Моделирование образовательной среды на основе комплексного сбора и анализа данных

Автор: Кумратова А.М., Параскевов А.В., Махнов В.А.
Журнал: Известия Санкт-Петербургского государственного экономического университета @izvestia-spgeu
Рубрика: Экономика предприятий, регионов и отраслей
Статья в выпуске: 2 (158), 2026 года.
Бесплатный доступ
Настоящая статья посвящена комплексному анализу образовательных данных в российских высших учебных заведениях с целью повышения качества образовательного процесса. Рассматриваются проблемы фрагментации и изолированности данных, а также ограниченности существующих подходов к управлению. Представлен универсальный процесс обработки и анализа данных, включающий этапы сбора, предобработки, моделирования и интерпретации результатов. Особое внимание уделяется использованию современных методов статистики и машинного обучения для выявления закономерностей и прогнозирования академической успеваемости. Описаны примеры практического применения подхода в образовательной среде и сравнение с кейсами предиктивной аналитики издругих отраслей. Подчеркивается значимость перехода к data-driven решениям и их роль в формировании эффективной системы управления образованием.
Анализ данных, комплексный анализ, моделирование, экономическое развитие
Короткий адрес: https://sciup.org/148333646
IDR: 148333646
Modeling of the educational environment based on complex data collection and analysis
This article focuses on the comprehensive analysis of educational data in Russian higher education institutions aimed at improving the quality of the educational process. The problems of data fragmentation and isolation, as well as the limitations of existing management approaches, are discussed. A universal process of data processing and analysis is presented, including stages of collection, preprocessing, modeling, and interpretation of results. Special attention is given to the use of modern statistical and machine learning methods for identifying patterns and predicting academic performance. Examples of practical applications of the approach in the educational environment and comparisons with predictive analytics cases from other industries are described. The importance of the transition to data-driven solutions and their role in forming an effective education management system is emphasized.
Текст научной статьи Моделирование образовательной среды на основе комплексного сбора и анализа данных
Система высшего образования в Российской Федерации переживает процесс глубокой трансформации, который обусловлен глобальными технологическими трендами, переходом к новой модели образования и стратегическими государственными инициативами, в частности «Приоритет – 2030». Одним из ключевых векторов этой программы является цифровизация, которая приводит к повсеместному внедрению информационных систем: электронных образовательных сред, балльно-рейтинговых систем, цифровых портфолио, библиотечных систем и т.п. Как следствие, наблюдается экспоненциальный рост объема накапливаемых образовательных данных, которые имеют потенциал повышения качества и эффективности образовательной деятельности [1].
Несмотря на наличие богатых баз данных, большинство российских университетов сталкивается с тем, что данные фрагментированы и изолированы друг от друга, что значительно затрудняет их анализ. Управленческие решения в области образовательной политики нередко принимаются «интуитивно» или основываются на устаревших срезах, а не на анализе реальных и актуальных данных. Это приводит к задержкам реакции на возникающие вызовы, такие как снижение вовлеченности студентов, снижение эффективности программ, и, как следствие, рост числа отчислений, а также несоответствие программ требования рынка труда.
Материалы и методы
Актуальность настоящего исследования обусловлена острой необходимостью нововведений в моделях управления в высших учебных заведениях и переходом к data-driven подходам, которые позволят не просто констатировать факты (например снижение успеваемости), но и выявлять их глубинные причины, прогнозировать развитие и предлагать оптимальные управленческие решения для улучшения ситуации.
Объектом исследования выступает процесс управления качеством образовательной деятельности в российских высших учебных заведениях. Предметом исследования являются методы и инструменты анализа образовательных данных для выявления закономерностей, влияющих на академическую успешность студентов и эффективность образовательного процесса. Целью данного исследования является разработка и обоснование комплексного подхода к анализу образовательных данных для решения прикладных задач управления качеством в системе высшего образования РФ.
Результаты и обсуждение
Данные об академической успеваемости являются наиболее структурированной и доступной категорией образовательных данных. Традиционно они использовались преимущественно для учета, контроля и составления отчетности. Однако современные методы анализа данных позволяют извлечь из этой информации значительно более глубокие инсайты, превращая ее в инструмент проактивного управления качеством образовательного процесса.
