Модель управления наукоёмким производством на основе технологии цифровых двойников

Автор: Логиновский О.В., Белякова В.А.
Рубрика: Управление в социально-экономических системах
Статья в выпуске: 2 т.25, 2025 года.
Бесплатный доступ
Представлена модель управления наукоемким производством на основе технологии цифровых двойников, объединяющая архитектуру озера данных и принципы онтологической инженерии и агентно-сервисного подхода. В исследовании рассматриваются проблемы управления сложными производственными средами в контексте Индустрии 4.0, предлагается гибридный подход, сочетающий принципы «умной фабрики» с методологиями бережливого производства. Модель включает в себя многоуровневую архитектуру, охватывающую стратегический, тактический и операционный уровни, поддерживаемую структурой агент-сервис для системной интеграции. Цель работы заключается в разработке комплексной модели управления наукоемким производством на основе интеграции технологии цифровых двойников, онтологического подхода и агентно-сервисной архитектуры с использованием озера данных.
Наукоемкое производство, модель управления, цифровой двойник, озеро данных, онтологический инжиниринг, агентно-сервисный подход, принятие решений
Короткий адрес: https://sciup.org/147248031
IDR: 147248031 | УДК: 519.816 | DOI: 10.14529/ctcr250209
Digital twin-based management model for high-tech production
A management model for high-tech production based on digital twin technology is presented, combining the architecture of a data lake and the principles of ontological engineering and an agent-based service approach. The study examines the problems of managing complex production environments in the context of Industry 4.0, and suggests a hybrid approach combining the principles of a “smart factory” with lean manufacturing methodologies. The model includes a multi-level architecture covering strategic, tactical and operational levels, supported by an agent-service structure for system integration. The aim of the work is to develop an integrated management model for high-tech production based on the integration of digital twin technology, an ontological approach, and an agent-service architecture using a data lake.
Текст научной статьи Модель управления наукоёмким производством на основе технологии цифровых двойников
O.V. Loginovskiy, , V.A. Beliakova, , South Ural State University, Chelyabinsk, Russia
Развитие наукоемкого производства в России характеризуется высокой степенью технологического прогресса и внедрения в различных отраслях. За последние годы российский производственный сектор претерпел значительные преобразования, при этом особое внимание уделяется интеграции цифровых технологий и современным методам производства [1, 2], что, в свою очередь, требует совершенствования моделей и алгоритмов управления.
Значительный прогресс в области контроля и оптимизации наукоемкого производства представляет интеграция технологии цифровых двойников в модели управления. Эта интеграция создает всеобъемлющую основу для принятия решений и оптимизации процессов в режиме реального времени, коренным образом трансформируя традиционные подходы к управлению производством [3].
В условиях Индустрии 4.0 наукоемкие предприятия в основном применяют модели управления, основанные на данных, поступающих от приборов и датчиков. Таким образом, для повышения быстродействия доступа и обработки необходимо иметь оптимальную систему хранения, а также алгоритмы поиска и обработки больших массивов данных в режиме реального времени.
Однако данные, поступающие через Интернет вещей, могут быть неструктурированными или частично структурированными, а также формат выходных файлов может отличаться в зависимости от модели оборудования.
Оптимальным способом хранения неструктурированной или частично структурированной информации является озеро данных и система электронных паспортов изделий, приборов и процессов, образующих онтологические структуры и сущности.
Представление знаний в среде цифровых двойников существенно выигрывает от использования онтологических структур. Онтологии предметной области, интегрированные с моделями цифровых двойников, обеспечивают повышенную семантическую ясность и улучшенные взаимосвязи данных, что приводит к более эффективной передаче знаний и пониманию процессов [4].
Такая интеграция оказывается особенно ценной в сложных производственных условиях, где точное определение взаимосвязей и представление знаний имеют решающее значение.
Таким образом, цель работы заключается в разработке модели управления наукоемким производством на основе интеграции технологии цифровых двойников, онтологического подхода и агентно-сервисной архитектуры с использованием озера данных.
Методы
Основой мо д е л и уп рав л ен ия наукоемким предприятием является гибри дн а я мо д ель, ос но ванн ая н а п ри н ц ип ах «у м н ой ф а б рик и» и бережливого производства, подразумевающих исполь з ова н и е к и бе р с и с тем и И н те рн е т а ве щ е й .
