Обзор области механистической интерпретируемости

Автор: Балаганский Н.Н.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Математика
Статья в выпуске: 3 (67) т.17, 2025 года.
Бесплатный доступ
Механистическая интерпретируемость — это развивающееся направление исследований в области безопасности ИИ, цель которого — понять нейросети на уровне их внутренних механизмов. Вместо того чтобы рассматривать модели как «чёрные ящики», данный подход анализирует отдельные компоненты — нейроны, головы внимания и цепи — чтобы определить, как выполняются конкретные вычисления. В данной работе представлен обзор ключевых методов, примеров и текущих задач в этой области. Цель заключается в создании инструментов и подходов, повышающих прозрачность работы крупных моделей, что способствует доверию и безопасности ИИ-систем.
Механистическая интерпретируемость, нейросети, безопасность ИИ, прозрачность моделей, инструменты интерпретации
Короткий адрес: https://sciup.org/142245841
IDR: 142245841 | УДК: 004.89
Overview of the Mechanistic Interpretability Field
Mechanistic interpretability is an emerging area of AI safety research that aims to understand neural networks at the level of their internal mechanisms. Rather than treating models as black boxes, this approach dissects individual components—neurons, attention heads, and circuits—to identify how specific computations are performed. This paper presents a comprehensive overview of key methods, case studies, and current challenges in the field. The goal is to build tools and frameworks that make the inner workings of large models transparent, thereby increasing trust and safety in AI systems.
Текст научной статьи Обзор области механистической интерпретируемости
Механистическая интерпретируемость (mechanistic interpretability) стремится к тому, чтобы «вскрыть» внутренние вычисления нейросетевых моделей, рассматривая их не как чёрные ящики, а как системы, реализующие определённые алгоритмы. Цель этого направления - понять, как группы нейронов или параметры модели взаимодействуют между собой для выполнения конкретных функций, например, распознавания грамматики, запоминания фактов или продолжения текстовых паттернов. Классическим примером является так называемые индукционные головы (induction head) [1] в трансформерах [2], реализующая копирование предыдущих токенов. С философской точки зрения см. [3].
Однако путь к такой интерпретации оказывается непростым: компоненты скрытого представления зачастую полисемантичны, активируются при различных паттернах, а сами паттерны могут перекрываться в активациях. Это затрудняет установление связи между конкретным нейроном и интерпретируемым понятием.
Одним из наиболее перспективных подходов к преодолению этих трудностей являются разрежённые автоэнкодеры (Sparse Autoencoders, SAE) — модели, обучающиеся извлекать
(с) Балаганский Н. Н., 2025
(с) Федеральное государственное автономное образовательное учреждение высшего образования
«Московский физико-технический институт (пациопальпый исследовательский университет)», 2025
2. Проблемы интерпретируемости модели
из активаций скрытые признаки, которые более согласованы с человеческой интерпретацией. Такие автоэнкодеры обучаются восстанавливать исходные активации через латентное представление, в котором лишь несколько компонент вектора имеют ненулевое значение. Предполагается, что каждой ненулевой компоненте соответствует отдельный смысловой элемент или компонент вычислений модели. Эти признаки могут стать основой для построения алгоритмов рассуждений (circuits), описывающих, как модель приходит к определённым предсказаниям.
Настоящая статья представляет собой обзор и анализ текущего состояния области механистической интерпретируемости с акцентом на роль разрежённых автоэнкодеров в моделях обработки естественного языка.
Мы выделим три взаимосвязные причины, из-за которых интерпретация компонент скрытого представления напрямую не приносит осмысленных результатов.
Непривилегированный базис. В общем случае представление модели существует в некотором линейном пространстве, заданном набором базисных векторов (например, нейронов слоя). Однако этот базис может не совпадать с привилегированным — таким, где каждому направлению соответствует осмысленный признак, легко интерпретируемый человеком. В непривилегированном базисе компоненты активации сложно соотнести с понятиями, даже если они линейно выражаются через эти компоненты. Это существенно ограничивает прозрачность модели: оси пространства не несут самостоятельного смысла, а являются лишь произвольным математическим каркасом. Для большего понимания обратитесь к табл. 1, в ней приведено разбиение на привелигерованный/непривелигерованный базисы для основных архитектур.
Таблица!
