Ономастическое наполнение географических нормативно-научных текстов: квантитативный подход

Автор: Андреев С.Н., Максимчук Н.А.
Журнал: Вестник Волгоградского государственного университета. Серия 2: Языкознание @jvolsu-linguistics
Рубрика: Развитие и функционирование русского языка
Статья в выпуске: 5 т.24, 2025 года.
Бесплатный доступ
Исследование посвящено решению актуальных задач определения содержательных характеристик текстов учебной литературы с применением методов статистической обработки их лексического наполнения. Работа выполнена в русле междисциплинарных исследований, нацеленных на установление роли и места имен собственных в структуре общеобязательного знания и его отдельных фрагментов. В результате проведенного анализа выделено и структурировано ономастическое пространство географических нормативно-научных макротекстов. С применением квантитативного анализа выявлены состав ономастического ядра и периферии данных макротекстов, распределение онимов по тексту. Показано, что состав и частотность топонимов в географических нормативно-научных текстах служат маркерами содержания географического фрагмента нормативно-научной картины мира (общеобязательного географического знания). Полученные результаты позволяют сделать выводы не только о составе и структуре ономастического наполнения нормативно-научных макротекстов, но и о степени его устойчивости во времени. Предлагаемая методика оценки ономастической (информационной) нагруженности текста может быть использована для анализа учебников по другим предметам. Анализ ономастического наполнения географических нормативнонаучных текстов, формирующего определенное ономастическое пространство, имеет практическую значимость, связанную с объективацией экспертизы текстов существующих учебников и с перспективой разработки рекомендаций для вновь создаваемой учебной литературы.
Имя собственное, общеобязательное научное знание, нормативно-научный текст, ономастическая нагруженность текста, ономастический фон, квантитативный анализ
Короткий адрес: https://sciup.org/149149749
IDR: 149149749 | УДК: 81’373.21 | DOI: 10.15688/jvolsu2.2025.5.1
Onomastic Content of Geographical Normative Scientific Texts: A Quantitative Approach
The article focuses on topical issues of statistical processing of educational books, which might contribute to their content peculiarities identification. The aim of this interdisciplinary research, within the framework of which this study is conducted, is to determine the role and place of proper names in the structure of universally mandatory knowledge and its individual fragments. The analysis undertaken resulted in identifiing and structuring the onomastic space of geographical normative scientific macrotexts. The application of quantitative analysis revealed the composition of the onomastic core and periphery of these macrotexts, as well as the basic and variable components of onyms and their distribution across the text. The composition and frequency of toponyms in geographical normative scientific texts are noted to serve as markers of the content of the geographical excerpt of the normative scientific picture of the world (universally mandatory geographical knowledge). The findings allow for conclusions not only about the composition and structure of the onomastic content of normative scientific macrotexts but also about the degree of its stability over time. The proposed methodology for determining the onomastic (informational) load of a text can be applied to the analysis of textbooks in other subjects. The analysis applied to onomastic content of geographical normative scientific texts, which forms particular onomastic space, has significant practical relevance, related to the objectification of expert evaluations of existing textbook texts and the prospect of developing recommendations for newly created ones.
Текст научной статьи Ономастическое наполнение географических нормативно-научных текстов: квантитативный подход
DOI:
Представляемое исследование выполнено в рамках разработки концепции изучения языкового выражения содержания общеобязательного научного знания. Научный фрагмент общеобязательного знания человека (нормативно-научная картина мира, далее – ННКМ) складывается из научных и научнопрактических сведений, усвоению которых в значительной степени посвящен процесс образования. Особенность этого фрагмента состоит в том, что он складывается не стихийно, а в результате целенаправленного сообщения отобранных и одобренных обществом научных сведений, овладение которыми регламентируется социумом и закрепляется в нормативных документах (образовательных стандартах, программах, учебниках и т. д.). Основным средством трансляции общеобязательных научных сведений служат нормативно-научные тексты (далее – ННТ) – специально созданные и принятые обществом научные тексты, функционирующие в учебной литературе. Основной формой представления научного знания в учебных целях служат учебники как нормативно-научные макротексты. Одним из двух (наряду с термином) опорных элементов нормативно-научной картины мира, существующей в сознании носителей научного знания, является имя собственное (далее – ИС).