Зде с ь к л ючевы м объект о м является система поддержки принятия реше н ий , ос н ова н н а я н а техн о ло ги и ц и фровых д вой н и ков . Поскольку эта гибридная модель относится к разряду моделей, о с н ова н н ых н а д а н н ы х, т о в ро ли хранилища данных выступает озеро данных и с и с те м а э ле к трон ны х п а с пор т ов , онтологи че ски связывающая сущности цифрового двойн и ка . В за и мо де й с т в и е м еж д у у ровн ями мо д е ли , а т а кже меж ду доменами цифрового двойника организовано с помощью агентно-с е рв и с н ог о п о дх о д а .
Основная часть
В н ед ре н и е ц ифров ы х мод е лей управления на основе двойников, включ ающ и х он т ологи ческие структуры и агентно-се рв и с н ые а рхи тект у ры, т ребу ет п риме н е н и я структурированного ие р а рхи че с ко г о п о дх о д а . Эт а мн ог оуровневая структура обеспечивает всестор он н ю ю и н тегра ц ию р а з л и чн ых фу н к ци й у п ра влен ия при сохранении операционной согласованнос т и и с т ра теги че с к о го с ог лас ова н и я. Том п сон и Р о дри г е с де мон с т ри р у ют , чт о эф фекти в н а я ре ализация модели требу ет тща те льн о го у че т а и ера рхи че ских связей и функциональных зависимосте й н а всех у ров н я х о рга н иза ц и и [5] . Ст р у кт ура мо д е ли у п ра вле н и я п р е д с т а вле на н а ри с. 1.
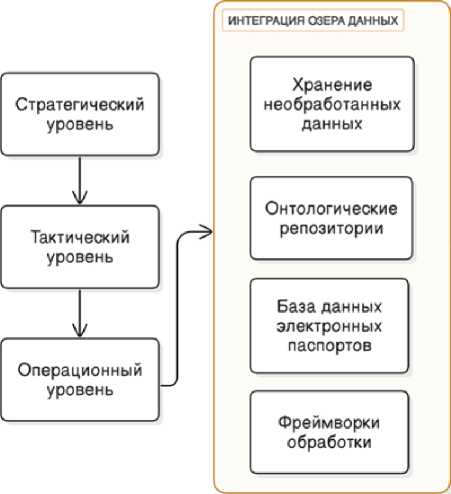
Рис. 1. Структура модели управления наукоемким производством Fig. 1. Structure of high-tech production management model
Ст ра тегиче с к и й урове н ь охв атывает цели всего предприятия и механизм ы п ри н яти я ре ш е н и й . Э т о т у рове н ь об ле г ча е т д о лгосрочное планирование и стратегии распред ел е н ия ре су рс ов, у с та н а вли ва я б а з ов ые п ара ме т ры для операций более низкого уровня [6]. Функции стратегиче ског о уров н я су щ е с тве н но вли яют на общую эффективность системы и резуль т а ты д е ятельн ос т и организации.
В н ед ре н и е н а т а кти чес ко м уровне направлено на удовлетворение промежу т очн ых т ре б ов аний к оперативн ому у п р а вле н и ю. Этот уровень координирует оптимизацию п рои зво д с тве н н ог о п л а н и рова н ия и уп ра вл е ни е и с пользованием ресурсов, устраняя разрыв межд у с т р а те ги че ск и ми ц елями и оп е рац ион н ой де яте льн о с ть ю [ 7 ] .
Операционный уровень ориентирован на повседневную производственную деятельность и функции непосредственного контроля. Андерсон и др. приводят доказательства того, что этот уровень требует надежной интеграции систем управления технологическими процессами в ре жиме реального времени и управления цехами [8]. Их исследования демонстрируют важность функциональности на операционном уровне для поддержания эффективности производства и контроля качества.
Архи те кт у ра и н те г ра ц и и озе ра д ан н ы х (рис. 2) представляет собой фундаментальный компон ент с т р укт у ры мо д ели . Ком п л ексные системы интеграции данных должны п о д д е ржи в а ть мн ог оу ров н е в ый п о т ок и н форм а ц и и, включая сбор данных с датчиков и возмо жн ости м он и т ори нга в режи м е ре аль ног о в ре м е н и [ 9].