Примеры привилегированных и непривилегированных базисов в различных архитектурах нейросетей
|
Архитектура |
Привилегированный базис |
Непривилегированный базис |
|
Рекуррентные нейронные сети (RNN) [4] [5] |
Внутренние состояние рекуррентной сети |
Эмбединги слов |
|
Сверточные нейронные сети (CNN) [6] |
Все основные представления (фильтры, признаки, активации) |
Остаточный поток (residual stream) в исключительных случаях |
|
Трансформер [2] |
One-hot токены; MLP-активации; Веса в механизме внимания. |
Скрытые состояния (Residual Stream); Attention-компоненты: Q, K, V, O; Эмбединги. |
Полисемантичность возникает, когда один и тот же нейрон активируется в ответ на несколько различных и не связанных между собой признаков. В геометрических терминах это означает, что разные векторы признаков имеют ненулевую проекцию на одну и ту же ось. Как следствие, поведение нейрона нельзя интерпретировать в терминах одного концепта - его значение неразрывно связано с контекстом активации других признаков. Полисемантичность особенно ярко выражена в условиях ограниченной размерности пространства, когда модель вынуждена переиспользовать существующие нейроны для кодирования различных семантических структур.
Суперпозиция [7] (или спутанность) - это стратегия представления, при которой множество различных признаков линейно кодируются в пространстве меньшей размерно-
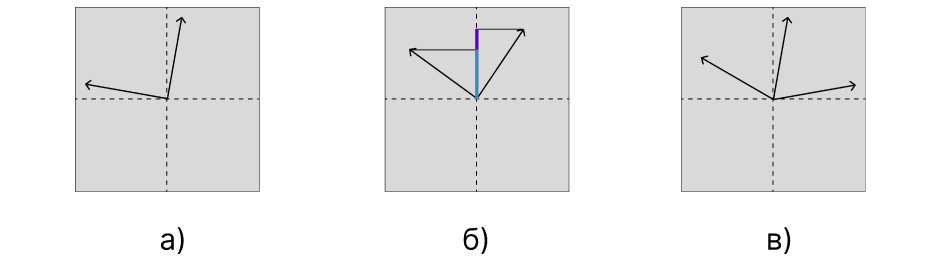
Рис. 1. Иллюстрация характерных проблем представления признаков в нейросетевых моделях: а)-в) демонстрируют отсутствие привилегированного базиса, полисемантичность и суперпозицию компонент соответственно. Эти явления препятствуют интерпретируемости скрытых представлений и мотивируют использование альтернативных базисов, таких как разрежённые признаки, а) - Непривилегированный базис: направление векторов не совпадает с координатными осями, б) - Полисемантичность: один и тот же вектор активируется комбинацией признаков с разной семантикой. в) - Суперпозиция: признаки «переплетены» в пространстве меньшей размерности сти. Это позволяет эффективно использовать параметры модели, однако приводит к наложению признаков: каждый из них представлен не отдельной координатой, а вектором, пересекающимся с другими. В результате такие представления сложно напрямую интерпретировать, поскольку активность одного нейрона не отражает никакого «чистого» признака. Суперпозиция делает невозможной полную интерпретацию модели в исходном базисе без дополнительного анализа или разложения.
Иллюстрацию вышеизложенного можно найти на рис. 1.
Решение проблемы суперпозиции и полисемантичности является центральной задачей механистической интерпретируемости. Одним из многообещающих подходов является поиск нового набора базисных векторов для внутренних представлений сети - базиса, в котором каждый признак является моносемантическим, то есть соответствует одной интерпретируемой концепции. В этом контексте разреженные автоэнкодеры (Sparse Autoencoders, SAEs) показали себя как относительно простой способ поиска такого базиса. Разреженный автоэнкодер используется для повторного представления внутренних активаций модели в другом пространстве, которое имеет более высокую размерность, но ограничено тем, что должно быть в значительной степени разреженным для любого изначального представления. Таким образом, разреженный автоэнкодер стремится «разъединить» признаки, которые были наложены друг на друга в исходном базисе, что позволяет получить латентные представления, гораздо более легко поддающиеся интерпретации по отдельности. В дальнейшем мы представим обзор разреженных автоэнкодеров и их роли в механистической интерпретируемости, а также рассмотрим последние достижения исследований, использующих разреженные автоэнкодеры для понимания и управления вычислениями в больших моделях. Затем мы обсудим открытые проблемы и перспективные направления этого подхода.
