Minimizing Separability: A Comparative Analysis of Illumination Compensation Techniques in Face Recognition

Автор: Chollette C. Olisah
Журнал: International Journal of Information Technology and Computer Science(IJITCS) @ijitcs
Статья в выпуске: 5 Vol. 9, 2017 года.
Бесплатный доступ
Feature extraction task are primarily about making sense of the discriminative features/patterns of facial information and extracting them. However, most real world face images are almost always intertwined with imaging modality problems of which illumination is a strong factor. The compensation of the illumination factor using various illumination compensation techniques has been of interest in literatures with few emphasis on the adverse effect of the techniques to the task of extracting the actual discriminative features of a sample image for recognition. In this paper, comparative analyses of illumination compensation techniques for extraction of meaningful features for recognition using a single feature extraction method is presented. More also, enhancing red, green, blue gamma encoding (rgbGE) in the log domain so as to address the separability problem within a person class that most techniques incur is proposed. From experiments using plastic surgery sample faces, it is evident that the effect illumination compensation techniques have on face images after pre-processing is highly significant to recognition accuracy.
Illumination compensation, preprocessing, feature extraction, face recognition, within-class separability, plastic surgery
Короткий адрес: https://sciup.org/15012646
IDR: 15012646
Текст научной статьи Minimizing Separability: A Comparative Analysis of Illumination Compensation Techniques in Face Recognition
Published Online May 2017 in MECS
Generally, most real-world images suffer poor lighting or are captured without following any of the imaging standards. As a result, illumination problem is usually intertwined with other cases of recognition such as expression, occlusion, aging and even plastic surgery. However, prior to imaging these various cases of recognition already exist with its own complexity within a person class. In other words, the margin between the face images of a person is already wide enough, not to talk of the inclusion of an added separability due to illumination problem. A number of researchers have adopted illumination compensation as a means of eliminating the possibility of the contribution illumination makes to the wide margin within a class, but without careful thought to the influence any of the illumination compensation techniques might have on extracting meaningful enough features for any of the cases of recognition. Various illumination compensation techniques exist, some of which will be discussed intensively in the review section under the categories of illumination models, illumination insensitive methods, illumination normalization methods and Illumination/Reflectance Separation Based Methods. Meanwhile, the following problem is stated.
-
A. Problem Statement and Contribution
It is usually difficult to achieve even illumination with the global normalization methods. The locally adapted normalization methods in a way employ high-level or low-level filtering processes in order to enhance particular image information over the other. However, any of the information lost in both cases might be useful pattern cues in feature extraction stage.
In this paper, a comparative analysis of illumination compensation techniques in the extraction of meaningful features for recognition is presented. The feature extraction method employed in this paper has been proposed in [1] and is known to be sensitive to illumination such that the presence of uneven illumination will result in poorly extracted features for recognition. It is for this reason that the feature extraction method adopted in this paper is more appropriate for use in the analyses. The sample data used for the analyses is the plastic surgery data set because there are fewer images in a class, yet there exist illumination separability margin between images of the same person. This can be likened to the different sources where the images were collected and also on the fact that facelift affect facial identity. With plastic surgery, two problems can arise: inter-class similarity and intra-class dissimilarity. These two terms imply that a face can tend towards the face or facial characteristics of another individual and the images of a person can differ, respectively. Additionally, this paper also proposes to enhance rgbGE [2], an existing illumination compensation technique, in the log domain. The proposition put forward in this paper is that rgbGE in the log domain will address the illumination separability problem within a person class that most illumination normalization techniques incur. This enhanced version of rgbGE will form part of the techniques to be analysed as well.
The rest of the paper is organized as follows. In section II is a detailed literature review on illumination compensation methods. The proposed approach for enhancing rgbGE in the log domain is presented in Section
-
III. Then, Section IV presents the proposed feature extraction approach. The experimental results of the comparative analysis of various illumination normalization techniques are presented in Section V, while the conclusion is given in Section VI.
-
II. Literature Review
For ease of discussion, the various methods in literature for compensating for illumination problem will be reviewed under two main categories, namely grey-level based illumination compensation methods and colour based illumination compensation methods. Under these categories, the different methods and approaches/techniques will be discussed.
-
A. Grey-level Based Methods
For a vast majority of illumination compensation methods, the grey-level images are usually input to illumination pre-processing. For the rest of this paper, the term pre-processing with respect to illumination is used to mean that another processing such as feature extraction follows the resultant image of the pre-processor. On the other hand, when processing is used with respect to illumination it means that the image illumination is corrected and the image is to serve as feature used directly for recognition. The grey-level illumination compensation methods will be discussed here in the following sub-categories; illumination models, illumination insensitive methods and illumination normalization methods. The methods under these categories are presented as follows.
-
1) Illumination Models
On attempt to correct for the effect of illumination on facial appearance, face models that captures various illumination conditions of images of a subject’s face taken under variable lighting have been proposed. Some of which can be found in the following literatures [3], [4], [5], [6], [7], [8], [9], [10], [11]. The methods proposed in these literatures assume a Lambertian surface, that is, the assumption that light is reflected equally across the image (diffuse reflectance). In some of the literatures, other surface properties are assumed, which will be pointed out in the course of the review.
In [3], the assumption that the surface properties of face images in fixed view-point belonging to a subject takes the form of convex cone in image space is exploited. Under this assumption, the surface geometry and albedo (texture) map of the faces in the image space are estimated and are used to generate possible variations not covered in the training images. These images are further approximated in a low-dimensional linear subspace as illumination cones and recognition of each cone is based on the Euclidean distance between the test image and the cone. Extending the idea that face images obtained under varying lighting conditions lie in low-dimensional subspace, Basri and Jacobs [4] obtained a 9-dimensional image space model that defines the varying lighting of a face which are then used for recognition task. The quotient image [5] is the outcome of estimating object’s surface reflectance from a linear combination of several sample basis images of a subject/object. The assumptions [5] uses to address illumination variation, is that the face images under observation are comprised of the diffuse reflection.
Still exploiting the common assumptions in [5], but from the point of a single image Wang et al . [6] proposed self-quotient image, which is obtained by employing the Gaussian function smoothing operator. Likewise, [7] reconstructs a shape-specific illumination subspace that characterizes statistics of measured illumination from single images of different subjects under various lighting conditions. Zhao et al . [8], generated illumination ratio images from a single frontal view image for the face recognition system to adapt to different illumination conditions. With a pre-estimated lighting attribute of a test image obtained using spherical harmonic model, [9] implemented an adaptive processing method to normalize lighting variation.
