Онтологически-ориентированная система управления контентом информационно-учебных Web-порталов

Автор: Титенко Сергей Владимирович
Журнал: Образовательные технологии и общество @journal-ifets
Рубрика: Восточно-Европейская секция
Статья в выпуске: 3 т.15, 2012 года.
Бесплатный доступ
Работа посвящена разработке структурно-алгоритмических основ и программных средств управления информационно-учебным Web-контентом. Разработан комплекс моделей и методов управления Web-контентом информационно-учебных порталов, основными из которых являются объектно-ориентированная иерархически-сетевая модель контента, понятийно-тезисная модель формализации смысла контента, модель профессиональных компетенций, метод автоматического построения онтологии на основе стэнфордской модели нечеткого вывода, алгоритм генерации тестовых заданий и метод построения индивидуальной образовательной Web-среды.
Управление контентом, модель контента, индивидуальная учебная среда, онтология, автоматизация тестирования
Короткий адрес: https://sciup.org/14062415
IDR: 14062415
Текст научной статьи Онтологически-ориентированная система управления контентом информационно-учебных Web-порталов
В условиях информационного перенасыщения и бурного развития сети WWW, когда ежегодный прирост знаний составляет 4-6%, специалист получает до 50% знаний после окончания учебного заведения и почти треть общего объема своего рабочего времени должен тратить на пополнение профессиональных знаний [1]. В связи с этим вопросы построения эффективных систем управления профессиональной информацией и поддержки обучения приобретают особую значимость. Украина стоит перед вызовом внедрения и поддержки образовательных процессов по принципу «обучение через всю жизнь». Стандартизированные и достаточно статичные пяти-шестилетние университетские программы не способны полностью удовлетворить переменчивые требования рынка труда. Инновации постоянно меняют спрос на различные профессии и сами профессии в частности. Поэтому обучение и профессиональное развитие не прекращаются после завершения университета, а продолжаются и в дальнейшем. Технологии построения информационно-учебных Web-порталов и систем дистанционного образования имеют потенциал ответить на такой общественный вызов, предоставив удобные механизмы доступа пользователей к требуемой профессиональной информации и обеспечив поддержку индивидуализированного обучения.
Сегодня существует достаточно большое количество программных систем для организации дистанционного обучения, среди них Blackboard, WebCt, Moodle, IBM Learning Space и др. Такие системы предоставляют инструментарий для управления электронным обучением, однако они не обладают достаточными функциями для гибкого управления Web-контентом в контексте построения информационных порталов организаций или учреждений. С другой стороны типичные системы управления контентом (CMS), пригодные для создания информационных порталов, не содержат необходимых функциональных возможностей в контексте учебного процесса. Современность выдвигает требования индивидуализации и адаптации учебного и профессионального контента к потребностям пользователя, а это не может быть качественно реализовано в рамках упомянутых систем и требует применения средств описания предметных областей и моделей представления знаний. Проблема моделирования знаний в задаче управления Web-контентом информационно-учебных программных систем требует специальных подходов на стыке разных отраслей, среди которых разработка программного обеспечения, моделирование баз данных и знаний, дидактика, а также современные средства разработки Web-систем.
В отрасль моделирования учебного контента программных систем обучения внесли весомый вклад такие ученые как Брусиловский П., Мюррей Т., П. Де Бра, Башмаков А.И., Семикин В.А., Манако А.Ф., МакАртур Д., Мазурок Т.Л. и др. Проблема автоматизированного тестирования на основе программных комплексов рассмотрена в работах Елизаренко Г.М., Аванесова В.С., Сороко В.М., Станкова С. и др. Современные образовательные требования, а также концепция непрерывного обучения исследовались такими учеными как Згуровский М.З., Богданова И.Ф., Дресвянников В.А., Сивец С.Д. и др. Несмотря на достижения, нерешенной остается проблема построения программных систем для создания информационно-учебных Web-порталов, которые бы предоставляли пользователям удобные механизмы индивидуализированного доступа к требуемым профессионально-учебным ресурсам междисциплинарного характера.
