О проекционном методе линейного программирования

Автор: Леонид Борисович Соколинский, Александр Эдуардович Жулев, Ирина Михайловна Соколинская
Статья в выпуске: 1 т.15, 2026 года.
Бесплатный доступ
В статье рассматривается проблема разработки эффективных методов проекционного типа для решения задач линейного программирования (ЛП). Предложен новый гибридный проекционный алгоритм HAlEM (Hybrid Along Edges Movement), сочетающий идеи проекционного подхода и симплекс-метода. Алгоритм начинает работу из произвольной вершины многогранника допустимых решений и осуществляет движение вдоль его ребер к оптимальной вершине. Для вычисления направления движения используется оригинальный метод двух-факторной проекции, обеспечивающий высокую вычислительную точность для любых задач ЛП. Основным преимуществом HAlEM перед предшествующими разработками (AlFaMove, AlEM) является отказ от комбинаторного перебора всех возможных комбинаций гиперплоскостей за счет использования техники обновления матричного базиса, заимствованной из симплекс-метода. Это позволяет избежать экспоненциальной вычислительной сложности. В статье представлена параллельная версия алгоритма, основанная на модели параллельных вычислений BSF и схеме «мастер-рабочие», позволяющих получить эффективную реализацию для суперкомпьютерных систем кластерного типа. Проведены вычислительные эксперименты на эталонных задачах из репозитория Netlib-LP и на серии параметризованных задач. Результаты экспериментов демонстрируют, что HAlEM, в отличие от симплекс-метода, обладает более высоким ресурсом параллелизма, позволяя эффективно использовать до нескольких десятков процессорных узлов, и показывает хорошую масштабируемость с параллельной эффективностью не ниже 51%. При этом алгоритм обеспечивает высокую точность вычислений на уровне машинного нуля.
Линейное программирование, алгоритм HAlEM, проекционный метод, параллельная реализация, MPI, кластерная вычислительная система, исследование масштабируемости, Netlb-LP
Короткий адрес: https://sciup.org/147253967
IDR: 147253967 | УДК: 519.852, 514.172.45, 519.168 | DOI: 10.14529/cmse260101
On Projection Method of Linear Programming
The paper addresses the problem of developing efficient projection-type methods for linear programming (LP). A new hybrid projection algorithm called HAlEM (Hybrid Along Edges Movement) is proposed, combining ideas from the projection approach and the simplex method. The algorithm starts from an arbitrary vertex of the feasible solution polytope and moves along its edges toward the optimal vertex. An original two-factor projection method is used to compute the direction of movement, ensuring high computational accuracy for any LP problem. The main advantage of HAlEM over previous projection algorithms (AlFaMove, AlEM) is its avoidance of exhaustive combinatorial enumeration of all possible combinations of hyperplanes by employing a matrix basis update technique borrowed from the simplex method. This allows one to circumvent exponential computational complexity. The paper presents a parallel version of the algorithm based on the BSF parallel computing model and a master-worker scheme, enabling an efficient implementation for cluster-type supercomputer systems. Computational experiments were conducted on benchmark problems from the Netlib-LP repository and on a series of parameterized problems. The experimental results demonstrate that HAlEM, unlike the simplex method, possesses a higher degree of parallelism, allowing the efficient use of up to several dozen processor nodes, and exhibits good scalability with parallel efficiency not falling below 51%. Furthermore, the algorithm provides high computational accuracy at the level of machine epsilon.
Текст научной статьи О проекционном методе линейного программирования
Линейное программирование (ЛП) [1, 2] является одной из самых востребованных математических моделей для решения задач оптимизации в индустрии, экономике, науке и многих других сферах человеческой деятельности [3 –6] . Основным методом решения задач ЛП на практике является симплекс-метод [7] , позволяющий эффективно решать широкий класс оптимизационных задач с числом неизвестных до 50 000 [8] . Однако симплекс-методу присущ ряд недостатков, среди которых выделим следующие. Во-первых, симплекс-метод в общем случае характеризуется ограниченной масштабируемостью и не допускает эффективного распараллеливания более чем на 32 процессорных узлах [9] . Во-вторых, симплекс-метод может зацикливаться на вырожденных задачах ЛП [10] , что не гарантирует его сходимость к решению [11, 12] . Поэтому остается актуальной задача разработки альтернативных эффективных методов ЛП, свободных от указанных недостатков. Одной из таких альтернатив являются методы проекционного типа, строящие на поверхности многогранника допустимых решений путь к оптимальной точке.
Идея проекционного метода чрезвычайно проста. Пусть в евклидовом пространстве \BbbRn задана задача ЛП стандартного вида arg max {(c,x) | Ax < b, x ^ 0} с ограниченной областью допу лый многогранник M . Старту проекционный метод вычисля z = v0 + 5ec, где \bfite\bfitc — единичный вектор, с вещественное число (см. рис. 1)
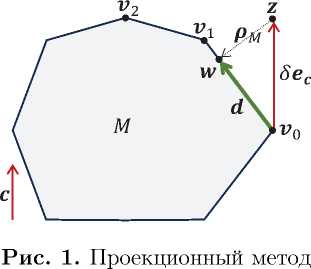
на многограннике M точку \bfitw :
w = pm (z) .
Выбор числа \delta должен гарантировать, что \bfitw будет на той же грани, что и \bfitu . Далее вычисляется направляющий вектор d = w — Г о , который позволяет получить следующее приближение \bfitv 1 :
v 1 = argmax{||x — v 0 | | x = Ad + v 0 , A G R > 0 , x G M } .
Выполняя аналогичные действия для \bfitv 1 , получим приближение \bfitv 2 . Процесс заканчивается на k-том приближении, для которого
Pm ( v k + 5e c ) = V k .
На рис. 1 этой ситуации соответствует точка \bfitv 2 . Таким образом получаем решение задачи ЛП.
В работе [13] описан апекс-метод решения задачи ЛП, реализующий этот подход в виде итерационного численного алгоритма. Для приближенного вычисления метрической проекции на выпуклый многогранник M апекс-метод использует M -фейеровское отображение ф м : R n ^ R n , характеризующееся тем, что образ ф м (x) любой точки x G M будет ближе к многограннику M, чем \bfitx :
-
V x /M, Ч у G M : |Hx) — у | < | x — у ^.
Многократно применяя фейеровское отображение к произвольной внешней точке \bfitx (0) \in / M , мы получим точку на границе многогранника M , являющуюся некоторым приближением 6 Вестник ЮУрГУ. Серия «Вычислительная математика и информатика»
метрической проекции. Указанный фейеровский процесс называется псевдопроектированием, а получившаяся точка — псевдопроекцией. Хотя апекс-метод способен решать некоторые реальные задачи ЛП, он обладает двумя существенными недостатками. Первый недостаток заключается в том, что фейеровский процесс, используемый для приближенного вычисления метрической проекции, имеет низкую линейную скорость сходимости:
■'■ - ^M (ж(0))| ^ Cqk, где 0 < C < +ж — некоторая константа, а q G (0,1) — параметр, зависящий от углов между гиперплоскостями, соответствующими граням многогранника M . Это означает, что расстояние между соседними приближениями с каждой итерацией уменьшается в геометрической прогрессии с коэффициентом, меньше единицы. Для малых углов скорость сходимости может падать до значений, близких к нулю. Второй недостаток связан с ограничением на длину «выводящего» вектора \delta\bfite\bfitc : когда исходная граничная точка \bfitv находится близко к противоположному краю гран рическая проекция не оказала точность вычисления метриче
В работах [14, 15] предло для решения задачи ЛП предл ник, а на аффинное подпростр как это показано на рис. 2. В
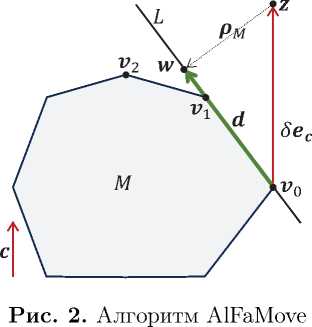
длину, что существенно увеличивает точность вычисления направляющего вектора \bfitd. Для любой грани многогранника M существует комбинация гиперплоскостей из системы ограничений задачи ЛП, пересечением которых будет аффинное подпространство L, образующее эту грань. В соответствии с этим алгоритм AlFaMove перебирает все возможные комбинации гиперплоскостей, проходящих через точку V o - Для каждой комбинации вычисляется свой направляющий вектор \bfitd. Отбрасываются комбинации, для которых луч X = { ж G К | ж = V o + X d , А € К ^ о } имеет с допустимым многогранником M только одну общую точку, являющуюся его начальной точкой V o - Для каждой оставшейся комбинации вычисляется точка \bfitv nex t по формуле
V next = V o +
b i * — ( a i * , V o )
\langle \bfita i \ast , \bfitd \rangle \bfitd
(i)
где
i e Arg min i \langle\bfitai, \bfitd\rangle
{ a i , d } > c| ,
(ii)
i пробегает строки матрицы A. В качестве следующего приближения \bfitv 1 из всех полученных точек \bfitv next выбирается та, в которой достигается наибольшее значение целевой функции. Повторяя описанные действия, алгоритм AlFaMove за конечное число итераций придет в допустимую точку с максимальным значением целевой функции. Основным недостатком этого подхода является необходимость комбинаторного перебора возможных комбинаций гиперплоскостей, проходящих через точку текущего приближения. Если через точку проходит k гиперплоскостей, то количество комбинаций будет равно 2 k . Таким образом, алгоритм AlFaMove имеет экспоненциальную вычислительную сложность. Это делает затруднительным его применение даже в случае простых многограннико в1 размерности больше 30. Также отметим, что для вычисления метрической проекции алгоритм AlFaMove по-прежнему использует медленные фейеровские процессы.
