Методы машинного обучения как инструмент повышения эффективности работы государственных бюджетных учреждений, уполномоченных на проведение государственной кадастровой оценки

Автор: Бабкин Павел Сергеевич, Ермоленко К.Ю.
Журнал: Имущественные отношения в Российской Федерации @iovrf
Рубрика: Экономика и управление народным хозяйством
Статья в выпуске: 2 (233), 2021 года.
Бесплатный доступ
В статье рассматриваются задачи, которые при проведении государственной кадастровой оценки (ГКО) могут решаться с привлечением методов машинного обучения, в том числе задача автоматического определения тематики обращений об исправлении ошибок, допущенных при определении кадастровой стоимости. Основное внимание уделяется проблеме классификации объектов недвижимости при массовой оценке. Приводятся результаты применения описанных методов в государственном бюджетном учреждении Московской области, уполномоченном на проведение ГКО. Предлагаются направления дальнейшего развития предложенных алгоритмов.
Использование нейронных сетей при государственной кадастровой оценке, классификация объектов недвижимости, кодирование объектов недвижимости, автоматизация в государственном управлении
Короткий адрес: https://sciup.org/170191077
IDR: 170191077
Methods of machine learning as a tool for increasing the efficiency of the work of state budgetary institutions authorized to perform state cadaster assessment
The article discusses the tasks that, when conducting a state cadastral valuation, can be solved using machine learning methods, including the problem of automatically determining the topic of requests for correcting errors made in determining the cadastral value. The main attention is paid to the problem of classifying real estate objects in mass appraisal. The results of applying the described methods in the state budgetary institution of the Moscow region, authorized to conduct a state cadastral valuation, are presented. Directions for further development of the proposed algorithms are proposed.
Текст научной статьи Методы машинного обучения как инструмент повышения эффективности работы государственных бюджетных учреждений, уполномоченных на проведение государственной кадастровой оценки
Предпосылки применения методов машинного обучения в деятельности государственных бюджетных учреждений (далее – ГБУ), уполномоченных на проведение государственной кадастровой оценки (далее – ГКО), обусловлены следующими особенностями деятельности учреждений:
-
1) методические указания требуют определения специальных кодов (код расчета вида использования земельных участков, код подгруппы объектов капитального строительства) для отнесения объектов к той или иной расчетной группе;
-
2) кодирование объектов недвижимости, таким образом, является одним из основных этапов при проведении кадастровой оценки – кодировка определяет расчетную группу, следовательно, применяемый метод расчета и соответствующий набор ценообразующих факторов;
-
3) специфика процесса кадастровой оценки (подготовка к этапу ГКО – проведение ГКО – непрерывный процесс оценки вновь образованных объектов и объектов с изменившимися характеристиками) позволяет хорошо адаптировать модели машинного обучения с учителем для решения ряда рутинных задач. В течение этапов под-
готовки и проведения ГКО формируются наборы данных, которые впоследствии могут рассматриваться как обучающие выборки. Дополнительным фактором, обуславливающим необходимость автоматизации, являются ограниченные сроки проведения оценки (особенно при оценке в рамках части 9 статьи 24 и статьи 16 Федерального закона от 3 июля 2016 года № 237-ФЗ «О государственной кадастровой оценке» (далее – Закон № 237-ФЗ), что, в свою очередь, приводит к существенному росту влияния человеческого фактора как с точки зрения возможных ошибок, которые становятся неизбежными в условиях ограниченного времени, так и с учетом временны ́ х затрат на подготовку и обучение новых сотрудников.
Цель настоящей работы – определить круг задач, которые могут быть решены методами машинного обучения, а также представить результаты применения подобного подхода при проведении кадастровой оценки на территории Московской области.
Среди типичных направлений деятельности ГБУ, в рамках которых могут успешно применяться методы машинного обучения с использованием крупных наборов данных, можно выделить следующие:
-
1) кодирование объектов недвижимости (земельных участков и объектов капитального строительства);
-
2) кодирование объектов, предоставляющих рыночную информацию (объектов-аналогов);
-
3) определение тематики обращений об исправлении ошибок, допущенных при определении кадастровой стоимости, которые поступают в ГБУ в соответствии со статьей 21 Закона № 237-ФЗ.
Исследование возможности автоматизации процесса кодирования объектов недвижимости, подлежащих кадастровой оценке, на мой взгляд, следует начинать с земельных участков. Для целей кадастровой оценки, являющейся массовой оценкой, в которой, как правило, не учитываются индивидуальные характеристики объектов, основные характеристики, определяющие вид использования земельных участков, содержатся в Едином государственном реестре недвижимости (далее – ЕГРН). К ним относятся вид использования участка по документу, вид использования в соответствии с классификатором Федеральной службы государственной регистрации, кадастра и картографии (далее – Росреестр) и вид использования в соответствии с классификатором видов разрешенного использования, утвержденным приказом Министерства экономического развития Российской Федерации от 1 сентября 2014 года № 540 «Об утверждении классификатора видов разрешенного использования земельных участков» (далее – Приказ № 540). Отчасти использование участка может определяться присвоенной ему категорией земель. В связи с этим следует отметить эволюцию понятия «фактическое использование земельного участка» в нормативных документах, регулирующих методику кадастровой оценки.
