Нейросетевая классификация видеороликов по малому числу кадров

Автор: Смирнов А.В., Парфенов Д.Д., Тищенко И.П.
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Математическое моделирование
Статья в выпуске: 4 (63) т.15, 2024 года.
Бесплатный доступ
В статье предложен метод нейросетевой классификации коротких видеороликов. Задача классификации рассматривается с точки зрения уменьшения числа требуемых операций для категоризации видеороликов. Предлагаемое решение заключается в использовании небольшого числа кадров (не более 10) для выполнения классификации при помощи самой лёгкой нейросетевой архитектуры семейства моделей ResNet. В ходе исследования создан собственный набор данных для обучения, состоящий из трёх классов: «animals», «cars» и «people». В результате получена точность классификации, равная 79%, а также сформирована база данных классифицируемых видеороликов и разработано приложение с элементами GUI для взаимодействия с классификатором и просмотра результатов.
Классификация видео, набор данных, нейронные сети, графический интерфейс пользователя
Короткий адрес: https://sciup.org/143183791
IDR: 143183791 | УДК: 004.93'11 | DOI: 10.25209/2079-3316-2024-15-4-79-96
Neural network classification of videos based on a small number of frames
The article proposes a method for neural network classification of short videos. The classification problem is considered from the point of view of reducing the number of operations required to categorize videos. The proposed solution consists of using a small number of frames (no more than 10) to perform classification using the lightest neural network architecture of the ResNet family of models. As part of the work, a proprietary training dataset was created, consisting of three classes: “animals”, “cars” and “people”. As a result, a classification accuracy of 79% was obtained, a database of classified videos was formed, and an application with GUI elements was developed for interacting with the classifier and viewing the results.
Текст научной статьи Нейросетевая классификация видеороликов по малому числу кадров
В настоящее время большую роль в обработке информации различного типа и происхождения играют нейронные сети. Одной из наиболее востребованных областей применения нейросетевых моделей является обработка графических данных, в частности изображений или видео.
Так, например, в работе [1] задача классификации видео рассматривается как операция присвоения некоторого индекса или метки конкретному видеоролику. Авторы используют собственную модель свёрточной нейронной сети (CNN), а также набор данных UCF1 11, состоящий из видеороликов с различными действиями людей. В результате была получена точность классификации действий, сравнимая с другими нейросетевыми моделями.
В другой работе [2] основное внимание уделялось поиску ключевых кадров на видео, что в последствии повышало точность классификации. Здесь авторы используют гибридную модель состоящую из свёрточной нейронной сети, технологии кластеризации пиков плотности временных сегментов (TSDPC) 2 и сети с долговременной краткосрочной памятью (LSTM) 3 . В итоге им удалось получить точность на наборах данных HMDB51 4 и UCF10 15 в 82.94% и 91.43% соответственно.
Статья [3] также посвящена поиску ключевых кадров. Разработанный метод основан на использовании шаблонов действий путем определения информативной области каждого кадра. Данный метод был протестирован на наборе данных UCF101 с использованием моделей ConvLST M6 и VGG1 67 . В результате была получена точность классификации видео более 80%.
Достаточно важным фактором в задаче классификации видео может стать используемый для обучения набор данных. Именно от используемого набора данных зависит итоговая цель классификации. В статье [4] рассматривается создание набора данных из видеороликов, содержащих действия с разжиганием ненависти. Авторы отмечают, что подобные наборы данных существуют, но содержат в основном текстовую информацию, а изображения и видео представлены очень редко. Вследствие чего, авторы вручную отобрали 43 часа видео для создания своего набора данных, на котором протестировали нейронную сеть и получили точность около 79%.
В работе [5] решается задача поиска признаков ненормального поведения пассажиров лифта. Эксперименты проводились на наборе видеоданных, содержащем четыре вида ненормального поведения: открывание двери, прыжки, пинки и блокировка двери. При использовании модифицированной модели PP-TSM удалось достичь точности классификации в 95%, что на 10% больше, чем было получено на стандартной модели PP-TS M8.
Статья [6] описывает метод обнаружения аномального поведения на видео. В данном случае под таким поведением подразумевается проявление жестокости с использованием оружия. Для обнаружения аномалий поведения авторы используют собственную модель нейронной сети J.QCNN, основанную на квантовой свёрточной нейронной сети (QCNN) [7] и глубокой свёрточной нейронной сети Javeria (DCNN). В результате была получена точность обнаружения более 90% по метрике F1-scor e9 .
