On usage of machine learning for natural language processing tasks as illustrated by educational content mining

Author: Melnikov A.V., Botov D.S., Klenin J.D.
Journal: Онтология проектирования @ontology-of-designing
Section: Методы и технологии принятия решений
Article in issue: 1 (23) т.7, 2017.
Free access
In this paper, we review most popular approaches to a variety of natural language processing (NLP) tasks, primarily those, which involve machine learning: from classics to state-of-the-art technologies. Most modern approaches can be separated into three rough categories: ones based on distributional hypothesis, those extracting information from graph-like structures (such as ontologies) and the ones that look for lexico-syntactic patterns in text documents. We focus mainly on the former of the three. Before the analysis can even begin, one of the important steps in preparation stage of NLP is the task of representing words and documents as numeric vectors. There exists a variety of approaches from the most simplistic Bag-of-Words to sophisticated machine learning methods, such as word embedding. Today, in the task of information retrieval the best quality for both English and Russian languages is achieved by approaches based on word embedding algorithms, trained on carefully picked text corpora in conjunction with deep syntactic and semantic analysis using various deep neural networks. A big variety of different machine learning algorithms is being applied for NLP tasks such as Part-of-Speech-tagging, text summarization, named entity recognition, document classification, topic and relation extraction and natural language question answering. We also review possibilities of applying these approaches and methods to educational content analysis, and propose the novel approach to utilizing NLP and machine learning capabilities in analyzing and synthesizing educational content in a form of a decision support systems.
Machine learning, natural language processing, educational data mining, semantic similarity, deep learning, neural networks
Short address: https://sciup.org/170178741
IDR: 170178741 | UDC: 004.855 | DOI: 10.18287/2223-9537-2017-7-1-34-47
Об использовании машинного обучения в задачах обработки естественного языка на примере анализа образовательного контента
Рассмотрены наиболее популярные подходы к различным задачам обработки естественного языка (NLP), преимущественно использующие машинное обучение: от классических до передовых технологий. Большую часть подходов можно разделить на три подмножества. В одном - используют гипотезу дистрибутивной семантики, в другом - информацию из графовых баз знаний (например, онтологий), и в третьем - анализируют лексико-синтаксические шаблоны в документах. Основной фокус статьи на первом из этих подходов. Один из наиболее важных подготовительных шагов NLP - это задача представления документов в виде числовых векторов. Существуют различные методы, начиная от простейшей модели “Мешок Слов” и заканчивая изощрёнными подходами к машинному обучению, например вложению слов. На сегодняшний день в задаче поиска информации самое высокое качество и для английского, и для русского языков достижимо подходами на основе алгоритмов вложения слов, тренированных на тщательном подборе корпусов в сочетании с синтаксическим и семантическим анализом на основе различных глубоких нейронных сетей. Различные алгоритмы машинного обучения используются в задачах NLP таких как тегирование частей речи, реферирование текстов, распознавание именованных сущностей, классификация документов, извлечение тем и отношений сущностей, и вопросно-ответные системы на естественном языке. Рассмотрена применимость данных алгоритмов к анализу образовательного контента, а также предложен подход к приложению возможностей NLP и машинного обучения к анализу и синтезу образовательного контента в виде системы поддержки принятия решений.
Text of the scientific article On usage of machine learning for natural language processing tasks as illustrated by educational content mining
Development of methods of intelligent text analysis is one of the key problems in the field of Artificial Intelligence (AI) research. Tasks, related to this problem, are usually referred to as Natural Language Processing (NLP). It's an interdisciplinary area of science and technology, aimed to resolve the problems of automatic analysis and synthesis of natural language that appear during man-machine interactions, using various AI and computer linguistics approaches.
Until recently, despite scientists' best efforts accuracy and recall of such methods couldn't possibly compare to results, demonstrated by a human. At best, results that were worth speaking of, were achieved only for a limited area of knowledge or a select range of text properties. However, development of machine learning techniques made it possible to achieve quality, required for practical use in NLP tasks. Nowadays, it is possible to propose a problem of deep information extraction from text to be used in creation of formal models of specific areas of knowledge.