Постановка задачи
Целью работы является разработка структурных основ программного обеспечения системы автоматизированного управления информационно-учебным Web-контентом, которая позволит организовать индивидуализированный доступ пользователей к требуемой профессионально-учебной информации.
Для достижения поставленной цели необходимо решить следующие задачи:
-
• Проанализировать особенности существующих программных систем, применяемых для управления Web-контентом информационных порталов учебного и профессионального назначения, а также осуществить анализ современных образовательных требований к ним.
-
• Разработать модели структурирования и формализации знаний и информации, представленных в Web-контенте информационно-учебного портала, с целью обеспечения основы для разработки и программной
реализации методов индивидуализированного доступа пользователей к требуемым профессионально-учебным ресурсам.
-
• Разработать методы и программно реализовать на их основе подсистему индивидуализированного доступа пользователей к требуемым ресурсам информационно-учебных Web-порталов.
-
• Разработать прикладную программную систему управления информационно-учебным Web-контентом с функцией
индивидуализированного доступа пользователей к требуемым информационно-учебным ресурсам.
Программные системы построения информационно-учебных порталов и современные образовательные требования
Современные образовательные тенденции предполагают, что системы построения информационно-учебных порталов (ИУП) должны быть чем-то большим, чем просто среда для передачи статических учебных материалов определенной группе пользователей с возможностью общения и последующим тестированием, что характерно для традиционных систем дистанционного обучения. Такие характеристики как индивидуальность, практическая целесообразность, релевантность, междисциплинарность и другие особенности непрерывного обучения требуют качественно иных методов и моделей построения таких систем. Модель образовательного процесса по требованиям непрерывного обучения в отличие от классического дистанционного обучения содержит следующие этапы: 1) определение образовательных потребностей и целей пользователя, 2) определение уже имеющихся у пользователя знаний и навыков, соответствующих целям обучения, 3) построение и адаптивная поддержка релевантного учебного процесса на основе сведений, полученных на 1-м и 2-м этапах.
Анализ существующих технологий, методов и моделей интеллектуальных систем обучения позволяет обратить внимание на недостатки таких систем в контексте непрерывного обучения, а также выработать рекомендации к их преодолению. Проблема однопредметности и закрытости контента обучающей системы должна быть преодолена путем обеспечения моделей контента способностью поддерживать междисциплинарные связи, а также представлять многопредметные учебные материалы. С целью обеспечения профессиональной направленности обучения программные системы управления контентом ИУП должны предусматривать моделирование профессиональных компетенций и должностных требований в их соотношении с учебным контентом. Образовательными требованиями к современным информационно-учебным Web-системам являются следующие: многопредметность и междисциплинарность учебно -методического наполнения, обеспечение средствами моделирования кадровых и производственных задач и компетенций; наличие методов автоматизированного построения индивидуальных учебных сред с функцией контроля и диагностики знаний. Таким образом предлагается соответствующая концептуальная схема системы управления контентом ИУП (рис.1).
