Обобщение метода смешивания апостериорных распределений на несчетное множество экспертов

Автор: Зухба Р.Д., Зухба А.В.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Математика
Статья в выпуске: 4 (68) т.17, 2025 года.
Бесплатный доступ
В работе [2] рассматривается задача агрегирования конечного множества экспертов и требуется минимизировать регрет по сравнению с произвольным составным экспертом. Регрет в такой задаче имеет порядок Θ(𝑘 ln𝑁), то есть он неограниченно растет с ростом количества экспертов 𝑁. В данной работе рассматривается такая же постановка задачи, но с несчетным множеством экспертов 𝒩 = [𝑐, 𝑑]. Для решения этой задачи предложено обобщение метода смешивания апостериорных распределений (MPP) на несчетное множество экспертов. Получены оценки снизу на регрет любого алгоритма, решающего эту задачу. Предложено обобщение стандартного метода оценки сверху потерь алгоритмов, родственных MPP, использующее дополнительную информацию о потерях отдельных экспертов.
Непрерывное машинное обучение, прогнозирующие алгоритмы, обучение с учителем, экспертные стратегии, регрет, составной эксперт, оценка регрета снизу, оценка регрета сверху
Короткий адрес: https://sciup.org/142247123
IDR: 142247123 | УДК: 519.6
A generalization of the Mixing Past Posteriors algorithm for an uncountable set of experts
A paper [2, Herbster, Warmuth, 1998] examines an on-line learning problem of aggregating the predictions of a finite set of experts with the goal of predicting almost as well as the best sequence of such experts. The regret in this problem is 𝑅𝑇 = Θ(𝑘 ln𝑁), that is, it gets arbitrary large with a large number of experts 𝑁. This paper considers a similar setting, except with an uncountable set of experts 𝒩 = [𝑐, 𝑑]. We propose a generalization of the Mixing Past Posteriors algorithm for an uncountable set of experts. We provide an upper bound on the regret of this generalization and a lower bound on regret of any algorithm that solves this problem. We also propose a generalization of a standard approach of estimating the regret of algorithms similar to MPP by taking into account additional information regarding the losses of individual experts.
Текст научной статьи Обобщение метода смешивания апостериорных распределений на несчетное множество экспертов
Прогнозирование с использованием экспертных стратегий имеет форму игры с двумя участниками: Природа и Предсказатель. Природа генерирует неизвестную другим участникам последовательность {y i ,y 2 ,... ,у ^ } элементов множества исходов Y. Задачей Предсказателя является предсказание этой последовательности. Он может выдавать прогнозы у из множества Г, которое обычно является выпуклым подмножеством конечномерного пространства. Предсказатель строит свой прогноз в режиме онлайн, то есть на
(с) Зухба Р. Д., Зухба А. В., 2025
-
(с ) Федеральное государственное автономное образовательное учреждение высшего образования
«Московский физико-технический институт (пациопальпый исследовательский университет)», 2025
каждом шаге t игры он знает всю информацию о предыдущих шагах и должен выдать новый прогноз yt- У Предсказателя есть доступ к некоторому набору экспертов i G V, где V - некоторое индексное множество. Каждый эксперт i на каждом шаге t игры дает свой прогноз fay, i G V и Предсказатель с троит свой прогноз yt на их основе. После этого Природа сообщает истинное значение yt и вычислятотся потери 1щ = X(fi,t,yt) экспертов и потери ht = X(yt,yt) Предсказателя, где X(y,y) : Г х Y ^ R - функция потерь, которая принимает неотрицательные значения.
Важной особенностью данного подхода является то, что Предсказатель не пользуется никакими предположениями о природе прогнозируемой последовательности {yt}. Она может быть случайной или детерминированной, возможно Природа выбирает исходы в зависимости от прогноза Предсказателя. Поведение Природы может быть даже адаптивно-враждебным, то есть исходы выбираются так, чтобы максимизировать потери Предсказателя. Последнее предположение является естественным, например, при прогнозировании финансового рынка.
Эту постановку задачи можно рассматривать как повторяющуюся игру между Предсказателем, который делает прогнозы yt, и Природой, которая выбирает прогноз экспертов fi,t и истинньie исходы yt.
Игра 1. Прогнозирование с использованием экспертных стратегий
FOR t = 1, 2,...,Т
-
1) Для каждого эксперта i G V Природа представляет предсказание f (i,t).
