Lipstick color suggested using hybrid hidden Markov model

Author: Khatreja A., Mulay P.
Journal: Cardiometry @cardiometry
Section: Original research
Article in issue: 22, 2022.
Free access
In today’s lifestyle, facial makeup plays an important role in enhancing visual attractiveness a nd boosting one’s self-esteem. Makeup is known as the second skin of the women, and that too lipstick is a soul of the makeup. According to a survey, an average urban woman spends almost one year and three months of her life just wearing makeup. This much of the time is due to decision-making and choosing the best makeup style that would fit a particular age, skin complexion, profession, and occasion, requiring high imagination and full art. Many makeup recommendations systems exist, but no solitary system has existed to recommend a lipstick color properly to solve this problem computationally. Therefore, as a tiny step towards helping women save their time in decision-making, the proposed model puts forward an idea of a hybrid recommendation model for lipsticks alone. This proposed methodology uses a hidden Markov model to unleash the possible color of the lipsticks based on the given attributes. The collaborative filtering system catalyzes the process to recommend the best lipstick colors using a hybrid recommendation model.
Ybrid recommendation, hidden markov model, collaborative filtering, k-means clustering, shannon information gain
Short address: https://sciup.org/148324624
IDR: 148324624 | DOI: 10.18137/cardiometry.2022.22.421428
Text of the scientific article Lipstick color suggested using hybrid hidden Markov model
Aanchal Khatreja, Preeti Mulay. Lipstick color suggested using hybrid hidden Markov model. Cardiometry; Issue 22; May 2022; p. 421-428; DOI: 10.18137/cardiome-try.2022.22.421428; Available from: http://www.cardiometry. net/issues/no22-may-2022/lipstick_color_suggested_using
With the advent of new technologies, it is easier to get suggestions about various aspects ranging from which book to buy (Amazon), which movie is must go
(Book My Show), which stocks to invest in, and the list is endless. Such recommendations are feasible using a combination of machine learning algorithms.
For the impressive presentations during various events, including professional meetings, attending conferences, welcoming guests, and everyday chores, the focus is more on facial expressions, looks, and overall makeup/appearance of the person [1]. According to an Indian newspaper known as Indian mirror, it recorded sales of INR356.6 billion in 2009 for the cosmetic industry, despite the global recession. Studies also show that applying makeup enhances one’s visual attractiveness; it also positively affects the self-esteem of a person, as it gives a younger look and according to the ongoing trends.
With such a humungous variety in makeup styles and products, it is a huge task to choose a particular makeup style or product that will fit a certain face for a specific occasion. Hence, there have been many makeup recommendation systems that have been developed. Still, this hybrid recommendation system focuses solely on lipstick color, recommended by the system by considering attributes such as user’s age, skin complexion, his/her profession, and the occasion/ event to be attended [2].
This research aims to apply machine-learning concepts for recommending apt lipstick(s) based on gender, age, profession, and event. Hence, we propose an Adaptive Hybrid Lipstick Recommendation System, which achieves the following two things and they are: 1) A new data set is built by surveying the usage of lipsticks among women of different ages and professions. This data set also includes the occasion\ event, for which a particular woman is wearing a certain lipstick.
-
2 ) A fully automatic hybrid recommendation system using collaborative filtering and further using Hidden Markov Model (HMM).
The proposed Lipstick recommendation system consists of three main steps:
-
1) Automatic attributes classification of the dataset.
-
2) Performing clustering for the attributes using K-means
-
3) Hybrid recommendation system, which uses collaborative filtering and hidden Markov Model (HMM). K-means also called Lloyd’s algorithm, is one of the pioneered algorithms used widely to resolve the clus-
- tering issue in a very efficient and simple way [3]. The method to apply k-means is to categorize a provided data set into clusters. Individual K-centers are formed for each cluster and intelligently and smartly because different places generate a different result. So, for best results, centers are placed as far as possible from each other. The next procedure is to associate every point that belongs to a given dataset to the nearby center. After completing all the points, we need further calculation of k-new cancroids, and once again, a fresh binding takes place between the nearest new center and the same data set points [4]. A loop is created because k-centers change their location frequently step-by-step until there is no scope for further change. Algorithmic steps fork-means are:
Let Y= {y1,y2,y3,y4…………………….,yn} be the data point set and J={j1,j2,j, jn} is the center sets.
