Об использовании логарифмированных моделей для криминологического интервального прогнозирования

Автор: Деменченок О.Г., Баранов С.А.
Журнал: Вестник Восточно-Сибирского института Министерства внутренних дел России @vestnik-vsi-mvd
Рубрика: Уголовно-правовые науки (юридические науки)
Статья в выпуске: 1 (116), 2026 года.
Бесплатный доступ
Введение. В статье отмечается, что современная методика интервального прогнозирования ограничивается всего тремя моделями: линейной, квадратичной и кубической. Однако для некоторых исходных данных эти модели могут оказаться слишком строгими и неспособными гибко реагировать на изменения. В статье показана возможность применения в интервальном прогнозировании логарифмированных форм показательной модели и логарифмической параболы. Исследуется, как логарифмирование влияет на качество описания исходных данных и точность оценки ошибки прогноза. Кроме того, даются рекомендации по использованию логарифмированных моделей в криминологическом прогнозировании. Материалы и методы. Исследование опирается на статистические данные о преступности в России и современные методы математической статистики. Результаты исследования. Предложено дополнить набор инструментов для интервального криминологического прогнозирования двумя моделями: показательной и логарифмической параболой. Эти модели были апробированы на практике для краткосрочного прогнозирования количества зарегистрированных преступлений в Красноярском крае. Полученные в ходе решения задачи результаты свидетельствуют о существенном влиянии логарифмирования на качество описания данных и прогностические свойства моделей. Выводы и заключения. Подтверждена целесообразность использования логарифмированных моделей для криминологического прогнозирования. При использовании логарифмированных моделей необходимо проводить проверку качества описания данных восстановленными моделями. При выборе модели для криминологического прогнозирования следует учитывать прогностические свойства не логарифмированных, а восстановленных моделей. Оценки ошибки прогноза для восстановленных моделей существенно возрастают при увеличении величины данных, что необходимо учитывать при прогнозировании процессов, имеющих тенденцию к росту.
Криминологическое прогнозирование, интервальное прогнозирование, логарифмирование
Короткий адрес: https://sciup.org/143185605
IDR: 143185605 | УДК: 343.9.01
The application of logarithmic models to criminological interval forecasting
Introduction. The article notes that current interval forecasting methodology is often limited to only three types of models: linear, quadratic, and cubic. However, for certain datasets, these models may prove too rigid and fail to respond flexibly to underlying fluctuations. This paper demonstrates the feasibility of applying logarithmic forms of the exponential model and the logarithmic parabola in interval forecasting. The study investigates how logarithmization affects the quality of data fitting and the accuracy of forecast error estimation. Furthermore, practical recommendations are provided for implementing logarithmic models in criminological forecasting. Materials and Methods. The research draws upon Russian national crime statistics and utilizes advanced mathematical statistical methods. The Results of the Study. The study proposes expanding the toolkit for interval criminological forecasting by incorporating two additional models: the exponential model and the logarithmic parabola. These models were empirically tested for short-term forecasting of registered crime rates in the Krasnoyarsk Territory of the Russian Federation. The findings indicate that logarithmization significantly enhances the quality of data fitting and improves the predictive performance of the models. Findings and Conclusions: The study confirms the efficacy of using logarithmic models for criminological crime forecasting. When applying these models, it is essential to evaluate the goodness-of-fit of the back-transformed (original-scale) models. The selection of a model for criminological forecasting should be based on the predictive performance of the back-transformed models rather than the logarithmic ones. Forecast error estimates for these models increase significantly as the data values grow; this must be taken into account when forecasting processes with an upward trend.
Текст научной статьи Об использовании логарифмированных моделей для криминологического интервального прогнозирования
Введение. В статье отмечается, что современная методика интервального прогнозирования ограничивается всего тремя моделями: линейной, квадратичной и кубической. Однако для некоторых исходных данных эти модели могут оказаться слишком строгими и неспособными гибко реагировать на изменения. В статье показана возможность применения в интервальном прогнозировании логарифмированных форм показательной модели и логарифмической параболы. Исследуется, как логарифмирование влияет на качество описания исходных данных и точность оценки ошибки прогноза. Кроме того, даются рекомендации по использованию логарифмированных моделей в криминологическом прогнозировании.
