Онтологический инжиниринг в решении задач корпусной лингвистики

Автор: Шучалова Ю.С., Ланин В.В.
Журнал: Вестник Пермского университета. Математика. Механика. Информатика @vestnik-psu-mmi
Рубрика: Информатика. Информационные системы
Статья в выпуске: 1 (28), 2015 года.
Бесплатный доступ
Рассмотрены методы автоматического построения онтологии на базе корпуса документов, представлена авторская система классификации методов. При анализе корпусов документов предлагается использовать многоаспектную онтологию электронных документов.
Корпусная лингвистика, онтология, автоматическое построение онтологии
Короткий адрес: https://sciup.org/14729969
IDR: 14729969 | УДК: 004.822
Ontological engineering in corpus linguistics
The article describes the methods of automatic ontology construction of based on a document corpus. Classification of existing methods is presented. Using of multidimensional electronic documents ontology is proposed for corpus analysis purpose.
Текст научной статьи Онтологический инжиниринг в решении задач корпусной лингвистики
Введение 1. Онтологии и их применение
В настоящее время во многих областях компьютерной лингвистики работа ведётся с корпусами текстов. Корпусом называется коллекция документов, объединённых общей тематикой [1]. Существует потребность автоматизации многих процессов, связанных с анализом корпуса. Создано множество программных средств, предоставляющих широкий спектр возможностей для обработки текстов [2]. Однако не все эти программы содержат средства анализа текста с позиции семантики, в том числе построения онтологий.
Тем не менее, именно добавление компонентов, предназначенных для автоматического или полуавтоматического построения онтологии на основе имеющегося корпуса, позволит расширить возможности программы и повысить точность некоторых видов анализа текста. Например, построения тезауруса предметной области, организации семантического поиска или указания особенностей словоупотребления.
Исследование выполнено при финансовой поддержке РФФИ в рамках проектов № 14-07-31273-мол а и 14-07-31330-мал а.
В литературе приводятся различные определения понятия "онтология". В монографии Н.В. Лукашевич [3] этот термин вводится как «система, состоящая из набора понятий и набора утверждений об этих понятиях, на основе которых можно строить классы, объекты, отношения, функции и теории». Онтологии можно классифицировать по типам отношений между понятиями: например, таксономия (класс-подкласс), партономия (часть-целое) и т.п.
Онтологии применяются для решения различных задач, часто связанных с обработкой текстовых документов и корпусов. Представление данных с помощью онтологий позволяет в удобном виде отображать связи между понятиями предметной области [5], осуществлять семантический поиск и др. Среди наиболее известных сфер применения онтологий - создание Семантической паутины (Semantic Web, Web of Data) [6] для упрощения машинной обработки данных Всемирной паутины, а также реализации логического вывода на основе имеющихся ресурсов.
-
2. Теоретические подходы
к автоматическому построению онтологий
Постановку задачи можно сформулировать следующим образом. На входе имеется коллекция текстов, тематика которых принадлежит одной предметной области. Необходимо получить на основе данной коллекции множество понятий (концептов) предметной области и связи между ними. Формат входных данных и возможные связи между объектами могут варьироваться в зависимости от метода.
Большая часть встретившихся в ходе исследования методов автоматического построения онтологий включает в себя элементы лингвистического анализа. Иногда лингвистический анализ комбинируется с использованием статистики или методов искусственного интеллекта (например, генетических алгоритмов).
На основе исследованных методов автоматического построения онтологий можно выделить следующие группы:
-
- лингвистические методы;
-
- статистико-лингвистические методы;
-
- методы, опирающиеся на способ хранения информации;
-
- прочие методы.
-
2.1. Лингвистические методы
-
2.2. Статистико-лингвистические методы
Ниже будут рассмотрены методы, относящиеся к каждой из групп. Важно уточнить, что в данной статье приведены условные названия групп и самих методов.
Данная группа содержит множество методов, опирающихся на лингвистический анализ текста.
Одним из таких методов является использование лексико-синтаксических шаблонов [7]. Подобные шаблоны разрабатываются экспертами и позволяют выявить отношения между терминами на основе части текста на естественном языке.
Разработанные Е.И. Большаковой и её коллективом шаблоны [8] применяются для анализа научно-технических документов. Существует язык LSPL, предназначенный для формализованной записи шаблонов. Однако стоит отметить, что данный язык не единственный: например, в работе [7] Е.А. Рабчев-ский описывает собственный язык лексикосинтаксических шаблонов, разработанный отдельно от группы Большаковой и назван- ный также LSPL. По форме записи язык Раб-чевского похож на языки HTML, XML. На основе полученных из текста на естественном языке семантических моделей можно построить онтологию.