-
1. Select centers cluster randomly.
-
2. Find Euclidean distance for every data point and cluster center.
-
3. Then appoint the data point associate with provided dataset to the minimum distance cluster center.
-
4. Recalculate the value of the new cluster center and distance amongst every data point and freshly formed cluster center till no data center will remain too reassigned.
There are many advantages of using k-means as fast and simple to understand, more efficient, and better results when data sets are distinct from each other. It has been widely used in a market segment, geo statistics, computer vision, etc.
The Hidden Markov Model (HMM) is a finite statistical set of states, where each set is associated with the probability distribution. The system in HMM being modeled is pretended as a Markov process with invisible states. Transition probabilities direct transition among states. The Dynamic Bayesian Network is the simplest representation of the HMM model [5]. In HMM model, the latent variable is selected for every observation and connected through a Markov process. Currently, HMM is generalized as triplet Markov models and Markov models to permit a more complicated data structure. HMM is used in temporal pattern recognition, gesture recognition, reinforcement learning, handwritten, bioinformatics, etc.
Collaborative Filtering (CF), also known as social filtering, has been the method most frequently used in recommender systems [6], as it filters out the information or recommends the data to the users by
422 | Cardiometry | Issue 22. May 2022
using the information that has been recommended to the past users. Narrow and general are the two senses of CF. The method used in narrower senses CF is to automatically collect users’ interests by collecting taste information or preferences of lots of users. In general, sense CF, the information using a method for filtering process involving viewpoints, multiple agents, collaborations, data sources, etc. The collaborative filtering technique is used for various types of data like mineral exploration [7], monitoring, sensing data, financial data, multiple sensors, web applications, electronic commerce, etc. There are various forms of CF, but many systems used two steps:
-
i. Find out the users whose rating patterns are the same as active users.
-
ii. Calculate active user prediction by using ratings of the same thinking users.
These steps are commonly followed in user-based collaborative filtering. In item-based collaborative filtering, the steps used are:
-
i. Formed an item-item matrix and find out the relations amongst item pairs.
-
ii. By studying the matrix and comparing it with user data, infer the current user taste.
The collaborative filtering types are memory-based, model-based, and hybrid [8]. The memory-based CF technique used the rating data of users and calculated the similarity between items or users. Model-based CF technique developed the model by utilizing different machine learning, data mining algorithms to determine the unrated items and user rating. The hybrid CF technique combines the model-based and memory-based CF method or algorithms. Many problems arise using collaborative filtering techniques, like Data scarcity, Scalability, shilling attacks, Gray sheep, etc. This paper has been classified for literature survey under section 2, and section 3 is dedicated to a detailed narration of our proposed model. In contrast, section 4 is dedicated to the Comparative Analysis of our model, and finally, section 5 concludes the paper with its future enhancement scope [9].
-
2 Literature survey
A smart facial makeup recommendation and combination system was proposed by Taleb Alash-kar et al. They categorize the makeup connected facial attributes that makeup artists acknowledge to choose the makeup style. A deep neural network was proposed by Taleb et al. by considering a proper en- hanced makeup recommendation system. The whole structure of the proposed system contains three stages. The first stage categorizes makeup-based facial attributes into organized coding. The second stage uses these facial attributes as examples rules to supervise the deep neural recommendation model, which combines makeup artist knowledge and pairs of before-after images jointly. Finally, an enhanced makeup combining system is made to visualize the makeup style of the recommendation system [10]. A manually labeled facial makeup database of before and after the image is created. The knowledge base system also forms the idea of the makeup artist. They evaluated the whole system performance through different experimental analyses.
Madeleine presented women’s behavior behind lipstick use, O. et al. They found out that the women used lipstick to transform their looks and present themselves. Still, the choice of lipstick depends on their identity and moods [11]. They collected the data of one geographical area. Most of their data belonged to western Australian society. They found out that most women used their self-strategies for the use of lipstick. The result shows that lipstick uses plays an important role in understanding and constructing women’s self-identity and appearance in their daily lives.
