Machine Learning in Cyberbullying Detection from Social-Media Image or Screenshot with Optical Character Recognition

Author: Tofayet Sultan, Nusrat Jahan, Ritu Basak, Mohammed Shaheen Alam Jony, Rashidul Hasan Nabil
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 2 vol.15, 2023.
Free access
Along with the growth of the Internet, social media usage has drastically expanded. As people share their opinions and ideas more frequently on the Internet and through various social media platforms, there has been a notable rise in the number of consumer phrases that contain sentiment data. According to reports, cyberbullying frequently leads to severe emotional and physical suffering, especially in women and young children. In certain instances, it has even been reported that sufferers attempt suicide. The bully may occasionally attempt to destroy any proof they believe to be on their side. Even if the victim gets the evidence, it will still be a long time before they get justice at that point. This work used OCR, NLP, and machine learning to detect cyberbullying in photos in order to design and execute a practical method to recognize cyberbullying from images. Eight classifier techniques are used to compare the accuracy of these algorithms against the BoW Model and the TF-IDF, two key features. These classifiers are used to understand and recognize bullying behaviors. Based on testing the suggested method on the cyberbullying dataset, it was shown that linear SVC after OCR and logistic regression perform better and achieve the best accuracy of 96 percent. This study aid in providing a good outline that shapes the methods for detecting online bullying from a screenshot with design and implementation details.
Cyberbullying Detection, Data Mining, Machine Learning, NLP, OCR
Short address: https://sciup.org/15018988
IDR: 15018988 | DOI: 10.5815/ijisa.2023.02.01
Text of the scientific article Machine Learning in Cyberbullying Detection from Social-Media Image or Screenshot with Optical Character Recognition
Published Online on April 8, 2023 by MECS Press
Cyberbullying and rumors, particularly, have become a significant issue as the popularity of the Internet and social media grew. Cyberbullying is defined as using ICT infrastructure by anybody to shame or humiliate another individual or group of persons which may take several forms. [1]. It is now a severe national health issue, with sufferers having a much higher risk of suicidal thoughts. It was only a matter of time after the Internet's growth that bullies began to utilize this new and popular medium. Cyberbullying makes the sufferer feel as though he is being attacked from all sides because the internet world is merely a click away.
Even if the Internet is secure for users, its flexibility may lead to problems like cyberbullying, which has lately been identified as a public health concern [2]. As a result, it is crucial to explore the problem roots of cyberbullying. A system might distinguish between bullying and non-bullying messages and take appropriate action [3]. Because of the detrimental impact cyberbullying has on victims, detection and prevention are crucial. Many cyberbullying detection technologies have been developed to aid in the management and reduction of cyberbullying. Researchers working on cyberbullying detection have progressed, but many difficulties remain unresolved. Detecting cyberbullying in a photograph or screenshot is one of them. The phrase "Sentiment Analysis" (SA) refers to a technique for determining one's views in written language. People's frequent expressing of thoughts on social, economic, health, and product and brand concerns and the fact that social media is such an essential tool for people has paved the way for sentiment analysis [4]. Data mining and text mining are currently popular [5]. The most popular technique to categorize literature using SA is to seek the writer's point of view on a particular topic [6].
With the use of this study, we will be able to identify occurrences of cyberbullying from a snap across social media platforms. Our goal is to examine every potential sub-domain that is connected to the detection of cyberbullying so that we may develop a method that has a greater level of acceptance than any other now available. In order to do this, the first obstacle we face is extracting text from images, which requires us to find a system that has the least amount of complexity possible. The obtained text will be processed. Then, we will investigate every relevant sub-domain associated with the detection of cyberbullying. When the time finally comes, we will conduct an analysis and make any necessary adjustments to the procedure. Previous research in this area has had limited success, so our hopes are high for this one.