В соответствии с первой редакцией Методических указаний о государственной кадастровой оценке [3] под видом использования объекта недвижимости понималось его использование в соответствии с фак- тическим разрешенным использованием. При этом фактическим разрешенным использованием считалось фактическое (текущее) использование объекта недвижимости, не противоречащее установленным требованиям к использованию объекта недвижимости. Другими словами, для отнесения объекта к той или иной группе было важно определить его фактическое использование, что часто бывает затруднительным с использованием только данных ЕГРН.
В новой редакции Методических указаний [4] под видом использования понимается вид разрешенного использования земельного участка, определенный в отношении такого объекта недвижимости и зафиксированный в ЕГРН по состоянию на дату определения кадастровой стоимости. Таким образом, методически закреплена достаточность сведений ЕГРН для определения вида использования объекта недвижимости.
В отличие от видов разрешенного использования земельных участков сведения о виде использования объектов капитального строительства (назначение зданий и сооружений, их наименование и т. п.) имеют менее структурированный и полный характер, что зачастую не позволяет определить, к какой расчетной группе следует отнести объект, без использования дополнительной информации. По этой причине оценить возможность автоматической кодировки целесообразно в первую очередь на земельных участках.
Предварительным подходом к кодировке земельных участков традиционно является использование справочников, сформированных на основе кодировки при проведении ГКО. Справочники показывают удовлетворительный результат в случае соответствия комбинации видов использования и категории земель у новых объектов тем сочетаниям, которые встречались ранее. Дополнительные трудности возникают при появлении технических ошибок (опечатки, лишние символы, ка- вычки и т. п.) в написании видов использования, которые не являются справочными значениями.
Методы машинного обучения (нейронные сети) позволяют более гибко реагировать на изменения сочетаний значений факторов, определяющих виды использования объектов недвижимости, а использование методов предварительной обработки текстов решает проблему технических ошибок. В качестве базовой модели нейронной сети, предназначенной для кодирования земельных участков, выбрана многослойная полносвязная сеть (многослойный перцептрон) 1. Ядро сети состоит из нескольких слоев, на каждом из которых осуществляются последовательные преобразования исходных данных.
В качестве исходных данных для системы кодирования земельных участков выбраны следующие характеристики:
-
1) площадь земельного участка. Как показали эксперименты, более устойчивых результатов удается добиться в том случае, если вместо непосредственного значения площади передавать на вход системы один из диапазонов площади, который соответствует объекту. В качестве таких диапазонов были выбраны следующие интервалы: до 3 000 кв. м, от 3 000 до 10 000 кв. м, от 10 до 100 тыс. кв. м, более 100 тыс. кв. м;
-
2) категория земель;
-
3) вид разрешенного использования по документу;
-
4) вид разрешенного использования по классификатору Росреестра;
-
5) набор адресных характеристик объекта недвижимости – адрес и тип населенного пункта.
Следует отметить, что вид использования участка в соответствии с классификатором видов использования, утвержденным Приказом № 540, на стадии обучения нейронной сети не использовался, так как для объектов, подлежащих ГКО в Московской области, этот фактор был заполнен менее, чем у 5 процентов объектов. В последующей практической эксплуатации нейронной сети этот вид использования может применяться для объектов, у которых отсутствует значение вида использования по документу.
Результатом обработки перечисленных исходных данных для каждого объекта является набор пар значений: код расчета вида использования и соответствующая ему вероятность. Перечень возможных кодов расчета приведен в Приложении № 1 к Методическим указаниям о кадастровой оценке. Вероятность кода представляет собой некоторое нормированное в интервале [0,1] значение, которое можно интерпретировать как степень достоверности того, что земельный участок принадлежит классу земельных участков, имеющих такой же код расчета вида использования.
Обучение модели осуществлялось на совокупности земельных участков, участвовавших в ГКО в Московской области, проведенной в 2018 году. Исходная выборка состояла из 3,8 миллиона участков, которая была разделена на обучающую (50 процентов от исходной выборки), тестовую (30 процентов) и проверочную (20 процентов). Обучающая выборка предназначена для подбора параметров нейронной сети, тестовая выборка используется для независимой от данных, использованных при обучении модели, проверки качества полученной модели. Проверочная выборка используется для настройки параметров алгоритма оптимизации нейронной сети.
Построенная на основе данных ГКО нейронная сеть показала точность кодирования земельных участков на уровне 90 процентов. Для проверки качества модели и уточнения некоторых особенностей классификации продемонстрируем результаты кодирования земельных участков, которые поступали в ГБУ Московской области в течение 2019 года, для расчета кадастровой стоимости в соответствии со статьей 16 Закона № 237-ФЗ. При этом в качестве дан-
1 Haykin. S. Neural networks and learning machines. 3rd ed. Pearson. 2009. С. 937.

ных для проверки были отобраны только земельные участки, которые поступили впервые, то тесть модель их не «видела» ни в каком качестве – ни в обучающей, ни в тестовой, ни в проверочной выборках. Общий объем такой выборки составил 145 тысяч земельных участков. Для наглядности результаты сгруппированы по сегментам земельных участков. Методическими указаниями определено 14 сегментов, при этом к 14-му сегменту относятся участки, использование которых установить не удалось, поэтому в дальнейшем такие объекты учитываться не будут.