Следующая работа [8] посвящена распознаванию действий на видео с последующим расставлением временных меток. Здесь предлагается модель на основе метода двухпотокового слияния информации с механизмами внимания (DSIFAM). При тестировании разработанной модели на наборах данных UCF11 и UCF5 010 была получена точность в 91.2% и 89.1% соответственно.
Помимо анализа готовых видеофайлов, также ведутся работы по обработке потокового видео. Такой подход следует использовать, когда необходимо оперативно принять решение, например, быстро идентифицировать потенциально критические или опасные ситуации. Так в статье [9] рассматривается унифицированная и теоретически обоснованная адаптационная система для решения проблемы онлайн-классификации видеоданных, которая основана на математической модели теории классификации. Благодаря этому авторам удалось получать результат от нейронной сети гораздо быстрее без значительного ущерба для точности по сравнению с классическим подходом.
В статье [10] представлено исследование на тему классификации спортивных видео. Ключевой проблемой является природа данных видеороликов, которая заключается в присутствии большого количества динамических сцен. Для решения поставленных задач, авторы разрабатывают собственную нейросетевую модель, основанную на извлечении ключевых кадров и использующую принципы сиамских сете й11. В результате новая модель продемонстрировала точность в 97% на наборе видеоданных высокого разрешения и 87% на наборе видеоданных низкого разрешения.
Анализ мультипликационных видеороликов представлен в работе [11] . Здесь авторы поставили задачу отфильтровать нежелательный контент, содержащий жестокие и откровенно сексуальные сцены. Они использовали предварительно обученную на наборе данных ImageNe t12 свёрточную сеть в сочетании с сетью двунаправленной долговременной краткосрочной памяти на основе внимания (BiLST M13) . Эксперименты показали, что разработанная модель работает относительно лучше других сетей, достигая точности в 95.3%.
Нейросетевая обработка видеоданных находит применение в различных сферах. Благодаря высокой точности такого анализа некоторые результаты исследований можно применять уже сейчас в различных видеохостингах в качестве инструмента фильтрации и автоматизированной категоризации контента.
В настоящей работе предложен метод нейросетевой классификации коротких видеороликов по небольшому числу кадров. В рамках данной работы был создан собственный обучающий набор данных, состоящий из 3 классов: «animals», «cars» и «people». В результате была получена точность классификации, равная 79% по метрике F1-score, что немного ниже, чем в представленных выше работах. Однако прямое сравнение точности классификации нецелесообразно, так как использовались не только разные нейросетевые модели, но и разные наборы данных.
1. Цель и задачи исследования
Классификация изображений или объектов на изображениях предполагает отнесение целевого объекта к одному из рассматриваемых классов. При классификации видеороликов задача классификации сводится к определению категории/класса видео. Однако видеоролик по сути является набором изображений/кадров, которые постепенно сменяют друг друга. В таком случае требуется определить класс большого множества отдельно взятых кадров, что может быть ресурсозатратно, так как в одной секунде стандартного видеоролика может быть от 30 кадров. Очевидным выходом из данной ситуации может быть использование лишь части кадров видеоролика.
Отличительной особенностью настоящего исследования является использование малого числа кадров видеоролика для выполнения его классификации. Тесты нейросетевого анализа показали, что для достижения удовлетворительной точности достаточно использовать около 10±1 кадров видео.
Основной целью настоящего исследования является экспериментальная проверка метода нейросетевой классификации/категоризации видеороликов, который основан на анализе малого числа кадров без предварительной обработки. Метод считается условно работоспособным, если точность классификации видеороликов превышает 70%.
2. Используемая нейросетевая модель-классификатор
В качестве классификатора рассматривались следующие нейросетевые решения: ResNet [12] , Faster R-CNN [13] и EfficientNet [14] . Среди представленных моделей была выбрана 18 слойна я14 нейросетевая архитектура ResNet (рисунок 1) , так как она предлагает баланс между глубиной, сложностью и производительностью.
Вероятно, для будущих итераций настоящего исследования будет использована 50 слойна я15 арихетектура ResNet. Такое решение было продиктовано тем, что 50 слойная архитектура показывает более высокие результаты точности, но также требует больше времени на обучение и классификацию. Тем не менее, 18 слойная архитектура ResNet способна показывать сопоставимые значения точност и16. Реализация архитектуры ResNet–18 была выполнена на ЯП Python с использованием инструментария PyTorc h17 .