1 Main tasks and approaches to natural language analysis
Most common tasks in NLP are:
-
■ semantic similarity and relatedness evaluation;
-
■ information retrieval;
-
■ information extraction (named entity recognition, relation extraction, fact extraction, knowledge extraction, coreference resolution);
-
■ text classification and text clustering;
-
■ natural language question answering;
-
■ machine translation;
-
■ text summarization;
-
■ sentiment analysis and opinion mining;
-
■ automated ontology/dictionary/thesaurus/knowledge base generation;
-
■ speech recognition and speech synthesis;
Before approaching more complex and specific tasks, it is important to find a representation for a text, through the use of text models (See Figure 1).
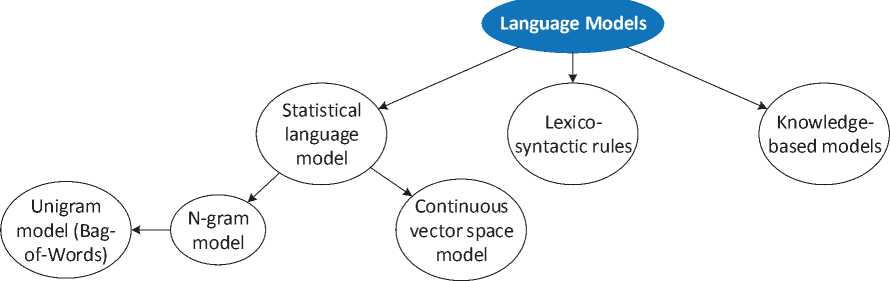
Figure 1 – Language modelling approaches
The most simplistic approach to language modeling includes various statistical models, based primarily on word distributions within the document or a collection of documents i.e. distributional semantics.
Distributional semantics approach defines semantic similarity between two linguistic items (such as words or words combinations) based on their distributional properties in large corpora of text, generally without specific knowledge of lexical or grammatical meanings of said items. The main idea behind this approach is so-called distributional hypothesis: linguistic items with similar distributions have similar meanings. Various vector models and word embedding techniques that transform each text item (words, usually) into numeric vectors are commonly used in context of distributional semantics.
One of the ways to represent words with those ideas in mind is to cut documents into sets and sequences of words – n-grams [1] or shingles, which account for information contained within multi-word constructs of length n: bigrams for word pairs, trigrams for triples and so on.
The edge case scenario for n-gram model occurs with n equal to 1. Such model could be called unigram, but more often referred to as the Bag-of-Words model [2]. Such model disregards all document properties except for the counts of words in it. Bag-of-Words represents a set of documents as a matrix with rows corresponding to documents and columns – to a specific term. Values on the intersections describe the count of a word in a specific document.
As multi-word constructs contain additional information, when compared to a set of singular words (word collocations, idioms and so on), it is an important step in text preparation to distinguish bigrams and trigrams to keep, while breaking the rest of the document into a Bag-of-Words.
In practice, BoW models usually include some sort of weight for each term-document pair. The simplest and most obvious measure would be the number of occurrences (frequency) of a term in each document within collection, or normalized probability of finding the word within the document. This, however, evaluates more common words as more important, while that might not necessarily be true. The most common weighting measure for both singular words and n-grams, which counteracts this bias is TF-IDF (TF — term frequency, IDF — inverse document frequency) [3, 4]. It is a statistic, used to determine the importance of the word in the context of a document, which itself is part of a document collection or a corpora. The weight of the word in a certain document is proportional to its count in said document and at the same time inversely proportional to this word's frequency in other documents from the same collection.
One of the early methods utilizing distributional semantics was Latent Semantic Analysis (LSA). This method defines a vector for each word based on results of applying singular value decomposition (SVD) to a weighted term-document matrix, containing word counts. All word-vectors together represent vector space.