Укрупненная группировка участков по сегментам удобна тем, что в рамках одного сегмента применяются схожие методы моделирования кадастровой стоимости, используются общие ценообразующие факторы, поэтому отнесение объекта к конкретному сегменту в значительной степени определяет метод расчета и порядок получаемой кадастровой стоимости. Исключением является сегмент № 6 «Производственная деятельность» (нумерация сегментов соответствует нумерации, установленной в Методических указаниях [4]), к которому относятся участки с существенно различающимися видами использования. Помимо объектов традиционного производственно-складского назначения, в этот сегмент включены объекты обеспечивающих производств, в том числе объекты коммунального хозяйства, объекты сельскохозяйственного производства (которые, как правило, располагаются на землях сельскохозяйственного назначения), объекты придорожного сервиса (которые в рыночной оценке обычно относятся к объектам коммерческого назначения), линейные объекты (магистральные сети инженерных коммуникаций, автодороги и т. п.), а также земли общего пользования. Для того чтобы выделить перечисленные виды использования земельных участков, сегмент № 6 условно разделен на шесть подсегментов:
-
6.1 – производственно-складская деятельность;
-
6.2 – обеспечение сельскохозяйственного производства;
-
6.3 – коммунальное обслуживание;
-
6.4 – придорожный сервис;
-
6.5 – линейные объекты;
-
6.6 – земли общего пользования.
На рисунке 1 в графическом виде представлены значения доли успешного отнесения земельных участков к каждому сегменту. Под успехом для целей проводимого анализа понимается случай, когда
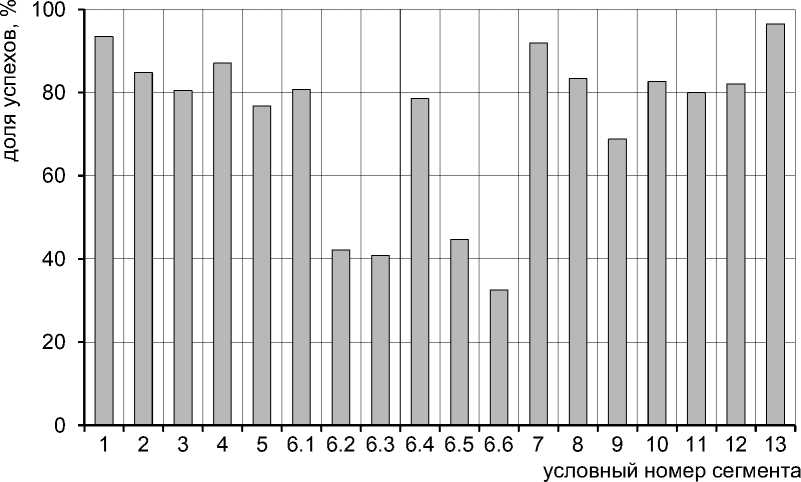
Рис. 1. Доля успешного кодирования земельных участков
код расчета вида использования земельного участка, классифицированный с помощью нейронной сети, совпал с кодом расчета, который был независимо присвоен сотрудниками ГБУ. Поскольку при кодировании объектов в рамках статьи 16 Закона № 237-ФЗ сотрудниками, осуществляющими кодирование, значительное внимание уделяется вопросам уточнения фактического использования объектов, код расчета, присвоенный вручную, будет считаться правильным.
Как видно из графика, представленного на рисунке 1, для большинства сегментов доля успешного кодирования превышает 80 процентов, что свидетельствует о достаточно высоком качестве работы нейронной сети. Общая точность кодирования составила 93 процента, что соответствует уровню точности, достигнутом на этапе обуче- ния модели. Следует отметить, что высокое итоговое значение достигается за счет самого массового сегмента – сегмента № 13 «Садоводческое, огородническое и дачное использование, малоэтажная жилая застройка». Тем не менее для некоторых из выделенных из шестого сегмента подсегментов (6.2, 6.3, 6.5 и 6.6) точность классификации оказалась достаточно низкой. Для уточнения причин таких отклонений следует провести более развернутый анализ и определить, между какими сегментами возникает основной дисбаланс. Удобным инструментом такого анализа является матрица ошибок.
