Оценивание степени семантической близости слов посредством визуализации их векторного представления

Автор: Михайлин Сергей Игоревич
Рубрика: Управление сложными системами
Статья в выпуске: 1, 2020 года.
Бесплатный доступ
Установление семантической близости между набором слов является важной задачей, решение которой позволит продвинуться в ряде направлений, связанных с коммуникацией и передачей информации. Для выявления семантической близости слов предлагается использовать визуализацию их векторного представления с последующей интерпретацией. Описан алгоритм предобработки исходного текста для достижения необходимого результата.
Векторизация, нейронные сети, семантика, семантическая близость, визуализация векторов
Короткий адрес: https://sciup.org/148309066
IDR: 148309066 | УДК: 519.25+004.8 | DOI: 10.25586/RNU.V9187.20.01.P.093
Estimation of the degree of semantic proximity of words by means of visualization of their vector representation
Establishing semantic proximity between a set of words is an important task, the solution of which will allow us to advance in a number of areas related to communication and information transfer. To identify the semantic proximity of words, it is proposed to use the visualization of their vector representation with subsequent interpretation. The algorithm of preprocessing the source text to achieve the desired result is described.
Текст научной статьи Оценивание степени семантической близости слов посредством визуализации их векторного представления
В век информатизации множество людей обменивается информацией, будь то устные или письменные сообщения, передача изображения или видео. При формировании сообщения, которое впоследствии будет отправлено адресату для последующей интерпретации, в него закладывается основная мысль. Однако само понятие смысла до сих пор не имеет однозначного строгого определения в силу сложности этого понятия, нашедшего свое формальное отображение в термине «семантика».
Нередко звучание и написание двух разных слов существенно расходится, но при этом их смысловое содержание может в значительной степени совпадать. Тем не менее полная идентичность понятий может быть достигнута только в случае их абсолютного совпадения. Например, слова «тонкий» и «стройный» сильно отличаются друг от друга с точки зрения фонетики, более того, они не являются синонимами, но заложенная в них мысль имеет определенное сходство.
Если научиться определять у некоторых наборов слов степень их взаимного семантическое различия, то это позволит приблизиться к пониманию и формализации понятия семантики как таковой.
В рамках настоящей работы предпринята попытка построения метода измерения степени семантического различия языковых конструкций на основе методологии визуализации векторного представления (см., например: [4; 5; 6]). Это может позволить продемонстрировать в явном виде семантическое сходство или различие между двумя и более словами и/или предложениями.
Векторизация текста
Сегодня, когда нужную информацию можно найти на множестве сайтов или запросить у своего коллеги через мессенджер, пожалуй, основным форматом передачи информации по-прежнему остается текст. Всякий письменный текст представляет собой определенную последовательность слов и символов, а изменение их порядка может повлечь за собой изменение смысла. Это означает, что определенная последовательность слов формирует контекст, который становится необходимым для адекватной интерпретации сообщений. Таким образом, разные слова, которые встречаются в одних и тех же местах текста, при похожих контекстах могут иметь существенно близкое смысловое значение.
Михайлин С.И. Оценивание степени семантической близости слов... 95
Поскольку зрительное восприятие окружающего мира человеком является наиболее эффективным, представляется целесообразным визуализировать семантическое сходство (различие) через градации цветовой шкалы. Для реализации такого подхода необходимо перейти к векторному пространству в некотором характеристическом базисе, элементами которого являются слова.
Подход, при котором дискретные величины переводятся в непрерывные векторы, в английской литературе носит название embedding [4], но в русском языке он не имеет единого, устоявшегося названия, поэтому в рамках настоящей статьи будет использоваться термин векторизация.
Рассмотрим простейший случай векторизации предложений. Длиной вектора в таком пространстве может являться количество существующих слов в соответствующем алфавите, а областью значений каждой компоненты вектора является множество {0, 1}, где единица означает появление слова в предложении, а нуль – его отсутствие. Как меру схожести двух векторов можно использовать косинусное расстояние:
cos _ similarity = 1 —
AB
AB .
В таком случае два предложения, представленные двумя множествами слов, пересечение которых содержит половину используемых слов, будут иметь схожесть ~50%. Аналогично можно поступить со словами, для которых вектор будет представлен длиной, равной количеству букв в алфавите. К сожалению, такой подход не учитывает порядок слов (букв), и наличие частично одинаковых слов (букв) в предложениях (словах) не гарантирует выявления их семантической близости.