В недавней работе [16] предложен новый проекционный алгоритм ЛП, получивший название AlEM (Along Edges Movement). В отличие от алгоритма AlFaMove, алгоритм AlEM начинает свою работу в произвольной вершине многогранника допустимых решений и двигается к оптимальной вершине только по ребрам. Для любого ребра существует n — 1 гиперплоскостей из системы ограничений задачи ЛП, пересечением которых будет прямая, образующая это ребро. Если через вершину проходит k гиперплоскостей ( k \geqslant n ), то количество комбинаций может быть вычислено по следующей формуле:
C n-1 = _______к_______ k (n — 1)!(k — n + 1)
Для вычисления метрической проекции точки на прямую алгоритм AlEM вместо фейе-ровских отображений использует формулу ортогональной проекции на аффинное подпространство [17] , что оказывается несравненно более эффективным. Вычислительные эксперименты показали, что быстродействие алгоритма AlEM на задачах ЛП, область допустимых решений которых является простым многогранником, сравнимо с быстродействием симплекс-метода. Однако, в отличии от симплекс-метода, алгоритм AlEM допускает эффективное распараллеливание и исключает возможность зацикливания на вырожденных задачах. К сожалению, в реальных задачах ЛП количество гиперплоскостей, проходящих через вершины многогранника допустимых решений, существенно превышает размерность пространства, что приводит к необходимости комбинаторного перебора.
В этой статье мы предлагаем новый проекционный алгоритм HAlEM (Hybrid Along Edges Movement), который совмещает в себе свойства алгоритма AlEM и симплекс-метода. Принцип работы алгоритма HAlEM заключается в следующем. В начальной вершине \bfitv0 формируется матричный базис A0 из n линейно независимых строк матрицы A, соответствующих n гиперплоскостям, проходящим через Uq. Каждая комбинация из n — 1 таких гиперплоскостей определяет прямую, являющуюся результатом их пересечения. Всего получится n линейно независимых прямых, называемых реберными. Каждая реберная прямая проходит через ребро, инцидентное вершине \bfitv0 . С помощью ортогональной проекции для каждой реберной прямой вычисляется направляющий вектор \bfitd. Затем для всех реберных прямых с помощью формул (i), (ii) вычисляются точки \bfitvnext, являющиеся смежными вершинами по отношению к \bfitv0 . В качестве \bfitv1 выбирается та вершина, в которой достигается наибольшее значение целевой функции. На основе матричного базиса A0 формируется новый матричный базис A1 путем замены строки, не участвовавшей в формировании ребра перехода, на некоторую строку из матрицы A, соответствующую гиперплоскости, проходящей через вершину \bfitv1 , так, чтобы сохранялась линейная независимость матричного базиса A1 . Процесс продолжается до тех пор, пока не будет достигнута вершина, у которой отсутствуют ребра, ведущие к увеличению целевой функции. Эта вершина будет искомым решением задачи ЛП.
Статья организована следующим образом. Раздел 1 содержит обозначения, определения и утверждения, необходимые для описания алгоритма HAlEM и его численной реализации. В разделе 2 дается формализованное описание алгоритма HAlEM. Раздел 3 посвящен параллельной версии алгоритма HAlEM. В разделе 4 представлены информация о программной реализации алгоритма HAlEM и результаты вычислительных экспериментов. В заключении суммируются полученные результаты и намечаются направления дальнейших исследований. В конце статьи приводится сводка используемых математических обозначений.
1. Необходимые определения и утверждения
В этом разделе приводятся определения и утверждения, необходимые для формального описания алгоритма HAlEM.
В евклидовом пространстве R n размерности n > 1 имеется задача ЛП общего вида с системой из m ограничений, включающей в себя k линейных уравнений и m - k линейных неравенств:
( a i , ж ) = b i , .........
( a k , ж ) = b k ,
\langle \bfita k +1 , \bfitx \rangle \leqslant b k +1 ,
\bfita m , \bfitx \rangle \leqslant b m .
Здесь и далее \langle\ast , \ast\rangle обозначает скалярное произведение двух векторов. Предполагается, что система (1) включает в себя также неравенства вида
- x i < 0,
— x n < 0.
Необходимо найти точку в области допустимых решений системы (1) , в которой достигается максимум линейной целевой функции
F (ж) = ( с, ж ) .
Для J = {j i ,. .. ,j q } C { 1,..., m } , | J | = q > 0 определим матрицу
\bfitaj1
A j =
.
.
.
\bfitajq и столбец bj1
bj = bj
Обозначим через I множество индексов уравнений системы (1) , и через I — множество индексов неравенств системы (1) :
_
I = { 1,...,k } ,
I = {k + 1,..., m}.
Тогда систему ограничений (1) можно представить в матричном виде
A i x = b j , A f X < b j .
Без ограничения общности мы можем считать, что матрица A j имеет полный ранг:
rank (A j ) = k. (3)
Мы также будем полагать, что k < n, так как в противном случае область допустимых решений вырождается в точку.
Известно, что область допустимых решений системы (1) представляет собой замкнутый выпуклый многогранник
M = {x E ^n^Ajx = bj, AjX < bj} , называемый допустимым. Мы будем предполагать, что допустимый многогранник M является ограниченным множеством. В этом случае задача ЛП всегда имеет решение. Поскольку система (1) включает в себя неравенства (2), то из ограниченности допустимого многогранника M следует, что общее число неравенств должно превышать размерность пространства:
m - k > n.
Каждому индексу i \in I \cup I соответствует гиперплоскость
H i = { x E R n | ( a i , x ) = b i } .
В совокупности эти гиперплоскости образуют грани допустимого многогранника M .
Определение 1. Пусть точка \bfitv является вершиной допустимого многогранника M . Базисным индексом вершины \bfitv будем называть множество индексов \scrV , удовлетворяющее сле-10 Вестник ЮУрГУ. Серия «Вычислительная математика и информатика»
дующим условиям:
VC I,(6)
M = n - k,(7)
Vi eV : (щ, v) = bi,(8)
rank (A/uv) = n.(9)
Квадратную матрицу А / иу размера n х n будем называть базисной.
С геометрической точки зрения это означает, что пересечение гиперплоскостей, соответствующих строкам базисной матрицы А/ иу , образует вершину v:
{ v } = П H j .
j e i uv
Базисная матрица A j .y задает n — к различных реберных прямы х2, проходящих через вершину \bfitv :
V i eV : L i = П H j , (10)
j г г где
£ i = V\{i}.
Множество индексов \scrE i , однозначно определяющих i -тую реберную прямую, будем называть реберным индексом. Реберную прямую L i ( i \in I \cup \scrV ) удобно представлять в параметрическом виде
L i = { x e R n | x = v + X d , X e R } .
Направляющий вектор \bfitd \in \BbbR n можно получить следующим образом. Выберем произвольный ненулевой «выводящий» вектор \bfitg , не являющийся ортогональным по отношению к прямой L i , и вычислим вторую точку w = v на прямой L i :
w = “ I .- ( v + 9 )
Здесь “=.£. (*) обозначает ортогональную проекцию на подпространство3 Q Hj, образу-j г г ющее реберную прямую Li в соответствии с формулой (10). Ортогональная проекция на подпространство вычисляется через псевдообратную матрицу по известной формуле [17]:
“ю г . ( x ) = x — A T u- i ( A i . - A T u- i ) ( A / uf i x — b I u£ i ) ■
Заметим, что матрица A = и£, имеет полнострочный ранг в силу того, что базисная матрица A = uv имеет полный ранг и £ i С V . Поэтому матрица A = и£. A T является обратимой (см.
i I cupscrEi утверждение 3F в [18]). В итоге получаем искомый направляющий вектор d = w — v.
Следующие утверждения понадобятся нам для выполнения прохода по ребру от одной вершины к другой.