Некоторые методы также используют языковые шаблоны для выявления связей между понятиями, но связи эти устанавливаются в ходе анализа корпуса текстов предметной области. В работе [9] предлагается информационная система для построения и самообучения онтологии. В процессе построения онтологии производится разметка корпуса синтаксическими тегами (несущими информацию о морфологии слова), определяются наиболее часто встречающиеся лингвистические структуры, на основе чего строятся лингвистические шаблоны. Далее из текста выделяются фрагменты, соответствующие полученным шаблонам, и после нормализации новое понятие вводится в базовую онтологию. Для оценки релевантности выделенных понятий необходимо мнение эксперта предметной области.
Ещё один лингвистический метод реализован в плагине OntoLT [10]. В нём используется XML-разметка текста, на основе которой по указанным правилам выделяются кандидаты на роли сущностей и связей. Правила вводятся пользователем до начала работы приложения на специальном языке, названном в документации «precondition language». Они тоже представляют собой своего рода лексико-семантические шаблоны.
Следующая группа методов помимо лингвистических особенностей текста, учитывает различные статистические характеристики.
Их применение удобно рассмотреть на примере статьи Е.С. Мозжериной [11] об автоматическом построении онтологий на базе коллекции текстов. Перед вычислением собственно статистик производится предварительная обработка корпуса, включающая в себя приведение документов к единому формату, токенизацию, лемматизацию и исключение стоп-слов. Для выделения из коллекции текстов терминов автор вводит следующие эвристики:
– имя класса онтологии содержит хотя бы одно существительное;
– общеупотребительные слова по сравнению с терминами обладают большей часто- той встречаемости, приблизительно равной в различных предметных областях;
– количество информации термина нескольких слов больше, чем количество информации отдельных слов, входящих в его состав.
С опорой на указанные эвристики выделяются термины. Также автор указывает на возможность использования существующих разработанных экспертами онтологий для работы с неспециализированными в предметной области документами.
Для случая двусложных терминов приведена следующая статистика, определяющая количество "взаимной информации" [11]:
mi ( x , y ) =
P ( x , y ) P ( x ) P ( y ),
где x , y – отдельные слова термина, P(x) – частота встречаемости x , P(x,y) – частота совместной встречаемости x и у .
Отношения между классами также определяются с помощью количества информации. В работе Мозжериной описаны отношения типов "is-a" и "synonym-of". По количеству информации можно распределить уровни иерархии между терминами. Также учитывается вхождение слова (более общего термина) в другие термины. Кроме этого, отношение "is-a" может устанавливаться из учёта контекста, как и отношение "synonym-of". В данном случае контекст термина понимается как множество слов, которые встречаются одновременно с данным.
Другой способ использования статистики показан в работе [12]. Этот способ удобен для викификации текстов (соотношения понятий и сущностей из текста со связанной страницей в Википедии). Подготовка корпуса текстов аналогична предыдущему методу. Далее из текста выделяются кандидаты в термины: все одно-, двух- и трёхсловные словосочетания, удовлетворяющие имеющимся лингвистическим шаблонам (например, "прилагатель-ное_существительное", "существитель-ное_существительное"). С помощью методов, реализованных в авторском фреймворке для обработки текстов Texterra, из имеющегося списка выделяются термины.
Texterra базируется на знаниях из Википедии и сохраняет все входящие и исходящие ссылки для статьи. Таким образом для каждо- го нового понятия определяются "соседи" по контексту, с учётом того, что термины, появляющиеся в схожих контекстах, обычно имеют схожее значение. При обработке термина выбираются термины из текстового "окна" (15 слов справа и слева от термина) и вычисляются случаи совместного употребления с данным термином. В качестве оценки возможности неслучайного "соседства" терминов используется статистика t-тест [13].
Ещё один статистический метод представлен в работе [14]. Извлечение терминов производится с помощью z-статистики (z-score), вычисляемого для значений частотности слов и "показателя странности" (weirdness index). Последняя характеристика вычисляется с использованием как специализированного корпуса, так и неспециализированного (e.g. British National Corpus). Отношения вида "is_a" определяются между словами и содержащими их словосочетаниями (collocates), на основе чего строятся иерархии.
-
2.3. Методы, опирающиеся на способ хранения информации
-
2.4. Прочие методы
Как видно из названия группы, следующие методы для построения онтологий используют особенности определённым образом структурированной информации.
