О связи имитационной логит-динамики в популяционной теории игр и метода зеркального спуска в онлайн оптимизации на примере задачи выбора кратчайшего маршрута

Автор: Гасников А.В., Лагуновская А.А., Морозова Л.Э.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Доклады
Статья в выпуске: 4 (28) т.7, 2015 года.
Бесплатный доступ
В работе описывается метод зеркального спуска для задач стохастической онлайн оптимизации на симплексе и прямом произведении симплексов. На базе этого метода строятся оптимальные стратегии пользователей транспортной сети при выборе маршрутов следования. Поведение всех пользователей, действующих согласно таким стратегиям, порождает имитационную логит-динамику в популяционной игре, соответствующей модели Бэкмана равновесного распределения потоков по путям. Таким образом, на конкретном примере (The Shortest Path Problem) в работе показывается связь онлайн оптимизации и популяционной теории игр. Обнаружение отмеченной связи составляет основной результат данной работы.
Короткий адрес: https://sciup.org/142186090
IDR: 142186090 | УДК: 51.77
Текст научной статьи О связи имитационной логит-динамики в популяционной теории игр и метода зеркального спуска в онлайн оптимизации на примере задачи выбора кратчайшего маршрута
-
1. Введение
-
2. Метод зеркального спуска для задач стохастической онлайн оптимизации с неточным оракулом
В литературе по онлайн оптимизации почетное место занимает так называемая «Задача о выборе кратчайшего пути» («The Shortest Path Problem»), см., например, п. 5.4 [1]. Основной результат здесь заключается в описании «оптимальной» стратегии пользователя транспортной сети (на базе алгоритма «Follow the Perturbed Leader»), из дня в день выбирающего маршрут следования, исходя из истории загрузок графа транспортной сети.
В литературе по равновесной теории транспортных потоков наиболее популярными являются модели равновесного распределения потоков по путям. Одной из первых (и по-прежнему наиболее популярных) моделей такого рода является модель Бекмана [2] (также называемая BMW-моделью). Современные исследования этой модели связаны с ее пониманием как популяционной игры загрузок (как следствие, потенциальной игры [3]), поиск равновесия (Нэша) в которой сводится к задаче выпуклой оптимизации. Упомянутый эволюционный подход, в частности, приводит к изучению различных естественных динамик (наилучших ответов, репликаторов, имитационной логит-динамики и др.), отражающих «нащупывание» пользователями транспортной сети равновесия [4]. Все эти динамики положительно коррелированы с антиградиентной динамикой, поэтому все они приводят в конечном итоге к одному и тому же равновесию (или в более общем случае к одному и тому же множеству равновесий). Тем не менее возникает желание глубже разобраться с природой этих динамик, понять, чем та или иная динамика дополнительно (помимо отражения рациональности игроков/пользователей транспортной сети) примечательна.
В данной работе мы постараемся изложить, чем примечательна имитационная логит-динамика, пояснив ее связь с алгоритмом поведения «Follow the Perturbed Leader», а точнее, с переформулировкой этого алгоритма на языке современной выпуклой онлайн оптимизации: с методом зеркального спуска [5–11].
В разделе 2 статьи описаны различные варианты классического метода зеркального спуска применительно к задачам стохастической онлайн оптимизации с шумами. Ввиду последующих приложений мы сосредоточимся на множествах вида симплекса и прямого произведения симплексов. Хотя во многом эти результаты ранее были известны, тем не менее в такой общности, в которой они приведены в данной статье, нам не удалось найти точной ссылки, поэтому было решено посвятить этому отдельный раздел 2. В разделе 3 мы используем результаты раздела 2 (в данной статье не в максимальной общности) для объяснения имитационной логит-динамики, возникающей при описании поведения пользователей транспортной сети в модели Бекмана.