Утверждение 1. [16] Пусть в контексте системы ограничений (1) заданы точка \bfitv \in M, произвольный вектор \bfitd \in \BbbR n и полупространство
Pi = {x £ ^nl(ai, x) < bi} , ограниченное гиперплоскостью
Hi = {x £ Kn| X = {x £ Rn|x = v + Ad, A £ R^o} • Тогда если (ai, d) < 0, то X C Pi, (12) если (ai, d) > 0, то X П Hi = iv + bi - v) d] . (13) \langle\bfitai, \bfitd\rangle Другими словами, луч, исходящий из принадлежащей допустимому многограннику M точки \bfitv в направлении \bfitd, пересечет гиперплоскость Hi в том и только в том случае, когда (ai, d) > 0. При этом точка пересечения может быть вычислена по формуле (13). Утверждение 2. Пусть в контексте системы ограничений (1) заданы точка \bfitv \in M и вектор \bfitd \in \BbbRn такой, что Vi £ I : (ai, d) = 0. (14) Определим луч, исходящий из точки \bfitv в направлении вектора \bfitd: X = {x £ Rn|x = v + Ad, A £ R^o} . (15) Тогда X П M = {x £ Rn|x = Av + (1 - A)q, 0 < A < 1} , где q = v + yd, bi - \langle\bfitai, \bfitv\rangle У = mln \langle\bfitai, \bfitd\rangle i £ I, (ai, d} > 01 . Другими словами, пересечение луча X и допустимого многогранника M представляет собой отрезок между точками \bfitv и \bfitq, где \bfitq вычисляется по формулам (16) и (17). Доказательство. Прежде всего удостоверимся, что точка \bfitq, вычисляемая по формуле (16), принадлежит лучу X. Поскольку v £ M, то для всех i £ I справедливо \langle\bfitai, \bfitv\rangle \leqslant bi. Это равносильно bi - (ai, v) > 0. Следовательно, bi - \langle\bfitai, \bfitv\rangle если (ai, d) > 0, то — ---—— > 0. (18) \langle\bfitai, \bfitd\rangle С учетом (17) отсюда получаем 7 ^ 0. В соответствии с (15) и (16) это означает, что точка \bfitq принадлежит лучу X. Теперь нужно удостовериться, что точка \bfitq принадлежит допустимому многограннику M. Сначала покажем, что точка \bfitq, вычисляемая по формуле (16), удовлетворяет всем уравнениям системы ограничений (1). Возьмем произвольное i \in I и покажем, что \bfitq удовлетворяет уравнению (ai, ж) = bi. (19) Так как \bfitv \in M , имеем (ai, v) = bi. (20) Подставляя \bfitq в левую часть неравенства (19) вместо \bfitx, с учетом (14), (16) и (20) получаем: (ai, q) = (ai, v + 7d) = (ai, v) + 7(ai, d) = (ai, v) = bi. То есть, \bfitq удовлетворяет уравнению (19). Теперь покажем, что точка \bfitq, вычисляемая по формулам (16) и (17), удовлетворяет всем неравенствам системы ограничений (1). Возьмем произвольное i G I и покажем, что \bfitq удовлетворяет неравенству \langle\bfitai, \bfitq\rangle \leqslant bi.(21) Сначала предположим, что выполняется условие (ai, d) < 0. В этом случае, в соответствии с (12), все точки луча X, включая \bfitq, принадлежат полупространству Pi. Следовательно, \bfitq удовлетворяет неравенству (21). Теперь предположим, что выполняется условие (ai, d) > 0. Согласно (13) луч X пересекает гиперплоскость Hi в точке bi - \langle\bfitai, \bfitv\rangle v + \langle\bfitai, \bfitd\rangle Это означает, что bi - \langle\bfitai, \bfitv\rangle ( ai, v +-------—d ) = bi. \langle\bfitai, \bfitd\rangle Отсюда получаем bi - \langle\bfitai, \bfitv\rangle (ai, v) +------—— (ai, d) = bi. \langle\bfitai , \bfitd\rangle С учетом (17), (18) и (23) из последней формулы следует (ai, v) + 7 (ai, d) < bi, что равносильно (ai, v + 7d) < bi. Вместе с (16) это дает \langle\bfitai, \bfitq\rangle \leqslant bi. Таким образом, точка \bfitq, вычисляемая по формулам (16) и (17), принадлежит допустимому многограннику M . Поскольку M выпуклый, это означает, что весь отрезок между точками \bfitv и \bfitq принадлежит этому многограннику. Осталось убедиться, что точка \bfitq является граничной точкой допустимого многогранника M. Для этого достаточно показать, что для любого е > 0 точка q+ed не принадлежит M. В соответствии с (13), (16) и (17) существует i' G I такой, что (ai,, d} > 0 (24) и (ai,, v + 7 d} = bi,. Последнее равносильно (ai,, v) + 7 (ai,, d} = bi,. В силу (24) отсюда следует (ai,, v) + 7 (ai,, d) + e (ai,, d) > bi,, что эквивалентно (ai,, v + 7d + ed} > bi,. Таким образом, с учетом (16) получаем (ai,, q + ed} > bi,. Это означает, что точка q + ed не принадлежит полупространству Pi, и, следовательно, не принадлежит допустимому многограннику M . Утверждение доказано. Следствие 1. Пусть в контексте системы ограничений (1) имеется вершина \bfitv\prime\in M, являющаяся начальной точкой ребра, соответствующего реберной прямой L = {х G Kn ^ = v' + Xd,X G К} . Тогда вершина \bfitv\prime\prime\in M , являющаяся конечной точкой этого ребра, может быть вычислена по формуле v„ = v' + j -j^ d, (25) \langle\bfitaj\ast,\bfitd\rangle где j* G Arg min | j . ( 3. }j G I, (a3, d} > 0^ . (26) \langlebfitaj, \bfitd\rangle bigm| Гиперплоскость Hj\ast в этом случае называется ограничивающей по отношению к реберной прямой L. Утверждение 3. Пусть в контексте системы ограничений (1) имеется вершина \bfitv\prime\in M с базисным индексом \scrV\prime. Зафиксируем некоторый i\ast\in \scrV\prime. Ему соответствует реберная прямая Li\ast , вычисляемая по формуле Li- = Г) Hj. jeiuv '\{i-} Пусть также известен направляющий вектор \bfitd прямой Li\ast : Li- = {ж G лпт = v' + Xd, X G K} . (28) Пусть точка \bfitv\prime\primeявляется конечной вершиной рассматриваемого ребра. Положим J * = Arg min I bj—jll jeI, (aj, d) > o| . \langle\bfitaj , \bfitd\rangle \bigm| Тогда для любого j\ast\in J\astмножество V'' = (v' \{i*})u{j*} (30) будет являться базисным индексом для вершины \bfitv\prime\prime. Доказательство. Необходимо для вершины \bfitv\prime\primeпроверить выполнение условий (6)–(9) из определения 1. По построению очевидно, что выполняются условия (6) и (7). Проверим выполнение условия (8). В соответствии со следствием 1 имеем v'' = v' + bj\ast - \langle\bfitaj\ast, \bfitv\prime\rangle \langle\bfitaj\ast,\bfitd\rangle \bfitd Отсюда \bfitaj\ast v") = (j-,*, v' + j—j^LL d\ = (a-, v') + bj-j^l -j.,, d) = bj langle\bfitaj\ast,\bfitdrangle langle\bfitaj\ast,\bfitdrangle то есть, (a.-, r" = bj-. Таким образом, условие (8) также выполняется. Осталось проверить выполнение условия (9) для \bfitvprimeprime. Так как scrVprimeявляется базисным индексом для \bfitvprime, то в соответствии с (9) имеем rank (A/uV,) = n- Поскольку Aiuy> является квадратной матрицей размера n х n, отсюда получаем rank (Aiuv'\{i-}) = n-1- Предположим, что для \bfitvprimeprimeне выполняется условие (9). В сочетании с (32) это означает, что rank (A!u(V'\{i-})u{j-}) = n — 1- Согласно (27) в этом случае Вместе с (28) отсюда следует Vj e I и (у' \{i*}) U{j*} : {aj, d) =0. В частности, \langle\bfitaj \ast , \bfitd\rangle = 0. Получили противоречие с (29). Утверждение доказано.
