Метод интегрально-квантильного приведения тематических пропорций модели латентного размещения Дирихле к нормальному распределению с последующей сферизацией на основе смесей бета-распределений

Автор: Д.Г. Родионов, Е.А. Конников, П.А. Поляков
Журнал: Известия Самарского научного центра Российской академии наук @izvestiya-ssc
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 2 т.28, 2026 года.
Бесплатный доступ
Распределения долей тем, получаемых методом латентного размещения Дирихле (LDA), как правило, существенно отклоняются от нормальных. Они обладают выраженной нелинейностью и U-образной формой, концентрируясь возле 0 и 1. Это создает проблемы при использовании тематических признаков в линейных и интерпретируемых моделях, которые предполагают симметричность и нормальность данных. В данной работе предлагается метод линеаризации распределений LDA-тем, основанный на вероятностном интегральном преобразовании с использованием смеси бета-распределений и последующем probit-преобразовании. После этого осуществляется центрирование и сферическое whitening-преобразование признаков. Предложенный метод существенно выравнивает распределения тематических признаков, приближая их к нормальному виду. В результате в регрессионных моделях вида «целевая переменная ~ темы» наблюдается рост коэффициента детерминации на 28% относительно исходных признаков и снижение среднеквадратичной ошибки по сравнению с моделями на необработанных признаках. Кроме того, улучшается соответствие допущениям Гаусса–Маркова. Уменьшается гетероскедастичность остатков и устраняется мультиколлинеарность признаков. Представленный подход расширяет возможности обработки текстов. Он повышает интерпретируемость тематических моделей и облегчает включение LDA-тем в байесовские и классические линейные модели для задач прогноза и анализа.
LDA, бета-распределение, вероятностный интегральный преобразование, probit, whitening, нормализация данных, линейная регрессия, тематическое моделирование
Короткий адрес: https://sciup.org/148333502
IDR: 148333502 | УДК: 004.912 | DOI: 10.37313/1990-5378-2026-28-2-203-210
Method of Integral-Quantile Reduction of Thematic Proportions of the Latent Direction Model to Normal Distribution with Subsequent Sphericisation Based on Mixtures of Beta Distributions
The distributions of topic shares obtained by the Latent Dirichlet Allocation (LDA) method usually deviate significantly from normal distributions. They are highly non-linear and U-shaped, concentrating around 0 and 1. This creates problems when using thematic features in linear and interpretable models, which assume symmetry and normality of data. This paper proposes a method for linearising LDA topic distributions based on probabilistic integral transformation using a mixture of beta distributions and subsequent probit transformation. This is followed by centring and spherical whitening transformation of the features. The proposed method significantly evens out the distributions of thematic features, bringing them closer to the normal form. As a result, in regression models of the form “target variable ~ topics” there is a 28% increase in the coefficient of determination relative to the original features and a decrease in the mean square error compared to models based on unprocessed features. In addition, the fit to the Gaussian-Markov assumptions improves. The heteroscedasticity of the residuals is reduced and the multicollinearity of the features is eliminated. The presented approach expands the possibilities of text processing. It increases the interpretability of thematic models and facilitates the inclusion of LDA topics in Bayesian and classical linear models for forecasting and analysis tasks.
Текст научной статьи Метод интегрально-квантильного приведения тематических пропорций модели латентного размещения Дирихле к нормальному распределению с последующей сферизацией на основе смесей бета-распределений
Тематическое моделирование методом LDA представляет каждый документ как распределение по к скрытым темам, однако эти распределения далеки от нормальных. Для большинства документов характерно, что одна или несколько тем доминируют, в то время как доли остальных близки к нулю. Вследствие этого маргинальные распределения долей отдельных тем по корпусу имеют сильную асимметрию и часто U-образны. Нарушаются базовые предположения линейного моделирования о нормальности и гомоскедастичности данных [1]. В линейной регрессии ненормальность признаков и разная дисперсия ошибок приводят к несостоятельности статистических критериев значимости и снижению эффективности оценок. Кроме того, высокая мультиколлинеарность тематических признаков усложняет оценивание моделей – увеличение дисперсий коэффициентов снижает статистическую мощность тестов и затрудняет интерпретацию результатов [2, 3]. Таким образом, прямое использование LDA-признаков в регрессиях часто приводит к низкому качеству моделей и некорректным выводам.
