О генерации случайных задач линейного программирования на кластерных вычислительных системах

Автор: Соколинский Леонид Борисович, Соколинская Ирина Михайловна
Статья в выпуске: 2 т.10, 2021 года.
Бесплатный доступ
В статье рассматривается масштабируемый алгоритм FRaGenLP для генерации больших совместных случайных задач линейного программирования произвольной размерности n на кластерных вычислительных системах. Для обеспечения совместности и ограниченности допустимой области система ограничений включает в себя 2n+1 стандартных неравенств, называемых опорными. Случайные неравенства добавляются в систему последовательно так, чтобы сохранялась совместность ограничений. Кроме этого, вводятся две метрики «похожести», которые препятствуют добавлению нового случайного неравенства, «похожего» на какое-либо из уже включенных в систему, включая опорные. Также отклоняются случайные неравенства, которые при фиксированной целевой функции не влияют на решение опорной задачи линейного программирования. Параллельная реализация алгоритма FRaGenLP выполнена на языке C++ с использованием параллельного BSF-каркаса, инкапсулирующего в проблемно-независимой части своего кода все аспекты, связанные с распараллеливанием программы на базе библиотеки MPI. Приводятся результаты масштабных вычислительных экспериментов на кластерной вычислительной системе, подтверждающие эффективность использованного подхода.
Случайная задача линейного программирования, генератор задач, FRaGenLP, кластерные вычислительные системы, BSF-каркас
Короткий адрес: https://sciup.org/147234293
IDR: 147234293 | УДК: 004.382.2 | DOI: 10.14529/cmse210203
On generator of random problems for linear programming on cluster computing systems
The article presents and evaluates a scalable FRaGenLP algorithm for generating random linear programming problems of large dimension n on cluster computing systems. To ensure the consistency of the problem and the boundedness of the feasible region, the constraint system includes 2n+1 standard inequalities, called support inequalities. New random inequalities are generated and added to the system in a manner that ensures the consistency of the constraints. Furthermore, the algorithm uses two likeness metrics to prevent the addition of a new random inequality that is similar to one already present in the constraint system. The algorithm also rejects random inequalities that cannot affect the solution of the linear programming problem bounded by the support inequalities. The parallel implementation of the FRaGenLP algorithm is performed in C++ through the parallel BSF-skeleton, which encapsulates all aspects related to the MPI-based parallelization of the program. We provide the results of large-scale computational experiments on a cluster computing system to study the scalability of the FRaGenLP algorithm.
Текст научной статьи О генерации случайных задач линейного программирования на кластерных вычислительных системах
Эпоха больших данных [1, 2] породила задачи линейного программирования (ЛП) сверхбольших размерностей [3]. Подобные задачи возникают в экономике, индустрии, логистике, статистике, квантовой физике и других областях. Решение таких сверхбольших задач невозможно без масштабируемых параллельных алгоритмов, ориентированных на кластерные вычислительные системы. В соответствии с этим в последние годы интенсифицировались усилия по разработке новых и модернизации известных параллельных алгоритмов решения задач ЛП. В качестве примеров можно привести работы [4–8]. При разработке новых масштабируемых алгоритмов для решения сверхбольших задач линейного программирования возникает необходимость их тестирования на известных и случайных задачах. Одним из наиболее известных репозиториев больших задач линейного программирования является Netlib-Lp [9]. Данный репозиторий считается эталонным при апробации новых алгоритмов решения задач линейного программирования. Однако при
∗ Статья рекомендована к публикации программным комитетом Международной научной конференции «Параллельные вычислительные технологии (ПаВТ) 2021»
отладке решателей часто возникает необходимость в генерации случайных задач ЛП с определенными характеристиками, из которых основными являются размерность пространства и количество ограничений. В работе [10] был предложен один из первых методов генерации случайных задач ЛП с известными решениями. Метод позволяет генерировать тестовые задачи произвольного размера с широким диапазоном числовых характеристик. Идея метода заключается в том, что за основу берется задача ЛП с известным решением, которая затем модифицируется случайным образом так, чтобы решение не изменилось. Основным недостатком этого метода является то, что предварительная фиксация оптимального решения в значительной мере ограничивает случайный характер итоговой задачи ЛП. В [11] предложен генератор GENGUB, позволяющий строить случайные задачи ЛП с известным решением и заданными характеристиками, такими как размер задачи, плотность ненулевых значений матрицы коэффициентов, степень вырожденности, количество неизбыточных неравенств и др. Отличительной особенностью генератора GENGUB является введение обобщенных верхних границ , представляющих собой совокупность ограничений, в которых каждая переменная появляется как минимум один раз (имеет ненулевой коэффициент). Указанный метод имеет тот же недостаток, что и предыдущий: предварительная фиксация оптимального решения в значительной мере ограничивает случайный характер результирующей задачи ЛП. В статье [12] предложен метод генерации случайных задач ЛП с заранее выбранным типом решения: ограниченное или неограниченное, единственное или множественное. В зависимости от выбранного типа решения конструируется допустимая область задачи ЛП как объединение линейного многообразия, конуса и многогранника. Каждая из перечисленных структур генерируется с помощью случайных векторов с целочисленными координатами. Далее генерируется целевая функция, приводящая к решению требуемого типа. Описанный генератор задач ЛП используется в основном для учебных целей и мало подходит для тестирования новых алгоритмов линейного программирования в силу ограниченности многообразия генерируемых задач.
