Методы и модели анализа научной деятельности

Автор: Губанов Д.А., Жилякова Л.Ю., Кузнецов О.П., Чхартишвили А.Г.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Методы и технологии принятия решений
Статья в выпуске: 4 (58) т.15, 2025 года.
Бесплатный доступ
Статья посвящена описанию методов анализа научной деятельности и созданных на их основе инструментов для принятия обоснованных решений на всех уровнях управления в научной сфере – от отдельных исследователей до руководителей научных организаций. Проведѐн обзор отечественных и зарубежных исследований в области наукометрии, выявлены основные тенденции, а также обозначены пробелы, на устранение которых направлен проект ИПУ РАН по созданию информационной системы анализа научной деятельности. Проект включает разработку моделей, методов и алгоритмов анализа научной деятельности учѐных, организаций, журналов, конференций в области теории управления на основе данных о публикациях. Эта задача решается с помощью междисциплинарного подхода, включающего сетевой анализ, онтологическое проектирование, методы анализа больших данных и машинного обучения, оптимизации. В основе разработанной системы лежит онтология научного знания в теории управления, основные принципы создания и структура которой описаны в статье. В сочетании с технологическими возможностями этой системы представленная онтология позволяет обеспечить высокий уровень детализации анализа, недоступный в других наукометрических системах (Web of Science, Scopus, РИНЦ и др.). Показано, что принципы создания и структура разработанной онтологии переносимы на другие области исследований. Рассмотрены современные методы сбора и представления данных, методы сетевого анализа и анализа содержания научных текстов. Представлены основные подходы, методы и модели анализа научной деятельности, рассмотрено применение этих методов в разработанной информационной системе.
Анализ научной деятельности, теория управления, информационная система, классификация, онтология, тематический профиль, тематическое пространство, термин, обработка текстов, сетевой анализ
Короткий адрес: https://sciup.org/170211139
IDR: 170211139 | УДК: 519.711:001 | DOI: 10.18287/2223-9537-2025-15-4-578-597
Methods and models for the analysis of scientific activity
This article describes methods for analyzing scientific activity and the tools developed on their basis to support informed decision-making at all levels of management in the scientific domain — from individual researchers to the heads of research organizations. A review of domestic and international studies in the field of scientometrics is provided, highlighting key trends and identifying existing gaps that the Institute of Control Sciences of the Russian Academy of Sciences (ICS RAS) project seeks to address through the creation of an information system for the analysis of scientific activity. The project involves the development of models, methods, and algorithms for analyzing the scientific activity of researchers, organizations, journals, and conferences in the field of control theory, using publication data. This problem is approached through an interdisciplinary framework that integrates network analysis, ontological design, big data processing, machine learning techniques, and optimization methods. The proposed system is built upon an ontology of scientific knowledge in control theory, the main principles of its construction and structure being discussed in this article. Combined with the system's technological capabilities, the presented ontology enables a level of analytical detail that surpasses existing scientometric systems (such as Web of Science, Scopus, Russian Science Citation Index, etc). It is demonstrated that the principles underlying the development and structure of the proposed ontology can be applied to other research domains. The paper also considers modern approaches to data collection and visualization, as well as methods of network and content analysis of scientific texts.The main concepts, methods, and models for the analysis of scientific activity are summarized, and their implementation within the developed information system is discussed.
Текст научной статьи Методы и модели анализа научной деятельности
Рост количества научных журналов и увеличивающиеся темпы роста числа научных публикаций затрудняют полный охват информации даже в узких областях науки. Специалисты в одной и той же предметной области не всегда могут узнать друг о друге. Проблемы возникают у редакторов журналов при поиске рецензентов, у организаторов конференций при рассылке приглашений, у лиц, принимающих управленческие решения в научной деятельности (НД). Из-за неравномерного представительства журналов из разных дисциплин при разделении на квартили авторы не всегда могут найти высокорейтинговые журналы для публикации своих результатов [1]. С развитием информационных и телекоммуникационных технологий всё большие объёмы данных становятся доступными в электронном виде, что открывает большие возможности для автоматизации сбора, структурирования и обработки информации, создания моделей анализа, прогнозирования, планирования и поддержки принятия решений в области управления НД.
Вследствие этого актуально создание систем, автоматизирующих получение информации об объектах НД (публикациях, авторах, научных журналах, организациях, конференциях и др.) на основе анализа публикаций. Такие системы можно разделить на две группы. Хорошо известны базы Web of Science, Scopus, РИНЦ, Google Scholar, ResearchGate, OpenAlex и др., их главная цель – анализ цитируемости публикаций, на основе которого вычисляются наукометрические оценки публикаций и их авторов (индекс Хирша), а также научных журналов (импакт-фактор). Более сложными и менее исследованными являются задачи анализа содержания научных текстов. Систем такого рода гораздо меньше. Можно отметить систему Semantic Scholar (, специализирующуюся на компьютерных науках и медицине, а также разработку iFORA , которая работает не только с научными публикациями, но и с патентами, бизнес-аналитикой и др.