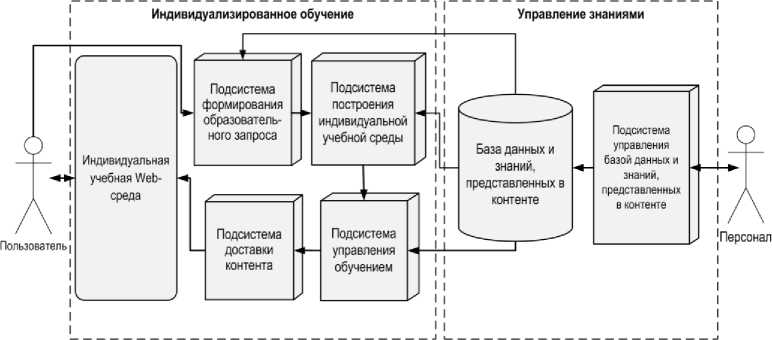
Рис.1. Концептуальная схема программной системы управления контентом ИУП
Ключевыми задачами в процессе создания такой программной системы являются построение модели базы данных и знаний, представленных в контенте, разработка структурно-алгоритмических основ подсистемы построения индивидуальной учебной среды и автоматизация тестирования знаний. Моделирование знаний должно осуществляется путем построения онтологии предметной области, представленной в учебном и профессиональном контенте системы. Таким образом, база знаний ИУП должна содержать контент, т.е. информационное наполнение, которое выражает знания языком коммуникации человека, его онтологически-ориентированную формализацию, а также дидактическую функцию, которая управляет на основе онтологии процессом поставки контента пользователю. Следовательно, задача моделирования знаний в системе управления контентом ИУП сводится к построению онтологически-ориентированной модели учебного контента, включающей три ключевых компонента: 1) информационное наполнение, 2) онтологию предметной области, 3) дидактическую функцию.
Комплекс моделей и методов для системы автоматизированного управления контентом ИУП
Предлагается двухуровневый подход к управлению контентом. На основе этого подхода на первом уровне работы с системой происходит управление знаниями. Уровень управления знаниями предусматривает выполнение двух основных функций: формализацию компетенций и формализацию контента. Результатом этой работы является построение Web-портала знаний организации или учреждения. Второй уровень работы с системой заключается в непосредственной организации индивидуализированного обучения и содержит такие ключевые функции: организация образовательного запроса (ОЗ) и автоматизированное построение индивидуальной учебной среды (ИУС). Ко второму уровню также относятся контроль и диагностика знаний, как необходимые компоненты учебного процесса. Функциональность системы на уровне организации индивидуализированного обучения целиком основана на знаниях, заложенных в систему на уровне управления знаниями.
Понятийно-тезисная модель и формирование онтологии предметной области
Для обеспечения моделирования контента на предметном уровне предлагается понятийно-тезисная модель (ПТМ) [2-3]. Она применяется как средство моделирования смысла контента ИУП, при этом формализация происходит внутри фрагмента учебного текста. Краеугольным камнем модели является понятие, предмет обсуждения, некоторый объект из предметной области, о котором в учебном материале есть знания. Теза - это некоторое сведение или утверждение о понятии. Понятия указывают на предмет контента, а тезы являются описательно-смысловым наполнением базы знаний, которое раскрывает характер и свойства имеющихся понятий. С каждым понятием связывается множество тез. Формально теза является одним или несколькими предложениями, в которых речь идет непосредственно о соответствующем понятии, однако само понятие там синтаксически не фигурирует. Приведем примеры: тезис о понятии «процедура» - «позволяет разбить программу на подпрограммы»; тезис о понятии «класс» - «может иметь в своей структуре не только поля-свойства, но и методы, то есть функции и процедуры». Множество понятий: C= { c 1 ,_,cn1 }. Множество тез: T= { t 1 ,...,tn2 }. Связь между тезами и понятиями: CT:T ^ C , TC: C ^ 2T .
Элементы ПТМ выделяются экспертом непосредственно из текста учебного фрагмента с помощью специализированных средств пользовательского интерфейса. В итоге каждый фрагмент v i может стать источником произвольного количества тез t j , , что задается отображением: TV:V ^ 2T, VT:T ^ V . Понятия, относящиеся к данному учебному фрагменту, и соответственно, учебный материал, к которому относится данное понятие, определяются операторами:
CV(v)= { c: TV(v)nTC(c)* 0}, VC(c)= { v:TV(v)nTC(c) * 0 } .
Классификация тез и понятий служит для сохранения в БЗ информации о смысловом или лексическом характере того или иного понятия или тезы: TClass=T → TClasses, CClass=C → CClasses.