Сформулируем основную задачу стохастической онлайн оптимизации с неточным оракулом. Требуется подобрать последовательность {ж^} G Q так, чтобы минимизировать псевдорегрет [6–11]:
-
1 N 1 N
Regret tv ({ffe ( • ) } , {ж/г}) = — ^ f k (V) - m a in — ^ f k (ж) (1)
-
V k=1 x 4 N k =1
на основе доступной информации:
{Vx/1 (ж1^1) ;...; VxA-1 (ж^Леfc-1)} при расчете жк. Причем выполнено условие :1
-
1) для любых к = 1,..., — (S fc -1 - сигма алгебра, порожденная е 1 , • • •, е^ -1 )
\\v xfk ( х к ,£к) -V / к х Лк) ||* 6 5, E ■ \к (х к ,Е )] = V / к (х к ) .
Здесь случайные величины {^к} могут считаться независимыми и одинаково распределенными. Онлайновость постановки задачи допускает, что на каждом шаге к функция /к ( • ) может выбираться из рассматриваемого класса функций враждебно по отношению к используемому нами методу генерации последовательности {хк}. В частности, /к ( • ) может зависеть от
{ж 1 ,е 1 ,/ 1 ( • );...; Ж к - 1 ,^ к -1 ,/к - 1 ( • );х к} .
Относительно класса функций, из которого выбираются { / к ( • ) } , в данной работе будем предполагать выполненными следующие условия :
-
2) { / к ( • ) } - выпуклые функции;
-
3) для любых к = 1,..., N , х Е Q
v ■ . (х,е)\ \ 2 6М 2 .
Опишем метод зеркального спуска для решения задачи (1) (здесь можно следовать огромному числу литературных источников, мы в основном будем следовать работам [12, 13]). Введем норму |||| в прямом пространстве (сопряженную норму будем обозначать ||П*) и прокс-функцию d (х), сильно выпуклую относительно этой нормы, с константой сильной выпуклости не меньше 1. Выберем точку старта х1 = arg mind (х), XEQ считаем, что d (х1) = Vd (х1) = 0.
Введем брэгмановское «расстояние»
V x (у) = d (у) - d (х) - (V d (х), у - х} .
Везде в дальнейшем будем считать, что d (х) = Vxi (х) 6 В для всех х Е Q.
Определим оператор «проектирования» согласно этому расстоянию:
Mirrx k (9) = arg m l in { ( 9, У -хк) + V x k (у) } .
Метод зеркального спуска (МЗС) для задачи (1) будет иметь вид, см., например, [13]:
х k +1 =Mirr x k (a V x / к (х к , ^ к )) , к = 1,..., N.
Тогда при выполнении условии (2) для любого и Е Q, к = 0,..., N — 1 имеет место неравенство, см., например, [13]:
а ( V x/к (х к , Е ) , хк - и ) 6 ^ || V x / к ^ , Е ) 112 + V x k (и) - V x k +1 (и).
2/2
Это неравенство несложно получить в случае евклидовой прокс-структуры d (х) = | х |
-
[14] (в этом случае МЗС для задачи (1) есть просто вариант обычного метода проекции
градиента). Разделим сначала выписанное неравенство на а и возьмем условное математическое ожидание E^k+i [ • | Нк], затем просуммируем то, что получится по к = 1,...,N, используя условие 1. Затем возьмем от того, что получилось при суммировании, полное математическое ожидание, учитывая условие 3. В итоге, выбирая и = ж* (решение задачи
N
52 f k (ж) ^ min), получим при условиях 1, 2, 4 [11]:
к =1 №
N • Е [RegretN ( { fk ( • ) } , {ж к })] 6 ^^ - ^М + Q м 2 а + R 8^n 6
6?+( 2м 2 “+R6)N- выбирая2
R р2 а = М\N, получим
Е [RegretN ( { fk( • ) } , {ж к })] 6 MRJ Nn + R 5.