В настоящей статье дан обзор методов и систем анализа НД; рассмотрена Информационная система анализа научной деятельности (ИСАНД), разработанная в ИПУ РАН [6]. Её основу составляет онтология наук об управлении [7, 8]. На основе классификатора ИСАНД разработан новый тематический класс «Теория управления» в Государственном рубрикаторе научно-технической информации (ГРНТИ) [9], который появится в открытом доступе в следующей редакции ГРНТИ под номером 42.
1 Управление научной деятельностью: обзор основных подходов
Для управления наукой требуются комплексные модели НД, интегрирующие методы наукометрии, сетевого анализа (СА), теории управления. В качестве объективной оценки работы учёных, журналов, научных коллективов, школ, организаций используются наукометрические показатели [10, 11]. Термин «наукометрия» в русскоязычных исследованиях был введён в 1969 г. [12] и не потерял своей актуальности спустя десятилетия [13]. В настоящее время исследованиям по наукометрии посвящены периодические научные журналы: “ Scientometrics ” ( Springer ), “ Quantitative Science Studies ” ( MIT Press Direct ), “ Journal of Informetrics ” ( ScienceDirect ), «Управление наукой и наукометрия» (РИЭПП), «Библиосфера» (ГПНТБ СО РАН) и др.
Большой потенциал в наукометрии и управлении НД имеет применение аппарата сетевых наук. С их помощью становятся возможными исследование возникающих научных связей, явных и неявных сообществ, поиск наиболее влиятельных учёных и научных школ и решение других задач, которые можно сформулировать в рамках сетевой парадигмы. Начало этому направлению положили статьи [14-16]. В обзоре [17] используется рекурсия (исследуется развитие области СА): построена сеть соавторства более 50 тысяч учёных, занимающихся сетевыми науками; проанализирована её топология и динамика; исследованы модели сотрудничества и структурные свойства сети соавторства; определены ведущие авторы, крупнейшие сообщества; проведено сравнение свойств сети с наукометрическими показателями.
В настоящее время наукометрия включает ряд методов СА [18]: определение центральности узлов (обзор методов определения центральности см. в [19]) для поиска ключевых авторов и публикаций, влияющих на развитие области исследования [20, 21], кластерный анализ в сетях [22] и его адаптация к наукометрическим сетям [23-25], визуализация связей [26, 27], определение плотности сети и др.
Объёмный наукометрический анализ литературы по теме «научные социальные сети» проведён в [28]. Программная статья [29], посвящённая эволюции сетей научного сотрудничества, процитирована около четырех тысяч раз. Исследованию научных социальных сетей ( LinkedIn, ResearchGate, Academia.edu, Mendeley ) посвящена статья [30]. Научным взаимодействиям в научных сетях посвящено большое количество работ (см., напр., [31-33]). Как правило, в исследованиях рассматриваются отдельные области науки [34, 35], отдельные научные и исследовательские заведения [36, 37]; в [38] проведён анализ гендерного распределения авторов научных публикаций; глобальное гендерное неравенство в науке исследуется в [39]. Исследование научных социальных сетей позволяет представить структуру научного сообщества, выявить влиятельных авторов и организации, проследить возникновение и развитие сотрудничества.
Отдельной областью исследований является анализ индексов цитирования и их влияния на научные сети, который имеет важное значение в оценке научного влияния и создании баз данных (БД) для СА. К основным наукометрическим индексам относятся: для авторов - индекс Хирша ( h -индекс) и его модификации ( g -индекс и i -индекс); для журналов - показатели, отражающие среднее количество цитируемости недавних статей (к ним можно отнести им-пакт-фактор и SiteScore ). В [40] сравниваются различные модификации индекса Хирша на примере данных из области биомедицины; в [41] приведён обзор исследований по цитированию авторов. В [42] приводится сравнение показателей и цитирования с междисциплинарной точки зрения. В [43] исследуется стратификация сетей соавторства, построенных по данным за 50-летний период, на основе h -индекса. В [44] рассмотрена совместная эволюция сетей соавторства и цитирования, а также их влияние на научные показатели: индекс Хирша автора и импакт-фактор журнала. В [45] предлагается альтернативный индекс, который учитывает семантические связи опубликованных работ в междисциплинарной области знаний, а также цитирование и соавторство учёных, облегчая идентификацию и картирование наиболее релевантных тем и авторов в этой области. Высокую цитируемость имеют обзор литературы по показателям цитируемости [46] и обзор по теории и практике наукометрии [47].
