Онтология методов машинного обучения при управлении проектами

Автор: Мурзагалеев Т.М., Жукова Н.А.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Инжиниринг онтологий
Статья в выпуске: 2 (60) т.16, 2026 года.
Бесплатный доступ
Применение методов машинного обучения в области управления проектами потенциально обеспечивает ряд преимуществ, которые могут позволить улучшить управление. Для эффективного применения методов машинного обучения используются наиболее показательные метрики с учѐтом разнообразия наборов данных, для которых требуется структурирование и систематизация элементов управления проектами. Целью данного исследования является разработка онтологии, позволяющей обеспечить необходимую информацию о применении методов машинного обучения в управлении проектами для прогнозирования трудозатрат и сроков выполнения проектов. Выполнен обзор методов машинного обучения, их метрик и наборов данных из научных публикаций, разработана и описана структура онтологии в области применения методов машинного обучения в управлении проектами для прогнозирования трудозатрат и сроков проектов, описана схема информационного взаимодействия пользователя с онтологией. Результаты проведѐнного исследования могут позволить упростить процесс поиска необходимых методов машинного обучения для их использования при управлении проектами на основе новых или общедоступных наборов данных.
Онтология, управление проектами, прогнозирование срока проекта, трудозатраты проекта, методы машинного обучения, набор данных
Короткий адрес: https://sciup.org/170213152
IDR: 170213152 | УДК: 004.82 | DOI: 10.18287/2223-9537-2026-16-2-300-313
Ontology of machine learning methods in project management
The application of machine learning methods in project management offers a number of potential advantages that can contribute to improving project management processes. Effective use of machine learning methods requires the identification of the most informative performance metrics while taking into account the diversity of available datasets, which in turn necessitates the structuring and systematization of project management elements. The aim of this study is to develop an ontology that provides the information necessary for the application of machine learning methods in project management, particularly for forecasting project effort and completion time. A review of machine learning methods, evaluation metrics, and datasets reported in scientific publications was conducted. Based on the results of this review, an ontology structure was developed and described for the application of machine learning methods in project management for effort estimation and project schedule forecasting. In addition, a scheme of user interaction with the ontology is presented. The results of the study may facilitate the process of identifying appropriate machine learning methods for project management tasks using new or publicly available datasets.
Текст научной статьи Онтология методов машинного обучения при управлении проектами
Основными проблемами при управлении проектами (УП) в любой отрасли являются малоэффективное использование ресурсов, превышение ожидаемой продолжительности выполнения задачи и перерасход ресурсов, а также отсутствие непрерывного мониторинга процесса выполнения проекта [1, 2]. Точная оценка сроков и затрат проектов позволяет разрабатывать планы выполнения работ, выявлять и преодолевать потенциальные задержки и конфликты, а также обеспечивать баланс между стоимостью и качеством [3, 4].
Применение прогнозирующих методов машинного обучения (ММО) для оценки сроков и затрат при разработке проектов считается высокоэффективным способом устранения неопределённости, а также автоматизации решения повторяющихся задач, составления прогнозов и предоставления аналитических данных для эффективного принятия решений [5, 6].
Успешность применения ММО в УП зависит от наличия актуальных и высококачественных исходных данных. В качестве характеристик наборов данных (НД), используемых для построения модели, рассматриваются: размер НД, наличие выбросов, категориальных признаков, пропущенных значений и др. Разнообразие и сложность проекта в сочетании с присутствующими рисками затрудняют разработку модели, позволяющей точно оценить трудоёмкость проекта. Поэтому используется ряд подходов и методов, адаптированных к конкретным типам проектов внутри отдельных отраслей [7]. Для эффективного применения ММО с учётом разнообразия НД требуется структурирование и систематизация ММО, метрик и НД в исследуемой предметной области (ПрО).
Целью данного исследования является разработка онтологии, позволяющей обеспечить интеграцию информации о применения ММО в УП для прогнозирования трудозатрат и сроков выполнения проектов.