Немного более аккуратные рассуждения (использующие неравенство Азума–Хефдинга) позволяют уточнить оценку (2) следующим образом (см., например, [15]):
RegretN ( { fk ( • ) } , {ж к }) 6 Ма^2 (R + 2jR VM ^ 1 )) -I (3)
с вероятностью не меньше 1 — ст.
Оценки (2), (3) являются неулучшаемыми с точностью до мультипликативного числового множителя. Причем верно это и для детерминированных (не стохастических) постановок, в которых нет шумов (5 = 0), при этом можно ограничиться классом линейных функций [1].
Рассмотрим три примера, которые понадобятся нам в дальнейшем [11, 15].
Пример 1 (симплекс). Предположим, что
Q = S n (1) =
{ж > 0:
п Л
Еж. = 1 .
. =1 )
Выберем
п
IHI = IH^, d (ж) = 1n n + У^ж. 1п ж..
. =1
Тогда МЗС примет следующий вид (а = М 1 ^21n n /N):
ж1 = 1/n, г = 1,..., n, при к = 1,..., N, г = 1,..., n
( А дЛ(жг ,§г )\ к ( 8Jk(xk^k )\ exp |^— ^ а) жк exp -а vd$1 )
'Е е( 5^ о8^( х Т ,^ Г) ^ 5^ ж к exп (— а Э ^ к ( ж к ,^ к ) А Zx^ exp I — 2_^а —s^i— ) ^ж/ exp а Эх і J
Оценки псевдорегрета будут иметь вид
Е [RegretN ( { fk ( • ) } , {ж к })] 6 М^ ^N^ + 2 5,
RegretTV ( { /к ( • ) } , {x k }) 6 M\PN ( ^ inn + Win (ст 1 )) + 25 с вероятностью не меньше 1 — с.
Пример 2 (прямое произведение симплексов). Предположим, что x = (z1,
..
.,<) e Q
m
= П S n 3 (d j ).
j=1
Выберем
m
0 x 0 = . £ V 0 1 , N 3=1
d (x)=£ m(a j =1
n NA d3 (z 3 ) = d j in n + £ ln (dj) ■
Тогда, вводя обозначения
R p2 a = mN N,
R 2
m
£ d2 in nj, j=1
МЗС можно записать следующим образом:
4 = d j / n j ,
г = 1, ...,n j ,
при к = 1,..., N, г = 1, ...,n j , j = 1,..., m
3,к +1 A
= d j
( к exp — X a \ r=1
^3 ,^ ) dz i
)
x ^ exp
n к к
X exP — X a
1=1 \ r=1
->Г'хл
8z i
— = dj —
\
)
/1=1
-- a ^
k ( 9Jk (xk,^ )\ ■ x exp (-a N )
Оценки псевдорегрета будут иметь вид
Е
R R egretv ({/к ( • ) } ,
m
{x; k })] 6H N А £ d j ln n j +25 \ j=1
N
m
£ d2, j=1
Regretv { /fk ( • ) } ,
m
{x k }) 6Mv n (\£ d 2 ln
\ N з =1
m nj+4^ £ d2 vin(c-1)
+ 25^
m
£ dj j=1
с вероятностью не меньше 1 — т.
Пример 3 (выбор среди вершин симплекса). Вернемся к примеру 1 и будем дополнительно считать, что по условию задачи {xk} должны выбираться среди вершин единичного симплекса S n (1). Так же, как и раньше, онлайновость постановки задачи допускает, что на каждом шаге к функция / к может подбираться из рассматриваемого класса функций враждебно по отношению к используемому нами методу генерации последовательности {x^1}. В частности, / к может зависеть от
{x1,^1,/1(•); ...;xk-1,^k-1,/k-1(•)} и даже от распределения вероятностей рк, согласно которому осуществляется выбор x/c. Чтобы можно было работать с таким классом задач, нам придется наложить дополнительные условия :
-
4) /к (x) = (Jk ,x), к = 1,...,N.
