Многопоточность на платформе.NET. Обзор средств

Автор: Шимановская М.В., Муфтеев И.А., Илларионова Е.И.
Журнал: Вестник Пермского университета. Математика. Механика. Информатика @vestnik-psu-mmi
Рубрика: Информатика. Информационные системы
Статья в выпуске: 2 (49), 2020 года.
Бесплатный доступ
Рассмотрены способы применения параллелизма на платформе .NET на языке программирования C#. Приведен сравнительный анализ подходов к распределенным вычислениям. Представлены числовые показатели по времени, между каждым из способов, а также диаграммы для наглядного представления.
Многопоточность
Короткий адрес: https://sciup.org/147245488
IDR: 147245488 | УДК: 004.451.45 | DOI: 10.17072/1993-0550-2020-2-69-75
Multithreading on the .NET platform. Product overview
The methods of using parallelism on the .NET platform in the C # programming language are considered. A comparative analysis of distributed computing approaches is presented. Numerical indicators of time between each of the methods are presented, as well as diagrams for visual representation.
Текст научной статьи Многопоточность на платформе.NET. Обзор средств
Традиционно программное обеспечение писалось для последовательных вычислений, алгоритмы реализовывались в виде последовательного потока инструкций, которые выполняются на центральном процессоре.
Идея параллельных вычислений не нова и зародилась в 1960-х гг., ее основателем был Эдгар Дейкстрой. Однако реализация таких вычислений была осложнена физической реализацией исполняющего устройства, который владел только одним потоком управления в один момент времени.
Развитие центральных процессоров в 2000-х годах шагнуло на ступень эволюции, которая определила ветвь развития в сторону увеличения процессорных ядер. Сейчас программисты имеют практически неограниченный потенциал для разработки программного обеспечения с использованием нескольких вычислительных ресурсов для решения задачи, однако до сих пор у большинства появляются трудности с определением параллельного алгоритма.
Эффективное распараллеливание программ на нескольких вычислительных ресурсах дает:
‒ Прирост в производительности вычислений;
‒ Отзывчивость пользовательского интер фейса (во время выполнения фоновых задач);
‒ Горизонтальное масштабирование, позволяющее улучшать производительность за счет применения нескольких ядер процессора.
Рассмотрим возможности встроенных классов и интерфейсов по организации многопоточных приложений на языке C#. На каждый способ будет приводиться пример, который производит определенные действия над массивом значений.
Наипростейший пример задействования параллельного вычисления – возведение массива в степень. Последовательный метод будет проходить по каждому элементу и выполнять действие (листинг 1).
Листинг 1. Последовательный доступ к массиву
-
1: var arr = new int[n];
-
2: for (int i = 0; i < n; i++)
-
3: {
-
4: arr[i] = (int)Math.Pow(arr[i],5);
-
5: }
Такую процедуру возведения массива в степень довольно просто подвергнуть разделению на подзадачи, которые будут заниматься своею независимой частью.
Класс Thread
Класс Thread является самым элементарным из всех типов пространства имен System.Threading. Этот тип определяет набор методов, которые позволяют создавать новые потоки внутри текущего контейнера приложения, а также приостанавливать, останавливать и уничтожать определенный поток. Основным применением этого метода является запуск фоновых потоков.
Для того чтобы применить класс Thread, необходимо для него заранее подготовить «почву», а именно разделить массив на такое количество частей, чтобы каждая часть была доступна отдельному потоку. Количество потоков рекомендуется создавать в таком количестве, сколько доступно ядер процессора, если используется технология Hyper-threading то количество исполняющих устройств в два раза больше.
Для разделения массива создадим класс Step, который на каждую часть массива будет иметь начальный индекс и конечный (листинг 2).