2. Алгоритм HAlEM Данный раздел посвящен описанию алгоритма HAlEM, строящего из произвольной вершины \bfitv путь вдоль ребер допустимого многогранника M к вершине, в которой достигается максимум целевой функции задачи ЛП. Псевдокод HAlEM представлен в виде алгоритма 1. Поясним шаги алгоритма 1. На шаге 1 вводятся размерность пространства n, количество ограничений m, количество уравнений k в системе ограничений, матрица коэффициентов A и столбец свободных членов (правых частей) \bfitb системы ограничений, градиент \bfitc линейной целевой функции и координаты начальной вершины vg допустимого многогранника M. Эти данные являются глобальными в том смысле, что они доступны всем подпрограммам-функциям, используемым в алгоритме 1. Предполагается, что ограничения задачи ЛП приведены к виду (1). Также предполагается, что среди уравнений нет избыточных, то есть rank(Aj) = k, где к — число уравнений. Допускается случай, когда к = 0. Шаги 2 и 3 формируют множество индексов уравнений I и множество индексов неравенств I\^, составляющих систему ограничений (1). Шаг 4 с помощью функции \mathrm{B}\mathrm{a}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x} формирует базисный индекс Уд СI для начальной вершины Vg. Такой базисный индекс существует в силу (4). Псевдокод функции \mathrm{B}mathrm{a}mathrm{s}mathrm{i}mathrm{s}mathrm{I}\mathrm{n}\mathrm{d}mathrm{e}\mathrm{x} представлен в виде алгоритма 2. Шаг 5 устанавливает счетчик итераций t в значение 0. На шаге 6 логической переменной \ite\itx\iti\itt присваивается значение «ложь». Основной цикл repeat/until (шаги 7–36) выполняет последовательные переходы от вершины к вершине по ребрам допустимого многогранника, пока не будет достигнута оптимальная вершина. Один переход соответствует одной итерации этого цикла. Вложенный цикл loop (шаги 8–35) выполняет переход от вершины \bfitvt к следующей вершине vt+i с большим значением целевой функции. На шаге 9 точке V* присваиваются координаты текущей вершины \bfitvt. Следующий за этим цикл for all (шаги 10–22) находит для текущей вершины \bfitvt ребро с индексом i\ast , ведущее к вершине \bfitv\ast с наибольшим значением целевой функции среди всех ребер с индексами из \scrVt. Прокомментируем шаги в теле этого цикла. Шаг 11 с помощью функции \mathrm{D}mathrm{i}mathrm{r}mathrm{e}mathrm{c}mathrm{t}mathrm{i}mathrm{o}\mathrm{n}\mathrm{V}mathrm{e}mathrm{c}mathrm{t}mathrm{o}mathrm{r} вычисляет направляющий вектор \bfitd текущей реберной прямой Li в направлении увеличения целевой функции. Псевдокод функции \mathrm{D}mathrm{i}mathrm{r}mathrm{e}mathrm{c}mathrm{t}mathrm{i}mathrm{o}\mathrm{n}\mathrm{V}mathrm{e}mathrm{c}mathrm{t}mathrm{o}mathrm{r} представлен ниже в виде алгоритма 3. Оператор if на шаге 12 проверяет выполнение условия \bfitd = \bfzero. В этом случае на шаге 13 выполняется оператор continue, осуществляющий досрочный переход к следующей итерации цикла for all. В противном случае на шаге 15 с помощью функции \mathrm{B}mathrm{o}\mathrm{u}\mathrm{n}\mathrm{d}mathrm{i}\mathrm{n}\mathrm{g}\mathrm{H}\mathrm{y}\mathrm{p}mathrm{e}mathrm{r}\mathrm{p}mathrm{l}\mathrm{a}\mathrm{n}mathrm{e}mathrm{I}\mathrm{n}mathrm{d}mathrm{e}\mathrm{x} вычисляется индекс j гиперплоскости Hj , ограничивающей текущую реберную прямую Li . Псевдокод функции \mathrm{B}\mathrm{o}\mathrm{u}\mathrm{n}\mathrm{d}mathrm{i}\mathrm{n}mathrm{g}\mathrm{H}\mathrm{y}\mathrm{p}mathrm{e}mathrm{r}\mathrm{p}mathrm{l}\mathrm{a}\mathrm{n}mathrm{e}mathrm{I}\mathrm{n}mathrm{d}mathrm{e}\mathrm{x} представлен ниже в виде алгоритма 4. Шаг 16 вычисляет конечную вершину \bfitvnex текущего ребра в соответствии с формулой (25). Если в операторе if на шаге 17 значение целевой функции в вершине \bfitvnex оказывается больше значения целевой функции в вершине \bfitv\ast , то вершине \bfitv\ast присваиваются координаты вершины \bfitvnex (шаг 18), индекс i текущей реберной прямой сохраняется в переменной i\ast (шаг 19), а индекс соответствующей ограничивающей гиперплоскости Hj сохраняется в переменной j\ast (шаг 20). Шаг 21 закрывает оператор if. Шаг 22 заканчивает цикл for all. Ал горитм 1 Алгоритм HAlEM 1: input n, m, k, A, b, c, vq 2: I\=:=\{1,...,k\} 3: I :=\{k + 1, . . . , m\} 4: Vq := Basislndex(vg) // см. алгоритм 2 5: t:=0 6: \ite\itx\iti\itt := \bff\bfa\bfl\bfs\bfe 7: repeat 8: loop 9: \bfitv\ast:=\bfitvt 10: for all i \in \scrVt do 11: \bfitd := \mathrm{D}\mathrm{i}\mathrm{r}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}\mathrm{V}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{o}\mathrm{r}(\bfitvt, \scrVt \setminus \{i\}) // см . алгоритм 3 12: if \bfitd = \bfzero then 13: continue 14: end if 15: j := \mathrm{B}\mathrm{o}\mathrm{u}\mathrm{n}\mathrm{d}\mathrm{i}\mathrm{n}\mathrm{g}\mathrm{H}\mathrm{y}\mathrm{p}\mathrm{e}\mathrm{r}\mathrm{p}\mathrm{l}\mathrm{a}\mathrm{n}\mathrm{e}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x}(\bfitvt, \bfitd) // см. алгоритм 4 16: bj-\langle\bfitaj,\bfitvt\rangle \bfitvnex :=\bfitvt +\langle\bfitaj,\bfitd\rangle \bfitd 17: if \langle\bfitc, \bfitvnex\rangle > \langle\bfitc, \bfitv\ast\rangle then 18: \bfitv\ast:= \bfitvnex 19: i\ast:=i 20: j\ast:=j 21: end if 22: end for 23: if \bfitv\ast\not= \bfitvtthen 24: Vt+1:= v* 25: Vt+1 :=(Vt \{i*}) U{j*} 26: t:=t+1 27: break 28: end if 29: \scrVt\prime:= \mathrm{S}\mathrm{c}\mathrm{r}\mathrm{o}\mathrm{l}\mathrm{l}\mathrm{B}\mathrm{a}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x}(\bfitvt , \scrVt) // см. алгоритм 5 30: if \scrVt\prime= \scrVtthen 31: \ite\itx\iti\itt := \bft\bfr\bfu\bfe 32: break 33: end if 34: \scrVt :=\scrVt\prime 35: end loop 36: until \ite\itx\iti\itt 37: output \bfitvt 38: stop Если в операторе if на шаге 23 удалось получить вершину \bfitv\astс координатами, отличными от координат текущей вершины \bfitvt, то выполняются следующие действия. На шаге 24 эта вершина становится следующим приближением vt+i- На шаге 25 для новой вершины vt+i вычисляется базисный индекс Vt+i по формуле (30). Шаг 26 увеличивает на единицу счетчик итераций t. На шаге 27 оператор break осуществляет выход из цикла loop, после чего выполняется следующая итерация основного цикла repeat/until. Если условие оператора if на шаге 23 не выполняется, происходит переход к шагу 29. Эта ситуация возникает, когда базисный индекс \scrVt оказался «тупиковым»: в нем отсутствуют ребра, ведущие к увеличению целевой функции. В этом случае на шаге 29 выполняется «прокручивание» базисного индекса вершины vt с помощью функции ScrollBasisIndex, псевдокод которой представлен в виде алгоритма 5. В результате получается обновленный базисный индекс У= = Vt. В этом случае оператор if (шаги 30—33) пропускается, и выполняется шаг 34, который заменяет предыдущий базисный индекс на новый. После этого повторяется итерация цикла loop для текущей вершины \bfitvt, но уже с обновленным базисным индексом. Если обновить базисный индекс невозможно, функция ScrollBasisIndex возвращает исходный базисный индекс. Это означает, что оптимальная вершина уже достигнута. В этом случае выполняется условие в операторе if на шаге 30, что приводит к выполнению шага 31, который устанавливает логическую переменную \ite\itx\iti\itt в значение «истина». После этого оператор break на 32 шаге производит выход из цикла loop. Поскольку exit = true, оператор until на шаге 36 завершает выполнение основного цикла repeat/until. Шаг 37 выводит координаты оптимальной вершины. Шаг 38 завершает работу алгоритма HAlEM. Псевдокод функции Basisindex, используемой на шаге 4 алгоритма 1 для построения базисного индекса начальной вершины, представлен в виде алгоритма 2. В силу предполо- Алгоритм 2 Построение базисного индекса для начальной вершины 1: function Basisindex(v) 2: V : = 0 3: for j = k + 1,. .., n do // к — число уравнений в системе (1) 4: for all i £ I do 5: if (ai, v) = bi then 6: if rank(A/UVU{i}) = j then 7: V := VU{i} 8: break 9: end if 10: end if 11: end for 12: end for 13: return scrV 14: end function жения (3) система ограничений (1) не содержит избыточных уравнений4. Поскольку любая точка допустимого многогранника M должна удовлетворять всем уравнениям из системы (1), любой матричный базис в любой вершине \bfitv допустимого многогранника M должен включать в себя коэффициенты всех уравнений. Для того, чтобы получился полный матричный базис в вершине V, к матрице А^ необходимо добавить n — к строк коэффициентов неравенств, соответствующих ограничивающим гиперплоскостям, проходящим через \bfitv , так, чтобы ранг получившейся квадратной матрицы был равен размерности пространства n. Алгоритм 2 вычисляет базисный индекс, содержащий индексы соответствующих неравенств. На шаге 