В данной статье предлагается альтернативный способ генерации случайных задач ЛП, особенность которого состоит в том, что генерируются совместные задачи заданной размерности с неизвестным решением. Такая задача подается на вход решателя. Полученное решение проверяется программой-валидатором [13], которая сертифицирует решение. Предложенный метод генерации случайных задач ЛП реализован в виде параллельной программы FRaGenLP ( Feasible Random Generator of LP ) для кластерных вычислительных систем. Статья организована следующим образом. В разделе 1 дается формальное описание предлагаемого метода генерации случайных задач ЛП и приводится последовательная версия алгоритма FRaGenLP. В разделе 2 рассматривается параллельная версия алгоритма FRaGenLP. В разделе 3 предлагается ее реализация с использованием параллельного BSF-каркаса и приводятся результаты масштабных вычислительных экспериментов на кластерной вычислительной системе, подтверждающие эффективность предложенного подхода. В заключении суммируются полученные результаты и раскрываются планы по использованию генератора FRaGenLP для разработки искусственной нейронной сети, способной решать задачи ЛП большой размерности.
-
1. Метод генерации случайных задач ЛП
Метод генерации случайных задач ЛП, используемый в программе FRaGenLP, позволяет генерировать случайные совместные ограниченные задачи ЛП произвольной размерности n , решение которых заранее неизвестно. Для обеспечения корректности задачи
|
ЛП система ограничений в |
ключает в Г " 1 * 2 |
себя следующие опорные неравенства :
* — — — — — — |
|||
|
- * - * - 2 |
xn |
< |
a 0 0 |
(1) |
|
|
* J + * 2 |
- * n " + * n |
< |
0 a (n - 1) + 100 |
||
Здесь a ∈ R>0 — положительный масштабирующий коэффициент, являющийся параметром программы FRaGenLP. Количество опорных неравенств равно 2n + 1. Количество случайных неравенств определяется параметром d ∈ !≥0 . Общее количество неравенств m определяется по формуле m = 2 n +1 + d. (2)
Коэффициенты целевой функции задаются вектором c = 0( n, n -1, n - 2,^,1), (3)
где θ ∈ R > 0 — положительный постоянный множитель, являющийся параметром программы FRaGenLP и удовлетворяющий условию
θ ≤ a .
Везде далее будем предполагать, что необходимо найти допустимую точку, в которой достигается максимум целевой функции. При количестве случайных неравенств d = 0 генерируется задача ЛП, ограничения которой включают только опорные неравенства (1). В этом случае задача ЛП имеет следующее единственное решение:
x = ( a , ^ , a , a[ 2 ) .
Коэффициенты случайного неравенства a i = ( a i1 , ! , a in ) и правая часть b i вычисляются с помощью функции rand( l, r ), генерирующей случайное вещественное число из интервала [ l, r ] ( l, r e R ; l < r ) , и функции rsgn(), случайным образом выбирающей число из множества { 1, — 1 } :
a j : = rsgnO • rand(0, a max ), b i : = rsgnO • rand(0, b max ).