Проблемы, препятствующие развитию наукометрических исследований и научных коммуникаций, и пути их преодоления рассматриваются в [48]. Методика оценки результативности научных организаций представлена в [49], а концептуальная модель системы наукометрического мониторинга результативности НД - в [50]. Задачам управления НД с помощью наукометрического подхода посвящены исследования [51, 52]. Современные подходы в наукометрии изложены в [53]. Международное сотрудничество учёных исследуется в [54, 55], при этом используются новые наукометрические показатели (коцитирование и др.). Анализ количества публикаций и цитирований в различных областях отечественной науки проведён в [56]. Анализу публикаций в информационной системе Math - Net.Ru посвящена работа [57], граф цитирования статей российских математиков приведён в [58]. Обзор литературы о влиянии самоцитирования на возникающие искажения в библиометрическом анализе представлен в статье [59]. Сетевая модель коллаборации учёных приведена в [60]. В ИПУ РАН подготовлен специальный выпуск по наукометрии в журнале «Управление большими системами» [61].
Менее исследованными являются задачи анализа содержания научных текстов. В [62] на основе семантического анализа и анализа социальных сетей предложено прогнозирование успеха научных публикаций. Проведённый на основе набора данных анализ публикаций по химической инженерии за 2010–2012 годы позволил предсказать цитирование через шесть лет после публикации с точностью почти 80%. В [63] исследуются тематики библиометриче-ских исследований посредством сетей цитирования и семантического анализа. Рассмотрено распределение тем научной литературы, в которой используются термины «библиометрия», «наукометрия» и «информетрика». В [64] проводится мета-анализ семантической классификации цитирований на корпусе 60 научных статей в этой области. Исследуются подходы к классификации цитирований на основе их семантического типа. Обзор [65] посвящён кластеризации исследовательских документов на основе семантического анализа и извлечения ключевых слов. Проведён сравнительный анализ алгоритмов извлечения ключевых слов и кластеризации; предложен прототип поисковых систем на основе документов, а также методы семантической классификации исследовательских работ в области компьютерных наук.
Коллективом ФИЦ ИУ РАН разработаны методы семантического анализа научных текстов [66], методы реляционно-ситуационного анализа текстов [67]; интеллектуальная поисковая система Exactus , на основе которой созданы система выявления заимствований в научных текстах Exactus Like [68] и система интеллектуального поиска и анализа научных публикаций Exactus Expert [69] . В [70] представлен прогноз путей развития науки, технологий и инноваций. Представлен подход и инструменты интеллектуального анализа текста для построения карт науки особого вида – «Карты науки в квадрате». Работа [71] посвящена семантическому анализу трудов конференции по семантическому анализу.
Разработанный в Московском государственном университете многоязычный энкодер SciRus - tiny , использующий семантические векторные представления текстов, предназначен для анализа научных текстов и способен осуществлять поиск близких по тематике публикаций [72]. Открытый бенчмарк RuSciBench рекомендован для оценки векторных представлений научных текстов на русском и английском языках из данных библиотеки eLibrary [73].
Выявлению плагиата и нарушения этики публикаций в русскоязычных научных изданиях посвящена статья [74], а выявлению сгенерированных языковыми моделями фрагментов в научных публикациях – работа [75].
2 Онтология наук об управлении
Примером научной области, в которой неудобна одномерная классификация, является теория управления. Неудобства проявляются в работе редакций научных журналов по управлению. Для рецензирования статьи, в которой описывается, например, интеллектуальная система, нужен не только специалист по искусственному интеллекту, но и эксперт, владеющий математическими методами, использованными при описании системы, а также компетентный в предполагаемой сфере применения этой системы.
Подход к решению этой проблемы предложен в ИПУ РАН [7]. Тематическое пространство наук об управлении делится на три области: фундаментальные науки ; прикладные теории и проблемные области ; области приложений . Каждая из этих областей детализируется: среди фундаментальных наук выделяются математика, физика, биология, ..; в проблемных областях - теория автоматического управления, анализ данных, вычислительная техника, .; в сферах приложений - летательные аппараты, медицина, технологические процессы, финансы и др. Фрагмент дерева тематического пространства представлен на рисунке 1. Вершины дерева названы темами . Число уровней дерева и ветвлений вершин зависит от требуемой детализации, но три вершины первого уровня, названные главными , неизменны.