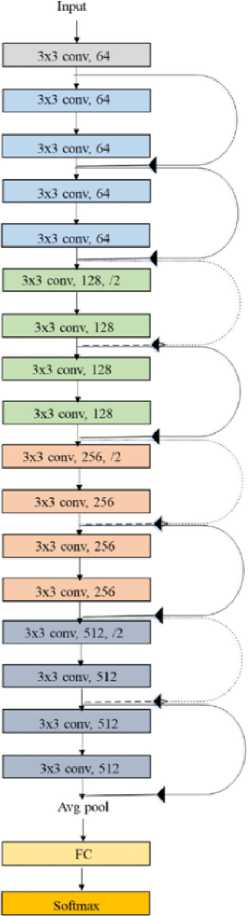
Рисунок 1. Оригинальная архитектура ResNet18
3. Создание набора обучающих данных
Несмотря на наличие готовых наборов данных, для решения поставленных задач был создан собственный обучающий набор данных, состоящий из кадров видео с изображением неудач. Так называемое «видео с неудачей» обычно длится менее 10 секунд и содержит не более двух действий-неудач.
По мнению авторов настоящей статьи такой видеоролик с большой долей вероятности может быть успешно классифицирован, так как его содержание достаточно однозначно определено типом отображаемой неудачи. Однако из-за короткой продолжительности «видео с неудачей» часто собирают в тематические подборки, что, с одной стороны, упрощает поиск достаточного количества данных, а с другой стороны, затрудняет извлечение и обработку конкретного ролика.
-
3.1. Критерии определения классов
-
3.2. Формирование набора данных
Для классификации видеоданных было сформировано три основных класса: «animals», «cars» и «people». Каждый класс определялся наличием на видео объекта конкретного типа, который непосредственно совершал неудачное действие или становился причиной неудач, а именно:
animals — класс включал сцены, где причиной неудачи было животное.
Сюда входили различные виды животных, от домашних до диких, которые по своей природе создавали ситуации, подходящие под определение «видео с неудачей»;
cars — класс включал сцены, в которых основной причиной возникновения неудачи являлся автомобиль. Подобные видеофрагменты охватывали инциденты с участием автомобилей, такие как аварии, неудачные маневры и другие события, связанные с транспортными средствами;
people — класс содержал видеоматериалы, где неудачные ситуации происходил исключительно с участием людей, без присутствия животных или автомобилей. Сцены данного типа включали падения, ошибки и другие инциденты, произошедшие с людьми.
В первую очередь был осуществлён сбор исходного видеоматериала, сгруппированного по трем ранее описанным категориям. Видеоконтент был извлечён с популярного видеохостинга18 при помощи специально написанного скрипта на ЯП Python, который позволяет загружать видеофайлы различного формата и качества.
Процесс формирования набора данных состоял из следующих этапов:
Предварительная обработка видео. После получения исходных видеофайлов была проведена их предварительная обработка в программе Adobe Premiere Pr o19. С помощью функции «определение сцен» (Scene Detection) видео было автоматически разделено на отдельные сцены. Этот шаг был необходим, так как скачанный видеоматериал представлял собой подборки «видео с неудачами», которые были смонтированы в единый видеоролик.
Разделение сцен на кадры. Полученные ранее сцены были разделены на кадры. В рамках данного процесса из каждой сцены были извлечены последовательности по 10 случайных кадров.
Верификация и очистка данных. На этом этапе был проведён тщательный анализ полученных кадров. Кадры проверялись на корректность и соответствие выбранным критериям категорий. Нерелевантные кадры (размытый кадр, чёрный экран и т.п.) были удалены из набора данных.
Расширение и балансировка набора данных. Завершающим этапом было расширение и балансировка набора данных. Поскольку изначально количество данных в каждой из категорий могло отличаться, были приняты меры по балансировке классов. Для этого использовались методы дополнения данных, включая операции поворота, изменения масштаба, а также другие трансформации, что позволило создать равномерно распределённый набор данных для последующего обучения нейронной сети.