In [10], learned statistics from a single image is used to estimate the spherical harmonic basis images that characterizes the arbitrary lighting conditions an image is captured-in. Wang et al . [11], under the assumption that approximation error can be higher with spherical harmonic model for images acquired from harsh lighting conditions (which they assume can affect albedo information) they adopted the Markov random field in order to include the face texture in the model. The term albedo can be used to refer to surface texture properties.
-
2) Illumination Insensitive Methods
The Illumination insensitive methods seek to create a feature that is not affected by illumination, in other words it is an illumination processing approach. In achieving the stated goal, the illumination components are separated from that which constitutes the facial appearance. A number of illumination compensation methods under this category are currently attracting research interest in face recognition task, some of which are discussed as follows.
The earliest used illumination insensitive approach is the edge map. The edge map has been widely applied in object recognition [12], [13], [14], [15], [16]. Presently, it has been attracting research interest in face recognition [17], [18], [19], [20] even though it is generally not invariant with respect to variation in light intensity or contrast [21]. The edge map proposed by Gao and Leung [17] groups edge pixels into line segments that provides compact information of the most significant details that are regarded as the underlying structure of the face image. The capability of the edge map to describe the face image by its shape characteristics makes it insensitive to illumination inconsistencies on the face image. The edge map is mostly insensitive to diffuse illumination component than other illumination components such as the ambient and specular components. The concept used in [17] was extended to similarity retrieval in [18]. Zhao-Yi et al . [20] adopted the Canny edge detection operator and active appearance model in order to extract illumination insensitive information and for expression recognition. As the basis of their image representation Suzuki and Shibata
-
[22] used the edge-based feature maps to create illumination insensitive features. The feature maps utilized are of first order derivative for four-directional axis, namely horizontal, +45, vertical and -45-degree axis. Lowe [12] proposed the scale invariant features transform (SIFT) for detecting local points, which are referred to as key points, in an image. The SIFT is mostly reliable for object retrieval and natural scene images that have more distinctive points and edges, unlike the face image, which have little distinctive patterns.
Illumination processing from the point of image edge gradient is currently receiving attention. One of the very reasons is that under varying illumination, pixel values are likely to be randomly distributed whereas, edge gradients are distributed along the intrinsic properties of an image. The gradient based approaches are based on a simple image processing principle, which is the image surface partial derivative. So far only few literatures exploit the gradient domain. Samsung [23] proposed an illumination invariant feature that uses the gradient domain for face recognition. They normalized the image gradient to obtain binary edge maps, which are further integrated into the original grey-level image. Using anisotropic smoothing, the impact of step edge is reduced. In [24] a near robust image edge gradient direction is used to derive illumination invariant features. They considered a wide range of illumination problem such as sharp cast shadows; quantum and quantization noise and face regions poorly illuminated. Khan et al . [25] employed an adaptive approach to anisotropic smoothing. Their approach works by determining the difference between the global level variance and local level variance of an image via image histogram. The resulting intensity contrast in the neighbourhood serves as the thresholding parameter to adaptively effect noise smoothing, while preserving low gradient edges.
-
3) Illumination Normalization Methods
In order to compensate for varying illumination in face images of individuals, the illumination normalization methods are often employed. They are mostly thought of to be pre-processing methods that preserves the intrinsic shape characteristics of a face [26], [27]. Here, the discussions presented under the illumination normalization pre-processing methods will introduce approaches that use image information to correct for illumination problem and also the pre-processing methods that do not use any knowledge of the image prior to processing (that is, global enhancement). The reason for this pattern of review is that recent trend in illumination normalization is moving towards the methods which are adapted to the state of the image processed. The approaches under this category are discussed as follows.
To output pre-processing that compares with that of the human visual processing and perception, Jobson et al. [28] proposed a simple approach that convolves a Gaussian passed image with the logarithmic transform of intensity image in their spectral band. This approach is well known as single scale retinex (SSR) and/or multi scale retinex (MSR) and their objective is to be able to achieve compression in dynamic range of image pixels, grey-world consistency, and image tonal rendition. Based on the retinex theory in [28], Wang et al. [29] proposed a method that adopts the concept of retinex theory and weighted Gaussian filtering (anisotropic) for normalizing the illumination of a single image. A further improvement to [27] was made by Chen et al [26]. They employed the logarithm domain based discrete cosine transform (LOG-DCT) to compensate for varying illumination in the logarithm domain, which is defined in [28]. However, in [26] a zeroing of the low frequency DCT coefficients is done in the logarithm domain. A different approach for addressing varying illumination is proposed by Nishiyama et al. [27]. In [27] a classified appearance-based quotient image (CAQI) is proposed to address the limitations of [26] in terms of cast shadow, attached shadow and specular highlight, which they claim is better version of SQI. This is for the fact that unlike theirs, the SQI only considers diffuse component in the illumination compensation design. In the continuity of the normalization filters discussion, Gross and Brajovic [30] developed a method based on anisotropic smoothing (AS). Their method uses a blurred version of the original image to iteratively estimate illumination problem in a given image. A modified version of the AS is proposed by Tang and Whitaker [31], where a smoothening function is applied along the direction of the level sets curve, the process is to be able to enhance edges in an image. This method is called modified anisotropic smoothing (MAS).
A method of normalizing image illumination in the wavelet domain is proposed by Du and Ward [32]. The sub-bands of the wavelet transform are the basis for the histogram equalization (HE) and point multiplication by a scalar value greater than one. This method is referred to as wavelet based normalization (WN). Another frequency domain based processing is proposed by Oppenheim et al. [33]. A high-pass filter, which increases the high-frequency components and reduces the low-frequency components, is used to achieve even illumination. The technique is called the homomorphic filtering (Homo) technique. Still on frequency domain processing, in [34] the authors exploited equalizing the histogram of approximation coefficients as in [32]. However, they employed directional filter bank in order to enhance edge details of the wavelet decomposed images at different bands. enhancement of image edges is obtained by using a directional filter bank. Based on the argument that most techniques either discard large scale or small scale features Xie et al. [35] proposed combining pre-processing methods from the frequency domain (LOG-DCT) and spatial domain self-quotient image (SQI) in order to retain large and small scale features (LSSF).