Матрица ошибок представляет собой таблицу, по строкам и столбцам которой указываются классы объектов, то есть в рассматриваемом случае – условные номера сегментов земельных участков. Строкам
Таблица 1
Матрица ошибок классификации при кодировании земельных участков, %
|
Классифицированный сегмент |
||||||||||||||||||
|
1 |
2 |
3 |
4 |
5 |
6.1 |
6.2 |
6.3 |
6.4 |
6.5 |
6.6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
|
1 |
93 |
4 |
1 |
|||||||||||||||
|
2 |
85 |
7 |
2 |
1 |
3 |
|||||||||||||
|
3 |
1 |
81 |
2 |
3 |
4 |
4 |
2 |
|||||||||||
|
4 |
2 |
87 |
2 |
3 |
2 |
|||||||||||||
|
5 |
3 |
10 |
2 |
77 |
1 |
2 |
3 |
|||||||||||
|
6.1 |
2 |
5 |
81 |
1 |
2 |
2 |
2 |
2 |
1 |
|||||||||
|
5 6.2 |
50 |
5 |
42 |
|||||||||||||||
|
6.3 |
41 |
4 |
41 |
7 |
4 |
|||||||||||||
|
О >§ 6.4 |
10 |
1 |
3 |
79 |
3 |
2 |
||||||||||||
|
5 6.5 |
6 |
8 |
3 |
45 |
29 |
5 |
||||||||||||
|
i 6.6 |
2 |
3 |
2 |
4 |
2 |
1 |
33 |
25 |
25 |
|||||||||
|
та £ 7 |
1 |
2 |
2 |
92 |
||||||||||||||
|
8 |
2 |
6 |
2 |
6 |
2 |
83 |
||||||||||||
|
9 |
3 |
6 |
10 |
69 |
4 |
3 |
4 |
|||||||||||
|
10 |
2 |
4 |
9 |
83 |
||||||||||||||
|
11 |
10 |
10 |
80 |
|||||||||||||||
|
12 |
6 |
2 |
2 |
3 |
82 |
|||||||||||||
|
13 |
1 |
1 |
97 |
|||||||||||||||
соответствует информация о «правильно классифицированных» объектах, то есть об объектах, которые были классифицированы вручную и отнесены к сегменту, соответствующему номеру строки. Аналогичным образом столбцам соответствуют объекты, классификация которых была осуществлена с помощью нейронной сети. На пересечении строки со столбцами матрицы ошибок указывается количество (или доля) объектов, которые относятся к классу с номером строки, а нейронной сетью были отнесены к классу с номером столбца. Диагональным элементам, таким образом, соответствуют правильно классифицированные объекты. В таблице 1 приведена матрица ошибок, в которой указаны доли объектов, отнесенные к сумме количества объектов по строкам матрицы, то есть относительно общего количества объектов, классифицированных вручную (правильный сегмент) к сегменту, указанным по строкам. Такая построчная нормировка позволяет легко и наглядно определить важный показатель качества любой модели классификации – долю ложно отрицательных выводов для каждого класса, то есть оценку вероятности того, что объект, представляющий тот или иной класс, будет отнесен системой к другому классу.
Для наглядности значения, превышающее 20 процентов, выделены более темной заливкой, интенсивность которой зависит от самого значения. В идеальной ситуации, когда алгоритм модели классифицирует объекты так же, как это делается вручную, значения матрицы ошибок располагаются только по диагонали. Также в таблице не приводятся пренебрежимо малые значения менее 0,5 процента.
Из матрицы ошибок видно, что почти все случаи ошибочной классификации в сегменте 6.2 (сельскохозяйственное производство) приходятся на сегмент № 1 «Сельскохозяйственное использование». Это связано с тем, что при ручной кодиров- ке уточняется фактическое использование земельного участка с учетом наличия на нем построек и нахождения его в функциональной зоне, допускающей или не допускающей строительство. Ошибочная классификация для сегмента 6.3 («коммунальное обслуживание») приходится на сегмент № 3 «Общественное использование», к которому также относятся участки, предназначенные для размещения объектов коммунального обслуживания. Например, земельные участки с видом разрешенного использования «коммунальное обслуживание» могут использоваться как для размещения объектов инфраструктуры (например трансформаторной подстанции), так и для размещения зданий для обслуживания граждан в связи с предоставлением им коммунальных услуг (например офисов приема платежей за коммунальные услуги). В первом случае участку должен быть присвоен код расчета вида использования 03:012 («Размещение ОКС в целях обеспечения физических и юридических лиц коммунальными услугами, в частности: котельные, водозаборы, очистные сооружения, насосные станции, трансформаторные подстанции…»), а во втором – 03:013 («Размещение ОКС в целях обеспечения физических и юридических лиц коммунальными услугами») 2. Здесь для уточнения кода расчета следует принять во внимание функциональную зону, в которой находится оцениваемый объект. Первый участок должен находиться в зоне коммунального обслуживания (зона «К» в соответствии с правилами землепользования и застройки территории), а второй – в общественно-деловой зоне (зона «О»). Ошибочные классификации участков сегмента 6.5 («линейные объекты») связаны с сегментом № 7 «Транспорт». Учитывая, что в сегменте 6.5 значительную часть занимают автомобильные дороги, такая ситуация также выглядит закономерной. Ошибки в сегменте 6.6 («земли общего пользования») в равной степени распределились между сегментами № 9 «Охраняемые природные территории и благоустройство» и № 13 «Садоводческое, огородническое и дачное использование, малоэтажная жилая застройка». В сегмент № 9 входят в том числе участки для размещения спортивных и детских площадок в зонах жилой застройки, что также можно считать землями общего пользования, и с точки зрения применяемых расчетов различия в такой классификации можно считать несущественными. Ошибочное отнесение моделью участков, которые фактически являются землями общего пользования в садовых и дачных товариществах, к сегменту № 13 связано с тем, что такие участки часто оформляются с видами разрешенного использования таким же, как и у основных участков товариществ и поселков, а не как территории общего пользования. В отличие от предыдущих случаев выделить такие ошибки с помощью функционального зонирования территории невозможно. В этой ситуации, по всей видимости, можно учитывать графическую информацию (при ее наличии), поскольку для земельных участков, включающих территории общего пользования, характерно большее число поворотных точек, а также большее отношение периметра участка к его площади по сравнению с «обычными» участками.