Листинг 2 . Класс Step
-
1: class Step
-
2:{
-
3: public int[] Arr { get; set;}
-
4: private int From { get; set;}
-
5: private int To { get; set;}
-
6: public Step(int[] arr, int index,
int threadCount)
-
7:{
-
8: Arr = arr;
-
9: var rd = (int)((double)arr.Length
/ threadCount);
-
10: From = index * rd;
-
11: To = index != (threadCount - 1)?
-
12:}
-
13: public void Solve()
-
14:{
-
15: for (int i = From; i <= To; i++)
-
16:{
-
17: Arr[i]=(int)Math.Pow(Arr[i],5);
-
18:}
-
19:}
-
20:}
Реализация параллелизма тогда будет выглядеть как вызов метода Solve из каждого потока (листинг 3).
-
1: var threads = new
Thread[threadCounts];
-
2: var steps = new Step[threadCounts];
-
3: for (int i = 0; i < threadCounts;i++)
-
4: {
-
5: steps[i] = new Step(arr, i,
threadCounts);
-
6: threads[i] = new Thread(new
ThreadStart(steps[i].Solve));
-
7: }
Класс ThreadPool
Создание потоков требует времени. Если есть различные короткие задачи, подлежащие выполнению, можно создать набор потоков заранее и затем просто отправлять соответствующие запросы, когда наступает очередь для их выполнения. Было бы неплохо, если бы количество этих потоков автоматически увеличивалось с ростом потребности в потоках и уменьшалось при возникновении потребности в освобождении ресурсов.
Создавать подобный список потоков самостоятельно не понадобится. Для управления таким списком предусмотрен класс ThreadPool, который по мере необходимости уменьшает и увеличивает количество потоков в пуле до максимально допустимого. Значение максимально допустимого количества потоков в пуле может изменяться. В случае двуядерного ЦП оно по умолчанию составляет 1023 рабочих потоков и 1000 потоков ввода-вывода.
Можно указывать минимальное количество потоков, которые должны запускаться сразу после создания пула, и максимальное количество потоков, доступных в пуле. Если остались какие-то подлежащие обработке задания, а максимальное количество потоков в пуле уже достигнуто, то более новые задания будут помещаться в очередь и там ожидать, пока какой-то из потоков завершит свою работу.
Чтобы запросить поток из пула для обработки вызова метода, можно использовать метод QueueUserWorkItem(). Этот метод перегружен, чтобы в дополнение к экземпляру делегата WaitCallback позволить указывать необязательный параметр System.Object для специальных данных. Данная функция добавлена для организации пользовательских callback-функций.
Листинг 3. Класс Thread
В примере, так же, как и в случае с Thread необходимо сначала подготовить массив данных, а затем отправить на обработку (листинг 4).
Листинг 4. Класс ThreadPool
-
1: using var mrEvent = new
ManualResetEvent(false);
-
2: for (int i = 0; i < processors; i++)
-
3: ThreadPool.QueueUserWorkItem(
-
4: new WaitCallback(x =>
-
5: {
-
6: var step = x as Step;
-
7: step.Solve();
-
8: if (Interlocked.Decrement(ref
pool) == 0)
-
9: mrEvent.Set();
-
10: }), steps[i]);
-
11: mrEvent.WaitOne();
Класс Task
В основу TPL (Task Parallel Library) положен класс Task. Элементарная единица исполнения инкапсулируется в TPL средствами класса Task, а не Thread. Класс Task отличается от класса Thread тем, что он является абстракцией, представляющей "умную" асинхронную операцию. Массив таких задач в пуле одного приложения может исполняться как синхронно на одном ядре, так и в режиме многопоточности, в зависимости от нагрузки, а в классе Thread инкапсулируется поток исполнения.
Кроме того, исполнением задач управляет планировщик задач, который работает с пулом потоков. Это, например, означает, что несколько задач могут разделять один и тот же поток. Класс Task (и вся остальная библиотека TPL) определены в пространстве имен System.Threading.Tasks применение этого подхода к нашей задаче см. в листинге 5.