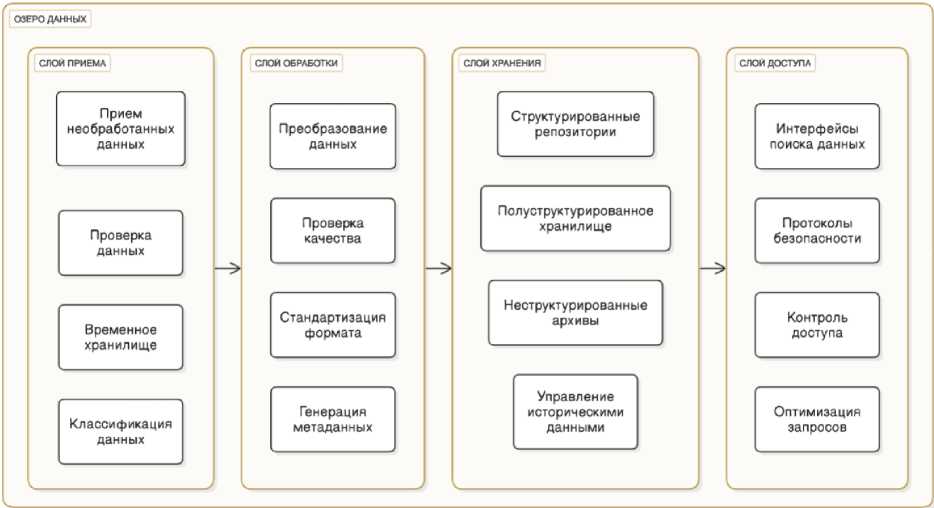
Рис. 2. Структура озера данных Fig. 2. Data lake structure
С л ой п ри е м а п ре д ст а вля е т собой начальную точку входа для всех дан ных , п ос т у п а ю щ и х в оз ер о пр о мы ш л енн ы х д а нных . Этот слой обрабатывает потоки неструктур ир о в ан ны х д анн ых о т п рои зво д с тве н н ого об ор у д ова н и я, корп ор а ти в н ых с и с те м и внешних источников, реализуя предв арител ь н ые про в ерки д о сто верности при сохранении исходного формат а и целост ност и да нных [ 5]. Сл ой обес п е чива е т соответствие входящих данных базовым ст а н д а р т а м ка че с тва и в к л ю ч а ет необ х о д и мы е м е т а д ан ны е для о т слежи ван ия и обработки.
С л ой об ра бо тк и п р е об р азует необработанные данные в пригодную для и сп о льз ова н и я и нф орм а ц ию п ос редс твом п роце дур стандартизации и обогащения. Данный с лой п ри ме н яе т ал г ор итмы преоб ра з ова н и я, п рове р ки качества и процессы обогащения для подг о т ов к и данных к анал и зу и и спо ль зовани ю [ 1 0] . С лой обработки управляет требованиями как к об ра бо тке в реа льн ом в рем ени , т ак и к п ак е тн о й об работке, обеспечивая соответствие данных орга н и за ц и он н ым с т а нда р т а м и нали чи е н еоб х оди мой кон те кс тн ой и н фо рм а ц и и .
Слой хране н и я п о дд е р жив ает организованное хранилище обработанных д ан н ых, п о д д ерж ивая ра з л и чн ые форма ты д а н н ы х и схемы доступа. Данный слой управляет ве рс и он н ос тью д а нн ы х, и с т ори че ск и м и а р хи ва ми и отображением взаимосвязей, обеспечивая п ри э т ом эф фе кти в н ы е возможност и и звле че н и я да н ных [11]. Архитектура хранения вмещает стру к т у ри рова н н ые , п ол у-ст р укт у ри рова н н ые и н ест р у ктурированные данные, поддерживая взаимосвязи и кон те кс т межд у различными типами данных.