Таким образом, повышение качества классификации земельных участков с помощью созданной нейронной сети может быть достигнуто за счет использования дополнительной информации в процессе постобработки получаемых результатов. Основными источниками такой информации могут являться:
-
1) правила землепользования и застройки территории (для определения функциональной зоны, в которой находится оцениваемый участок);
-
2) графическая часть перечня объектов, подлежащих кадастровой оценке (для определения геометрических особенностей
участков);
-
3) информация о наличии построек на участках (такая информация может использоваться в графическом и семантическом виде), а также об их характеристиках (для уточнения фактического использования участка).
Для расширения возможностей применения результатов работы нейронной сети в качестве вспомогательного инструмента в систему был встроен механизм определения семантической близости вида разрешенного использования земельного участка по документу одному из видов использования, предусмотренных классификатором видов разрешенного использования, утвержденным Приказом № 540. Дело в том, что Методическими указаниями о государственной кадастровой оценке установлено соответствие между каждым кодом расчета вида использования и кодом вида разрешенного использования из указанного классификатора. Такое соответствие не является взаимно однозначным – один и тот же код классификатора может соответствовать нескольким кодам расчета вида использования. Таким образом, установив, какой из видов разрешенного использования по классификатору наиболее близок виду разрешенного использования по документу кодируемого участка, можно заранее определить набор кодов расчета вида использования для этого участка с учетом выявленной взаимосвязи. В дальнейшем полученный набор используется совместно с набором кодов, выделенных нейронной сетью, для получения итогового кода расчета вида использования.
Следует отметить и то, что изменение нормативной методической базы кадастровой оценки в части изменения подхода к определению фактического разрешенного использования земельных участков, что предусматривается новой редакцией Методических указаний, позволяет для кодирования земельных участков опираться только на сведения ЕГРН, что расширяет возможности применения представленного подхода.
Аналогичная нейронная сеть, предназначенная для определения кода подгруппы объектов капитального строительства (зданий и сооружений), в качестве исходных данных принимает следующие характеристики, содержащиеся в ЕГРН:
-
• вид объекта недвижимости;
-
• площадь;
-
• наименование объекта;
-
• назначение объекта;
-
• адресные характеристики;
-
• этажность объекта.
Следует отметить, что задача кодирования зданий и сооружений значительно сложнее задачи кодирования земельных участков, поскольку схожие описания назначения и наименования могут относиться к объектам совершенно разного класса. Для преодоления этих проблем система кодирования объектов капитального строительства имеет многоступенчатую архитектуру, представляющую собой множество нейронных сетей. На первой ступени с помощью нейронной сети определяется функциональная группа верхнего уровня, к которой может относиться каждый объект (в Методических указаниях определено 10 таких функциональных групп 3). Затем вторая группа нейронных сетей позволяет определить, какой код подгруппы и с какой вероятностью может быть присвоен объекту внутри выделенной функциональной группы первого уровня.
Обучение нейронной сети осуществляется на обучающей выборке, содержащей сведения о 3,2 миллиона зданий и сооружений, участвовавших в ГКО в Московской области в 2018 году. Предварительные результаты проводимых экспериментов показывают, что точность присвоения кода подгруппы варьируется от 75 (индивидуальные жилые дома) до 98 процентов (объекты гаражного назначения).
Методология массовой оценки предполагает широкое использование рыночной информации, основным источником которой являются объявления о продаже тех или иных объектов недвижимости. При этом используемая при определении кадастровой стоимости рыночная информация также должна быть сгруппирована по сегментам и оценочным подгруппам. Таким образом, каждому объекту-аналогу, объявление о продаже которого используется при кадастровой оценке, должен быть присвоен код расчета вида использования. В отличие от объектов оценки, о виде использования которых в ГБУ поступают сведения из ЕГРН, единственной информацией об объектах-аналогах является текст объявления. В этом случае задача автоматического кодирования сводится к задаче обработки текста для получения кода расчета вида использования.
Учитывая специфику сформулированной задачи, в общем виде система кодирования объектов-аналогов может быть представлена как следующая последовательность операций:
-
1) предварительная подготовка текста объявления, которая включает:
-
1.1) проверку орфографии в тексте и исправление найденных ошибок;
-
1.2. ) токенизацию текста (разбиение текста на отдельные слова и исключение незначащих частей речи – предлогов, местоимений и т. п.);
-
1.3) лемматизацию текста – приведение каждого слова к так называемой лемме, являющейся нормальной (словарной) формой слова. Нормальными формами являются следующие морфологические формы: для существительных – единственное число именительного падежа, для прилагательных – мужской род единственного числа именительного падежа, для глаголов, причастий и деепричастий – инфинитивная форма глагола;
-
1.4) удаление стоп-слов – слов, которые исключаются из объявлений, поскольку заведомо не содержат смысловой нагрузки в контексте решаемой задачи (например такие слова, как «продам», «предлагаю», «участок» и т. п.);
-
-
2) преобразование фраз из обработанного текста в числовую (векторную) форму. Нейронная сеть, являясь математическим алгоритмом классификации, «умеет» работать только с данными, представленными в числовой форме;
-
3) обработка входных векторов в нейронной сети и получение на ее выходе набора кодов расчета вида использования для объекта-аналога вместе с вероятностью каждого кода.
