Методика автоматизированной разметки изображений и нахождения ключевых слов

Автор: Маркеев М.В.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 11-2 (74), 2022 года.
Бесплатный доступ
В данной статье предлагается методика автоматизированной разметки изображений и нахождения ключевых слов для них. На практике часто стоит задача понять суть того, что изображено на картинке и перевести это в текстовый формат. Это нужно для задач классификации, кластеризации и других, например, составление текстового описания для фотографии. Основная проблема здесь заключается в том, что современные нейросети обычно обучены распознавать определенное количество классов (обычно 1000). Этого часто не хватает, чтобы получить качественное текстовое описание изображения. Наш мир гораздо сложнее. В данной статье показана методика нахождения ключевых слов, наиболее близко подходящих для описания изображения. Для этого высчитывается близость между вектором изображения и вектором слова. Те вектора слов, которые оказываются наиболее близки к вектору изображения и будут использоваться как ключевые слова. А также, в статье проведено сравнение с обычной классификацией на 1000 классов изображение на датасете ImageNet.
Нейронные сети, машинное обучение, искусственный интеллект
Короткий адрес: https://sciup.org/170196729
IDR: 170196729 | DOI: 10.24412/2500-1000-2022-11-2-115-120
Methods of automated image markup and keyword finding
This article offers a methodology for automated markup of images and finding keywords for them. In practice it is often necessary to understand the essence of what is shown in the picture and translate it into text format. This is needed for classification, clustering and other tasks, such as making a text description for a photo. The main problem here is that modern neural networks are usually trained to recognize a certain number of classes (usually 1000). This is often not enough to get a quality text description of an image. Our world is much more complex. This article shows a technique for finding the keywords that most closely match the description of the image. For this purpose the proximity between vector image and vector word is calculated. Those vectors of words, which appear to be closest to the vector image and will be used as keywords. And also, the article compares with the usual classification of 1000 classes of the image on the ImageNet dataset.
Текст научной статьи Методика автоматизированной разметки изображений и нахождения ключевых слов
В современном мире все более часто и широко используются различные модели машинного обучения в том числе нейросети. В данное время предпринимаются попытки обучения одновременно изображений и соответствующего текста. Это сильно отличается от того, к чему мы привыкли ранее. Можно использовать для обучения картинки и подписи к ним из интернета, что позволяет не ограничиваться отдельными категориями, а задействовать огромные объемы данных – то, что нужно для нейросетей.
Часто сообщается, что системы глубокого обучения достигают человеческой или даже сверхчеловеческой производительности [1] в тестах на компьютерное зрение. В 2015 году группа исследователей из Microsoft впервые обучила модель, которая достигла точности топ-5 на ImageNet, что превзошло заявленную точность топ-5 человека [2]. Однако при использовании в реальных условиях их производительность может быть намного ниже ожиданий, установленных эталоном. Другими словами, существует разрыв между "эталонной производительностью" и "реальной производительностью".
Проблема состоит в том, что модели обученные на ImageNet хорошо предсказывает 1000 категорий ImageNet, но это все, что они может сделать "из коробки". Они обучены предсказывать заранее предопределенные категории. Но наш мир гораздо сложнее. Если мы хотим выполнить любую другую задачу, специалисту по машинному обучению (ML) необходимо создать новый набор данных, добавить выходную головку и точно донастроить модель. А если после такой донастройки появились новые данные, то нужно дополнительно перенастраивать. Компания OpenAI разработала модель CLIP (Contrastive Language–Image Pre-training) [3], позволяющую находить расстояния между изображениями и текстом. В отличие от моделей обученных находить определенные категории, CLIP может быть адаптирован для выполнения широкого спектра задач визуальной классификации без необходимости в дополнительных обучающих примерах. Чтобы применить CLIP к новой задаче, достаточно "сооб- щить" текстовому кодировщику CLIP названия визуальных понятий задачи, и он выдаст линейный классификатор визуальных представлений CLIP. Точность этого классификатора часто конкурирует с полностью контролируемыми моделями. CLIP может быть применен к любому эталону визуальной классификации путем просто- го указания названий визуальных категорий, которые необходимо распознать, аналогично возможностям "zero-shot" (т.е. без дополнительного обучения) в GPT-2 [4] и GPT-3 [5].
Принцип работы модели
Обучения модели происходит следующим образом:
Рис. 1. Пример обучения модели, сочетающей текстовые фразы и изображения [3]
Модель имеет 2 энкодера. Один для текста, другой для изображений. При обучении картинка с подходящей подписью должны быть близки, а с неподходящей – максимально далеки в пространстве их векторов (эмбеддингов [6]).