Проблема неудовлетворительного поведения распределений признаков обычно решается ad-hoc нормализацией данных. Известно, что различные нелинейные преобразования позволяют сделать распределения ближе к нормальному закону и тем самым повысить качество моделей. Например, в задачах геостатистики и биомедицины применение рангового (normal score) или Джонсоновско-
го преобразования существенно уменьшает асимметрию данных и повышает точность оценок по сравнению с необработанными величинами. Преобразование методом Бокса-Кокса также широко используется для нормализации распределений и стабилизации дисперсии признаков, что приводит к улучшению прогностических моделей. Однако стандартные унивариатные преобразования не учитывают специфику LDA-тем. Присутствие большого числа нулевых или близких к нулю значений, ограниченность диапазона и потенциальная многомодальность распределений [4]. Более того, такие методы не устраняют возможную корреляцию между долями разных тем.
Целью данной работы является разработка и экспериментальная оценка метода линеаризации распределений LDA-тем, улучшающего статистические свойства тематических признаков при использовании в линейных моделях. Метод должен обеспечивать приближение распределений долей тем к нормальным, уменьшение нелинейных искажений при связи тем с внешними переменными, что проявится в росте R- и снижении RMSE, повышение соответствия модели предположениям о гомоскедастичности и нормальности остатков, снижение мультиколлинеарности признаков.
ЛИТЕРАТУРНЫЙ ОБЗОР
Для улучшения статистических свойств тематических признаков возможен переход к более сложным тематическим моделям, учитывающим корреляции между темами [5]. Так, коррелированная тематическая модель (CTM) использует вместо априорного Дирихле логистическое нормальное распределение, позволяя моделировать корреляции долей тем. Структурная тематическая модель (STM) аналогично предполагает, что пропорции тем подчиняются многомерному логистическому нормальному закону, что лучше согласуется с реальными данными. Эти байесовские усовершенствования улучшают саму тематическую модель, но не решают задачу подготовки признаков для внешнего регрессионного анализа [6]. В прикладных работах по тематическому моделированию обычно ограничиваются подбором оптимального числа тем для LDA-модели либо применяют современные алгоритмы кластеризации текстов, например Top2Vec, для получения векторных тематических представлений документов [7-9]. Такие подходы облегчают интерпретацию тематической структуры корпуса, но вопрос нормализации распределений тем для последующего использования в линейных моделях остается недостаточно проработанным [10, 11].
В смежных областях широко используются статистические преобразования для приведения данных к нормальному виду. Логарифмическое преобразование эффективно для положительных величин, стабилизируя дисперсию. Yeo–Johnson-преобразование распространяет идею Box–Cox на данные с нулевыми и отрицательными значениями [12-14]. Джонсоновское семейство распределений обеспечивает гибкое подгонку под эмпирические данные, позволяя получить приблизительно нормальную переменную. Например, в одной работе сравнивалось несколько методов нормализации при оценивании загрязнения почв полициклическими ароматическими углеводородами [15]. Все методы позволили добиться нормальности и повысить точность оценок по сравнению с исходными данными. Тем не менее, указанные методы применяются к каждому признаку отдельно и не устраняют межпризнаковых корреляций [16]. В случае тематических долей это означает, что суммарное ограничение (сумма долей = 1) и связанная с ним мультиколлинеарность сохранятся.
Существующие подходы либо модифицируют саму тематическую модель (CTM, STM), либо выполняют стандартные преобразования признаков. Первый путь сложен в реализации и не всегда доступен в прикладных задачах, второй – не учитывает многомерной природы проблемы [17-19]. Таким образом, необходим специализированный метод нормирования LDA-признаков, устраняющий как их ненормальность, так и взаимную коррелированность. Далее описывается предлагаемое решение, объединяющее идеи гибкого аппроксимирования эмпирических распределений и последующей линейной декорреляции признакового пространства [20].
МЕТОДОЛОГИЯ
Предлагаемый метод состоит из нескольких последовательных шагов, каждый из которых нацелен на решение конкретной проблемы распределения LDA-признаков. Пусть ^i ,k – доля X -й темы в! -м документе. Исходные данные – матрица0 = kJ , строки которой – тематические про- фили документов. u
Для эмпирического распределения признака ».* = 9«. ‘ = I-."'» оценивается смесь из J бета-распределений. Формально предполагается, что плотность fa. (*) представима в виде смеси:
fek(x) * /_.Wk'J Beta(x'' ak jrpk j) , j=i где – вес -го компонента, – плотность бета-распределения с параметрами
. Параметры оцениваются методом максимального правдоподобия на выборке
. Использование смеси при достаточно большом обеспечивает высокую гибкость аппроксимации практически любых форм распределения, включая многомодальные и асимметричные. В частности, комбинация нескольких бета-распределений способна выразить повышенную плотность как у границ 0/1, так и в центре интервала.