Таким образом, результат работы нейронной сети аналогичен результату, получаемому при кодировании объектов оценки – код расчета совместно с соответствующей ему вероятностью.
Для обучения нейронной сети использовались объекты-аналоги, которые были прокодированы в ГБУ Московской области при проведении ГКО в 2018 году. При этом, учитывая, что метод рыночного моделирования применятся не для всех сегментов, объекты-аналоги относились только к следующим сегментам:
-
• сегмент 2 «Жилая застройка (среднеэтажная и многоэтажная)»;
-
• сегмент 4 «Предпринимательство»;
-
• сегмент 6 «Производственная деятельность»;
-
• сегмент 7 «Транспорт»;
-
• сегмент 13 «Садоводческое, огородническое и дачное использование, малоэтажная жилая застройка».
Для обучения нейронной сети использовалась информация о 90 тысячах объектов-аналогов. Архитектура нейронной сети представляет собой LSTM-сеть 4, которая удобна при использовании значительного количества текстовой информации, поскольку настройка векторов, в которые пре- образуются текстовые данные, происходит во время самого процесса обучения сети. В таблице 2 приведены результаты проверки кодировки, полученной с использованием построенной нейронной сети, на тестовой выборке.
Таблица 2
Результат кодирования объектов-аналогов
|
Сегмент |
Количество |
||
|
объектов-аналогов |
всего совпадений |
совпадений из первых 3 |
|
|
2 |
50 940 |
40 953 |
48 523 |
|
4 |
2 074 |
1 531 |
1 702 |
|
6 |
1 182 |
859 |
934 |
|
7 |
946 |
715 |
822 |
|
13 |
35 546 |
25 504 |
30 064 |
|
Всего |
90 688 |
69 562 |
82 045 |
В последнем столбце таблицы 2 (количество совпадений из первых 3) приводится количество объектов-аналогов, для которых хотя бы один из первых трех (наиболее вероятных) кодов расчета вида использования, присвоенных нейронной сетью, относится к тому же сегменту, к которому аналог был отнесен при ручной кодировке.
На рисунке 2 в графическом виде представлены доли успешного кодирования объектов-аналогов для каждого из рассматриваемых сегментов. На графиках видно, что нейронная сеть, построенная для распознавания текста объявлений о продаже земельных участков, показывает высокую эффективность, достаточную для ее дальнейшей практической эксплуатации.
После проведения ГКО нейронная сеть для кодирования объектов-аналогов используется для оперативного кодирования новой рыночной информации, которая будет использоваться в следующих турах ГКО. Автоматическая кодировка позволяет не отвлекать сотрудников от рутинных операций, а также в режиме, приближенном
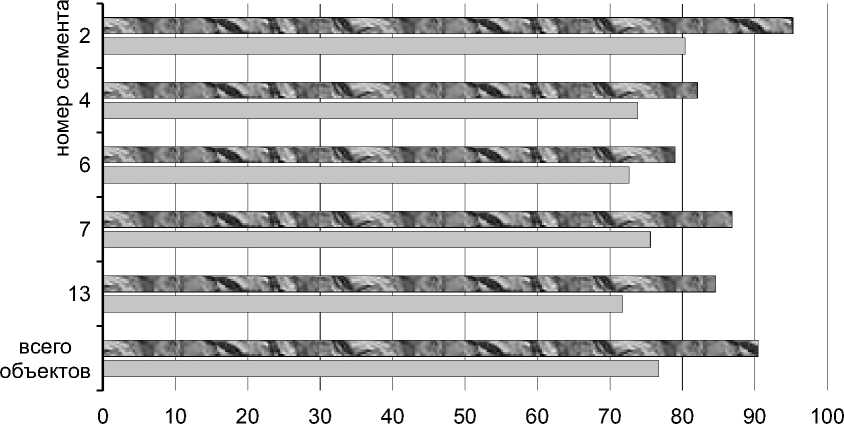
успешность, %
□ успешность из первых 3 □ полная успешность
Рис. 2. Доля успешного кодирования объектов-аналогов
к реальному времени, получать различную сводную информацию о ценовой ситуации в различных сегментах рынка.
Важным аспектом деятельности ГБУ после завершения этапа проведения ГКО является обработка обращений об исправлении ошибок, допущенных при определении кадастровой стоимости. Особенности процесса рассмотрения таких обращений регулируется статьей 21 Закона № 237-ФЗ. Очевидно, что в отличии от подготовки разъяснений, связанных с определением кадастровой стоимости (см. статью 20 Закона № 237-ФЗ), в которых содержится стандартизированное описание методики определения кадастровой стоимости и значений используемых при этом факторов, подготовка ответа на обращение об исправлении ошибки требует активного непосредственного участия сотрудника ГБУ. Более того, подготовка таких ответов является основной функцией большинства сотрудников производственных подразделений ГБУ в период между турами проведения ГКО. Однако при обработке значительного количества обращений (в ГБУ Московской области в течение 2019 года поступили около 3 тысяч обращений в отношении 5 тысяч объектов недвижимости) 5 возникает задача сокращения времени предварительной обработки таких обращений с целью определения его тематики и адресации сотруднику, который в дальнейшем будет непосредственно заниматься его обработкой и подготовкой ответа. Решение этой задачи позволило бы разгрузить сотрудников, занятых рутинным распределением входящих обращений, для решения более «творческих» задач.