2 создается пустой базисный индекс \scrV. Внешний цикл for выполняет n-k итераций, добавляя каждый раз в У новый индекс i из I так, чтобы ранг матрицы А/иуиИ оставался полным. Это обеспечивается путем выполнения вложенного цикла for all (шаги 4–9), который для каждого i-того неравенства на шаге 5 проверяет условие {ai, v) = bi. Если это условие выполняется, то граничная гиперплоскость, соответствующая i-тому неравенству, проходит через вершину V. В этом случае на шаге 6 проверяется условие rank(AiuVU{ij) = j. Выполнение этого условия означает, что матрица AfUyU{i} имеет полнострочный ранг. В этом случае шаг 7 добавляет индекс i в \scrV , после чего оператор break на шаге 8 выполняет досрочный выход из вложенного цикла for all. Процесс продолжается, пока не будут выполнены все итерации внешнего цикла for. В итоге получается полный базисный индекс \scrV , который на шаге 13 возвращается в качестве результата функции Basisindex. Псевдокод функции DirectionVector, используемой на шаге 11 алгоритма 1 для вычисления направляющего вектора реберной прямой с реберным индексом \scrE , представлен в виде алгоритма 3. Реализация этого алгоритма основывается на предложенном нами вычисли- Алгоритм 3 Вычисление направляющего вектора 1: function DirectionVector(v, 8) 2: ес:= с/ ||с|| 3: z := V + 8ес 4: w := ^Tu£(z) 5: if |w — V| =0 then 6: return \bfzero 7: end if 8: d := w — V 9: ed := d/ |d| 10: z' := V + 8ed 11: w' := К jus(z') 12: d' := w' — V 13: return \bfitdprime 14: end function и она не может вести к увеличению целевой функции. В этом случае на шаге 6 функция \mathrm{D}\mathrm{i}\mathrm{r}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}\mathrm{V}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{o}\mathrm{r} в качестве результата возвращает нулевой вектор. В противном случае на шаге 8 получаем ненулевой вектор \bfitd = \bfitw - \bfitv , направленный в сторону увеличения целевой функции. Точность вычисления координат точки \bfitw критически зависит от двух факторов: величины \delta и угла \alpha между векторами \bfitc и \bfitd. Вычислительные эксперименты показали, что для достижения высокой точности на реальных задачах ЛП значение параметра \delta должно находится в следующих пределах: 105^ S ^ 109. Но этого оказывается недостаточно. Если величина угла \alpha оказывается близкой к 90\circ, то наблюдается катастрофическая потеря точности для любых значений параметра \delta. На рис. 3 такая потеря точности выражается в том, что точка \bfitw оказывается на некотором расстоянии от прямой L\scrE . Для нейтрализации этого эффекта выполняется вторая фаза проектирования. На шаге 9 вычисляется единичный вектор \bfite\bfitd = \bfitd/\|\bfitd\|, сонаправленный с вектором \bfitd. Шаг 10 находит точку \bfitz\prime= \bfitv + \delta\bfite\bfitd. Шаг 11 с помощью формулы (11) вычисляет точку w' = ^^g(г7), являющуюся ортогональной проекцией точки \bfitzprimeна прямую LscrE. Шаг 12 с высокой точностью вычисляет направляющий вектор \bfitdprime= \bfitwprime- \bfitv реберной прямой LscrE , указывающий в сторону увеличения целевой функции. Шаг 13 возвращает вектор \bfitdprimeв качестве результата функции \mathrm{D}\mathrm{i}\mathrm{r}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}\mathrm{V}\mathrm{e}\mathrm{c}\mathrm{t}\mathrm{o}\mathrm{r}. Псевдокод функции \mathrm{B}\mathrm{o}\mathrm{u}\mathrm{n}\mathrm{d}\mathrm{i}\mathrm{n}\mathrm{g}\mathrm{H}\mathrm{y}\mathrm{p}\mathrm{e}\mathrm{r}\mathrm{p}\mathrm{l}\mathrm{a}\mathrm{n}\mathrm{e}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x}, используемой на шаге 15 алгоритма 1 для вычисления индекса j гиперплоскости Hj , ограничивающей реберную прямую Li , представлен в виде алгоритма 4. Здесь \bfitv — вершина, через которую проходит реберная пря- Алгоритм 4 Вычисление индекса ограничивающей гиперплоскости 2: 3: 4: 5: 6: // см. формулы (17) и (18) мая Li , \bfitd — ее направляющий вектор. Алгоритм 4 в точности реализует вычисления по формуле (29) и не нуждается в пояснении. Заметим только, что ограничивающая гиперплоскость всегда существует в силу ограниченности допустимого многогранника M . Следующий алгоритм реализует функцию «прокручивания» базисного индекса. Алгоритм 5 Прокручивание базисного индекса для выхода из тупика Require: g = (gi,.. .,gn); у = (yi,... ,yn); и = (ui,.. .,um); V = [vi,.. .,vn-k] 1: function ScrollBasisIndex(r, V) 2: 3: 4: 6: 7: 8: 9: 10: 11: 12: 13: 14: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: repeat g :=cA^v и := 0 for i = 1,... ,n — k do uvi :=gk+i end for i* :=0 for i = 1,..., m do if ui < 0 then i* := i break end if end for if i* = 0 then return \scrV end if for j = 1,... ,n — k do if Vj = i* then for i = 1, . . . , n do yi := -A^[i,k + j] end for end if end for Amin : = +® for all j G I do if \langle\bfitaj, \bfity\rangle > 0 then \ . = bj-(«j^ langle\bfitaj,\bfityrangle if \lambda < \lambdamin then Amin := A j* :=j end if end if end for V :=(V\{i*}) U{j*} until Amin > 0 return \scrV 38: end function В некоторых случаях алгоритм HAlEM, находясь в вершине \bfitvt, может попасть на шаге 29 в «тупиковую» ситуацию, когда в базисном индексе \scrVtотсутствуют ребра, ведущие к увеличению целевой функции. С помощью комбинаторного перебора всевозможных сочетаний ограничивающих гиперплоскостей, проходящих через \bfitvt , всегда можно найти ребро, ведущее к увеличению целевой функции (если такое ребро не существует, мы уже находимся в оптимальной вершине). Этот метод был нами реализован в алгоритме AlEM [16]. Однако алгоритм AlEM имеет неприемлемо высокую экспоненциальную вычислительную сложность для многих практических задач ЛП. Вместо этого в алгоритме HAlEM на шаге 29 мы используем функцию \mathrm{S}\mathrm{c}\mathrm{r}\mathrm{o}\mathrm{l}\mathrm{l}\mathrm{B}\mathrm{a}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x}, которая «прокручивает» в вершине \bfitvtразличные варианты базисного индекса \scrVtдо тех пор, пока не будет найдена комбинация, в которой есть ребро, ведущее к увеличению целевой функции. Функция \mathrm{S}\mathrm{c}\mathrm{r}\mathrm{o}\mathrm{l}\mathrm{l}\mathrm{B}\mathrm{a}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x}, представленная в виде алгоритма 5, для этой цели использует подход, применяемый в симплекс-методе, и детально описанный в разделе 11.1 монографии [19]. При написании алгоритма 5, реализующего функцию \mathrm{S}\mathrm{c}\mathrm{r}\mathrm{o}\mathrm{l}\mathrm{l}\mathrm{B}\mathrm{a}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x}, мы сохранили обозначения, использованные в [19], за исключением следующих: вершине xg соответствует vt; матрице Aq соответствует матрица A/uV; столбцу bg соответствует Ь^у. Для своей работы алгоритм 5 использует три вспомогательных вектора: \bfitg, \bfity \in \BbbRnи \bfitu \in \BbbRm. Основной цикл repeat/until (шаги 2–32) осуществляет «прокрутку» базисных индексов, пока не будет найден вариант с ребром, ведущим к увеличению целевой функции. Шаг 3 вычисляет вспомогательный вектор \bfitg. Шаги 4–7 заполняют координаты вектора \bfitu из двойственной задачи. В отличии от [19], мы заполняем нулями координаты \bfitu, соответствующие уравнениям. На шагах 8–14 находим индекс i\ast, соответствующий первой отрицательной координате вектора \bfitu. Если в \bfitu таких координат нет, то мы находимся в оптимальной вершине. В этом случае функция \mathrm{S}\mathrm{c}\mathrm{r}\mathrm{o}\mathrm{l}\mathrm{l}\mathrm{B}\mathrm{a}\mathrm{s}\mathrm{i}\mathrm{s}\mathrm{I}\mathrm{n}\mathrm{d}\mathrm{e}\mathrm{x} на шаге 16 возвращает исходный базисный индекс. В противном случае на шагах 18–24 вычисляются координаты направляющего вектора \bfity для i\ast-го ребра. Шаги 25–34 вычисляют индекс j \astограничивающей гиперплоскости подобно тому, как это делалось в алгоритме 4. Шаг 35 обновляет («прокручивает») базисный индекс \scrV, удаляя из него i\astи добавляя j\ast. Процесс продолжается до тех пор, пока не будет получен вариант с \lambdamin> 0, означающий, что j \ast-тое ребро ведет к увеличению целевой функции. Следует отметить, что в редких случаях могут встретиться вырожденные задачи ЛП, для которых через определенное число итераций цикла repeat/until мы можем получить базисный индекс, который уже встречался ранее. В этом случае произойдет зацикливание алгоритма 5. Это характерно и для оригинального симплекс-метода, разработанного Данцигом. Для таких случаев предложены различные техники [11], позволяющие выйти из зацикливания. Однако обсуждение этих вопросов выходит за рамки настоящей статьи. Для невырожденных задач ЛП алгоритм HAlEM за конечное число шагов гарантированно сходится к оптимальной вершине.