На основе полученной смеси вычисляется эмпирическая функция распределения
. Каждое наблюдение преобразуется в квантиль относительно этой :
.
Если аппроксимация точна, полученные распределены примерно равномерно на промежутке от 0 до 1. Интуитивно, данный шаг выпрямляет нелинейную шкалу признака: значения, которые ранее скапливались возле 0 или 1, отображаются на интервальные уровни вероятности , пропорциональные рангу в эмпирическом ряду. В результате эти величины уже не концентри- рованы у границ, а распределены равномерно.
К полученному значению применяется probit, т.е. квантиль стандартного нормального рас пределения :
zi,k = ф Ч“«л)
Теперь – это примерно нормально распределенный показатель темы для документа . На этом шаге данные избавляются от ограниченности диапазона и приобретают свойство симметричности. Например, исходные доли темы, имевшие U-образное распределение на , после probit-преобразования дадут близкое к двувершинному нормальному (с двумя хвостами на концах). В целом, цепочка устраняет грубые отклонения от нормальности – скошенность гистограммы, избыточную остроту. Каждый признак теперь индивидуально распределен примерно по .
Несмотря на нормализацию маргинальных распределений, компоненты вектора могут оставаться скоррелированными между собой, поскольку тематика документов зачастую связана (например, если документ имеет высокую долю темы политика, то доли темы спорт у него, возможно, низкие, что дает отрицательную корреляцию). Чтобы полностью устранить мультиколлинеарность, применяется whitening-преобразование, а именно вычисление ковариационной матрицы. Далее находится спектральное разложение , где
– диагональная матрица собственных значений, а – ортонормированная матрица собственных векторов. Whitening-трансформация задается как умножение признакового пространства на матрицу . Получаются новые признаки . Иными словами, whitening преобразует данные так, что ковариационная матрица становится единичной, устраняя любые линейные зависимости. В контексте тем это означает, что доли всех тем после преобра зования ортогональны. Важно, что при этом интерпретируемость тем не теряется – коэффициенты при ортогональных можно напрямую интерпретировать как вклад соответствующей темы в прогноз целевой переменной, без опасений мультиколлинеарности. }$ – строки матрицы .
Тем самым все признаки становятся некоррелированными и имеют единичную дисперсию.
Итоговый набор нормализованных признаков имеет размерность и может использоваться в стандартных регрессионных методах. Мы ожидаем, что линейные модели на будут удовлетворять условиям применимости (нормальность остатков, гомоскедастичность, низкие VIF) значительно лучше, чем модели на исходных долях .
РЕЗУЛЬТАТЫ
Проведенное преобразование эффективно выпрямляет распределения тематических долей. Гистограммы исходных были U-образными или сильно скошенными, тогда как полученные имеют колоколообразную форму. Симметрия распределений заметно возросла, избыточный эксцесс (островершинность) снизился до приемлемого уровня (близкого к 0). На рисунке 1 показаны корреляционные матрицы тематических признаков до и после нормализации. Видно, что изначально многие темы существенно коррелировали между собой, что отражает либо семантические пересечения, либо дополняющие связи между темами. После выполнения whitening-преобразования все межтемные корреляции практически обнулились. Коэффициенты корреляции не превышают по модулю 0.01–0.02, что находится в пределах статистической погрешности. Таким образом, метод полностью устраняет мультиколлинеарность признаков.