Таким образом, процесс создания набора данных был тщательно структурирован и включал в себя этапы сбора, обработки, верификации и балансировки данных, что обеспечило получение качественного и надежного материала для дальнейшего обучения модели. Сформированный набор данных содержал по 2939 изображений/кадров для каждого из трёх классов.
4. Обучение нейронной сети
Обучение нейронной сети происходило при помощи трансферного метода. Трансферное обучение (TL)20 — это метод машинного обучения, при котором модель, предварительно обученная выполнению одной задачи, перенастраивается для выполнения другой, похожей на предыдущую. Обучение новой модели – это трудоемкий и длительный процесс, требующий большого количества данных, достаточной вычислительной мощности и прохождения нескольких итераций, прежде чем модель будет готова к запуску. Вместо этого применяется метод TL для переобучения существующих моделей, подготавливая их к решению смежных задач с использованием новых данных.
Метод TL был использован на предварительно обученной модели ResNet–18. Переобучение модели выполнялось в течении 25, 35 и 50 эпох. В таблице 1 представлены характеристики модели после обучения.
Таблица 1. Характеристики модели после обучения
|
Кол-во эпох |
Точность на тренировочной выборке, % |
Точность на валидационной выборке, % |
Ошибка на тренировочной выборке |
Ошибка на валидационной выборке |
|
25 |
78.0 |
89.7 |
0.538 |
0.266 |
|
35 |
77.3 |
90.4 |
0.546 |
0.262 |
|
50 |
81.4 |
93.6 |
0.458 |
0.172 |
На рисунках 2 и 3 представлены графики точности и ошибки для обучения модели в течение 50 эпох.
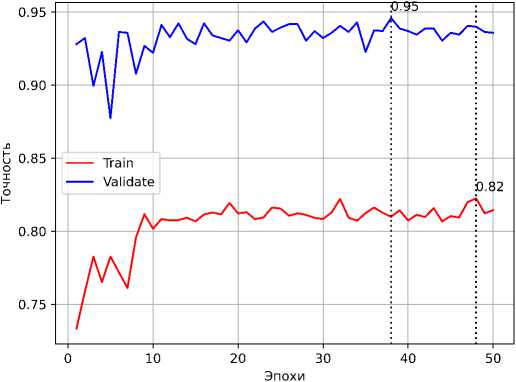
Рисунок 2. График изменения значения точности, полученной на тренировочной и валидационной выборках в процессе обучения
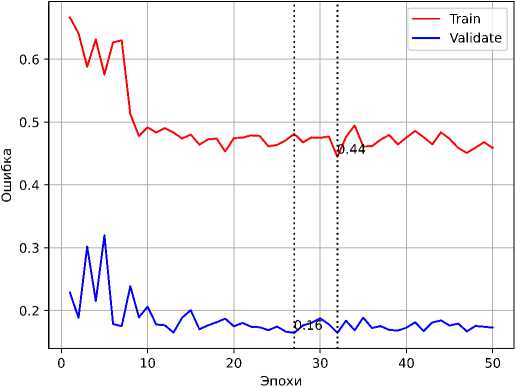
Рисунок 3. График изменения значения ошибки, полученной на тренировочной и валидационной выборках в процессе обучения
5. Тестирование нейросети и подсчёт точности
Для тестирования обученной нейронной сети использовалось 35 видеороликов класса «animals», 39 видеороликов класса «cars» и 42 видеоролика класса «people». Из каждого видеоролика извлекалось 10±1 кадров с равными временными промежутками. Принадлежность ролика к какому-либо классу определялась классом большинства его кадров, то есть, если более 50% кадров ролика имели некоторый класс, то и сам видеоролик относился к этому же классу.
Точность рассчитывалась по метрике F1-score с помощью функции MulticlassF1Scor e21 библиотеки PyTorch Lightnin g22. Также были подсчитаны значения Precision (точность) 23 и Recall (полнота) 24 для видеороликов и их кадров. В таблицах 2 и 3 представлены данные, полученные в ходе тестирования нейросети.
