Методы и технологии полуавтоматического структурирования и оценки текста научной статьи: обзор и перспективы разработки информационной системы

Автор: Александр Александрович Толстенко, Екатерина Владимировна Исаева
Журнал: Вестник Пермского университета. Математика. Механика. Информатика @vestnik-psu-mmi
Рубрика: Компьютерные науки и информатика
Статья в выпуске: 1 (72), 2026 года.
Бесплатный доступ
В статье описывается проблема получения своевременной и качественной обратной связи по научной статье от рецензентов и рассматривается целесообразность применения ИИ для ее решения. Приводится системное описание существующих коммерческих и исследовательских решений для структурирования и оценки качества текста (Writefull, Grammarly, Quillbot, ChatGPT и др.), анализируются их преимущества и недостатки. Изучаются различные подходы и архитектуры и выполняется сравнение эффективности их использования в задаче структурирования и оценки текста научной работы. В качестве целевой структуры научной статьи выбрана IMRAD, обладающая универсальностью, гибкостью и возможностью применения в различных областях. На основе выполненного анализа сформулированы требования к системе структурирования и оценки текста научной статьи. Предлагается модульная секционно-ориентированная архитектура информационной системы, интегрируемой в текстовый редактор. Система состоит из четырех модулей: "Шаблоны предложений", "Оценка структуры текста", "Оценка стиля текста" и "Оценка понятности и логичности текста". Особенностью архитектуры является использование ИИ-агентов (экземпляры большой языковой модели) для анализа отдельных аспектов текста с сохранением контекста каждого раздела структуры IMRAD (введение, методы, результаты, обсуждение). Обсуждаются технические и методологические ограничения реализации подобных систем. Представленное исследование может стать основой для разработки информационной системы, которая может быть полезна образовательным учреждениям для обучения академическому письму.
Структурирование и оценка качества текста, , обработка естественного языка, NLP, большие языковые модели, LLM, академическое письмо, искусственный интеллект
Короткий адрес: https://sciup.org/147253758
IDR: 147253758 | УДК: 004.89 | DOI: 10.17072/1993-0550-2026-1-131-143
Methods and Techniques for Semi-Automatic Structuring and Evaluation of the Text of a Scientific Article: Review and Prospects for the Development of Information System
The article describes the problem of obtaining timely and high-quality feedback on scientific articles from peer-reviewers and considers the feasibility of using AI to solve it. A systematic description of existing commercial and research solutions for structuring and text quality evaluation (Writefull, Grammarly, Quillbot, ChatGPT, etc.) is provided, their advantages and disadvantages are analyzed. Various approaches and architectures are studied, and their effectiveness in structuring and evaluating scientific texts is compared. IMRAD was chosen as the target structure for scientific articles due to its versatility, flexibility, and applicability in various fields. Based on the analysis, requirements for a system for structuring and evaluation of the scientific article text were formulated. A modular section-based architecture of an information system integrated into a text editor is proposed. The system includes four modules: "Sentence Templates", "Text Structure Evaluation", "Text Style Evaluation", and "Text Clarity and Logic Evaluation". A distinctive feature of the proposed architecture is the use of AI agents (instances of a large language model) to analyze individual aspects of the text while taking into an account the context between sections of the IMRAD structure (introduction, methods, results, discussion). Technical and methodological limitations of implementing such systems are discussed. The presented study can serve as a basis for the development of an information system.
Текст научной статьи Методы и технологии полуавтоматического структурирования и оценки текста научной статьи: обзор и перспективы разработки информационной системы
Лицензировано по CC BY 4.0. Чтобы посмотреть копию этой лицензии, посетите
Академическое письмо является одним из самых важных навыков в научной сфере наравне с профильными дисциплинами. Без умения четко, ясно и аргументированно описать проведенное исследование невозможно донести полученные результаты до широкой аудитории. Освоение данного навыка студентом или аспирантом – достаточно длительный процесс, так как требует не только постоянной практики, но и обратной связи от научного руководителя, преподавателя и рецензентов. И если объем практики зависит напрямую от студента/аспиранта, то получение конструктивной и развивающей обратной связи, особенно от рецензентов, может сильно растянуться во времени. Связано это в первую очередь с увеличением количества отправляемых научных работ. Например, по официальному заявлению организаторов конференции "Neural Information Processing Systems" в 2025 году было подано 21575 статей, в то время как в 2020 году заявок было всего 9467 [1]. Если учесть, что каждую статью проверяют три рецензента в течение минимум одного часа, то получается, что на проверку всех отправленных в 2025 году работ было затрачено не меньше семи лет экспертного времени. Очевидно, что в таких условиях у рецензентов нет возможности быстро дать обратную связь.