As presented by Don R., human intention is an important key factor in deciding the self-presentation technique. The personal presentation skill is the important practices on beauty judgment. A self-regulating makeup recommendation system was presented by Taleb Alashkar et al. that depend on a deep neural network, which jointly considers examples and information-based rules [12]. They display the ability of their system to recommend a similar type of makeup style, which fits on the face, according to mechanized categorical facial attributes. They also make before and after makeup databases. They evaluate their system performance through numerous experimental researches. Their research authenticates mechanized facial attributes categorization, the effectiveness of their recommendation system on statistical technique [13].
A k-mean clustering-based recommendation system was proposed by Young S. et al. They categorize items depending upon the RFM technique to learn the attribute of the ordered item to fetch out the item with the highest possibility to purchase. They used an implicit technique to minimize the intricacy of the QA method. To validate their system performance, they make a database of internet-based cosmetic shopping malls and do experiments with that data [14].
A system was designed by Cunjian Chen et al. to recognize the makeup presents in facial images. They proposed an algorithm that detects a feature vector that finds the color, texture, and shapes of input images, and then a classifier is used to decide the presence or absence of makeup on the face. They use two databases, which contain unconstrained faces. The output is then preprocessed to recognize faces with makeup and no makeup images.
A mechanized structure was presented by Lin Xu et al., which implements a cosmetic makeup and enhancement to a given face [15]. Their system first detects the important landmarks of giving face using the previous algorithm and then uses the Gaussian Mixture Model to adjust the skin color with landmarks. They categorize the skin color into three layers, and makeup is applied in different layers using distinctive methods. The results of their system show the improved effect on input faces.
A movie recommendation system was proposed by Manoj Kumar et al. depending on the collaborative filtering technique. The given system analyzes the information given by the end users and then refers the movies to the users according to the time [16].
A two-stage algorithm was developed by Sukhpreet D. et al. by combining fuzzy k-means and self-organizing maps with an enhanced distance function to categorize users into a cluster. The results of their algorithm provide a better precision to identify clusters of related users. A technique was presented by Dong-Moon Kim et al. to provide personalized music service, according to users. They used Shortest Time Fourier Form (STFT) to analyze the quality of music by extracting music sound waves. They used k-means clustering to make clusters of music lists dynamically. They also use the speed division technique to increase the recommendation system’s speed and handle huge music data. Wu Xiaoyong et al., a TSA model, was presented, which relies upon HMM to examine the target’s movement on the sea [17].
Pavel Paramonov introduced the fastest algorithm to recognize the isolated words, which depend on the HMM static allocation. The computational intricacy of the fast algorithm is linear. The proposed algorithm also requires minimum memory for the storage of model parameters compared to DNN and HMM-GMM models. TIMIT random database is used to compute the feasibility of the algorithm. A novel recommendation algorithm CR-IIA was presented by Pengfei He et al., which is a combination of association rule mining and matrix factorization. Their technique used item correlation to search the latent correlation between items provided by association rule mining. They integrate the item correlations with a PMF model to enhance item feature vectors. Item correlation factors improve rating prediction and make it perfect and realistic [18]. The comparison of their algorithm with context-based model and social trust model prove that the accuracy of rating prediction is improved by using their approach without provoking data scarcity problem due to extra information. Their structure also permits extra dimensionality to be treated simultaneously.
A multi-task matrix factorization method was proposed by Wanlu et al. by integrating rating data with user feedback. They proved the enhancement in predictive accuracy in comparison to biased MF algorithm and SVD++. They utilize the feature space of the common user and concurrently train the whole matrix factorization task. Their experiment shows that fresh user feedback works great and shows enhancement on predictive accuracy about state-of-the-art algorithms [19].
A novel social recommender was introduced by Junliang Yu et al. depending on the idea of likeability due to distance. The proposed model combined the distance metric learning and factorization model to understand the latent factor space and positioning of items and users inside the space. They mapped the items and users into undivided low-dimensional space. The items and user position in space are determined jointly by social relations and ratings; it helps determine the appropriate location of users with fewer ratings. Finally, reliable and understandable recommendations are generated by using positions and learned metrics. A personalized recommendation method was introduced by Shan Liu et al. for the news system. They also enhance the Pearson correlation sufficient formula by combing the hot factory to minimize the popular item’s importance to recognize the similar users [20].