2. Create dataset classifier from label text
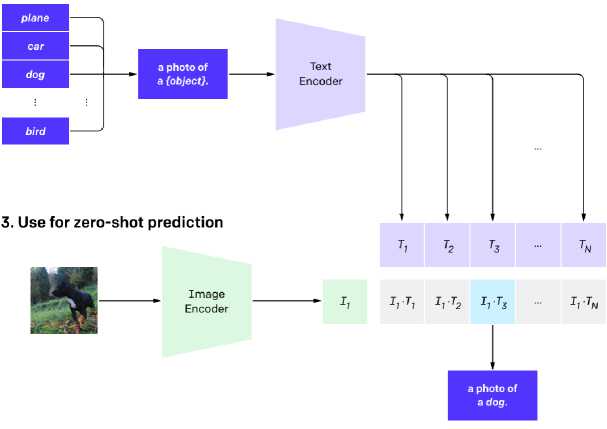
Рис. 2. Пример нахождения пары: текст – рисунок, имеющие минимальное расстояние в пространстве векторов [3]
CLIP отлично подходит для задач "zeroshot" предсказаний. Для того, чтобы создать определить класс изображения или подобрать ключевые слова к нему следует создать набор предложений, например, «A photo of a {object}». Где вместо «object» и будет одно из подбираемых ключевых слов. Набор слов с помощью текстового энкодера можно преобразовать в набор векторов. Далее, изображение с помощью энкодера для изображений также преобразуется в вектор. Если нормировать близость вектора изображений с векторами подбираемых слов, то можно интерпретировать результат как вероятность того, что на изображении находится тот или иной класс (то или иное ключевое слово). В процессе тестирования оказалось, что для многих задач “zero-shot learning“ этот подход работает даже лучше, чем натренированные на распознавание конкретных да-тасетов нейронные сверточные сети [3]. Чтобы еще улучшить качество работы следует давать модели дополнительную подсказку. Например, если мы знаем, что на изображениях животные, то следует это явно задать. Например, «A photo of animal {object}». Или “A photo of a {object}, a type of pet.”
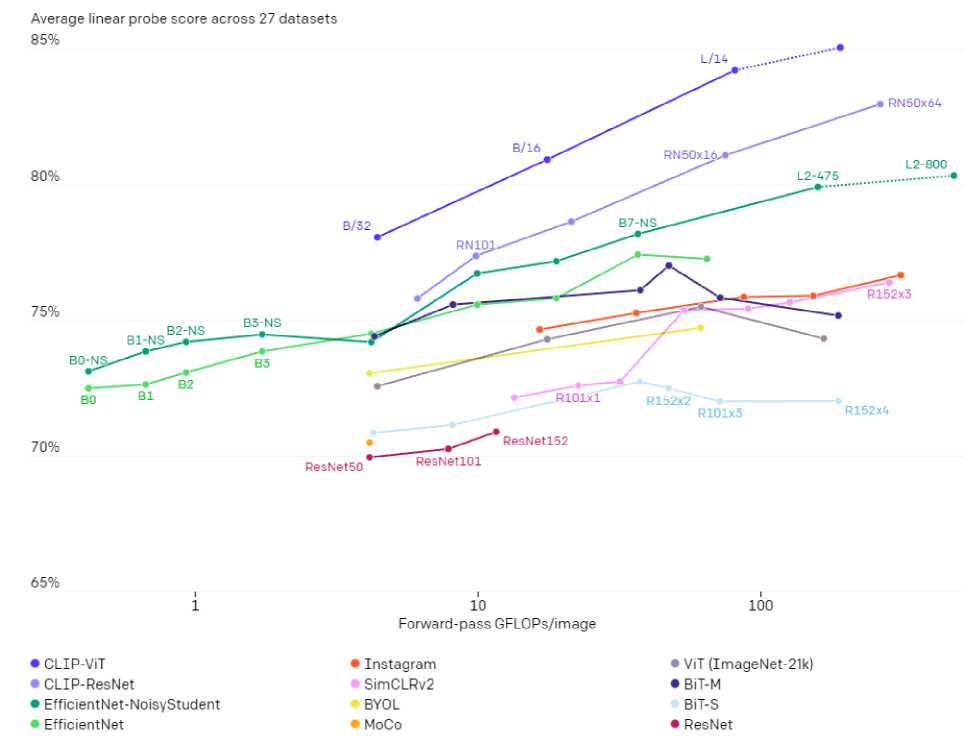
Рис. 3. Модели CLIP также более эффективны в вычислениях, чем модели 10 предыдущих подходов, с которыми проводились сравнение. Средняя оценка на 27 датасетах [3]
Нахождение ключевых слов для изображений
Для выполнения эксперимента выбран датасет изображений: nner и датасет слов:
lish-word-frequency. В нем более 300 тысяч английских слов, что не очень удобно. Для эксперимента взяты 50 тысяч наиболее распространенных слов из английского языка. Модели CLIP доступные для экс- перимента: 'RN50', 'RN101', RN50x4',
'RN50x16', 'RN50x64', 'ViT-B/32', 'ViT-
B/16', 'ViT-L/14'. Перфоманс моделей на 27 датасетах показан на рисунке 3. Для эксперимента выбрана модель ViT-L/14.
