Обработка текста с помощью нейросети в направлении авторства

Автор: Леонтьев Н.А., Саввинова А.А.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 5-1 (92), 2024 года.
Бесплатный доступ
В статье рассматривается задача обработки текста с помощью нейронных сетей для определения авторства. Актуальность данной темы обусловлена возрастающей ролью искусственного интеллекта в различных сферах, в том числе в области обработки естественного языка. Представлен практический пример реализации нейросетевого подхода к определению авторства текста с использованием библиотеки Keras Python на платформе Google Colaboratory. Описаны шаги по подготовке данных, создание обучающей и тестовой выборок, построения и обучения модели. Полученные результаты демонстрируют высокую точность идентификации авторства текстов, достигающую 95-98%.
Нейросеть, авторство, обработка, данные, текст
Короткий адрес: https://sciup.org/170205085
IDR: 170205085 | DOI: 10.24412/2500-1000-2024-5-1-249-253
Text processing with neural network in the direction of authorship
The article deals with the task of text processing using neural networks to determine authorship. The relevance of this topic is due to the increasing role of artificial intelligence in various fields, including natural language processing. A practical example of implementation of neural network approach to text authorship determination using Keras Python library on Google Colaboratory platform is presented. The steps of data preparation, creation of training and test samples, model building and training are described. The obtained results demonstrate high accuracy of text authorship identification, reaching 95-98%.
Текст научной статьи Обработка текста с помощью нейросети в направлении авторства
Благодаря развитию компьютерных статистическом анализе и методах машин-технологий появились новые методы ного обучения.
идентификации авторства, основанные на
Рис. 1. Методы идентификации автора
На рисунке 1 показаны основные методы определения авторства спорных текстов, предложенные как отечественными, так и зарубежными учеными, результаты которых были проверены другими исследователями.
Искусственные нейронные сети представляют собой упрощенную модель функционирования головного мозга [1].
Стандартная n-слойная сеть прямого распространения состоит из входного сенсорного слоя, (n-1) скрытых ассоциативных слоев и выходного слоя, соединенных
последовательно в прямом направлении и не содержащих связей между элементами
внутри слоя и обратных связей между слоями (рис. 2).
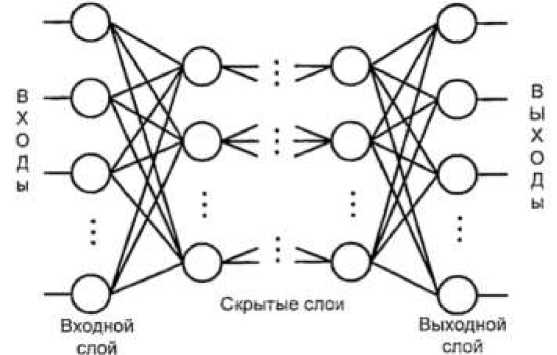
Рис. 2. Типовая структура сети прямого распространения
Входной слой принимает и передает входные сигналы на нейроны скрытого слоя. Каждый скрытый слой выполняет нелинейное преобразование линейной комбинации сигналов от предыдущего слоя. Выходной слой объединяет взвешенные сигналы последнего скрытого слоя [2].
Для достижения цели необходимо обучить нейросеть, предоставляя на вход данные, соответствующие обучающим примерам. В процессе обучения сеть использует взаимосвязи между нейронами (синаптические веса) для усвоения информации о предметной области. В итоге сеть запоминает примеры и может классифицировать
новые образцы, не участвовавшие в процессе обучения [3].
Для исследования были взяты тексты 6 авторов в *.txt, кодировка UTF8. Разделены на обучающую и проверочную выборку, т.е. на каждого автора по 2 текста. Анализ текста проведено с помощью простейшей сети в Colab с помощью библиотеки Keras на языке программирования Python.