-
5) На каждом шаге генерирование случайной величины ж к согласно распределению вероятностей р к осуществляется независимо ни от чего. Выбор /к осуществляется без знания реализации ж к .
Следуя примеру 1, положим р 1 = ж 1 = ^, г = 1, ...,п. При к = 1, ...,N , г = 1, ...,п согласно распределению вероятностей (а = М -1 ^ 2lnn/N)
( А эДх' ,0 Л к ( эЦхк Д А exp — £ а 1 Pi exP —а дхг рк+1 = ____£^=________/ = ______V/
* £ ex"P (— Д “■) gP-'exP (-«')’ генерируем случайную величину г (к + 1) и полагаем ж^+і) = 1, жк+1 = 0, j = г (к + 1).
Оценки псевдорегрета будут иметь вид
Е [Regret^ ( { /к ( • ) } , {ж к })] 6 М ^2 n " + 25,
Regret V ({/к ( • ) } , {ж к }) 6 M^N ( V lnn + б^іп (ст -1 )) + 25
-
с вероятностью не меньше 1 — ст.
-
3. Приложение к задаче о выборе кратчайшего пути
Рассмотрим транспортную сеть, которую будем представлять ориентированным графом ( V,E ) , где V - множество вершин, а Е - множество ребер. Обозначим множество пар источник-сток через OD С V 0 V ( | OD | = m); d w - корреспонденция, отвечающая паре w; ж р - поток по пути р; P w - множество путей, отвечающих корреспонденции w, Р = U P w w e OD - множество всех путей. Обозначим через L - максимальное число ребер в пути из Р . Будем считать, что затраты на прохождениe ребра е Е Е описываются неубывающей (и ограниченной в рассматриваемом диапазоне значений) функцией
0 6 Те (/е) 6 м, где /е - поток по ребру е:
/е (ж) = ^ 5 ер ж р , 5 ер = I о е Е р
P E P V
Положим М = ML. Введем G P (ж) - затраты на проезд по пути р:
GP (ж) = ^2те (/е (ж)) 5 ер .
e E E
Введем также множество (прямое произведение симплексов), на котором транспортная сеть «будет жить»:
X = ж > 0 :
У^ жр = dw, w Е OD > , PEPw и функцию, порождающую потенциальное векторное поле G (ж):
/ е (х )
Ф
(ж)=Е I е ЕЕ 0
т е (г) dz.
Основное свойство этой функции заключается в том, что
V Ф(ж) = G (ж).
Будем считать, что число пользователей транспортной сети большое:
dw := dw • N, N » 1, w E OD, но в функциях затрат это учитывается:
Т е (fe) := T e (fe/N ) .
Таким образом, далее под d w , ж, f будем понимать соответствующие прошкалированные (по N ) величины [4].
Выберем корреспонденцию w E OD и рассмотрим пользователя транспортной сетью, соответствующего этой корреспонденции. Стратегией пользователя является выбор одного из возможных путей следования р E Pw. Будем считать, что пользователь мало что знает об устройстве транспортной системы и о формировании своих затрат. Все, что доступ- но пользователю на шаге к + 1, — это история затрат на разных путях, соответствующих
{'; = g (ж' ) }„„ . }‘ _1
его корреспонденции, на всех предыдущих шагах
. Для простоты
рассуждений мы не зашумляем эту информацию, считая, что доступны точные значения имевших место затрат. Все последующие рассуждения (ввиду общности выбранной в разделе 2) можно обобщить и на случай зашумленных данных (детали мы вынуждены здесь опустить).
Допуская, что 0 6 {Zp} 6 М могут выбираться враждебно, пользователь стремится действовать оптимальным образом, то есть так, как предписывает стратегия из примера 3 (с г = р, п = \ P W | ). Заметим, что при некоторых дополнительных оговорках (см. п. 5.4 [1]) случайный выбор пути (согласно примеру 3) может быть осуществлен за время O ( | Е | ), что не зависит от п, которое может быть намного больше (например, для манхетенской сети, см. п. 5.4 [1]).