Здесь a max ,b mx g R > 0 — константы, являющиеся параметрами программы FRaGenLP. В качестве знака неравенства всегда выбирается ≤ . Введем следующие обозначения:
Л.Б. Соколинский, И.М. Соколинская f( x ) = Cc, x );
^ =al2 !a/ 2 ) ;
. К a, h cnr} - b i\ dist( a i , b i , h cntr ) = -----о----- ; a i
n (x, at, b ) = x - ’ —- a.
i l ^ i f i
Формула (7) определяет целевую функцию задачи ЛП. Здесь и далее ! , ! обозначает скалярное произведение векторов. Формула (8) определяет центральную точку ограничивающего гиперкуба , задаваемого первыми 2 n неравенствами системы (1). Формула (9) определяет функцию dist( a i , b i , hcntr ), вычисляющую расстояние от гиперплоскости ai , x = bi до центра ограничивающего гиперкуба. Здесь и далее ! обозначает евклидову норму. Формула (10) определяет вектор-функцию, вычисляющую ортогональную проекцию точки x на гиперплоскость ai , x = bi .
Случайное неравенство ai , x ≤ bi получается путем генерации координат вектора ai и свободного члена bi с помощью датчика псевдослучайных дробно-рациональных чисел. Сгенерированное случайное неравенство добавляется в систему ограничений в том, и только в том случае, когда выполняются следующие условия:
(ai, hcntr) ^ bi;
p < dist( ai, bi, hcntr) < 0;
f (n ( hcntr , ai, bi))> f ( hcntr );
Vl g{1,!,i-1}:-like(ai,bi,al,bl).
Условие (11) требует, чтобы центр ограничивающего гиперкуба являлся допустимой точкой для добавляемого неравенства. Если это условие не выполняется, то вместо неравенства ai , x ≤ bi можно взять неравенство - ai , x ≤- bi . Условие (12) требует, чтобы расстояние от гиперплоскости ai , x = bi до центра hcntr ограничивающего гиперкуба было больше ρ и меньше θ . Константа ρ ∈ ! > 0 является параметром программы FRaGenLP и должна удовлетворять условию ρ < θ , где θ , в свою очередь, удовлетворяет условию (4). Условие (13) требует, чтобы значение целевой функции в точке проекции hcntr на гиперплоскость ai , x = bi было больше, чем в самой точке hcntr . Это условие в сочетании с (11) и (12) отсекает ограничения, которые не могут повлиять на решение задачи ЛП. Условие (14) требует, чтобы новое неравенство было непохоже на все ранее добавленные, включая опорные. Указанное условие использует булевскую функцию like , определяющую похожесть ( likeness ) двух неравенств ai , x ≤ bi и al , x ≤ bl по следующей формуле:
like( a i , b i , a i , b i ) =
aial a i - a l
< L mvaix ^
bibl a i - a l
< Smin *
Константы Lmax, Smin ∈!>0 являются параметрами программы FRaGenLP. При этом параметр Lmax должен удовлетворять условию
L
max
≤ 0.7
(обоснование этому ограничению будет дано ниже). В соответствии с формулой (15) неравенства ai , x ≤ bi и al , x ≤ bl считаются похожими, если выполняются следующие два условия:
aial a i - a l
bib l a i - a l
< L max ;
< S min .
Условие (17) оценивает параллельность гиперплоскостей ai , x = bi и al , x = bl , ограничивающих допустимые области исходных неравенств. Для этого сначала вычисляются единичные векторы нормалей ei = aiai и el = alal к гиперплоскостям ai , x = bi и al , x = bl . Затем вычисляется норма разности единичных векторов нормалей: δ = ei - el .
Если δ = 0 , то гиперплоскости параллельны. Если 0 < δ < Lmax , то гиперплоскости считаются почти параллельными . Условие (18) оценивает «близость» гиперплоскостей ai , x = bi и al , x = bl относительно друг друга. Для этого сначала вычисляются нормализованные свободные члены β i = biai и β l = blal . Затем вычисляется модуль их разности σ = β i - β l . Если гиперплоскости параллельны и σ = 0 , то эти гиперплоскости совпадают. Если 0 < σ < Smin , то гиперплоскости считаются почти близкими . Два линейных неравенства в R n считаются похожими , если соответствующие им гиперплоскости являются почти параллельными и почти близкими.
Ограничение (16) для параметра Lmax основано на следующем утверждении.
Утверждение 1. Пусть заданы два единичных вектора e,e′ ∈ Rn и угол ϕ<π между ними. Тогда e-e′ =2(1 - cosϕ).
Доказательство. По определению нормы в евклидовом пространстве имеем
IIe ell J^(ej ej) J^(ej 2ejej + ej ) J^ej 2^ejej + ^ej V1 2e ,,ej/ jjjjj
Таким образом
|| e - e '|| = ^ 2 (1 - (j,, e‘)).
По определению угла в евклидовом пространстве для единичных векторов имеем ej,e′j= cosϕ.