Листинг 5. Класс Task
1:var threadCounts =
Environment.ProcessorCount;
2:var arr = new int[n];
3:var tasks = new Task[threadCounts];
4:var steps = new Step[threadCounts];
5:for (int i = 0; i < threadCounts;i++)
-
6: steps[i] = new Step(arr, i,
threadCounts);
7:for (int i = 0; i < threadCounts;i++)
-
8: tasks[i]=Task.Run(steps[i].Solve);
-
9: Task.WaitAll(tasks);
PLINQ
Parallel LINQ (PLINQ) – параллельная реализация шаблона LINQ. Запрос PLINQ во многом напоминает непараллельный запрос LINQ to Objects. Запросы PLINQ, как и последовательные запросы LINQ, работают с любым источником данных IEnumerable в памяти и поддерживают отложенное выполнение, т. е. выполнение только по завершении перечисления запроса. Основное различие состоит в том, что PLINQ пытается задействовать сразу все процессоры в системе. Для этого разбивается источник данных на сегменты, а затем запрашивается каждый сегмент в отдельном рабочем потоке сразу, используя сразу несколько процессоров. Во многих случаях параллельное выполнение значительно сокращает время выполнения запроса.
Благодаря параллельному выполнению PLINQ позволяет повысить производительность некоторых видов запросов по сравнению с устаревшим кодом. Часто для этого достаточно добавить к источнику данных оператор запроса AsParallel (листинг 6). Тем не менее, параллелизм может представлять свои собственные сложности, и не все операции запросов в PLINQ выполняются быстрее. Некоторые запросы при применении параллелизма только замедляются. В связи с этим необходимо понимать, как влияют на параллельные запросы такие аспекты, как упорядочение.
Листинг 6 . Запрос PLINQ
-
1: var arr = new int[n];
-
2: arr = arr
-
3: .AsParallel()
-
4: .AsOrdered()
-
5: .Select(x => (int)Math.Pow(x, 5))
-
6: .ToArray();
-
7: arr = arr.Select(x => x).ToArray();
Методы класса Parallel
Методы класса Parallel – For и ForEach являются отличными кандидатами для парал-лелизации мелких однотипных задач над одной коллекцией. Библиотека TPL предоставляет поддержку распараллеливания циклов посредством явных методов, очень близких своим языковым эквивалентам. Данные методы максимально близко имитируют поведение и синтаксис циклов for и foreach.
Метод Parallel.ForEach() применим для перебора коллекций из ссылочных элементов, то есть объектов, реализующих какой-либо класс (листинг 8).
Листинг 8 . Метод Parallel.ForEach()
|
1: |
var arr = Enumerable |
|
2: |
.Range(0, n) |
|
3: |
.Select(x => new Number { X = … }) |
|
4: |
.ToArray(); |
|
5: |
Parallel.ForEach(arr, x => x.X = (int)Math.Pow(x.X, 5)); |
Метод Parallel.ForEach() отличается от Parallel.For() тем, что входной параметр – ссылка на коллекцию IEnumerable а не числовой промежуток, вследствие чего функция обратного вызова принимает не индекс обрабатываемого элемента, а сам элемент, поэтому, если элемент массива структурный, например int, то в области видимости обратного вызова с типом делегата Action бессмысленно присвоение элементу нового значения.
Из вышесказанного следует, что для демонстрации работы этого метода необходимо обернуть каждый элемент массива в класс с единственным полем – элементом массива. Для наглядной демонстрации того или иного метода произведены измерения быстродействия каждого метода относительно количества элементов. В качестве аппаратуры взяты два компьютера, с процессорами Intel Core i5 двух поколений – 3-го и 8-го поколения c тактовой частотой 2,5–3,1 ГГц и 2,8–4,0 ГГц соответственно. Критериями исследования выбраны 4 позиции – время работы, занимаемый объем памяти метода с подготовленными данными, объем памяти, занимаемой методом, и сложность кода. Каждый способ повторялся 50 раз для усреднения результатов.