Предмет исследования в данной статье – ономастическое наполнение (топонимы) нор- мативно-научных текстов учебников географии, цель – разработка методики определения ядерного и периферийного компонентов общеобязательного научного знания путем сопоставительного анализа структуры ономастического наполнения школьных учебников географии разных временных периодов.
Работа имеет междисциплинарный характер, поскольку поставленная цель объединяет несколько смежных дисциплин: ономастику (языковой материал представлен ономастической лексикой), когнитивную лингвистику (имя собственное рассматривается как носитель общеобязательного научного знания, которое влияет на формирование личности), теорию учебно-научного текста (имя собственное функционирует в нормативно-научных текстах, формируя их информационную насыщенность), прикладную лингвистику.
Теоретическое значение исследования связано с тем, что оно позволит расширить представление об онимах как носителях общеобязательного научного знания и ономастическом наполнении нормативно-научных текстов как ономастическом пространстве, его практическая значимость обусловлена возможностью использования представленных методов при анализе и экспертной оценке нормативно-научных текстов действующих учебников.
Ономастическое наполнение нормативно-научных текстов определенной тематической отнесенности (в том числе – географической) формирует своего рода ономастическое пространство. Современные философские теории пространства рассматривают фундаментальные измерения человеческого мира, выражаемые в специфических нестрогих понятиях верх – низ, центр – окраина, поверхность – глубина, удаленность – близость и др., которые фиксируются уже на уровне обыденного сознания и отражают то, в каких именно координатах и векторах описывается динамика и статика человеческого существования [Философия..., 2004]. Очевидно, что значительная часть пространственных координат и векторов в их вербальном выражении будет иметь, помимо нарицательных обозначений, собственные наименования, что позволяет применить к термину пространство уточняющее определение.
В лингвистике появление термина ономастическое пространство связано с именами В.Н. Топорова и А.В. Суперанской. В.Н. Топоров трактует (топ)ономастическое пространство как совокупность принадлежащих ему собственных наименований [Топоров, 2004]. А.В. Суперанская, понимая ономастическое пространство как совокупность всех имен собственных, употребляющихся в определенном социуме в определенную историческую эпоху, подчеркивает, что его объем и характер могут меняться [Суперанская, 1973].
Используя понятие ономастического пространства в целях нашего исследования, мы обозначаем этим термином совокупность ономастических единиц нормативно-научных текстов разных уровней – от ННТ одного раздела до ННТ отдельного учебника (макротекста) или всей учебной линии – предметного гипертекста [Максимчук, Голубничая, 2018]. Анализ ономастического пространства любого ННТ может быть комплексным, одновременно охватывая онимы всех представленных в нем разрядов, или последовательным, проводимым по отдельным разрядам. В данной работе детально анализируются топонимы (конкретно – названия стран) как основной разряд онимов в географических текстах – носителях базового географического знания.
Поскольку наполнение ономастического пространства как составной части (фрагмента) лексической системы языка позволяет квалифицироваться в терминах теории поля [Супрун, 2000; Максимчук, 2017; и др.], то применение квантитативного анализа частот имен собственных позволяет определить состав ядра и периферии данной ономастической структуры, уровень информационной нагруженности одноименных нормативно-научных текстов и, следовательно, выявить степень сходства и различия в представлении базового географического знания в учебниках разных поколений.
В перспективе комплексный анализ ономастического наполнения нормативно-научных текстов как носителей существенного объема общеобязательного научного знания в сочетании с корпусным анализом других характеристик учебных текстов (см., например: [Куприянов, Солнышкина, Лехницкая, 2023; Монахов, Турчаненко, Чердаков, 2023;
Лапошина, Лебедева, 2024; и др.]) и методом экспертных оценок позволит выработать концепцию построения оптимального учебного текста с учетом его содержательных задач, потребностей и возможностей адресата.
Материал и методы
Материалом для проведения исследования послужили ННТ учебников географии. Выбор обусловлен несколькими причинами. География относится к традиционным предметам общего образования, что свидетельствует о понимании обществом важности формирования системы географических знаний как компонента научной картины мира для ориентации человека в окружающем его физическом (материальном) мире в целом и мире разных стран и народов в частности. В современной ситуации, характеризующейся повышенной геополитической турбулентностью, значительными изменениями в природной географической среде, освоение молодыми людьми базового географического знания может способствовать, согласно нормативным образовательным документам, формированию целостного представления о роли России в современном мире, ценностных ориентаций личности. Кроме того, в структуре географических знаний имя собственное занимает особое место, поскольку все географические объекты, известные человеку, имеют индивидуальные наименования – топонимы, составляющие один из самых многочисленных разрядов ономастической лексики.