Таблица 2. Данные о количестве используемых кадров и результирующей точности
|
Класс |
Кол-во кадров |
Precision |
Recall |
F1-score |
|
animals |
378 |
0.754 |
0.576 |
0.653 |
|
cars |
427 |
0.899 |
0.733 |
0.807 |
|
people |
456 |
0.602 |
0.824 |
0.696 |
|
Общее |
1261 |
0.752 |
0.711 |
0.719 |
Таблица 3. Данные о количестве используемых видеороликов и результирующей точности
|
Класс |
Кол-во видео |
Precision |
Recall |
F1-score |
|
animals |
35 |
0.884 |
0.657 |
0.754 |
|
cars |
39 |
0.916 |
0.846 |
0.880 |
|
people |
42 |
0.666 |
0.857 |
0.750 |
|
Общее |
116 |
0.822 |
0.786 |
0.794 |
6. Приложение для взаимодействия с классификатором и просмотра результатов
В рамках исследования, описанного в настоящей статье, было разработано приложение с графическим интерфейсом пользователя (GUI) для взаимодействия с классификатором, хранения и просмотра результатов классификации видеороликов. На рисунке 4 изображены основные окна приложения.
Разработанное приложение имеет следующий функционал:
Выбор видеофайла. Данная операция позволяет пользователю выбрать один или несколько видеофайлов с локального диска для их классификации. При нажатии на соответствующий элемент GUI открывается диалоговое окно для выбора файлов с расширениями .mp4, .avi и .mov. После завершения выбора выполняется анализ каждого файла. Результатом анализа является определённый класс/категория видео («animals», «cars» или «people»).
Взаимодействие с базой данных. При нажатии на соответствующий элемент GUI открывается новое окно, в котором отображается список видеофайлов, ранее классифицированных и сохраненных в базе данных. Далее отправляется запрос к базе данных для извлечения видео на основе выбранного фильтра. Пользователь может выбрать категорию для фильтрации или оставить фильтр на значении «All» для отображения всех видео. В окне предпросмотра отображается список видеофайлов с указанием их пути и категории.
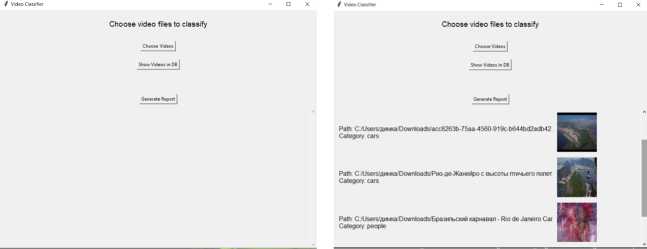
(а) Основное окно (б) Окно отображения результатов приложения классификации
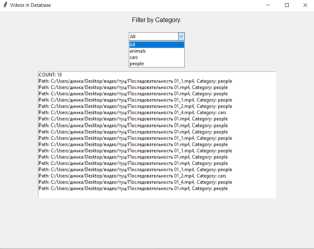
( в ) Окно взаимодействия с базой данных
Рисунок 4. Приложение для взаимодействия с классификатором
Создание отчёта. При нажатии на на соответствующий элемент GUI приложение генерирует текстовый файл, который содержит сводку о количестве видео в каждой категории и полный список видео с указанием их категорий.
7. Анализ полученных результатов
В процессе тестирования нейронной сети была достигнута точность классификации более 79% (0.794), при этом точность классификации отдельного класса «cars» составила 88% (0.880). Данные показатели выше, чем заявленный порог в 70%, при достижении которого предложенный метод считается успешно проверенным и условно работоспособным.
Тем не менее, полученное значение точности меньше, чем в аналогичных работах, рассмотренных ранее. Это может указывать на наличие некоторых недостатков представленного метода классификации. Однако проводить прямое сравнение некорректно, так как использовались не только разные нейросетевые модели, но и разные наборы данных.
Стоит отметить, что в предложенном методе не используются какие-либо алгоритмы предобработки видео/кадров видео. Помимо этого, классификатором выступает относительно простая и лёгкая нейросетевая модель. Основная идея предложенного метода как раз и заключалась в том, чтобы выполнить классификацию/категоризацию видеороликов с использованием минимально возможных инструментария и данных.
Вывод
В результате проведённого исследования была достигнута точность классификации/категоризации видео более 79%, что доказывает жизнеспособность выбранного метода. Однако следует учесть тот факт, что при анализе видео сложной композиции или при классификации на более конкретные классы, вероятно, потребуется прибегнуть к дополнительным методам извлечения признаков или ключевых кадров, которые были описаны в рассмотренных статьях.