Материалы и методы. Исследование опирается на статистические данные о преступности в России и современные методы математической статистики.
Результаты исследования. Предложено дополнить набор инструментов для интервального криминологического прогнозирования двумя моделями: показательной и логарифмической параболой. Эти модели были апробированы на практике для краткосрочного прогнозирования количества зарегистрированных преступлений в Красноярском крае. Полученные в ходе решения задачи результаты свидетельствуют о существенном влиянии логарифмирования на качество описания данных и прогностические свойства моделей.
Выводы и заключения. Подтверждена целесообразность использования логарифмированных моделей для криминологического прогнозирования. При использовании логарифмированных моделей необходимо проводить проверку качества описания данных восстановленными моделями. При выборе модели для криминологического прогнозирования следует учитывать прогностические свойства не логарифмированных, а восстановленных моделей. Оценки ошибки прогноза для восстановленных моделей существенно возрастают при увеличении величины данных, что необходимо учитывать при прогнозировании процессов, имеющих тенденцию к росту.
-
5.1.4. Criminal Law Sciences (Legal Sciences)
Original article
THE APPLICATION OF LOGARITHMIC MODELS TO CRIMINOLOGICAL INTERVAL FORECASTING
Oleg G. Demenchenok1, Sergej A. Baranov2
Introduction. The article notes that current interval forecasting methodology is often limited to only three types of models: linear, quadratic, and cubic. However, for certain datasets, these models may prove too rigid and fail to respond flexibly to underlying fluctuations. This paper demonstrates the feasibility of applying logarithmic forms of the exponential model and the logarithmic parabola in interval forecasting. The study investigates how logarithmization affects the quality of data fitting and the accuracy of forecast error estimation. Furthermore, practical recommendations are provided for implementing logarithmic models in criminological forecasting.
Materials and Methods. The research draws upon Russian national crime statistics and utilizes advanced mathematical statistical methods.
The Results of the Study. The study proposes expanding the toolkit for interval criminological forecasting by incorporating two additional models: the exponential model and the logarithmic parabola. These models were empirically tested for short-term forecasting of registered crime rates in the Krasnoyarsk Territory of the Russian Federation. The findings indicate that logarithmization significantly enhances the quality of data fitting and improves the predictive performance of the models.
Findings and Conclusions: The study confirms the efficacy of using logarithmic models for criminological crime forecasting. When applying these models, it is essential to evaluate the goodness-of-fit of the back-transformed (original-scale) models. The selection of a model for criminological forecasting should be based on the predictive performance of the back-transformed models rather than the logarithmic ones. Forecast error estimates for these models increase significantly as the data values grow; this must be taken into account when forecasting processes with an upward trend.
Успех в любой сфере общественной жизни во многом зависит от качества информационно-аналитического обеспечения управления, включая прогностическую составляющую. В современных условиях, когда возрастает неопределенность и существует множество вариантов развития всех сфер общественной жизни, значение прогностической функции социальных наук становится особенно важным. Совершенствование управления невозможно без развития его прогностической составляющей и укрепления связи между прогнозированием, перспективным и текущим планированием [1, с. 4]. Внедрение передовых методов прогнозирования способно не только оптимизировать распределение ресурсов, но и значительно повысить эффективность работы правоохранительных органов. Кроме того, это может способствовать снижению уровня преступности и улучшению качества жизни граждан.
Среди наиболее перспективных подходов к криминологическому прогнозированию стоит выделить методы экстраполяции, моделирования и экспертных оценок [2, с. 65]. Экстраполяция основана на создании трендовых моделей – статистических инструментов, которые применяются для анализа данных, собранных в разные периоды времени. Трендовые модели позволяют прогнозировать будущее на основании наиболее вероятного развития наблюдаемых тенденций изучаемого явления.