3. Параллельная версия алгоритма HAlEM Алгоритм 1 перебирает в цикле for all (шаги 10–22) n - k ребер базисного индекса \scrVtс целью нахождения ребра, ведущего к вершине с наибольшим значением целевой функции. Этот цикл поддается эффективному распараллеливанию, что мы реализовали в параллельной версии алгоритма HAlEM. Параллельная версия алгоритма HAlEM основана на модели параллельных вычислений BSF [20], ориентированной на кластерные вычислительные системы. Модель BSF использу- ет схему распараллеливания «мастер–рабочие» и требует представление алгоритма в виде операций над списками с использованием функций высшего порядка \mathrm{M}\mathrm{a}\mathrm{p} и \mathrm{R}\mathrm{e}\mathrm{d}\mathrm{u}\mathrm{c}\mathrm{e}. Функция высшего порядка Map(F, MapList) выполняет функцию F для всех элементов списка \itM\ita\itp\itL\iti\its\itt, в результате чего формируется список \itR\ite\itd\itu\itc\ite\itL\iti\its\itt. Функция высшего порядка Reduce(®, ReduceList) попарно выполняет ассоциативную бинарную операцию ф для всех элементов списка \itR\ite\itd\itu\itc\ite\itL\iti\its\itt, в результате чего получается один элемент. В данном случае список MapList имеет длину n — к и включает в себя все элементы базисного индекса \scrVt , взятые в определенном порядке: MapList = [i1,..., in-k], где {ii,... ,in-k} = Ft. Семантика функции Ft определяется алгоритмом 6, шаги которого соответствуют шагам 11– 16 алгоритма 1. Алгоритм 6 Функция \mathrm{F}t 1: function Ft(i) 2: d :=DirectionVector(rt, Ft \ {i}) // см. алгоритм 3 // см. алгоритм 4 3: if \bfitd = \bfzero then 4: return (vt,i, 0) 5: end if 6: j := BoundingHyperplaneIndex(vt, d) 7: \bfitv\ast:=\bfitv +bj-\langle\bfitaj,\bfitvt\rangle\bfitd : t \langle\bfitaj,\bfitd\rangle 8: return (v*,i,j) 9: end function Список \itR\ite\itd\itu\itc\ite\itL\iti\its\itt, получаемый в результате вызова функции высшего порядка Map(Ft, MapList), будет выглядеть следующим образом: ReduceList = [(^iij),...,(^n-k,in-k,jn-k)] , где для любого l G {1,...,n — к} точка v* является смежной вершиной по отношению к вершине vt, i* — индекс соответствующего ребра, j* — индекс гиперплоскости, ограничивающей соответствующую реберную прямую, за исключением случая, когда j* = 0. В этом случае \bfitvl\ast = \bfitvt . Бинарная операция \oplus над элементами списка \itR\ite\itd\itu\itc\ite\itL\iti\its\itt определяется следующей фор- мулой: (v',i',j') ф V"ii"d") = (v',i,j'), (v'',i'',j'') , if (c, v') > (c, v"), if (c, v') < (c, v'), семантика которой соответствует шагам 17–21 алгоритма 1. Псевдокод параллельной версии алгоритма HAlEM представлен в виде алгоритма 7. Распараллеливанию подвергается цикл for all (шаги 10–22) последовательного алгоритма 1. Параллельные вычисления организуются по схеме «мастер–рабочие» и включают в себя L + 1 процесс: один процесс-мастер и L процессов-рабочих, где L ^ n — к. Для простоты мы будем предполагать, что n — к кратно L. Процесс–мастер (далее — просто «мастер») выполняет последовательную часть алгоритма 7 и организует выполнение параллельной части процессами–рабочими (далее — про-2026, т. 15, № 1 23 Алгоритм 7 Параллельная версия алгоритма HAlEM горитма 1. На шаге 29 мастер с помощью системной функции Broadcast рассылает всем рабочим значение логической переменной exit, в зависимости от которого рабочие продолжают или заканчивают свою работу. Финальные шаги 30–32 мастера соответствуют финальным шагам 36–38 последовательного алгоритма 1. Все рабочие выполняют одну и ту же последовательность шагов, но над разными данными. На шаге 1 каждый рабочий вводит исходные данные задачи ЛП. На шаге 2 с помощью системной функции \bfN\bfu\bfm\bfb\bfe\bfr\bfO\bff\bfW\bfo\bfr\bfk\bfe\bfr\bfs рабочий получает общее число рабочих L, задействованных в вычислениях. На шаге 3 с помощью системной функции \bfM\bfy\bfN\bfu\bfm\bfb\bfe\bfr рабочий получает свой номер l. Далее рабочий входит в вычислительный цикл repeat/until (шаги 7–30). На шаге 9 рабочий с помощью системной функции Recv ожидает получения от мастера координат текущей вершины \bfitvtи элементов текущего базисного индекса \scrVt. На шаге 10 рабочий вычисляет длину K той части списка \itM\ita\itp\itL\iti\its\itt, которую ему необходимо обработать. На шаге 11 рабочий строит свою часть списка \itM\ita\itp\itL\iti\its\ittl. На шаге 12 с помощью функции высшего порядка Мар рабочий вычисляет список ReduceList 1. На шаге 13 рабочий с помощью функции высшего порядка Reduce редуцирует список ReduceList 1 к одной тройке (v*,i*,j*) путем попарного применения бинарной операции ф по формуле (34). На шаге 14 с помощью системной функции Send рабочий отсылает полученную тройку мастеру. После этого рабочий на шаге 29 с помощью системной функции Recv ожидает получения от мастера значения логической переменной exit. Если на шаге 30 переменная exit принимает значение \bff\bfa\bfl\bfs\bfe, рабочий переходит к следующей итерации вычислительного цикла repeat/until. В противном случает рабочий заканчивает свою работу. Отметим, что с помощью системных функций Recv и Gather осуществляется неявная синхронизация параллельных процессов.
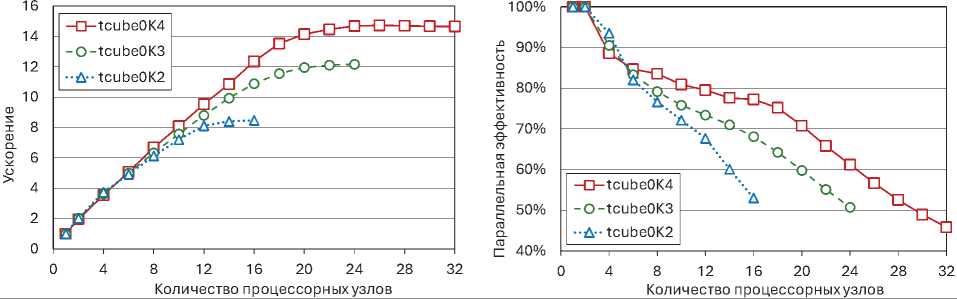
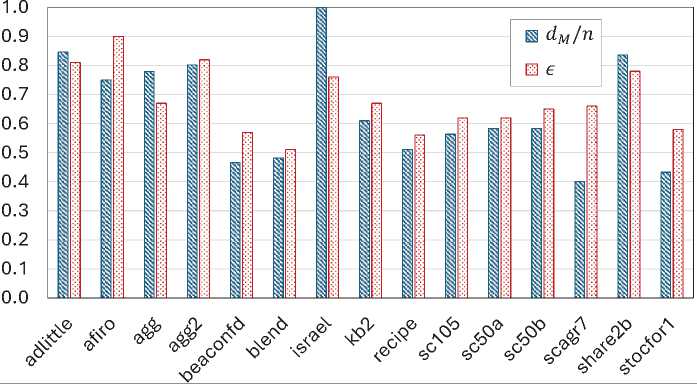
4. Реализация и вычислительные эксперименты Мы реализовали параллельную версию алгоритма HAlEM на языке C++ с использованием программного BSF-каркаса [21], базирующегося на модели параллельных вычислений BSF [20]. BSF-каркас инкапсулирует все аспекты, связанные с распараллеливанием программы на основе библиотеки MPI. Исходные коды параллельной реализации свободно доступны в репозитории GitVerse по адресу С использованием этой реализации были проведены вычислительные эксперименты по исследованию масштабируемости параллельной версии алгоритма HAlEM на различных задачах ЛП. Все эксперименты проводились на суперкомпьютере «Торнадо ЮУрГУ» [22], характеристики которого представлены в табл. 1. Для сборки программы использовался Таблица 1. Характеристики суперкомпьютера «Торнадо ЮУрГУ» Параметр Значение Количество процессорных узлов Процессоры Число процессоров на узел Память на узел Соединительная сеть Операционная система 480 Intel Xeon X5680 (6 cores, 3.33 GHz) 2 24 GB DDR3 InfiniBand QDR (40 Gbit/s) Linux CentOS Таблица 2. Тестирование параллельного алгоритма HAlEM на задачах Netlib-LP В первой серии экспериментов мы исследовали ускорение и эффективность распараллеливания алгоритма HAlEM на эталонных задачах ЛП из репозитория Netlib-LP [23], доступного по адресу В качестве начальной вершины \bfitv0 всегда выбиралась точка \bfzero, если она являлась вершиной допустимого многогранника M . В противном случае начальная вершина вычислялась с помощью программы VeRSAl (Vertex Retrieve by Simplex Algorithm), написанной на языке C++, исходные тексты которой свободно доступны в репозитории GitVerse по адресу Программа VeRSAl строит на основе исходной задачи ЛП расширенную задачу ЛП в соответствии с методом, описанными в [19] (см. «Общий случай», стр. 199). Точка \bfzero по построению является вершиной допустимого многогранника для расширенной задачи ЛП. Программа VeRSAl решает эту задачу с помощью стандартного симплекс-метода, в результате чего получается вершина допустимого многогранника для исходной задачи ЛП. Результаты экспериментов с эталонными задачами из репозитория Netlib-LP представлены в табл. 2. В столбце 1 перечислены имена задач из репозитория Netlib-LP, использованные для тестирования параллельного алгоритма HAlEM. Файлы со спецификациями этих задач в формате MPS [24] доступны в репозитории GitVerse по адресу В этом же репозитории в формате MatrixMarket [25] сохранены координаты начальных вершин для всех указанных задач. В столбце 2 указано количество ограничений m для соответствующей задачи ЛП, включая неравенства, уравнения (если они присутствуют) и ограничения вида (2). В столбце 3 указано количество переменных n (размерность пространства решений). Столбец 4 содержит размерность dM допустимого многогранника M, совпадающую с размерностью его аффинной оболочки: dM = dim(M) = dim (aff (M)). Если система ограничений не содержит избыточных уравнений и неявных равенств5 , то размерность допустимого многогранника M может быть вычислена по следующей формуле: dim(M) = n — k, где k — количество уравнений в системе ограничений. В соответствии с этим количество уравнений k в системе ограничений задачи ЛП из табл. 2 может быть вычислено по формуле k = n — dM. (35) Столбец 5 содержит отношение размерности dM допустимого многогранника к размерности n пространства решений. В столбце 