Ключевыми источниками данных в этой категории в российских вузах выступают: электронные зачетные книжки и ведомости; балльно-рейтинговые системы; системы управления обучением. Совокупность этих данных формирует детальный «цифровой след» академической траектории каждого студента. Комплексный анализ этого следа позволяет решать различные прикладные задачи: предиктивное моделирование рисков академической неуспеваемости; анализ сложности и взаимосвязи учебных дисциплин; формирование адаптивных образовательных траекторий [2].
Если академическая успеваемость отражает результат образовательного процесса, то поведенческие данные позволяют заглянуть внутрь самого процесса, анализируя вовлеченность, мотивацию и паттерны учебной деятельности студента. В современной цифровой среде каждый шаг студента оставляет «цифровой след», совокупность которых формирует поведенческий профиль. Анализ этого профиля позволяет перейти от формальной оценки знаний к «пониманию» студента, что открывает новые возможности для своевременной поддержки.
Основными источниками поведенческих данных в российских университетах являются: системы управления обучением (например Moodle; лог-файлы этих систем фиксируют широкий спектр активностей); системы контроля и управления доступом (данные о проходе через турникеты позволяют с высокой точностью оценить физическую посещаемость занятий); данные о внеучебной деятельности (учет участия студентов в научных конференциях, спортивных секциях, волонтерских проектах и творческих коллективах); данные библиотечных систем (информация о взятых книгах и использовании электронных научных ресурсов). Анализ этих, на первый взгляд, разрозненных данных позволяет решать следующие критически важные задачи: установление корреляции между вовлеченностью и академическими результатами; сегментация студентов на основе поведенческих паттернов.
Современный образовательный подход, закрепленный в Федеральных государственных образовательных стандартах (ФГОС), предполагает значительную гибкость учебных планов. Университеты получили право самостоятельно формировать значительную часть образовательной программы. В этих условиях критически важной задачей становится адаптация содержания и структуры образовательных программ (ОП) на основе объективных данных, а не только на базе экспертных мнений профессорско-преподавательского состава. Анализ данных, связанных с реализацией ОП, позволяет оценить их актуальность, внутреннюю согласованность и эффективность с точки зрения образовательных результатов [3].
Источниками данных для такого анализа служат: системы выбора элективных занятий; данные об успеваемости студентов в разрезе курсов и программ; платформы электронных образовательных сред, которые содержат данные о времени и характере взаимодействия студентов с учебными материалами по каждой дисциплине; данные о трудоустройстве выпускников. Комплексный анализ этих данных позволяет решать следующие стратегические задачи: оценка востребованности и актуальности учебных курсов; оптимизация логической структуры и сложности образовательной программы; анализ образовательных траекторий.
Преподавательский состав является ключевым активом любого университета и главным носителем образовательной миссии. Оценка и развитие кадров – одна из главных задач управления качеством образования. Традиционные подходы к оценке, основанные на квалификационных требованиях (степень, звание, стаж) и периодических аттестациях, не всегда отражают реальную эффективность педагогической и научной деятельности. Анализ данных позволяет перейти к более объективной, многофакторной и динамической модели оценки и развития педагогического состава [4].
Источниками данных для такого анализа являются: данные кадровых систем и отделов планирования учебной работы, которые содержат информацию об учебной нагрузке преподавателей (лекционные часы, семинары, консультации), их должностях, ставках и административных обязанностях; библиографические базы данных (РИНЦ, Scopus, Web of Science), которые предоставляют метрики научной продуктивности, такие как количество публикаций, индекс Хирша, цитируемость; результаты студенческой оценки преподавания (анонимные опросы, в которых студенты оценивают различные аспекты работы преподавателя по пройденным курсам); данные об успеваемости студентов в разрезе преподавателей – средний балл, процент отличных оценок и процент пересдач по группам, которые вел конкретный преподаватель. Интеграция и анализ этих данных позволяют решать задачи, направленные на повышение эффективности педагогической деятельности и оптимизацию кадровой политики.
В начале 2000-х годов Target столкнулась с потребностью не просто привлекать клиентов, а формировать их долгосрочную лояльность, превращая разовых покупателей в постоянных на десятилетия вперед. Аналитики компании понимали, что большинство покупательских привычек у взрослых людей уже сформированы и инертны. Кардинально изменить их, заставив человека сменить привычный супермаркет сложно и дорого. На основе этого понимания была сформулирована стратегическая гипотеза: существуют ключевые события или «триггеры», когда устоявшиеся поведенческие паттерны человека временно дестабилизируются и становятся восприимчивыми к изменениям [5].