На основе семантико-синтаксического анализа элементов ПТМ и стэнфордской модели нечеткого вывода [4] предлагается метод автоматического построения онтологии предметной области , основанной на отношении дидактического следования. Под дидактическим следованием concept_before(A, B) будем понимать такое отношение, которое указывает на то, что в структуре учебного материала понятие A следует представить раньше, чем понятие B , так как знания о понятии B основываются на знаниях о понятии A.
Метод автоматического построения онтологии основан на трех базовых логических правилах [5] :
Правило № 1. Если понятие «1» фигурирует в названии понятия «2», то понятие «1» является дидактической предпосылкой понятия «2» с высокой степенью достоверности:
ck е CinC ( c ) ^ concept _ before ( ck , c ) CCFcinc
Правило № 2. Если понятие «1» фигурирует в тезе понятия «2», то понятие «1» является дидактической предпосылкой понятия «2» с некоторой достоверностью:
t е TC ( c, ) a ck е CinT ( t ) a TClassCF(TClass ( t )) > 0 ^
^ concept _before ( ck,c ) (TClassCF ( TClass ( t )))
Правило № 3. Также для некоторых случаев действует обратное правило: если понятие «1» фигурирует в тезе понятия «2», то понятие «2» является дидактической предпосылкой понятия «1» с некоторой достоверностью:
t e TC ( c, ) л ck e CinT ( t ) л TClassCF ( TClass ( t )) < 0 ^
^ concept _ before ( ct , ck ) -- TClassCF ( TClass ( t )))
В случае, когда для противоположных гипотез одновременно имеет место CF>0 , истинной принимается гипотеза с большим значением CF , при этом фактор уверенности пересчитывается по формуле:
_ max ( CFCtoC ( a , c ), CFCtoC ( c , a ) ) - min ( CFCtoC ( a , c ), CFCtoC ( c , a ) ) . 1 - min ( CFCtoC ( a , c ), CFCtoC ( c , a ) )
Данные дидактической онтологии используются для построения дидактикосемантических карт [5] , которые предоставляют дополнительную информацию как эксперту, который отвечает за ПТ-формализацию, так и пользователю с целью повышения наглядности. Структурная схема ПТМ изображена на рис.2.
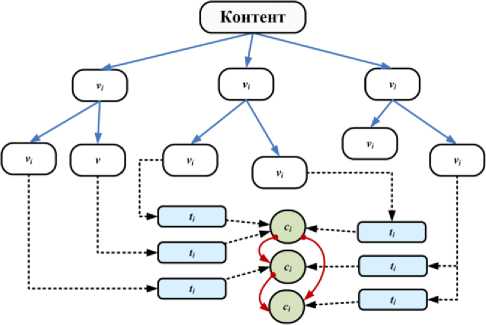
Рис.2. Структурная схема ПТМ и связь с контентом
Метод автоматического построения тестовых заданий на основе понятийно-тезисной модели
С целью представления структурных основ и алгоритмов генерации и автоматизированного анализа тестов разработана модель контроля и диагностики знаний и состояния обучения [2 ,3 ,6] . Строительным материалом тестовых заданий являются семантические сущности ПТМ. Множество тестов : Test= { test i }. Входным параметром теста является контрольная область учебного контента: Vtrg:Test ^ 2 V . Ресурсная область контента служит в качестве дополнительного источника ПТ-элементов: Vres:Test ^ 2V . Множество тестовых заданий: Task= { task i }. Связь тестов с заданиями задается отображением: TestTasks: Test → 2Task . Каждое задание связывается с контрольной ПТ-парой, т.е. таким понятием и его тезисом, которые лягут в основу этого тестового задания: TaskCT:Task ^ CT .
Формируется набор шаблонов для тестовых заданий TTempl= { TTempl, }, TaskTempkTask ^ TTempl . Каждое задание связывается с набором семантических элементов, используемых как варианты альтернативных ответов: TaskAItems:Task ^ 2C и2Т. Типизация вопросительного ПТ-элемента задается отображением: TQEntity:TTempl ^ CTEntity, где CTEntity= { Concept, Thesis }.