One of the main problems for such models is a so-called "semantic gap", which results in sparse vectors and is caused by ratio of unique words existing in the language to the count of unique words that appear in a single document.
Distributional semantics approaches are attempting to solve the task of sparse word vector space dimensionality reduction in order to reduce the effects of semantic gap.
Another statistical model – continuous space language model – helps treating semantic gap issue. This model represents text as a continuous stream of words, perceived through the context window, which includes immediate context of each word. To calculate the vector representation of each word, this type of model utilizes various word embedding techniques. Previously discussed models represent words from document collection in a form of a sparse vector space with dimensionality of entire word count of the language (measuring around one million or more for English, for example). Mathematical embedding involves transforming those vectors into a much less dimensional vector space with much denser vectors. This is usually done through various machine learning approaches, like neural networks and log-bilinear regression. The topic of word embedding is discussed further in part 4 of these paper.
A different approach to language modeling involves using a priori knowledge of lexical and syntax rules for a specific language in order to extract the inner structure of the text. Lexico-syntactic knowledge helps determining types of entities and relationships between them, based on exact words, their forms, part of speech and part of a sentence.
Many methods use lexico-syntactic patterns and syntactic-semantic analyzers as parts of the solutions to the task of information extraction. One of the possible approaches to formulate lexico-syntactic pattern is to apply context-free grammar and keyword dictionaries (Tomita-parser from Yandex, for instance), meta-languages describing rules (such as RCO Fact Extractor). PatternSim [5] is an example of a tool that uses lexico-syntactic patterns to measure semantic similarity between words.
Another approach has demonstrated its efficiency in analysis of texts in Russian. It is based on relationally-situational text model [6], communicative grammar and heterogeneous semantic networks theories. Relationally-situational methods combine static and dynamic approaches to text processing. This approach also uses dictionaries, thesauruses, ontologies and linguistic knowledge bases.
Third popular approach to text modeling involves usage of various ontologies and knowledge bases, containing specific terms, entities and their relationships. This approach is also known as graph-based or network-based approach. Due to how easy it is for a human mind to represent knowledge space as a set of objects and their interconnections, methods utilizing various graphs as a knowledge base structure are quite popular. Such structures include semantic nets, concept maps, ontologies, thesauruses. Objects, concepts and ideas are usually represented by nodes in a graph and their connections to each other – by graph's edges.
There are many methods suggested for determining semantic similarity between concepts that are based on paths and depths of objects in a graph, such as Resnik, Lin, Jiang and Conrath, Wu and so on. Mentions in the document can be resolved into certain nodes of the underlying knowledge base, which provides an opportunity to project graph structure onto the text and discover how specific relations are represented in text. This could be used to extract syntactic patterns, which could be used to further populate the database by extracting new concept pairs with known types of relations.
Graph-like structures can be used to solve complex problems of semantic analysis. Historically local ontologies of specific fields, semantic net of WordNet, community encyclopedia Wikipedia, and other dictionaries and thesauruses were used as such structures.
Thorough overview of existing modern semantic similarity measures is presented in [7].
2 Machine learning in NLP: algorithms, tools and technologies
Before we introduce some of the more popular and specific approaches, it is important to understand the general structure of machine learning as a field. Traditionally specified approaches to machine learning (ML) are supervised and unsupervised machine learning. Supervised ML is based on the idea of an algorithm learning how to perform specific action on a training data set, which already has correct answers to the learning problem, while unsupervised approaches attempt to generate the answer themselves, by working directly with unlabeled data. Obviously, the main difference in practice is the training data requirement. For supervised algorithms this dataset needs to be assembled and labelled with correct answers (class tags, for example) and only then it can be used to train algorithms. This usually involves high amounts of manual work, which is unnecessary for unsupervised algorithms. Furthermore, way more data, text data in particular, is available in an unlabeled form, making unsupervised training especially interesting for NLP tasks.