Как правило, экстраполяция приводит к получению точечной оценки прогнозируемого явления, известной как точечный прогноз. Например, в следующем году количество зарегистрированных преступлений в определенном районе может составить 20 225. Очевидно, что в точечной оценке всегда есть некоторая ошибка – расхождение между прогнозом и реальным количеством. На этапе прогнозирования невозможно точно определить эту ошибку, но можно оценить ее величину. Статистический анализ погрешности прогноза позволяет составить так называемый интервальный прогноз. Это означает, что с определенной вероятностью прогнозируемая величина будет находиться в пределах конкретного интервала значений: точечный прогноз ± оценка ошибки.
Интервальное прогнозирование более информативно, чем точечное, так как учитывает возможные ошибки. Именно поэтому его считают более предпочтительным для решения управленческих задач.
Существующая методика интервального прогнозирования оперирует всего тремя моделями – линейной, квадратичной и кубической (полиномы первого, второго и третьего порядка). Методика расчета границ доверительного интервала прогноза для других видов моделей недостаточно разработана [3, с. 193].
Эти полиномы обычно хорошо подходят для описания исходных данных, которые отличаются малой изменчивостью и стабильной тенденцией. Однако для некоторых исходных данных такие модели могут оказаться слишком жесткими и неспособными адаптироваться к их изменениям [4, с. 35]. Если характер изменения данных существенно отличается от функциональной зависимости, которую предполагает трендовая модель, то не всегда удается получить модель, пригодную для прогнозирования.
В исследованиях социально-экономических процессов часто используется показательная модель:
У = a • b t, где a и b – постоянные коэффициенты; t – время.
Показательная функция с успехом применяется для описания процессов, которые либо ускоряются, либо замедляются, но при этом характеризуются стабильным темпом роста:
-
- рост населения в социологии;
-
- производство электромобилей в экономике;
-
- радиоактивный распад в физике;
-
- полимеразная цепная реакция в биохимии;
-
- концентрация лекарственного средства в кровотоке после его внутривенного введения в организм и так далее.
Благодаря своей способности точно отражать долгосрочные тенденции, показательные модели могут служить основой для математического прогнозирования.
Учитывая это, было бы разумно включить показательную модель в перечень инструментов для криминологического прогнозирования.
Более усложненным вариантом показательной модели является функция, получившая название логарифмической параболы [5, с. 47]:
у = а-Ь* • с*2. , где с - постоянный коэффициент.
Переход от мультипликативной формы модели к аддитивной осуществляется с помощью операции логарифмирования [6, с. 161]:
ln ( У ) = ln ( a ■ b t ) = ln ( a) + t ln ( b ) = ai + bi t , ln(y) = ln(a • b* • c*2} =«1 + bit + c^t2 , где ai , bi и ci - постоянные коэффициенты.
Логарифмирование преобразует исходные функции в уравнения линейной регрессии, но уже с другими коэффициентами [7, с. 30]. Уравнение показательной модели становится линейным, а логарифмической параболы - квадратичным. Это означает, что в логарифмированном виде показательная модель и логарифмическая парабола могут использоваться для интервального прогнозирования. Разница лишь в том, что для расчета средней ошибки прогноза используются не исходные данные, а их логарифмы [8, с. 114].
Важно учитывать, что нелинейность логарифмического преобразования может повлиять на свойства ошибок и распределение величин [9, с. 352]. В контексте криминологического прогнозирования наиболее важными показателями являются качество описания исходных данных и оценка ошибки прогноза. Очевидно, что существует некоторое различие между качеством описания логарифмированной моделью логарифмов исходных данных и качеством описания исходных данных восстановленной после логарифмирования моделью.
Кроме того, следует отметить различие в формировании доверительного интервала прогноза для полиномиальных и логарифмированных моделей:
для полиномов 1, 2 и 3 степени - доверительный интервал = прогноз + ошибка .. прогноз - ошибка;
для логарифмированных моделей -доверительный интервал = ехр(прогноз + ошибка) ... ехр(прогноз - ошибка), где ехр - экспонента.