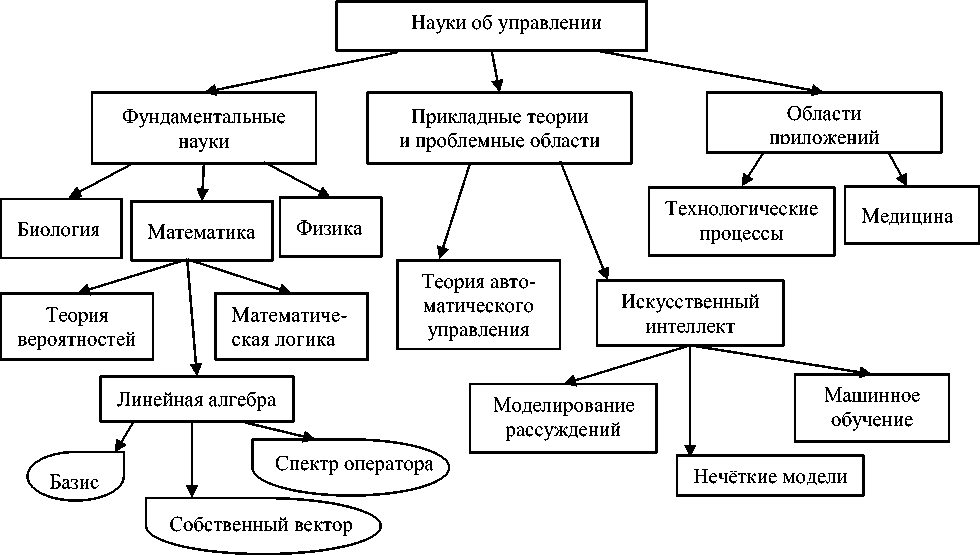
Рисунок 1 - Фрагмент онтологии тематического пространства (прямоугольники - темы и подтемы, листья - термины)
Позиционирование объектов НД в тематическом пространстве многомерно. Как правило, документ (статья, доклад и т.д.) релевантен многим темам, и поэтому он характеризуется вектором релевантностей, который называется профилем документа . Этот вектор представляет собой сечение дерева (не обязательно равномерное по уровням); в каждой точке сечения (теме) стоит число из отрезка [0, 1]; сумма всех чисел равна 1 (вектор - стохастический). Каждое число - степень релевантности документа данной теме относительно других тем.
Для вычисления профиля документа тематическое дерево снабжается словарём: к каждой висячей вершине-теме (и, быть может, к некоторым промежуточным вершинам-темам) присоединяется множество вершин-терминов, характеризующих данную тему. Тематическое дерево вместе со словарём образует онтологию наук об управлении. В этой онтологии смежные вершины-темы связаны отношением класс-подкласс, а смежные вершина-тема и вершина-термин связаны отношением класс-экземпляр. Введение терминов нарушает древовидность онтологии, т.к. термин может относиться к нескольким темам. Метод вычисления профиля документа в [7] основан на частотности содержащихся в нём терминов.
В программной реализации описанной схемы использована база публикаций работников ИПУ РАН. В [7] приведены некоторые данные пробной эксплуатации разработанной системы на материале публикаций журнала «Автоматика и телемеханика». Набор профилей публикаций работника даёт возможность вычислять профиль работника , характеризующий набор его научных интересов и компетентностей. А наличие профилей работников облегчает решение различных задач по управлению НД, таких как назначение рецензентов и экспертов, подбор команды для наукоёмкого проекта и т.д.
Составление словаря - это работа, требующая разнообразных компетенций, охватывающих всё тематическое пространство наук об управлении. Для практического использования онтологии удобно, чтобы тематические профили научных объектов строились на фиксированных уровнях дерева тематического пространства.
3 Методы и модели 3.1 Сбор данных и извлечение информации
Для анализа НД требуются данные о публикациях и связанных сущностях: метаданные статей, сведения об авторах и их аффилиациях, журналах и конференциях, грантах и т.п. Источники данных - коллекции полнотекстовых документов и открытые библиографические базы. Если доступны только полнотекстовые документы, то, как правило, применяются инструменты извлечения метаданных и ссылок. В частности, библиотека GROBID [76] демонстрирует лучшее качество извлечения метаданных и списков литературы среди открытых инструментов. Для специализированных задач могут привлекаться отдельные инструменты (например, Adobe Extract для табличных данных). На практике нередко применяют комбинированные конвейеры: несколько инструментов анализа используются последовательно или параллельно, а результаты объединяются и проходят верификацию экспертом.