С л ой д ос т у п а обе с п е чи вае т и с п о льз ова н и е д а н н ых в ра зли чн ых п рои зводственных приложен и ях и д ля а н а ли ти че с к их т ребований. Данный слой предоставляет интерфе й с ы для и звле че н ия да н н ых, а н а ли ти че с к и х о п е ра ц ий и синхронизации цифровых двойников, п о д д е р жи ва я п ри э т ом соотве тс твующ и е меры б ез оп а с н ос ти и о гра н и че ни я д ос т у п а [12 ]. Слой доступа поддерживает мн ож ес тво схе м ис п о льзова н и я – от операционных запросов в реальном времени до сложной аналитической обработки.
Слои, описанные выше, работают вместе, создавая целостную среду управления данными, поддерживающую различные производственные операции и аналитические требования [9]. Интегрированная структура обеспечивает эффективный поток данных при сохранении качества данных и операционной гибкости, в конечном итоге поддерживая передовые производственные возможности и процессы принятия решений.
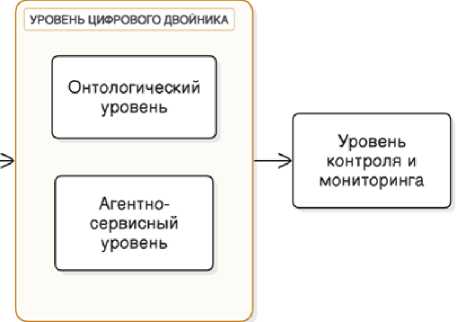
Онтологический уровень устанавливает семантические структуры и иерархии взаимосвязей, необходимые для функционирования системы. Уилсон и др. предполагают, что этот уровень должен включать сложные структуры представления знаний и механизмы логического вывода [13]. Их исследования показывают, что надежные онтологические структуры вносят значительный вклад в системный интеллект и возможности принятия решений. Агрегирующим элементом онтологических сущностей цифрового двойника и элементов системы управления является цифровой паспорт, хранящий техническую информацию, исторические, промышленные, расчетные и прочие данные.
Ввиду неоднородности промышленных данных, поступающих в озеро данных, удобно применять нечеткие онтологии как комплексную систему формализации знаний, интегрирующую классическую онтологическую модель с теорией нечетких множеств [14, 15].
В основе данного подхода лежит математический аппарат, позволяющий оперировать неточными и неопределенными понятиями, где каждому элементу x из универсального множества X ставится в соответствие степень принадлежности ц ( x ) е [ 0,1 ] .
Теоретический базис нечетких онтологий формируется на основе интеграции формальной семантики дескрипционной логики и методологии Fuzzy OWL [16]. Ключевыми структурными элементами выступают нечеткие классы, отношения и экземпляры, описываемые через функции принадлежности ц(t, k), где t представляет термин предметной области, а к - соответствующую лингвистическую переменную.
В контексте логического вывода степень уверенности в полученном результате определяется выражением
l
S rule =Ш t , U (1)
i = 1
где l – количество термов в правиле, а нормализация показателей осуществляется через
S = S^
nNorm max (sn), где Sn – нормализованное значение степени уверенности рекомендации каждого n-го правила.
Практическая реализация нечетких онтологий осуществляется через механизмы интеграции с OWL DL и применение SWRL-правил. Формальное описание нечеткого отношения R между классами A и B может быть представлено как
R : A x B ^ [ 0,1 ] . (3)
Данный подход позволяет существенно расширить возможности традиционных онтологий в контексте обработки неопределенных данных. При этом каждому аксиоматическому утверждению ϕ ставится в соответствие степень истинности α, что формально записывается как ⟨ϕ, α⟩.
В условиях современных производственных систем Индустрии 4.0 нечеткие онтологии обеспечивают более гибкий подход к моделированию предметной области. Они позволяют формализовать экспертные знания с учетом неопределенности и субъективности оценок, что особенно важно при построении интеллектуальных систем управления производством.
Эффективность применения нечетких онтологий проявляется в повышении адекватности моделирования сложных систем, где классический булев подход {0, 1} оказывается недостаточным для описания реальных процессов. Использование лингвистических переменных и функций принадлежности позволяет более точно отразить экспертные знания и обеспечить более качественный логический вывод в системах поддержки принятия решений [17–19].
Внедрение агентно-сервисной архитектуры обеспечивает динамические операционные возможности благодаря автономным агентам и механизмам управления сервисами. Исследование [20] подчеркивает важность четко определенных протоколов связи и механизмов координации для поддержания эффективности системы. Интеграция агента и сервиса значительно повышает адаптивность системы и оперативность реагирования [21].