As a compromise between two approaches, the semi-supervised ML is specified. Technically, semi-supervised ML is still supervised, but this umbrella term covers techniques and methods that start by using only a tiny amount of labelled data and go on from there attempting to label unlabeled data on their own, learning from the mixed dataset of labelled and unlabeled data. This approach is quite popular among researchers in the field of NLP and is used for many of the examples below.
The development of machine learning approaches has caused many scientific researchers to apply those methods to NLP tasks. In an attempt to structure popular in NLP algorithms and methods, we combined them into the rough diagram presented in figure 2.
Conditional Random Fields (CRF) classifiers are one of the popular ML algorithms in text analysis, since they can take into account not only singular words, but their context as well. CRF are used, for instance, in the task of named entity recognition in documents from various fields and areas of knowledge [8-10] and text summarization problems [11, 12] in which this classifier is applied to distinguish more important sentences.
Logistic regression algorithms were applied to named entity recognition as well, for instance in [13], in which they were applied to the problem of classification Wikipedia articles according to the types of concepts they represent. This classifier was also used to determine similarity between nodes, extracted from the graph of the knowledge base, and the correct answer as part of the natural language question-answering systems [14].
Support Vector Machines (SVM) were applied to a variety of text analysis-related tasks. In particular, in named entity recognition, SVM were used to increase quality of found entities as a last level of a three-level framework, proposed in [15]. Another team of researchers compared SVM to CRF (with CRF showing slightly better results in majority of tests) in the task of word classification as a part of a named entities in sentences from medical documents [16] in BIO (Beginning-Inside-Outside) format.
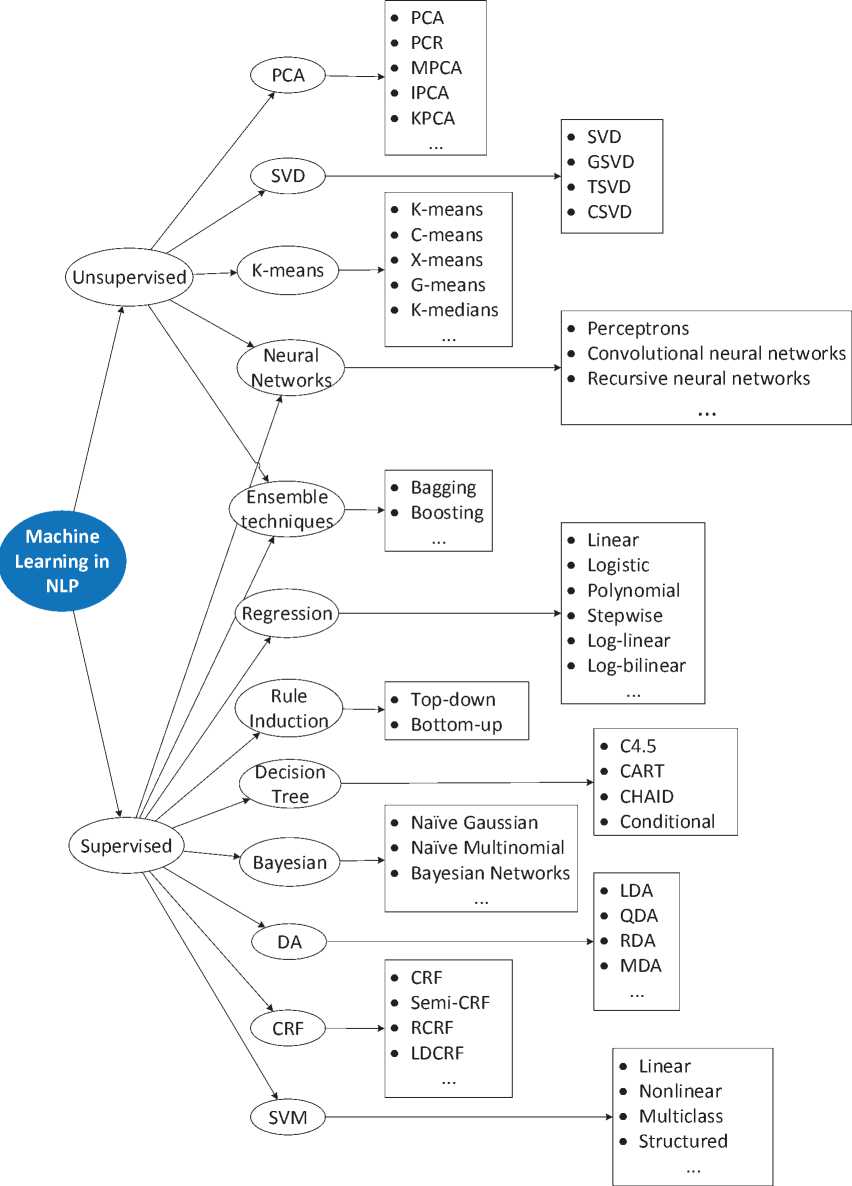
Figure 2 – Rough diagram of popular machine learning algorithms to natural language processing tasks
Among other algorithms, one could mention LDA-based LabeledLDA, applied to named entity recognition [17], as well as naive Bayes classifier and decision-tree generator C4.5, which were applied to the task of authorship recognition (classification problem) based on syntactic n-grams [18], but lost in quality to SVM.
Some of the popular information retrieval approaches are based on rules that describe certain properties of text elements. With these methods, ML can be applied to automatize the process of rule induction. One type of such systems - top-down - is based on the process of generating new, more detailed rules on the intersections of more general ones. For example, LemmaGen [19] is an part-of-speech tagger, which is based on iterative process of RDR (Ripple Down Rules).