Представим себе, что остальные пользователи ведут себя аналогичным образом, но независимо (в вероятностном плане) друг от друга. Тогда в пределе N ^ то такая стохасти- ческая марковская динамика в дискретном времени вырождается в детерминированную динамику в дискретном времени [16], описываемую итерационным процессом из примера 2 с j =w, Z3 = {жр}реРш, п = |pw|, а, = М-1 2lnn,/N,
N Regret N 6 max a
3=1,...,m •
' 3
1 ( R 2 +— М 2 N max a2 ) ,
\ 2 j=1,...,m
для задачи не онлайн оптимизации:
Ф (ж) ^ min, xEX
f k (ж) = Ф (ж) , ж^ = N ^ ж к , Ф * = Ф (ж * ) ,
N к=1
Ф (ж^) - Ф * 6 Regret N 6
max { ln п 3 }
М j=1,...,m 3
NN /2 min { Inn у j=1,...,m
m \
E d 3 + 1) .
3 =1 /
Решение задачи (4) иногда называют равновесием Нэша(–Вардропа) в описанной популяционной игре [4, 17], соответствующей модели Бэкмана равновесного распределения потоков по путям [2]. Для простоты формулировок будем далее считать, что решение единственно.
Введем теперь схожий процесс (совпадающий с описанным ранее в пределе N ^ то ): дискретный аналог имитационной логит-динамики с произвольным параметром а > 0, популярной в эволюционной теории игр [4]. Пусть отрезок времени [0, Т ] разбит на Т N ^ 1 одинаковых отрезков, соответствующих шагам. На каждом шаге к = 1,...,TN каждый пользователь корреспонденции j = w Е OD независимо от всех остальных пользователей с вероятностью N -1 принимает решение выбрать потенциально новую стратегию (маршрут следования) согласно распределению вероятностей г Е P j (в действительности, тут требуются некоторые оговорки на случай, когда x k = 0, мы опускаем здесь эти детали, за подробностями отсылаем к монографии [4]):
Р^1 =
x k exp ( — aG i (x k ))
Z xk exp (—aGi (xk)), ip а с вероятностью 1 — N-1 — использовать стратегию предыдущего шага. Аналогично действуют пользователи, принадлежащие другим корреспонденциям: j = 1, ...,m. Тогда в пределе N ^ то эта динамика превратится на отрезке [0, Т] в имитационную логит-динамику в непрерывном времени [4, 16], в которой с каждым пользователем связан свой (независимый) пуассоновский процесс с интенсивностью 1. В моменты скачков процесса пользователь принимает решение о потенциальной смене маршрута следования согласно распределению вероятностей г Е Pj, j = 1, ...,m:
( t ) = X i (t) exp ( — aGi (x (t))) P i Z x i (t) exp ( — aGi (x (t))).
i ^ P i
При T ^ то описанный эргодический марковский процесс выходит на стационарную вероятностную меру [4]:
~ exp (—N • (Ф (х) + о (1))) , которая при N ^ то экспоненциально концентрируется в окрестности решения задачи (4).
Если описанные предельные переходы выполнить в обратном порядке: сначала N ^ то , потом Т ^ то , то марковский процесс, отвечающий имитационной логит-динамике, выродится в СОДУ г Е P j , j = 1, ...,m:
dx i (t) X i (t)exp( — aG i (x (t)))
dt j Z x l (t) exp ( — aG l (x (t))) i ^ P j
-
X i .
Эта динамика (на внутренности инвариантного относительной данной динамики множества X ) имеет глобальным аттрактором неподвижную точку, определяемую как решение задачи (4). Более того, СОДУ (5) имеет функцию Ляпунова Ф (x) [4] (это общий факт: функционал Санова является функционалом Больцмана [18]), причем [5]
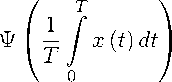
1 m
— Ф * 6 ат ^' 2 ;.
j=i
Заметим также, что СОДУ (5) можно понимать как непрерывный аналог (см., например, [19]) примера 2.