Уровень контроля и мониторинга обеспечивает непрерывную оптимизацию системы и управление производительностью. Комплексные системы мониторинга должны включать механизмы отслеживания производительности и обеспечения качества [22]. Эффективные системы контроля необходимы для поддержания высокого уровня операционной эффективности.
Реализация
Рассмотрим реализацию описанной выше модели на примере системы поддержки принятия решений в системе многомасштабного моделирования для озера данных цифровых двойников химических материалов и соединений.
Многомасштабное моделирование в современной науке о материалах сталкивается с фундаментальными проблемами обработки, анализа и хранения массивов больших данных. В рамках исследований по материаловедению накапливаются значительные объемы информации, полученной как экспериментальным путем, так и посредством теоретических расчетов.
Для эффективного управления подобными наборами данных требуется специализированная архитектура хранилища. Учитывая неструктурированный или частично структурированный характер данных, оптимальным решением является применение концепции озера данных. Данный подход обеспечивает необходимую гибкость при работе с разнородной информацией из множества независимых источников.
В контексте междисциплинарных исследований на стыке химии и материаловедения особую значимость приобретает систематизация следующих типов данных [23]:
-
• структурная информация;
-
• свойства материалов;
-
• корреляционные зависимости;
-
• методология теоретического моделирования;
-
• результаты экспериментальных измерений.
Особого внимания заслуживает моделирование многокомпонентных систем, включающих полимерные соединения, реакционные смеси, сокристаллы.
Методологический инструментарий включает молекулярную динамику, квантово-химические расчеты, методы химической кинетики.
В рамках оптимизации процессов поиска и обработки данных разработан электронный паспорт материалов как структурный элемент цифрового двойника. Паспорт представляет собой комплекс атрибутивных полей, характеризующих композиционный состав, структурные параметры, расчетные и экспериментальные свойства, реакционную способность, построенные модели и закономерности «структура – свойство», реализующий пространство онтологий и связей.
Техническая реализация электронного паспорта осуществляется посредством JSON-объектов (рис. 3), интегрирующих данные из Crystal и Cif файлов, а также результаты расчетов метадинамики. Данная архитектура обеспечивает экспорт данных, методологическую документацию, возможность ручного ввода, интеграцию с библиографическими источниками.
Эффективная обработка данных требует специальной предварительной обработки. В результате дальнейший анализ данных будет более продуктивным. В нашем случае данные предлагается структурировать и хранить в реляционной базе данных. Структура предлагаемой реляционной базы данных показана на рис. 4.
Изначально экспериментальные данные представляют собой набор неструктурированных выходных файлов. Такие данные невозможно сохранить в реляционной базе данных. Поиск и анализ также невозможны.
Методология оптимизации процедур поиска в озерах данных основана на применении агентов-сервисов. Агент транспортного уровня работает со сбором экспериментальных данных через множество каналов. Эти предварительные данные существуют в неструктурированном формате, преимущественно состоящем из выходных файлов различных химических экспериментальных процедур. Эти файлы содержат всестороннюю информацию о свойствах материалов и характеристиках соединений.
