Математическое моделирование процесса принятия решения о состоянии стохастических систем

Автор: Балашова Е.А., Битюкова В.В., Котов Г.И., Буданов А.В.
Журнал: Вестник Воронежского государственного университета инженерных технологий @vestnik-vsuet
Рубрика: Информационные технологии, моделирование и управление
Статья в выпуске: 2 (68), 2016 года.
Бесплатный доступ
Вследствие трудности построения строгих математических моделей технологических, биомедицинских и экономических объектов получили своё развитие методы прогнозирования состояния на основе статистического анализа. Сложность анализируемого объекта эквивалентна его информационной ёмкости. Максимальная ёмкость достигается, если все состояния объекта равновероятны. Относительная неопределённость информации, получаемой решающей системой, затрудняет принятие решения о состоянии объекта. Для надёжного предсказания состояния объекта измеряется несколько его признаков, диапазон измерения разбивается на градации, а в пределах каждой градации производится усреднение сигнала. Далее решают две задачи: обнаружения (выявление отклонения функционирования объекта от нормального режима), и распознавания (оценка степени отклонения от нормы). Число градаций признака тесно связано с мощностью обучающей выборки (не менее 40). При описании системы с 8–30 признаками и мощностью обучающей выборки от 40 до 120, методика, включающая в себя формализацию признаков на первом этапе, отбор с помощью корреляционного анализа наиболее информативных признаков на втором этапе и классификацию состояния объекта методом кластерного анализа позволили правильно диагностировать состояние системы в аварийном режиме с точностью от 89 до 98 %. Предложенный информационный подход позволяет осуществлять классификацию и прогнозирование технических, экономических и биомедицинских систем любой сложности, что открывает возможности предсказания поведения таких систем и управления при появлении помех.
Информационная ёмкость, обучающая выборка, градации, классификация состояния
Короткий адрес: https://sciup.org/14043247
IDR: 14043247 | DOI: 10.20914/2310-1202-2016-2-118-124
Mathematical modeling of the decision-making process on the state of stochastic systems
Because of the difficulty of constructing rigorous mathematical models of technological, biomedical and economic facilities have been developed methods of forecasting based on statistical analysis. The complexity of the analyzed object is equivalent to its information capacity. The maximum capacity is achieved if all of the object's state is equally likely. The relative uncertainty of information obtained crucial system complicates decision-making on the state of the object. To reliably predict the state of the object is measured several characteristics, the measurement range is broken into grades, but within each gradation is made by averaging of the signal. Next solve two problems: the detection problem (detection of deviation of operation from normal mode) and a recognition task (assessment of the degree of deviation from the norm). The number of gradations of the trait is closely linked to the capacity of the training sample (at least 40). In the description of the system from 8 to 30 signs and power training samples from 40 to 120, the method includes the formalization of the signs in the first stage, the selection using a correlation analysis of the most informative features in the second stage and a classification of the state of the object by the method of cluster analysis allowed to correctly diagnose the system status in emergency mode with an accuracy of between 89 to 98%. The proposed information approach allows the classification and prediction of technical, economic and biomedical systems of any complexity, which opens up the possibility of predicting the behavior of such systems and control the appearance of interference.
Текст научной статьи Математическое моделирование процесса принятия решения о состоянии стохастических систем
Стохастические системы, элементы которых могут иметь множество состояний и иерархически взаимодействовать между собой, с трудом поддаются моделированию, и их статистические модели, как правило, неизвестны. Описание таких систем осуществляется с использованием эвристически выбранных параметров состояния [6, 9, 11], которые будем называть признаками стохастической системы. Статистическое описание стохастических систем реализуется в пространстве эвристических признаков, а не состояний, что позволяет реализовать огромное сжатие информации.
Описание и прогнозирование состояния широчайшего класса технических, биотехнологических и экономических систем, которым присущи вероятностные связи между частями и иерархическая организация, возможны только на базе информационной модели их функционирования.
Материал и методы исследования
Пусть иерархически организованная система характеризуется N признаками, каждый из которых имеет n состояний с вероятностью появления Р i некоторого i -го состояния.