On global based approaches, widely known is the HE, Santamarıa and Palacios [36] presented and proposed methods that are versions of HE, but are locally adapted to image pixels. They are namely; local histogram equalization (LHE), local histogram matching (LHM) and local normal distribution (LNORM). The HE has also been further enhanced in the following literatures. Pizer and Amburn [37] proposed an adaptive version of histogram equalization (AHE). By a cantered image region, histogram equalization is computed in order to achieve contrast enhancement on a local basis. In [38] a block based local histogram equalization (BHE) method is adopted. The difference between [37] and [38] are that the blocks overlap and the noise level present in [37] is reduced by using a method proposed in [38].
Another widely adopted global based approach is the logarithmic transform (LT). A variant of the LT was proposed by Liu et al . [39], which they named the LogAbout method. The LogAbout method is adopted to control logarithmic distribution in the image in order to achieve better compression of high frequency signals and enhanced shadow level regions. The Gamma correction (GC) is known to correct pixel overall brightness level to a pre-defined “canonical form” that are widely known to fade away varying lighting effect. Shan et al . [40] further enhanced the functionalities of GC by adopting a strategy whereby the illumination state of the image processed is determined and used to optimize the gamma coefficient used in GC processing. They called their method the gamma intensity correction. A recently proposed pre-processing chain, which comprises of gamma correction includes difference of Gaussian filtering, masking, and contrast equalization. This pre-processing chain is proposed by Tan and Triggs [41]. Their method achieves uniform illumination after the pre-processing chains are employed, but due to over processing, some useful information are likely lost in the course of illumination correction and image filtering.
-
B. Colour-based Methods
At this point of the review it can be noted that all the above-mentioned illumination pre-processing/processing methods presented and discussed do not consider specular highlight (though this might be attributed to the reasoning behind the objective of the pre-processing method) and are based on grey-scale images. However, the face images that are available for face recognition task are mostly colour images. A number of illumination pre-processing or processing has also been geared towards colour based processing to fully utilize the body of possibilities present in the colour domain, as highlighted in [42], [43]. In these studies, [42], [43] it has been shown that when the source colour of an illuminated image is known and constant over a scene, the illumination effect as a result of the changes in light direction can be addressed. Here the review on some existing colour based illumination pre-processing or processing methods are presented under the categories of illumination/reflectance separation based methods, illumination invariant colour normalization methods.
-
1) Illumination/Reflectance Separation Based Methods
Typically, the colour domain illumination pre-processing assumes that an image is often made up of surface illumination and surface reflectance properties. The former depicts image properties as a result of the light used to illuminate a surface and the latter relates to the reflective ability of the imaging surface, which can bring about specular highlight. For most uniformly illuminated objects, an assumption often made is that there is the presence of specular highlight, the optimum interest is to separate the reflectance from the illumination as a means to restore illumination component for further processing. Here, literatures belonging to this category are reviewed as follows.
Shafer [44] proposed a generalized model that is based on the colour distribution of pixel-values to separate the specular reflection component from the illumination component. In [45] an estimation of the illumination colour is determined in order to project the region of interest on the image onto the colour space. This is done to isolate the matte in the colour region, the highlight range and the clipped region in the image using a dichromatic plane. This helps to remove the specular reflection component in the image. The term matte used by the author in [45] is used to mean diffuse. Similarly, Schluns [46] transformed the red, green and blue (RGB) image colour channels to the luma (Y), chrominance (UV), which is abbreviated as YUV-space and hue-space. The hue-space allows for segmentation of the data in order to determine each pixel diffuse (matte) colour. For the specular component, it is estimated from the illumination colour since it is assumed to take the colour of the illumination.
An S-space introduced by Bajcsy et al . [47] stands as the basis for illumination/reflectance separation. The RGB image is first converted to the S-space, where then the image brightness, hue and saturation are obtained. A further segmentation process is carried out to separate the specular reflection from the diffuse reflection. Lee et al . [48] extended the concept of the S-space introduced in [47] without the segmentation aspect. They utilized multiple views of images in order to achieve separation of the specular component from the diffuse component in the image sequence using the spectral differencing algorithm.
In [49] a partial differential equation (PDE) is proposed for specularity removal, image filtering, and independently processing the specular and diffuse components either by separating them or recombining them for textured scene images/videos. Based on the assumption that specular highlight for inhomogeneous objects such as textured data is of linear combinations of the diffuse and specular reflection components. Tan and Ikeuchi [50] proposed the comparison of image intensity in logarithmic domain and its specular-free image in their chromaticity space. The resultant image is subsequently used to separate the specular component from the diffuse component. Tappen et al . [51] presented an algorithm that uses multiple cues such as colour and grey-scale information to classify the intrinsic derivate of an image. The algorithm works in a way that determines whether the derivative of the image corresponds to change resulting from shading or from the surface reflectance.
-
2) Illumination-Invariant Colour Normalization Methods
The methods under this category are often based on colour constancy, which is an invariant technique that recovers an object colour independent of the object lighting intensities. Interestingly, colour normalization based methods adopt the concept of the colour constancy to obtain images that are insensitive to intensity and colour variability caused by different imaging sensors. As a result of the prior discussions, the colour normalization methods are considered to be relatively robust to illumination effect. Several colour spaces such as hue saturation intensity (HIS), Y-luminance and IQ-chrominance (YIQ), red, green blue (RGB), CIE-Commission Internationale de l'Eclairage L-luminance uv-chrominance (CIE L*u*v*), YUV, normalized RGB space, have been found in literature, but of more emphasis is the normalized RGB space. The reason is that more realistic resultant image after colour constancy is feasible with RGB space than other colour spaces. Here, literatures will be reviewed for RGB colour space on the basis of invariance to illumination while maintaining a uniform colour despite varying sensor intensities.
A well-known method under this category is the single scale retinex (SSR). The SSR results from the multiscale retinex proposed by Jobson et al . [52]. The retinex theory uses the colour subpace for obtaining colour constancy and high level dynamic range compression of image intensity. However, the retinex parameters can bring about greying in uniform colour regions of an image, which results in poorer colour rendition. Using the subspaces of RGB colour space under the assumption of dichromatic surfaces Zickler et al . [42] proposed to derive specular reflectance and shading from diffuse reflectance invariant image. Their idea is to achieve invariance to specular highlight so that image features can correspond to surface shape and surface spectral properties. In [43] Finlayson et al . proposed to remove dependence on luminance and lighting geometry from an image by employing iteratively r, g, and b colour channel normalization. Unlike [42], and [43] where no form of estimation of the light source or material medium is made, Wang et al . [53] uses the Gibbs distributions to approximate reflectance and illumination. The authors instead of the retinex parameters used the Bayes approximate to estimate the unknown distributions in the hierarchical Bayesian model.