При определении источников материала исследования (учебников) учитывались следующие параметры. Во-первых, учебники должны быть рекомендованы к использованию высшими образовательными институтами, чем подтверждается их статус носителей общеобязательного научного знания, структура которого закреплена в нормативных документах. Во-вторых, они должны быть существенно разделены во времени, что позволяет рассматривать их содержание в динамическом аспекте, оценивая степень его стабильности и актуальности. В-третьих, источники должны принадлежать разным авторам, что обеспечивает, на наш взгляд, большую объективность выявляемых сходства и раз- личий в структуре представляемого общеобязательного научного знания.
Источниками послужили учебники географии для 10 класса 1991 г. (ГЕО-1) и 10–11 классов 2018 г. (ГЕО-2), отвечающие всем трем требованиям.
В работе использованы описательный, структурный, сравнительно-сопоставительный методы, квантитативный анализ (сбор, подготовка, преобразование данных, кодирование, создание базы данных, визуализация результатов, статистический анализ).
Отбор имен собственных из текстов проводился программными средствами с использованием кода на Python и двух модулей: регулярных выражений (Regular Expressions) и спейси (spaСy).
Рассматривались все разряды и структурные типы онимов, включая аббревиатуры. Не учитывались иноязычные имена собственные, приводимые на латинице (их количество в исследуемых массивах ограничивается несколькими единицами).
Изучение ономастической структуры географических ННТ проводилось при помощи квантитативного анализа частот. Были рассмотрены следующие аспекты: 1) уровень ономастической насыщенности текста и частотное ядро ономастической структуры; 2) периферия ономастической структуры; 3) характер распределения частот вводимых в учебный текст онимов от его начала к концу; 4) использование ономастической системы для описания ведущих в политико-экономическом отношении стран мира. На всех этапах исследования анализ проводится как в рамках отдельных учебников, так и в их сопоставлении друг с другом.
Результаты
Уровень ономастической насыщенности текста и частотное ядро ономастической структуры
В результате анализа были получены данные о количестве онимов и их соотношении с общим объемом текста, что позволило определить уровень ономастической насыщенности текста (далее – ОНТ). Под ономастической насыщенностью понимается количе-
РАЗВИТИЕ И ФУНКЦИОНИРОВАНИЕ ство ономастических единиц на единицу текста. В свою очередь, единицей текста считается завершенный текстовый отрезок любой протяженности, объем которого в данном случае диктуется особенностями учебно-образовательных (нормативно-научных) требований к полноте раскрытия содержания текста, обозначенного его заглавием.
Определение уровня ОНТ достигается путем установления процентного отношения проприальной лексики к общему количеству лексических единиц рассматриваемого текстового массива.
Нами были установлены следующие значения: ОНТ в ГЕО-1 составляет 6,56 %, в ГЕО-2 немногим больше – 7,82 %. Таким образом, уровень ономастической насыщенности текста в обоих источниках сходный: на каждые 15 (ГЕО-1) и 13 (ГЕО-2) слов приходится один оним.
Очевидно, что общий уровень ОНТ зависит не только от количества различных они-мов, используемых в тексте, но и от их повторяемости – частотности. В таком случае для характеристики ономастического наполнения сопоставляемых текстов важным оказывается вопрос о влиянии на уровень их ономастической насыщенности конкретных ономастических единиц.
Вопросы о критериях разграничения частотной и малочастотной лексики и выявлении границы между этими двумя частотными областями лингвистических единиц в настоящее время часто решается при помощи использования критерия Хирша, широко применяемого в наукометрии [Hirsch, 2005]. Этот критерий основан на поиске такой лексической единицы, частота которой совпадает с ее рангом [Popescu, 2007; Popescu, Altmann, 2006]. Использование данного критерия позволило получить значимые результаты в области изучения соотношения синсемантической и автосемантической лексики, структуры текста, при исследовании вопросов золотого сечения и др. [Andreev, Místecký, Altmann, 2018, c. 93–95; Místecký. 2018; Pan, Qiu, Liu, 2015; Zhang, Liu, 2020].