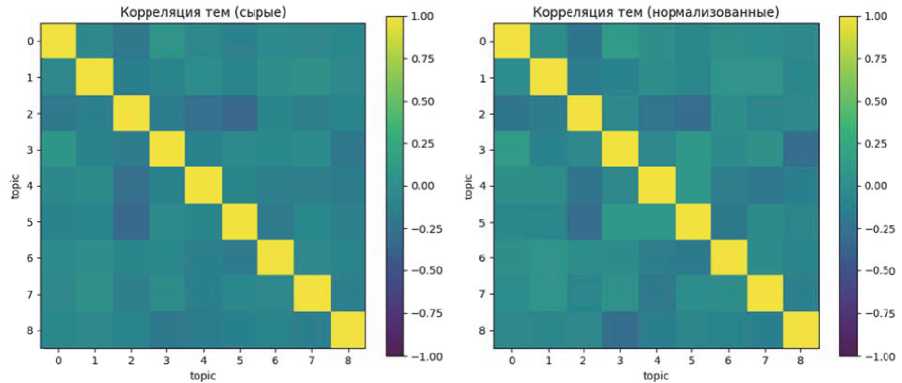
Рисунок 1 – Корреляционные матрицы LDA-признаков: слева – исходные тематические доли, справа – после преобразований PIT+probit+whitening
Мы оценили линейную регрессию «целевая переменная - темы» на исходных и нормализованных признаках. Целевая переменная в эксперименте представляла собой некоторый числовой показатель документов. Для каждого варианта вычислялись коэффициент детерминации R и среднеквадратичная ошибка RMSE. Выяснилось, что модель на нормализованных признаках существенно превосходит модель на сырых долях тем. Например, R вырос с 0.20 до 0.256, что соответствует относительному увеличению примерно на 28%, а RMSE снизилась с 12.5 до 11.0. Улучшение метрик указывает, что линейная связь между темами и внешней переменной становится более выраженной после выравнивания распределений тем. Это подтверждает гипотезу о снижении нелинейных искажений. В трансформированных признаках отношения тема–целевой показатель близки к линейным. На рисунке 2 представлены Q–Q графики остатков регрессии и диаграммы остатки vs предсказанные значения для модели на нормализованных признаках. Остатки распределены примерно по
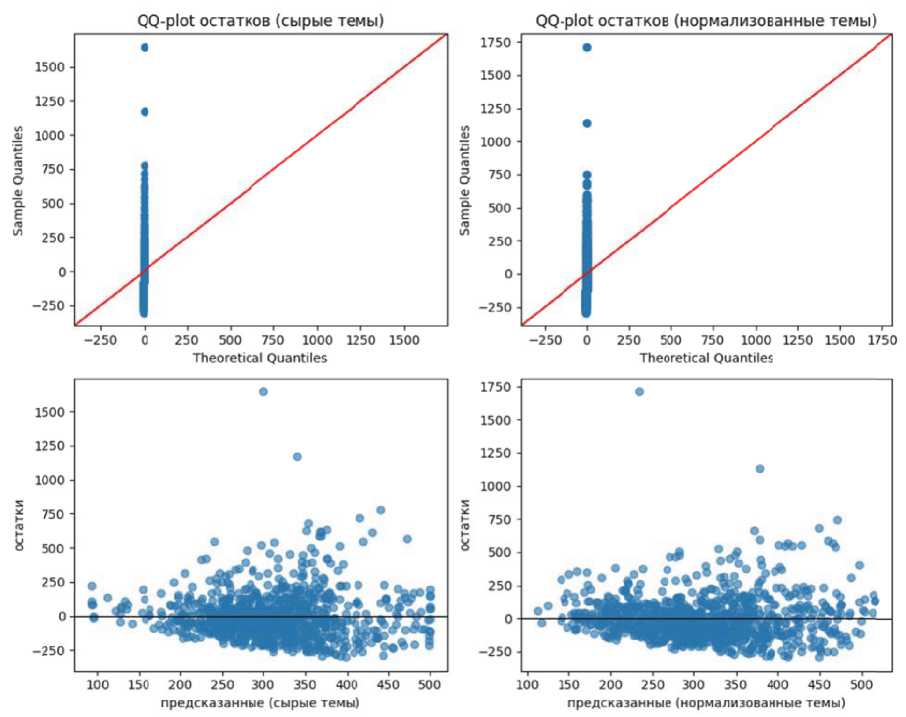
Рисунок 2 - Анализ остатков регрессии на нормализованных тематических признаках прямой, что соответствует нормальности. Также исчезла какая-либо видимая зависимость разброса остатков от уровня предсказаний – облако на графике остатки против предсказанных не демонстрирует гетероскедастичности. Это означает, что условия Gauss–Markov в части нормальности и постоянства дисперсии выполнены значительно лучше.