Any of the illumination normalization techniques discussed under the grey-scale domain can also be applied in the colour domain but on each individual colour channel. Li et al . [54] exploited the grey-world of the r, g, and b colour channels independently in order to achieve illumination compensation. They adopted a sequence of normalization methods; gamma correction, difference of Gaussian (DoG), and contrast equalization, proposed by Tan and Triggs [41] in order to correct for illumination problem in a colour image.
-
C. Limitations and Discussions
Achieving uniform illumination across face images of a subject are difficult to achieve with the global illumination normalization methods. However, they are still well suited as pre-processing methods for feature extraction processing. The model based methods are basically for a recognition system to adapt to different illumination conditions. However, they require prior information of the geometry and reflectance properties of the illuminating objects for compensation to take place. Illumination-invariant approaches like the gradient based methods are according to Chen et al [26] a function of illumination and surface reflectance, which means that image surface properties can limit the gradient distribution. It is well known that colour constancy methods remove dependence on illumination intensities. Therefore, the image can only be described by its chrominance property. However, the outcomes of colour constancy assumptions result in images that can be termed unrealistic for face recognition, which is why they are mostly often used for segmentation tasks.
Having established through review of the reported literatures under illumination compensation that some pre-processing techniques diminish the intrinsic shape characteristics in the face image which makes further processing difficult. More also, a number of the methods result in the increase in the difference margin between the face images of an individual due to over exaggeration of different facial information. It is important to investigate further through experimental analysis the extent illumination compensation techniques affect the extraction of significant and discriminative facial features. However, since the illumination normalization approaches are still better-off a pre-processing technique on basis that they preserve the intrinsic shape characteristics of a face [26], [27], the analysis is limited to compensation techniques with respect to illumination normalization. The comparison is extended to include the work in [2] and the enhanced version which is presented in the subsequent section.
-
III. Enhanced Rgbge Illumination Normalization
The rgbGE [2] adopts the principle of color constancy in achieving illumination insensitive images. To overcome the unrealistic effect resulting from color constancy, rgbGE fuses color constancy with GC, a global normalization method. The enhancements made to rgbGE by normalizing in the log domain at the channel level is to correct for non-linearity problem arising from nonlinear transformation of pixels’ local dynamic range which GC introduces. The enhancement rgbGE in log domain makes to the original rgbGE algorithm is presented as follows.
Algorithm 1
Input: Original Color image I ( с ) of size MxN
Output: Illumination Normalized image ̿
Begin
//Split color image into channels and initialize
-
E, ( c ), Eg ( c ), Eg ( C ), ̂ к ,‖ E ( c )‖←0
//Stretch intensity values using:
G'k ( c )= Ek ⁄v( c )
//treat for nonlinearities
L'k ( c )=∁∗ Log ( G'k ( c )+ e )
//Estimate illuminant ̂
For i =1→ M ; increment by 1, do
For j =1→ N ; increment'll by 1, do
‖ E ( c )‖= sqrt ( sqrt ( Er ( i , j ))+ sqrt ( Eg ( i , j ))+
… ( Eb ( i , j )))
̂ к = ( i , i )⁄‖ E ( i , i )‖
End For
End For
//Concatenation along third-dimension
̿= fk ( C )⨁ fk ( C )⨁ f ′ к ( C )
End
The algorithm is diagrammatically illustrated in Fig.1 and explained as follows. Given a color image, the algorithm first separate it into its respective rgb color channels. The image matrix of each of the color channels are further normalized as in equation (1) by using different gamma values, which are 0.2, 0.2 and 0.1 for the red, green and blue image matrixes, respectively. These values were determined through experimentation for the optimal value of gamma. Also, for the fact that each of the channel signals exhibit different levels of sensitivity to illumination. Since GC introduces non-linearity problem arising from the nonlinear transformation of pixels’ local dynamic range, the GC normalized image matrices at various color channels are Log transformed as in equation (2) by using a scaling constant value of 2, to dynamically compress pixel range. More importantly, to obtain an intensity-invariant colour normalized image, colour constancy method is adopted, where the r, g, b channel signals are made to be independent of the lighting intensities using equation (4). The resulting image matrices from the prior steps act as multiplier function (5) to the resulting image matrices of the log transformed image for all channel signals. Further on, is concatenation and possibly grayscaling, based on user purposes.
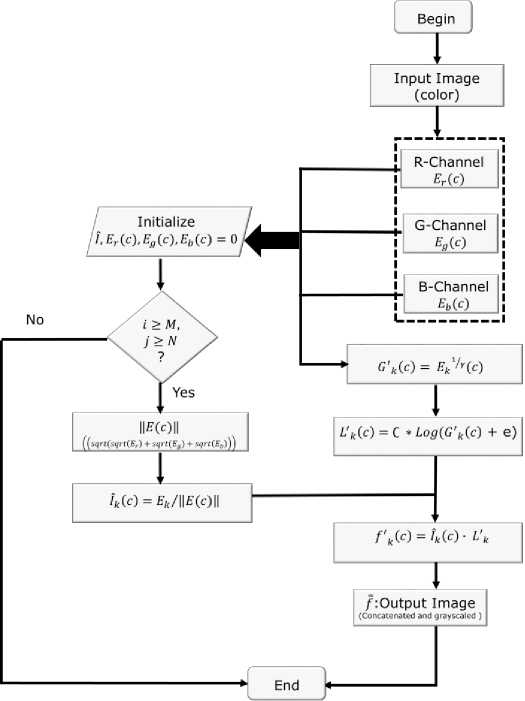
Fig.1. Flowchart of the rgbGE normalization process with enhancement differences.