В частности, в модуле предварительной обработки данных ИСАНД [6] применяется конвейер на основе GROBID : модель предварительно дообучена на корпусе русскоязычных текстов по теории управления, что позволяет повысить точность извлечения данных.
Открытые агрегаторы научных данных, такие как OpenAlex , предоставляют свободный доступ к информации о публикациях и цитированиях. OpenAlex обеспечивает сопоставимое с коммерческими базами Scopus / Web of Science покрытие цитат (на пересечении их корпусов) и индексирует существенно больше журналов открытого доступа (34 тыс. в OpenAlex , 6 тыс. в WoS и 7 тыс. в Scopus на 2024 год) [77]. Качество и полнота метаданных могут различаться по дисциплинам, поэтому целесообразна оценка покрытия БД для конкретной предметной области [77, 78]. В ИСАНД выполняется сбор данных из нескольких источников (в том числе OpenAlex ), что повышает полноту базы. Каждый источник вносит вклад в общий граф знаний, при этом при загрузке данных в ИСАНД помечается происхождение метаданных.
Ключевая задача при сборе данных - объединение записей об одном объекте (авторе, организации) из разных источников. Внедрение уникальных идентификаторов научных объек- тов – ORCID для авторов, Research Organization Registry (ROR) для организаций и др. – упрощает эту задачу. В частности, в Crossref поддерживаются ROR-идентификаторы фондов, это позволяет унифицировать сведения о грантодателях (см. . Для полного автоматического разрешения неоднозначности требуются специальные алгоритмы и эталонные наборы данных. Создаются бенчмарки для сравнения методов идентификации авторов по метрикам точности [79]. В ИСАНД применяется алгоритм объединения записей на основе полученных из разных источников идентификаторов объектов: ORCID, DOI, Researcher ID, Scopus Author ID, ROR и др.
-
3.2 Структурирование и представление метаданных
-
3.3 Анализ текстов научных публикаций
Собранные данные о публикациях и связях между ними необходимо представить в удобной для анализа форме. Для этого используются реляционные схемы данных, которые обеспечивают целостность и эффективный доступ к данным, но не являются гибкими (например, при добавлении новых сущностей) и не предназначены для представления сетевых структур (например, для поиска цепочки сотрудничества между учёными).
Графовая модель данных позволяет отразить экосистему науки как сеть объектов. В такой модели любые научные объекты – публикации ( D ), исследователи ( A ), организации ( O ), конференции ( C ), ключевые термины ( T ) и др. – можно представить как вершины графа ( v G V), а отношения между ними - как рёбра ( е = (v,, v) G Б). Можно определить сеть НД как ориентированный граф G = ( V, Б), где V - объединение множеств разных сущностей, а Е содержит несколько подмножеств Ег,Е 2 , ■■■ типов связей. Например, если А - множество авторов, D - множество публикаций, то подграф соавторства можно задать как Gauth = (А ,Еаиth), где каждое ребро е = ( а,,а) G Еаиth означает совместную публикацию автора at с автором а.. Аналогично, граф цитирования задаётся как ориентированный граф Gсt1 = (D,ЕСi t ), где дуга ( dt ^ dj) G Ec11 означает цитирование работы dj в работе d , . Эти специализированные графы можно анализировать раздельно, однако полное представление даёт интегрированная сеть, включающая все типы объектов и связей. В интегрированном представлении множество вершин V = А U D U О U Т U .„, а каждое ребро помечено типом (например: «автор – статья»; «статья цитирует статью»; «статья содержит термин»; «автор работает в организации» ). Этот граф можно воспринимать как многослойную сеть науки: каждый тип связи образует свой слой, но объекты (вершины) одни и те же и могут соединять слои [80]. Для учёта групповых отношений, когда единицами анализа выступают не пары, а группы объектов, применяются гиперграфы. Гиперребро может связывать, например, множество авторов а^, а2 ,...,ак, совместно написавших статью (это единое событие, связывающее всю группу). Гиперграфы усложняют математический аппарат анализа, но способны представить коллективные взаимодействия напрямую, без разбиения их на парные взаимодействия .
Преимущество графового представления – возможность хранить и обрабатывать всю структуру отношений. Добавление новой сущности или типа связи не требует доработки схемы данных – достаточно ввести новый тип узла или ребра. Запросы к графу могут гибко следовать по любым цепочкам связей: например, можно запросить «найти путь от автора А к автору Б через цепочку совместных работ и цитирований длиной не более 4» или «найти всех авторов, статьи которых процитированы в журнале В». Подобные запросы сложно выразить на языке SQL в реляционной БД, тогда как графовые базы имеют для этого оптимизированные языки (Gremlin, Cypher, SPARQL и др.) и алгоритмы обхода графов. Сформировались две основные парадигмы для работы с графовыми данными. Первая – семантические сети, основанные на стандартах RDF/OWL (Resource Description Framework/Web Ontology Language). Семантические хранилища поддерживают язык запросов SPARQL, позволяют ис- пользовать онтологии и выполнять логический вывод. Вторая парадигма – графы свойств [81], в которой узлы и связи могут иметь произвольные свойства (атрибуты), а схема данных часто гибридна. В ИСАНД [6] для хранения и обработки данных о НД используется семантическое хранилище, схема которого задаётся онтологией OWL.