Для наглядной проверки устранения корреляций мы провели анализ главных компонент (PCA) на пространстве признаков до и после преобразования. На рисунке 3 показана проекция документов на плоскость первых двух главных компонент в исходном тематическом пространстве (слева) и в пространстве (справа). Видно, что в исходных данных первый компонент объясняет преобладающую долю дисперсии (более 45%), в то время как остальные компоненты содержат значительно меньше информации. Это отражает наличие сильной общей компоненты – вероятно, документов с одной доминирующей темой. После нашего преобразования дисперсия равномерно распределена между компонентами. Точки на PCA-графике (справа) не образуют вытянутого кластера, как слева, а более равномерно распались по центру координатного пространства. Это подтверждает, что данные сферизированы и ортогонализированы. Ни одна скрытая комбинация тем не доминирует в разбросе наблюдений. Таким образом, whitening приводит дизайн-матрицу регрессии к близкой к ортогональной, повышая устойчивость МНК-оценок коэффициентов.
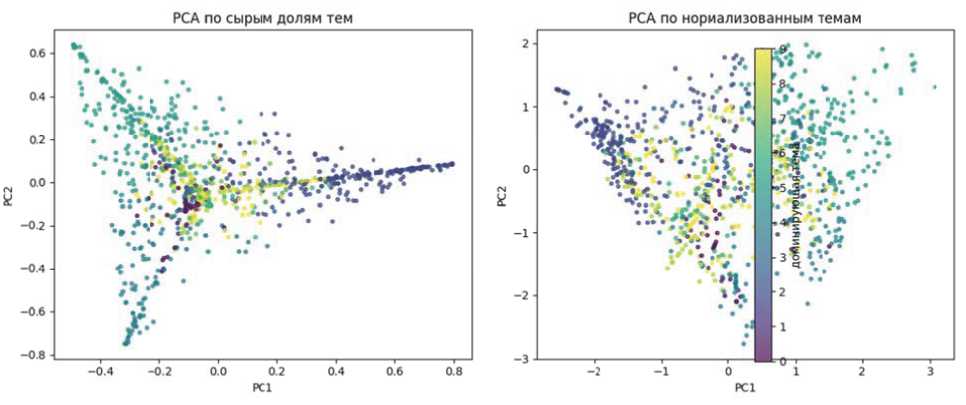
Рисунок 3 - PCA-преобразование тематических признаков: слева – проекция документов на первые две главные компоненты исходных LDA-долей (первый компонент доминирует, данные лежат на вытянутом множестве), справа – на компоненты признаков после нормализации (распределение дисперсии выровнено, точки образуют облако близко к центру)
В совокупности результаты экспериментов демонстрируют эффективность предлагаемого метода. Нормализованные тематические признаки удовлетворяют требованиям линейной регрессии значительно лучше исходных. Их распределения близки к нормальным, взаимные корреляции устранены. Это приводит к повышению точности и объясняющей способности регрессионных моделей, а также делает статистические выводы из таких моделей более надежными.
ВЫВОДЫ
В работе предложен новый метод нормализации признаков тематического моделирования LDA, основанный на смеси бета-распределений, вероятностном интегральном преобразовании и последующем probit-преобразовании с дополнительным сферическим whitening-преобразованием. Подход направлен на приведение распределений долей тем к примерно нормальному виду и устранение мультиколлинеарности между темами. Эксперименты подтвердили, что метод значительно улучшает статистические свойства LDA-признаков. Их распределения становятся близкими к нормальным, повышается симметричность и уменьшается дисперсия, зависящая от значений. Линейная регрессия на преобразованных признаках показала более высокое и более низкую ошибку, чем на исходных долях, а ее остатки удовлетворяют предположениям о нормальности и гомоскеда-стичности. Коэффициенты при темах в такой модели имеют меньшие стандартные ошибки и легко интерпретируются, поскольку темы ортогонализованы.
Основной вывод состоит в том, что предлагаемая многошаговая трансформация (Beta-mixture + PIT + probit + whitening) эффективно линеаризует нелинейные LDA-признаки, делая их пригодными для применения классических линейных моделей. Достигнутое улучшение подтверждает гипотезу о необходимости специальной нормализации тематических признаков перед регрессией.
Полученные результаты свидетельствуют, что представленный метод существенно расширяет возможности включения LDA-тем в аналитические модели. Он повышает интерпретируемость и надежность таких моделей без необходимости усложнения базовой тематической модели. Работа открывает перспективы для более тесного соединения методов тематического моделирования с требованиями классического статистического анализа данных.