Список литературы Нейросетевая классификация видеороликов по малому числу кадров
- Duvvuri K., Kanisettypalli H., Jaswanth K., Murali K. Video classification using CNN and ensemble learning // 2023 9th International Conference on Advanced Computing and Communication Systems.– V. 1, ICACCS 2023 (17-18 March 2023, Coimbatore, India).– IEEE.– 2023.– ISBN 9798350397383.– Pp. 66–70. https://doi.org/10.1109/ICACCS57279.2023.10112975
- Tang H., Ding L., Wu S., Ren B., Sebe N., Rota P. Deep unsupervised key frame extraction for efficient video classification // ACM Transactions on Multimedia Computing, Communications and Applications.– 2023.– Vol. 19.– No. 3.– id. 119.– 17 pp. https://doi.org/10.1145/3571735
- Savran K. R., Gan J. Q., Escobar J. J. A novel keyframe extraction method for video classification using deep neural networks // Neural Computing and Applications.– 2023.– Vol. 35.– No. 34.– Pp. 24513–24524. https://doi.org/10.1007/s00521-021-06322-x
- Das M., Raj R., Saha P., Mathew B., Gupta M., Mukherjee A. HateMM: a multi-modal dataset for hate video classification // Proceedings of the International AAAI Conference on Web and Social Media.– 2023.– Vol. 17, Proceedings of the Seventeenth International AAAI Conference on Web and Social Media (ICWSM 2023).– Pp. 1014–1023. https://doi.org/10.1609/icwsm.v17i1.22209
- Lei J., Sun W., Fang Y., Ye N., Yang S., Wu J. A model for detecting abnormal elevator passenger behavior based on video classification // Electronics.– 2024.– Vol. 13.– No. 13.– id. 2472.– 15 pp. https://doi.org/10.3390/electronics13132472
- Amin J., Anjum M. A., Ibrar K., Sharif M., Kadry S., Crespo R. G. Detection of anomaly in surveillance videos using quantum convolutional neural networks // Image and Vision Computing.– 2023.– Vol. 135.– id. 104710. https://doi.org/10.1016/j.imavis.2023.104710
- Cong I., Choi S., Lukin M. D. Quantum convolutional neural networks // Nature Physics.– 2019.– Vol. 15.– Pp. 1273–1278. https://doi.org/10.1038/s41567-019-0648-8
- Jianmin H., Jie L. A video action recognition method via dual-stream feature fusion neural network with attention // International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems.– 2024.– Vol. 32.– No. 04.– Pp. 673–694. https://doi.org/10.1142/S0218488524400130
- Trędowicz M., Struski Ł., Mazur M., Janusz S., Lewicki A., Tabor J. PrAViC: probabilistic adaptation framework for real-time video classification.– 2024.– 12 pp. https://doi.org/10.48550/arXiv.2406.11443 arXivarXiv 2406.11443 [cs.CV]
- Gao T., Zhang M., Zhu Y., Zhang Y., Pang X., Ying J., Liu W. Sports video classification method based on improved deep learning // Applied Sciences.– 2024.– Vol. 14.– No. 2.– id. 948.– 13 pp. https://doi.org/10.3390/app14020948
- Kanwal Y., Tabassam N. An attention mechanism-based CNN-BiLSTM classification model for detection of inappropriate content in cartoon videos // Multimedia Tools and Applications.– 2024.– Vol. 83.– No. 11.– Pp. 31317–31340. https://doi.org/10.1007/s11042-023-16727-6
- He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition // 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016 (27-30 June 2016, Las Vegas, NV, USA).– IEEE.– 2016.– ISBN 978-1-4673-8850-4.– Pp. 770–778.
- Ren S., He K., Girshick R., Sun J. Faster R-CNN: towards real-time object detection with region proposal networks // Proceedings of the 28th International Conference on Neural Information Processing Systems.– V. 1, NIPS’15 (December 7–12, 2015, Montreal, Canada), Cambridge: MIT Press.– 2015.– ISBN 9781510825024.– Pp. 91–99. https://doi.org/10.5555/2969239.2969250
- Tan M., Le Q. V. EfficientNet: rethinking model scaling for convolutional neural networks // Proceedings of the 36th International Conference on Machine Learning, ICML 2019 (9-15 June 2019, Long Beach, California, USA), Proceedings of Machine Learning Research.– vol. 97.– ICML.– 2019.– ISBN 9781510886988.– Pp. 6105–6114.
