Модель параллельных вычислений для многопроцессорных систем с распределенной памятью

Автор: Ежова Надежда Александровна, Соколинский Леонид Борисович
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 2 т.7, 2018 года.
Бесплатный доступ
Появление мощных многопроцессорных вычислительных систем выдвигает на первый план вопросы, связанные с разработкой фреймворков (шаблонов), позволяющих создавать высокомасштабируемые параллельные программы, ориентированные на системы с распределенной памятью. При этом особенно важной является проблема разработки моделей параллельных вычислений, позволяющих на ранней стадии проектирования программы оценить ее масштабируемость. В статье приводятся общие требования к модели вычислений и строится новая высокоуровневая модель параллельных вычислений Bulk Synchronous Farm (BSF), являющаяся расширением модели BSP, и основанная на методе программирования SPMD и парадигме «мастер-рабочие». Модель BSF ориентирована на вычислительные системы с массовым параллелизмом на распределенной памяти, включающие в себя сотни тысяч процессорных узлов, и имеющие экзафлопный уровень производительности и на численные итерационные методы с высокой временной сложностью. Определяется архитектура BSF-компьютера и описывается структура BSF-программы. Описывается формальная стоимостная метрика, с помощью которой получаются верхние оценки масштабируемости параллельных BSF-программ применительно к вычислительным системам с распределенной памятью. Также выводятся формулы для оценки эффективности распараллеливания BSF-программ и даются аналитические оценки масштабируемости BSF-приложений.
Параллельное программирование, модель параллельных вычислений, фреймворк "мастер-рабочие", модель bsf, временная сложность, масштабируемость, многопроцессорные системы с распределенной памятью
Короткий адрес: https://sciup.org/147160642
IDR: 147160642 | УДК: 004.051 | DOI: 10.14529/cmse180203
Parallel computational model for multiprocessor systems with distributed memory
The emergence of powerful multiprocessor computing systems brings to the fore issues related to the development of frameworks (templates) that allow creating high-scalable parallel programs oriented to systems with distributed memory. In this case, the most important problem is the development of parallel computing models that allow us to assess its scalability at an early stage of the program design. General requirements for computational models are described and a new high-level parallel computing model called BSF is derived, which is an extension of the BSP model, and is based on the SPMD programming method and the «master-workers» framework. The BSF-model is oriented to computational systems with massive parallelism on distributed memory, including hundreds of thousands of processor nodes, and having an exaflop level of performance and numerical iterative methods with high time complexity. The BSF-computer architecture is defined, and the structure of the BSF- program is described. The formal cost metric, which provides parallel BSF-programs scalability upper bounds in context of distributed memory computing systems, is described. Also, formula for BSF-programs parallel efficiency are derived.
Текст научной статьи Модель параллельных вычислений для многопроцессорных систем с распределенной памятью
Суперкомпьютер TaihuLight с массово-параллельной архитектурой, занимающий первое место в списке ТОР-500 [1] самых мощных суперкомпьютеров мира (ноябрь 2016), имеет 40 960 процессорных узлов, каждый из которых включает в себя 260 процессорных ядер. Общая оперативная память системы составляет 1.3 Петабайт, пиковая
Статья рекомендована к публикации программным комитетом Международной научной конференции «Параллельные вычислительные технологии (ПаВТ) 2018».
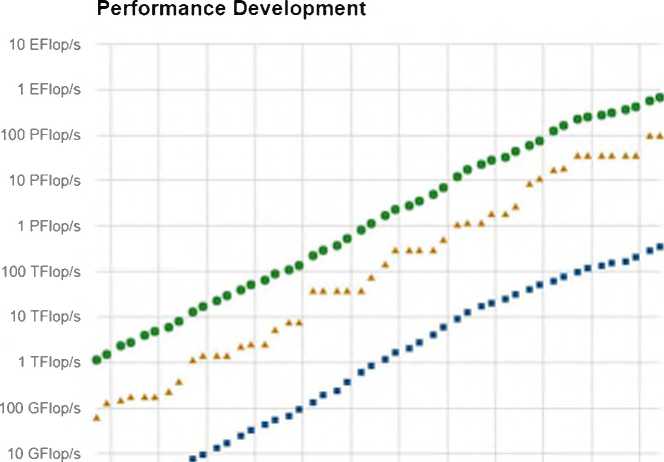
производительность превышает 120 петафлопс. Анализ динамики роста производительности суперкомпьютеров (рис. 1) показывает, что через 8-9 лет самый мощный суперкомпьютер становится рядовой системой, и что через 5-6 лет мы можем ожидать появление суперкомпьютера с экзафлопным уровнем производительности. Появление столь мощных многопроцессорных вычислительных систем выдвигает на первый план вопросы, связанные с разработкой фреймворков (шаблонов), позволяющих создавать высокомасштабируемые параллельные программы, ориентированные на системы с распределенной памятью. При этом особенно важной является проблема, разработки моделей параллельных вычислений, позволяющих на ранней стадии проектирования программы оценить ее масштабируемость.