Под сложностью системы будем понимать число состояний её признаков, отличающихся друг от друга, которое характеризуется отношением N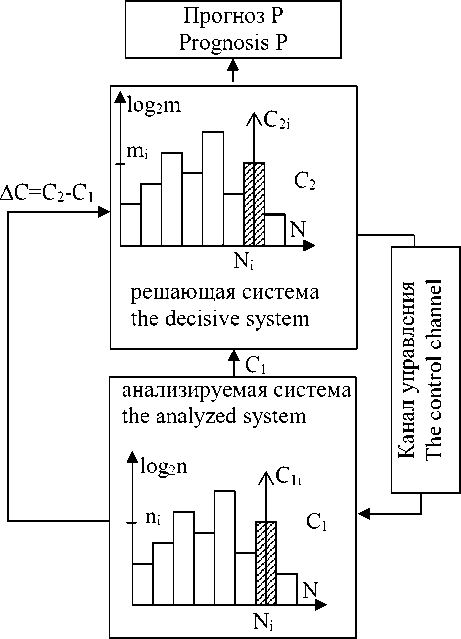
Рисунок 1. Информационная модель иерархически организованной системы
Figure 1. Information model hierarchically organized system
Введём относительную неопределённость информации, получаемой решающей системой:
R = ^C- = 1
C
—
C 1
, C 2
N 2
где C 2 = £ log2 m , - информационная ёмкость i = 1
базы данных решающей системы, N 2 – число информативных признаков системы.
Эта неопределённость затрудняет распознавание и классификацию полученной информации и может быть использована для управления анализируемой системой в канале обратной связи. Этот случай соответствует условию С1 < С2 и 0 < R < 1. Случай С1 > С2 соответствует прогнозированию поведения системы при недостатке или полном отсутствии априорной информации о ней, и –∞ < R < 0.
Случай R = 0 соответствует полному совпадению полученного сообщения с существующей базой данных, то есть система абсолютно предсказуема и управляема и может классифицироваться как детерминированная.
С учётом выражений (1) и (2) вероятность правильного предсказания состояния системы по некоторому N i признаку запишем следующим образом:
P i = n - R^ (5)
Проанализируем полученное соотношение. Если имеется абсолютно полная информация об анализируемой системе по каждому признаку (событию), то R = 0 и Р = 1 . Следовательно, система, несмотря на то что она может характеризоваться множеством признаков и состояний и быть очень сложной, является абсолютно предсказуемой, то есть детерминированной. То есть детерминизм – это предельный частный случай, когда возможно полное описание системы в выбранном пространстве признаков, которые являются определяющими в рамках решаемой задачи.
Если все состояния системы (события) равновероятны, то относительная неопределённость максимальна, то есть R i = 1 , P i = 1/n и n
^ P i = 1 - полная группа событий.
i = 1
Причём это характерно для абсолютно случайной системы, когда все состояния системы равновероятны и вероятность правильной классификации обратно пропорциональна их числу. Промежуточные случаи характеризуются некоторыми преимущественными состояниями системы и описываются различными статистическими распределениями.
Соотношение (5) является основой для построения классификационно-прогностической диаграммы состояния стохастических систем (рисунок 2). Для простых систем область существования детерминированных состояний 1 чрезвычайно мала. На рисунке 2 она ограничена кривыми для n = 1 и n = 2 и прямой R = 0,05 . Эти системы имеют практически одно состояние. К ним относится большинство технических систем, особенно механических.
-
2 – область существования однородных вероятностных систем. К ним относятся множество физических и химических систем, простейшие биологические и экономические системы.
-
3 – область существования сложных детерминированных систем. Она несколько больше области 1, но также достаточно мала. На рисунок 2 она ограничена кривыми для n = 2 и n = 16 и прямой R = 0,05 . Сюда можно отнести сложные технические системы, жесткоорганизованные кибернетические системы.
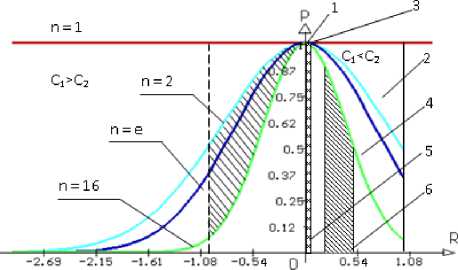
Рисунок 2. Классификационно-прогностическая диаграмма
Figure 2. Classification-prognostic chart
-
4 – область существования сложных вероятностных систем, к которым можно
отнести иерархические системы искусственного интеллекта, а также экономические системы.