-
IV. Feature Extraction
The algorithmic process for extracting the feature [2] is presented as follows. Given the illumination normalized face image (graysclaed), , a structural pattern of the face image is determined by finding the pixel gradient based on its surrounding neighbor. Successively, an addition of the global appearance information (which is of a nonrationalized image) to the structural defined image follows. The resulting information from the preceding step, known as the complete face structural pattern is further process in the frequency domain using Gabor wavelets. This is to express at various frequencies the discriminative properties of the complete face structural information. The resulting information is use for describing a face sample. On applying Gabor wavelets at 5-scales and 8-orientations, a face image is described by forty (40) features, which are further down-sampled using an interpolation dependent down-sampling approach. This is to mitigate the problem of redundancy resulting from Gabor wavelet. Given that there are forty (40) independent down-sampled features for describing a sample face, their respective data will have to be standardized. Therefore, a zero-mean/unit-variance standardization method is employed on the forty (40) down-sampled features. Finally, this standardized features are further concatenated along the scale to obtain the augmented feature vectors for describing a single sample face image.
-
V. Experimental Results And Discussion
Firstly, is a visual assessment of various illumination normalization techniques on a randomly selected sample color face image from a single view-point. Secondly, the same techniques are as well visually assessed, but from a multiple view-point. This second experimental analysis uses sample images from Georgia Tech Face data set (GT) [55], labelled faces in the wild data set (LFW) [56], the plastic surgery data set (PS) [57], and Essex data set [58]. These are followed by experiments run on the plastic surgery database in order to evaluate the performances of various illumination compensation (normalization) approaches in the presence of appearance variation due to plastic surgery. Plastic surgery problem is one which requires careful pattern extraction for effective description and recognition. The identification and verification results of the recognition experiment are reported using the cumulative match characteristics (CMC) curve, receiver operating characteristics (ROC) curve or points from the ROC curve, and the equal error rate (EER) as evaluation metrics.
-
A. Visual assessment of various Illumination
Normalization Techniques from a single view-point
In Fig. 2 is the outputs of normalizing a sample image having non-uniform illumination problem with contemporary illumination normalization techniques. These techniques are the AS [30], LOG-DCT [28], Homo [33], LSSF [34], MAS [31], SSR [27], and WN [32]. The figure is summarized as follows, in Fig. 2 (a)-(j) are the outputs of rgbGE [2], rgbGE in log domain and contemporary illumination normalization techniques, respectively.
From the resulting images of these techniques, it can be observed that rgbGE in log domain achieved the following: even illumination, appearance is preserved and the facial information is not lost. Some deficiencies were observed for other techniques. It is either that even illumination is not achieved, facial information is lost, and/or some additional information is introduced. This visual observation is on the basis of a single image. Later on, the experiment will be extended to that of multiple-view point. The reason being that face recognition involves matching of multiple images belonging to a person with images of different individuals. In such a case, the objective of the illumination normalization technique is not only to achieve even illumination for a single image but for all the images while still minimizing separability within a class. For ease of discussion, from now henceforth let illumination pre-processors be used to mean illumination normalization technique.
-
B. Visual assessment of various Illumination
Normalization Techniques from multiple view-point
From the plastic surgery, GT, LFW and Essex data set some sample images are collected and used to demonstrate the output of different illumination pre-processors for images belonging to a person class. The illumination pre-processors used are the AS [30], LOG-DCT [28], Homo [33], LSSF [34], MAS [31], SSR [27], and WN [32], rgbGE [2] and rgbGE in log domain (proposed in this paper). The resulting outputs of the illumination pre-processors are illustrated in Fig. 3. For each of the data sets, the corresponding outputs of the illumination pre-processors are row-wise arranged, while the column represents a pre-processor output for the images belonging to a person class.

Fig.2. Example output of various illumination pre-processors. (a) original (b) rgbGE (c) rgbGE log domain, (d) AS, (e) LOG-DCT, (f) Homo, (g) LSSF, (h) MAS, (i) SSR, and (j) WN
It is important to note that the visual quality of illumination pre-processed images does not necessary translate to good feature detection nor good recognition [31]. The essence of illumination pre-processing is to achieve uniform illumination across a range of different sensor settings so that appearance information can be retained and extracted through the use of facial descriptors. This claim will be validated through experiments in the later subsection of this paper. However, from a visual assessment point of view, of interest is how identity information is preserved.
From the observation made, some illumination pre-processors were of better image brightness and of good contrast than the others, while some of poor contrast. The Homo, MAS, and the rgbGE versions share a similar concept, which is that they remove image luminance. The resulting images of these illumination pre-processors, as can be visually observed from Fig. 3, appear to have poor contrast. For this category of pre-processors, the rgbGE in log domain shows to be more insensitive to different sensor settings. This is for the fact that all the images belonging to a person class appear to visually share better evenness in illumination than its member group. Also, it is important to note that the illumination pre-processors which have the potential to introduce foreign details to the actual facial features invariably maximizes separability within a person class. The AS is observed to be one such illumination pre-processor. More also, the SSR and WN illumination pre-processors are observed to have achieved even illumination across the images belonging to a person class.

" 2 sa wop-without post-processing, wp-with post-processing

Fig.3. Illumination normalization on some example images from the plastic surgery (top left), GT (bottom left), LFW (bottom right), and Essex (top right) data sets.
Having made so many visual observations that might or might not be a true measure of performance, it will be worth it to evaluate the illumination pre-processors influence on the feature extraction stage with face recognition experiment. Therefore, the following proposition should hold in the experimentation. If the illumination pre-processor minimizes illumination separability, then the feature extraction process will be able to extract meaningful features which will invariably increase between class margins for improved recognition accuracy.
-
C. Experimental evaluation of different Illumination pre-processors
0.95
0.9
0.8
43 0.7
0.65
0.6
Using a subset of a severe case of plastic surgery data set, facelift, the performances of the illumination pre-processors are compared. The facelift a subset of the plastic surgery data set consists of 308 subjects.
The experimental scenario is given as three images per subject, one each for the train set, gallery set (generated through mirroring before surgery image) and test set (the test set is unseen during the training phase). Note that rgbGE-1 signifies rgbGE (original) rgbGE-2 (in log domain with visual quality), rgbGE-3 (in log domain with no visual quality).
In Fig. 4 is the CMC curve showing the identification rates for different illumination pre-processors plotted over their respective Ranks. The Ranks 1-25 are considered. The Fig. 5 show verification rates over FAR for different illumination pre-processors. The CMC Rank-1 identification rates, verification rates at 0.01, 0.05 and 0.1 FAR and EER are summarized in Table 1. The following observations are made from the experimental results graphed in Fig. 4 and 5.