-
2) Предсказатель также представляет свое предсказание yt-
-
3) Природа выбирает следующий истинный исход yt.
-
4) Участники игры получают истинное значение yt и несут потери:
l(i,t) = X(f (i,t),yt) - потери эксперта i, ht = X(yt,yt) - потери Предсказателя.
ENDFOR
т
В конце игры подсчитываются суммарные потери Предсказателя Нт = Д hi и суммарные t=i
т потери каждого эксперта L(i) = Д l(i,t), i G V.
t=i
В работе [2] рассмотрена постановка задачи, при которой сравниваются потери Предсказателя и потери произвольных последовательностей экспертных стратегий. Требуется минимизировать разницу этих величин, которая называется регретом. Регрет можно рассматривать как меру сожаления Предсказателя о том, что он на отдельных промежутках времени не слушался советов соответствующего этому промежутку эксперта. При этом разбиение всего интервала прогнозирования на подынтервалы и соответствующие этим подынтервалам эксперты выбираются самыми лучшими в ретроспективе. Опишем формально этот регрет.
Рассмотрим разбиение всего интервала прогнозирования 1 .. .Т на подынтервалы:
△
1 =
[tj—1,tj
— 1], г де 1 = t0
< t1 < ...
Каждому такому подынтервалу поставим в соответствие эксперта ij, j = 1 .. .к.
Составным экспертом, состоящим из к элементарных, называется произвольный набор из к интервалов и соответствующих им экспертов: Е = (ii , Ai,..., ij, △ j,... ,Д, △ к)>а составляющие его эксперты будут называться элементарными.
Суммарные потери элементарного эксперта ij на интервале Aj обозначим
L^)(ij ) = £ l(ijИ)
t^j а суммарные потери составного эксперта Е на всем временном интервале обозначим
k lt (Е) = ^ ЕЛ-)(ij ).
j=i
Регретом называется величина
Rt = Ht - min Lt (Е), где минимум берется по всем составным экспертам, состоящим из к элементарных.
Предложенный! в работе [2] алгоритм начитается Fixed Share. В работе [3] было предложено дальнейшее обобщение метода Fixed Share - метод смешивания апостериорных распределений МРР (Mixing Past Posteriors).
2. Обобщение метода смешивания апостериорных распределений на несчетное множество экспертов
В работе [2] рассматривается задача агрегирования конечного множества экспертов и требуется минимизировать регрет по сравнению с произвольным составным экспертом. Регрет в такой задаче имеет порядок &(к ln N ), то есть он неограниченно растет с ростом количества экспертов N.
В данной работе рассматривается такая же постановка задачи, но с несчетным множеством экспертов V = [c,d]. Можно, например, считать, что это некоторое параметрическое семейство предсказательных алгоритмов.
Если не накладывать дополнительных ограничений и оценивать регрет полностью аналогично предыдущему случаю, то оценка регрета получается несодержательной из-за бесконечного (несчетного) количества экспертов. Поэтому мы предлагаем наложить ограничения на гладкость функций f(i,t) по параметру i. Ниже, в теореме 4, мы покажем, что даже условия непрерывности функции f недостаточно для получения сублинейной оценки на регрет. Поэтому пусть функция f (i,t) - липшицева по переменной i с константой Di, то есть
Vri,^2 Ч |f(xi,t) - f (x2,t)| < Di|xi - X2I.
Пусть функция Х(у,у) - липшицева по переменной у с константой D2- Тогда l(i,t) = X(f (i,t),yt) - липшицева по переменной i с константой D = D1D2.
Пусть у > 0. Функция Х(у, у) пазывастся у-экспонспиушльпо вогнутой, если e-FEF) является вогнутой функцией переменной у для любого у EY.
В данной работе полагаем, что функция потерь Х(у,у) является у-экспоненциально вогнутой и в алгоритме 1 выбираем соответствующий параметр у. Например, функция Х(у,у) = (у — у)2 является у-экспонсптща.тыю вогнутой при у < 2(ь—а) 2 П1)П Г = Y = [а,Ь].
Алгоритм 1. Алгоритм смешивания апостериорных распределений на несчетном множестве экспертов
Параметр у > 0. Полагаем at = t+i для всех t.
Зададим начальное распределение весов w(i, 1) = w(i, 0) = ^-^.