1 GFIop/s ■■
100 MFIop/s
Lists
• Sum ♦• #1 • #500
Рис. 1. Динамика роста производительности суперкомпьютеров в ТОР500
В данной работе предлагается новая модель параллельных вычислений BSF (Bulk Synchronous Farm) — блочно-синхронная ферма, основанная на моделях «мастер-рабо-чие», BSP и SPMD. Модель BSF ориентирована на вычислительные системы с массовым параллелизмом на распределенной памяти, включающие в себя сотни тысяч процессорных узлов, и имеющие экзафлопный уровень производительности. Модель BSF включает в себя каркас (skeleton) для разработки параллельных программ и стоимостную метрику для оценки масштабируемости приложения. Статья имеет следующую структуру. В разделе 1 дается краткий обзор концептуальных моделей параллельных вычислений, лежащих в основе новой модели BSF. В разделе 2 приводятся общие требования к модели
Модель параллельных вычислений для многопроцессорных систем с распределенной... вычислений. Раздел 3 посвящен описанию модели BSF. В разделе 4 строится стоимостная метрика, и даются аналитические оценки масштабируемости BSF приложений, а также исследуется вопрос эффективности распараллеливания BSF программ. В заключении суммируются полученные результаты и намечаются направления дальнейших исследований.
1. Модели параллельных вычислений
Одним из популярных фреймворков, используемых в параллельном и распределенном программировании, является парадигма «мастер-рабочие» [2-4]. В соответствии с этой парадигмой процессорные узлы вычислительной системы делятся на два множества: узлы-мастера и узлы-рабочие. Задача, решаемая на многопроцессорной системе, разбивается на независимые подзадачи. Каждая подзадача, в свою очередь, разбивается на три последовательные стадии: стадия предобработки, стадия вычислений и стадия постобработки. Стадии предобработки и постобработки выполняются узлами-мастерами, стадии вычислений выполняются узлами-рабочими. В каждый момент времени любой процессорный узел может выполнять только одну стадию. Предполагается, что количество подзадач совпадает с количеством узлов-рабочих и превышает количество узлов- мастеров. Решение задачи происходит следующим образом. Очередная подзадача назначается некоторому узлу-мастеру, который выполняет стадию предобработки. После этого он посылает задание (передает данные) узлу-рабочему, который должен выполнить стадию вычислений указанной подзадачи. После того, как узел-рабочий завершил требуемые вычисления, он посылает отчет (передает данные) тому узлу-мастеру, от которого получил задание. На этом выполнение подзадачи заканчивается. Задача считается выполненной целиком, когда выполнены все ее подзадачи. Фреймворк «мастер-рабочий» очень часто используется в параллельном программировании при реализации различных приложений, ориентированных на многопроцессорные системы с распределенной памятью (см., например, [5-10]). При этом наиболее популярна конфигурация, включающая одного мастера и множество рабочих (рис. 2). Основной проблемой модели «мастер-рабочие» является нахождение такого расписания вычислений, при котором время выполнения задачи будет минимальным. Известно, что указанная проблема является в общем случае NP-сложной [11]. В определенной мере эту проблему можно решить, используя модель SPMD.
SPMD (Single Program Multiple Data) [3, 12] — популярная парадигма параллельного программирования, в соответствии с которой все процессорные узлы выполняют одну и ту же программу, но обрабатывают различные данные. Какие именно данные необходимо обрабатывать тому или иному процессорному узлу, определяется его уникальным номером, который является параметром программы. Данный подход наиболее часто используется в сочетании с технологией MPI (Message Passing Interface) [13], которая де-факто является стандартом для параллельного программирования на распределенной памяти.
Модели BSP (Bulk-Synchronous Parallelism) была предложена Валиантом (Valiant) в работе [14]. Данная модель широко используется при разработке и анализе параллельных алгоритмов и программ. BSP-компьютер представляет собой систему из р процессоров, имеющих приватную память, и соединенных сетью, позволяющей передавать
Мастер
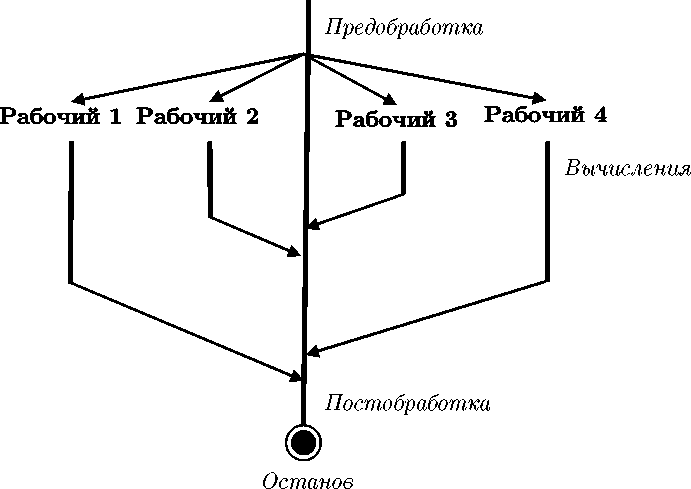
Рис. 2. Фреймворк «мастер-рабочие».