Программный код на языке программирования Python с использованием библиотеке ИИ PyTorch для получения текстовых и графических эмбеддингов с использованием видеокарты:
texts = clip.tokenize(word).cuda()
-
# Get Text Embeddings
text_embeddings = model.encode_text(texts)
-
# Preprocess image using clip
img = preprocess(img).unsqueeze(0).cuda()
-
# Get Image embeddings
image_embeddings = mod- el.encode_image(img)
-
# Calc dot product between image and text embeddings
score = float((image_embeddings @ text_embeddings.T).cpu().numpy())
Где word это текстовое описание изображения, например, word = "a photo of {animal}", где в качестве animal – подбираемое слово, а file это путь к файлу с изображением, score это мера близости вектора изображения и вектора описания. В качестве ImageNet использована модель EfficientNetB3 [7], обученная на ImageNet. Предсказание сделано на разрешении 300x300.
Хотя обе модели имеют одинаковую точность на тестовом наборе ImageNet, результаты CLIP гораздо более показательны для того, как она будет работать на наборах данных, которые измеряют точность в различных условиях, не связанных с ImageNet. Например, в датасете ObjectNet проверяется способность модели распознавать объекты в разных позах и на разных фонах внутри домов.
Таблица 1. Результаты работы модели CLIP и EfficientNetB3
|
Изображения |
CLIP ViT-L/14 описание |
ImageNet описание |
|
^^^^^^^^ "^je^^^^^^^l |
a photo of hippo a photo of maternal a photo of mamas a photo of motherhood a photo of mothers a photo of postnatal a photo of maternity a photo of hola a photo of mamma a photo of zoo |
hippopotamus, hippo, river horse, Hippopotamus amphibius pomegranate hog, pig, grunter, squealer, Sus scrofa turnstile grand piano, grand American black bear, black bear, Ursus americanus |

a photo of present a photo of festive a photo of christmas a photo of presents a photo of decorations a photo of expectancy a photo of wishlist a photo of xmas a photo of wrapping a photo of gifts

a photo of carriage a photo of carriages a photo of towing a photo of pulling a photo of horsepower a photo of equine a photo of conveyance a photo of limousine a photo of loaders a photo of plough
Persian cat
Pomeranian
Angora, Angora rabbit hamster
Pekinese, Pekingese, Peke guinea pig, Cavia cobaya
Maltese dog, Maltese terrier, Maltese
Egyptian cat lynx, catamount
West Highland white terrier horse cart, horse-cart plow, plough breastplate, aegis, egis tick thresher, thrasher, threshing ma chine bearskin, busby, shako military uniform fly harvester, reaper football helmet
Заключение
Современные нейросети способны самостоятельно создавать описание и ключевые слова для изображений. Это может применятся для множества разных задач, в частности для классификации и кластеризации. Обучение моделей CLIP на большом объеме данных из интернета, в том числе шумным, дает заметное превосходство над обученными под конкретные классы нейросети (рис. 3). CLIP может быть применен к любому эталону визуальной классификации путем простого указания названий визуальных категорий, которые необходимо распознать, аналогично возможностям в режиме "zero-shot".
Список литературы Методика автоматизированной разметки изображений и нахождения ключевых слов
- He, K., Zhang, X., Ren, S., & Sun, J. (2015). "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification". In ICCV 2015.
- Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S.,.. & Berg, A.C. (2015). "Imagenet large scale visual recognition challenge". In IJCV 2015.
- Radford A. et al. Learning transferable visual models from natural language supervision // International Conference on Machine Learning. - PMLR, 2021. - С. 8748-8763.
- Radford A. et al. Language models are unsupervised multitask learners // OpenAI blog. - 2019. - Т. 1. - № 8. - С. 9.
- Brown T. et al. Language models are few-shot learners // Advances in neural information processing systems. - 2020. - Т. 33. - С. 1877-1901.
- Kiela D., Bottou L. Learning image embeddings using convolutional neural networks for improved multi-modal semantics // Proceedings of the 2014 Conference on empirical methods in natural language processing (EMNLP). - 2014. - С. 36-45.
- Tan M., Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks //International conference on machine learning. - PMLR, 2019. - С. 6105-6114.