Наибольшее разнообразие для создания очень сложных детерминированных систем предоставляет область 5, что видно на примерах простейших биологических объектов – клеток, тканей, органов, которые, несмотря на огромную сложность, функционируют по строго заданной программе.
-
6 – область существования чрезвычайно
сложных вероятностных систем, иерархически гибко организованных, способных к саморазвитию и сложному поведению. К ним относится огромное разнообразие биологических видов, в том числе и человек. Это самая обширная область на диаграмме, что предполагает огромные возможности в создании самых разнообразных систем искусственного интеллекта. Здесь штриховкой выделена область существо- вания саморазвивающихся систем.
Величина 1 - R = C1 JC2 - относительная информационная ёмкость системы, характеризует качество прогноза. Введём коэффициент качества прогноза
K =
1 - R
R ,
Качество прогноза при K > 19 весьма высокое для детерминированных систем и ограничивается только ошибками измерений.
Для вероятностных систем качество прогноза удовлетворительное, если известен закон распределения их состояний ( 0,05 < R < 0,2, 4 < K < 19 ). Саморазвивающиеся системы, обладающие свободой выбора, прогнозируютсясущественно хуже ( 0,2 < R < 0,5, 1 < K < 4 ). И, наконец, относительно абсолютно случайных систем можно лишь сказать, что все их состояния близки к равновероятным при R > 0,5 , когда коэффициент качества прогноза K < 1 . В этом случае никакой прогноз и управление системой невозможны.
Очевидно, что надёжное управление любой системой возможно в случае приближения информационной ёмкости управляемого сообщения (сигнала) С 1 к информационной ёмкости базы данных С 2 . Помехи в каналах управления и отказы отдельных элементов системы уменьшают информационную ёмкость сигнала управления, качество прогноза падает, и уменьшается вероятность правильного функционирования системы. Это приводит к отказам технических устройств, экономическим кризисам и болезням биологических объектов. Очевидно, для каждой системы есть своя пороговая величина Р , ниже которой нормальное функционирование системы становится невозможным и она погибает.
Левая часть диаграммы является прогностической, когда осуществляется анализ системы с использование априорной информации, заложенной в экспериментально накопленной базе данных. В этом случае С > С 2 и значения R становятся отрицательными. Оптимальное прогнозирование системы опять реализуется в случае С 1 = С 2 , что подтверждается теорией распознавания образов [4]. Вероятность правильного принятия решения падает с уменьшением информационной ёмкости существующей базы данных и усложнением анализируемой системы.
Если информационная ёмкость сообщения вдвое превосходит таковую для базы данных, то есть С 1 ^С 2 = 2, то возможно лишь случайное предсказание состояния системы с вероятностью P = 1/ n . Следовательно, системы распознавания образов могут функционировать при условии 1 < С 1 /С 2 < 2 или - 1 < R < 0.
Эта область ограничена на диаграмме пунктирной линией. Дальнейшее уменьшение информационной ёмкости базы данных С2 свидетельствует об отсутствии в ней адекватных алгоритмов анализа сообщения и вероятность правильного принятия решения стремится к нулю тем быстрее, чем сложнее анализируемая система. Аналогично при полном отсутствии информации о системе С1 = 0 и Р ^ 0 при |к| < 1.
Для вычисления вероятности правильного предсказания состояния системы введём её среднее значение в N -мерном пространстве признаков, с учётом выражения (5):
N N 2 N J 1 - log 2 n i 1
Е p i Е n - R i ') Е n 1 log2 ™ i J2
p = — = 2=1-----= 2=1-------- (7)
NN N
Здесь учтено, что размерности анализируемой системы признаков и решающей системы одинаковы, то есть определяются одной и той же экспериментальной базой данных.
Вследствие трудности построения строгих математических моделей технологических, биомедицинских и экономических систем получили своё развитие методы прогнозирования состояния на основе статистического анализа. Эвристическое описание таких систем осуществляется с использованием ряда признаков (параметров состояния, симптомов, экономических показателей), характеризующих макросостояние анализируемой системы [1–3, 5–8, 10].