Классы ПТ-элементов, которые могут быть применены для тестового задания каждого из шаблонов: TQClasses: TTempl^ 2CCC™se и 2TClasses . Запрещенные ПТ- классы в задании: TQNotClasses: TTempl^ 2CCassesu 2TClasses. Для аналогичного указания классов для ПТ-элементов, служащих как варианты ответов, используются отображения TAClasses и TANotClasses.
Предложенный алгоритм построения и визуализации тестового задания taskk на основе ПТ-элементов, их связи с учебными материалами и шаблонами тестовых заданий содержит следующие шаги:
-
1) выбор контрольной ПТ-пары:
TaskCT(task k )=(t k ,c k ): (t k ,c k )e CT л VT(t k )e Vtrg(test k ) ;
-
2) поиск допустимых шаблонов заданий:
П"= {tt:TQEntity(tt)=Conceptл(CClass(ck) е TQClasses(tt)vTQClasses(tt)=0)л CClass(ck) 6 TQNotClasses(tt)л(TClass(tk) e TAClasses(tt)vTAClasses(tt)=0)л TClass(tk)^ TANotClasses(tt)}, аналогично ищется TT" для TQEntity(tt)=Thesis, TT=TTC TT";
-
3) выбор шаблона задания: TaskTempl(taskk)=ttk ;
-
4) поиск альтернативных вариантов ответов;
TaskAItems'= {t: t * tk лCT(t) *ckл( (TClass(t)e TAClasses(ttk)л TAClasses(ttk)*0)v(te Tл TAClasses(ttk)=0) )л TClass(t)6 TANotClasses(ttk)л VT(t)e Vres (testk)}, где TaskAItems' состоит из тез; аналогично ищутся варианты ответов-понятия;
-
5) визуализация тестового задания.
Иерархически-сетевая объектно-ориентированная модель структуры информационно-учебного Web-контента
Для обеспечения иерархического представления больших объемов контента, поддержки междисциплинарных связей, тематической группировки и сортировки, поддержки повторного использования контента, а также для организации навигации по контенту Web-портала предлагается иерархически-сетевая объектноориентированная модель структуры информационно-учебного Web-контента [7] . Схематически модель контента изображена на рис. 3.
Элементы контента: V= { vi } , , где i=1..nV . Дочерние элементы: Ch:V ^ 2V . Родительские связи: F:V ^ V . Оператор определения всех элементов-потомков: Desc(e) , eeV . Бинарные сетевые связи между элементами: NcVxV . Типизация элементов контента: VTypes= { item, list, block } . Здесь item означает обычный элемент контента, list - список, block - семантический блок. Семантические роли или типы элементов контента задаются отношением: VType:V ^ Vtypes.
Понятие семантического блока контента вводится с целью описания множества элементов контента, которые имеют логическое и структурное единство, имеют единый источник происхождения, например одно авторство, и представляют одну тему. Множество элементов семантического блока определяется оператором Desc(v) , где v - вершина блока в дереве контента, VType(v)=block . Отношение псевдонимов между элементами контента служит для повторного использования контента: A:V ^ V . Говорим, что элемент vk является псевдонимом элемента vl в том случае, когда ( vk,vl) eA , при этом vk играет роль получателя, а vl - источника.
Для организации различных межпредметных и внутрипредметных связей между элементами контента, моделирования предметных областей, каталогизации, группировки и поиска ассоциативного контента предлагается использовать структуру тематических групп. Множество групп: G= {gb...,gnG}. Дочерние группы: ChG:G^2G. Родительские связи: FG:G^G. Определение групп-потомков происходит с помощью оператора: DescG(g), g∈G. Определение потомков множества групп: DescGG(A) = u(DescG(gi)), где gieA, AcG. Оператор генеалогической линии группы g: AncG(g), g∈G. Генеалогическая линия множества групп A⊆G: AncGG(A)=∪(AncG(gi)),где gi∈A, A⊆G.