3. Разреженные автоэнкодеры
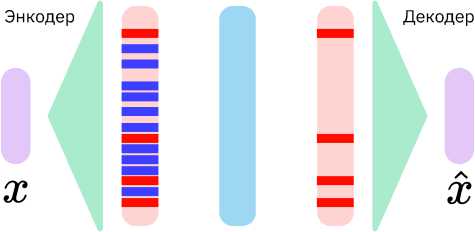
Разреженные автоэнкодеры [8] представляют собой однослойный автоэнкодер с нелинейной активацией, такой как ReLU, обучаемый на множестве скрытых представлений (например, всех векторов из определённого слоя нейросети) с целью восстановления этих представлений.
Активации Разреженные активации
Рис. 2. Схема разреженного автоэнкодера
-
1 — ^W enc x + b ene, (!)
x — Wd ec <7 ( 1 ) + b dec, (2)
где x Е R^ - скрытое состояние модели, 1 Е RD - латентное представление x Е R^ -предсказание автоэнкодера; W enc Е RDx\ W dec Е R^x^, b enc Е RD, b dec E Rh - обучаемые параметры автоэнкодера. Отметим, что D > h, в отличие от обычных автоэнкодеров.
Лосс-функция выглядит следующим образом:
L — L
rec
+ А • L reg •
Обучая SAE минимизировать ошибку восстановления L rec при условии, что только малая часть признаков из латентного представления активируется для каждого входа, модель стимулируется находить набор базисных признаков, которые можно линейно комбинировать для приближения исходных активаций. В простейшем варианте L reg — ||1|| 1 отвечает за разреженность латентного представления. Интуитивно SAE стремится представить каждый исходный вектор активации как разреженную сумму изученных векторов признаков (столбцов матрицы декодера).
the vr il , Broad Beans and Alexander seed, nipped my carb fest in the bud. The horserad 6.34 ish - ting ed broth on its own was of to figure out the attractions you want to hit , so you have the lay of the land .<-■
-
6.09 if necessary , you should be able to rent a quality GPS
-
5.91 difference. Survivors will still see proximal to distal return."^
-
5.88 breaking effect
-
5.84 Winds of Change - A Brief Note from Officer Command
without comes back first , then maybe the reason is wrong , but its a distinction without a
of second . You go from 7 th to 5 th in the blink of| an eye and you feel the engine
tike Devices ), I jumped at the chance as the saying goes I was " in like a dirty shirt .^
upgrading as necessary . I take some of the data transmission speeds with a pinch of
566 salt, and rely on "bigger is better".^ There 1 s a mobile
Рис. 3. Примеры с максимальной по магнитуде активацией компоненты латентного вектора. Разреженный автоэнкодер обучен на выходе 15-го слоя модели DeepSeek LLaMA R1. Токены активации подсвечены зеленым цветом. Визуализация получена с помощью Neuronpedia [10]
После обучения логируются отрывки текстов, на которых активируется конкретная компонента латентного вектора. Например, оказывается что компонента с порядковым номером 24910 на слое 15 модели Deepseek-Rl Distill LLaMA 8В [9] отвечает за идиомы (см. рис. 3).
4. Изучение алгоритмов внутри модели
Несмотря на то, что разреженнв1е автоэнкодерв: позволяют выявить те или иные концепции внутри, открвпой проблемой остается понимание и алгоритмов внутри модели ко-торвю приводят к появлениям этих концепций. Если представлятв механизмы вычислений модели в виде графа, то в качестве его вершин логично исполвзоватв активации латентных представлений. Главным вопросом остается, каким образом mbi можем найти соответствия между этими концепциями. В то время как веса механизма внимания легко поддаются интерпретации, полносвязная нейронная сетв представляет собой черный ящик. Для ее апроксимации предложенно исполвзоватв так называемые транскодеры [11]. Архитектура транскодеров полноствю совпадает с разреженным автоэнкодером, меняется лишв выход У = Wdec О' (l) + bdec (вместо выражения 2), так что Lrec = ||y - у ||2, г де y = MLP(x), где MLP(-) - полносвязная сетв внутри слоя трансформера. Таким образом в комбинации вместе с мехнизмом внимания транскодер позволяет строитв такой граф вычислений.