В исследовании использовалась методика определения интервальных оценок в процессе прогнозирования, изложенная в работе В. В. Бучацкой [10, с. 137-138].
Цель этой работы – выяснить, насколько существенно влияет логарифмирование на качество описания исходных данных и точность оценки ошибки прогноза, а также выработать рекомендации по применению логарифмированных моделей в криминологическом прогнозировании.
Для исследования значимости влияния логарифмирования на качество описания данных и оценку ошибки прогноза рассмотрим задачу краткосрочного прогнозирования количества преступлений в Красноярском крае (далее – количество преступлений). Сведения о количестве зарегистрированных в Красноярском крае преступлений получены из отчетов «Состояние преступности в России», размещенных на официальном сайте МВД Росси и1.
Для исследования выбран интервал наблюдения с 2010 по 2024 год. Исходные данные приведены в табл. 1.
Таблица 1
Исходные данные
|
Год |
Количество преступлений (тысяч) |
Год |
Количество преступлений (тысяч) |
Год |
Количество преступлений (тысяч) |
|
2010 |
71,009 |
2015 |
62,282 |
2020 |
48,152 |
|
2011 |
63,087 |
2016 |
57,248 |
2021 |
47,027 |
|
2012 |
58,585 |
2017 |
51,085 |
2022 |
45,561 |
|
2013 |
58,832 |
2018 |
45,902 |
2023 |
50,069 |
|
2014 |
56,359 |
2019 |
46,530 |
2024 |
48,208 |
Наглядное представление исходных данных представлено на рис. 1. В целом наблюдается тенденция к снижению, однако динамика отличается нестабильностью с частыми изменениями направления. В 2012, 2013, 2014, 2015, 2018, 2020, 2022 и 2023 годах направление изменения данных неоднократно менялось: после периода снижения начинался рост, а после периода роста – снижение.
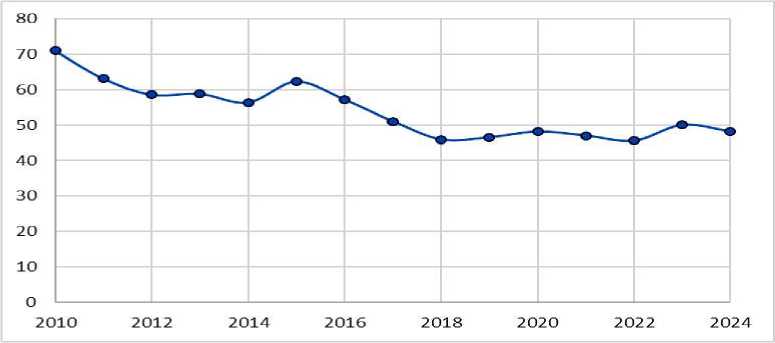
Рис. 1. Графическая интерпретация исходных данных
В рамках исследования использовались четыре модели: линейная, квадратичная, показательная и логарифмическая парабола.
Регрессионный анализ для определения коэффициентов моделей проводился в обычном порядке. Однако для логарифмированных моделей коэффициенты оценивались не по значениям исходных данных, а по значениям их логарифмов.
Регрессионный анализ проведен для каждой модели в диапазоне от 3 до 15 лет, в результате чего было получено 52 результата.
В исследовании были исключены регрессионные модели, которые не могли адекватно описать исходные данные (коэффициент детерминации R2 менее 0,7), а также модели с низкой статистической значимостью уравнения (значимость критерия Фишера более 0,1) и коэффициентов уравнения (вероятность равенства коэффициента нулю более 0,1).
Для интервалов наблюдения от 3 до 8 лет и 13 лет статистически значимых регрессионных моделей получить не удалось. Статистически значимые модели анализа представлены в табл. 2, в которой также содержится оценка ошибки прогноза на один год при уровне значимости α = 0,1.