Для загрузки текстов можно использовать более компактный код используя ‘(‘в качестве токена для определения нужных файлов:
wrlters_text“[]
tor files in os.llstdiri, J:
if ifiles.startswlth* (':
Файл: (Рэе Бродберри) Тестомя_8 вместе.txt длина: 86867 3
Файл: (О. Генри) Тестовая_20 вместе.txt длина: 349662
Файл: (Булгаков) О0учмцаят9 вместе.txt длина: 1765648
Файл: (Махе Фрай) Гестовам_2 внес’e.txt длина; 1278191
Файл: (Стругацкие) О6уч*<шая_5 вместе.txt длина: 2942469
Файл; (Стругацкие) Тестовая—2 вместе.txt длина: 704846
Файл; (Булгаков) Тесгоыя_2 вместе.txt длина: 875042
Файл: (О. Генри) 06ума<)щая_50 вместе.txt длина; 1049517
Файл: (КлифФ^рД-Саймак) Обучаошдя_5 внес те.txt длина: 1609507 Файл: (Макс Фрай) 06уч*ощая_5 вместе.txt длина: 3700010
Файл: (Рэй Брэдберри) Обуч»тая_22 вместе.txt длина: 1386454
Рис. 3. Чтение загруженных файлов
В каждом из двух списков содержатся тексты от каждого из 6 авторов для обучения и проверки модели.
Важным этапом для обеспечения высокого качества обучения нейронной сети является предварительная обработка дан-
ных. Для выполнения такой предобработки в библиотеке Keras применяется класс Tokenizer. С помощью класса Tokenizer
можно определять индекс слова в массиве, можем узнать в скольких массивах встречается слово и количество повторений [4].
print(tokenizer.word_index 'лиса‘■) Позиций/ индекс слова в массиве токенов print(tokenizer.word_docs[’лиса']) #в скольки источниках встретилось слово print(tokenizer.Hord_counts 'лиса‘ ^количество повторений слов
Рис. 4. Пример использования класса Tokenizer
После предварительной обработки довательность числовых индексов, ис-необходимо преобразовать текст в после- пользуя частотный словарь [5].
Статистика по обучающим текстам:
-
•Г*. - •;
words • •} printitTaterrwe по оОу*аам«м гесотв*!*)
Гу I in г акфа(laritrainlaxt | i > .i ' UatyUf«|X , t',, la згаШакг |1| , Чя-мыаь. , ь-лгилЫвгбХпМхвИИ-( . ub*
9jMb« •• ’nnctriiniextill)
■•ords •- l»n(traLfMprflmltNM[l])
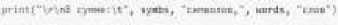
РППГГ ♦

t Г--И1,:1дьь1им| 1 , t , 1. ЧакТТахсЦ ; , -кики», , Iw Еа4«МагН|пМхвЦ1] , «yam •- ■ • | ЧаПТгкЧ 1 I I words •• la» •TwilH^dbdniasI 1 | pr|nt| - nS rfw^- r', l)F4Hj ‘гк-тмиа, , -nrdsj “rW
<тг«о««» no оо>ч»«дм теасташ
0, Гамра 1*0517 rawmoaoa, 115117
Саймак 1W9W7 CMMHIM4 221602 CMM tpa* 37***t* ClMB8MM4 SHU?# rann Ер«д4«Р* 13 864 54 tawauiaua, 166 841
* CH^e US»M5 CNMMOW, 3525W end#
{raiwciaKi по проаарочюм пакетам
0. l-нра JdMOJ rawuna^ 12M5 Сгрутацаи» 784646 сантилоп, 67212 слоа Сайма# 510 811 смчмпм4 44 2 58 слов ■*И Ш11Ч1 Гурков, 104445 спев 6р«#б«рп 86*673 г аятолла, 18*665 гл=а В c,w*o 4395225 СМВМП, 553779 СМ* Рис. 5. Статистика по обучающим текстам В статистике видно сколько символов и слов содержат тексты у каждого из авторов. Отдельно у обучающей группы текстов и отдельно у проверочной. ЯГи»^#»»- Лг'АйниСВЯ *ну« (♦’» (F»Hf lirwf i H? •odeldl. add* BotchMoraallution i •odel^l .eOdi^ropaut Л.