Полужирными линиями обозначены потоки вычислений, тонкими линями со стрелками — потоки данных пакеты данных фиксированного размера от одного процессора другому. Для соединительной сети вводятся следующие характеристики: д — время, необходимое для передачи по сети одного пакета; L — время, необходимое для инициализации передачи данных от одного процессора другому.
BSP-программа состоит из р потоков команд, каждый из которых назначается от-делвному процессору, и делится на супершаги, которые выполняются последовательно относительно друг друга. Каждый супершаг, в свою очередь, включает в себя следующие четыре последовательных шага: 1) вычисления на каждом процессоре с использованием только локальных данных; 2) глобальная барьерная синхронизация; 3) пересылка данных от любого процессора любым другим процессорам; 4) глобальная барьерная синхронизация. Переданные данные становятся доступными для использования только после барьерной синхронизации. Пример BSP-программы приведен на рис. 3.
Стоимостная функция в модели BSP строится следующим образом [15]. Пусть BSP-программа состоит из S супершагов. Пусть wt — максимальное время, затраченное каждым процессором на локальные вычисления, hi — максимальное количество пакетов, посланных или полученных каждым процессором, на г-том супершаге. Тогда общее время б , затрачиваемое системой на выполнение г-того супершага, вычисляется по формуле t = w. + qh -\-L .
г г у г
Время Т выполнения всей программы определяется по формуле
T = WpHgPLS,(1)
SS где Ж = ^шг и Н = с/^2•
8 = 18 = 1
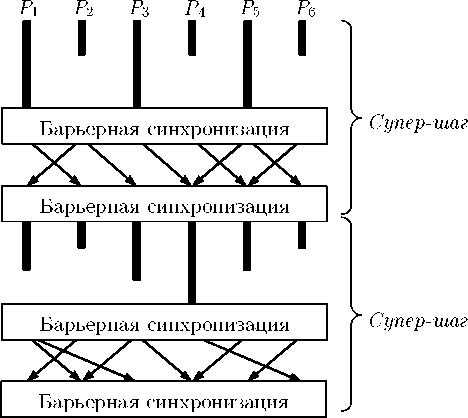
Рис. 3. BSP- программа из двух супершагов на шести процессорах. Жирными линиями обозначены локальные вычисления, тонкими линями со стрелками — пересылка данных
Для того, чтобы облегчить программистам использование той или иной модели параллельных вычислении на практике, применяются программное каркасы [16]. Одним из наиболее популярных является фермерной каркас (farm skeleton), реализующий фреймворк «мастер-рабочие» [17]. Такой каркас представляет собой программную структуру, полностью реализующую фреймворк «мастер-рабочие», однако вместо эффективного кода и реальных данных она содержит заглушки, которые должны быть заменены по определенным правилам на фрагменты кода, реализующие целевую задачу.
2. Требования к модели параллельных вычислении
Модель параллельных вычислений в общем случае должна включать в себя следующие четыре компонента, некоторые из которых в определенных случаях могут быть тривиальны [18].
-
1. Архитектурной компонент, описываемый как помеченный граф, узлы которого соответствуют модулям с различной функциональностью, а дуги — межмодульным соединениям для передачи данных.
-
2. Спеуификаусюнной компонент, определяющий, что есть корректная программа.
-
3. Компонент выполнения, определяющий, как взаимодействуют между собой архитектурные модули при выполнении корректной программы.
-
4. Стоимостной компонент, определяющий одну или более стоимостных метрик для оценки времени выполнения корректной программы.
В качестве наиболее важных свойств модели параллельных вычислений обычно выделяют следующие [19]:
-
- Юзабилити, определяющая легкость описания алгоритма и анализа его стоимости средствами модели (модель должна быть легкой в использовании).
-
- Адекватность, выражающаяся в соответствии реального времени выполнения программ и временной стоимости, полученной аналитически с помощью стоимостных
метрик модели (программа, имеющая меньшую временную стоимость, должна выполняться быстрее).
- Портируемость, характеризующая широту класса целевых платформ, для которых модель оказывается применимой.
3. Модель BSF
Модель параллельных вычислений BSF (Bulk Synchronous Farm) — блочно-синхронная ферма ориентирована на многопроцессорные системы с кластерной архитектурой и архитектурой МРР. BSF-компьютер представляет собой множество однородных процессорных узлов с приватной памятью, соединенных сетью, позволяющей передавать данные от одного процессорного узла другому. Среди процессорных узлов выделяется один, называемый узлом-мастером (или кратко мастером). Остальные К узлов называются узлами-рабочими (или просто рабочими). В BSF компьютере должен быть по крайней мере один узел мастер и один рабочий (К >1). Схематично архитектура BSF-компьютера изображена на рис. 4.
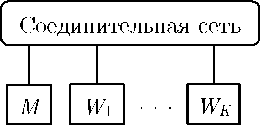
Рис. 4. BSF- компьютер.