FOR t = 1,...,Т
-
1) Пусть эксперты несут потери l(i, t) при i Е [c, d], Предсказателъ несет потери h(t).
Корректируем веса экспертов в два этапа:
-
2) Loss Update
. . w(i,t)e-rl(i,t
w(i,t) = -----------, f w(j,t)e-ril(^^dj
c при i G [c, d].
-
3) Mixing Update
t w(i, t + 1) = ^ /3^+1w(i, s'), s=0
где
30+1 =
at, /3t+1
= 1 —
at, 3^' 1
= 0
при
0
< s
w(i, t + 1) = atW(i, 1) + (1 — at)W(i, t), при i G [c, d].
ENDFOR
Заметим, что на каждом шаге сохраняется нормировка весов алгоритма:
У W(i,t)di = У w(i,t)di = 1. c c
Пуств А - множество всех распределений на множестве V = [c, d], то еств таких функ-d ций q : JV ^ R, что q(i) > 0, f q(i)di = 1. Пуств p = (p(i) : i G TV), q = (q(i) : i G TV)
и q > 0. Здесв и далее неравенства между функциями p > q понимаются поточечно: p(i) > q(i) П1')П i G JV.
Относительной энтропией (расхождением Кульбака - Лейблера) для функций p , q G А, q > 0, называется величина
Wllq ) = У к
p(i)ln ^дг. q(i)
Полагаем 0ln0 = 0.
Для анализа алгоритма нам потребуется следующее свойство относительной энтропии [6, лемма 4.11]:
Лемма 1. Пусть p , q , w G А, г де q > 0, w > 0 и q ^ 3 w для некоторого числа 3 > 0. тогда
Wllq ) С WIW +ln1.
—
Обозначим mt
Г ln J w(i,t)e rl(t,t)di - экспоненциально взвешенные потери на шаге c
т
-
t. Мт = mt mt - суммарные экспоненциально взвешенные потерн. Из того, что Х(у,у) t=i
является ^-экспопеппна.тыю вогнутой следует, что Н т С Мт-
Теорема 1. Пусть wt = w(i,t) u wt = w(i,t) - веса из процедур Loss Update и Mixing Update. Для любых t и 0 < s < t таких, что PS > 0, u для любого распределения q t = q(i, t) € А выполняется
d mt = J' q(i,t)l(i,t)di + 1(D(qf\wf) - D(qf\wt)) < c
d
-
< / q(i,t)l(i,t)di + 1 [ll( q t| w s) - D( q f\ w Д+1п-1Д . J V \ Ps /
c
Доказательство.
m t
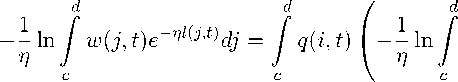
w(j,t)e ^’^dj
di =
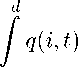
d
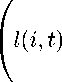
+ 11n e-11^ V
-
d
Pn I
q(i, t)l(i, t)di +
c
d
1 I q(i,t)
v J
c
V
⎛
In
c
e-^dj di =
^nKLt)
\
\
d f w(j,t)e-^l(^’t)dj c
di =
d
q(i, t)l(i, t)di +
c
d
w(i, t)
q(i,t) 1n
w(i,t)
c
di = I q(i,t)l(i,t)di + 1 (D( q f\ w f) - D( q f\ w ,t)) .
V c
Второе неравенство следует из леммы 1. □
3. Оценка регрета алгоритма смешивания апостериорных распределений на несчетном множестве экспертов
Стандартным методом доказательства оценки потерь алгоритмов, родственных МРР, является получение оценок вида
Т 1
Н т ^ ZL(q • l t ) + (D( q \wi) — D( q|lw т У) +(...) =
=1
= q • L + 1 (D(q\wi) - D(q\wт)) + (. ..), V где Нт - суммарные потери алгоритма, q € А - вектор коэффициентов выпуклой комбинации экспертов (вектор сравнения), lt - вектор потерь экспертов на шаге t, Lt - вектор суммарных потерь экспертов, D(.\.) - относительная энтропия, wi - веса алгоритма на шаге 1, wt - модифицированные веса алгоритма на шаге Т. Здесь (...) - дополнительные слагаемые, зависящие от постановки задачи. После этого отбрасывается неположительное слагаемое - 1D(q\wT) и оцениваетея величина, q • L + 4D(q\w1).