В отличие от задачи классификации объектов недвижимости, когда множество классов (кодов расчета вида использования земельных участков или кодов подгрупп объектов капитального строительства) заранее известно, количество тем, на которые можно распределить обращения, заранее не известно. Более того, определение количества таких тем также является частью решаемой задачи. При этом следует учитывать, что, с одной стороны, количество тем должно быть достаточным для описания большинства обращений без существенной потери (искажения) информации, а с другой – тем не должно быть слишком много, чтобы избежать лишнего информационного «шума». Для каждого обращения известно только, какой сотрудник занимался его обработкой. В дальнейшем эта информация может быть использована для разделения выделенных тем между сотрудниками, что позволит по теме обращения определять сотрудника (или сотрудников), который мог бы это обращение обработать.
Задачи подобного типа, когда заранее неизвестно множество классов, к которым могут быть отнесены объекты, относятся к задачам обучения без учителя . Для выбора метода решения этой задачи ее можно переформулировать следующим образом: если набор всех обращений представить в виде некоторой матрицы вещественных чисел, то в пространстве какой размерности можно приблизить эту матрицу к матрице меньшего ранга с наименьшими потерями информации, содержащейся в исходной матрице. Поиск такого представления исходной матрицы применительно к задачам обработки информации на естественном языке является содержанием метода латентно-семантического анализа (метод LSA) 6. Это метод позволяет выявлять характерные факторы (тематики), присущие всем документам из некоторого набора (библиотеки). В рассматриваемом случае документом является отдельное обращение. Математическая основа метода LSA – сингулярное разложение исходной матрицы документов, которое, как известно, является наилучшим представлением исходной матрицы матрицей заданного ранга.
В качестве исходной информации в методе LSA, как правило, используется преобразование исходной текстовой информации в числовую форму в виде весов, учитывающих частоту появления каждого слова в каждом документе и одновременно его встречаемость во всех документах исполь- зуемого набора. Такое представление текста называется TF-IDF-преобразованием. Таким образом, каждое слово в обращении заменяется числом (частотностью), отражающим важность этого слова в контексте обращения, являющегося частью большого набора документов. С учетом сделанных замечаний задача классификации обращений формально может быть представлена следующим образом.
Обозначим А прямоугольную матрицу, содержащую значения частотностей появлений слов (терминов) для каждого обращения. Размерность матрицы:
m x n, где m – количество документов (обращений);
n – количество уникальных терминов (слов) во всех обращениях.
Матрицу А в рамках латентно-семантического анализа принято называть матрицей «Документ-Термин». Сингулярное разложение матрицы А может быть представлено в следующем виде (для удобства запишем разложение для транспонированной матрицы АT ):
AT « и x S x VT, где U – матрица «Термин-Тема», которая отражает важность отдельного термина для темы, причем размерность матрицы - n x p, где p – не известное на данный момент количество тем;
VT – матрица «Тема-Документ», которая показывает, насколько можно отнести отдельный документ к каждой из тем (размерность матрицы - p x m );
S – квадратная матрица (размерности p ), содержащая первые p наибольших сингулярных значений матрицы А .
Необходимо выбрать такую величину p (количество тем), чтобы потери информации при сжатии матрицы А были не слишком
Landauer T., Foltz P.W., Laham D. Introduction to Latent Semantic Analysis // Discourse Processes. 1998. Vol. 25. P. 259–284.
большими. В случае, когда p = m , приведенное приближенное равенство становится точным, но с практической точки зрения такая ситуация является бессмысленной, так как количество тем соответствует количеству документов, то есть каждое обращение имеет свою собственную тематику.
Для решения поставленной задачи был использован массив обращений, поступивших в ГБУ Московской области в течение 2019 года и 6 месяцев 2020 года (3 тысячи документов). Проведенные расчеты показали, что при выделении в массиве документов 7 тем ( p = 7) потери информации при сингулярном приближении исходной матрицы составляют менее 5 процентов, что можно считать достаточно приемлемым с практической точки зрения результатом. После анализа содержания обращений, разбитых на темы, удалось условно сформулировать описания для каждой из выделенных тем:
-
• некорректно определены ценообразующие факторы для объекта недвижимости;
-
• не учтены факторы, которые влияют на стоимость объекта;
-
• неверно определено фактическое местоположение объекта;
-
• земельный участок фактически используется по другому назначению;
-
• удельный показатель стоимости объекта существенно отличается от показателя соседнего объекта;
-
• кадастровая стоимость слишком сильно увеличилась по сравнению с предыдущим туром ГКО;
-
• требование присвоить кадастровую стоимость в размере ранее оспоренной стоимости (в суде или комиссии по рассмотрению споров).
Используя информацию о том, какой сотрудник обрабатывал каждое обращение из обучающей выборки, было сформировано распределение тем между сотрудниками. Таким образом, после отнесения нового обращения к определенной теме можно сразу определить сотрудника, который этой темой ранее занимался и распределить ему поступившее обращение.