М —мастер; Wi, ..., Wk —рабочие
BSF компьютер работает по схеме SPMD. BSF-программа состоит из последовательности супершагов и глобальных барьерных синхронизаций, выполняемых мастером и всеми рабочими. Каждый супершаг делится на секции двух типов: секции мастера, выполняемые только мастером, и секции рабочего, выполняемые только рабочими. Относительный порядок секций мастера и рабочего в рамках супершага не существенен. Данные, обрабатываемые конкретным узлом-рабочим, определяются его номером, являющимся параметром среды исполнения.
BSF программа включает в себя следующие последовательные разделы (рис. 5):
-
- инициализация;
-
- итерационный процесс;
-
- завершение.
Инициализация представляет собой супершаг, в ходе которого мастер и рабочие считывают или генерируют исходные данные. Инициализация завершается барьерной синхронизацией. Итерационный процесс состоит в многократном повторении тела итерационного процесса до тех пор, пока не выполнено условие завершения, проверяемое мастером. В разделе завершение осуществляется вывод или сохранение результатов и завершение программы.
Тело итерационного процесса включает в себя следующие супершаги:
-
1) передача рабочим заданий от мастера;
-
2) выполнение задания (рабочими);
-
3) передача мастеру результатов от рабочих;
-
4) обработка полученных результатов мастером.
На первом супершаге мастер рассылает всем рабочим одинаковые задания. На втором супершаге происходит выполнение полученного задания рабочими (мастер при этом простаивает). Все рабочие выполняют один и тот же программный код, но обрабатывают
Секции мастера Секции рабочего
Итерационный процесс
|
1 |
Инициализация мастера |
Инициализация рабочего |
||
|
Барьерная синхронизация |
||||
|
Начало итерационного процесса |
||||
|
Посылка задания рабочим |
Получение задания от мастера |
|||
|
Выполнение задания |
||||
|
Получение результатов от рабочих |
Посылка результатов мастеру |
|||
|
Барьерная синхронизация |
||||
|
Обработка результатов |
||||
|
Конец итерационного процесса |
||||
|
Вывод результатов |
Завершение рабочего |
|||
|
Завершение мастера |
||||
Супершаги
Инициализация
Передача задания
Выполнение задания
Передача результатов
Обработка результатов
Завершение
Рис. 5. Структура BSF-программы различные данные, адреса которых определяются по номеру рабочего. Это означает, что все рабочие тратят на вычисления одно и то же время. Никаких пересылок данных при выполнении задания не происходит. Это является важным свойством модели BSF. На третьем супершаге все рабочие пересылают мастеру полученные результаты. Суммарный объем результатов является атрибутом задачи и не зависит от количества рабочих. После этого происходит глобальная барьерная синхронизация. В ходе четвертого супершага мастер производит обработку и анализ полученных результатов. Рабочие в это время простаивают. Время обработки мастером результатов, полученных от рабочих, является параметром задачи и не зависит от количества рабочих. Если после обработки результатов условие завершения оказывается истинным, то происходит выход из итерационного процесса, в противном случае осуществляется переход на первый супершаг итерационного процесса. На четвертом супершаге происходит вывод или сохранение результатов и завершение работы мастера и рабочих. Графическая иллюстрация работы BSF-программы приведена на рис. 6.
Областъю применения модели BSF являются масштабируемые итерационные численные методы, имеющие высокую вычислительную сложность итерации при относительно невысокой стоимости коммуникаций. Под масштабируемым итерационным методом понимается метод, допускающий разбиение итерации на подзадачи, не требующие обменов данными. Пример такого метода можно найти в работе [20].
4. Исследование масштабируемости BSF-программ
Основной характеристикой масштабируемости является ускорение, вычисляемое как отношение времени выполнения программы на одном процессорном узле ко времени выполнения на К узлах. В данном разделе мы проведем аналитическое исследование масштабируемости модели BSF. Для этого нам понадобится оценка временных затрат на выполнение BSF-программы. Мы предполагаем, что временные затраты на инициализацию
М Ж Ж И-з Ж Ж
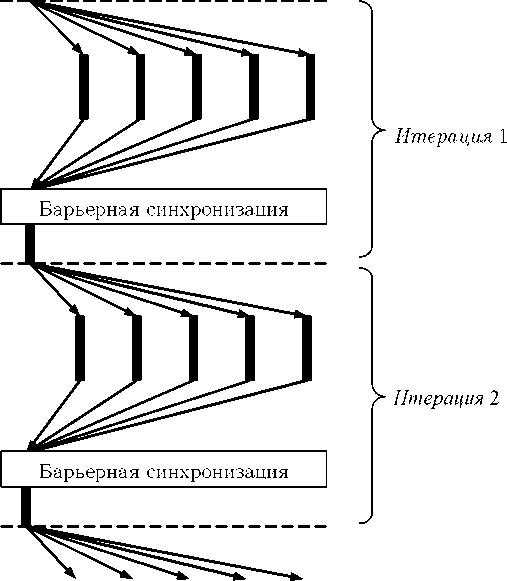
Рис. 6. Иллюстрация работы ВВВ-программы с одним мастером М и пятью рабочими W1,...,W5 (жирными линиями обозначены локальные вычисления, тонкими линями со стрелками — пересылка данных, пунктирными линиями — границы одной итерации)
и завершение BSF-программы пренебрежимо малы по сравнению с затратами на выполнение итерационного процесса. Стоимость итерационного процесса получается как сумма стоимостей отдельных итераций. Поэтому для оценки времени выполнения BSF- программы нам достаточно получить оценку временной стоимости одной итерации.