The opposite approach - bottom-up - proposes rule induction for more general rules from specific cases and mentions of concepts in the document. These rules were used, for instance, to retrieve information about medical events from clinical records. [20].
Quite popular are ensemble algorithms, such as random forest, used, for example to extract information about medical drug interactions [21] and determining personal characteristics of a writer [22]. There was also proposed a variation of the algorithm, which was stable against imbalanced classes [23].
3 Machine learning approaches based on neural networks
Nowadays, approaches that utilize neural networks are rapidly grow in popularity. For instance, averaged perceptron was used for coreference resolution by the developers of Reconcile [24], as a classifier, determining the coreference probability of two noun phrases.
In natural language question-answering task a hidden variable perceptron was used to filter incorrect relations, extracted from the knowledge base [25].
Striking example of applying neural network in the context of distributional semantics is Word2Vec model, created by a team of researchers from Google, led by Tomas Mikolov [26]. Word2Vec solves the problem of generating a statistical model of natural language via analysis of large text corpora.
This model is based on earlier research [27, 28] into statistical modelling of natural language through word embedding, accomplished by using neural networks. Main idea behind this approach is to use two-layer neural network to transform text corpora into its vector form in n-dimensional vector space (with n usually being around several hundreds), based on the distribution of the original linguistic items in the corpora. The notable property of resulting vectors is that similarity between vectors reflects semantic similarity or relatedness between original linguistic items, with model being trained specifically to improve the quality of vector representation: the more distribu-tionally similar original items are, the more similar their vector representations must be.
Word2Vec uses two models for training: continuous bag-of-words (CBOW) model, attempting to predict the word, knowing its context (word order within context window is of lesser importance) and continuous skip-gram model, which does the opposite, by predicting word’s context from a single word. Continuous skip-gram shows better results for corpora that include rare words and in general achieves better quality than CBOW given a larger datasets, however it takes longer to train and is worse for determining syntactic trends.
Word2Vec on its own shows good results in calculating semantic similarity of words, determining the missing word from context, and achieves satisfying in multi-word structures’ analysis. However, Word2Vec is presented by its authors as a first stage of text analysis. To solve complex problems additional methods and metrics based on specific area of knowledge are required. Semantic vectors of documents or parts can be used for further analysis, for example classification and clustering with more generic algorithms of ML (SVM, decision-trees, neural network and so on).