2. Related Works 2.1. Background Study
Cyberbullying has been studied from several contexts and viewpoints; this is why various definitions have been proposed. Because of these different viewpoints, we need to prevent this problem from different contexts as much as possible. Teenage to older, everyone is the victim of this harassment as it is a common problem on social media and other platforms. For these reasons, the detection of cyberbullying using machine learning or other algorithms has been done by many researchers and has been happening for years [7]. But eradicating online bullying is an ongoing activity, methods need to be routinely updated from different views to take into account the most recent developments [8].
2.2. Image to Text
2.3. Text Processing & Classification
3. Dataset
4. Methodology
Deep learning has a variety of useful applications, one of which is optical character recognition. This work [9] describes the technique for partitioning text from character pictures, which may include visuals and computer-typed or handwritten words. The suggested character identification and extraction approach achieve encouraging results, demonstrating its resilience. A text extraction pipeline is described in this study [10] to address text extraction from varying quality photos obtained from social media. They collected datasets from 4 categories of images from social media. Several preprocessing techniques were included with Tesseract OCR to improve the accuracy of OCR. Using textual, visual, and infographic social data modalities, this paper [11] provides a deep neural network for cyberbullying detection. There infographic material separated from the image using Google Lens of the Google Photos App. There are many types of OCR: Keras-OCR, EasyOCR and Tesseract. In contrast to other libraries, the easyOCR library is extremely straightforward and lightweight to use [12]. It provides support for a variety of languages. It is also possible to improve its performance for particular use cases by adjusting the values of various hyper – parameters. When used to well-organized texts such as pdf files, receipts, and bills, it produces more accurate results though.
According to a publication, they are extended a list of post-offensive phrases and assigned various strengths to create abuse components, which are then combined with Bag-of-Words and latent word meanings to produce the final form before passing them into a linear SVM Classification algorithm [13]. They proposed Encoding -enhanced Bag-of-Words, a novel representation learning approach for hate speech detection that is both simple and effective. In all evaluation metrics, their proposed method surpasses other compared methods. The suggested approach in this article [14] is used to identify harmful online interactions, such as abusive content spread through text and graphics. The proposed strategy uses Convolutional Neural Network and Bag of Words algorithms along with the current method to identify cyberbully images and text on the Instagram dataset. Islam et al. [15] reported that another model named TF-IDF outperforms bag of words feature when they analyzed it for four machine learning algorithms.
In a recent study, a suggestion for recognizing cyberbullying is made based on the fact that text message usage, settings, and language have changed over time. Sentiment analysis, in addition to conventional feature extraction techniques like TF-IDF, N-gram, and profanity, increases the system's accuracy. Information was given by over 20,000 students. The suggested method fails to identify the ironic component of cyberbullying. The suggested response has an F1 score of 74%, accuracy of 74.50%, precision of 74% and recall of 74% [16]. Alam et al. use two alternative feature extraction algorithms in conjunction with numerous n-gram analyses to demonstrate four machine learning classifiers and three ensemble models using Twitter data. Their suggested SLE and DLE models achieve 96% effectiveness when TFIDF feature extraction is combined with K-Fold cross-validation [17]. With an average accuracy of about 90.57%, the test findings in this study indicate that LR is better. SGD had the greatest precision (0.968), SVM had the highest recall (0.928), and logistic regression had the highest F1 score among the classifiers (1.00). The tests shown that LR outperforms other classifiers in terms of prediction time and improves with increasing data volume. As a consequence, SGD performs almost as well as LR, while the error is not as tiny [18]. This study's recommended approach achieved 90.3% accuracy using SVM with 4 grams and 92.8% accuracy using Neural Network with 3 grams while applying both TFIDF and sentiment classification. Their Neural Network greatly outperformed the SVM classifier, with a mean f-score of 91.9% compared to the SVM's 89.8% [19].