В качестве примера приведем данные по одному из разделов ГЕО-2. Ранжирование имен собственных, используемых в последней теме (главе) этого учебника, обнаруживает,
РУССКОГО ЯЗЫКА что они образуют последовательность по убыванию частот: Земля (ранг 1; частота 12), США (2; 12), Россия (3; 11), Мировой океан (4; 10), ООН (5; 9), Африка (6; 8), Азия (7; 7), Европа (8; 5) и т. д. Согласно этому критерию точка отсечения (H-point) устанавливает границу, которая проходит по ониму Азия, имеющему частоту 7, совпадающую с его рангом. В тех случаях, когда полного совпадения нет, предложена методика определения условной границы [Mačutek, Popescu, Altmann, 2007]. Для приведенной последовательности привлечение этого дополнительный критерий не потребовалось.
Пороговым значением для ранжированного по частоте ряда имен собственных ГЕО-1 стал оним Европа с частотой и рангом 26. На 26 онимов частотной части списка приходится 42 % всех словоупотреблений ИС в учебнике, причем на первые 15–32 %.
В ГЕО-2 граница проходит по слову Лондон с частотой и рангом, равными 30. Слова частотного списка охватывают 42 % словоупотреблений всех онимов в ГЕО-2, первые 15 слов – 36 %.
Рассмотрим этот показатель для 15 наиболее частотных онимов в обоих источниках, поскольку на эти онимы приходится около трети всех словоупотреблений ИС. Состав и частотный ранг данных единиц являются весьма важными показателями для характеристики содержательной стороны текста. Полученные данные представлены в таблице 1, в которой также приводится процентное выражение использования данного онима и его ранг по частотности.
Как видно из таблицы, в ядро высокочастотных онимов входят названия ведущих в экономическом и политическом отношении стран, а также частей света. При этом данные обоих учебников почти полностью совпадают. Единственное исключение состоит в том, что в ГЕО-1 в число самых частотных попал оним Земля , а в ГЕО-2 его место занял оним Бразилия . Однако и здесь изменения крайне незначительные: оним Земля в ГЕО-2 стал 17 по рангу, а оним Бразилия с 16 ранга в ГЕО-1 поднялся на 12 ранг в ГЕО-2.
Совпадение обнаруживается и по рангам: 4 из 15 наиболее частотных онимов – США , СССР / Россия , Индия , Азия – имеют полное
Таблица 1. Ядро ономастической структуры в сопоставляемых учебниках
Table 1. The onomastic structure core in compared textbooks
|
ГЕО-1 |
ГЕО-2 |
||||
|
Ранг |
Оним |
% |
Ранг |
Оним |
% |
|
1 |
США |
5,14 |
1 |
США |
5,73 |
|
2 |
СССР |
3,21 |
2 |
Россия |
4,30 |
|
3 |
Япония |
3,01 |
3 |
КНР |
3,40 |
|
4 |
Африка |
2,42 |
4 |
Европа |
2,78 |
|
5 |
Западная Европа |
2,28 |
5 |
Япония |
2,61 |
|
6 |
Индия |
1,93 |
6 |
Индия |
2,39 |
|
7 |
Канада |
1,84 |
7 |
Африка |
2,17 |
|
8 |
Азия |
1,69 |
8 |
Азия |
2,17 |
|
9 |
Австралия |
1,64 |
9 |
Канада |
1,83 |
|
10 |
ФРГ |
1,64 |
10 |
Латинская Америка |
1,55 |
|
11 |
Земля |
1,62 |
11 |
ФРГ |
1,46 |
|
12 |
Франция |
1,52 |
12 |
Бразилия |
1,43 |
|
13 |
Латинская Америка |
1,52 |
13 |
Австралия |
1,40 |
|
14 |
Великобритания |
1,30 |
14 |
Франция |
1,39 |
|
15 |
КНР |
1,15 |
15 |
Великобритания |
1,27 |
ранговое соответствие, а ФРГ и Великобритания занимают смежные позиции в сопоставляемых текстах. Если опустить это единственное несовпадение по лексическому составу, то для остальных единиц обоих списков коэффициент ранговой корреляции Спирмена показывает большое сходство R = 0,71 (статистически значим для p < 0,05). Причем в четырех случаях ( США , СССР / Россия , Индия , Азия ) имеет место и сходство рангов. Таким образом, на уровне частотной лексики ономастическое наполнение географических ННТ в высшей степени стабильно.