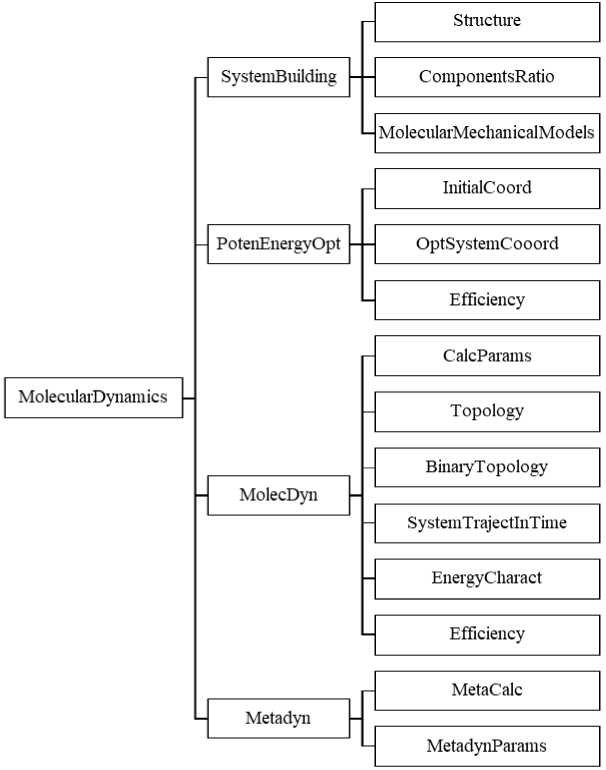
Рис. 3. Структура JSON-объекта для молекулярно-динамических расчетов Fig. 3. JSON object structure for molecular dynamics calculations
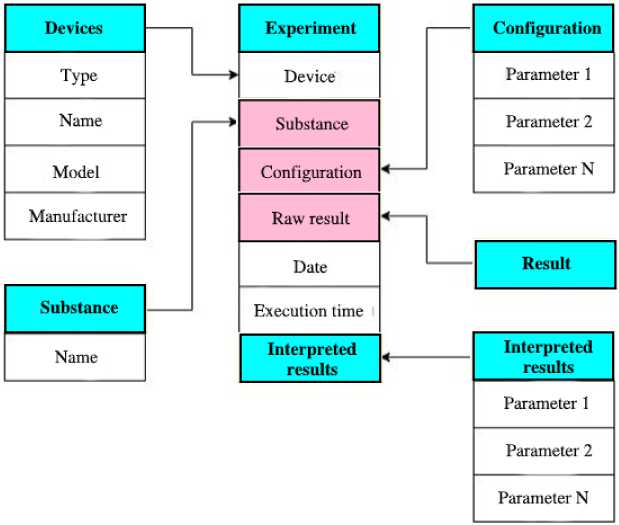
Рис. 4. Пример структуры базы данных результатов химических экспериментов Fig. 4. Example of database structure for chemical experiment results
Агент-сервис трансформации включает систематическое преобразование неструктурированных данных в организованные форматы. Реализация использует архитектуру JSON (JavaScript Object Notation), облегчая организацию трех фундаментальных структурных компонентов: данные кристаллографической структуры, данные кристаллографического информационного файла (CIF) и результаты вычислений молекулярной динамики.
Архитектура базы данных использует двойной системный подход, включающий реляционные и нереляционные системы баз данных. Реализация реляционной базы данных через PostgreSQL обеспечивает возможности структурированных запросов и управление индексированными атрибутами. Одновременно реализация нереляционной базы данных через HBase использует структурную организацию семейства столбцов, оптимизированную для распределенного управления данными агентом-парсером выходных файлов.
Структурированный протокол поиска использует архитектуру индексированных JSON-файлов, демонстрирует логарифмическую сложность O ( log ( n ) ) , реализует организацию на основе атрибутов и показывает превосходные метрики производительности по сравнению с неструктурированным протоколом поиска, который использует необработанные файлы, демонстрируя линейную вычислительную сложность, что требует увеличенных вычислительных ресурсов и показывает сниженную эффективность производительности (см. таблицу).
Время поиска структурированных и неструктурированных файлов Search time for structured and unstructured files
|
Количество файлов |
Время поиска, мс |
|
|
Структурированные файлы |
Неструктурированные файлы |
|
|
100 |
0,1 |
496,8 |
|
1 000 |
0,7 |
4 583,6 |
|
5 000 |
3 |
25 975,6 |
|
10 000 |
5,8 |
47 565,6 |
|
15 000 |
8,8 |
69 502,8 |
|
20 000 |
11,3 |
91 524,7 |
|
25 000 |
14,3 |
113 184,5 |
|
30 000 |
16,6 |
156 251,3 |
Эмпирический анализ выявляет значительные различия в производительности между этими подходами. Структурированные протоколы поиска демонстрируют время отклика на уровне миллисекунд, в то время как неструктурированные протоколы поиска требуют обработки на уровне секунд и минут. Примечательно, что разница в производительности увеличивается пропорционально расширению объема данных. Реализация структурированных протоколов поиска демонстрирует превосходную эффективность в операциях извлечения данных в среде озер данных цифровых двойников.