Одним из таких методов является кластеризация [15]. Для построения онтологий с её помощью документы представляются в виде набора терминов и разбиваются на кластеры по тематике. Определяется частота встречаемости каждого термина (вес). Терминами онтологии выбираются термины с частотой выше средней, а термины с максимальным весом являются понятиями (концепциями). Представляя коллекцию документов в виде дерева, можно задать иерархические отношения в онтологии (таксономию).
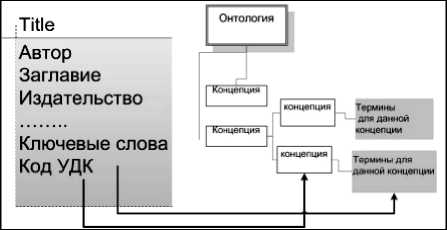
Метод выделения терминов из ББД [15]
Существуют методы, которые нельзя отнести ни к одной из вышеописанных групп. В частности, таким является один из методов искусственного интеллекта, описанный в монографии Л.В. Найхановой [16]. Здесь для автоматического построения онтологий применяется генетическое и автоматное программирование. Одним из особенностей и достоинств данного метода можно назвать возможность извлекать в ходе построения онтологии новую информацию.
-
3. Сравнение методов автоматического построения онтологий
-
4. Оценка эффективности методов автоматического построения онтологий
Универсального алгоритма автоматического построения онтологий в настоящий момент не существует. Каждый из вышеописанных методов обладает достоинствами и недостатками, связанными с самой идеей алгоритма и требующимися для его осуществления данными.
К последним можно отнести такие данные, как набор лексико-семантических шаблонов (метод лексико-семантических шаблонов), правил определения онтологических структур (метод OntoLT [10]), список начальных эвристик для выделения терминов (метод, описанный в работе Е.С. Мозжериной [11]). Кроме того, некоторые методы требуют особенной (не стандартной для корпуса текстов) предварительной разметки текста. Так, метод OntoLT базируется на работе с XML-разметкой.
Большая часть методов автоматического построения онтологий может быть универсальной в плане работы с разными языками, но потребуют создания собственных или использования имеющихся наборов данных, относящихся к нужному естественному языку. Например, лексико-семантических шаблонов или стоп-слов.
Следует также отметить, что описанные методы позволяют выявлять различные виды онтологий. Наиболее широкий спектр возможностей в этом плане предоставляют методы лексико-семантических шаблонов, так как шаблоны составляются с учётом не только морфологии, но и семантики естественного языка.
Качество построенных онтологий может различаться в зависимости от имеющихся данных и целей приложения, использующего онтологию. В работе [11] предложено оценивать онтологии по качеству работы систем семантического поиска, использующих онтологии.
Очевидным подходом является сравнение полученной онтологии предметной области с экспертным решением задачи. Однако работа экспертов требует большого труда и времени, поэтому особую ценность в деле оценки эффективности алгоритмов приобретают те общедоступные специализированные корпуса, для которых существует построенный тезаурус терминов [11].
-
5. Многоаспектная онтология электронных документов в обработке корпусов документов
Для решения задач обработки электронных документов необходимо иметь консолидированные знания об их структуре и содержании (формат и тип электронного документа, его структура). Таким ресурсом может стать многоаспектная онтология электронных документов [17]. В данном онтологическом ресурсе содержатся понятия, отно- сящиеся к трём выделенным аспектам представления информации о документах. Каждый аспект описывается онтологией, однако понятия, относящиеся к различным аспектам, связаны между собой. Таким образом, создаётся единая онтология электронных документов. Ресурс поддерживает возможность расширения и уточнения для настройки на решение конкретных задач.
Заключение
Итак, существуют методы автоматического построения онтологий, использующие разные подходы для решения задачи. В зависимости от подходов было выделено четыре основных группы методов: лингвистические, статистико-лингвистические, опирающиеся на способ хранения информации и прочие методы. Основная идея лингвистических методов состоит в выявлении понятий и связей с помощью лексико-синтаксических шаблонов. Статистико-лингвистические методы при построении онтологии опираются на вычисление статистических функций, учитывая лексические особенности при выделении терминов. Методы, опирающиеся на способ хранения информации, работают с документами, имеющими чёткую структуру – например, из библиографических баз данных. Прочие методы включают в себя элементы генетического и автоматного программирования и др.
Целесообразность использования того или иного из вышеописанных методов зависит от множества факторов. Среди них: наличие или отсутствие необходимых данных, в том числе учитывающих специфику естественного языка; доступа к ресурсам, которые используются в методе; наличие возможности структурировать имеющиеся данные определённым образом; типа онтологий, необходимых для решения пользовательских задач.