В текстах обоих рассматриваемых источников лидируют онимы США – Россия / СССР , однако, как будет показано ниже, ономастическая структура представления этих стран значительно различается, что связано уже с другой характеристикой текста. Кроме них в частотный список онимов (выше точки Хирша) входят все страны – основатели БРИКС и все страны «Большой семерки».
Состав, а также количество употребляемых в географических текстах онимов и их частотность в определенной степени являются отражением объективного места объекта ономастической номинации на географической и экономической картах мира (и, следовательно, в структуре географического знания). Полученные данные о частотах, употребленных в географических текстах имен собственных, можно рассматривать как предварительные ориентиры в содержании географического фрагмента ННКМ (общеобязательного географического знания).
Характеризуя совокупность наиболее частотных онимов анализируемых географических макротекстов не только как ономастическое ядро их лексического наполнения, но и как центральную часть общеобязательного географического знания, обратим внимание на другие компоненты данной полевой структуры и, прежде всего, на ее периферию.
Периферия ономастической структуры
При изучении частотных показателей значение имеют не только высокочастотные, но и малочастотные единицы – гапаксы (см. об этом: [Popescu, Altmann, 2006]). Мы обнаружили имена собственные, используемые в учебнике один раз (Hapax legomena): Баотоу , Брисбен , Корба , Науру , Того , Эссен и др. (ГЕО-1); Аньхой , Бурунди , Лхасой , Теночтитлан , Цзянсу и др. (ГЕО-2), и имена собственные, которые используются в учебнике два раза (Hapax dislegomena): Бокаро , Лагос , Оман и др. (ГЕО-1), Гуандун , Луанда , Свазиленд и др. (ГЕО-2).
В таблице 2 приводятся данные о количестве таких единиц в процентах от всех ИС и указано количество словоупотреблений этих малочастотных слов относительно всех словоупотреблений ИС.
По этим показателям оба учебника снова представляются достаточно сходными, хотя в случае с гапаксами речь идет не о сход-
Таблица 2. Процентный состав гапаксов в текстах, %
Table 2. Percentage composition of hapaxes in texts, %
|
Тип ИС |
Лексические единицы |
Словоупотребления |
||
|
ГЕО-1 |
ГЕО-2 |
ГЕО-1 |
ГЕО-2 |
|
|
Hapax legomena |
47,47 |
55,83 |
8,74 |
9,76 |
|
Hapax dislegomena |
15,43 |
14,27 |
5,68 |
4,99 |
В структуре ономастического наполнения географических текстов эти онимы составляют ближнюю и дальнюю периферии, располагающиеся в границах между ядром и зоной гапаксов и составляющие зону информационного (ономастического) расширения. В нее входят ИС с показателями частотности 3–4, тематически (содержательно) соотносящиеся с одной из единиц ядра. Единицы зоны ономастического расширения находятся с ключевым онимом в отношениях включения: страны – моря – реки – горы – равнины – города и т. д.
Зона гапаксов, объединяющая Hapax legomena (с учетом или без Hapax dislegomena), составляет так называемый ономастический фон, участвующий в формировании географического знания, основным манифестантом которого является тот или иной ключевой оним текста (определение степени участия конкретных онимов зоны информационного расширения и зоны гапаксов в формировании предметного знания относится к перспективам исследования). В отличие от единиц зоны расширения, гапаксы могут иметь в разной степени отдаленные, но прямые связи с ключевыми онимами или не иметь таких связей. Однако в любом случае количество онимов-гапаксов в составе ономастического фона ННТ в значительной степени и определяет уровень ономастической (информационной) нагруженности текста.
Распределения частот онимов от начала текста к его концу
Особенность оценки ОНТ состоит в том, что она может устанавливаться в статическом и динамическом аспектах. С позиций статики под ономастической (информационной) нагруженностью текста будем понимать ко- личество разных онимов в процентном соотношении с общим количеством лексических единиц в тексте (фрагменте, разделе и т. д.). Информационная нагруженность в динамическом ракурсе обусловливается тем, как быстро возрастает количество онимов в текстах от начала учебника к концу. Для установления этого показателя можно использовать методику определения сумм с нарастающим итогом, в ряде исследований позволившую получить существенные результаты [Naumann, Popescu, Altmann, 2012].
На рисунке 1 по оси х отложены Введение и 7 тем учебника ГЕО-1, по оси y – количество использования онимов. От темы к теме количество словоупотреблений они-мов возрастает, так как каждый раз к словоупотреблениям в данной теме прибавляются словоупотребления онимов, использованных раньше.