Решением данной проблемы может стать искусственный интеллект (ИИ), который является одной из самых популярных и быстро развивающихся технологий нашего времени. Нейронные сети, а особенно большие языковые модели (LLM), находят применение не только в повседневной жизни, но и в научной деятельности. Наиболее показательным примером является программа на основе ИИ "AlphaFold", которую использовали для решения задачи предсказания структуры белка. Данный подход стал революционным в структурной биологии и материаловедении, и открыл новые возможности для создания лекарств [2, с. 5].
Помимо решения узкоспециализированных задач активно исследуется возможность использования ИИ в академическом письме. Например, Weixin Liang и др. использовали GPT-4 для рецензирования научных статей и определили, что "обратная связь, сгенерированная большой языковой моделью схожа с той, что исследователь может получить от рецензентов" [3, с. 4]. Телицына А. Ю в обзорной статье приходит к выводу, что "инструменты, основанные на ИИ, могут анализировать написанный текст и предлагать улучшения, например, по структуре, ясности изложения и устранению повторов" [4, с. 225]. К похожим выводам пришли Adam Cheng и др . : "Наиболее этичным применением ChatGPT является изменение структуры ранее написанного текста или существующих идей, включая грамматику и орфографию, понятность и перевод на другой язык" [5, с. 5]. Всё это позволяет предположить, что на основе большой языковой модели можно построить систему, которая будет выступать в роли помощника-рецензента при работе с текстом научной работы.
В данной статье предпринимается попытка системного описания методов для анализа структуры и качества текста научных работ и определения возможности создания систем, способных выступать в роли рецензентов. Таким образом, целью статьи является обзор современных методов и технологий для автоматической структурностилистической оценки научных работ и формирования рекомендаций по улучшению текста статей. Для достижения данной цели решаются следующие задачи:
-
1) определение целевой структуры текста научной работы;
-
2) формализация задач, решаемых системой оценки текста научных работы;
-
3) анализ существующих моделей и инструментов, применяемых для анализа и улучшения качества и структуры текста;
-
4) описание архитектуры возможной информационной системы;
-
5) выявление ограничений существующих технологий и определение направлений дальнейшего развития.
Реализация этих задач позволит сформулировать требования к информационным системам оценки текстов научных работ, определить возможности и ограничения практического применения в обучении и научной деятельности.
Определение целевой структуры научной статьи
Соблюдение строгой структуры научной работы – это базовое требование. Рецензенты и редакторы сильно ограничены во времени и ожидают определенного стандарта от анализируемой работы. Четкая структура статьи упрощает чтение, помогает быстро находить нужную информацию и критически оценивать каждую часть работы по-отдельности: оценить методы, валидировать полученные результаты и обоснованность выводов.
Одним из общепринятых и универсальных стандартов структуры научных работ является IMRAD. В 1980-х гг. данный формат был самым распространенным и фактически единственным стандартом в научных статьях [6]. Согласно исследованию Moskovitz C. и др. к 2024 году структуры IMRAD строго придерживаются почти во всех работах по биологии и медицине (94%) и примерно в половине статей в инженерных и социальных науках (40%) [7]. Таким образом, IMRAD остается одним из самых распространенных форматов академического письма в настоящее время. Популярность данного формата обусловлена его универсальностью и гибкостью, так как он задает логические правила структурирования текста, которые не зависят от области исследования. Единственным ограничением структуры IMRAD можно считать ее нацеленность на эксперименты, что с одной стороны обеспечивает воспроизводимость исследования, а с другой – ограничивает область применения STEM дисциплинами, т.е. относящимися к науке (Science), технологии (Technology), инженерии (Engineering) и математике (Mathematics).