Рн 0.85 fl
s 0.75 fl
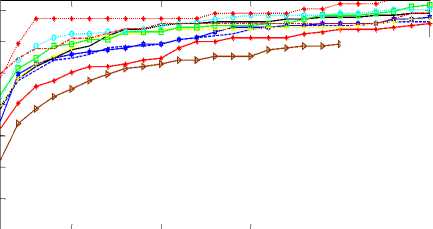
AS
-*— LOG-DCT LSSF
—♦—rgbGE-1 SSR WN
—B— Homo
■■■■0- MAS rgbGE-2 rgbGE-3
5 10 15 20
Rank
Fig.4. Comparative verification performances of various illumination pre-processors.
0.6
0.95
0.9
y: 0.85
0.8
0.75
> 0.7
0.65
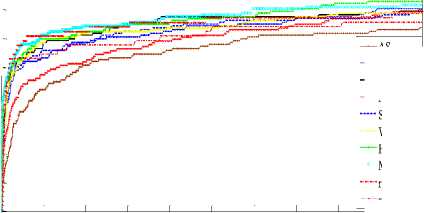
0.01
0.1
AS LOG-DCT LSSF rgbGE-1 SSR WN Homo-2 MAS-2 rgbGE-2 rgbGE-3
0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
FAR
Fig.5. Comparative verification performances of various illumination pre-processors.
In Fig. 4 it can be observed that LOG-DCT, LSSF, SSR, and WN performed better than the rgbGE-1. However, the Homo, MAS and rgbGE in log domain outperform them by 5.4% to 7.7% increase in the recognition accuracy, respectively. The rgbGE in log domain with visual quality is plotted as the rgbGE-3. Though the Rank-1 performance of rgbGE-2 shows to be better by 0.8%, the rgbGE-3 continued to have an increase in recognition rate from the Ranks 2-25 which made the overall performance of rgbGE-3 better-off than rgbGE-2. This means that under strict top-most rank rgbGE-2 is better, but if there is a degree of freedom (which is likely in the real-world) in finding a match the rgbGE-3 is better-off. Therefore, it can be stated that visual quality of illumination pre-processed images does not necessary translate to good feature extraction nor good recognition, similar statement is made in [33].
A single value of the EER can best describe the performance of a verification system because subtracting the value of the EER from 100 gives the system's overall verification accuracy. For instance, the overall verification rate of rgbGE-3 for EER value of 5.26 (that is 0.0526 x 100) is 94.74%, which implies that it is the best-performing illumination pre-processor in comparison with other pre-processors. Since verification rate increases with an increase in FAR the best-performing technique can as well be obtained at the point on the ROC curve where FAR is lowest, that is, at lowest allowable error (note that FAR at 0.01 is used to mean the lowest allowable error).
Table 1. Recognition performance benchmarking between different illumination pre-processors
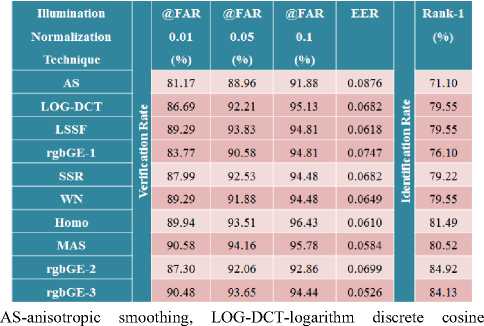
transform, SSR-single scale retinex, WN-wavelet normalization,
From the given details of the curves in Table 1, it can be seen that the best performing illumination pre-processors are the Homo, rgbGE-3, and MAS with verification rates of 89.94%, 90.48% and 90.58%, respectively. This shows that for the verification rate at FAR 0.01 MAS performed better by 0.1%. Though 0.1% might be considered as a negligible difference considering the performance of rgbGE-3 in other aspects of the experiments, it also points to the fact that visual quality is not a good measure of the increase in recognition accuracies.
Overall, it can be observed that the rgbGE-3 illumination pre-processor perform better than the contemporary illumination pre-processors both in the identification and verification experiments. The performance of the rgbGE-3 validates our claim: 1) visual quality is not a true test of illumination pre-processing performance, 2) a good illumination pre-processor minimizes illumination separability within a class thereby allowing the feature extraction process to effectively perform its task of retrieving meaningful features for recognition. However, this is dependent on the feature extraction method and the case it addresses which can either be expression, aging, occlusion or plastic surgery.
-
D. Discussions
The working principle of the rgbGE (even in log domain) is based on the dichromatic reflectance model, which does not consider the ambient component. Hence, the performance of the technique will be significantly affected by ambient lighting components such as cast shadows. The limitation of rgbGE with respect to the ambient component is demonstrated in Fig. 6. Though the attached shadow component of the ambient lighting is not one of the objectives of the rgbGE, it is able to address it. This can be observed in Fig. 6. On the contrary, the cast shadow component is still far from being addressed by rgbGE (including rgbGE in log domain). It is also a common problem for illumination pre-processors in the category of normalization methods.
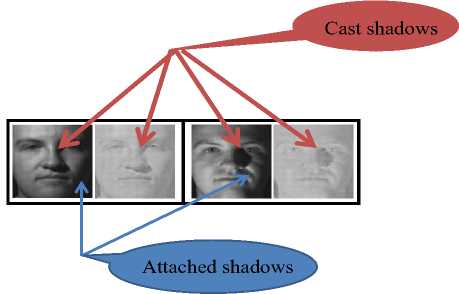
Fig.6. Demonstration of the limitations of rgbGE in log domain with respect to cast-shadow
-
VI. Conclusion
From the recognition experiments reported in this paper, it was obvious that a number of the illumination pre-processors diminish the intrinsic shape characteristics in the face image when further processed, while a number of the methods bring about the increase in the difference margin in face images belonging to a person class due to introduced foreign features. Overall, the rgbGE in log domain proved to be the best fit for minimizing illumination separability between face images belonging to a complex person class. A concluding note is that focus in illumination pre-processing should be directed more towards minimizing separability within a class and extracting actual features of the face for recognition task than achieving visually satisfying output images.
Список литературы Minimizing Separability: A Comparative Analysis of Illumination Compensation Techniques in Face Recognition
- C. C. Olisah and P. Ogedebe. “Recognizing Surgically Altered Faces using Local Edge Gradient Gabor Magnitude Pattern”. In proc. of the 15th International Conference on Information Security South Africa, 17-18 August 2016.