Отсюда следует, что для корректного выполнения процедуры векторизации в рассматриваемом случае необходимо использовать некоторый набор эвристических правил:
-
1. Необходимо учитывать порядок следования слов. Множество слов, которые пред-
- шествуют определенным словам в предложении или следуют за ними, называют его контекстом. Формально, если предложение P представлено как набор слов с определенным порядком P = { w 1,w 2, ^.,wn}, то контекстом С, например, для слова w. является предложение без этого слова C= P/wi.
-
2. Для осуществления векторизации необходимо учитывать и тот факт, что некоторые слова являются служебными частями речи или не имеют своей ярко выраженной семантики (например, такие части речи, как союзы, предлоги), поэтому их необходимо исключить из контекста.
-
3. Поскольку одинаковые слова в предложении могут иметь разное окончание, необходимо провести процесс лемматизации – приведения слова к лемме – «нормальной» форме [3]. Например, слово «бежал» следует преобразовать в «бежать», а «кошками» – в «кошка».
Зачастую контекст ограничивают «окном» определенной длины, поскольку далеко отстоящие слова могут не оказывать влияния друг на друга, причем как слева, так и справа от зафиксированного слова берут одинаковое количество слов, т.е. n /2 (если это возможно). Например, возьмем предложение «Утром кофе помогает взбодриться» и ограничим длину окна двумя словами. Тогда получится следующий набор слов и соответствующих контекстов (табл.).
Набор слов и соответствующих контекстов предложения «Утром кофе помогает взбодриться»
|
Слово |
Контекст |
|
Утром |
Кофе помогает |
|
Кофе |
Утром помогает |
|
Помогает |
Кофе взбодриться |
|
Взбодриться |
Кофе помогает |
96 в ыпуск 1/2020
Метод word2vec
Для предварительной обработки текста подходящим способом векторизации выглядит алгоритм word2vec, который формально определяется как способ перевода слов из словесного пространства в векторное [2; 5]:
word 2 vec : W → V .
Важнейшим свойством данной модели является то, что слова, встречающиеся в похожих контекстах, имеют схожие векторы (близость определяется косинусной мерой). Поскольку алгоритм реализуется в виде нейронной сети, а количество параметров велико, найти решение становится возможным только с помощью численных методов. Поэтому для обучения сети используется метод обратного распространения ошибки на основе градиентного спуска [1].
Алгоритм word2vec может работать в двух вариантах:
-
1. Common Bag of Words (CBoW). При обучении модель использует контекст слова как входное значение и выдает наиболее подходящее для этого контекста слово.
-
2. Skip-Gram. Является инвертированной моделью CBoW, т.е. на основе входного слова модель предлагает наиболее вероятный контекст.
На рисунке 1 представлен общий вид модели word2vec для работы в режиме CBoW. На вход модели поступает С векторов, представляющих собой контекст.
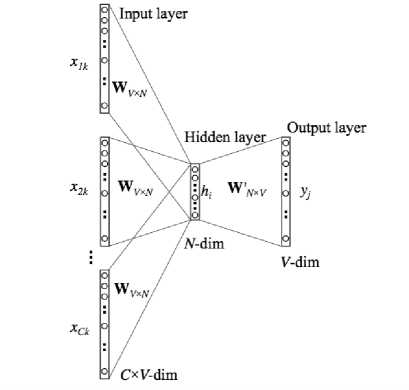
Рис. 1. Общий вид модели word2vec для работы в режиме CBoW
Михайлин С.И. Оценивание степени семантической близости слов... 97
Здесь x 1 k , x 2 k , … , xCk – входные слова (контекст) размерности V-dim ; hi – скрытое (латентное) представление слова в виде вектора размерности N-dim ; yi – вероятность появления i -го слова в таком контексте.
Для обучения модели и реализации векторизации использовались библиотеки gensim, реализующая модель word2vec, и nltk, с помощью которой обрабатывался исходный текст для обучения.
Визуальная оценка семантического сходства слов
Для визуализации, предлагаемой в настоящей работе, нет необходимости использовать именно CBoW или Skip-Gram, поскольку наибольший интерес представляет именно промежуточное представление слов (в виде векторов), которые формируются при обучении самой модели.
Поскольку слова, имеющие схожий контекст, имеют и близкую семантику, то становится возможным визуализировать такие представления следующим образом:
-
1. Применяя алгоритм word2vec, представить слово w в пространстве R n .
-
2. Начертить горизонтальную полосу определенной толщины, функция которой будет состоять в отображении векторов слов с помощью цветовой палитры.
-
3. Разбить полосу на n равных отрезков, количество которых соответствует длине векторов слов (из эвристических соображений взято n = 40).
-
4. Сопоставить каждой компоненте вектора в порядке их следования отрезок на полосе.