Структура IMRAD состоит из четырех основных разделов: введение (Introduction), методы (Methods), результаты (Results) и обсуждение (Discussion). Классическая структура обычно дополняется аннотацией, заключением и списком использованных источников. Во введении необходимо обозначить проблему, обосновать актуальность исследования, сформулировать основную цель и четко обозначить что будет сделано. В разделе методы требуется описать использованные процедуры, инструменты, материалы, данные и методы обработки данных, чтобы читатель мог повторить эксперименты и получить такой же результат. Раздел результаты должен содержать полученные результаты (качественные и количественные показатели) исследования в удобном для изучения виде (графики, таблицы), но без развернутой интерпретации. В обсуждении приводится интерпретация полученных результатов в контексте обозначенной проблемы. В этом разделе также выполняется сравнение результатов с работами других исследователей, анализируются ограничения текущего исследования и формулируются предложения для будущих работ.
Как было отмечено ранее, в строгом виде данной структуры придерживаются в основном только в области биологии и медицины. В остальных доменах исследователи заменяют методы на несколько узкоспециализированных разделов, а обсуждение объединяют с выводами/заключением и/или выносят ограничения в отдельную главу. Важно отметить, что такие статьи все равно будут соответствуют требованиям IMRAD, пусть и в неявном виде, так как логика повествования от дробления разделов не меняется.
Таким образом, широкое распространение, независимость от области исследования и гибкость использования в сочетании с четко обозначенной логикой повествования позволяют выбрать структуру IMRAD в качестве целевой в информационной системе структурно-стилистической оценки текста научных работ.
Обзор методов анализа текста
Текущий прогресс в области обработки естественного языка (NLP) предоставляет эффективный инструментарий для автоматизации процесса написания и редактирования текста, в том числе в академическом стиле. Большие языковые модели и инструменты на их основе позволяют перефразировать готовый текст и оценивать:
-
1) логичность повествования и соответствие определенной структуре;
-
2) понятность и легкость восприятия;
-
3) соответствие заданному стилю (академическому, юридическому, художественному и т. д.).
В рамках представленного далее обзора описаны существующие подходы и решения для автоматического анализа текста научных работ.
Одним из готовых инструментов для академического письма является Writefull. В основе данного инструмента лежат большие языковые модели, обученные на большом количестве рецензируемых научных статей, находящихся в открытом доступе. Благодаря этому данный инструмент может выполнять следующие функции в контексте академического письма:
-
1) выполнять поиск грамматических и стилистических ошибок и опечаток;
-
2) перефразировать предложения, изменять стиль и тон текста;
-
3) генерировать аннотацию, ключевые слова и заголовок на основе аннотации и текста.
Несмотря на обширный функционал, разработанный специально для научного сообщества, данное решение проблематично использовать при написании статьи на русском языке, так как по следующим причинам:
-
1) LLM обучены только на англоязычных статьях и не учитывают специфику русского языка, особенно в научной литературе;
-
2) система обрабатывает текст на иностранных серверах, что ставит под угрозу конфиденциальность данных.
Помимо Writefull для работы с текстом активно используются и другие готовые инструменты: Grammarly, Quillbot и ChatGPT. Tokdemir Demirel проанализировал, какие функции данных сервисов студенты используют при написании текстов, и определил, что чаще всего ChatGPT, Grammarly и Quillbot используются для "исправления грамматических и орфографических ошибок (83,3% опрошенных), выбора более подходящих слов (68,1% опрошенных) и улучшения структуры предложения (58,3% опрошенных)" [8, с. 16]. Данная статистика подтверждается исследованием Khalifa M., согласно которому ИИ лучше всего справляется с задачами структурирования, редактирования (улучшение качества и исправление ошибок) и рецензирования текста [9]. Эффективность использования Grammarly и ChatGPT для структурирования текста, исправления грамматических ошибок и улучшения связности и стилистическое единообразия текста подтверждает и Granjeiro J. M. и др. [10]. Однако вместе с тем отмечается, что данные сервисы плохо справляются с узкоспециализированными научными терминами [10]. Как и Writefull, все перечисленные системы требуют отправки текста на их серверы, что ставит под сомнения безопасность их использования.
Одним из способов решить проблему с данными – самостоятельно разработать систему на основе обученной модели и разместить ее на собственном компьютере или сервере.