Результаты регрессионного анализа
Таблица 2
|
Длина интервала наблюдения |
Модель |
R2 |
Оценка ошибки прогноза при a=0,1 |
|
9 |
y = 0,4065 t2 - 4,7218 t + 59,6 |
0,723 |
6,956 |
|
ln( y ) = 0,00798 t2 - 0,0923 t + 4,096 |
0,714 |
0,138 |
|
|
10 |
y = 0,4675 t2 - 6,3515 t + 67,^4 |
0,881 |
6,263 |
|
ln( y ) = 0,00879 t2 - 0,1193 t + 4,228 |
0,872 |
0,122 |
|
|
11 |
y = 0,2 789 t2 - 4,5341 t + 65,14 |
0,732 |
8,782 |
|
ln( y) = 0,00536 t2 - 0,0867 t + 4,196 |
0,737 |
0,164 |
|
|
12 |
y = 0,1923 t2 - 3,7233 t + 65,22 |
0,727 |
8,739 |
|
ln( y ) = 0,00369 t2 - 0,0711 t + 4,197 |
0,729 |
0,164 |
|
|
14 |
y = -1,274 t + 62,34 |
0,705 |
7,338 |
|
ln( y ) = - 0,0238 t + 4,138 |
0,701 |
0,138 |
|
|
15 |
y = -1,491 t + 65,93 |
0,747 |
8,125 |
|
y = 0,1389 t2 - 3,7129 t + 72,22 |
0,842 |
7,908 |
|
|
ln( y ) = - 0,0268 t + 4,195 |
0, 753 |
0,144 |
|
|
ln( y ) = 0,0023 t2 - 0,0637 t + 4,299 |
0, 834 |
0,146 |
Авторы считают, что для корректного сравнения линейной, квадратичной и логарифмированных моделей недостаточно лишь результатов регрессионного анализа. Для логарифмированных моделей необходимо провести операцию потенцирования, обратную логарифмированию. После этого следует рассчитать коэффициент детерминации R2 для исходных данных и сравнить его с результатами, полученными по восстановленным моделям. Также необходимо определить оценку ошибки прогноза для восстановленных моделей, которая представляет собой половину ширины доверительного интервала прогноза. Полученные результаты для восстановленных моделей представлены в табл. 3.
Сравнение результатов моделирования
Таблица 3
|
Длина нтервала наблюдения |
Модель |
R2 |
Оценка ошибки прогноза при o =0,1 |
|
9 |
y = 0,4065 t2 - 4,7218 t + 59,6 |
0,723 |
6,956 |
|
y = exp ( 0,00798 t2 - 0,0923 t + 4,096) |
0,739 |
7,361 |
|
|
10 |
y = 0,4675 t2 - 6,3515 t + 67,14 |
0,881 |
6,263 |
|
y = exp ( 0,00879 t2 - 0,1193 t + 4,228 ) |
0,894 |
6,533 |
|
|
11 |
y = 0,2 789 t2 - 4,5341 t + 65,14 |
0,732 |
8,782 |
|
y = exp ( 0,00536 t2 - 0,08671 + 4,196) |
0,717 |
8,386 |
|
|
12 |
y = 0,1923 t - 3,7233 t + 65,22 |
0,727 |
8,739 |
|
y = exp ( 0,00369 t2 - 0,0711 t + 4,197) |
0,709 |
8,132 |
|
|
14 |
y = -1,274 t + 62,34 |
0,705 |
7,338 |
|
y = exp(- 0,0238 t + 4,138 ) |
0,722 |
6,079 |
|
|
15 |
y = -1,491 t + 65,93 |
0,747 |
8,125 |
|
y = 0,1389 t2- 3,7129 t + 72,22 |
0,842 |
7,908 |
|
|
y = exp(- 0,0268 t + 4,195 ) |
0,772 |
6,242 |
|
|
y = exp(0,0023 t2 - 0,0637 t + 4,299 ) |
0,841 |
6,999 |
Сравнительный анализ подтверждает влияние логарифмирования на качество описания данных и прогностические свойства моделей:
-
1. Коэффициент детерминации R2 между исходными данными и расчетом по восстановленным моделям отличается от коэффициента детерминации между расчетом по логарифмированным моделям и логарифмами данных. Качество описания данных может как улучшаться (например, на 3,6 % – для логарифмической параболы с интервалом наблюдения 9 лет), так и ухудшаться (например, на 2,7 % – для
-
2. Процесс восстановления логарифмированных моделей оказывает значительное влияние на их прогностические качества:
-
3. Ошибки прогноза для восстановленных моделей нелинейно зависят от ошибок логарифмированных моделей. Большое влияние на эту зависимость оказывает размер исходных данных.