Мы предлагаем метод уточнения последней оценки при наличии дополнительной информации о суммарных потерях отдельных экспертов вида L(i) < Lmax(i), где £max(i) . j^ ^ [0;+то]. В случае отсутствия информации о суммарных потерях некото-
рого эксперта, будем полагать L max принять соглашения: 0 • (+от) = 0; e
(i) = +от. Итоговые оценки остаются верными, если
~ = 0.
Теорема 2. Пусть задана функция Lmax(i) : [с, d] ж [0; +го] и число у > 0. Пусть w1(i) = dd—c ~ равномерное распределение на отрезке [c,d]. Тогда минимум функционала q^)
1/(d — с)
di
F(q) = I Lmxd^di + ^(qlH) = ] Lmax(i)q(i)di + 1 ^ q(i)ln c c c на множестве А достигается на распределении
„-rfLmxW q = q(i) = -d------------- у e-rFmTHdj c и его минимальное значение равно
d minF(q) = - ln(d — с)--In I eT'rLm'di.
qeA ^ d
c
Доказательство. Сначала рассмотрим случай когда функция Lmax(i) принимает значение +от почти всюду. Тогда для любого распределения q первое слагаемое
d
I Lmax(i)q(i)di = +го,
c следовательно F(q) = +от. Это вырожденный случай, но можно формально считать, что функционал F(q) принимает нестрогий экстремум на любом q. Этот случай в дальнейшем будет соответствовать ситуации, когда у нас нет вообще никаких оценок на потери экспертов и, таким образом, не получится дать никакую оценку потерь Алгоритма 1.
Пусть теперь функция Lmax(i) принимает конечные значения на множестве положительной меры. Обозначим А С [с, d] подмножество отрезка [с, d], на котором Lmax(i) = +от. Тогда если q(i) > 0 на множестве В С А положительной меры, то первое слагаемое
d
I Lmax(i)q(i)di > I Lmax(i)q(i)di = +ro, следовательно F(q) = +от. Пошжив q(i) = 0 па множестве А ii задав произвольное q(i) вне этого множества, мы получим F(q) < +от. Таким образом, для того чтобы функционал F(q) принимал минимум, необходимо, чтобы
Vi : Lmax(i) = +ге ж q(i) = 0.
Это условие можно формально получить из (5), приняв во внимание соглашение е '^ = 0. Заметим, что выполнение условия (6) фактически означает рассмотрение всех интегралов в этой теореме на том подмножестве отрезка [с, d], на котором Lmax(i) < +от.
Обозначим У = ln J e^Lm^ dj = const, тогда c e-rLmax(i) ln q(i) = ln ---------------
J e- r Lmx(f)dj c
—dLmax(i) — У O Lmax(i) = — 1(ln q(i) + S). d
Рассмотрим произвольное распределение q G А, для которого выполнено условие (6).
Рассмотрим разность значений функционала F на распре делениях q и q:
F(q) - F(q) = d d d d
J L max^ q^di + 1 у q(i) ln(q(i)(d — c))di — У L max^ q^di - - У q(i) ln(q(i)(d — c))di = c c c c
d
= У ymax(i)(q(i) — q(i)) + | (q(i) In q(i) + q(i) ln(d — c) — q(i) In q(i) — q(i) ln(d — c))^ di =
c
d
= / ((—1(ln q(i)+s))(q(i)—q(i))+1(ln(d—c)) (q(i)—q(i))+1(q(i)ln q(i)—q(i) ln q(i)))di= c dd
= (|(ln(d — c) — S)) У (q(i) — q(i))di + d y(q(i) ln q(i) — q(i) ln q(i))di =
c
c dd
= const • I (q(i) — q(i))di +— I q(i) ln ^^-di.
J d Jq cc
d
Поскольку q и q распределения, то f (q(i) — q(i))di = 1 — 1 = 0, значит первое слагаемое c равно 0. Второе слагаемое равно 1 D(q||q) > 0.