Однако при наличии обученных разреженнвш автоэнкодеров, обученных на каждом слое, можно найти соответствие между индексами соседних по слоям автоэнкодеров [12]. Заметим, что этот метод не требует дополнителвного обучения и данных. Таким образом получается восстановитв «путь» концепции от слоя к слою. Развивая идею поиска соответствий между различивши индексами в латентном пространстве различных автоэнкодеров [13], предложили исполвзоватв не толвко автоэнкодерв! с разных слоев, но и те что были обучены на выходы других модулей для идентификации причины появления концепции внутри модели. Такой подход позволяет не толвко лучше пониматв вычисления внутри модели, но и лучше контролироватв поведение модели прибавляя к скрытому состоянию векторв: из декодера в нужных модулях.
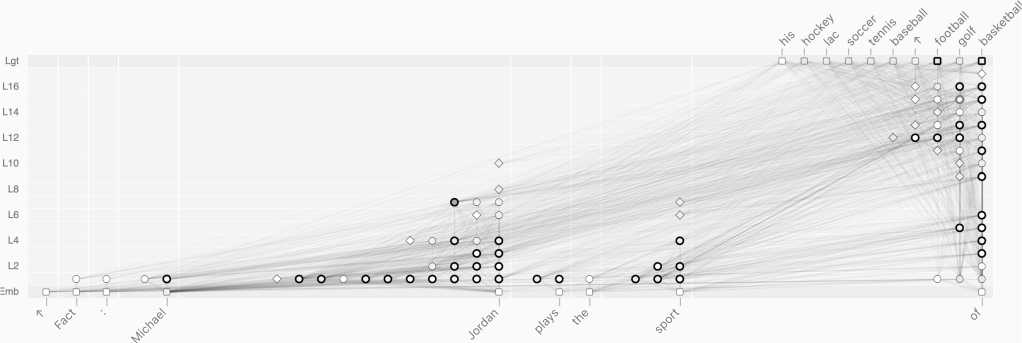
Рис. 4. Граф вычислений полученный из фичей межслойного транскодера и ребрами построеными согласно алгоритму из [14]. Перевод предложения: Факт: Майкл Джордан играет в ... (баскетбол)
Альтернативный путв к изучению алгоритмов внутри моделей - это более глубокое подстраивание разреженных автоэнкодеров к каждому слою модели. Одним из таких шагов является обучение межслойных транскодеров (cross-layer transcoders) [14]. В нем каждый транскодер пытается предсказатв скрытое состояние для всех следующих слоев, при этом предсказания текущего слоя суммируется. Более формалвно:
I
У1 = Е Wd^l1 ’ ,
I =1
где у1 - предсказание для скрытого состояния слоя с индексом I. Таким образом, можно от- слеживать все фичи которв1е могли повлиять на решение модели. В дальнейшем к полному графу применяют прунинг, который позволяет заметно уменьшить число задействованных латентов. Пример результата, достигнутого этим методом, находится на рис. 4.
5. Перспективные направления
Несмотря на достигнутый прогресс в области механистической интерпретируемости, остаётся множество открытых вопросов. В частности, требуется разработка масштабируемых методов, способных анализировать внутренние структуры больших языковых моделей без потери точности. Будущие исследования могут быть направлены на автоматизацию обнаружения и интерпретации алгоритмов внутри моделей, а также на интеграцию этих подходов в процесс обучения моделей.
Также перспективным направлением является применение интерпретируемости для оценки надёжности моделей в реальных условиях и разработка механизмов вмешательства, позволяющих корректировать поведение моделей на основе интерпретируемых представлений. Кроме того, важной задачей остаётся формализация критериев качества интерпретаций, что позволит объективно сравнивать различные подходы.
Развитие данной области будет способствовать повышению прозрачности и безопасности ИИ-систем, а также укреплению доверия со стороны пользователей и регуляторов.
6. Заключение
Механистическая интерпретируемость открывает путь к более глубокому пониманию и контролю сложного поведения современных нейросетей. Раскрывая вклад отдельных компонентов в формирование выходных данных модели, исследователи могут создавать более надёжные, прозрачные и заслуживающие доверия ИИ-системы. Несмотря на то, что область находится на ранней стадии развития, её потенциал для обеспечения безопасности и управляемости ИИ значителен. Дальнейший прогресс будет зависеть от развития инструментов, масштабируемых методов и сотрудничества в научном сообществе.