One of the Word2Vec's analogues is GloVe, developed by a group of researchers from Stanford [29]. It is based on global log-bilinear regression model, which combines pros of both global matrix decomposition and local context window. GloVe allows for highly efficient solutions to named entity recognition, semantic similarity tasks. For particular test sets it consistently outperforms Word2Vec, however, according to researches: exact comparison is difficult due to vast amounts of parameters in both models.
Efficiency of word embedding approach can be judged from results of Dialogue Evaluation competition. In this competition, various algorithms tested against each other in a set of text analysis tasks for Russian. During 2015s competition for semantic similarity (RUSSE) [30], majority of top-performing models were based on Word2Vec (or its analogues), trained on various Russian corpora. Other methods that proved effective when combined with Word2Vec were: decision trees over n-gram model, logistic regression and taking into account morphological properties of linguistic items.
For instance, direct comparison [31] of three systems based on lexico-syntactic patterns for syntax extraction, context window over data from Google n-grams and Word2Vec over a huge corpora, respectively shows that the best results were achieved by the latter system.
Later on the team behind Word2Vec had suggested the way to apply similar techniques to bigger textual units – sentences, paragraphs, and entire documents [32]. Similarly to Word2Vec, the new algorithm was named Paragraph2Vec, as it provides the vector space representation of a paragraph of text – paragraph vector. Overall, the algorithm is extremely similar to Word2Vec with major difference being in the utilization of a secondary matrix, containing vectors for every text or paragraph encountered during training.
Again, similarly to Word2Vec, this algorithm provides two distinctive models for training. The Distributed Memory model (PV-DM) is similar to CBOW approach in Word2Vec, using both vectors of words from the context window and the paragraph vectors to maximize the quality of predicting the missing word in its context. In this case the paragraph vector represents the topic of the entire paragraph which is missing from the immediate context of the predicted word (with this context being represented by the word vectors) – thus being the memory which is distributed across all the contexts within the paragraph.
Second model in Paragraph2Vec is called Distributed Bag-of-Words (PV-DBOW) and is similar to the skip-gram model in Word2Vec. This model uses only paragraph vectors to predict words from contexts sampled from these paragraphs. As the authors specify, PV-DM works well in most situations, but they do recommend pairing two models together to achieve a more consistent result.
4 Deep learning in NLP tasks
Lately, the deep learning approach became one of the breakthrough NLP technologies. Main idea behind this approach is to create models with complex structure and non-linear transformations in order to model high-level abstraction in data. The "depth" in this case is a distance in model graph between input and output nodes. In order to do so the task of training inner layers of multilayer network needs to be resolved, which can't be done by a classical ML approach of backward propagation of errors. A detailed review of deep learning structures is presented in [33]. Another extensive report, covering deep-learning approaches and algorithms and their applications in artificial intelligence was presented in [34]. That paper doesn’t focus only on those algorithms, models and techniques used and represented in NLP, but instead mainly covers semantic data mining tasks in general, as well as the uses of such algorithms in computer vision. One of the main discussed subjects of that report is knowledge bases and ontology building and how could deep learning techniques be applied to building and researching models of human knowledge.
Deep learning approach allowed for a significant improvement in speech recognition and NLP tasks, such as NLQA, sentiment analysis, information retrieval, topic modelling, text classification and text clustering, machine translation.
Most common deep learning architectures used for NLP tasks are recursive neural networks (for instance, recurrent neural networks) and convolutional neural networks.
There exists a number of works about usage of neural networks [35-38].
CNN are used for analysis of semantico-syntactic properties of the text. For example, semanti-co-syntactic analyzer ABBYY Compreno, shows best results for information retrieval tasks in Russian [39]. This analyzer allows one to resolve more complex tasks in information retrieval: coreference and anaphora resolution [40].
CNN as deep learning approach and SVM algorithm are often used in construction of NLQA systems. For instance, in IBM Watson CNN are used to conduct deep search of syntax patterns and answer generation [41]. In other research [42] CNN were used to transform entities and patterns of their relations in questions into vector space to be compared to already known concepts and their relations in the knowledge base.