Аналогичные данные по росту числа словоупотреблений онимов во Введении и 12 главах ГЕО-2 приводятся на рисунке 2.
Чтобы выявить характер нарастания количества онимов и того, есть ли какая-нибудь упорядоченность в этом нарастании, можно использовать степенную функцию [Naumann, Popescu, Altmann, 2012; Andreev 2016]:
0J-------о------£
о о
о
Рис. 1. Суммы словоупотреблений ИС с нарастающим итогом в ГЕО-1
Fig. 1. Cumulative sums of onyms frequencies in GEO-1
8000 ,
4000 -
3000 - о
О
1000 - °
о
о
0 -I-----°------Т-------------Т-------------Т-------------т-------------Т---------
Вв T1 Т2 ТЗ Т4 Т5
о о
о
а
о
о
о
Тб Т7 Т8 те Т10 Т11 Т12
Рис. 2. Суммы словоупотреблений ИС с нарастающим итогом в ГЕО-2 Fig. 2. Cumulative sums of onyms frequencies in GEO-2
y = axb, где a и b – параметры.
Ее применение показано на рисунках 3 и 4.
Кружками обозначены наблюдаемые суммы, линия показывает теоретически ожидаемые частоты согласно этой функции. Как видно на рисунках, кружки расположены близко к линии, а иногда и накладываются на нее. Это говорит о том, что функция хорошо отражает распределение частот. На это же указывает и коэффициент детерминации r2, который может иметь значения в диапазоне от 0 до 1. Для ГЕО-1 r2= 0,941 (рис. 3), для ГЕО-2 r2 = 0,967 (рис. 4). В обоих случаях коэффициент детерминации близок к верхнему пределу, что свидетельствует об успешности применения данной функции.
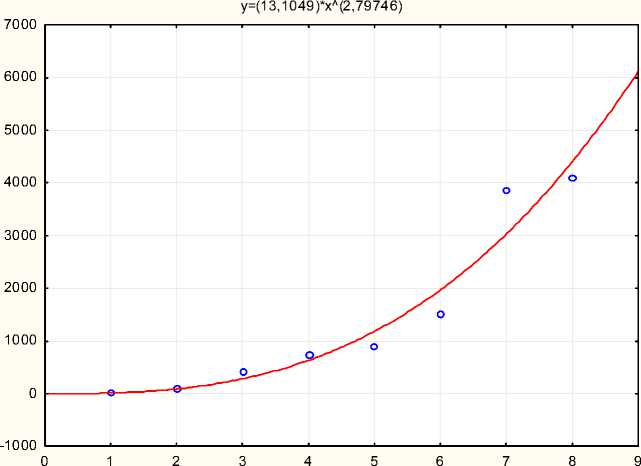
Рис. 3. Аппроксимация распределения частот онимов с нарастающим итогом в ГЕО-1
Fig. 3. Fitting the cumulative frequency distributions of onyms in GEO-1
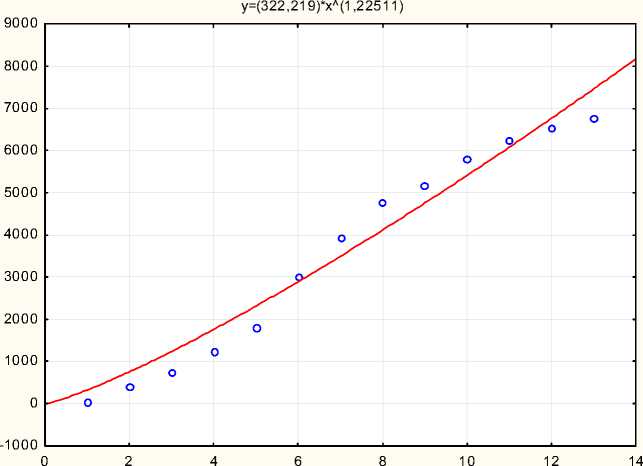
Рис. 4. Аппроксимация распределения частот онимов с нарастающим итогом в ГЕО-2
Fig. 4. Fitting the cumulative frequency distributions of onyms in GEO-2
Несмотря на то, что в обоих случаях степенная функция успешно отражает распределение накопленных частот словоупотреблений, в характере накопления ИС от начала к концу в двух учебниках наблюдаются значительные различия. В ГЕО-1 имеется резкий рост использования ИС только к концу учебника, в то время как в ГЕО-2 нарастание имеет более плавный характер.