The authors of this article [20] aims to compare the predicting models for fundamental machine learning in cyberbullying detection and the suggested systems with participation techniques for feature selection, resampling, and utilizing two classifiers: Support Vector Machine (SVM) and Decision Tree for optimization. N-gram characteristics from the ASKfm corpus were used in word extraction and then applied to eight different experiment setups. The best performance is provided by Decision Tree, according to an analysis of performance metrics. Kumar et al. [21] used Sequential Machine Optimization, Random Forest, K-Nearest Neighbor and Naive Bayes. The data was provided from YouTube. They obtained data from 7962 comments on 60 YouTube videos, an average of 116 per video. The researchers discovered that when applied to Clips on YouTube for online bullying identification, K-Nearest Neighbor had the greatest accuracy of 83 percent, outperforming all other approaches. It has been shown in a published approach that Neural Networks outperform SVMs and achieve an efficiency of 92.8 percent, while SVMs achieve an efficiency of 90.3 percent [22]. A research paper by authors [23] described their works using deep learning for cyberbullying detection where they used several classifications with CNN-CB Architecture, and as a result, SVM gave 81% accuracy. Despite the methods and features to detect cyberbullying, researchers also used some other classifiers in different way.
From previous study’s we have seen easyocr which can be used to get the efficient outcome for image to text extraction and for processing extracted text we are going to use two of the mentioned NLP technique which are Bag of words & TF-IDF [12, 15]. Besides, some of the followed effective text classification strategies we got which are Logistic Regression, Decision Tree, Random Forest classifier, SGD classifier and Linear SVC [17,18,23]. There are a variety of flaws in the research being done to identify cyberbullying using various machine learning techniques. Now it can be said that many platforms have tried to solve this issue automatically; then again, many countries have to take action manually, yet if the issue is significant, it takes time. That’s why an expert system that has the ability to detect cyberbullying from snap with design and implementation details is proposing by us with other existing methods to give better precision and grouping. We should check each possible combination of every step to get the best combination for cyberbullying detection from snap for this reason we will employ not only the regular classifiers but also some other classifiers which may out performs the usual techniques. More specific about our suggested approach for detecting cyberbullying are found in the methodology section.
We used a Kaggle dataset1 on online bullying and toxicity that was gathered by the authors Fatma Elsafoury. Several datasets relevant to the automated detection of cyberbullying are collected in this info, which comes from a wide range of sources. A variety of social media sources were used to access the data, including Kaggle, Twitter, Wikipedia Talk pages, and YouTube. There is text in the dataset that has been classified as cyberbullying and text that has not been classified as bullying. In the statistics, there are numerous types of online bullying. From there, we utilized a dataset that had around 160000 instances that were associated with toxicity. There is text in the data that has been classified as bullying and text which has not been classified as bullying. We will implement the system for cyberbullying detection where we require the collected dataset to build a machine learning model for classification in Jupyter Notebook, an open-source software we planned to implement.
We followed the diagram's stages here as research workflow in fig 1. We started by previously collected data from social media networks. After that, we preprocessed the dataset because it included some redundant components that could cause errors later. Then, we extracted the feature using the Bag of words model and the TF-IDF model. These features are used to train the text mining model. We used optical character recognition (OCR) software to extract text from snapchats and photos to detect cyberbullying. We use an OCR technology that's more accurate than others. After gathering text, it is simplified and made easier to understand before classification. Using a classification system, we'll decide if it's cyberbullying. In this scenario, we apply logistic regression, decision trees, gradient boosting, random forest, bagging, SGD, linear SVC, and adaboost classifiers. We got several results by using many NLP models and algorithms. Then, we compared the accuracy parameter to the others to see which is giving the best results. Here fig 2 illustrates the methodology or implementation details of this study.
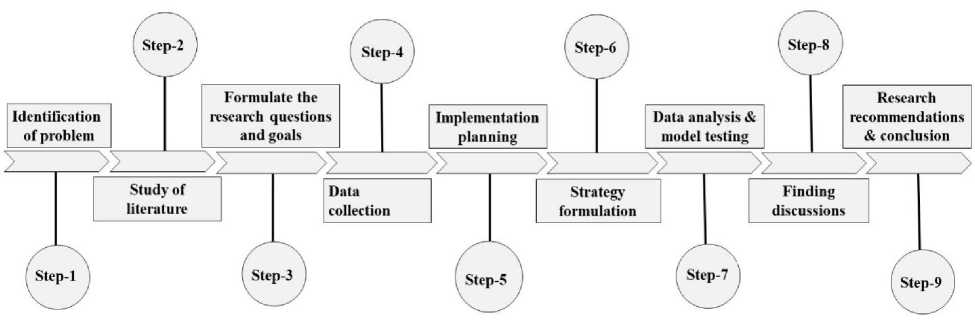
Fig.1. Research workflow.