Подставив правую часть в (20), получаем
|| e - e '|| = 2 ( 1 - cos ^ ) .
Утверждение доказано.
Разумно считать два единичных вектора e , e ′ почти параллельными, если угол ϕ между ними меньше, чем π 4 . В этом случае согласно (19) имеем
II e - e' < 2 1 1 - cos -
I 4
Учитывая, что cos ( П 4 ) ~ 0.707, получаем требуемую оценку:
e - e ′ < 0.7.
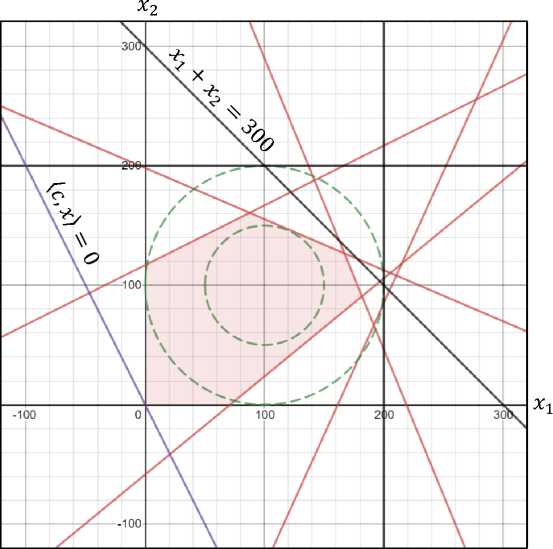
Рис. 1. Случайная задача линейного программирования для n = 2, d = 5, a = 200,0 = 100, p = 50, Smin = 100, Lmax = 0.35, amax = 1000, bmax = 10000 (нарисовано с помощью графического калькулятора Desmos [14])
На рис. 1 представлена случайная задача, сгенерированная программой FRaGenLP в соответствии с выше описанным методом для размерности n = 2 с использованием следующих значений параметров: d = 5 , a = 200 , θ = 100 , ρ = 50, Smin = 100 , Lmax = 0.35 , amax = 1000 , bmax = 10000 . Фиолетовым цветом на рисунке обозначена прямая, определяемая коэффициентами целевой функции; черными линиями обозначены прямые, соответствующие опорным неравенствам; красными линиями обозначены прямые, соответствующие случайным неравенствам. Для наглядности на рисунке также обозначены зелеными пунктирными линиями большая и малая окружности, задаваемые уравнениями ( x 1 - 100 ) 2 + ( x 2 - 100 ) 2 = 100 2 и ( x 1 - 100 ) 2 + ( x 2 - 100 ) 2 = 50 2 соответственно. Любая случайная прямая должна пересекать большую окружность и не пересекать малую окружность в соответствии с условием (12). Полупрозрачным красным цветом выделена область допустимых точек получившейся задачи линейного программирования.
Алгоритм 1. Последовательный алгоритм генерации случайной задачи ЛП
-
1: input n, d, ct, 6,p, S m / n , L max , ci max , b max
-
2: k := 0
-
3: A:=[]
-
4: B:=[]
-
5: AddSupport(A, B)
-
6: for j = n ... 1 do C j := 6 ■ j
-
7: if d = 0 goto 20
-
8: for j = 1 .n do a j := rsign() ■ rand(0, a max )
-
9: b := rsign( ) ■ rand(0, b max )
-
10: if (a, h cntr) < b goto 13
-
11: for j = 1 ...n do a j := —a j
-
12: b :=—b
-
13: if dist(a,b,h cntr ) < p or dist(a, b, h cntr ) > 6 goto 8
-
14: if /(n(h c„tr ,ai,bi)) >/(h c„tr ) goto 8
-
15: for all (d, S) £ (A,B) do if Hke(a,b,d/b) goto 8
-
16: A:=A*a
-
17: B:=B*b
-
18: k:=k + 1
-
19: if k < d goto 8
-
20: output A, B, c 21: stop
-
2. Параллельный алгоритм генерации случайных задач ЛП
Неявные циклы с возвратом на метку 8, возникающие на шагах 13–15 алгоритма 1, могут потребовать значительных временных затрат. Так, при генерации задачи ЛП, представленной на рис. 1, возвраты на метку 8 осуществлялись 112581 раз с шага 13, 32771 раз с шага 14, и 726 раз с шага 15. В силу этого генерация большой случайной задачи ЛП на обычном персональном компьютере может длиться несколько суток. Поэтому нами
-
3. Программная реализация и вычислительные
Описанный метод представлен в виде последовательного алгоритма 1. На шаге 1 вводятся параметры алгоритма. На шаге 2 счетчику случайных неравенств присваивается значение 0. На шаге 3 формируется пустой список строк матрицы A . На шаге 4 формируется пустой список строк свободных членов B . На шаге 5 в списки A и B добавляются коэффициенты и свободные члены опорных неравенств (1). На шаге 6 проверяется количество случайных неравенств d : если d = 0 , то происходит вывод только опорных неравенств, после чего алгоритм заканчивает свою работу. На шаге 7 генерируются коэффициенты целевой функции в соответствии с формулой (3). На шагах 8 и 9 генерируются коэффициенты и свободный член нового случайного неравенства. На шаге 10 проверяется условие (11). Если это условие не верно, то знаки коэффициентов и свободного члена меняются на противоположные (шаги 11, 12). На шаге 13 проверяется условие (12). На шаге 14 проверяется условие (13). На шаге 15 проверяется условие (14). На шаге 16 коэффициенты нового случайного неравенства добавляются в матрицу A . На шаге 17 свободный член нового случайного неравенства добавляется в столбец B . На шаге 18 счетчик неравенств увеличивается на единицу. На шаге 19 проверяется, достигло ли количество неравенств требуемого числа, и, при необходимости, осуществляется переход к следующей итерации. На шаге 20 происходит вывод результатов. Шаг 21 завершает работу алгоритма.