In [43] CNN were successfully used to model natural language sentence structure.
CNN and RNN display high quality in sentiment analysis in short texts [44] and opinion mining tasks [45].
In SentiRuEval 2015 and 2016 - the Russian language sentiment analysis competition [46], best quality were achieved by systems, using Word2Vec trained on special corpora of lexicons and short documents, as a first and SVM or neural network classifier as a second stage of analysis. Among them the best results were shown by RNN and or CNN with addition of syntactic attributes to Word2Vec vectors [47].
5 Machine learning approaches in educational content analysis
One of the possible fields of knowledge for data analysis is educational content. The part of data mining concerned with this field is called educational data mining (EDM). Next, we'll provide a general overview of several researches of ML algorithms and semantic analysis application to the EDM tasks.
For the task of clustering of computer-supported collaborative learning participants [48] researchers used naive Bayes classifier. Another team of researchers [49] used HMM and SVM classifiers for sentiment analysis of reviews, left by users of e-learning systems, left in blogs and forums. Logistic regression model was utilized for the analysis of text recognized from speech by automatic tutor [50]. For e-learning FAQ generation [51] hierarchical classifiers and rough set theory were used. For information extraction from educational content, researchers suggested automatic framework [52] for knowledge base concept hierarchy generation from found e-learning documents on specific topic, which utilized naive Bayes classifier.
A variety of text ranking algorithms and systems designed to rate documents involved in the educational process, such as student essays, was proposed. For instance, Writing Pal [53] is a system, trained on a corpora of essays, rated by a group of experts, to predict human rating of an essay, based on wide range of linguistic, rhetorical, and contextual features as predictors in a process of stepwise regression. Another team of researchers [54] focused on developing a system capable of ranking the readability of text based on multilevel linguistic features – as in features from word, semantics, syntax and cohesion levels. Their research was performed for a corpora of text produced from Chinese textbooks and rated by a group of experts – teachers, educational psychologists and language professors. The readability is then evaluated by applying a classifier to the sets of extracted features – discriminant analysis and support vector machines.
It is important to understand, that educational content varies greatly. First of all, representation of content varies between different kinds of educational content. Secondly, even within the same educational content type, representations may still vary for documents made by different educational organizations, or even between different departments or educators within the same organization.
But more importantly – educational content representations are not uniform documents. These documents usually consist of completely different and semi-independent parts. For example, generic course programme may include a generic text description, a multilevel list, describing the topics within the course (each of which may or may not come with a short text description of its own) and table of learning outcomes (which themselves consist of an action verb from a small set of words and a learning outcome made using various terms bounded only by course’s field of knowledge).
It is apparent, that different parts of the document require individual approach and different algorithms could show better results for these parts. For instance analysis of aforementioned learning outcomes would involve different approaches for its action verb and learning statement parts. While learning statement analysis falls under short text semantic similarity calculation and has to be solved by NLP methods, same cannot be said for the action verbs. Action verbs come from a small taxonomical list. One of the researchers [55], suggested a relatively simple algorithm for semantic similarity computation between these – by using a specific matrix representing position of the verbs in a space defined by their cognitive process domain and complexity coordinates. The similarity in this approach is determined by the distance between specified verbs in this matrix.
Another example of extracting concepts from educational documents according to some sort of a structure is represented in research [58]. Authors present approaches to classifying examination questions into the concept hierarchy for underlying knowledge to determine what exactly the question evaluates. The proposed model draws inspiration from widely known hierarchical classification techniques.
In [59], authors described a concept of an intelligent system for analysis and synthesis of educational content which took labor market into account. That system’s architecture in context of our recent research is shown in Figure 3. This novel approach is intended to solve the complex problem of decreasing the amount of manual labor that goes into preparing educational content by Russian educational organizations in particular, while at the same time improving the overall quality of the content itself.