-
3 Proposed methodologies
The proposed system of the Adaptive recommendation model for lipsticks using the hidden Markov model (AHH) can be narrated using the steps mentioned below and the overview diagram depicted in Figure 1.
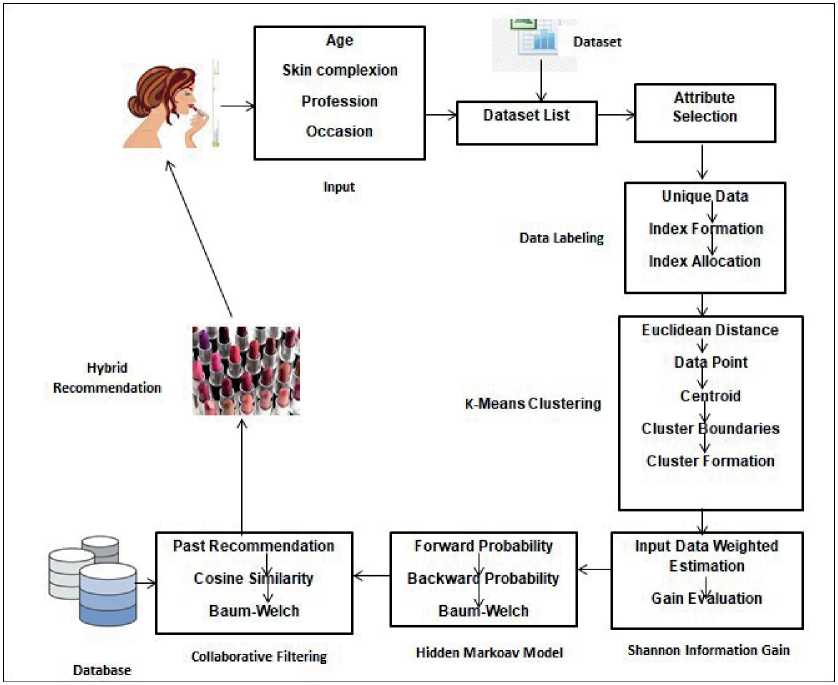
Fig. 1. System overview diagram of the proposed hybrid lipstick recommendation system
Step 1: Dataset Survey - This is the primitive step of our system, where AHH conducts a survey on women about lipsticks by hosting a Google survey web page form. It collects survey data from all the women belonging to different professions.
Here survey asks some primitive and simple questions to women like
-
• What is your date of birth?
-
• What is your skin complexion?
-
• What is your profession?
-
• How often do you use/ apply lipstick (Not lipgloss)?
-
• When/where do you usually apply lipstick?
-
• What shade(s) of lipstick would you prefer to wear for an official meeting/job interview?
-
• What shade(s) of lipstick would you prefer to wear for a “casual-day” hangout?
-
• What shade(s) of lipstick would you prefer to wear for a “club/lounge”?
-
• What shade(s) of lipstick would you prefer to wear for a regular day at “school/college/office”?
After collecting all the data, it has been stored in the workbook as a dataset to further the system’s processing.
Step 2: User Input - Once the Dataset is gathered and ready for the process, AHH asks for some inputs from the user who seeks recommendations for lipsticks through the interactive and simple user interface. The system asks for some input like Age, Skin Complexion, Profession, and occasion, for which lipstick needed to be worn by the user. Once the system gathers input from the user, AHH reads the workbook dataset stored in a predefined path with the help of a third-party API, like JXL, into the double dimension list.
Step 3: Preprocessing and Labeling - Once the user input is received, it is statically stored for the instance recommendation, and the double dimension list of the dataset is subjected to preprocessing, where predefined attribute column data is selected for the further process of recommendation.
Then the data is being iteratively segmented into the data points till all data belongs to each cluster for recursively evaluated cancroids. Therefore, this takes much time to perform the clusters on multidimensional data.
Whereas in the proposed model of AHH, average normalized Euclidean distance is being evaluated for each row, and then a mean Euclidean distance is calculated for all the rows. Once the mean Euclidean distance is evaluated, fixed data points are identified based on the random percentage. Each data point of centered is subjected to find the cluster boundary, as shown in equation 2. Then each row is added into the respective cluster, which has Euclidean distance in between the evaluated boundary. This process of K-means cluster decreases the time complexity and gives a proper cluster of the data.