Эта комплексная методология обеспечивает надежную основу для оптимизации процедур поиска в системах управления химическими данными, особенно в контексте реализаций цифровых двойников. Подход значительно повышает доступность данных и эффективность обработки, что является критически важными факторами в современных средах химических исследований и анализа.
Применение методологии оптимизации поисковых процедур в металлургии и наукоемком производстве представляет собой перспективное направление цифровой трансформации промышленности. В контексте металлургического производства данная методология позволяет существенно оптимизировать работу с данными о составах сплавов и их свойствах, обеспечивая эффективный анализ технологических режимов плавки и обработки металлов. Особую значимость представляет возможность осуществления контроля качества продукции на основе накопленных данных и прогнозирования свойств новых материалов.
Данный пример нетрудно масштабировать на другие области знаний и области применения. В сфере наукоемкого производства внедрение структурированного поиска способствует совершенствованию организации данных о технологических процессах и управлению информацией о сложном оборудовании. Это позволяет осуществлять комплексную оптимизацию производственных циклов и обеспечивать высокоэффективный контроль качества продукции. Существенным преимуществом является возможность реализации предиктивного обслуживания оборудования на основе анализа накопленных данных.
Практическая значимость внедрения данной методологии выражается в значительном сокращении времени поиска технологических решений и повышении точности подбора параметров производства. Анализ исторических данных способствует улучшению качества продукции и оптимизации использования ресурсов, что приводит к существенному снижению производственных издержек.
Особую ценность представляет возможность создания цифровых двойников производственных линий, технологических процессов и отдельных агрегатов. Данный подход позволяет осуществлять комплексное моделирование производственных процессов, прогнозировать результаты технологических изменений и оптимизировать режимы работы оборудования. Кроме того, использование систем управления, основанных на технологии цифровых двойников, способствует эффективному предупреждению нештатных ситуаций и планированию технического обслуживания.
Заключение
Внедрение моделей управления наукоемким производством на основе цифровых двойников является примером трансформации традиционных производственных парадигм. Исследование показывает, что интеграция цифровых двойников с озером данных обеспечивает повышение операционной эффективности при одновременном значительном улучшении возможностей принятия решений в режиме реального времени. Кроме того, благодаря этой сложной технологической базе производственные процессы демонстрируют повышенную гибкость и адаптивность.
Многоуровневая архитектура, объединяющая стратегический, тактический и операционный уровни, доказала свою эффективность в практических приложениях. Этот архитектурный подход, поддерживаемый комплексной реализацией озера данных, позволяет успешно управлять как структурированными, так и неструктурированными данными, в то время как онтологическая инженерия устанавливает важные семантические связи между компонентами системы. Эмпирические данные, в частности, полученные в результате анализа химических материалов, подтверждают теоретическую основу и демонстрируют значительное повышение операционной эффективности.
Примечательно, что протоколы поисковой оптимизации демонстрируют исключительное повышение производительности, а структурированные подходы работают в геометрической прогрессии быстрее, чем традиционные неструктурированные методологии. Это количественное улучшение подчеркивает практическую ценность предлагаемой платформы, а также ее потенциал для масштабирования в различных промышленных приложениях. Адаптивность модели предполагает ее широкое применение в различных отраслях производства, что открывает возможности для широкого внедрения в современных промышленных условиях.
Результаты исследования закладывают прочную основу для дальнейшего развития интеллектуальных производственных систем, одновременно определяя перспективные направления для будущих исследований и разработок. По мере развития технологий Индустрии 4.0 интеграция возможностей искусственного интеллекта и машинного обучения с платформами цифровых двойников открывает возможности для повышения производительности систем и оптимизации операций. Это исследование вносит вклад в накопление знаний об управлении наукоемким производством, а также дает практическую информацию для промышленного внедрения.
Синтез цифровых двойников, озер данных и онтологической инженерии создает комплексную основу для управления наукоемким производством, позволяя организациям сохранять конкурентные преимущества во все более сложных производственных условиях. По мере того как глобальное производство продолжает переходить на цифровые технологии, такие интегрированные подходы будут приобретать все большее значение для повышения операционной эффективности и устойчивого конкурентного преимущества в меняющемся промышленном ландшафте.