Анализ содержания научных публикаций позволяет определить тематику работ и измерить их семантическую близость. Публикацию можно представить в виде вектора признаков (профиля), отражающего распределение тем или терминов, разными способами: с помощью классификаторов; тематического моделирования; нейросетевых векторных представлений.
Первый способ – заранее создать онтологию или рубрикатор научных тем и на их основе классифицировать тексты [82, 83]. В частности, в системе ИСАНД используется разработанный экспертами словарь, покрывающий ключевые понятия (термины) заданной научной области. Это позволяет каждому научному объекту ставить в соответствие стохастический вектор р = (р х ,р 2 ,^,р п ) в пространстве из п предопределённых тематических категорий, где рi > 0 отражает степень принадлежности объекта к теме i. В ИСАНД профили рассчитываются на основе онтологии наук об управлении. Каждая загруженная в систему публикация автоматически анализируется: производится лемматизация, извлекаются ключевые слова, соотносятся с терминами тезауруса, формируется тематический профиль . Профили хранятся как атрибуты соответствующих узлов (публикаций, авторов, организаций), что позволяет быстро сравнивать объекты по их тематическим векторам. Для измерения близости профилей используется косинусное сходство или метрика на основе -нормы, например расстояние для двух публикаций d 1 и d 2 : d(p (dl) ,p (d2) ) = | £ i |р (dl) — p (d2) |. Близкие по тематике публикации будут иметь близкое к 1 значение. Это даёт возможность улучшать поиск и рекомендации: в ИСАНД реализованы методы поиска экспертов для рецензирования, поиска тематически близких исследований и т.д.
В противоположность априорному заданию тем методы тематического моделирования позволяют автоматически извлекать темы из массива текстов. Наиболее известный метод – LDA ( Latent Dirichlet Allocation ) и его варианты [84, 85]. Основная гипотеза LDA : существует некоторое (заданное числом ) количество скрытых тем, каждая из которых характеризуется статистическим распределением слов P(w\z), а каждый документ есть смесь этих тем с определёнными весами вd = P(z\d). Параметры модели (распределения P(w\z ) и вd для всех документов) оцениваются по набору текстов с помощью стохастических методов. В результате работы алгоритма получается набор из тем – списков слов с указанием вероятностей P(w\z i ). Одновременно для каждого документа получается распределение dd = (р (z l \d), .^,p(z k \d )), которое является тематическим профилем этого документа для выявленных алгоритмом тем, не привязанных к каким-либо заранее заданным категориям. Тематические модели хорошо подходят для первичного анализа корпуса, когда заранее может быть неизвестно, какие тематические кластеры присутствуют. Тематическое моделирование часто применяется для анализа научной литературы, в т.ч. кластеризации публикаций [86] и отслеживания эволюции научных направлений [87].
Можно использовать векторные представления текстов на основе предобученных языковых моделей [88]. Эти модели преобразуют текст статьи в плотный вектор ∈ℝ (эм-беддинг), располагая близкие по смыслу публикации рядом в пространстве эмбеддингов (даже если они не имеют общих ключевых слов). Используя эмбеддинги, можно решать разные задачи, в частности проводить тематическую кластеризацию публикаций [89]. Недостатки нейросетевых эмбеддингов и тематического моделирования – отсутствие учёта дрейфа пред- метной области (поскольку обучающая выборка фиксирована) и сложность интерпретации признаков эмбеддинга.
Для решения конкретных научных задач используются специальные методы анализа текстов . В частности, методы извлечения терминов и ключевых слов [90], автоматического реферирования [91], анализа интенции цитирования [92-94], выявления новых научных направлений [95]. Эти методы позволяют составить тезаурус, облегчить анализ больших коллекций работ и оценить влияние научной работы по характеру цитирования. Большие языковые модели активно исследуются, но их применение для анализа НД сопряжено с рисками генерации некорректной информации [96]. Поэтому их следует воспринимать как вспомогательный инструмент для эксперта.