Возможно также повышение эффективности алгоритмов за счёт использования дополнительных лингвистических шаблонов, статистических характеристик, кластеризации коллекции документов.
Таким образом, подобрав и реализовав оптимальный метод автоматического построения онтологий, можно расширить функционал приложения, предназначенного для анализа текстовых документов. Также при построении онтологии будут полезны метаданные о документе и его семантический ин- декс, которые могут быть получены с использованием многоаспектной онтологии электронных документов.
Список литературы Онтологический инжиниринг в решении задач корпусной лингвистики
- Национальный корпус русского языка .//URL: http://www.ruscorpora.ru/(дата обращения: 01.10.2014).
- Software, Tools, Lists, Recourses//URL: http://www.uow.edu.au/~dlee/software.htm (дата обращения: 01.10.2014).
- Лукашевич Н.В. Тезаурусы в задачах информационного поиска. М.: Изд-во Моск. ун-та, 2011. С. 100-103.
- Гаерилова Т.А., Хорошевский В.Ф. Базы знаний интеллектуальных систем: учебник для вузов. СПб.: Питер, 2000. 384 с.
- Murray Т. Special purpose ontologies and the representation of pedagogical knowledge//ICLS '96 Proceedings of the 1996 international conference on Learning sciences. P. 235-242.
- W3C Semantic Web Activity Homepage .//URL: http://www.w3.org/2001/sw/(дата обращения: 01.10.2014).
- Рабчевский E.A. Автоматическое построение онтологии на основе лексико-синтаксических шаблонов для информационного поиска//Тр. 11-й Всерос. науч. конф. "Электронные библиотеки: перспективные методы и технологии, электронные коллекции" -RCDL'2009. Петрозаводск, 2009. С. 69-77.
- Большакова Е.И., Васильева Н.Э., Морозов С. С. Лексико-синтаксические шаблоны для автоматического анализа научно-технических текстов//Десятая Национальная конференция по искусственному интеллекту с международным участием КИИ-2006. Тр. конф. в 3-х т. М.: Физмат-лит, 2006. Т. 2. С. 506-524.
- Оробинская Е.А. Метод автоматического построения онтологии предметной области на основе анализа лингвистических характеристик текстового корпуса. URL: arxiv.org/pdf/1405.1346 (дата обращения: 01.10.2014).
- Buitelaar, P., Olejnik, D., Sintek, М. А protege plug-in for ontology extraction from text based on linguistic analysis. Bussler, C.J., Davies, J., Fensel, D., Studer, R. (eds.) ESWS 2004. LNCS. T. 3053. C. 31-44.
- И.Мозжерина Е.С. Автоматическое построение онтологии по коллекции текстовых документов//Электронные библиотеки: Перспективные Методы и Технологии, Электронные коллекции -RCDL 2011. Воронеж, 2011. С. 293-298
- Astrakhantsev N.A., Fedorenko D.G., Turda-kov D.Y. AUTOMATIC ENRICHMENT OF INFORMAL ONTOLOGY BY ANALYZING A DOMAIN-SPECIFIC TEXT COLLECTION//Компьютерная лингвистика и интеллектуальные технологии: по матер, ежегод. междунар. конф. "Диалог" (Бека-сово, 4-8 июня 2014 г.). Вып. 13(20). М.: Изд-во РГГУ, 2014. С. 29-42.
- Manning C.D. Foundations of statistical natural language processing//H. Schutze (Ed.). MIT press, 1999.
- Ahmad K, Gillam L. Automatic Ontology Extraction from Unstructured Texts//In (Eds.) R. Meersman and Z. Tari. On the Move to Meaningful Internet Systems -OTM, Confederated Int. Conf, CoopIS, DOA, and OD-BASE 2005, AgiaNapa. Ч. П. C. 1330-1346.
- Захарова И.В., Тимченко М.С Способы автоматического построения онтологии для задач анализа текстов//Знания-Онтологии-Теории: тр. Всерос. конф. ЗОНТ-09. Новосибирск, 2009. Т. 2. С. 164-167.
- Найханова Л.В. Технология создания методов автоматического построения онтологии с применением генетического и автоматного программирования//Л.В.Найханова. Улан-Удэ: Изд-во БНЦ СО РАН, 2008. 244 с.
- Ланин В. Онтологии как основа функционирования систем обработки электронных документов//Матер. Всерос. конф. с междунар. участием "Знания-Онтологии-Теории". Новосибирск, 2009, Т. 2. С. 173-177.