Рассмотрим показатели обработки данных на процессоре Intel Core i5 8400.
В табл. 1 представлены числовые показатели, отображающие зависимость времени обработки в секундах от количества элементов в последовательности. Sequence – метод последовательного доступа к массиву.
Исходя из полученных показателей видно, что самыми эффективными являются методы ThreadPool и Task. Такой результат можно объяснить тем, что для обоих пул-потоков выделяется программной платформой во время запуска приложения, что не влечет за собою расходов по времени на создание потоков.
Для наглядности на рис. 1 изображен график. Из графика исключен метод Sequence, как самый медленный, дабы не уплотнять показатели остальных.
Таблица 1. Занимаемое время обработки (c)
|
Эл-ов Метод |
1 млн |
10 млн |
100 млн |
|
Sequence |
0,00061 |
0,00604 |
0,05946 |
|
For |
0,00013 |
0,00129 |
0,01349 |
|
ForEach |
0,00015 |
0,00128 |
0,01331 |
|
PLINQ |
0,00013 |
0,00108 |
0,01020 |
|
ThreadPool |
0,00012 |
0,00103 |
0,01024 |
|
Thread |
0,00035 |
0,00151 |
0,01052 |
|
Task |
0,00011 |
0,00104 |
0,01020 |
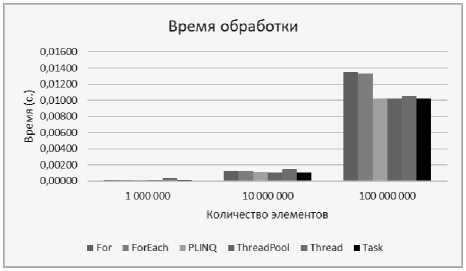
Рис. 1. Время обработки
В табл. 2 представлены показатели, отображающие зависимость объема занимаемой оперативной памяти в мегабайтах, включая данные (массив) и накладные расходы для создания потоков от количества элементов в массиве.
На рис. 2 изображен график.
В данном случае самым "прожорливым" оказался метод ForEach.
Как было описано ранее, для применения метода ForEach необходимо создать массив не из структурных элементов, а ссылочных (классов), поэтому объем памяти одного элемента занимает не 4 байта, как в случае структуры int, а 32 (помимо числового поля у объекта память занимает служебный блок в 16 байт + 4 байта на числовое поле и выравнивание памяти до кратного 8 в большую сторону – 32).
Таблица 2. Занимаемый объем памяти (МБ )
|
Эл-ов Метод |
1 млн |
10 млн |
100 млн |
|
Sequence |
3,82 |
38,15 |
381,47 |
|
For |
3,85 |
38,21 |
381,56 |
|
ForEach |
30,56 |
305,24 |
3052,05 |
|
PLINQ |
3,85 |
38,19 |
381,51 |
|
ThreadPool |
3,82 |
38,15 |
381,47 |
|
Thread |
3,86 |
38,19 |
381,52 |
|
Task |
3,82 |
38,15 |
381,47 |
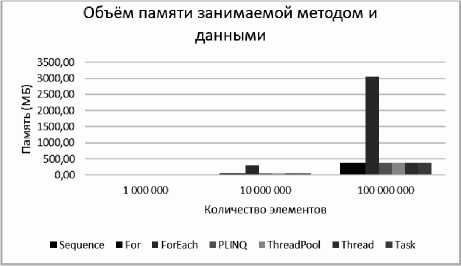
Рис. 2. Объем памяти, занимаемый методом и данными
В табл. 3 представлены показатели, отображающие зависимость объема занимаемой оперативной памяти реализацией параллелизма в килобайтах от количества элементов в массиве. На рис. 3 изображен график.
Исходя из показателей, вполне логично, что последовательный метод не будет использовать оперативную память, а методы Task и ThreadPool, в основе которых лежит пул-потоков, занимают минимальный объем.
