97644 |
|
USE |
Градиентный бустинг |
0.29525 |
0.95790 |
|
BERT |
Градиентный бустинг |
0.35244 |
0.97118 |
|
MathBERT |
Полносвязная нейронная сеть |
0.22522 |
0.93059 |
|
MathBERT |
Градиентный бустинг |
0.48798 |
0.97495 |
Лучшей моделью в сравнении, представленном в табл. 1, показала себя модель MathBERT вместе с градиентным бустингом, показав наивысшее качество получившихся результатов по Fl-мере (и одно из лучших по accuracy), худшей моделью по Е1-мере показала себя модель Word2Vec.
Рассмотренные визуализации на рис. 2-8 показали возможности применимости моделей векторных представлений для целевого домена математических текстов, а также общее качество разделения векторных представлений определений от остального текста. Представленные в табл. 1 результаты подтверждают исследования визуализации векторных представлений и показывают, что наибольшее качество получила модель MathBERT, натренированная на корпусе математических текстов. Это обосновывается тем, что механизм внимания данной модели наиболее приспособлен к различению отношений между математическими объектами, за счет домена-источника (корпуса математических документов). Из этого следует, что модели, обученные на обычных текстах в качестве домена-источника, плохо подходят для работы со специфическим форматом математических документов и набором текстов со служебной разметкой.
Из двух подходов к классификации более плохое качество на модели MathBERT получил классификатор из полносвязной нейронной сети по сравнению с моделью классификатора градиентного бустинга, что обуславливается малым набором данных, где для данной задачи градиентный бустинг показывает более высокие результаты.
Также можно увидеть, что достаточно высокое качество (2-е по ранжированию Fl-меры) показала модель BOW, что обосновывается общей разреженностью текста служебными словами и формульными вставками, где, благодаря неупорядоченности коллекций входящих в модель BOW и отсутсвием их нормировки (как в модели ТЕ-IDF), отдельные маркеры в тексте выражают более высокую степень значимости для классификатора, что отображает проблемы обработки домена и сложность работы с ним как с обычным естественным языком.
В качестве перспективных направлений для будущего исследования стоят задачи:
-
1. Дообучения MathBERT на математических статьях, заменяя формулы токеном, то есть дообучение на задаче маскирования текста, для получения более устойчивых и соответствующих задаче векторных представлений.
-
2. Увеличения объема существующего набора данных, для получения более статистически достоверных результатов.
Также с помощью вышеуказанных пунктов планируется развитие задачи классификации «определений» на предложениях в задачу извлечения именованных сущностей: определяемых понятий и символов, описывающих их.
Список литературы Классификация определений в математических latex статьях
- Ganesalingam M. The language of mathematics. Berlin, Heidelberg: Springer, 2013.
- Сайт LaTeX [Электронный ресурс]. Режим доступа: https://www.latex-project.org/
- Ohri A., Schmah T. Machine translation of mathematical text // IEEE Access. 2021. V. 9. P. 38078–38086.
- Berlioz L. ArGoT: A Glossary of Terms extracted from the arXiv // arXiv preprint arXiv:2109.02801. 2021.
- Feigenbaum E.A. [et al.]. Computers and thought. New York: McGraw-Hill, 1963. V. 7.
- Bobrow D. [et al.]. Natural language input for a computer problem solving system. 1964.
- Charniak E. Computer solution of calculus word problems // Proceedings of the 1st international joint conference on Artificial intelligence. 1969. P. 303–316.
- Meadows J., Freitas A. A survey in mathematical language processing // arXiv preprint arXiv:2205.15231. 2022.
- Berlioz L. WIP: Creating a Database of Definitions From Large Mathematical Corpora.
- Guidi F., Sacerdoti Coen C. A survey on retrieval of mathematical knowledge // Mathematics in Computer Science. 2016. V. 10, N 4. P. 409–427.
- Zanibbi R., Blostein D. Recognition and retrieval of mathematical expressions // International Journal on Document Analysis and Recognition (IJDAR). 2012. V. 15. P. 331–357.
- Sparck Jones K. A statistical interpretation of term specificity and its application in retrieval // Journal of documentation. 1972. V. 28, N 1. P. 11–21.
- Qaiser S., Ali R. Text mining: use of TF-IDF to examine the relevance of words to documents // International Journal of Computer Applications. 2018. V. 181, N 1. P. 25–29.
- Harris Z.S. Distributional structure // Word. 1954. V. 10, N 2–3. P. 146–162.
- Cer D. [et al.]. Universal sentence encoder // arXiv preprint arXiv:1803.11175. 2018.
- Devlin J. [et al.]. BERT: Pre-training of deep bidirectional transformers for language understanding // arXiv preprint arXiv:1810.04805. 2018.
- Peng S. [et al.]. Mathbert: A pre-trained model for mathematical formula understanding // arXiv preprint arXiv:2105.00377. 2021.
- Van der Maaten L., Hinton G. Visualizing data using t-SNE // Journal of machine learning research. 2008. V. 9, N 11.
- Vaswani A. [et al.]. Attention is all you need // Advances in neural information processing systems. 2017. V. 30.
- Iyyer M. [et al.]. Deep unordered composition rivals syntactic methods for text classification // Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th International joint conference on natural language processing. 2015. V. 1. P. 1681–1691.
- Cайт NTCIR-12 [Электронный ресурс]. Режим доступа: https://ntcirmath.nii.ac.jp/task-overview/
- Бенджио И., Гудфеллоу Я., Курвилль А. Глубокое обучение Москва: ДМК-Пресс, 2018.
- Cайт Brat [Электронный ресурс]. Режим доступа: https://brat.nlplab.org/
- Чару А. Нейронные сети и глубокое обучение: учебный курс Санкт-Петербург: ООО «Диалектика», 2020.
- Friedman J.H. Stochastic gradient boosting // Computational statistics & data analysis. 2002. V. 38, N 4. P. 367–378.
- Chen T., Guestrin C. Xgboost: A scalable tree boosting system // Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016. P. 785–794.
- Akiba T. [et al.]. Optuna: A next-generation hyperparameter optimization framework // Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019. P. 2623–2631.