Одним из самых мощных таких событий является рождение первого ребенка. В этот период у семьи возникает целый пласт новых, долгосрочных потребностей: подгузники, детское питание, одежда, игрушки, а позже – товары для школы и досуга. Семья находится в активном поиске надежного поставщика всех этих товаров. Таким образом, ритейлер, который сможет первым идентифицировать этот момент и предложить будущим родителям релевантную помощь и выгодные условия, с высокой вероятностью «завоюет» их лояльность не только в детских категориях, но и во всех остальных (продукты, бытовая химия, одежда), закрепив их за собой на многие годы вперед.
Эта стратегическая гипотеза была преобразована в конкретную аналитическую задачу: не просто идентифицировать беременных женщин среди своих покупательниц, а сделать это на как можно более раннем сроке, в идеале – в начале второго триместра беременности. Именно в этот период начинаются активные закупки, но конкуренция за внимание клиента еще не достигла своего пика. Задача состояла в том, чтобы перейти от реактивного маркетинга (предлагать товары тем, кто уже очевидно их ищет, например, покупает детскую кроватку) к предиктивному (прогнозному) маркетингу – предвосхищать будущие потребности клиента на основе едва заметных изменений в его текущем поведении. Это требовало разработки сложной математической модели, способной находить скрытые закономерности в огромном массиве данных о покупках [6].
Решение поставленной задачи потребовало создания единой инфраструктуры данных, ядром которой стал уникальный идентификатор клиента (Guest ID). Этот идентификатор позволял агрегировать все транзакционные и демографические данные о клиенте в единый продольный профиль, отслеживая его покупательское поведение во времени. Аналитический процесс был реализован в два последовательных этапа, демонстрирующих переход от ретроспективного анализа к прогнозному моделированию:
этап 1: описательный и диагностический анализ. Была проанализирована контрольная выборка клиенток, добровольно сообщивших о своей беременности путем регистрации в системе «детского реестра». Изучение их покупательской истории за месяцы, предшествующие этому событию, позволило выявить устойчивый поведенческий паттерн. Было идентифицировано около 25 категорий товаров-предикторов (включая лосьоны без запаха, пищевые добавки с магнием и кальцием и др.), покупка которых в определенной комбинации коррелировала с высокой вероятностью беременности. Данный этап позволил сформулировать и эмпирически подтвердить гипотезу о существовании измеримого «сигнала» в данных;
этап 2: предиктивное моделирование. На основе выявленных паттернов была построена модель машинного обучения (логистическая регрессия), автоматизирующая процесс идентификации. Модель обрабатывала текущие транзакционные данные каждой покупательницы и рассчитывала для нее два ключевых показателя: интегральный «балл вероятности беременности» (pregnancy prediction score) и прогнозируемую дату родов [7]. Это позволило не только выявлять целевой сегмент с высокой точностью, но и определять конкретный этап жизненного цикла, на котором находится клиент. Таким образом, был осуществлен качественный переход от анализа свершившихся фактов к прогнозированию будущих потребностей в промышленных масштабах.
Интеграция предиктивной системы в маркетинговые процессы компании позволила автоматически формировать персонализированные предложения для клиенток на основе прогноза беременности. Однако первоначальная реализация столкнулась со значительным социально-психологическим барьером: чрезмерно точная персонализация была воспринята как вторжение в частную жизнь, порождая ощущение «слежки» и репутационные риски. В ответ компания скорректировала тактику, применив «маскировку» персонализации: релевантные купоны на детские товары интегрировались в подборки со случайными предложениями. Этот подход сохранил эффективность целевого маркетинга, но снизил его навязчивость, создавая у покупателя впечатление совпадения, а не целенаправленного наблюдения.
Экономический эффект от внедрения оказался колоссальным. Выручка Target в категории «Товары для мам и детей» выросла на сотни миллионов долларов, что стало одним из драйверов общего роста выручки компании с $44 млрд до $67 млрд за 2002–2010 гг. Таким образом, кейс эмпирически доказал высокий возврат на инвестиции от предиктивного анализа. Стратегический вывод заключается в демонстрации сдвига от реактивного управления к предиктивному на уровне парадигм, что позволяет прогнозировать потребности и формировать лояльность клиента.