Примером создания системы на основе обученных моделей (ChatGPT-3 и ChatGPT-3.5-turbo) является Manubot AI Editor [11]. Pividori M. и Greene C. предложили секционно-ориентированный подход для анализа текста статьи и пришли к выводу, что "модели понимают основные идеи текста и вносят изменения, которые часто более четко и лаконично передают заложенный смысл" [11, с. 15]. Основная идея секционноориентированного подхода заключается в анализе каждого раздела статьи по-отдельности: на вход модели подается текст секции и инструкция на естественном языке (промпт) с подробным описанием того, что необходимо проанализировать и по каким критериям. Основным ограничением данного подхода авторы отмечают невозможность сохранения контекста между разделами: из-за того, что секции анализируются по-отдельности, система, например, не учитывает контекст "Методов" при анализе "Результатов".
Современные решения не ограничиваются только большими языковыми моделями. Сейчас все большую популярность набирают решения на основе ИИ-агентов, такие как MARG [12], AgentReview [13] и Agent Laboratory [14]. В данных системах под агентом имеются в виду один экземпляр GPT-4 (может быть использована любая LLM) с отдельной историей сообщений и промптов. Основная идея заключается в том, что каждый агент специализируется на каком-то одном аспекте: дизайне экспериментов, ясности изложения или новизне результатов. Использование нескольких агентов в рамках одной системы позволяет генерировать более точные и полезные комментарии. Авторы MARG таким образом добились снижения количества общих комментариев с 60% до 29% [12]. Основным недостатком агентных систем является вычислительная сложность и высокая стоимость, так как система генерирует в несколько раз больше токенов и увеличивает общее время обработки одной статьи.
Несмотря на заметную эффективность ИИ в работе над текстами научных работ, есть ряд ограничений и недостатков, которые необходимо учитывать при проектировании систем оценки текста.
Одной из таких проблем являются слишком поверхностные правки, которые не учитывают содержания абзаца/раздела/статьи. Chen и др. в своем исследовании продемонстрировали, что GPT-4o на запрос отредактировать абзац с проблемами в аргументации просто "улучшил читаемость текста, но не устранил проблему с логическим обоснованием выводов, оставив абзац все таким же неубедительным" [15, с. 2].
Также отмечают, что большинство ИИ-решений не учитывает итеративную природу работы с текстом, а, наоборот, предполагают однократное внесение изменений. Эффективность использования итеративного подхода с учетом вносимых изменений демонстрируется в работах [16, 17]. Nguyen A. и др . в рамках исследования определили, что студенты, применяющие итеративный подход при использовании ИИ для написания статей, демонстрируют значимо более высокие результаты [17].
Наибольшие опасения у исследователей вызывает снижение оригинальности и критического мышления при активном использовании искусственного интеллекта. Promethi Das Deep и Yixin Chen признают эффективность таких решений как Grammarly, QuillBot и ChatGPT, но в то же время обращают внимание на то, что "студенты становятся зависимыми от ИИ-инструментов, из-за чего пропадает необходимость развития собственных навыков" [18]. Поэтому ИИ в контексте работы с текстом должен восприниматься как вспомогательный инструмент, а не полная замена человека.
Результаты
В результате анализа возможностей и ограничений современных инструментов и методов работы с текстами были сформулированы основные требования к системе оценки текстов научных работ:
-
1) система должна состоять из модулей, каждый из которых отвечает за один аспект оценки текста: структуру, соответствие стилю, качество, понятность и т. д. Каждый модуль может быть представлен ИИ-агентом на базе большой языковой модели;
-
2) система должна обнаруживать проблемы как в самом тексте, так и в его структуре, но не должна самостоятельно их исправлять. Результатом работы системы должен быть отчет с описанием каждой обнаруженной ошибки и рекомендациями по их исправлению. Важно, чтобы пользователь самостоятельно анализировал и исправлял найденные ошибки;
-
3) система должна анализировать текст по секциям, учитывая при этом контекст других секций. Например, при анализе "Результатов" или "Обсуждения" необходимо обязательно учитывать "Методы";
-
4) система должна предоставлять возможность пользователю итеративно работать с текстом, т. е. учитывать ранее обнаруженные и исправленные проблемы;
-
5) целевой структурой системы должна быть структура IMRAD;
-
6) языковые модели, лежащие в основе системы, должны поддерживать русский язык и быть достаточно небольшими, для того чтобы их можно было использовать на собственном компьютере/сервере.
В соответствии с перечисленными требованиями была спроектирована архитектура системы оценки текстов научных работы, состоящая из 4 модулей. Систему предлагается реализовать в виде надстройки для текстового редактора, чтобы сразу интегрировать инструмент в процесс написания текста научной работы.