Алгоритм 2. Параллельный алгоритм генерации случайной задачи ЛП
Сначала рассмотрим шаги, выполняемые узлом-мастером. На шаге M1 мастер считывает параметры задачи. На шаге M2 счетчику случайных неравенств присваивается значение 0. В параллельной версии опорные и случайные неравенства хранятся в разных списках. На шагах M3 и M4 мастер создает пустые списки AS и BS для коэффициентов и свободных членов опорных неравенств. На шаге M5 в эти списки добавляются опорные неравенства (1). На шаге M6 генерируются коэффициенты целевой функции в соответствии с формулой (3). На шагах M7 и M8 создаются пустые списки AR и BR для коэффициентов и свободных членов случайных неравенств. На шаге M9 проверяется количество случайных неравенств d : если d ≤ 0 , то происходит вывод только опорных неравенств (шаг M10), после чего мастер заканчивает свою работу (переход с шага M11 на шаг M37). Если d > 0 , то мастер продолжает свою работу. На шаге M19 мастер получает по одному случайному неравенству от всех рабочих. Рабочие обеспечивают для своих неравенств выполнение свойств (11)–(13) и проверяют их похожесть на все опорные неравенства. Мастер в цикле M20–M33 проверяет все поступившие случайные неравенства на похожесть с ранее включенными в списки AR и BR случайными неравенствами (вложенный цикл M22–M27). Если обнаруживается похожее случайное неравенство (шаги M23– M26), то новое неравенство игнорируется, и осуществляется переход к проверке следующего поступившего неравенства (шаг M28). Если похожих неравенств не нашлось, новое случайное неравенство добавляется мастером в списки AR , BR (шаги M29, M30), и счетчик случайных неравенств увеличивается на единицу (шаг M31). Если количество неравенств достигло заданного значения (шаг M32), то происходит выход из внешнего цикла, в противном случае проверки продолжаются. После завершения проверок и добавлений поступивших случайных неравенств мастер рассылает всем рабочим общее количество случайных неравенств, включенных в систему на данный момент (шаг M34). Если это количество не достигло требуемого, то происходит переход к следующей глобальной итерации (шаг M35), в противном случае мастер выводит результаты и завершает свою работу (шаги M36, M37).
Теперь рассмотрим шаги, выполняемые l-м рабочим . На шаге W1 рабочий считывает параметры задачи. На шаге W2 проверяется количество случайных неравенств d : если d ≤ 0 , то рабочий немедленно заканчивает свою работу, в противном случае создаются пустые списки A S и B S для коэффициентов и свободных членов опорных неравенств (шаги W3, W4). На шаге W5 в эти списки добавляются опорные неравенства (1). На шагах W6–W9 рабочий генерирует новое случайное неравенство. На шаге W10 проверяется условие (11). Если это условие не верно, то знаки коэффициентов и свободного члена сгенерированного неравенства меняются на противоположные (шаги W11, W12). Шаги W13– W15 проверяют условия (12), (13). Шаги W16–W18 проверяют похожесть сгенерированного неравенства на опорные неравенства с использованием формулы (14). Если хотя бы одно из этих условий не выполняется, осуществляется переход на шаг W6 для повторной генерации нового случайного неравенства. Если все указанные условия выполнены, рабочий пересылает мастеру построенное случайное неравенство (шаг W19). После этого рабочий ждет, когда мастер пришлет ему новое значение счетчика случайных неравенств k (шаг W34). Если k меньше заданного количества случайных неравенств d , то происходит переход на шаг W6 для генерации следующего случайного неравенства (шаг W35), в противном случае рабочий завершает свою работу (шаг W37).