-
3.4 Сетевой анализ
Сетевые модели фокусируются на структуре научного сообщества и коммуникаций в нём. Сеть соавторства – неориентированный граф, в котором узлы – авторы, а рёбра соединяют соавторов одной публикации. Анализ такой сети позволяет найти научные группы, научные школы, «мосты» между научными группами, определить силу связей между исследователями и т.п. Сеть цитирования – ориентированный граф, в котором узлы – статьи (или другие научные объекты), а ребро → означает, что работа A цитирует работу B . Граф отражает информационные потоки, позволяет находить наиболее влиятельные публикации и научные направления, строить карты знаний по цитируемости. В зависимости от цели исследования строятся и другие виды научных сетей: граф аффилиации (автор – организация), граф сотрудничества организаций, граф терминов (термин – узел, совместная встречаемость терминов – связь). Эти представления можно рассматривать как проекции единой многослойной сети НД.
Такой подход позволяет выявлять явные и скрытые закономерности, в т.ч. структуру коллабораций, центры влияния, междисциплинарные связи. Типовые задачи СА: идентификация ключевых узлов / расчёт влиятельности узлов – поиск наиболее значимых учёных, работ, организаций по различным показателям [10, 97]; обнаружение неформальных сообществ – разбиение сети на плотные кластеры (например, выявление тематических или географических научных групп) [98]; рекомендация и прогноз связей – выявление потенциальных связей (для эффективного сотрудничества учёных, для тематического дополнения работ и т.п.) [99]; анализ динамики – исследование эволюции сети во времени (например, для оценки роста новых направлений) [100].
В теории сложных сетей разработан широкий спектр мер центральности (более 400) (см. [101]), позволяющих ранжировать узлы по их значимости [102]. Мера центральности – это функция , которая каждому узлу сети ставит в соответствие действительное число. Простейшая мера CD(y ) = d ед (у) - степень вершины v Е( (число связей узла). В контексте науки степень автора в графе соавторства равна числу его соавторов, а степень статьи в графе цитирования – числу её входящих ссылок (цитируемость) либо исходящих (число цитат). Высокая степень означает активное участие объекта в научной коммуникации. Более сложные меры учитывают глобальные свойства. Например, посредничество С((у) показывает, через какие узлы проходят кратчайшие пути в сети: узел с высоким посредничеством служит «мостом» между частями графа. Такой узел может указывать на учёного, соединяющего разные научные сообщества, или работу, цитируемую разными областями, или метод оценки влияния на основе причинно-следственных отношений [103]. Эти показатели позволяют количественно определить наиболее влиятельных учёных, публикации, организации. Библио-метрические индексы можно рассматривать как частные случаи мер центральности, однако сетевые показатели дают более полную картину, с учётом всей структуры графа цитирова- ния. Современные обзоры подтверждают продуктивность сетевого подхода для оценки научного вклада учёных [104].
Важная задача СА - выявление сообществ в сетях . Сообществом называют подмножество тесно связанных узлов [98]. Для нахождения сообществ ищется разбиение множеств узлов f:V ^ {1, ...,К} (количество сообществ K не фиксируется). Для автоматического обнаружения сообществ применяются алгоритмы кластеризации графов, которые обычно оптимизируют модульность - меру Q E [-0,5; 1], сравнивающую плотность внутри кластера с ожидаемой в случайной модели [105]. Методы итерационного укрупнения графа, такие как алгоритм Лувена и его модификации [106], гарантируют получение более связных кластеров. Выявленные в сетях соавторства сообщества помогают обнаружить коллаборации и скрытые социальные структуры (например, научные школы). Кластеры в сети цитирования зачастую соответствуют направлениям исследований.
Методы прогнозирования связей [99] позволяют определить, какие связи являются скрытыми или какие связи появятся в будущем (потенциальных соавторов, сотрудничество между группами). В случае со скрытыми связями используется следующая постановка задачи: пусть истинная сеть G* = (V, Е* ) наблюдаема частично G o bs = (V,E ob s ), где E o bs £ Е * , необходимо восстановить E*\E 0bs. Для определения потенциальных связей используются меры сходства узлов u,v EV в графе [99], в частности, мера Adamic / Adar :
Saa (u,v) - E ze г мп ГО) 10 gde5(z) .
Актуально направление анализа динамики сетей [100]: изу чается, как изменяется структура сети со временем G)) - например, растёт ли связность научного сообщества, увеличивается или уменьшается фрагментация по группам, как влияют коллаборации на последующую цитируемость работ. Такие исследования находятся на стыке с социологией науки и позволяют делать выводы о тенденциях в организации НД.