Ed = V (x 1 - x 2)2 + (y 1 — y 2)2 (1), minb= Dpi – Ed maxb = Dpi + Ed (2)
Where
Ed = Euclidean Distance Dpi = Data Point
Minb = Minimum Boundary Range
Maxb = Maximum Boundary Range
Step 5: Entropy Evaluation – to know the distribution of the attributes like age, skin complexion, profession, and occasion in different clusters, entropy estimation is the best way. Once the clusters are formed, then the input data like age, skin complexion, occasion, and profession from the user are also labeled with the same protocol as of dataset. Then each of these input labeled data is evaluated for the entropy in each cluster using Shannon information gain as shown in equation 3. By evaluating this entropy, and information gain value is acquired, which is between 0 and 1. Any value nearer to 1 indicates the importance of the attribute for which it is being evaluated. Then, each cluster yields a single entropy value that is eventually the summation of all the information gain from the input data. Then the cluster with the highest info gain value is selected for further process.
IG (E) = - (P I T) log (P I T) - (N I T) log (N I T), (3)
Where
P= Frequency of the present count N= Non presence count
T= Cluster Elements Size.
IG (E) = Information Gain for the given Entity
Step 6: Hidden Markov Model (HMM) - HMM involves three different parts to obtain a recommendation’s hidden probability of color.
|
и= E^ n |
(4) |
|
5 = A E ( Edi -^2 Nt1 |
(5) |
|
f ( F p ) = ц- 5 — ц + 5 |
(6) |
|
f ( B p ) =< ц -5 —> ц + 5 |
(7) |
Where
δ – Standard Deviation
μ – Mean
Edi – Euclidean distance of instance row N- Number of Rows in the cluster f (Fp) – Forward Probability Function f(Bp) - Backward Probability Function
Baum Welch – The size estimation between the backward and forward probability data is evaluated to consider the bigger list as the probability list. And then, this probability list is subjected to a transition matrix process to evaluate the probable Recommendation List based on the following “algorithm 1”.
ALGORITHM 1: Baum -Welch
// Input: Probability List PL
// User Input List UL
// Output: Probability Color (PL, UL)
-
1: Start.
-
2: count=0, PRL = Ø
[PRL= Probable Recommendation List]
-
3: For i = 0 to size of PL // FOR LOOP TO THE SELECTED CLUSTER IN BETWEEN FP AND BP thatis PL
-
4: TSET =PLi // GET A ROW FROM A PL SET ASTSET
[TSET = Temporary Set]
-
5: For j=0 to size of TSET // RUN A FOR LOOP FOR THE ROW ATTRIBUTES OFTSET
-
6: If (TSET[j] ==UL[j] ) // MATCH TSET ATTRIBUTES WITH THE INPUT USER SETUL
-
7: count++; // COUNT IFMATCHED
-
8: End for
-
9: If (count>=T) [T: Threshold] // IF COUNT IS GREATER THAN THE THRESHOLD
-
10: ADD TSET to PRL // THEN ADD THE ROW COLOR AS PROBABILITY RECOMMENDATION COLOR INPRL
-
11: End for
-
12: R eturn PRL // RETURN THEPRL
Step 7: Collaborative Filtering - Each of the entities of the probable recommendation list obtained from the Baum-Welch Algorithm is subjected to measure the Cosine Similarity between the past recommendations in the database using Equation 8.
Where
PRL is probable Recommendation List DB is the Database List
Cos (PRL, DB) is the Cosine Similarity
So, all the probable Recommendation List (PRL) entities that have passed the minimum Threshold Set by AHH are selected for the recommendation. Then, finally, colors of the selected lists are gathered and displayed as the recommended lipstick colors to the user for the given input through the designed interface.