5. Закрасить отрезки в соответствии с выбранной палитрой цветов, в которой каждый определенный цвет характеризует определенное число. В нашем случае числу 0 поставим в соответствие черный цвет, числу 3 – темно-серый, а –3 – светло-серый. Тогда числу 2, например, будет соответствовать темный оттенок серого, поскольку число 2 находится между числами 0 и 3.
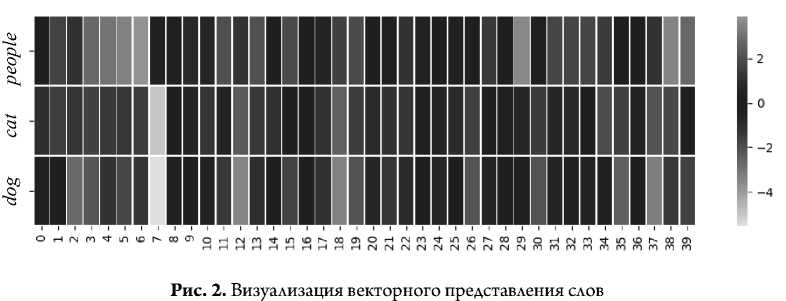
На рисунке 2 представлен пример визуализации векторов слов people, cat и dog. Такую визуализацию можно интерпретировать, в частности, следующим образом:
-
• компоненты с номерами 3, 6, 7, 13, 17, 26, 27, 30, 32, 35, 38 векторов «cat» и «dog» выглядят в цветовом отношении значительно похожими друг на друга и при этом существенно отличающимися от слова «people». Можно предположить, что эти компоненты
98 в ыпуск 1/2020
отображают (кодируют) нечто общее в смысловом отношении между двумя словами, которые, в частности, представляют два разных вида домашних животных;
-
• компоненты 8, 16, 36 во всех трех случаях имеют черный цвет: их значение близко к нулю, поскольку векторное представление для рассматриваемых слов слабо задействует данные компоненты;
-
• компонента 22 имеет близкие оттенки темно-серого цвета во всех трех словах, что, по-видимому, кодирует связь между домашними животными и человеком.
Как следует из анализа рисунка 2, предлагаемый способ визуализации в принципе позволяет оценить степень семантической близости слов. В частности, конкретный пример на рисунке 2 позволил продемонстрировать, что степень взаимной семантики пары слов «cat» и «dog» ощутимо больше, чем для каждой из них в сочетании со словом «people». Однако некоторые компоненты похожи во всех трех случаях, что можно интерпретировать как отражение связи человека с домашними животными.
Хотя смысловое значение компонент векторов для нас остается неясным (что обусловлено использованием сетевой модели), но на основе общей картины различия и сходства в смысловом содержании слов проявляется с очевидностью.
Заключение
Данные относительно семантической связи слов, полученные на основе цветовой визуализации их векторов, показывают, что такой подход, соответствующий наиболее полному отображению окружающего мира в нашем сознании, позволяет обеспечить разнообразие нюансов семантического сравнения языковых конструкций. Простота выполнения и наглядность сообщают предложенному методу признаки практической полезности.
Автор благодарит профессора И.С. Клименко за полезное обсуждение.
Список литературы Оценивание степени семантической близости слов посредством визуализации их векторного представления
- Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере. Новосибирск: Наука, 1996. 276 с.
- Золотарев О.В., Шарнин М.М., Еромасова А., Тезадова Ф.М. Современные подходы к обработке многоязычных текстов, основанные на методах дистрибутивной семантики // Сборник трудов международной научной конференции по физико-технической информатике - СРТ2018 (Пущино, 28-31 мая 2018 г.). Протвино, 2018. С. 43-47.
- Camacho-Collados J., Mohammad T.P. On the Role of Text Preprocessing in Neural Network Architectures: An Evaluation Study on Text Categorization and Sentiment Analysis // Cornell University. URL: https://arxiv.org/abs/1707.01780 (date of the application: 23.08.2018).
- Mikolov T., Chen K., Corrado G., Dean J. Efficient Estimation of Word Representations in Vector Space // Cornell University. URL: https://arxiv.org/abs/1301.3781 (date of the application: 16.01.2013).
- Mikolov T., Sutskever I., Chen K., Corrado G., Dean J. Distributed Representations of Words and Phrases and Their Compositionality // Cornell University. URL: https://arxiv.org/abs/1310.4546 (date of the application: 16.10.2013).
- Molino P., Wang Y., Zhang J. Parallax: Visualizing and Understanding the Semantics of Embedding Spaces via Algebraic Formulae // Cornell University. URL: https://arxiv.org/pdf/1905.12099.pdf (date of the application: 27.01.2020).