-
3.5 Интеграция методов анализа текстов и анализа сетей
Сетевые методы дают в распоряжение исследователей мощный инструментарий для структурного анализа науки [104]. Однако графы не позволяют учитывать смысловое содержание: статьи могут быть связаны через общих авторов или цитирование, но иметь разную тематику. Методы анализа текстов сосредоточены на тематике (на смысле). Их ограничения - отсутствие учёта социальной структуры (исследователи могут быть тематически близки, но в сети находятся далеко друг от друга), значительные затраты на подготовку данных (очистка текста, лемматизация, обучение моделей) и обработку корпусов, особенно полнотекстовых. Предпочтительна интеграция подходов для одновременного учёта того, кто с кем взаимодействует, и о чём ведутся исследования. В частности, комбинация признаков социальной сети и семантики текста позволяет предсказывать цитируемость с точностью около 80% [62]. В [107] показано, что качество профилей научных объектов можно улучшить, если учесть связи авторства между объектами. В ИСАНД все данные хранятся в виде графа (что даёт возможность выполнять СА - обход связей, расчёт центральностей и пр.), при этом каждый узел снабжён тематическим профилем. Это позволяет выполнять комбинированные запросы и аналитические сценарии. Например, при поиске рецензента можно отобрать кандидатов по близости профилей и выбрать тех, у кого высокие показатели влияния в сети.
4 Основные характеристики разработанной информационной системы
ИСАНД предназначена для обеспечения исследователей, научных коллективов и организаторов науки средствами анализа НД и содержит данные о различных научных объектах .
Основой ИСАНД являются массивы публикаций, загружаемые из внешних источников – крупных БД научных материалов. Поскольку одна и та же публикация нередко индексируется в разных системах, в ИСАНД предусмотрена возможность выявления и фиксации дубликатов. То же относится и к другим научным объектам, например авторам или организациям: один и тот же объект может иметь разные представления в разных источниках. Для случаев, когда вероятность совпадения велика (например, у авторов один и тот же уникальный цифровой идентификатор ORCID ) в системе указывается, что объекты являются дубликатами. Отношение «является дубликатом» считается симметричным и транзитивным.
Особенностью ИСАНД является наличие оригинального классификатора , который задаёт структуру тематического пространства теории управления. Каждый научный объект в этой системе описывается как вектор в многомерном пространстве, и его можно считать точкой в стандартном симплексе соответствующей размерности. Такой подход обеспечивает корректное сравнение объектов и позволяет применять различные методы анализа.
Структура классификатора имеет три основных уровня. Первый уровень - это факторы , которые отражают укрупнённые области исследований, например «Управление в организационных системах». Второй уровень образуют подфакторы , детализирующие тематику в рамках факторов, например «Управление в сетевых структурах». Третий уровень представляет собой набор конкретных терминов , например, «Социальное влияние».
Для каждого научного объекта в ИСАНД строятся три вида тематических профилей: базовый профиль на уровне факторов; детализированный профиль на уровне подфакторов; профиль терминов . На каждом уровне строится профиль каждой публикации и проводится расчёт профиля для других объектов на основе публикаций, связанных с этими объектами: профиль автора на основе его публикаций (с учётом количества соавторов каждой публикации), профиль журнала на основании опубликованных в нём статей и т.п. С их помощью в ИСАНД осуществляется поиск публикаций, авторов и других научных объектов.
На множестве тематических профилей введена метрика, позволяющая рассчитывать расстояние (от 0 до 1) между научными объектами и находить тематически близкие объекты. Например, исследователь может искать все публикации, находящиеся в тематическом пространстве не далее, чем на расстоянии 0,2 от его собственной работы. В специализированных запросах и сценариях поиска (кого пригласить для рецензирования публикации, кому направить приглашение на конференцию и т.д.) пользователь может самостоятельно задавать радиус тематической окрестности научного объекта (область точек, которые находятся от научного объекта на расстоянии не больше заданного). Алгоритмы расчёта профилей и расстояний между ними описаны в [6].
Заключение
В статье описана Информационная система ИСАНД в области теории управления и сделана попытка поместить её в более широкий контекст мировой науки о науке - как наукометрии, так и анализа текстов и СА, выявляющих ключевые темы и термины публикаций, взаимосвязи между учёными, организациями и конференциями. Представленный подход к построению онтологии наук об управлении позволяет позиционировать объекты (публикации, их авторов, журналы, конференции и научные организации) в многомерном тематическом пространстве. ИСАНД потенциально представляет собой многофункциональную систему, которая объединяет онтологическую основу, массивы данных и математический аппарат анализа. Информационная система ИСАНД призвана обеспечить исследователей и управленцев инструментами для информационного поиска, изучения НД и принятия обоснованных решений в организации и управлении НД.