Рассмотрим сначала конфигурацию вычислительной системы в составе мастера и одного рабочего. Пусть t — время, необходимое для посылки задания рабочему (без учета латентности); t — время, необходимое для передачи результата мастеру от рабочего (без учета латентности); t — время обработки мастером результатов, полученных от рабочего; L — затраты на инициализацию операции передачи сообщения (латентность); £ — время выполнения задания бригадой из одного рабочего. Общее время Ту выполнения итерации одним мастером и бригадой из одного рабочего может быть вычислено следующим образом:
Тл = t -Н ^ -V L -V t Н- ^ A- L (2)
что равносильно
^1 = 2^ + t8 + ф + tp + 0. (3)
Теперь рассмотрим конфигурацию вычислительной системы в составе одного мастера и К рабочих. Все рабочие получают от мастера одно и то же сообщение, поэтому общее время передачи сообщений от мастера рабочим составит K(L + t ) . Все рабочие выполняют один и тот же код над своей частью данных, поэтому время выполнения всех вычислений К рабочими в рамках одной итерации будет равно t^JК . Суммарный объем результатов, вычисленных рабочими, является параметром задачи и не зависит от К, поэтому общее время передачи сообщений мастеру от рабочих составит К • L + t . Время обработки мастером результатов, полученных от рабочих, также является параметром задачи и не зависит от количества рабочих. Таким образом, общее время Тк выполнения итерации в системе с одним мастером и К рабочими может быть вычислено следующим образом:
ТА-+(4)
Из формул (3) и (4) получаем следующую формулу для ускорения а:
а(К) = =.
Тк K^L + tsHtr+tp+tjK
Свяжем величины t и ф через новую переменную у следующим уравнением:
у = 1ё(^Д)-(
Тогда
^ = 10"^.(7)
Подставляя значение t из уравнения (7) в уравнение (5), получим т 2L + 107' / + t + t + t
а(К) = =--------------w r р w , .(8)
Тк K(2L + 10 + ф + tp + t^K
Исследуем, как для некоторой фиксированной задачи выглядят графики зависимости ускорения от числа рабочих. Пусть имеется некоторая задача с решением в пространстве Кп. Предположим, что n = 104, ^ = п3 = 1012, tp = tr = п = 104, L = 0.5 . (9)
Подставляя указанные значения в формулу (8), получаем
1 + IO12 + 204 + 1012 10" " + 2 + 108 z х
а(К) =------------------------------ зз---------------------. (Ю)
(1 + 1012^)К + 204 + 1012 / К И Г ' + 2 + 108 / К
На рис. 7 приведены кривые ускорения а, вычисляемые по формуле (10) для различных значений параметра и
Границами масштабируемости в каждом случае являются точки максимумов кривых ускорения, то есть — это точки, где производная ускорения равна нулю. Для определения таких точек вычислим производную по К для ускорения, вычисляемого по формуле (5):
(2L + ts + tr + tp + t^U^K — 2L — ts) ^K(2L + t^ + tr + tp + tw//K^
Соответственно, для задачи (9), продифференцировав (10), получаем
10' ' + 2 + Ю8 108 / К2 - НГ
«'W ^ 1----;---------21---------;---
(нН 'К + 2 + 108 / а)
(Н)
Примера! графиков производных ускорения а/ , вычисляемых по формуле (12), при ведены на. рис. 8.
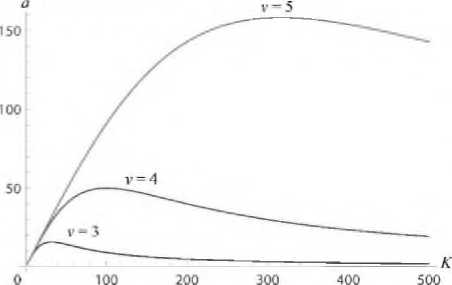
Рис. 7. Кривые ускорения для задачи (9) при различных у
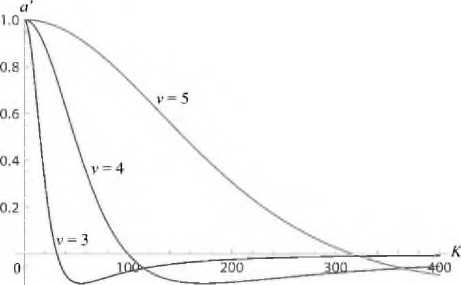
Рис. 8. Кривые производной ускорения для задачи (9) при различных л
Для того, чтобы вычислить нули производной (И), найдем корни уравнения
(2L + t + t + t + t Mt /К2 - 2L - £ ) X S Г p W / X W / S /
^K^2L + tj + ф + tp + t^K^
Поделив обе части уравнения (13) на (^L + tg + tr + t + tw), и умножив их на ^K(2L + ts) + ф + tp + tujK^ , получим что равносильно
то есть
<.Д-2^-‘,=0.