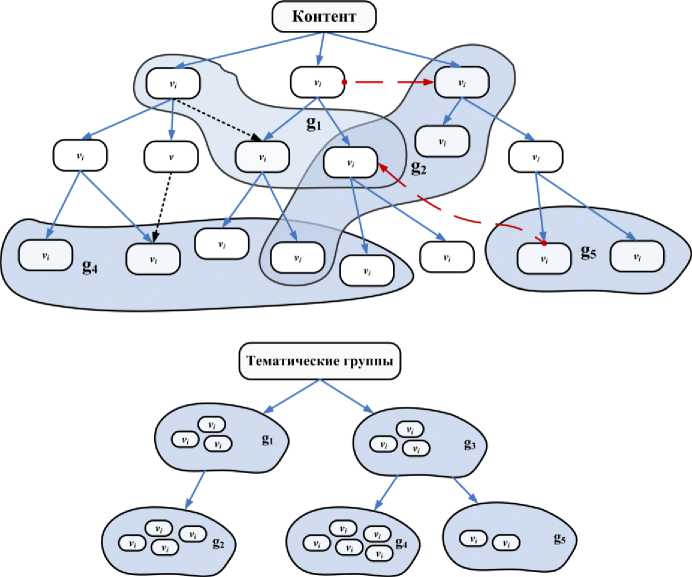
Рис.3. Схематическое изображение структурной модели Web-контента: дерево контента и дерево тематических групп
Тематической группе соответствует набор элементов контента, которые входят в эту группу, что задается отображением: VG:G → 2V . Благодаря семантическим ролям элементов контента, заданным с помощью VType , множество контента, касающегося данной группы, автоматически расширяется, что реализуется благодаря разработанному оператору:
GV(v) = { g: ve VG(g)v(veDesc(v') л v'eVG(g) л VType(v')=block ) (ve Ch(v’) л v’eVG(g) л VType(v’)=list) } .
Структурная модель профессиональных компетенций (МПК)
Для представления знаний о специальностях, профессиях и должностях предлагается структурная модель профессиональных компетенций (МПК) [8] . С помощью МПК описываются конкретные профессиональные компетенции (знания, навыки, умения), из совокупности которых формируется общее описание той или иной специальности (профессии), при этом устанавливается связь между компетенциями и соответствующим учебным контентом. Множество компетенций, описанных в системе: S= { s i } , i=1..nS . Иерархия компетенций: дочерние компетенции
ChS:S ^ 2s ; родительские связи FS:S ^ S . Декомпозиция компетенции, т.е. множество всех потомков: DescS(s), seS . Для того, чтобы предоставить возможность организовать модель компетенций таким образом, чтобы одна компетенция могла стать основой не только для единственной родительской, но и для других компетенций высшего уровня, вводится отношение псевдонимов: AS:S → S . Таким образом s=AS(s') представляет компетенцию-источник s для ее псевдонима s' . Связь компетенций с контентом: VS:S → 2V; SV:V → 2S . Для поиска полного набора контента компетенции с учетом семантических ролей элементов контента, заданных их типизацией, разработан соответствующий оператор:
VatS(s) = { v: veVS(s) v (ve Desc(v') л v'eVS(s) VType(v')=block) v
(ve Ch(v') л v'eVS(s) л VType(v')=list) } .
С помощью компетенций предлагается строить профиль специалиста: Exp= { expi }. Связь между профилем специалиста и его компетенциями задается отображением: SExp: Exp ^ 2 .
С целью представления структурных основ и алгоритмов генерации и автоматизированного анализа тестов разработана модель контроля и диагностики знаний и состояния обучения (МКД), подробно описанная в работах [2 ,3 ,6] .