Таблица 3. Используемая память на реализацию параллелизма (КБ )
|
Эл-ов Метод |
1 млн |
10 млн |
100 млн |
|
Sequence |
0,00 |
0,00 |
0,00 |
|
For |
40,30 |
66,24 |
90,24 |
|
ForEach |
42,88 |
64,96 |
267,04 |
|
PLINQ |
40,57 |
40,68 |
40,81 |
|
ThreadPool |
0,80 |
0,32 |
0,32 |
|
Thread |
48,32 |
48,00 |
48,00 |
|
Task |
0,64 |
1,02 |
1,92 |
Таблица 4. Занимаемое время обработки (с)
|
Эл-ов Мегод\^ |
1 млн |
10 млн |
100 млн |
|
Sequence |
0,00105 |
0,01009 |
0,10031 |
|
For |
0,00045 |
0,00418 |
0,04214 |
|
ForEach |
0,00043 |
0,00431 |
0,04381 |
|
PLINQ |
0,00045 |
0,00424 |
0,04171 |
|
ThreadPool |
0,00037 |
0,00366 |
0,03797 |
|
Thread |
0,00059 |
0,00377 |
0,03681 |
|
Task |
0,00037 |
0,00366 |
0,03653 |
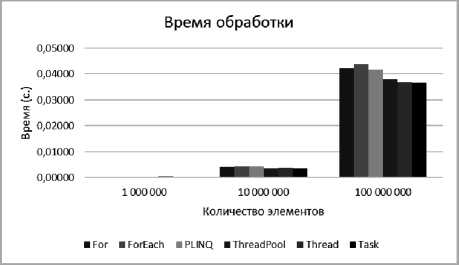
Рис. 4. Время обработки
Таблица 5. Занимаемый объем памяти (МБ)
|
Эл-ов Метод'\ |
1 млн |
10 млн |
100 млн |
|
Sequence |
3,82 |
38,15 |
381,47 |
|
For |
3,84 |
38,20 |
381,67 |
|
ForEach |
30,55 |
305,24 |
3052,20 |
|
PLINQ |
3,84 |
38,17 |
381,49 |
|
ThreadPool |
3,82 |
38,15 |
381,47 |
|
Thread |
3,85 |
38,18 |
381,50 |
|
Task |
3,82 |
38,15 |
381,47 |
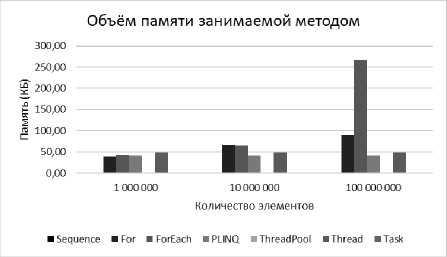
Рис. 3. Объем памяти, занимаемый методом
Для того чтобы подтвердить числовые показатели произведены измерения на более старшей модели процессора Intel Core i5 3210m.
В табл. 4–6 представлены показатели с зависимостью от количества элементов. К каждой таблице представлены графики (рис. 4–6) отображающие показатели.