З)J •nd-lOI .aW^Oense* i»‘* t-ainTett) g activatic*-'»Ia»^'I 1 •ode 101.' ctwi Г1 optimizer» adaa , less-‘cateporical.crMseHtropy, wtHc»-| accuracy’)) •Обучав* сеть на высюркс. сфоряаррва>«оЯ no Dag о/ words xTraiatl ►history - nodeiei.fittrTrainei. уTrain। epochc-je, bat ch_siie-126, хаИСат1йА_4ат*-' «TeetBl, /Test pit plot[history.History* accuracy' I, label-'Дола н-р-^ж ответов *• обучало* мабаре*) Рис. 6. Создание нейросети Нейронная сеть каждый раз обучается по-разному. Даже при равных исходных данных, может каждый раз выдавать разные результаты. В данном примере его точность равна 0.9873, при создании и более ранних прогонах, точность достигала 0.9987. £экй V1Й 114416 ]“—••••«••«••••••••••»••**•»! It Ям/idf l«r LMN accuracy: LSCT иИди: 1Л22 • valjcariq: Mill ДО|ДО шли I-.......................~; - 54 йв/sur - Ш» MW?. atu^t)! MJ* - ч1.1ам? 1Л51 - mUjcunq- • НИ Ьий 1'16 ЩД16 !**»•••••••••••«•••••••■•••■•) Ss Зйв/itit .us 9.W5 acaraq: 9.И6? m_lou: 9.456 • valjccsrK» Ы?й ЬкЯ^ 114<Ш ]м~'«''’"'«'-'^^ 5«Ля,Чир ДмгМБа асагжу: LKH иИви: 9.1665 valjcartq М1И Рис. 7. Обучение нейросети Было решено обучать нейросеть стандартным 20 эпохам. После каждой эпохи, нейросеть давали проверочную выборку для определения автора текста. Последний столбец показывает точность распознавания. Рис. 8. График точности распознавания Уже практически с первой эпохи обучения, нейросеть на обучающей выборке показывала 100% точность распознавания автора текста. После обучения, сети дава- ли тексты из проверочной выборки (тексты, которые не были включены в обучающую выборку) и точность его не падала 0.9563, а максимальная достигала 0.9873.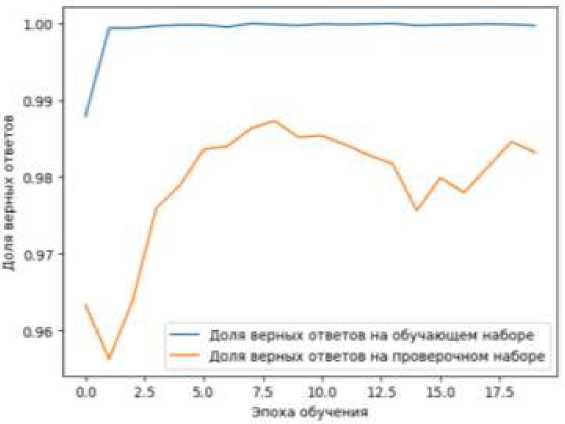
Список литературы Обработка текста с помощью нейросети в направлении авторства
- Романов, А. С. Методика и программный комплекс для идентификации автора неизвестного текста: специальность 05.13.18 "Математическое моделирование, численные методы и комплексы программ": диссертация на соискание ученой степени кандидата технических наук / Романов Александр Сергеевич. - Томск, 2010. - 149 с. EDN: QEWIEF
- Леонова А.В., Леонова И.В. Определение авторства текстов на основе подхода n-грамм // Научное обозрение. Технические науки. - 2018. - № 6. - С. 37-40. EDN: YVRGGL
- Парамонов, А.И. Модификации методов машинного обучения для решения задачи идентификации автора текста / А.И. Парамонов, И.А. Труханович // Информационно-коммуникационные технологии: достижения, проблемы, инновации (ИКТ-2022): Сборник материалов II Международной научно-практической конференции, Полоцк, 30-31 марта 2022 года. - Новополоцк: Учреждение образования "Полоцкий государственный университет имени Евфросинии Полоцкой"=Установа адукацыi "Полацкi дзяржаўны унiверсiтэт iмя Еўфрасiннi Полацкай", 2022. - С. 78-81. EDN: GQUIMD
- Demidovich I. et al. Processing Words Effectiveness Analysis in Solving the Natural Language Texts Authorship Determination Task // 2021 IEEE 16th International Conference on Computer Sciences and Information Technologies (CSIT). - IEEE, 2021. - Т. 2. - С. 48-51. EDN: ZINHSA
- Trukhanovich I., Paramonov A. Multispecies Ensemble Architecture For Texts Authorship Classification // 2023 7th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT). - IEEE, 2023. - С. 1-6.