Для реализации запроса к системе на образовательные услуги и инициализации индивидуального учебного процесса предлагается использовать модель образовательного запроса (МОЗ). Образовательный запрос Eq может задаваться с помощью различных элементов, среди которых следующие: 1) целевые компетенции или профиль специалиста: EqScS или EqExpcExp , 2) целевые учебные понятия: EqCcC; 3) целевой контент или учебный курс: EqVcV ; 4) целевая тематическая группа или предметная область: EqGcG . Полное описание образовательного запроса имеет вид:
Eq= { EqS, EqExp, EqC, EqV, EqG }.
Модель пользователя
Модель пользователя (МП) описывает цели обучения и уровень знаний пользователя системы. Множество пользователей в системе: L= { l i } , где i=1..nL . Целевой профиль специалиста: LExpAims:L → 2Exp . Целевые компетенции ученика: LSAims: L ^ 2S. Целевой контент пользователя: LVAims:L ^ 2 V . Целевые понятия ученика: LCAims:L ^ 2C . Целевые предметные области пользователя: LGAims:L ^ 2 G . Таким образом, совокупные цели пользователя задаются множеством:
LAims= { LExpAims, LSAims, LVAims, LCAims, LGAims } .
Подсистема автоматизированного построения индивидуальной учебной среды
Подсистема организации индивидуализированного обучения разработана для обеспечения обработки образовательного запроса и инициализации релевантного учебного процесса путем построения индивидуальной учебной среды (ИУС). В зависимости от целей пользователя и типа его образовательного запроса учебный процесс может принимать различные по целевому назначению и объему формы: 1) получение специальности: LExpAims(li)=EqExp; 2) получение компетенции или адаптированной специальности: LSAims(li)=EqS; 3) изучение индивидуального учебного курса: LVAims(li)=EqV; 4) исследование предметной области: LGAims(li)=EqG; 5) изучение отдельного учебного понятия: LCAims(li) = EqC.
Генерация ИУС для получения специальности происходит на основе сведений о профиле специалиста. Полный набор компетенций, касающихся данного профиля, является декомпозицией профиля специалиста и определяется следующим образом:
SDExp(exp)= { seS: seSExp(exp) v s eDescS(a), где aeSExp(exp) } .
Всю совокупность контента декомпозированного профиля специалиста будем называть профильной областью контента данного специалиста: VSDExp(exp) = { v: veVatS(s), где s eSDExp(exp) } .
После получения совокупности контента V=VSDExp(exp), V'cV декомпозиции профиля expeExp для его иерархического структурирования применяются базовые отношения иерархичности между элементами контента F и Ch . В итоге получаем некоторую совокупность поддеревьев контента, которые могут рассматриваться в качестве набора индивидуальных учебных курсов и модулей . Оператор Roots (V') укажет на корни новообразованных поддеревьев.
Для решения задачи дидактического упорядочения полученных блоков контента разработан метод на основе отношений между понятиями онтологии с применением аппарата стэнфордской модели нечеткого вывода (рис.4).
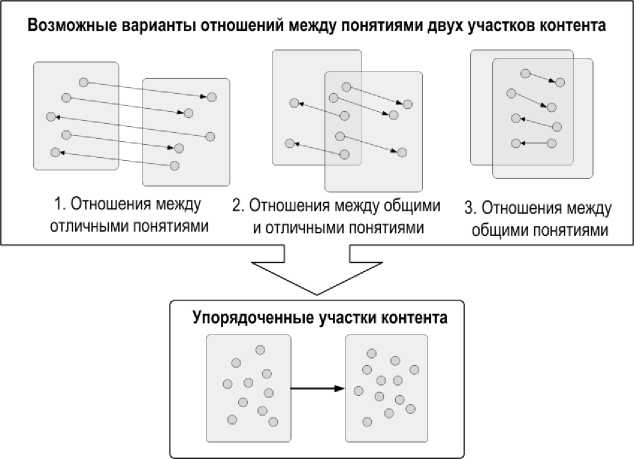
Рис. 4. Схематическое изображение задачи дидактического упорядочения контента
Этапы метода упорядочения индивидуального контента на основе онтологии и нечеткого вывода [9] :
1.Предварительный этап построения транзитивных связей между понятиями и формирование транзитивного замыкания графа онтологии, основанного на правиле:
concept _ before ( ck , c )( CFH ) A concept _ before ( c , cm )( CFim ) ^ concept _ before ( c k , c m ) ( CF k, x CF im } .