По нашему мнению, выводы из рассмотренного кейса могут быть адаптированы к сфере образования. Эффективное применение анализа данных для управления качеством образования требует выстроенного, циклического и воспроизводимого процесса. Простая констатация наличия данных не приводит к результату; ценность извлекается только в ходе их системной обработки, которая включает в себя несколько последовательных, взаимосвязанных этапов (см. рисунок).
Первым, фундаментальным этапом является сбор и накопление данных. В большинстве университетов информация «генерируется» и хранится в изолированных друг от друга системах: успеваемость – в балльно-рейтинговой системе, активность студентов – в LMS, данные о контингенте и преподавателях – в кадровых системах («1С: Университет» и т.п.), посещаемость – в системах контроля доступа. Для проведения комплексного анализа необходимо преодолеть эту разрозненность путем создания централизованного хранилища данных (Data Lake). Этот шаг позволяет интегрировать информацию из всех источников и создать единый, достоверный и целостный взгляд на образовательный процесс [8].
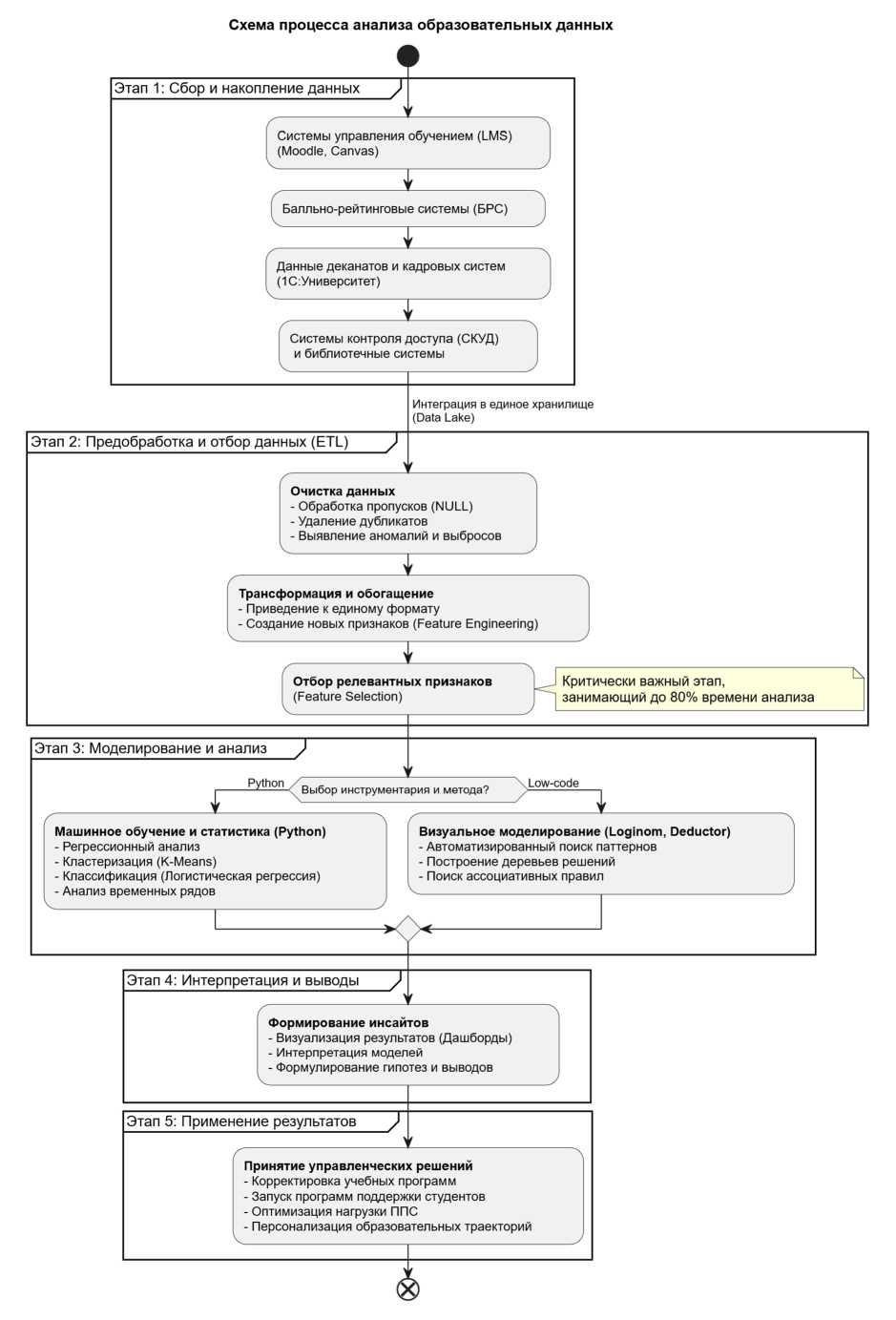
Рис. Процесс анализа образовательных данных
Следующий этап – предобработка и очистка данных – является наиболее трудоемким, занимая до 80% времени анализа, но именно от его качества зависит достоверность всех последующих выводов. «Сырые» данные практически всегда содержат ошибки: пропущенные значения, дубликаты, аномальные выбросы. В ходе очистки принимаются решения об обработке таких данных: пропуски могут быть заполнены средними или медианными значениями, либо с использованием более сложных моделей; аномалии исследуются и либо корректируются, либо исключаются из выборки. Далее данные трансформируются: приводятся к единым форматам и шкалам, обогащаются новыми, производными признаками (Feature Engineering). Например, на основе логов LMS можно рассчитать интегральный «показатель вовлеченности» для каждого студента.