Модуль 1 "Шаблоны предложений" – русскоязычный аналог "Sentence Palette" из Writefull. Данный модуль содержит список предложений-шаблонов, отсортированных по разделам IMRAD. Система автоматически вставляет выбранный шаблон в место, где установлен курсор пользователя. Прототип данного модуля реализован в виде надстройки Microsoft Word. Внешний вид и пример работы надстройки представлены на Рис. 1. Модуль "Шаблоны предложений.
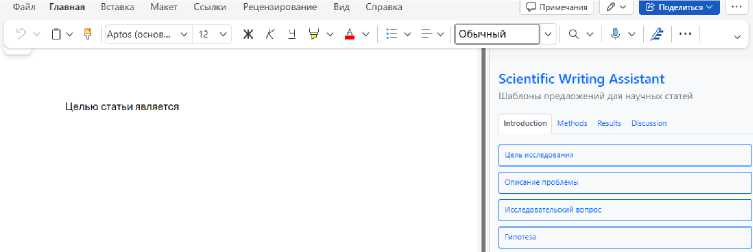
Рис. 1. Модуль "Шаблоны предложений"
Предполагается, что данный модуль будет использоваться на ранних этапах работы с текстом научной статьи. Как только пользователь решит, что текст статьи готов и его можно передавать на проверку, он может воспользоваться модулями 2–4.
Модуль 2 " Оценка структуры текста " , модуль 3 " Оценка стиля текста " и модуль 4 " Оценка понятности и логичности текста " являются отдельными экземплярами большой языковой модели, т. е. агентами. Перед тем, как запустить какой-либо из этих модулей, система выполняет поиск разделов IMRAD по текущему тексту. В результате выполнения данного шага система определит, какие разделы текста какому элементу IMRAD соответствуют. Затем пользователь выбирает, оценка какого характера ему нужна: анализ стиля, структуры или логики повествования. От выбора пользователя зависит, какой модуль будет запущен.
Для оценки структуры текста запускается модуль 2, который последовательно анализирует каждый раздел на соответствие IMRAD. Анализ секций выполняется по порядку " введение – методы – результаты – обсуждение " для того, чтобы при анализе каждого следующего раздела учитывался контекст предыдущего, и все последующие рекомендации были сформированы с учетом уже сгенерированных. Для того чтобы работа модуля и критерии оценки были понятными для пользователей, и что не менее важно, чтобы результат оценки был воспроизводимым, предлагается составить список требований в формате чек-листа для каждого раздела IMRAD. Этот чек-лист необходимо использовать в промпте, который отправляется в модуль при его запуске вместе с текстом статьи. Приведем пример промпта для раздела "Обсуждение":
"Требуется:
-
1. Определить, присутствуют ли в тексте ключевые элементы обсуждения:
-
1.1. интерпретация основных результатов и ответы на вопросы/гипотезы, заявленные во введении;
-
1.2. сравнение с результатами других исследований (сходства, различия, возможные причины);
-
1.3. обсуждение ограничений исследования;
-
1.4. предложения по направлениям дальнейших исследований;
-
-
2. Оценить, не содержит ли этот раздел " чистых " результатов, которые требуется перенести в секцию " Результаты " ;
-
3. Дать оценку полноты и качества " Обсуждения " и предложить конкретные шаги по улучшению структуры и содержания " .
В ходе работы модуль сформирует отчет с результатами анализа структуры текста и рекомендациями по ее улучшению. Отчет состоит из 5 разделов: " Введение " , " Методы " , " Результаты " , " Обсуждение " и " Общий вывод и оценка " . В первых четырех секциях указано, каким требованиям IMRAD текст статьи соответствует, а каким нет и почему. В финальном разделе дается общая оценка в формате " плохо соответствует " , " соответствует частично " , " полностью соответствует " с коротким пояснением, описываются сильные стороны текущей структуры и основные проблемы, а также рекомендации по их устранению. Отчет выводится пользователю в отдельном окне.
Пользователь анализирует полученный отчет, вносит соответствующие правки в текст статьи и может запустить повторную проверку, которая учитывает результат предыдущей проверки и внесенные изменения. При повторном запуске в промпт автоматически добавляется фраза о необходимости учета предыдущих правок и изменений.