1 Проектирование онтологии
Онтология является формой целостного представления системы знаний конкретной ПрО с помощью построения иерархии понятий (классов) и структуры отношений между ними [8]. В данной статье представлена онтология использования ММО для прогнозирования трудозатрат проектов при УП, как инструмент для структурирования и классификации данных [9].
В исследовании используется редактор Protégé , с помощью которого разрабатывается онтология. Запись семантических моделей осуществляется на языках RDF/RDFS и OWL . RDF/RDFS позволяют записывать простейшие факты об объектах, классах и свойствах. RDF предоставляет средства для записи триплетов: субъект–предикат–объект. OWL -онтология может включать описания классов, свойств и их экземпляров и определяет, как получать логические следствия, которые не присутствуют непосредственно в онтологии, но могут быть выведены из существующих с использованием семантики [10].
При построении онтологии выполняется следующая последовательность действий.
-
1) определение классов ( Classes ): типов объектов, их характеристик, комплексов понятий c их участием. В состав онтологии включены следующие классы: ММО ( Method_ML ), метрика ММО ( Metric_ML ), эксперимент ( Experiment ). Фундаментальным таксономическим конструктором для классов является отношение «быть подклассом» ( rdfs : subClassOf ), описывающее связь частного класса с более общим [11]. В разработанной онтологии классы Experiment , Method_ML и Metric _ ML являются подклассами суперкласса owl:Thing (см. рисунок 1).
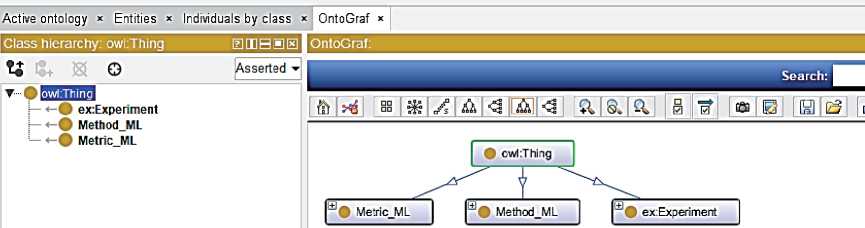
Рисунок 1– Представление иерархии классов в редакторе Protégé
2) определение отношений ( Object properties ) (см. рисунок 2). Отношения определяют семантические связи между экземплярами (индивидами) различных классов. При связи двух сущностей через Object properties одно из них является объектом, а другое субъектом. Например, класс ММО имеет связь с классом метрика ММО, в онтологии – это отношение Has_metric , в данной группе класс ММО определяется объектом, а класс метрика
ММО– субъектом с помощью описания отношения в секциях Domains и Ranges. Отношение означает, что лю бой метод имеет как минимум одну метрику. Отношения, имеющиеся в онтологии, представлены в таблице 1.
3) формирование схемы онтологии как связанного комплекса компонентов. Схема определяется структурой подчинения классов и отношениями между классами.
-
4) дополнение онтологии экземплярами классов ( Individuals ), являющихся основными нижнеуровневыми компонентами онтологии (см. рисунок 3), а также данными, имеющими физический смысл.