После того как данные подготовлены, наступает этап моделирования и анализа. Здесь применяются методы статистики и машинного обучения для поиска закономерностей и построения прогнозов. Выбор инструментария зависит от сложности задачи и компетенций исполнителей. Для глубокого исследования и построения сложных предиктивных моделей эффективным является использование языка Python и его аналитических библиотек (Pandas, Scikit-learn, Statsmodels). Для задач быстрой проверки гипотез, построения отчетов и решения стандартных аналитических кейсов могут применяться low-code платформы, такие как Loginom, которые позволяют реализовывать логику анализа в визуальном интерфейсе. На этом этапе могут быть построены модели регрессии для прогноза успеваемости, модели классификации для выявления риска отчисления или проведен кластерный анализ для сегментации студентов [9].
Четвертый этап – интерпретация результатов и формирование выводов. Результаты работы математической модели (например, набор коэффициентов или список кластеров) не являются конечным продуктом. Задача аналитика – интерпретировать эти технические результаты в контексте образовательного процесса, превратив их в понятные и практически значимые инсайты [10]. Ключевую роль здесь играет визуализация данных: построение интерактивных дашбордов и отчетов, которые наглядно демонстрируют выявленные закономерности и позволяют управленческому персоналу быстро понять суть проблемы или открытия.
Завершающим этапом, замыкающим цикл, является применение результатов и принятие решений. На основе сформулированных выводов руководство университета или образовательной программы принимает конкретные управленческие решения: вносит изменения в учебный план, запускает программы тьюторской поддержки для студентов из «группы риска», корректирует нагрузку преподавателей. Именно этот этап делает всю предыдущую аналитическую работу осмысленной, так как приводит к реальным изменениям, направленным на повышение качества образования. Эти изменения, в свою очередь, генерируют новые данные, которые поступают на первый этап, запуская новый виток аналитического цикла.
Заключение
В условиях цифровой трансформации переход к управлению, основанному на данных, становится необходимостью для российских университетов. Настоящее исследование показало, что комплексный анализ образовательных данных является мощным инструментом для повышения качества образовательного процесса. Было выявлено, что применение современных аналитических методов поможет решать ключевые задачи: от снижения отсева студентов за счет предиктивного моделирования до повышения актуальности образовательных программ и персонализации обучения. Пример из практики ритейла подтвердил универсальность предиктивной аналитики. Методология, позволяющая прогнозировать потребности клиентов и формировать их лояльность, полностью применима к задачам высшей школы, где успехи студента являются аналогом лояльности клиента.
Успешное внедрение data-driven подхода требует не только технологических решений, но и формирования культуры работы с данными при строгом соблюдении этических норм. Представленный процесс анализа подчеркивает системный характер этой деятельности, от сбора данных до их практического применения. Следовательно, инвестиции в аналитические компетенции и IT-инфраструктуру являются стратегическим вложением в конкурентоспособность вуза. Это обеспечивает переход от реактивного управления к проактивной управленческой парадигме, с приоритетом на интересах и потребностях обучающихся, где решения подкреплены данными, что способствует достижению главной цели – подготовке высококвалифицированных специалистов.