6 указана относительная погрешность максимума целевой функции, вычисленного с помощью алгоритма HAlEM, в сравнении с «точным» значением, приведенным в работе Коха [26]: ^ = FKoch - FHAIEM bigm| F\itK\ito\itc\ith bigm| Здесь F\itH\itA\itl\itE\itM — значение, вычисленное алгоритмом HAlEM, F\itK\ito\itc\ith — значение, указанное в работе [26]. Практически во всех случаях относительная погрешность оказалась в пределах машинного нуля (машинного эпсилон) [27], равного 2.2 х 10-16 для типа double (64 бита). Столь высокая точность вычислений была достигнута благодаря использованию метода двух-факторной проекции в алгоритме 3. В столбце 7 приведена верхняя теоретическая граница K\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k} масштабируемости алгоритма HAlEM, которая указывает максимальное число процессорных узлов, доступных для распараллеливания при использовании BSF-каркаса. Величина K\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k} вычисляется следующим образом. Алгоритм 7 организует параллельные вычисления путем деления списка \itM\ita\itp\itL\iti\its\itt на равные части по числу рабочих. Обработка этих подсписков выполняется рабочими на шаге 12 независимо друг от друга. Согласно (33) список \itM\ita\itp\itL\iti\its\itt имеет длину n - k. Из (35) следует, что длина списка \itM\ita\itp\itL\iti\its\itt равна dM . Это означает, что для параллельной обработки списка \itM\ita\itp\itL\iti\its\itt нельзя использовать более dM рабочих. Учитывая, что при прогоне задачи на каждом процессорном узле запускалось 12 рабочих MPI-процессов, приходим к выводу, что Kpeak = LdM /12J • Столбец 8 содержит реальную границу масштабируемости K\mathrm{m}\mathrm{a}\mathrm{x} , определенную для каждой задачи ЛП в ходе вычислительных экспериментов. Под реальной границей масштабируемости параллельного алгоритма понимается число процессорных узлов вычислительного кластера, при превышении которого время решения задачи перестает сокращаться. В соответствии с характеристиками вычислительной платформы, использованной при проведении экспериментов (см. табл. 1), число процессорных ядер, задействованных для решения задачи на Kmax узлах будет равно Kmax х 12. В столбце 9 указано время Тк^^ решения задачи ЛП на K\mathrm{m}\mathrm{a}\mathrm{x} узлах6 . В столбце 10 указано время T1 решения этой же задачи на одном процессорном узле. Значения ускорения, достигнутые на границе масштабируемости, представлены в столбце 11. Ускорение вычислялось по формуле T1 \alpha= . T max В столбце 12 содержится параллельная эффективность, достигаемая на границе масштабируемости. Параллельная эффективность вычислялась по формуле \epsilon = T1 . Kmax \cdotTKmax Анализ полученных результатов позволяет сделать несколько выводов. Первый вывод касается границы масштабируемости K\mathrm{m}\mathrm{a}\mathrm{x}. Для допустимых многогранников малой размерности (dM < 70) теоретическая граница масштабируемости совпадает с реальной: K\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k} = K\mathrm{m}\mathrm{a}\mathrm{x} . Для допустимых многогранников средней размерности (70 \leqslant dM \leqslant 100) теоретическая и реальная границы масштабируемости различаются не более чем на 1: K\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k}- K\mathrm{m}\mathrm{a}\mathrm{x}\leqslant 1. В случае допустимых многогранников большой размерности (dM > 100) реальная граница масштабируемости может быть существенно меньше теоретической: K\mathrm{m}\mathrm{a}\mathrm{x} \ll K\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k} . Это связано с тем, что при использовании большого количества MPI-процессов для решения задачи ЛП методом HAlEM накладные расходы на организацию параллельного выполнения могут полностью нивелировать ускорение, получаемое при добавлении новых процессорных узлов. Второй вывод связан с корреляцией между величиной dM /n и эффективностью распараллеливания \epsilon. Столбчатая диаграмма, представленная на рис. 4, показывает, что большому значению dM/n соответствует высокая параллельная эффективность \epsilon, и наоборот, низкая параллельная эффективность \epsilon характерна для задач ЛП с небольшим значением dM /n. Из этого ряда выпадает задача israel, которая характерна тем, что у нее единственной в системе ограничений отсутствуют уравнения, то есть размерность пространства решений совпадает с размерностью допустимого многогранника. Также отметим, что во всех случаях параллельная эффективность не опускалась ниже 51%, что является неплохим показателем для численного алгоритма. Для сравнения разработанной параллельной версии алгоритма HAlEM с симплекс-методом мы использовали программу Simplex, исходные тексты которой на языке C++ свободно доступны по адресу Программа Simplex реализует параллельную версию классического симплекс-метода, описанного в [19] (стр. 197–198). Используя эту реализацию, мы решили все упомянутые задачи из репозитория Netlib-LP на той же вычислительной платформе, на которой исследовали HAlEM. Для всех задач ЛП программа Simplex запускалась на двух процессорных узлах по 12 MPI-процессов на узел. Использование большего количества процессорных узлов приводило к деградации ускорения программы Simplex. Результаты сравнения приведены в табл. 3. Эксперименты показали, что метод НAlEM обладает существенно большим 28 Вестник ЮУрГУ. Серия «Вычислительная математика и информатика» Рис. 4. Корреляция между dM /n и параллельной эффективностью \epsilon Таблица 3. Сравнение метода HAlEM с симплекс-методом на задачах Netlib-LP
Задача
Процессорных узлов
Число итераций
Время (сек)
Относительная погрешность
HAlEM
Simplex
HAlEM
Simplex
HAlEM
Simplex
HAlEM
Simplex
adlittle
5
2
67
59
0.55
0.12
0
3.9 х 10-15
afiro
2
2
3
4
0.0015
0.0009
2.5 х 10-16
1.2 х 10-16
agg
6
2
23
63
2.57
1.06
0
0
agg2
8
2
99
132
93.4
19.3
7.4 х 10-16
0
beaconfd
6
2
15
23
9.18
2.07
2.2 х 10-16
2.2 х 10-16
blend
3
2
35
70
0.35
0.09
1.2 х 10-16
4.7 х 10-14
israel
7
2
146
160
5.46
1.26
1.2 х 10-15
3.9 х 10-15
kb2
2
2
23
76
0.02
0.02
0
4 х 10-15
recipe
7
2
12
17
2.07
0.41
0
0
sc105
4
2
13
13
0.13
0.03
0
0
sc50a
2
2
7
7
0.008
0.002
0
0
sc50b
2
2
5
5
0.005
0.002
2 х 10-16
0
scagr7
4
2
30
30
0.81
0.21
0
1.8 х 10-15
share2b
3
2
27
33
0.18
0.05
1.5 х 10-15
2.3 х 10-15
stocfor1
4
2
12
22
0.18
0.07
1.1 х 10-14
1.1 х 10-14
ресурсом параллелизма, чем симплекс-метод. По количеству итераций оба метода имеют близкие показатели, однако симплекс-метод превосходит HAlEM по быстродействию на всех исследованных задачах ЛП. При этом разница в быстродействии находится в пределах одного порядка, что не является катастрофическим. Оба метода демонстрируют высокую точность вычислений на границе машинного нуля для типа double (64 бит). Однако существуют классы задач ЛП, на которых метод HAlEM показывает более высокую эффективность, чем симплекс-метод. В качестве примера можно привести циклические многогранники. Используя пример циклического многогранника C4(8) из [28] (стр. 29-30), мы сконструировали задачу ЛП zieglerC4_8, исходные данные которой в формате MPS можно найти по адресу Miscellaneous-LP. Алгоритм HAlEM решает эту задачу за одну итерацию, в то время как программе Simplex для этого требуется 11 итераций. В финальной серии экспериментов с параллельной версией алгоритма HAlEM мы исследовали зависимость ускорения и параллельной эффективности от размера решаемой задачи. С этой целью мы сконструировали специальную параметризованную задачу ЛП «гиперкуб с отсеченной вершиной», для которой размерность n пространства решений является параметром. Ограничения этой задачи содержат 2n +1 неравенств следующего вида: x1 x2 \leqslant \leqslant . 