При поступлении нового обращения его тематика определяется с использованием вычисленных в процессе обучения модели матриц U , S и V . Для этого новое обращение может быть представлено в виде вектора a , содержащего значения частотностей, которые определяются аналогично построению матрицы А , то есть являющегося вектором размерности 1 х n , включающего TF-IDF-представление текста обращения. Основываясь на формуле сингулярного разложения, для трансформации вектора к виду «Документ-Тема» необходимо выполнить следующее преобразование к вектору v размерностью 1 х p :
v = а х U х ( U T х и ) -1 х S -1 .
Компоненты вектора v отражают степень близости поступившего обращения к каждой теме, что позволяет классифицировать обращение по тематике, упорядочив значения вектора по убыванию – искомый номер темы соответствует индексу максимального значения вектора v . Как правило, одну и ту же тему могут обрабатывать несколько сотрудников (за исключением специфических тем, связанных с необходимостью работы со специализированным программным обеспечением в части геоинформаци-онных систем), поэтому выбор конкретного сотрудника из группы осуществляется с учетом дополнительных ограничений, таких как текущая загруженность сотрудников, плановые отпуска, предшествующая статистика по времени обработки обращений и т. п.
Подводя итог, отмечу, что использование средств автоматизации, основанных на методах машинного обучения, в деятельности ГБУ позволяет на основе «оцифровки» предшествующего опыта сотрудников существенно сократить сроки выполнения рутинных ежедневных операций по кодированию земельных участков и объектов капитального строительства.
Сокращение времени кодирования основной массы объектов позволяет снизить влияние человеческого фактора и сосредоточиться на более точном исследовании «сложных» объектов, автоматическая обработка которых приводит к неоднозначным результатам. Кодирование объектов-аналогов обеспечивает сокращение сроков подготовки рыночной информации для ее использования в моделировании кадастровой стоимости и позволяет оперативно проводить ценовой мониторинг в различных сегментах рынка.
Автоматизация тематической классификации обращений и их распределение для дальнейшей обработки позволяет освободить сотрудников, занятых работой с входящими обращениями, особенно в периоды пиковой нагрузки.
**
от 1 сентября 2014 года № 540. Доступ из справочной правовой системы «Консуль-тантПлюс».
ГДЕ КУПИТЬ БОЛЬШУЮ КВАРТИРУ И КАК ПРИ ЭТОМ СЭКОНОМИТЬ?
В то время как некоторые застройщики столицы соревнуются в том, кто выведет на рынок наиболее компактные квартиры (последний ре корд – 9 кв. м), в Москве растет число многодетных семей. Что же они могут выбрать в московских новостройках?
Так, за последние 9 лет в Москве количество многодетных семей выросло в 2 раза и сейчас составляет 157 тысяч. Многодетной считается семья, в которой воспитываются трое и более детей. Понятно, что такой семье не подойдет даже достаточно просторная двухкомнатная квартира, и многие стремятся приобрести многокомнатную – с 4 и более спальнями.
Сделать это можно с привлечением материнского капитала, программы трейд-ин (например, реализуя старую трехкомнатную квартиру, тогда доплата будет небольшой), а также используя специальные банковские программы ипотечного кредитования. В большинстве банков многодетные семьи могут получить кредит со ставкой от 4,5% годовых, а в некоторых новостройках предлагаются еще более льготные условия покупки.
Например, в ЖК «Город на реке Тушино-2018» действует специальная программа, разработанная застройщиком совместно с банком дом.рф, в рамках которой ставку 3,1% годовых можно получить на ВЕСЬ срок кредитования. Самая настоящая европейская ипотека. Кстати, программой могут воспользоваться не только семьи, но и все желающие.
Окончание на с. 82
Список литературы Методы машинного обучения как инструмент повышения эффективности работы государственных бюджетных учреждений, уполномоченных на проведение государственной кадастровой оценки
- О государственной кадастровой оценке: Федеральный закон от 3 июля 2016 года № 237-ФЗ. Доступ из справочной правовой системы "КонсультантПлюс".
- Об утверждении классификатора видов разрешенного использования земельных участков: приказ Министерства экономического развития Российской Федерации от 1 сентября 2014 года № 540. Доступ из справочной правовой системы "КонсультантПлюс".
- Об утверждении методических указаний о государственной кадастровой оценке: приказ Министерства экономического развития Российской Федерации от 12 мая 2017 года № 226. Доступ из справочной правовой системы "КонсультантПлюс".
- О внесении изменений в методические указания о государственной кадастровой оценке, утвержденные приказом Минэкономразвития России от 12 мая 2017 года № 226": приказ Министерства экономического развития Российской Федерации от 9 сентября 2019 года № 548. Доступ из справочной правовой системы "КонсультантПлюс".
- Haykin. S. Neural networks and learning machines. 3rd ed. Pearson, 2009. 906 p.
- Gers F. A., Schmidhuber J. LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages (англ.) // IEEE Transactions on Neural Networks. 2001. Vol. 12, no. 6. P. 1333-1340.
- Landauer T., Foltz P.W., Laham D. Introduction to Latent Semantic Analysis // Discourse Processes. 1998. Vol. 25. P. 259-284.