Модуль 3 и модуль 4 работают точно так же, как и модуль 2. Отличаются только промпты, требования в них, и, как следствие, наполнение отчета с результатами оценки и рекомендациями (структура отчета такая же). При необходимости можно запустить все три модуля одновременно, так как результаты их работы никак не зависят друг от друга.
Для наглядного представления структуры, компонентов и используемых методов на рис. 2 приведена блок-схема системы, включающей ключевые модули и механизмы взаимодействия с пользователем.
Обсуждение
Несмотря на значительный прогресс в области обработки естественного языка, существующие решения и инструменты, все еще имеется ряд технических ограничений, которые предстоит решить в будущем.
Одним из очевидных ограничений на данный момент является недостаточная специализация предобученных LLM на академическом письме и предметной области. В первую очередь это проявляется в поверхностных комментариях, которые относятся к форме предложения, а не к его содержанию. Данную проблему можно решить, дообучив модель на специальном наборе данных. Однако сбор и разметка такого дата-сета, как и обучение большой языковой модели, являются очень дорогими и энергозатратными процессами.
Другим серьезным ограничением является дороговизна использования эксплуатация системы с несколькими агентами, так как необходимо одновременно содержать несколько экземпляров LLM. Каждый агент при этом последовательно обрабатывает все секции научной работы, из-за чего для обработки одной статьи требуется большее количество токенов и времени. Для решения данной проблемы можно попробовать использовать квантованные LLM, т. е. уменьшенные версии моделей. Так как при уменьшении модели качество и точность ее работы снижаются, требуется провести дополнительные исследование, чтобы определить максимально облегченную версию, способную качественно решать поставленную задачу.
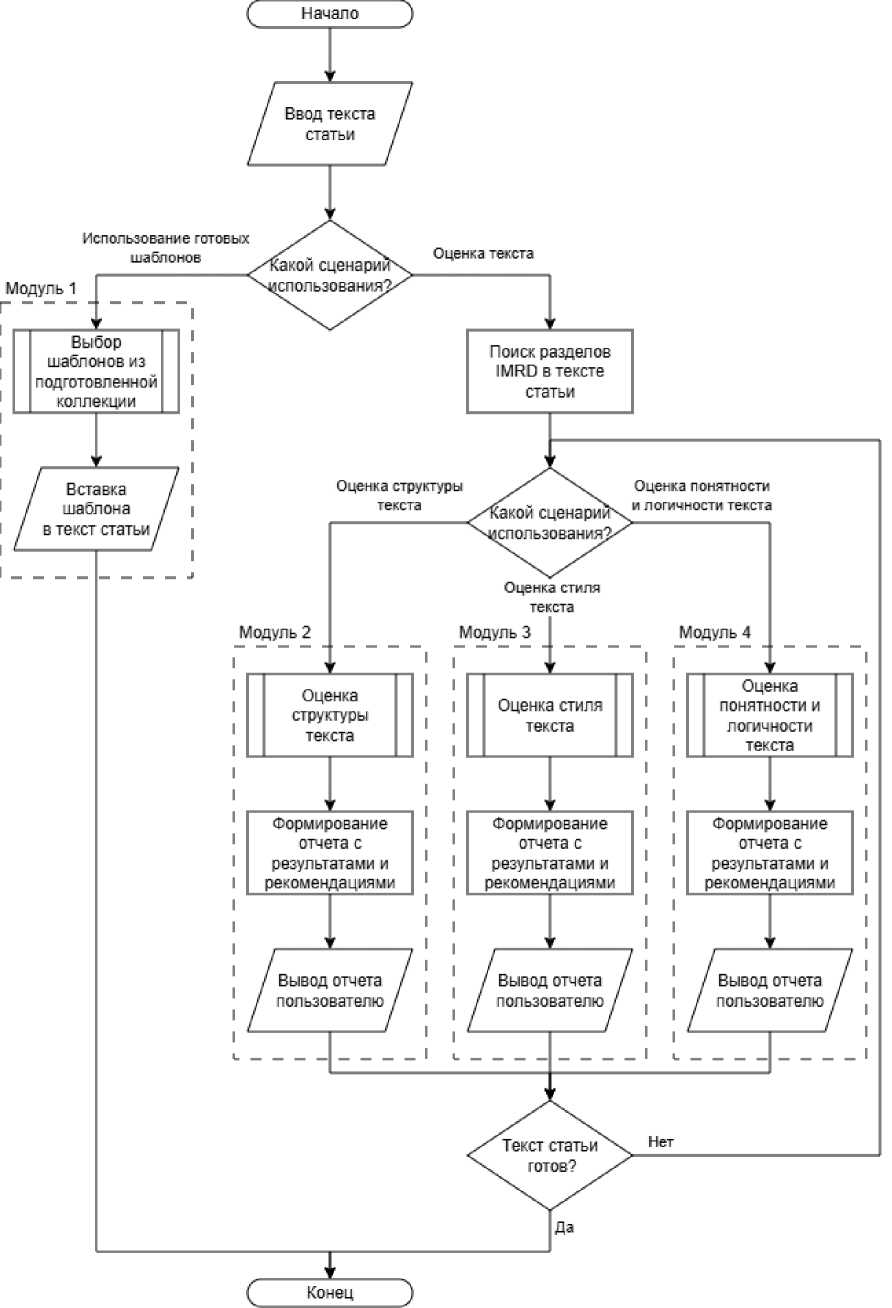
Рис. 2. Блок-схема прототипа предлагаемого решения
Одним из наиболее серьезных препятствий, которое необходимо преодолеть для решения поставленной задачи, является сложность количественной оценки корректности и качества работы системы. На данный момент нет общепринятой метрики, с помощью которой можно измерить работу системы и сравнить с аналогичными инструментами. В качестве решения данной проблемы можно попробовать использовать метрики из области машинного перевода. Например, BLEU, METEOR, ROUGE или TER. Для расчета данных метрик, помимо исходного текста и сгенерированной обратной связи от системы, необходима также эталонная обратная связь от экспертов. Подготовка такого набора данных также является препятствием для реализации системы.
Однако, даже с учетом всех перечисленных ограничений, предлагаемое решение может существенно повысить эффективность работы с текстом научной работы, в связи с представленными ниже обоснованиями:
-
1) система позволяет быстро и объективно оценить структуру, логику и понятность написанного текста и получить рекомендации по его доработке; важно, что она не исправляет работу за пользователя, а, наоборот, мотивирует его итеративно дорабатывать текст;
-
2) прозрачность и понятность критериев оценки ускоряет освоение и совершенствование академического письма пользователем;
-
3) интеграция решения в текстовый редактор делает процесс написания статьи плавным и " бесшовным " , так как пользователю не нужно делать лишних действий: копировать текст, открывать другое приложение или сервис, вставлять в него статью и ждать ответа от приложения; то есть система позволяет полностью сосредоточиться над формой и содержанием работы и не рассеивать внимание на посторонние сервисы;
-
4) модуль " Шаблоны предложений " позволяет преодолеть внутренний барьер, который мешает начать работу ( " боязнь чистого листа " ), знакомит пользователя с устоявшимися и общепринятыми формулировками, а также задает нужный тон и стиль повествования.
Таким образом, разработка эффективной системы требует не просто интеграции большой языковой модели в текстовые редакторы, но еще и разработки методологии, в центре которой должно быть раскрытие потенциала исследователя, обеспечение прозрачности и улучшение качества научной коммуникации.
Выводы
Текущий прогресс в области искусственного интеллекта уже сейчас делает возможной автоматизацию процесса оценки текста и структуры научных работ. Современные большие языковые модели с открытыми лицензиями, такие как DeepSeek-V3, Qwen-3 или Mistral, уже сейчас позволяют без дополнительного обучения решать задачи, которые не требуют глубокой экспертизы в рассматриваемой области. Например, оценивать структуру, стиль и понятность текста. Тем не менее, на данный момент LLM не могут полностью заменить рецензентов, особенно при оценке новизны и значимости исследования.
Однако перед широким внедрением систем оценки текста необходимо преодолеть существующие проблемы и ограничения: требования к вычислительным ресурсам для обучения и работы моделей, недостаток наборов данных на русском языке, отсутствие единого подхода к оценке качества работы модели. Перед использованием данных систем важно также учитывать и этические вопросы, связанные со сценарием использования и влиянием на критическое мышление в долгосрочной перспективе.
Решение данных вопросов требует дальнейших исследований и разработки методологии использования ИИ в академическом письме и образовательном процессе в целом.
Искусственный интеллект уже стал неотъемлемой частью нашей жизни, поэтому критически важно научиться максимально этично и эффективно использовать его в обучении и научной деятельности.