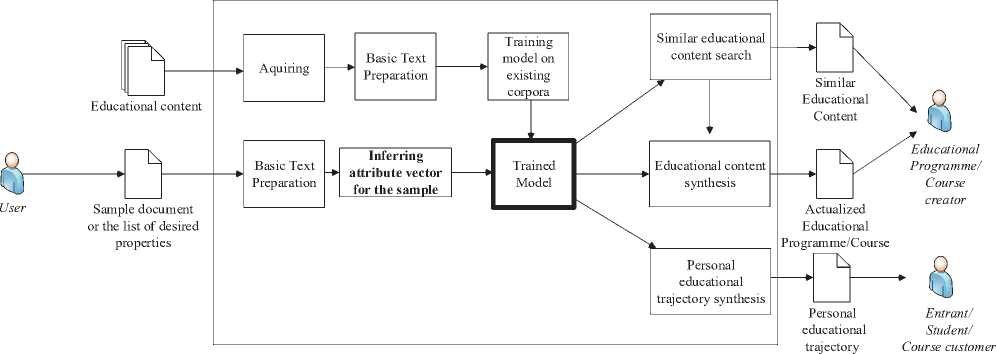
Figure 3 – General architecture of the proposed educational content synthesis system
The general workflow of the system is focused on acquiring educational content to put together a corpora and train the system on it, as to be able to embed the documents into the vector space. After it is done, the system would be used to infer the vectors for new documents coming in and compare those with the already known vectors from the corpora. This way we would achieve the possibility of search and synthesis of educational content, based on already known sources and new incoming samples. Here, by samples we understand both actual documents and more or less specific (potentially – also generated with the aid of the system) description of the desired content to be found or synthesized.
In order to increase effectiveness of new content generation and older content actualization (meaning educational programme, course programme and individual learning trajectories) it was suggested to solve the following tasks of educational content analysis:
-
■ information retrieval of educational content, filtered by a set of criteria (learning outcomes, labor market requirements, requirements to content contents, educational and professional standard requirements) sorted according to their relevance;
-
■ calculate structural and semantic similarity of educational content;
-
■ automatic generation of knowledge base;
-
■ variative structure and contents generation from existing knowledge base according to specified criteria;
To resolve the task of educational content analysis using the machine learning approaches one needs to:
-
■ study more common formats of educational content representation;
-
■ choose a set of criteria for each type of educational content;
-
■ create a document corpora of educational content and prepare input data for further analysis;
-
■ choose machine learning models (possibly hybrid) and algorithms and develop them, utilizing tools and libraries;
-
■ train chosen models on created corpora and evaluate their effectiveness;
-
■ choose the most effective algorithm (or combination) for each task of educational content analysis.
Conclusion
In this paper we reviewed modern approaches to solution of a variety of NLP tasks. Nowadays, the most effective approaches to text analysis in both English is Russian tend to be based on distributional semantics, utilizing neural networks combined with semantic-syntactic analysis, using var- ious deep learning architectures, such as recurrent neural networks and convolutional neural networks. We propose to evaluate effectiveness of those methods in regard to educational content analysis and synthesis in a future research.
References On usage of machine learning for natural language processing tasks as illustrated by educational content mining
- Damashek M. Gauging similarity with n-grams: Language-independent categorization of text // Science, New Series, 1995, vol. 267, pp. 843-848.
- Harris Zellig S. Distributional Structure [Journal] // WORD, 1954, no. 10, pp. 146-162.
- Jones K. A Statistical Interpretation of Term Specificity and Its Application in Retrieval // Journal of Documentation, 1972, no. 28, pp. 11-21.
- Manning C., Raghavan P., Schutze H. Scoring, term weighting, and the vector space model. Introduction to Infor-mation Retrieval, 2008, 100 p.
- Panchenko A., Morozova O., Naets H. A Semantic Similarity Measure Based on Lexico-Syntactic Patterns. Proceed-ings of the 11th Conference on Natural Language Processing (KONVENS 2012), Vienna (Austria), 2012, pp. 174-178.