Иерархическая организация таких систем и наличие блоков управления существенно ограничивает число их нормальных состояний. Поэтому дисперсия плотностей распределения признаков при нормальном состоянии анализируемых систем незначительна, что обеспечивает устойчивость их функционирования. Следовательно для описания нормального состояния анализируемых систем достаточно двух градаций каждого признака: среднего значения нормы m н и границы нормы х о (рисунок 3).
Выход за границу нормы приводит к аварийному функционированию системы со средним значением m а и значительной дисперсией признаков. Как правило, статистические распределения признаков в аварийном режиме функционирования неизвестны, а базы данных по этим признакам имеют малую мощность, так как существенные отклонения от нормального приводят к техногенным катастрофам, смертельным болезням биологических организмов и экономическим кризисам.
Для надёжного предсказания состояния анализируемой системы обычно измеряют несколько признаков N её состояния и осуществляют многофакторный анализ с исследованием различных методов [9–11].
При этом решаются две задачи: обнаружения, заключающаяся в оценке вероятности отклонения системы от нормального режима функционирования, и распознавания, заключающаяся в оценке степени отклонения от нормы. Первая задача сводится к построению решающей поверхности в многомерном пространстве признаков, разделяющей нормальную и аварийную области на базе принятого решающего правила. Вторая – к построению кластеров признаков, соответствующих принятым степеням отклонения от нормы и оценке положения измеренного многомерного вектора признаков.
Принципиальной трудностью, возникающей при решении указанных задач, является оценка минимально возможной мощности обучающей выборки и числа градаций признаков, обеспечивающих заданную вероятность решения задач обнаружения и распознавания в анализируемых системах.
Актуальность этой проблемы связана с бурным развитием современных средств измерений в различных областях науки и техники. Существующие датчики и системы контроля могут обеспечить чрезвычайно высокую точность измерений. При этом информационная ёмкость сигнала, поступающего в систему управления, может быть значительно большей, чем ёмкость обучающей выборки, что снижает вероятность правильного предсказания состояния системы [1].
Следовательно, возникает проблема оптимизации многофакторных измерений в анализируемых системах, то есть согласования относительно невысокой информационной мощности обучающей выборки и информационной ёмкости сигнала, обеспечиваемого современными средствами контроля, при сохранении заданной вероятности правильного предсказания состояния управляемой системы.
Задача обнаружения аварийного режима подобие классической – выбора одной из двух гипотез (рисунок 3) [4]. Если признак x попадает в область К 1 , то принимается гипотеза Н 1 – нормальное состояние; в область К 2 , то гипотеза Н 2 – аварийный режим. Однако порог обнаружения х о здесь определяется экспериментально.
Задача экспериментальной оценки порога х о является экспертной. Разделим область аварийного режима К 2 на три: лёгкое отклонение от нормы К 21 , среднее отклонение К 22 и тяжёлое – К 23 . Очевидно, что мощности обучающих выборок, соответствующих этим трём областям, будут различны и отличаются от мощности нормальной обучающей выборки.
Поэтому чрезвычайно высокая точность измерений вредна с этих позиций.
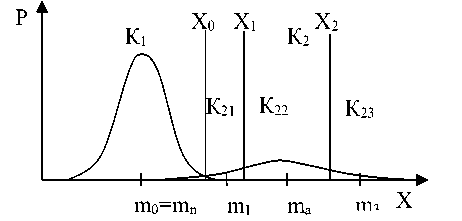
Рисунок 3. Классификационная диаграмма
Figure 3. Classification chart
Пороги Х 0 , Х 1 , Х 2 устанавливаются следующим образом. По обучающей выборке рассчитываются средние значения m 0 , m 1 , m 2 , т з и стандартная ошибка с о , c i , 0 2 , с з признаков по областям К 1 , К 21 , К 22 , К 23 . Порог:
X- — , i = 0, 1, 2 (8)
с > 2
где А т - разность средних значений между соседними областями, с с > - отношение меньшей и большей стандартных ошибок соседних областей. Порог откладывается от среднего с меньшей ошибкой.