200, 200, . . xn \leqslant 200, Х1 + x2 \cdot • • + xn С 200(n - 1) + 100, xi ^ 0, Х2 > 0, • •• ,Хп > 0. Градиент целевой функции задается вектором с = (1, 2,..., n). Задача предполагает нахождение максимума целевой функции и имеет единственное решение в точке (100, 200,..., 200) со значением целевой функции, равным Fmax(n) = 100(n2+ П - 1). Очевидно, что точка \bfzero является вершиной допустимого многогранника системы ограничений (36). Для произвольного n эта задача может быть получена в формате MatrixMarket [25] с помощью генератора FRaGenLP [29], если в качестве количества случайных неравенств задать 0. Исходные коды генератора FRaGenLP на языке C++ свободно доступны по адресу Сгенерированные задачи для различных n доступны по адресу content/master/Tcube под именами lp_tcube Таблица 4. Тестирование HAlEM на задачах Tcube Рис. 5. Ускорение и параллельная эффективность алгоритма HAlEM Заключение В данной работе представлен новый проекционный алгоритм HAlEM для решения задач линейного программирования, который объединяет сильные стороны разработанного ранее авторами алгоритма AlEM (проекционный подход) и классического симплекс-метода (обновление матричного базиса). Основная идея HAlEM заключается в построении пути к оптимальной вершине путем последовательного перехода по ребрам допустимого многогранника, причем на каждом шаге для определения направления движения используется эффективная процедура двух-факторной ортогональной проекции, а для переключения на новое ребро применяется механизм ротации базисных индексов, аналогичный симплекс-методу. Такой гибридный подход позволил преодолеть главные недостатки предшествующих алгоритмов: избежать экспоненциального комбинаторного перебора (в отличие от AlFaMove и AlEM) и проблем, связанных с низкой скоростью сходимости фейеровских процессов при вычислении проекций (в отличие от апекс-метода). Для предложенного алгоритма разработана параллельная версия, ориентированная на кластерные вычислительные системы. Распараллеливание, основанное на BSF-модели и схеме «мастер-рабочие», заключается в одновременной обработке всех ребер текущей вершины, что позволяет значительно сократить время выполнения итерации. Проведенные вычислительные эксперименты на задачах из репозитория Netlib-LP и на серии специально сконструированных задач подтвердили работоспособность и эффективность алгоритма HAlEM. Основные выводы по результатам исследования можно сформулировать следующим образом. Благодаря использованию метода двух-факторной проекции алгоритм HAlEM демонстрирует высокую точность вычисления оптимального значения целевой функции, находящуюся в пределах машинного нуля для типа double (64 бита). Алгоритм HAlEM имеет ресурс параллелизма, существенно превосходящий симплекс-метод, что позволяет эффективно задействовать значительно большее количество процессорных узлов. Хотя по абсолютному времени счета на малом числе узлов HAlEM уступает симплекс-методу (разница в пределах одного порядка), на некоторых задачах (например, на циклических многогранниках) HAlEM может находить решение за меньшее число итераций. Исследование масштабируемости показало, что граница эффективного распараллеливания алгоритма HAlEM напрямую зависит от размерности допустимого многогранника. Для задач с небольшой и средней размерностью теоретическая граница масштабируемости совпадает с реальной. При увеличении размерности накладные расходы на коммуникацию могут ограничивать рост ускорения, однако параллельная эффективность на реальной границе масштабируемости остается выше 50% во всех случаях, что является хорошим показателем для численного алгоритма. Дальнейшие исследования планируется направить на разработку искусственной нейронной сети, которая позволит идентифицировать ребра допустимого многогранника быстрее, чем это делает алгоритм HAlEM с помощью двух-факторной проекции. Подобная модернизация позволит алгоритму HAlEM составить конкуренцию симплекс-методу по быстродействию на реальных задачах. Обозначения n m k \BbbRn \langle\cdot, \cdot\rangle \|\cdot\| _ I I AJ \bfitbJ \bfitai Pi Hi M rank(A) aff(X) dim(X) ^J (ж) число переменных в системе ограничений (размерность пространства) число ограничений количество уравнений в системе ограничений вещественное евклидово пространство размерности n скалярное произведение двух векторов евклидова норма множество индексов ограничений в виде уравнений: I = {1,..., к} множество индексов ограничений в виде неравенств: I = {к + 1,..., т} матрица коэффициентов ограничений с индексами из J С {1,..., т} столбец правых частей ограничений с индексами из J С {1,..., т} i-тая строка матрицы Aj (i G J) полупространство, определяемое формулой \langle\bfitai, \bfitx\rangle \leqslant bi (iG I) гиперплоскость, определяемая формулой (ai, ж) = bi (i G {1,..., m}) допустимый многогранник (область допустимых решений) ранг матрицы A аффинная оболочка множества X размерность множества X: dim(X) = dim(aff(X)) ортогональная проекция точки \bfitx на подпространство Hi i\inJ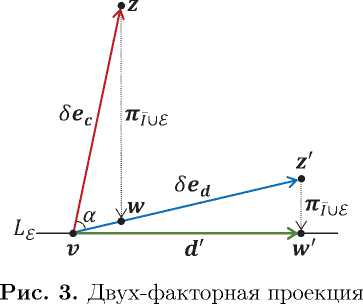
мастер
l-тый рабочий (l = 1,..., L)
1: input n,m,k,A, b, с, vo
1: input n, m, k, A, \bfitb, \bfitc
2: I :={1, ...,k}
2: L := NumberOfWorkers
3: I :={k + 1,..., m}
3: l := MyNumber
4: Vo := BasisIndex(vo)
4:
5: t :=0
5:
6: exit: = false
6:
7: repeat
7: repeat
8: loop
8:
9: Broadcast(vt, Vt)
9: Recv(vt, Vt) // Vt = {ii,...,in-k}
10:
10: K := n-k
11:
11: MapListi := [ii+(i-i)K,..., iiK]
12:
12: ReduceListi := Map(Ft, MapListi)
13:
13: (v*,i*,j*) := Reduce(ф, ReduceListi)
14: Gather(\itR\ite\itd\itu\itc\ite\itL\iti\its\itt\ast)
14: Send(v*, i*,j*)
15: (v*, i*,j*) := Reduce(ф, ReduceList*)
15:
16: if v* = vt then
16:
17: vt+1 := v*
17:
18: Vt+1 : = (Vt \{i*}) U{j*}
18:
19: t: = t +1
19:
20: break
20:
21: end if
21:
22: Vt := ScrollBasisIndex(vt, Vt)
22:
23: if Vt = Vt then
23:
24: exit : = true
24:
25: break
25:
26: end if
26:
27: Vt := Vt
27:
28: end loop
28:
29: Broadcast(exit)
29: Recv(exit)
30: until \ite\itx\iti\itt
30: until exit
31: output \bfitvt
31:
32: stop
32: stop
сто «рабочие»). Шаги 1–8 мастера соответствуют шагам 1–8 последовательного алгоритма 1. На шаге 9 мастер с помощью системной функции Broadcast рассылает всем рабочим координаты текущей вершины \bfitvt и соответствующий базисный индекс \scrVt. На шаге 14 мастер с помощью системной функции Gather собирает результаты всех рабочих, представленных в виде троек вида (v*,i*,j*), и организует их в единый список ReduceList*. На шаге 15 мастер с помощью функции высшего порядка Reduce редуцирует список ReduceList* к одной тройке (v*,i*,j*) путем попарного применения бинарной операции ф по формуле (34). Далее мастер выполняет шаги 16–28, соответствующие шагам 23–35 последовательного ал24 Вестник ЮУрГУ. Серия «Вычислительная математика и информатика»
Задача
m
n
dM
dM/n
\delta
К 1
\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k}
\mathrm{m}\mathrm{a}\mathrm{x}
TKmax
T1
\alpha
\epsilon
1
2
3
4
5
6
7
8
9
10
11
12
adlittle
153
97
82
0.85
0
6
5
0.55
2.22
4.04
0.81
afiro
59
32
24
0.75
2.5 x 10-16
2
2
0.0015
0.0027
1.8
0.90
agg
651
163
127
0.78
0
10
6
2.57
10.40
3.84
0.67
agg2
818
302
242
0.80
7.4 x 10-16
20
8
93.4
616.2
6.6
0.82
beaconfd
435
262
122
0.47
2.2 x 10-16
10
6
9.18
31.62
3.44
0.57
blend
157
83
40
0.48
1.2 x 10-16
3
3
0.35
0.52
1.5
0.51
israel
316
142
142
1
1.2 x 10-15
11
7
5.46
29.09
5.33
0.76
kb2
93
41
25
0.61
0
2
2
0.022
0.030
1.34
0.67
recipe
366
180
92
0.51
0
7
6
2.07
6.94
3.35
0.56
sc105
207
103
58
0.56
0
4
4
0.13
0.32
2.47
0.62
sc50a
97
48
28
0.58
0
2
2
0.008
0.009
1.2
0.62
sc50b
96
48
28
0.58
2 x 10-16
2
2
0.005
0.007
1.3
0.65
scagr7
269
140
56
0.4
0
4
4
0.81
2.13
2.6
0.66
share2b
175
79
66
0.83
1.5 x 10-15
5
3
0.18
0.43
2.34
0.78
stocfor1
228
111
48
0.43
1.1 x 10-14
4
4
0.18
0.43
2.32
0.58
компилятор g++, распространяемый в составе пакета компиляторов GCC 10, и библиотека Intel MPI 5.0. Компиляция выполнялась с опцией оптимизации O3. Задачи запускались на различном количестве процессорных узлов кластера. При этом общее число MPI-процессов было равно 12K, где K — количество задействованных процессорных узлов. Таким образом, на каждом узле работало 12 MPI-процессов — по числу физических ядер.
K и
Задача
m
n
\mathrm{m}\mathrm{a}\mathrm{x}
К i
\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k}
\mathrm{m}\mathrm{a}\mathrm{x}
TKmax.
T1
\alpha
\epsilon
tcube0K2
401
200
4019900
16
16
16.1
136
8.5
0.53
tcube0K3
601
300
9029900
24
24
92.5
1126
12.2
0.51
tcube0K4
801
400
16039900
33
24
387
5681
14.7
0.61
максимальное значение целевой функции. Относительная погрешность для всех трех задач была равна нулю. Соответствующие графики ускорения и параллельной эффективности приведены на рис. 5. Отметим, что, как и в предыдущих экспериментах, на каждом процессорном узле запускалось 12 MPI-процессов. В качестве начальной вершины всегда выбиралась точка \bfzero. Эксперименты показали, что для задач размерностей 200 и 300 теоретическая граница масштабируемости K\mathrm{p}\mathrm{e}\mathrm{a}\mathrm{k} совпала с реальной K\mathrm{m}\mathrm{a}\mathrm{x} . Однако при увеличении размерности задачи до 400, начиная с 25 узлов, накладные расходы на распараллеливание стали превалировать над ускорением. В этом случае реальная граница масштабируемости оказалась заметно меньше теоретической. Отметим, что и в этой серии экспериментов параллельная эффективность на реальной границе масштабируемости не опускалась ниже 51%, что можно считать хорошим результатом.