Ономастическая система в описании двенадцати ведущих стран мира
На основе анализа имен собственных в географических ННТ представляется возможным рассмотреть ономастическую структуру описания ведущих стран мира в обоих учебниках. В число этих стран вошли страны – основатели БРИКС и члены «Большой семерки» (G7). Отметим, что в ГЕО-1 отсутствует самостоятельный раздел о России, поскольку учебник посвящен политической и экономической географии зарубежных стран, в то время как ГЕО-2, также в основном направленный на описание зарубежных стран, такой раздел включает. Кроме того, в ГЕО-1 практически не представлена Южно-Африканская Республика. Целесообразно начать анализ с тематически более объемного учебника, то есть с ГЕО-2. При подсчете онимов от- бирались только те из них, которые относятся к рассматриваемой стране, причем анализу в этом случае подвергался не весь текст учебника, а только соответствующий параграф или раздел.
Для анализа привлекаются два параметра: количество словоупотреблений они-мов (tokens) и количество разных онимов (types) – уникальных лексем. При подсчете словоупотреблений (tokens) каждый оним учитывался столько раз, сколько он был употреблен в тексте. При подсчете уникальных лексем (types) каждый оним учтен только один раз вне зависимости от того, сколько раз он встречается в тексте.
Полученные в результате подсчетов данные представлены в виде диаграммы рассеяния (рис. 5).
На этой диаграмме по оси х отложены частоты словоупотреблений ИС, по оси y – количество уникальных лексем. Как видно на диаграмме, в нижних регистрах выстраивается достаточно плотная группа, которая от левого нижнего угла вытягивается в направлении к верхнему правому. Абсолютный минимум по обоим параметрам у ЮАР, абсолютный максимум – у США. В описании США находим максимум словоупотреблений ИС и максимум различных уникальных лексических единиц ИС. Примерно в середине диаго-
|
1 40 1 20 1 00 80 60 40 20 |
♦ США КНР ФРГ Япония ♦ ндия Канада Бразилия РФ Италия ♦♦ Франция Великобритания |
|
0 |
50 100 150 200 250 300 350 400 450 500 |
Рис. 5. Диаграмма рассеяния стран по количественным параметрам ономастической структуры их описания в ГЕО-2
Fig. 5. Scatterplot of countries by quantitative parameters of their description onomastic structure in GEO-2
нального кластера ЮАР – США располагаются Китай и ФРГ, которые образуют отдельную подгруппу. Она несколько отклоняется от оси вверх, что отражает большее разнообразие ономастического пространства данных разделов по сравнению с общей тенденцией при описании стран в этом учебнике.
По оси абсцисс к этой подгруппе близка Россия, однако ее положение относительно оси ординат значительно отличается от Китая и ФРГ (а также Индии из общего кластера) по количеству используемых уникальных ИС. Так, при описании РФ на оним Россия (с вариантом РФ ) приходится 158 словоупотреблений, то есть 80 % от использования всех онимов, которые связаны с Россией. Для сравнения, в тексте о США на оним США с вариантом Соединенные Штаты приходится только 35 % словоупотреблений, а остальные онимы отражают различные географические объекты в США. При описании Германии название страны ( ФРГ / Германия ) составляет 34 % от всех онимов в тексте, Китая ( Китай / КНР ) – 48 %.
На рисунке 6 приводятся данные относительно описания стран в учебнике ГЕО-1.
В ГЕО-1 наблюдается в целом та же картина, что и в ГЕО-2. США находится в правом верхнем углу с максимальными по обоим показателям значениями. КНР образует отдель- ный кластер, однако в него входит Индия, а не ФРГ. Остальные страны образуют единый кластер, вытянутый по диагонали.
Обсуждение результатов
Изучение ономастического наполнения географических нормативно-научных текстов показывает, что состав и количество употребляемых в них онимов, их частотность являются маркерами содержания географического фрагмента нормативно-научной картины мира (общеобязательного географического знания).
Для единиц ономастического ядра, номинирующих ведущие объекты на географической и экономической картах мира (и, следовательно, в структуре географического знания), зафиксирована суммарная частота употребления, равная приблизительно 40 % при интенсивности использования онимов в тексте с частотой 1 оним на 14 слов.