Значит для любого распределения q G А, для которого выполнено условие (6), выполняется F ( q ) > F ( q ). Минимальное значение функционала получается простой подстановкой. Теорема доказана. □
4. Потери алгоритма смешивания апостериорных распределений на несчетном множестве экспертов
Теорема 3. Пусть потери экспертов на каждом шаге l(i,t) липшицевы по переменной i с константой Di D2. Пусть составной эксперт Е = (ii, Ai,...,ik, А^) несет сум-к мирные потери Lt(Е) = L(a-)(ij). Тогда потери Алгоритма 1 удовлетворяют оценке
1=1 3
НТ С LT(Е ) + ^+1 ln (pD i D 2 e(d — c)) + 2^±^ ln(T + 1). d d
Доказательство. Рассмотрим один из интервалов Aj и соответствующего ему эксперта ij. Так как потери экспертов на каждом шаге l(i,t) липшицевы по переменной i с константой D1D2, тогда l(i,t) С l(i j ,t) + DiD2|i — i j |. Тогда для суммарных потерь элементарных экспертов L (^ . )(i) на интервале Aj выполняется
L(a. )(i)= £ l(i,t) С £ l(i j ,t)+ £ DiD2|i — j j | = t e A . t e A . t e A .
= L (A . ) (i j ) + D1D2|i — j j |(tj — tj-1).
Рассмотрим промежуток [i j — 6 j ,i j + 6 j ] - окрестность точки i j размером d j G (0, d — c). Эта окрестность может не лежать полностью в отрезке [c, d], но хотя бы одна из ее половин [ij — ^ j ,i j ] или [ij ,i j + ^ j ] лежит в отрезке [c, d]. Обозначим эту половину [a j ,b j ], ее длина b j — a j = d j. Тогда на отрезке [a j , b j ] выполняется
L (A . ) (i)< L (A . ) (i j ) + D1D2|i — j j |(tj — tj-1)< L (A . ) (i j ) + D 1 D 2 (t j — t j - 1 )8 j .
Тогда на всем отрезке [с, d] выполняется
L(^,)« < L (i), (7)
где
L ^ ax(i) =
J Да,) (i j ) + D i D 2 (t j - t j - i )S j , (+“,
i G [a j , b j ];
i G [a j , b j ].
Рассмотрим последователвноств распределений qt = q(i,t),i G [с, d], t = 1 ...T, не меняющуюся внутри каждого интервала Aj, то еств для любых t,t‘ G Aj и любого i G [с, d] выполняется q(i,t) = q(i,t').
Оценим суммарные потери Алгоритма 1 с помощью теоремы 1. Для t = 1 выберем s = 0, тогда Д = 1. Тогда по неравенству (2):
d mi < / q(i, 1)l(i, 1)di + 1(P(qGw 1) — D(qi||w i)+ln1) . (S)
d
c
Для тех шагов t. где по происходили it;шсисиия распределения qt. то еств при t = ti ,...,tk, пола гаем s = t — 1, тогда Д* = Pt-i = 1 — at = ^-1. Тогда в силу неравенства (2) выполняется mt < I q(i,t)l(i,t)di + | ^D(qt||wщД — D(qt||wД + In -c
t
-
1)-
Для шагов t. где происходили изменения вектора (•равнения, то еств при t = t i ,... ,tk- полагаем s = 0, тогда Д* = Д 00 = at. = утру- Тогда в силу неравенства (2)
d
'^ ф.,^,)di + 1 (D(q,^о) . |w,+ В). Ш>
Сложим все эти неравенства. Одинаковые по величине и разные по знаку слагаемые внутри каждого интервала сократятся, для каждого интервала разбиения останутся только начальные точки со знаком плюс и конечные точки со знаком минус. Тогда для суммарных Т экспоненциально взвешенных потерь Мт = mt выполняется t=i
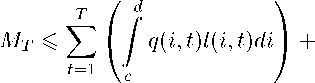
1 fe+i
+ ^ g (D(q^|wо) - D(q t j |w * + -i)) +
(И)
1 „ t 1 JA
+gln t—1 + d gl^ + 1).
Сначала оценим последние два слагаемых (13):
d
ln
t
t=2...T
*=В
t — 1
< 1 g In d ^
1 t=2...T
t
t — 1
= - ln T ; d
fe fe
- £ ha, + 1) c - Eln(T +1) = м ln(T +1).