К2 _£
21, +
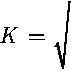
Таким образом, границы масштабируемости В^Т-программы определяется следующим неравенством:
Продемонстрируем, как полученная оценка может применяться на практике. Пусть имеется некоторая BSF-программа, для которой параметр п (размерность задачи) характеризует объем исходных данных. Предположим, что затраты на посылку задания одному рабочему составляют O(ri) , а суммарная временная стоимость вычислений, выполняемых рабочими, равна (Ху?). Тогда по формуле (17) получаем К < J^n^y^n), то есть К < О(^). Это означает, что верхняя граница масштабируемости программы будет расти пропорционально росту размерности задачи, и, следовательно, мы можем характеризовать такую программу как хорошо масштабируемую.
Предположим теперь, что временная стоимость посылки задания одному рабочему по-прежнему составляет О(п), а суммарная временная стоимость вычислений, выполняемых рабочими, равна О(у?). Тогда по формуле (17) получаем К < У^п^У^п) , то есть К < У (Ху) . Это означает, что верхняя граница масштабируемости программы будет расти как корень квадратный от размерности задачи. Такую программу мы можем характеризовать как ограниченно масштабируемую. В заключение рассмотрим случай, когда в рамках одной итерации суммарная временная стоимость посылки задания рабочему пропорциональна суммарной временной стоимости вычислений, выполняемых рабочими, и равна О(п) . В этом случае из формулы (17) получаем К < уО(пуО(тб). Это означает, что верхняя граница масштабируемости программы ограничена некоторой константой, не зависящей от размерности задачи. Такую программу мы можем характеризовать как плохо масштабируемую.
Таким образом, мы можем сделать вывод, что BSF-программа будет обладать хорошей масштабируемостью, если временные затраты на посылку задания одному рабочему будут пропорциональны кубическому корню от суммарных временных затрат на решение задачи рабочими.
Оценим теперь эффективность е распараллеливания BSF-программы. Используя (3) и (4), имеем
= = =
К ■ Тк K2(2L + ts) + K(tp + ф) + tw
= ___________j Ч + h
K\2L + ф) + K(tp + ф) + ф K2(2L + ф) + K(tp + ф) + ф
K'\2L + tj + Де, + 1,) + t„
В предположении К » 1 имеем
2В + ts
K^^L + У + K(tp + ф) + tto
и
K2(2L + ф) + K(tp + ф) + tm
Отсюда следует, что e to----------------------------------- для К » 1. Поделив числитель и знаменатель на tw, получаем итоговую формулу е и 7.(18)
1 + (№(2L + ts) + к<^р + ф))/ф
Подставляя значение tg из уравнения (7), можно получить следующий вариант формулы (18):
е ~ (19)
1 + (к2(2Ь + 10-Чю) + К(ф +ф))/ф
Подсчитаем по формуле (19) эффективность распараллеливания задачи (9):
е to-----.(20)
1 + (к2(1 + io12 ' ) + 2К • ю4 ую12
На рис. 9 приведены графики эффективности распараллеливания задачи (9) для различных значений у, построенные с использованием формулы (20). Указанные графики показывают, что величина v = ^K^tw^ts^ оказывает существенное влияние на эффективность распараллеливания. Чем больше соотношение tw / tg , тем выше эффективность распараллеливания.
Сумма tr + t также оказывает существенное влияние на эффективность распараллеливания. Это можно увидеть на рис. 10, где приведены графики эффективности распараллеливания задачи (9) при различных значениях суммы tr + t , указанных на кривых. Параметр tg в этом случае имеет фиксированное значение для всех графиков: tg = Ю^^ = 10 5 • 1012 = 107. Можно видеть, что при ф + t = 2 • 1011 эффективность распараллеливания на 20 процессорных узлах не превышает 20%, при этом, как показывает рис. 7, верхняя граница масштабируемости В5У-программы с такими параметрами лежит в районе 300 процессорных узлов.