Задача решается на основе модифицированного алгоритма Флойда-Варшала, где в качестве весов ребер рассчитываются факторы уверенности в соответствии с представленным выше правилом транзитивности.
-
2. Поиск целевых и фоновых понятий каждого из участков контента V с помощью правил:
-
3. Попарный анализ отношения следования между участками, на основе правил:
3 t ( CT ( t ) = c л tClass(t ) * tAttaching л VT ( t ) e V ) ^
^ concept _ essential ( c , V )
V t ( CT ( t ) = c л VT ( t ) e V л tClass(t ) = tAttaching ) ^ ^ concept _ pre (c , V ) .
concept _ essential ( c k , V k ) л concept _ pre ( c k , V ) ^
^ content _ before(V k , Vt ) C2F ees
, concept _ essential (ck, Vk) л cl e CVV(Vl) л concept _ before(ck, cl) ^ content _ before(Vk, Vl) CFg ^
где CVV ( V ) = { c : VC ( c ) о V * 0} .
-
4. Сортировка участков контента с помощью алгоритма топологической сортировки ациклического орграфа.
На основе предложенного комплекса моделей, методов и алгоритмов создано программное обеспечение системы автоматизированного управления контентом ИУП. Система функционирует на открытом учебном портале znannya.org, который представляет учебные материалы по информационным технологиям, программированию и проектированию программного обеспечения. Предложенный программный комплекс может применяться для построения информационноучебных Web-порталов по различным предметным областям с функцией индивидуализированного доступа пользователей к требуемым информационным ресурсам.
Заключение
В работе решена задача построения комплекса моделей и методов и создания на их основе программного обеспечения онтологически-ориентированной системы управления информационно-учебным Web-контентом с функцией индивидуализированного доступа пользователей к требуемой профессиональноучебной информации в рамках информационного Web-портала.
Разработана иерархически-сетевая объектно-ориентированная модель представления данных и знаний, представленных в Web-контенте, что обеспечило основу для информационной структуры разрабатываемой программной системы и предоставило комплексное решение задач репрезентации больших объемов многопредметной информации, организации междисциплинарных связей, моделирования предметных областей, представления структуры профессиональных компетенций и организации навигации в информационном Web-портале.
Разработана модель формализации понятийной составляющей контента информационно-учебной Web-системы, что обеспечило основу для метода автоматического построения онтологии предметной области и метода автоматизированного построения тестовых заданий.
Предложен метод автоматического построения онтологии предметной области для информационно-учебных Web-систем на основе стэнфордской модели нечеткого вывода. Суть метода заключается в автоматическом определении семантических отношений между структурными элементами формализованного контента на базе аппарата нечеткого вывода.
На основе онтологического подхода и нечеткой логики разработан метод автоматического построения индивидуальной междисциплинарной Web-среды обучения. Разработанный метод обеспечил основу для программной реализации подсистемы индивидуализированного доступа пользователей Web-порталов к требуемым информационно-учебным ресурсам.
Разработана прикладная программная система управления контентом с расширенным инструментарием автоматизированного построения информационноучебных Web-порталов, содержащая программные средства создания междисциплинарной базы контента учебного и профессионального назначения, средства автоматического построения и отображения онтологии предметной области, инструментарий для автоматического построения тестовых заданий, а также средства построения индивидуальной информационно-учебной среды. Текущие исследования и публикации представлены на сайте