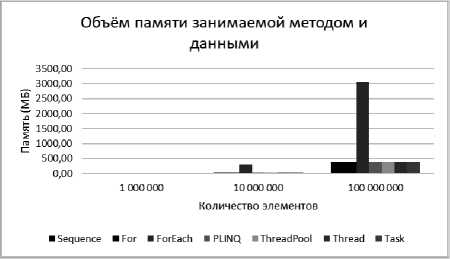
Рис. 5. Объем памяти, занимаемый методом и данными
Таблица 6. Используемая память на реализацию параллелизма (КБ )
|
'\^^ Эл-ов Метод |
1 млн |
10 млн |
100 млн |
|
Sequence |
0,00 |
0,00 |
0,00 |
|
For |
28,96 |
50,72 |
203,04 |
|
ForEach |
31,68 |
64,41 |
283,71 |
|
PLINQ |
25,04 |
24,67 |
24,66 |
|
ThreadPool |
0,48 |
0,32 |
0,32 |
|
Thread |
32,32 |
32,00 |
32,00 |
|
Task |
1,12 |
1,23 |
1,44 |
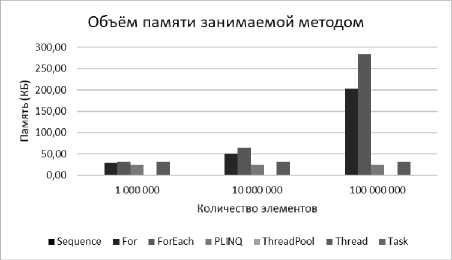
Рис. 6. Объем памяти занимаемый методом
Как и следовало ожидать, на более старшей модели процессора показатели завышены по времени, однако они пропорциональны графикам, полученным на младшем процессоре. Объем используемой памяти также пропорционален и равнозначен, за исключением небольших погрешностей, на которые влияют как физические характеристики машины, так и программные особенности исполняющей программной платформы разных версий .NET.
Выводы
В заключение можно отметить субъективные показатели по четырем критериям и выявить наиболее эффективные методы, которые можно применить для параллельных вычислений.
Время . По данному критерию эффективными являются методы Task и ThreadPool, причиной этого служит то, что при запуске этих методов не нужно каждый раз создавать новые потоки и запускать их, так как программная платформа делает это заранее, в момент запуска домена приложения.
Занимаемый объем памяти с подготовленными данными . Этот критерий выполнен для того, чтобы показать преимущество методов, которые могут работать не только с массивом состоящим из элементов ссылочного типа, но и структурного, в отличие от ForEach.
Объем памяти, занимаемой методом . Эффективными методами являются Task и ThreadPool, по той же причине, что описана ра-
нее. Данный критерий позволяет увидеть не только объем памяти, занимаемой методом, но и зависимость некоторых методов от количества элементов в массиве. Методы For и ForEach занимают больше памяти с ростом количества элементов – это получается из-за того, что дан ные методы создают стек задач, которые выпол няются параллельно, возможно, что данный стек разбивается пропорционально количеству имеющихся процессорных ядер в системе.
Сложность кода . Данный критерий – субъективный для каждого рода задачи.
Для задач, в которых необходимо обойти массив, подойдут – For, ForEach и PLINQ.
Для запуска потоков в фоновом режиме с возможностью синхронизации данных как между собою, так и между главным потоком подойдет метод Thread.
Список литературы Многопоточность на платформе.NET. Обзор средств
- Ахмадулин Р.К. Параллельное программирование на языке C#: учеб.-метод. пособие для студентов. Тюмень: ТИУ, 2016. 37 с.
- Стивен Клири. Concurrency in C# Cookbook: учеб.-метод. пособие для студентов. 2-е изд. СПб.: O'Reilly Media, 2018. 254 с.
- Террелл Рикардо. Конкурентность и параллелизм на платформе.NET. Паттерны эффективного проектирования. СПб.: ТИУ, 2019. 624 с.
- Шилдт Герберт. Полное руководство С# 4.0. М.: ООО И.Д. Вильямс, 2011. 1465 с.
- Джозеф Албахари. Threading in C#. URL: http://www.albahari. com/threading/part3. aspx Загл. с экрана (дата обращения: 02.10.2019).
- NET Type Internals - From a Microsoft CLR Perspective. 2007. URL: https://www.codeproject.com/Articles/20481/ NET-Type-Internals-From-a-Microsoft-CLR-Perspecti. Загл. с экрана (дата обращения: 13.09.2019).
- 2002 PODC Influential Paper Award. 2002. URL: http://www.podc.org/influential/2002-influential-paper/ Загл. с экрана (дата обращения: 25.09.2019).