Работа выполнена при финансовой поддержке РФФИ (коды проектов 13-01-12007-офи_м, 15-31-20571 мол_а_вед, 15-31-70001 мол_а_мос). Исследования первого автора, связанные с п. 2, выполнены в ИППИ РАН за счет гранта Российского научного фонда (проект № 14-50-00150).
Список литературы О связи имитационной логит-динамики в популяционной теории игр и метода зеркального спуска в онлайн оптимизации на примере задачи выбора кратчайшего маршрута
- Lugosi G., Cesa-Bianchi N. Prediction, learning and games. New York: Cambridge University Press, 2006
- Patriksson M. The traffic assignment problem. Models and methods. Utrecht, Netherlands: VSP, 1994
- Algorithmic game theory. Editors N. Nisan, T. Roughgarden, E. Trados, V.V. Vazirani. Cambridge University Press., 2007
- Sandholm W.H. Population games and Evolutionary dynamics. Economic Learning and Social Evolution. MIT Press; Cambridge, 2010
- Немировский А.С., Юдин Д.Б. Сложность задач и эффективность методов оптимизации. М.: Наука, 1979
- Sridharan K. Learning from an optimization viewpoint. PhD Thesis, Toyota Technological Institute at Chicago, 2011
- Bubeck S. Introduction to online optimization. Princeton University: Lecture Notes, 2011. http://www.princeton.edu/sbubeck/BubeckLectureNotes.pdf
- Shalev-Shwartz S. Online learning and online convex optimization//Foundation and Trends in Machine Learning. 2011. V. 4, N 2. P. 107-194
- Bubeck S., Cesa-Bianchi N. Regret analysis of stochastic and nonstochastic multi-armed bandit problems//Foundation and Trends in Machine Learning. 2012. V. 5, N 1. P. 1-122. http://www.princeton.edu/sbubeck/SurveyBCB12.pdf
- Hazan E. Introduction to online convex optimization. e-print, 2015. http://ocobook.cs.princeton.edu/OCObook.pdf
- Гасников А.В., Нестеров Ю.Е., Спокойный В.Г. Об эффективности одного метода рандомизации зеркального спуска в задачах онлайн оптимизации//ЖВМ и МФ. 2015. Т. 55, № 4. С. 55-71
- Nemirovski A. Lectures on modern convex optimization analysis, algorithms, and engineering applications. Philadelphia: SIAM, 2013
- Allen-Zhu Z., Orecchia L. Linear coupling: An ultimate unification of gradient and mirror descent. e-print, 2014. arXiv:1407.1537
- Nesterov Y. Primal-dual subgradient methods for convex problems//Math. Program. Ser. B. 2009. V. 120(1). P. 261-283
- Juditsky A., Nemirovski A. First order methods for nonsmooth convex large-scale optimization, I, II. In: Optimization for Machine Learning. Eds. S. Sra, S. Nowozin, S. Wright. MIT Press, 2012
- Ethier N.S., Kurtz T.G Markov processes. Wiley Series in Probability and Mathematical Statistics: Probability and Mathematical Statistics. John Wiley & Sons Inc., New York, 1986
- Гасников А.В., Гасникова Е.В., Мендель М.А., Чепурченко К.В. Эволюционные выводы энтропийной модели расчета матрицы корреспонденций//Математическое моделирование. 2016. Т. 28. arXiv:1508.01077 (принята к печати)
- Баймурзина Д.Р, Гасников А.В., Гасникова Е.В. Теория макросистем с точки зрения стохастической химической кинетики//Труды МФТИ. 2015. Т. 7, № 4. C. 95-103
- Wibisono A., Wilson A.C. On accelerated methods in optimization. e-print, 2015. arXiv:1509.03616