Annotation properties Datatypes = ■ Has_metric — Classes Object properties Data properties Description: Has_metric t ^ ^ 0 Asserted » ▼ • м о wl lopQbjectPro p e rty ; ......■ Has_metric_value Equivalent To 0 SubProperty Of Q Inverse Of 0 Domains (intersection) 0 OMethod_ML Ranges (intersection) 0 О Experiment
Рисунок 2– Определение Object properties в редакторе Protégé на примере Has_metric
Таблица 1– Связь классов в онтологии через Object properties
|
Отношения в онтологии |
Описание отношения |
Классы, участвующие в отношении |
|
Has_metric |
Связь указывает на наличие эксперимента со значением метрики у метода, причём экспериментов может быть несколько у метода |
Method_ML, Experiment |
|
Has_metric_value |
Связь указывает на тип метрики в эксперименте со значением этой метрики, причём в нескольких экспериментах может быть использован один и тот же тип метрики |
Experiment, Metric_ML |
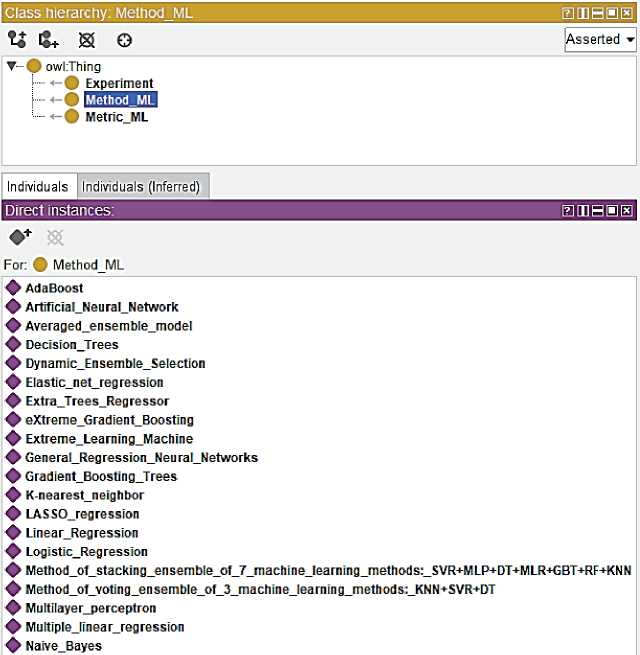
Рисунок 3– Individuals класса Method_ML в редакторе Protégé
Описание ПрО представлено на рисунке 5 в виде графа.
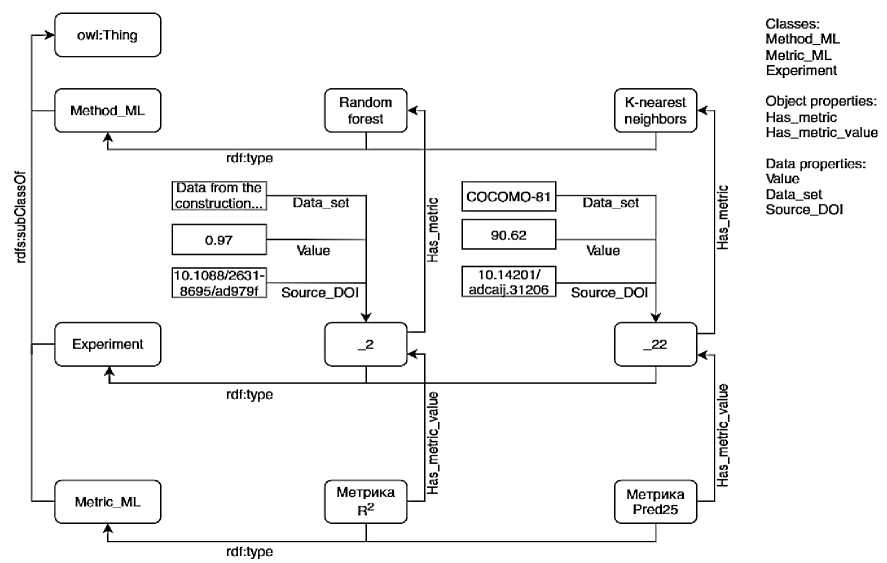
Рисунок 5– Фрагмент графа, описывающего классы, экземпляры и их отношения в предметной области
Связи объекта и субъекта обозначены линией с направлением стрелки в сторону объекта. Линией с направлением стрелки обозначены отношения между индивидами, на которой направление стрелки обозначает, какой индивид является объектом, а какой– субъектом.