Для целей предотвращения аварийного режима необходимо весь динамический диапазон изменения признаков разбить на градации, а в пределах каждой градации производить усреднение сигнала. Наличие аварийной статистики позволяет уменьшить необходимое число градаций. Однако эвристический подход к установлению порога требует определённого запаса по числу градаций сигнала, область изменения которых в зависимости от мощности обучающей выборки можно задать следующим образом 8 < n < 20 .
Очевидно, что число градаций статистического ряда обучающей выборки, так же как и число градаций сигнала, должно быть связано с мощностью обучающей выборки. При слишком большом числе градаций частоты статистического ряда имеют незакономерные колебания. При слишком малом числе градаций описание очень грубое. Поэтому даже если информационная ёмкость обучающей выборки близка к информационной ёмкости сигнала, число градаций в пределах заданного выше диапазона должно сочетаться с объёмом выборки.
В [1] установлен минимально возможный объем статистического ряда:
L > 10 5 , (9)
откуда следует, что 40 < L < 104 .
Следует отметить, что эвристические признаки, сложившиеся в практике, как правило, статистически зависимые [11], и подчёркивают те или иные специфические аспекты исследуемого процесса или явления. При проверке корреляционной связи между признаками и отборе статистически независимых, их число может быть существенно уменьшено.
Проведённые в [2, 3, 7, 8] экспериментальные исследования показали, что при описании системы с 8–30 признаками и мощностью обучающей выборки L от 40 до 120 методик, включающая в себя формализацию признаков на первом этапе, отбор с помощью корреляционного
Список литературы Математическое моделирование процесса принятия решения о состоянии стохастических систем
- Базарский О.В., Коржик Ю.В. Система признаков для анализа и распознавания изображений случайных пространственных текстур//Исследования Земли из космоса, 1985. № 6. С. 101-105.
- Балашова Е.А., Жданова Ю.А., Минаев Н.Н. Иерархический кластер-анализ для автоматизированной диагностики состояния объекта по совокупности качественных признаков//Системы управления и информационные технологии. 2005. T. 22. № 5. С. 4-10.
- Балашова Е.А., Битюков В.К., Саввина Е.А. Сравнительный анализ методов классификации при прогнозировании качества хлеба.//Вестник ВГУИТ. 2013. № 1. С. 57-62.
- Горелик А.Л.,Гуревич И.Б., Скрипкин В.А. Современное состояние проблемы распознавания: Некоторые аспекты. М.: Радио и связь, 1985. 160 с.
- Крамаренко С.С. Метод использования энтропийно-информационного анализа для количественных признаков//Известия Самарского научного центра Российской академии наук. 2005. Т. 7. №. 1.
- Крамаренко С.С., Луговой С.И. Использование энтропийно-информационного анализа для оценки воспроизводительных качеств свиноматок//Вестник Алтайского государственного аграрного университета. 2013. Т. 2. № 9. С. 58-62.
- Рогозина М.А., Подвигин С.Н., Балашова Е.А. Выявление информативных показателей и автоматизированная диагностика пограничных психических расстройств у студентов медицинского вуза//Системный анализ и управление в биомедицинских системах. 2009. Т. 8. № 3. С. 772-775
- Худякова О.В., Битюкова В.В., Балашова Е.А. Автоматизированная классификация тактики лечения врожденной фоновой патологии шейки матки//Системный анализ и управление в биомедицинских системах. 2009. Т. 8. № 2. С. 414-419
- Chater N., Tenenbaum J. B., Yuille A. Probabilistic models of cognition//Conceptual foundations.2006. V. 10. № 7. P. 287-291. DOI: DOI: 10.1016/j.tics.2006.05.007
- Cassandras C.G., Lygeros J. et al. Stochastic hybrid systems // CRC Press. 2006. V. 24. Bianchi L. et al. A survey on metaheuristics for stochastic combinatorial optimization // Natural Computing: an international journal. 2009. V. 8. №. 2. P. 239–287. DOI 10.1007/s11047–008–9098–4
- Garcia S. et al. A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning//Knowledge and Data Engineering, IEEE Transactions on. 2013. V. 25. №. 4. P. 734-775