- C. C. Chude-Olisah, G. Sulong, et al. “Face Recognition via Edge-Based Gabor Feature Representation for Plastic Surgery-Altered Images”. EURASIP Journal on Advances in Signal Processing, vol. 2014:102, 2014.
- A. S. Georghiades. P. N. Belhumeur and D. Kriegman. “From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, pp. 643-660, 2001.
- R. Basri, and D. W. Jacobs. “Lambertian Reflectance and Linear Subspaces”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 25, pp. 218-233, 2003.
- A. Shashua, and T. Riklin-Raviv. “The Quotient Image: Class-Based Re-Rendering and Recognition with Varying Illuminations”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, pp. 129-139, 2001.
- H. Wang, S. Li and Y. Wang. “Generalized Quotient Image”. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC, USA: IEEE. 2004, pp. 498-505, June 27-July 2, 2004.
- J. Lee, B. Moghaddam, et al. “Bilinear Illumination Model for Robust Face Recognition”. Proceedings of the Tenth IEEE International Conference on Computer Vision. Beijing: IEEE. 2005, pp. 1177-1184, October 17-21, 2005.
- J. Zhao, Y. Su, et al. “Illumination Ratio Image: Synthesizing and Recognition with Varying Illuminations”. Pattern Recognition Letters, vol. 24, pp. 2703-2710, 2003.
- H. Han, S. Shan, et al. “Lighting Aware Pre-processing for Face Recognition Across Varying Illumination”. Proceedings of the 11th European Conference on Computer Vision Part II, Heraklion, Crete, Greece: Springer Berlin Heidelberg. 2010, pp. 308-321, September 5-11, 2010.
- L. Zhang and D. Samaras. “Face Recognition from a Single Training Image under Arbitrary Unknown Lighting Using Spherical Harmonics”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, pp. 351-363, 2006.
- Y. Wang, Z. Liu, et al. “Face Re-Lighting from a Single Image under Harsh Lighting Conditions”. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA: IEEE. 2007, pp. 1-8, June 17-22,
- D. Lowe. “Distinctive Image Features from Scale-Invariant Keypoints”. International Journal of Computer Vision, vol. 60, pp. 91-110, 2004.
- B. Moghaddam and A. Pentland. “Probabilistic Visual Learning for Object Detection”. Proceedings of the Fifth International Conference on Computer Vision, Cambridge, MA, USA: IEEE. 1995, pp. 786-793, June 20-23, 1995.
- E. Kefalea “Object Localization and Recognition for a Grasping Robot”. Proceedings of the 24th Annual Conference of the IEEE on Industrial Electronics Society, Aachen, Germany: IEEE, 1998, pp. 2057-2062, August 31-September 4, 1998.
- H. Yuan, H. Ma and X. Huang, X. “Edge-based Synthetic Discriminant Function for Distortion Invariant Object Recognition”. Proceedings of the 15th IEEE International Conference on Image Processing. San Diego, CA, USA: IEEE, 2008, pp. 2352-2355, October 12-15, 2008.
- A. Chalechale, A. Mertins and G. Naghdy. “Edge Image Description using Angular Radial Partitioning”. IEE Proceedings on Vision, Image and Signal Processing, vol. 151, pp. 93-101, 2004.
- Y. Gao and M. Leung “Face Recognition Using Line Edge Map”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, pp. 764-779, 2002.
- Y. Gao, and Y. Qi. “Robust Visual Similarity Retrieval in Single Model Face Databases”. Journal of Pattern Recognition, vol. 38, pp. 1009-1020, 2005.
- Y. Suzuki and T. Shibata. “An Edge-Based Face Detection Algorithm Robust Against Illumination, Focus, and Scale Variations”. Proceedings of the 12th European Signal Processing Conference. Vienna, Austria: EURASIP, 2004, pp. 2279–2282, September 6-10, 2004.
- P. Zhao-Yi, Z. Yan-Hui and Z. Yu. “Real-Time Facial Expression Recognition Based on Adaptive Canny Operator Edge Detection”. Proceedings of the Second International Conference on Multimedia and Information Technology, Kaifeng: IEEE. 2010, pp. 154-157, April 24-25, 2010.
- F. Aràndiga, A. Cohen, et al. “Edge Detection Insensitive to Changes of Illumination in the Image”. Journal of Image and Vision Computing, vol. 28, pp. 553-562, 2010.
- Y. Suzuki and T. Shibata. “Illumination-invariant Face Identification Using Edge-Based Feature Vectors in Pseudo-2D Hidden Markov models”. Proceedings of the 14th European Signal Processing Conference. Florence, Italy: EURASIP. 2006.pp. 4-8, September 4-8, 2006.
- S. Samsung “Integral Normalized Gradient Image A Novel Illumination Insensitive Representation”. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Diego, CA, USA: IEEE. 2005. pp. 166-166, June 25-25, 2005.
- O. Arandjelovic “Gradient Edge Map Features for Frontal Face Recognition under Extreme Illumination Changes”. Proceedings of the British Machine Vision Conference. Surrey: BMVA Press. 2012. pp. 1-11, September 3-7, 2012.
- N. Khan, K. Arya and M. Pattanaik “Histogram statistics based variance controlled adaptive threshold in anisothropic diffucsion for low contrast image enhancement”. Signal Processing, vol. 93, pp. 1684-1693, 2013.
- W. Chen, M. Er and S. Wu. ”Illumination Compensation and Normalization for Robust Face Recognition using Discrete Cosine Transform in Logarithm Domain”. IEEE Transactions on Systems, Man, and Cybernetics, Part B, vol. 36, pp. 458-466, 2006.
- M. Nishiyama, T. Kozakaya and O. Yamaguchi “Illumination Normalization using Quotient Image-Based Techniques”. In: Delac, K., Grgic, M. and Bartlett, M. S. ed. Recent Advances in Face Recognition. Vienna, Austria: I-Teh. pp. 97-108, 2008.
- H. Han, S. Shan, et al. “Separability Oriented Pre-processing for Illumination-Insensitive Face Recognition”. Proceedings of the 12th European Conference on Computer Vision Part VII, Florence, Italy: Springer Berlin Heidelberg. 2012. pp. 307-320, October 7-13, 2012.
- D. Jobson, Z. Rahman and G. Woodell “A Single-Scale Retinex for Bridging the Gap Between Colour Images and the Human Observation of Scenes”. IEEE Transactions on Image Processing, vol. 6, pp. 965-976, 1997.