2 Наполнение онтологии
Для сбора применяемых ММО в УП при прогнозировании трудозатрат и сроков выполнения проектов были проанализированы публикации за период с 2017 по 2025 год.
В [12] для оценки стоимости и продолжительности строительства применён алгоритм оптимизации роя частиц. Для построения модели использована серия из 60 проектов, осуществленных в период с 2008 по 2016 года. Основными метриками в данном исследовании были корень из среднеквадратичной ошибки ( RMSE ) и коэффициент детерминации ( R 2 ).
В [13] ММО применены для прогнозирования продолжительности строительства. При оценке ММО использовались RMSE , R 2 и средняя абсолютная погрешность ( MAE ). Например, модель случайного леса ( Random Forest, RF) достигла значений RMSE в 74 дня и R 2 0.97.
В [7] рассматривался потенциал ММО для оценки временных задержек в проектах морского строительства. Использованы среднеквадратичная ошибка ( MSE ), MAE, RMSE , индекс разброса ( SCI ) и коэффициент корреляции ( R ). НД включал 30 проектов из государственных и частных секторов ряда стран. Искусственная нейронная сеть общей регрессии показала высокую прогностическую эффективность по сравнению с другими моделями.
В [14] исследование проведено на примере данных о строительных работах в порту. Среди использованных моделей наилучшие результаты в прогнозировании сроков выполнения проектов показала модель Silverkite .
В [15] использованы четыре различных ММО. В НД было 722 вектора. Сравнение результатов прогнозных моделей показало, что искусственная нейронная сеть и градиентный бустинг деревьев ( Gradient Tree Boost, GBT ) дали лучшие результаты.
В [16] предложена модель множественной линейной регрессии для прогнозирования продолжительности строительства офисных зданий.
В [17] использованы общедоступные НД: Albretch, Desharnais, COCOMO81, NASA, Kemerer, China и Kitchenham . Эффективность методов измерялась с помощью показателей: средняя величина относительной погрешности ( MMRE ), прогнозы, которые находятся в пределах 0.25 от фактического целевого значения PRED (0.25) и R 2. Для НД Albretch, NASA лучшая модель– гребневая регрессия, для НД Desharnais, COCOMO81, China, Kitchenham – метод деревьев принятия решений, для НД Kemerer – многослойный персептрон.
В [18] предложена усовершенствованная модель ансамбля с многоуровневой структурой Stacked Ensemble . Использованы НД COCOMO81 , содержащий данные по 63 программным проектам, методы RF и GBT для отбора признаков. Для прогнозирования трудозатрат разработки программных продуктов рассматривали различные ММО. Модель Stacked Ensemble показала высокие значения точности прогнозирования PRED (0.25).
В [19] приведено сравнение трёх моделей нечёткой логики для прогнозирования затрат на разработку программного обеспечения: Mamdani, Sugeno с постоянным выходом и Sugeno с линейным выходом. Использованы данные промышленных проектов из НД ISBSG с 5000 проектами. Эти модели нечёткой логики были сравнены с моделью множественной линейной регрессии и искусственной нейронной сетью с прямой передачей.
В [20] оценены различные модели штабелирования. Для оценки использованы НД Albrecht, China, Desharnais, Kemerer, Kitchenham, Maxwell и COCOMO81 . Лучшие результаты были получены на модели штабелирования с использованием RF .
В [21] выполнено сравнение модели экстремальной обучающей машины ( ELM ) с регрессионными моделями: линейная регрессия, многослойный персептрон, k -ближайших соседей, метод опорных векторов. ELM показал наилучшие результаты.
В [22] сравнивали восемь алгоритмов ММО на трёх НД: SCRAIM, JIRA, Project Control .