эксперименты
Параллельный алгоритм 2 был нами реализован на языке C++ с использованием параллельного BSF-каркаса [17, 18]. BSF-каркас базируется на модели параллельных вычислений BSF [15] и инкапсулирует в проблемно независимой части своего кода все аспекты, связанные с распараллеливанием программы с помощью библиотеки MPI [19]. BSF-каркас требует преобразования алгоритма в форму, работающую со списками с использованием функций высшего порядка Map и Reduce , определяемых формализмом Бирда—Миртенса (Bird–Meertens formalism) [20]. Это преобразование было сделано следующим образом. Длина списков Map и Reduce устанавливалась равной количеству рабочих MPI-процессов. Элементы списка Map определялись как пустые структуры:
struct PT_bsf_mapElem_T {}.
Каждый элемент списка Reduce хранил коэффициенты и свободный член одного случайного неравенства a , x ≤ b :
struct PT_bsf_reduceElem_T {float a[u]; float b}.
Каждый рабочий MPI-процесс генерировал по одному случайному неравенству с помощью функции PC_bsf_MapF, которая включала в себя шаги W6–W18 алгоритма 2. Неравенство, удовлетворяющее всем условиям, записывалось рабочим в локальный список Reduce, состоящий из одного элемента. Мастер получал от каждого рабочего сгенерированные элементы и помещал их в свой список Reduce (это выполнялось проблемно-независимой частью BSF-каркаса). Полученные элементы вручную проверялись на похожесть с ранее добавленными случайными неравенствами и, при отсутствии конфликтов, добавлялись в списки AR, BR. Указанная обработка (шаги M20–M33) была нами реализована в предопределенной функции PC_bsf_ProcessResults. Исходные коды параллельной программы FRaGenLP свободно доступны в сети Интернет по адресу
С использованием указанной программы нами были проведены масштабные вычислительные эксперименты на вычислительном кластере «Торнадо ЮУрГУ» [21], характеристики которого приведены в табл. 1. Вычисления проводились для размерности n , равной 3 000, 5 500 и 15 000. Количество неравенств, соответственно, составляло 6 301, 10 001 и 31 501. Из них случайных: 300, 500, 1500 соответственно. Во всех экспериментах были установлены следующие значения параметров, введенных в разделе 1: длина ребра ограничивающего гиперкуба α = 200 , радиус большой гиперсферы θ = 100 , радиус малой гиперсферы ρ = 50 , верхняя граница «почти параллельности» для гиперплоскостей L max = 0.35 , минимальная допустимая близость для гиперплоскостей S min = 100 , максимальное допустимое абсолютное значение при генерации коэффициентов случайных неравенств a max = 1000 , максимальное допустимое абсолютное значение при генерации правых частей случайных неравенств b max = 10000 . Результаты экспериментов представлены на рис. 2. Время генерации случайной задачи ЛП с 31501 ограничениями на конфигурации из одного узла-мастера и одного узла-рабочего составило 12 минут. На конфигурации из одного узла-мастера и 170 узлов-рабочих генерация такой же задачи заняла 22 секунды. Анализ результатов показывает, что граница масштабируемости предложенного алгоритма существенно зависит от размерности задачи (под границей масштабируемости здесь понимается максимум кривой ускорения). При n = 3000 граница масштабируемости составила приблизительно 50 процессорных узлов. Для задачи размерности n = 5000 эта
Таблица 1. Характеристики кластера «Торнадо ЮУрГУ»
|
Количество процессорных узлов |
480 |
|
Процессоры |
Intel Xeon X5680 (6 cores 3.33 GHz) |
|
Количество процессоров в узле |
2 |
|
Оперативная память узла |
24 GB DDR3 |
|
Соединительная сеть |
InfniBand QDR (40 Gbit/s) |
|
Операционная система |
Linux CentOS |
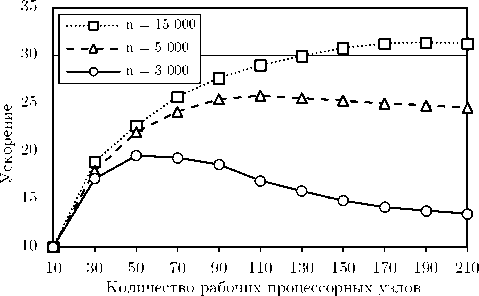
Рис. 2. Графики ускорения алгоритма FRaGenLP для различных размерностей
граница увеличилась до 110 узлов, а на задаче размерности n = 15000 она достигла 200 узлов. Дальнейшее увеличение размерности задачи приводило к нехватке оперативной памяти на процессорных узлах. Следует отметить, что граница масштабируемости предложенного алгоритма также существенно зависит от количества случайных неравенств. Увеличение этого числа в 10 раз приводило к двукратному уменьшению границы масштабируемости. Это объясняется тем, что при увеличении количества узлов-рабочих значительно возрастала доля последовательных вычислений, выполняемых узлом-мастером на шагах M20–M27, в течение которых узлы-рабочие простаивали.