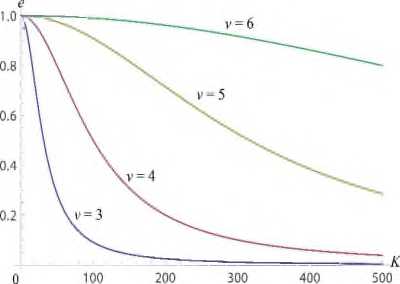
Рис. 9. Эффективность распараллеливания задачи (9) при различных у
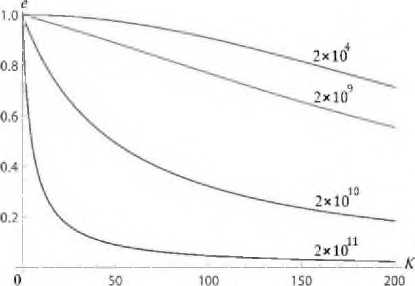
Рис. 10. Влияние tp на эффективность распараллеливания (и = 5)
Заключение
В работе описана новая модель параллельных вычислений BSF (Bulk Synchronous Farm) — блочно-синхронная ферма, ориентированная на вычислительные системы с массовым параллелизмом, включающие в себя сотни тысяч процессорных узлов и имеющие экзафлопный уровень производительности. BSF-компьютер представляет собой множество однородных процессорных узлов с приватной памятью, соединенных сетью, позволяющей передавать данные от одного процессорного узла другому. Среди процессорных узлов выделяется один, называемый мастером. Остальные К узлов называются рабочими. BSF-компьютер работает по схеме SPMD. Описана структура BSF-программы. Построена стоимостная метрика для оценки времени выполнения BSF-программы. На основе предложенной стоимостной метрики получена оценка для верхней границы масштабируемости BSF-программ. Данная оценка позволяет сделать вывод, что BSF-программа будет обладать хорошей масштабируемостью, если временные затраты на посылку задания рабочему будут пропорциональны кубическому корню от суммарных временных затрат на решение задачи рабочими. Также получены формулы для оценки эффективности распараллеливания BSF-программ.
Для валидации теоретических результатов, полученных в этой статье, была выполнена BSF-реализация алгоритма NSLP [11], используемого для решения нестационарных сверхбольших задач линейного программирования на кластерных вычислительных системах. Реализация выполнялась на языке C++ с использованием библиотеки MPI. Тексты BSF-реализации алгоритма NSLP свободно доступны в сети Интернет по адресу: С использованием BSF-реализации алгоритма NSLP на вычислительном кластере «Торнадо ЮУрГУ» [21] были проведены вычислительные эксперименты по исследованию масштабируемости и эффективности этой параллельной программы. Результаты сравнения данных, полученных аналитически с помощью стоимостной метрики модели BSF, с данными, полученными в результате вычислительных экспериментов, приведены в статье [22]. Эти результаты показывают, что модель BSF позволяет с высокой точностью предсказывать верхнюю границу масштабируемости BSF-реализации алгоритма NSLP.
В работе [23] был построен эмулятор BSF-программ, моделирующий работу BSF-программы на реальной кластерной вычислительной системе. Эмулятор реализован на языке C++ с использованием библиотеки MPI. В эмуляторе задаются числовые значения параметров модели BSF, приведенные в разделе 4. Эмулятор запускается на реальной кластерной вычислительной системе и имитирует работу BSF-программы, пересылая между матером и рабочими сообщения определенной длины, и симулируя вычислительную работу соответствующими циклами ожидания. Вычислительные эксперименты, проведенные на суперкомпьютере ЮУрГУ с использованием эмулятора BSF-программ, также показали хорошее соответствие показателей масштабируемости, полученных теоретически и экспериментально.
В рамках дальнейших исследований планируется решить следующие задачи:
-
1) разработать формализм для описания BSF-программ с использованием функций высшего порядка;
-
2) выполнить проектирование и реализацию каркаса для быстрой разработки BSF-программ на базе MPI (в виде библиотеки на языке C++);
-
3) провести вычислительные эксперименты на кластерной вычислительной системе с использованием известных итерационных методов для подтверждения адекватности модели BSF.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 17-07-00352 а, Правительства РФ в соответствии с Постановлением № 211 от 16.03.2013 г. (соглашение № 02.АОЗ.21.0011) и Министерства образования и науки РФ (государственное задание 2.7905.2017/8.9).
Список литературы Модель параллельных вычислений для многопроцессорных систем с распределенной памятью
- TOP500 Supercomputer Sites. URL: https://www.top500.org (дата обращения: 03.04.2017).
- Sahni S., Vairaktarakis G. The Master-Slave Paradigm in Parallel Computer and Industrial Settings//Journal of Global Optimization. 1996. Vol. 9, No. 3-4. P. 357-377 DOI: 10.1007/BF00121679
- Silva L.M., Buyya R. Parallel Programming Models and Paradigms//High Performance Cluster Computing: Architectures and Systems. Vol. 2. 1999. P. 4-27.