4 Results and discussions
A. Evaluation of accuracy
The proposed model is evaluated for the accuracy of the recommended results over the user’s ratings to analyze the performance of the hybrid recommendation system. A score is being awarded for the provided recommendation of the lipstick concerning the given input of age, profession, and occasion, and skin complexion by the user. If the score provided by the user is greater than 0, then it is considered as likes. If the score is less than 0, it is considered as dislike, and then the accuracy can be evaluated with the following equation 3:
Currect member of Predictions
(Ra) = ~--~--7---7--------X 100 Total Number of attempts
Where
Ra= Recommendation Accuracy
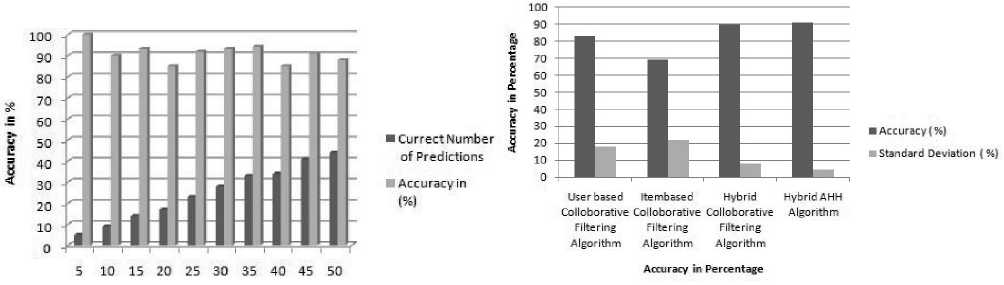
On applying this equation for different trials, our experiment yields the following results as tabulated in Table 1.
The plot in Figure 2 indicates that the proposed methodology of the Hybrid AHH recommendation system for lipstick dataset yields approximately 91.2% of accuracy, and the above plot also shows that as the number of attempts increases, the result of accuracy also remains steady and consistent, which is mainly due to the semi-supervised model that is incorporated with the help of Hidden Markov model.
Table 1
Accuracy of the AHH model
|
No of Attempts |
Correct Number of Predictions |
Accuracy (%) |
|
5 |
5 |
100 |
|
10 |
9 |
90 |
|
15 |
14 |
93.33 |
|
20 |
17 |
85 |
|
25 |
23 |
92 |
|
30 |
28 |
93.33 |
|
35 |
33 |
94.28 |
|
40 |
34 |
85 |
|
45 |
41 |
91.11 |
|
50 |
44 |
88 |
Table 2
Overall statistics on accuracy and standard deviation of differ- ent algorithms
|
[1] Category of Algorithms |
Accuracy (in %) |
Standard Deviation (in %) |
|
83.12 |
18.1 |
|
[4] Item-based Collaborative Filtering Algorithm |
69.19 |
21.52 |
|
[5] Hybrid Collaborative Filtering Algorithm |
89.85 |
7.6 |
|
[6] Hybrid AHH Algorithm |
91.2 |
4.3 |
No of Attempts
Fig. 3. AHH performance comparison with other methodologies
Fig. 2. Accuracy evaluation of the hybrid recommendation system of AHH
The collaborative filtering technique, which uses the past and the present results to provide the adaptive recommendation model, also kept growing as the number of attempts is being made to get the recommendation, which is a good sign for further evaluation of the model.
Comparison of accuracy
The obtained accuracy from the above plot in Figure 2 is used to compare with the accuracy of the other methodologies mentioned in Shan Liu et al. The obtained results of the other methodologies and the hybrid recommendation model of AHH are tabulated in Table 2.
The plot in Figure 3 indicates that the accuracy and standard deviation of the hybrid AHH recommendation system are better than that of all the remaining methodologies of Shan Liu et al., which works on hybrid recommendation model for news recommendation technique based on the user sparse data, whose accuracy is little lagging than that of the proposed model of AHH hybrid recommendation, which is mainly because of the proposed model of Shan Liu et al. uses the Pearson correlation equation to measure the similarity to provide a recommendation. This kind of recommendation model relies only on past data. Here methodologies are improved only to measure the relation between the current given query and the past recommendation data. In contrast, the proposed model AHH efficiently performs the semi-supervised learning model using machine-learning techniques of the Hidden Markov model. Along with this, AHH uses a collaborative filtering technique, which uses the cosine similarity method to measure the similarity of the past data, which excellently blends with the HMM model, which eventually increases the proposed model’s efficiency in the system proposed by Shan Liu et al.