Заключение
В данной работе представлен параллельный алгоритм FRaGenLP для генерации случайных совместных ограниченных задач ЛП на кластерных вычислительных системах. Генерируемые системы ограничений наряду со случайными неравенствами включают в себя стандартный набор неравенств, называемых опорными. Опорные неравенства гарантируют ограниченность допустимой области задачи ЛП. С геометрической точки зрения допустимая область опорных неравенств представляет собой гиперкуб, прилежащий к осям координат, у которого срезана дальняя от центра координат вершина. Целевая функция задается определенным образом, так, чтобы ее коэффициенты монотонно убывали. Коэффициенты и свободные члены случайных неравенств генерируются с помощью датчика случайных чисел. Если допустимая область сгенерированного случайного неравенства не включает в себя центр ограничивающего гиперкуба, то знак неравенства меняется на противоположный. Однако не всякое случайное неравенство включается в систему. Отклоняются случайные неравенства, которые не могут повлиять на решение задачи ЛП при заданной целевой функции. Также отклоняются все неравенства, для которых ограничивающая гиперплоскость пересекает малую гиперсферу, расположенную в центре ограничивающего гиперкуба (это гарантирует совместность). Кроме того, отклоняется всякое случайное неравенство, «похожее» на хотя бы одно неравенство, уже добавленное в систему (включая опорные). Для определения «похожести» неравенств введены две формальные метрики: почти параллельности и близости соответствующих им гиперплоскостей. Параллельный алгоритм спроектирован на базе модели параллельных вычислений BSF, использующей парадигму «мастер-рабочий». В соответствии с этой моделью узел-мастер является центром управления и коммуникации. Все узлы-рабочие выполняют один и тот же код, но над разными данными. Параллельная реализация выполнена на языке C++ с использованием параллельного BSF-каркаса, инкапсулирующего в проблемно независимой части своего кода все аспекты, связанные с распараллеливанием программы с помощью библиотеки MPI. Исходные коды разработанной параллельной программы свободно доступны в сети Интернет по адресу С использованием этой реализации были проведены масштабные вычислительные эксперименты на кластерной вычислительной системе. Проведенные эксперименты показали, что алгоритм FRaGenLP демонстрирует для размерности 15 000 хорошую масштабируемость вплоть до 200 процессорных узлов. Случайная задача ЛП, включающая в себя 31 501 неравенство, была сгенерирована на конфигурации из 171 процессорного узла за 22 секунды. На одном процессорном узле для этого потребовалось 12 минут. Разработанную программу предполагается использовать для генерации 70 000 образцов для обучения искусственной нейронной сети, способной быстро решать большие задачи ЛП.
Исследование выполнено при финансовой поддержке РФФИ (проект № 20-07-00092-а) и Министерства науки и высшего образования РФ (государственное задание FENU-2020-0022).
Список литературы О генерации случайных задач линейного программирования на кластерных вычислительных системах
- Jagadish H.V. et al. Big data and its technical challenges // Communications of the ACM. 2014. Vol. 57, no. 7. P. 86-94. DOI: 10.1145/2611567.
- Hartung T. Making Big Sense From Big Data // Frontiers in Big Data. 2018. Vol. 1. P. 5. DOI: 10.3389/fdata.2018.00005.
- Соколинская И.М., Соколинский Л.Б. О решении задачи линейного программирования в эпоху больших данных // Параллельные вычислительные технологии (ПаВТ'2017): Труды XI международной научной конференции (Казань, 3-7 апреля 2017 г.). Короткие статьи и описания плакатов. Челябинск: Издательский центр ЮУрГУ, 2017. С. 471-484.