- R. Gross and V. Brajovic “An Image Pre-Processing Algorithm for Illumination Invariant Face Recognition”. Proceedings of the 4th International Conference on Audio-and Video-Based Biometric Person Authentication. Guildford, UK: Springer Berlin Heidelberg. 2003. pp. 10-18, June 9–11, 2003.
- Z. Tang, and R. Whitaker. “Modified Anisotropic Diffusion for Image Smoothing and Enhancement”. Proceedings of the 12th SPIE 4304 on Nonlinear Image Processing and Pattern Analysis, May 8, 2001. San Jose, CA: SPIE. 2001. 318-325.
- S. Du and R. Ward “Wavelet-Based Illumination Normalization for Face Recognition”. Proceedings of the IEEE International Conference on Image Processing, Genova, Italy: IEEE. 2005. 954-957, September 11-14, 2005
- A. Oppenheim, R. Schafer and T. Stockham. “Nonlinear Filtering of Multiplied and Convolved Signals”. IEEE Transactions on Audio and Electroacoustics, vol. 56, pp. 1264-1291, 1968.
- B. L. Tran and T. H. Le. "Using wavelet-based contourlet transform illumination normalization for face recognition", IJMECS, vol.7, pp.16-22, 2015.
- X. Xie, W. Zheng, et al. “Normalization of Face Illumination Based on Large-and Small-Scale Features”. IEEE Transactions on Image Processing, vol. 20, pp. 1807-1821, 2011.
- M. Santamaria and R. Palacios. “Comparison of Illumination Normalization Methods for Face Recognition”. Proceedings of the Third Cost 275 Workshop Biometrics on the Internet. Hatfield, UK: Addison-Wesley. 2005, pp. 27-30, October 27-28, 2005.
- S. Pizer and E. Amburn “Adaptive Histogram Equalization and Its Variations”. Journal of Computer Vision, Graphics, and Image Processing, vol. 39, pp.355-368, 1987.
- X. Xie and K. Lam “Face Recognition under Varying Illumination Based on a 2D Face Shape Model”. Journal of Pattern Recognition, vol. 38, pp. 221-230, 2005.
- H. Liu, W. Gao, et al. “Illumination Compensation and Feedback of Illumination Feature in Face Detection”. Proceedings of the IEEE International Conference on Info-Tech and Info-Net, Beijing: IEEE. 2001. pp. 444-449, Oct. 29-Nov 1, 2001.
- S. Shan, W. Gao, et al. “Illumination Normalization for Robust Face Recognition against Varying Lighting Conditions”. Proceedings of the IEEE International Workshop on Analysis and Modelling of Faces and Gestures. Nice, France: IEEE. 2003. pp. 157-164, October 17, 2003.
- X. Tan and B. Triggs “Enhanced Local Texture Feature Sets for Face Recognition under Difficult Lighting Conditions”. IEEE Transactions on Image Processing, vol. 19, pp. 1635-1650, 2010.
- T. Zickler, P. Mallick et al. “Colour Subspaces as Photometric Invariants”. International Journal of Computer Vision, vol. 79, pp. 13-30, 2008.
- G. Finlayson, B. Schiele and J. Crowley. “Comprehensive Colour Normalization”. Proceedings of the 5th European Conference on Computer Vision, Freiburg, Germany: Springer Berlin Heidelberg. 1998. pp. 475–490, June 2–6, 1998.
- S. Shafer “Using Colour to Separate Reflection Components”. Journal of Colour Research and Applications, vol. 10, pp. 210-218, 1985.
- G. Klinker, S. Shafer, and T. Kannade, “Using a Colour Reflection Model to Separate Highlights from Object Colour”. In Proceedings of the 1st IEEE International Conference on Computer Vision. London: IEEE. 1987, pp. 45-150, June 8-11, 1987.
- K. Schluns and M. Teschner “Fast Separation of Reflection Components and Its Application in 3D Shape Recovery”. Proceedings of the 3rd Colour Imaging Conference. Scottsdale, Arizona, USA: Addison-Wesley. 1995, pp. 48-51, November 7-10, 1995.
- R. Bajcsy, S. Lee and A. Leonardis “Detection of Diffuse and Specular Interface Reflections and Inter-Reflections by Colour Image Segmentation”. International Journal of Computer Vision. vol. 17, pp. 241-272, 1996.
- S. Lee and R. Bajcsy “Detection of Specularity using Colour and Multiple Views”. Proceedings of the Second European Conference on Computer Vision. Santa Margherita Ligure, Italy: Springer-Verlag. 1992. pp. 99-114, May 19-22, 1992.
- S. Mallick, T. Zickler et al. “Specularity Removal in Images and Videos: A PDE approach”. Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: Springer Berlin Heidelberg. 2006. pp. 550-563, May 7-13, 2006.
- R. Tan, and K. Ikeuchi ”Separating Reflection Components of Textured Surfaces using a Single Image”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, pp. 178-193, 2005.
- M. Tappen, W. Freeman and E. Adelson “Recovering Intrinsic Images from a Single Image”. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, pp. 1459-1472, 2005.
- D. Jobson, Z. Rahman and G. Woodell. “Multiscale Retinex for Colour Image Enhancement”. Proceedings of the IEEE International Conference on Image Processing. Lausanne, Switzerland: IEEE. 1996, pp. 1003-1006, September 3, 1996.
- L. Wang, L. Xiao, et al. “Variational bayesian method for retinex”. IEEE Transactions on Image Processing, vol. 23, pp. 3381-3396, Aug. 2014.
- B. Li, B. W. Liu, et al. ”Face Recognition using Various Scales of Discriminant Colour” Neurocomputing, vol. 94, pp. 68-76, 2012.
- A. Nefian, “Georgia Tech Face Database”. http://www.anefian.com/research/face_reco.htm. [Accessed: 2 Feb. 2013].
- G. Huang, M. Mattar, et al. “Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments”. Proceedings of the Workshop on Faces in 'Real-Life' Images: Detection, Alignment, and Recognition. September 1-16, 2008. Marseille, France: Inria. 2008. 1-14.
- R. Singh, M. Vatsa, et al. “Plastic Surgery: A New Dimension to Face Recognition”. IEEE Transactions on Information Forensics and Security, vol. 5, pp. 441–448, 2010.
- A. Savchenko “Directed Enumeration Method in Image Recognition”. Journal of Pattern Recognition, vol. 45, pp. 2952-2961, 2012.