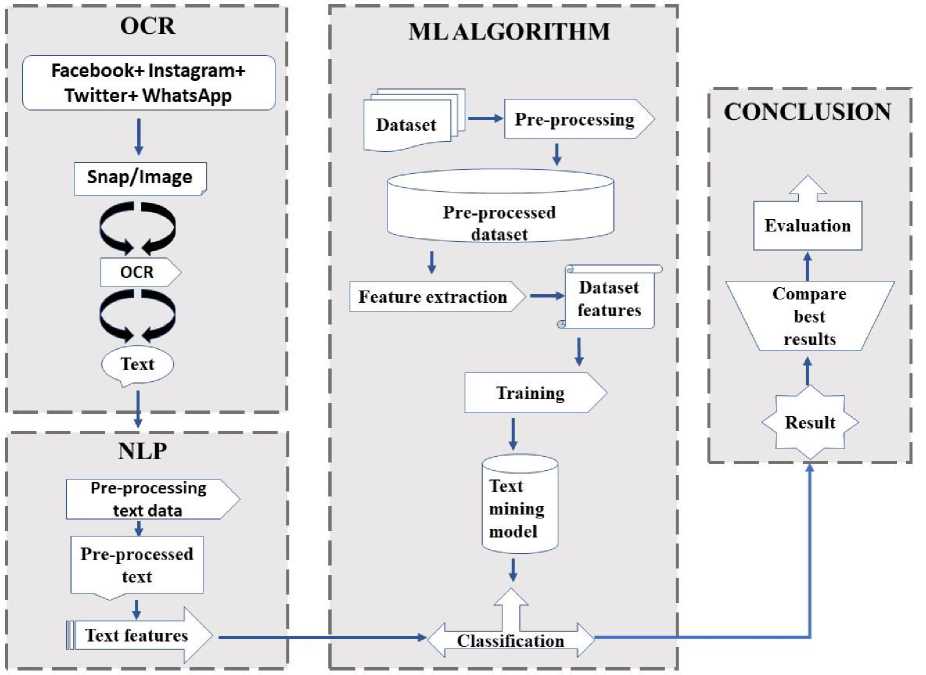
Fig.2. Methodology/ Implementation details.
-
4.1. Text Extract from Image
-
4.2. Natural Language Processing
We use machine learning to detect cyberbullying from a snapshot. To categorize the text from the photos, we must extract it. This requires OCR. Optical Character Recognition (OCR) translates picture text to device text. Visuals can be printed sheets, symbols, or handwritten writing.
References Machine Learning in Cyberbullying Detection from Social-Media Image or Screenshot with Optical Character Recognition
- A.Saravanaraj, J. I. Sheeba, S. Pradeep Devaneyan, 2016. Automatic Detection of Cyberbullying from twitter. IRACST - International Journal of Computer Science and Information Technology & Security (IJCSITS), ISSN.
- M. A. Al-Garadi, K. D. Varathan, and S. D. Ravana, “Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network,”Comput. Human Behav., vol. 63, 2016, pp. 433–443.
- Raisi, E. and Huang, B., 2017, July. Cyberbullying detection with weakly supervised machine learning. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017 (pp. 409-416).
- Basarslan, M.S. and Kayaalp, F., 2020. Sentiment Analysis with Machine Learning Methods on Social Media.
- J. Han, M. Kamber and J. Pei, “Data Mining: Concepts and Techniques,” Elsevier, Morgan Kaufmann Series in Data Management Systems, vol. 3, 2011
- B. Liu, “Sentiment Analysis and Opinion Mining,” Synthesis Lectures on Human Language Technologies, Morgan & Claypool, vol. 5, no. 1, pp. 1-167, May 2012
- Hosseinmardi, H., Rafiq, R.I., Han, R., Lv, Q. and Mishra, S., 2016, August. Prediction of cyberbullying incidents in a media-based social network. In 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM) (pp. 186-192). IEEE.