- Соколинский Л.Б., Соколинская И.М. Исследование масштабируемости апекс-метода для решения сверхбольших задач линейного программирования на кластерных вычислительных системах // Суперкомпьютерные дни в России: Труды международной конференции (Москва, 21-22 сентября 2020 г.). Москва: МАКС Пресс, 2020. C. 49-59.
- Mamalis B., Pantziou G. Advances in the Parallelization of the Simplex Method // Algorithms, Probability, Networks, and Games. Lecture Notes in Computer Science. Cham: Springer, 2015. Vol. 9295. P. 281-307. DOI: 10.1007/978-3-319-24024-4_17.
- Huangfu Q., Hall J.A.J. Parallelizing the dual revised simplex method // Mathematical Programming Computation. Springer Verlag, 2018. Vol. 10, no. 1. P. 119-142. DOI: 10.1007/s12532-017-0130-5.
- Tar P., Stagel B., Maros I. Parallel search paths for the simplex algorithm // Central European Journal of Operations Research. Springer Verlag, 2017. Vol. 25, no. 4. P. 967984. DOI: 10.1007/s10100-016-0452-9.
- Yang L., Li T., Li J. Parallel predictor-corrector interior-point algorithm of structured optimization problems // 3rd International Conference on Genetic and Evolutionary Computing, WGEC 2009. 2009. P. 256-259. DOI: 10.1109/WGEC.2009.68.
- Gay D.M. Electronic mail distribution of linear programming test problems // Mathematical Programming Society COAL Bulletin. 1985. no. 13. P. 10-12.
- Charnes A. et al. On Generation of Test Problems for Linear Programming Codes // Communications of the ACM. 1974. Vol. 17, no. 10. P. 583-586. DOI: 10.1145/355620.361173.
- Arthur J.L., Frendewey J.O. GENGUB: A generator for linear programs with generalized upper bound constraints // Computers and Operations Research. Pergamon, 1993. Vol. 20, no. 6. P. 565-573. DOI: 10.1016/0305-0548(93)90112-V.
- Castillo E., Pruneda R.E., Esquivel Mo. Automatic generation of linear programming problems for computer aided instruction // International Journal of Mathematical Education in Science and Technology. Taylor & Francis Group, 2001. Vol. 32, no. 2. P. 209-232. DOI: 10.1080/00207390010010845.
- Dhiflaoui M. et al. Certifying and Repairing Solutions to Large LPs How Good are LP-solvers? // SODA '03: Proceedings of the fourteenth annual ACM-SIAM symposium on Discrete algorithms. USA: Society for Industrial and Applied Mathematics, 2003. P. 255256.
- Desmos Graphing Calculator. URL: https://www.desmos.com/calculator (дата обращения: 09.03.2021).
- Sokolinsky L.B. BSF: A parallel computation model for scalability estimation of iterative numerical algorithms on cluster computing systems // Journal of Parallel and Distributed Computing. 2021. Vol. 149. P. 193-206. DOI: 10.1016/j.jpdc.2020.12.009.
- Sahni S., Vairaktarakis G. The master-slave paradigm in parallel computer and industrial settings // Journal of Global Optimization. 1996. Vol. 9, no. 3-4. P. 357-377. DOI:10.1007/BF00121679.
- Sokolinsky L.B. BSF-skeleton. User manual: arXiv:2008.12256 [cs.DC]. 2020. 22 p.
- Sokolinsky L.B. BSF-skeleton. 2019. URL: https://github.com/leonid-sokolinsky/BSF-skeleton (дата обращения: 09.03.2021).
- Gropp W. MPI 3 and Beyond: Why MPI Is Successful and What Challenges It Faces // Recent Advances in the Message Passing Interface. EuroMPI 2012. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2012. Vol. 7490. P. 1-9. DOI: 10.1007/978-3-642-33518-1_1.
- Bird R.S. Lectures on Constructive Functional Programming // Constructive Methods in Computing Science. NATO ASI Series F: Computer and Systems Sciences. Berlin, Heidlberg: Springer, 1988. Vol. 55. P. 151-216.
- Kostenetskiy P.S., Safonov A.Y. SUSU Supercomputer Resources // Proceedings of the 10th Annual International Scientific Conference on Parallel Computing Technologies (PCT 2016). CEUR Workshop Proceedings. Vol. 1576. 2016. P. 561-573.