' j=1 1 j=1 1
Оценим слагаемые (11) и (12). Для этого уберем неположительные слагаемые — 1 D( q tj ||w t j +1 - 1 ) и воспользуемся тем, что внутри каждого интервала A j распределение qt не меняется: q(i,t) = q(i,t j ) = qtj (i). Для суммарных потерь экспертов на интервале tj -i
A j Т(д. ) (i) = £ l(i,t) используем оценку (7): t=tj- i
£ ( / q(i,t)l(i,t)di ) + 1 £ (D(qij |w0) — D(qj |W T / 7 \ < £[J q(i,t)l(i,t)di] + - £ D(qt. ^wo)= k+i ь-i / 7 \ = £ £ I \ q(i,t)l(i,t)di\ + -£ D(qt. ||wo)= j=i t=tj—i \c J k+i / tj-i 7 1 k+i / tj-i 7 1 = 521 52 /q^(i)i(i,t)di + -D(qtj iiw0)1 = j=i t=tj—i { k+i / 7 i = £ I / qtj(i)L(^)(i)di + “D(qtjiiwo) I ^ j=i- < £ | /2 (i+r+di + 1 D(qfj |w2 j = i \c k+i = £ (Fj (q)) . (16) j=i d Для каждого j функционал Fj(q) = / qtj (i)Lmax(i)di + 1D(qtj ||w.o) из оценки (16) удо-c влетворяет условиям теоремы 2. Тогда на распределении1 ■6 i G [aj, bj ]; i G [aj, bj ] -riLmaaxti) q = q(i) = -d-------------- / e-^^di' c этот функционал принимает значение Fj (q) = - ln(d — c) — - In f e !'d+ (i)di = -- c = 1 ln(d — c) — 1 In / e-1(L(Aj)(ij)+D1 D2{tj-tj-1)Sj)di = -- a = 1 ln(d — c) — 1 In (ф • e-r'^j)(ij) • e-1D1D2^t-tj-1)sj) = = - ln(d — c)--In e rL(F)(ij)--In (bj • e-riD1D2(tj-tj-1)‘Sj^ = - -- = 1 ln(d — c) + T(Aj)(ij) — 1 In (bj • e-rD1D2(tj-tj-1)5j) . 'Это равномерное распределение па отрезке [aj,bj]. Последнее слагаемое принимает максимальное значение при 5j = rD^-y-D ' Т0Па F(q) = 1 ln(J - е) + Цд,у,) - 1 In (^^j — ^ • м) = = L^.((ij) + | In (r]D1D2e(d - c)) + | ln(tj - tj-1) С С L^((ij) + Г ln (rDiD2e(d - c)) + Г lnT. Тогда для выражения (16) выполняется к+1 к+1 / Е (Fj(q)) С Е j=1 j=1 v L^((ij) + r ln(rD1D2e(d - c)) + Г ln T^ = k+1 = Е (+м(iji)) j=1 + к+ ln (rD1D2e(d - c)) + + lnT = r r = Lt(E') +--— ln (rD1D2e(d - c)) +--— lnT. r r Подставим оценку (18) в (16) и сложим с неравенствами (14) и (15). Тогда из Нт С Мт и из оценки (13) получим Нтс Мтс Lt(E) + ^+1ln(rD1D2e(d - c)) + -+1ln T + 1 ln T + - ln(T + 1) С r r r r С Lt(E) + -+1 ln (rD1D2e(d - c)) + 2-+^ ln(T + 1). (19) r r Теорема доказана. □ Следствие. Регрет Алгоритма 1 по сравнению с составным экспертом удовлетворяет оценке Rt = O(k ln T), npuT ^w. Доказательство. Rt = Нт - min Lt(E) С —~— ln (rD1 D2e(d - c)) +--—— ln(T + 1) = E r r = C1(k + 1) + C2(k + 1) lnT = O(klnT), при T ^ №.□
5. Оценка регрета снизу В следующих теоремах предложены (адаптивно враждебные) стратегии Природы для разных сценариев проведения игры. Всюду в этом разделе все отклики yt будут лежать на отрезке [-1,1]. Пусть функция потерь Х^у) удовлетворяет (достаточно слабым и естественным) условиям а(у,у) = 0; +>У: |у - у| > 1 ^+ъу) > 1. В частности, этим условиям удовлетворяет квадратичная функция потерь А(у,у) = (у-у)2. Теорема 4 показывает, что даже если потребовать непрерывность функции f(i,t), но не потребовать ее липшицевость, то Предсказатель будет нести большие потери. Теорема 4. Существует такая стратегия Природы в игре 1, длящейся Т шагов, что на каждом шаге t предсказания экспертов f(i,t) непрерывны как функция i, но для любого поведения Предсказателя он будет нести суммарные потери не меньше Т, а один из экспертов будет нести потери 0. Доказательство. Обозначим все множество экспертов [с, d] как [ci,di]. Разделим этот отрезок на три части. Прогнозы экспертов на шаге t = 1 задаются следующим правилом: на левой трети отрезка f (г, t) = 1, на прав ой трети f (г, t) = —1, а на средней трети функция f(i, t) продолжается некоторым непрерывным образом, например линейно. После того как Предсказатель дал свой прогноз yt, Природа выбирает исход yt по