-
5 Conclusions
The proposed model of AHH efficiently provides the hybrid lipstick recommendation for the given query by the user. This paper narrated all the techniques involved in providing the lipstick recommendation by using collaborative filtering, which is finely blended with the Hidden Markov model technique. The dataset is collected over the Google survey farm page, which authenticates the data quality even more. A comparison of the proposed model of AHH reveals that using a semi-supervised learning technique enhances the performance of the hybrid recommendation model compared to other methodologies discussed in the prior step.
As the future scope proposed model can be enhanced to work in efficient web paradigm and mobile applications, live lipstick recommendations to the women in ongoing shopping or the makeup process to save time and enrich their beauty. There can also be an addition of opinions and suggestions to the application from popular and prominent makeup artists. The professionals can enter their suggestions right through the app in a separate panel for addition to the recommendation. There will also be a panel with the latest trends that have been popular in recent TV shows and movies and the colors inspired by the actors depicted in them.
Statement on ethical issues
Research involving people and/or animals is in full compliance with current national and international ethical standards.
Conflict of interest
None declared.
Author contributions
The authors read the ICMJE criteria for authorship and approved the final manuscript.
References Lipstick color suggested using hybrid hidden Markov model
- Taleb Alashkar, Songyao Jiang, Rule-Based Facial Makeup Recommendation System, (2017)
- Shuyang Wang, Examples - Rules Guided Deep Neural Network for Makeup Recommendation, AAAI Conference on Artificial Intelligence, (2017)
- Madeleine Ogilvie, Maria Ryan, Lipstick: More than a Fashion Trend, Research Journal of Social Science, and Management, 1, 6, 117-128, (2011)
- Don R. Osborn, Beauty is as Beauty Does. Makeup and Posture Effects on Physical Attractiveness Judgments, Journal of Applied Social Psychology, (1996)
- Young Sung Cho1, Song Chul Moon, Si Choon Noh, Keun Ho Ryu, Implementation of Personalized Recommendation System using k-means Clustering of Item Category based on RFM,
- Cunjian Chen, Antitza Dantcheva, Arun Ross, Automatic Facial Makeup Detection with Application in Face Recognition, (2013)
- Lin Xu, Yangzhou Du, Yimin Zhang, An Automatic Framework For Example-Based Virtual Makeup, (2013)
- Manoj Kumar, D.K. Yadav, Ankur Singh, Vijay Kr. Gupta, A Movie Recommender System, (2015)
- Phongsavanh, Phorasim, Lasheng Yu, Movies recommendation system using collaborative filtering and k-means, 2249-7277, (2017)
- Sukhpreet Dhaliwal, et al. Integrating SOM and Fuzzy K-means Clustering for Customer Classification in Personalized Recommendation System for Non-Text based Transactional Data, NIST Special Publication ICIT, (2017)
- Dong-Moon et al. Recommendation System with a Dynamic K-means Clustering Algorithm, (2017)
- J. Wu Xiaoyong, ING Tao, LIU Lei, The Research Of Target Situation Assessment Based On HMM, 978-1-4244, (2010)
- Pavel Paramonov, Fast Algorithm for Isolated Words Recognition Based on Hidden Markov Model, Stationary Distribution, (2017)
- Pengfei He, Collaborative Recommendation Algorithm Based on Implicit Item Associations, (2007)
- Nurudeen Sherif, Filtering Using Probabilistic Matrix Factorization and a Bayesian Nonparametric Model, (2017)
- Wanlu Shi, Tun Lu, Dongsheng Li, Peng Zhang, Ning Gu, Multi-Task Matrix Factorization for Collaborative Filtering, 978-1-5090-6199-0/17, IEEE, 2017.
- Junliang Yu, A Social Recommender Based on Factorization and Distance Metric Learning, 2169-3536, (2017)
- Shan Liu, Research of Personalized News Recommendation System Based on Hybrid Collaborative Filtering Algorithm, (2016)
- Limei Sun, A Time-sensitive Collaborative Filtering Model in Recommendation Systems, (2016)
- Jianping Chai, Research of Personalized News Recommendation System Based on Hybrid Collaborative Filtering Algorithm, (2016).