Уровень отсечения частотного списка, формирующего ядро содержания географического фрагмента нормативно-научной картины мира, от периферии совокупного ономастического пространства находится в диапазоне 26–30 рангов в ранжированном по нисходящей ряду ИС.
Малочастотная лексика, в обоих источниках выполняющая функцию информацион-
' ♦ Индия
♦ КНР
30 -
♦ Япония
2Q _ ♦ Канада
~ * Великобритания
-
♦ Франция фр|.
-
10 - *♦
Италия Бразилия
О 1---------------------------------1---------------------------------1---------------------------------1---------------------------------I---------------------------------1---------------------------------I---------------------------------1---------------------------------I---------------------------------I1
О 20 40 60 80 100 120 140 160 180200
Рис. 6. Диаграмма рассеяния стран по количественным параметрам ономастической структуры их описания в ГЕО-1
Fig. 6. Scatterplot of countries by quantitative parameters of their description onomastic structure in GEO-1
ного расширения и/или создания ономастического фона, оказывает серьезное влияние на полноту раскрытия содержания ключевых имен. Охватывая менее 10 % всех словоупотреблений ИС, онимы гапакс легомена составляют около половины всех ИС в учебных текстах.
Рост использования онимов от начала учебника к концу имеет тенденцию, отражаемую степенной функцией.
Несмотря на достаточно большой период времени, разделяющий выпуск анализируемых учебников, и произошедшие за это время значительные изменения в политикоэкономической ситуации в стране и в мире, сравниваемые ННТ характеризуются весьма высоким уровнем сходства их ономастического пространства. Это отражается в целом ряде аспектов: в области ономастической насыщенности макротекста; идентичности ономастического состава ядра; соотношении гапаксов с частотной лексикой и, как следствие, формировании сходного ономастического фона; специфике ономастического описания стран.
Установление с помощью квантитативных методов функции нарастания ономастической (информационной) напряженности текста служит существенным основанием как для анализа концентрации ИС с применением метода, предложенного в наших предыдущих работах и основанного на суммировании частот для аппроксимации распределения признака [Андреев, 2023], так и для разработки рекомендаций по созданию новых текстов.
Выявленная близость основных характеристик ономастического пространства двух источников ННТ, находящихся на противоположных точках почти тридцатилетней временной оси, может рассматриваться с позиции соотношения статики и динамики в характеристике географического фрагмента общеобязательного научного знания. Эта близость свидетельствует в пользу объективности представляемой в учебниках информации, ее достоверности и подчеркивает определенную (и необходимую) устойчивость общеобязательного знания. В связи с полученными результатами возникает вопрос о соотношении в структуре общеобязательного знания стабильности и актуальности, что, в свою очередь, требует более четкого определения са- мого понятия актуальности по отношению к базовому знанию. Очевидно, что в решение этого вопроса, имеющего не только образовательное, но и социокультурное значение, данные квантитативного анализа нормативно-научных текстов разной временной принадлежности могут внести необходимую объективность.
Выводы
Проведенное исследование позволило получить следующие результаты и сформулировать некоторые выводы.
В ходе квантитативного анализа ономастического наполнения нормативно-научных макротекстов двух школьных учебников географии были выделены и охарактеризованы ядро и периферия ономастического пространства сопоставляемых географических нормативно-научных макротекстов, определен состав единиц, выполняющих роль информационного расширения и формирующих ономастический фон.
Результаты анализа частот проприальной лексики показали высокую интенсивность использования онимов в текстах. Их распределение отражается степенной функцией, параметры которой позволяют оценить интенсивность введения имен собственных в текст и рост их количества от начала учебника к его концу.
Ономастическая структура характеризуется сильным противопоставлением частотного ядра и периферии. Школьные учебники, разработанные и изданные с большой разницей во времени, демонстрируют выраженную инерцию структуры ядра. Оно характеризуется высокой степенью устойчивости во времени как по составу лексических единиц, их частотности, так и по соотношению параметров ядра между собой (частотные ранги, точка отсечения от периферии, количество типов онимов).
Перспективой работы является применение описанной методики для исследования ономастического пространства других предметных фрагментов ННКМ с целью определения сходств и различий ономастической структуры ННТ в зависимости от предметной сферы, на основе чего предполагается разработка рекомендаций по ономастическому наполнению предметных ННТ для составителей новых учебников.