- Leung J.Y.-T., Zhao H. Scheduling Problems in Master-Slave Model//Annals of Operations Research. 2008. Vol. 159, No. 1. P. 215-231 DOI: 10.1007/s10479-007-0271-4
- Bouaziz R. et al. Efficient Parallel Multi-Objective Optimization for Real-Time Systems Software Design Exploration//Proceedings of the 27th International Symposium on Rapid System Prototyping -RSP’16, October 1-7, 2016, Pittsburgh, Pennsylvania, USA. P. 58-64 DOI: 10.1145/2990299.2990310
- Cantú-Paz E., Goldberg D.E. On the Scalability of Parallel Genetic Algorithms//Evolutionary Computation. 1999. vol. 7, no. 4. pp. 429-449 DOI: 10.1162/evco.1999.7.4.429
- Depolli M., Trobec R., Filipič B. Asynchronous Master-Slave Parallelization of Differential Evolution for Multi-Objective Optimization//Evolutionary Computation. 2012. Vol. 21, No. 2. P. 1-31 DOI: 10.1162/EVCO_a_00076
- Mathias E.N. et al. DEVOpT: A Distributed Architecture Supporting Heuristic and Metaheuristic Optimization Methods//Proceedings of the ACM Symposium on Applied Computing, March 11-14, 2002, Madrid, Spain. ACM Press, 2002. P. 870-875 DOI: 10.1145/508791.508960
- Ершова А.В., Соколинская И.М. Параллельный алгоритм решения задачи сильной отделимости на основе фейеровских отображений//Вычислительные методы и программирование. 2011. Т. 12. С. 423-434.
- Бурцев А.П. Параллельная обработка данных сейсморазведки с использованием расширенной модели Master-Slave//Суперкомпьютерные дни в России: Труды международной конференции (26-27 сентября 2016 г., г. Москва). М.: Изд-во МГУ, 2016. С. 887-895.
- Sahni S. Scheduling Master-Slave Multiprocessor Systems//IEEE Transactions on Computers. 1996. Vol. 45, No. 10. P. 1195-1199 DOI: 10.1109/12.543712
- Darema F. et al. A Single-Program-Multiple-Data Computational Model for EPEX/FORTRAN//Parallel Computing. 1988. Vol. 7, No. 1. P. 11-24 DOI: 10.1016/0167-8191(88)90094-4
- Gropp W., Lusk E., Skjellum A. Using MPI: Portable Parallel Programming with the Message-Passing Interface. Second Edition. MIT Press, 1999.
- Valiant L.G. A Bridging Model for Parallel Computation//Communications of the ACM. 1990. Vol. 33, No. 8. P. 103-111 DOI: 10.1145/79173.79181
- Goudreau M. et al. Towards Efficiency and Portability: Programming with the BSP Model//Proceedings of the Eighth Annual ACM Symposium on Parallel Algorithms and Architectures -SPAA’96. New York, NY, USA: ACM Press, 1996. P. 1-12 DOI: 10.1145/237502.237503
- Cole M.I. Algorithmic Skeletons: Structured Management of Parallel Computation. Cambridge, MA, USA: MIT Press, 1991. 170 p.
- Poldner M., Kuchen H. On Implementing the Farm Skeleton//Parallel Processing Letters. 2008. Vol. 18, No. 1. P. 117-131 DOI: 10.1142/S0129626408003260
- Padua D. et al. Models of Computation, Theoretical//Encyclopedia of Parallel Computing. Boston, MA: Springer US, 2011. P. 1150-1158. 4_218 DOI: 10.1007/978-0-387-09766-
- Bilardi G., Pietracaprina A., Pucci G. A Quantitative Measure of Portability with Application to Bandwidth-Latency Models for Parallel Computing//Euro-Par’99 Parallel Processing, Toulouse, France, August 31 -September 3, 1999. Proceedings. Lecture Notes in Computer Science, vol. 1685. Springer, Berlin, Heidelberg, 1999. P. 543-551 DOI: 10.1007/3-540-48311-X_76
- Соколинская И.М., Соколинский Л.Б. О решении задачи линейного программирования в эпоху больших данных//Параллельные вычислительные технологии -XI международная конференция, ПаВТ’2017, г. Казань, 3-7 апреля 2017 г. Короткие статьи и описания плакатов. Челябинск: Издательский центр ЮУрГУ, 2017. С. 471-484. http://omega.sp.susu.ru/pavt2017/short/014.pdf.
- Костенецкий П.С., Сафонов А.Ю. Суперкомпьютерный комплекс ЮУрГУ//Параллельные вычислительные технологии (ПаВТ’2016): труды международной научной конференции (28 марта -1 апреля 2016 г., г. Архангельск). Челябинск: Издательский центр ЮУрГУ, 2016. С. 561-573. http://ceur-ws.org/Vol-1576/119.pdf.
- Sokolinskaya I., Sokolinsky L.B. Scalability Evaluation of the NSLP Algorithm for Solving Non-Stationary Linear Programming Problems On Cluster Computing Systems//Суперкомпьютерные дни в России: Труды международной конференции (25-26 сентября 2017 г., г. Москва). М.: Изд-во МГУ, 2017. С. 319-332. http://russianscdays.org/files/pdf17/319.pdf.
- Ezhova N. Verification of BSF Parallel Computational Model//3rd Ural Workshop on Parallel, Distributed, and Cloud Computing for Young Scientists (Ural-PDC). CEUR Workshop Proceedings. Vol-1990. CEUR-WS.org. P. 30-39. http://ceur-ws.org/Vol-1990/paper-04.pdf.