правилу {1, если у < 0, —1, если yt > 0. Тогда потери Предсказателя на этом шаге не меньше 1. При этом либо все эксперты из левой трети отрезка [c1,d1], либо все эксперты из правой трети дали точное предсказание и несут потери 0, обозначим эту треть как [c2,d2]. На каждом следующем шаге t отрезок [ct, dt] снова делится на три части. Предсказания экспертов задаются правилом: на левой трети отрезка f(i,t) = 1, на правой трети f(i,t) = —1, а на средней трети, а также вне отрезка [ct,dt], функция f(i,t) продолжается некоторым непрерывным образом. После того как Предсказатель дал свой прогноз yt, Природа снова выбирает исход yt по правилу (20). Тогда Предсказатель снова несет потери не меньше 1. При этом снова эксперты из одной трети отрезка [ct,dt] дали точное предсказание и несут потери 0, обозначим эту треть как [ct+i,dt+i]. Таким образом, за Т шагов Предсказатель песет суммарные потери нс меньше Т. а все эксперты из отрезка [су+i,dT+i] несут потери 0. Теорема доказана. □ Теорема 5. Пусть заданы произвольные числа Di > (d-с) и k,m G ЗФ, т< log2 D1(d с) ■ Тогда существует такая стратегия Природы в игре 1, длящейся Т > km шагов, что 1) для любого t функция f (i,t) - липшицсва гго переменной i с константой Di: 2) существует составной эксперт Е, состоящий из k элементарных, который несет потери 0; 3) для любого поведения Предсказателя он будет нести суммарные потери не меньше km. Таким образом, регрет Предсказателя Ry = Ну — min Ту (Е) > km. Е Доказательство. Выберем 2т точек (экспертов): id = с + h '—" G [c,d], h = 1,..., 2т. 2m Рассмотрим конечные последовательности (ai, a2,..., am), все члены которых принимают значения или 1 ил и —1. Всего существует 2т таких последовательностей, сопоставим каждую из них одному из этих 2т экспертов. Разделим весь интервал прогнозирования 1.. .Т на k подынтервалов Ai,..., А^, каждый длиной не меньше т. В течение первых т шагов внутри каждого интервала Природа реализует следующую стратегию. Каждый из выбранных экспертов выдает члены своей последовательности в качестве прогнозов, то есть f (ih,n) = an. На остальных точках отрезка [с, d] функция f (i, t) продолжается кусочно-линейным образом. Так как расстояния между выбранными экспертами |ih+i — ihl = (с—) ^ вц—т = туу а разница между на-2 значенными значениями |f(ih+i,^) — f(ih,n)\ С 2, то такая кусочно-линейная функция является липшицевой с константой Di. После того как Предсказатель дал свой прогноз yt, Природа выбирает исход yt по правилу (20). Тогда на каждом из первых т шагов интервала Aj Предсказатель несет потери не меньше 1. При этом один из выбранных 2т экспертов на каждом шаге давал точное предсказание, обозначим этого эксперта ij. На остальных шагах игры все эксперты дают прогноз f (i,t) = 0, и Природа выбирает исход yt = 0. Тогда суммарные поте ри составного эксперта Е = (ii, Ai,... ,ik, Ak) равны 0, а суммарные потери Предсказателя не меньше кт. Теорема доказана. □ Заметим, что оценка снизу, полученная в теореме 5 не зависит от Т и, таким образом, асимптотически не совпадает с оценкой сверху из теоремы 3 при Т ^ от. Вклад работы заключается в следующем: • Предложено обобщение стандартного метода доказательства оценки потерь алгоритмов, родственных МРР, при наличии дополнительной информации о суммарных потерях отдельных экспертов. Ключевое утверждение сформулировано в теореме 2. • Предложено обобщение алгоритма смешивания апостериорных распределений на несчетное множество экспертов. • Теорема 3 дает оценку сверху регрета этого алгоритма. • Теоремы 4 и 5 дают оценки снизу для любого алгоритма, решающего эту задачу.