логарифмической параболы с интервалом наблюдения 11 лет).
Если качество описания данных снижается, коэффициент детерминации восстановленной модели может оказаться ниже минимально допустимого уровня. В таком случае модель следует исключить из рассмотрения, так как она не обеспечивает достаточного соответствия исходным данным. Поэтому при использовании логарифмированных моделей важно проверять качество описания данных восстановленными моделями.
в логарифмированном виде лучшей по точности прогнозирования оказывается логарифмическая парабола для интервала наблюдения в 10 лет с оценкой ошибки прогноза 0,122. Второе и третье место делят логарифмическая парабола - для интервала в 9 лет и показательная модель - для интервала в 14 лет (оценка ошибки прогноза - 0,138);
в восстановленном виде лучшей по точности прогнозирования становится показательная модель для интервала в 14 лет с оценкой ошибки прогноза 6,079. На втором месте - показательная модель для интервала в 15 лет (оценка ошибки прогноза - 6,242), а на третьем - логарифмическая парабола для интервала в 10 лет (оценка ошибки прогноза - 6,263).
Таким образом, при выборе модели для криминологического прогнозирования следует ориентироваться на прогностические качества восстановленных, а не логарифмированных моделей.
Например, если ошибка прогноза логарифмированной модели составляет 0,1, то при восстановлении модели она будет следующей:
0,27 при у = 1 ,
14,87 при у = 5 .
Таким образом, увеличение исходных данных в пять раз может привести к увеличению ошибки прогноза восстановленной модели в 55 раз. Эту особенность логарифмированных моделей необходимо учитывать при прогнозировании процессов, которые имеют тенденцию к росту.
В данной задаче из четырех математических моделей лучшей по критерию минимальной ошибки прогноза оказалась показательная модель при длине интервала наблюдения 14 лет. Это подтверждает целесообразность использования логарифмированных моделей для криминологического прогнозирования.
Чтобы получить точечный прогноз на один год по этой модели, в уравнение подставляем t = 15 :
у = exp (- 0,0238 t + 4,138 ) = exp (- 0,0238 15 + 4,138 ) = 43,877 .
Рассчитаем доверительный интервал прогноза:
exp (- 0,0238 15 + 4,138 + 0,138 ) ... exp (- 0,0238 15 + 4,138 - 0,138 ),
38,217 50,375 .
Очевидно, что середина доверительного интервала прогноза не совпадает с его точечным значением:
( 38,217 + 50,375 ) / 2 ^ 43,877 ,
44,296 ^ 43,877.
Этот результат соответствует выводам В. Н. Афанасьева о том, что для моделей, восстановленных методом потенцирования, характерна несимметричность доверительного интервала относительно точечного прогноза [3, с. 193].
Таким образом, можно предположить, что наиболее вероятное количество преступлений в Красноярском крае в 2025 году составит примерно 43,877 тысячи. С вероятностью 90 % реальное количество зарегистрированных преступлений будет находиться в диапазоне от 38,217 до 50,375 тысяч.
Исходя из изложенного, можно сделать следующие выводы:
подтверждена целесообразность использования логарифмированных моделей для криминологического прогнозирования;
при использовании логарифмированных моделей необходимо проводить проверку качества описания данных восстановленными моделями;
при выборе модели для криминологического прогнозирования следует учитывать прогностические свойства не логарифмированных, а восстановленных моделей;
оценки ошибки прогноза для восстановленных моделей существенно возрастают при увеличении данных, что необходимо учитывать при прогнозировании процессов, имеющих тенденцию к росту.