- Kargutkar, S.M. and Chitre, V., 2020, March. A study of cyberbullying detection using machine learning techniques. In 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC) (pp. 734-739). IEEE.
- Choudhary, A., Rishi, R. and Ahlawat, S., 2013. A new approach to detect and extract characters from off-line printed images and text. Procedia Computer Science, 17, pp.434-440.
- Akopyan, M.S., Belyaeva, O.V., Plechov, T.P. and Turdakov, D.Y., 2019, September. Text recognition on images from social media. In 2019 Ivannikov Memorial Workshop (IVMEM) (pp. 3-6). IEEE.
- Kumar, A. and Sachdeva, N., 2021. Multimodal cyberbullying detection using capsule network with dynamic routing and deep convolutional neural network. Multimedia Systems, pp.1-10.
- Ranjan S, Sanket S, Singh S, Tyagi S, Kaur M, Rakesh N, Nand P. OCR based Automated Number Plate Text Detection and Extraction. In2022 9th International Conference on Computing for Sustainable Global Development (INDIACom) 2022 Mar 23 (pp. 621-627). IEEE.
- Zhao, R., Zhou, A. and Mao, K., 2016, January. Automatic detection of cyberbullying on social networks based on bullying features. In Proceedings of the 17th international conference on distributed computing and networking (pp. 1-6).
- Drishya, S.V., Saranya, S., Sheeba, J.I. and Devaneyan, S.P., 2019. Cyberbully image and text detection using convolutional neural networks. CiiT International Journal of Fuzzy Systems, 11(2), pp.25-30.
- Islam, M.M., Uddin, M.A., Islam, L., Akter, A., Sharmin, S. and Acharjee, U.K., 2020, December. Cyberbullying detection on social networks using machine learning approaches. In 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE) (pp. 1-6). IEEE.
- Perera, A. and Fernando, P., 2021. Accurate cyberbullying detection and prevention on social media. Procedia Computer Science, 181, pp.605-611.
- Alam, K.S., Bhowmik, S. and Prosun, P.R.K., 2021, February. Cyberbullying detection: an ensemble based machine learning approach. In 2021 third international conference on intelligent communication technologies and virtual mobile networks (ICICV) (pp. 710-715). IEEE.
- Muneer, A. and Fati, S.M., 2020. A comparative analysis of machine learning techniques for cyberbullying detection on Twitter. Future Internet, 12(11), p.187.
- Hani, J., Mohamed, N., Ahmed, M., Emad, Z., Amer, E. and Ammar, M., 2019. Social media cyberbullying detection using machine learning. International Journal of Advanced Computer Science and Applications, 10(5).
- Wan Noor Hamiza Wan Ali, Masnizah Mohd, Fariza Fauzi, Centre for Cyber Security, Universiti Kebangsaan Malaysia Bangi, Selangor, 2020. Cyberbullying Predictive Model: Implementation of Machine Learning Approach.
- Kumar, A., Nayak, S. and Chandra, N., 2019. Empirical analysis of supervised machine learning techniques for Cyberbullying detection. In International Conference on Innovative Computing and Communications (pp. 223-230). Springer, Singapore.
- Hani, J., Nashaat, M., Ahmed, M., Emad, Z., Amer, E. and Mohammed, A., 2019. Social media cyberbullying detection using machine learning. Int. J. Adv. Comput. Sci. Appl, 10(5), pp.703-707.
- Monirah Abdullah Al-Ajlan, Mourad Ykhle, King Saud University, 2018. Deep Learning Algorithm for Cyberbullying Detection. (IJACSA) International Journal of Advanced Computer Science and Applications.
- Elsafoury, Fatma (2020), “Cyberbullying datasets”, Mendeley Data, V1, doi: 10.17632/jf4pzyvnpj.1