В [23] выполнена оценка трудозатрат для двух НД: Finnish и Maxwell . Первый этап состоял в нормализации данных, на втором этапе предложена улучшенная версия статического отбора ансамбля, основанная на генетическом алгоритме, на третьем этапе применён динамический отбор ансамбля. Использованы метрики: симметричная средняя абсолютная процентная ошибка, средняя относительная ошибка, средняя абсолютная шкалированная ошибка, коэффициент Нэша-Сатклиффа, R 2 .
В [24] для анализа использования ММО для улучшения оценки производительности программного обеспечения использованы НД ISBSG, NASA93, COCOMO, Maxwell и Desharnais . Для НД с применением метода отбора признаков по коэффициентам корреляции линейная регрессия позволила получить R 2=0.77 для НД ISBSG и 1.0 для НД NASA93, COCOMO, Maxwell и Desharnais . Метод RF для НД NASA93 и Desharnais показал R 2 равный 0.99.
В [25] для создания модели прогнозирования затрат применены различные ММО и метрика MMRE.
В [26] использован НД из семи признаков, состоявший из 2000 выборок данных, которые подавались в режиме реального времени. Результаты исследования показали, что метод дерева принятия решений даёт более точные результаты.
В [27] проанализированы восемь ММО на следующих НД: Albrecht, COCOMO81, Desharnais, China, Finnish, Maxwell, Miyazaki, NASA18, NASA93, Telecom, Kitchenham и Kemerer . Выявлено, что методы RF и k -ближайших соседей превзошли остальные.
В [28] для оценки трудозатрат использованы НД Albrecht, China, Desharnais, Maxwell . Алгоритм RF обеспечил лучшие результаты по метрикам MAE, MSE, RMSE и R 2.
В [29] разработана модель штабелирования, основанная на поправочных коэффициентах оптимизации, путём интеграции семи статистических методов и ММО. Точность оценки методов оценивалась с использованием статистических тестов и показателей эффективности на основе четырёх НД, с метриками SSE, MAE, RMSE, MBRE, MIBRE, MdMRE и PRED (0,25). Ансамблевая модель показала лучшие результаты.
В [6] выполнено усреднение по совокупности трёх наиболее эффективных ММО, а в [5] описана оптимизированная модель RF путём изменения значений её ключевых параметров.
На основе проведённого обзора ММО, НД и метрик, отбора методов и данных с экспериментальными результатами, которые могут быть полезными в практических целях, наполнена онтология в Protege. Общая графовая схема онтологии представлена на рисунке 6, а её фрагмент – на рисунке 7. На рисунках каждый индивид класса Experiment обозначен с использованием сквозной нумерации (например, «_1», «_2», «_11»), названия методов соответствуют их общераспространённым названиям (например, «Random_forest», «Decision_trees»), в названиях метрик– общераспространённые обозначения. Фиолетовые сплошные линии со стрелками на схеме указывают на связь индивида с классом (стрелка по направлению к индивиду, например, Method_ML и Random_forest, Metric_ML и Pred25). Прерывистые оранжевые линии на схеме указывают на отношения между классами, стрелка указывает направление от субъекта к объекту, на схеме– это связи между Method_ML и Experiment, а также Experiment и Metric_ML. Синяя линия со стрелкой на схеме– это связь классов с суперклассом owl:Thing, который является родительским классом по отношению ко всем классам. Прерывистые серые и оранжевые линии на схеме указывают на связи между индивидами различных классов, заданные через отношения между классами. Например, см. рисунок 7, оранжевая линия между индивидом _64 класса Experiment и индивидом Random_forest класса Meth- od_ML отражает отношение Has_metric. Это интерпретируется как метод RF использован в эксперименте _64. Серая линия между индивидом _64 класса Experiment и индивидом R2 класса Metric_ML показывает отношение Has_metric_value, что интерпретируется как: в эксперименте _64 для оценки применена метрика R2; при этом эксперимент _64 в своих свойствах содержит значение метрики R2, ссылку на исследование и наименование НД. Направление стрелки указывает какая из сущностей является объектом, а какая субъектом.
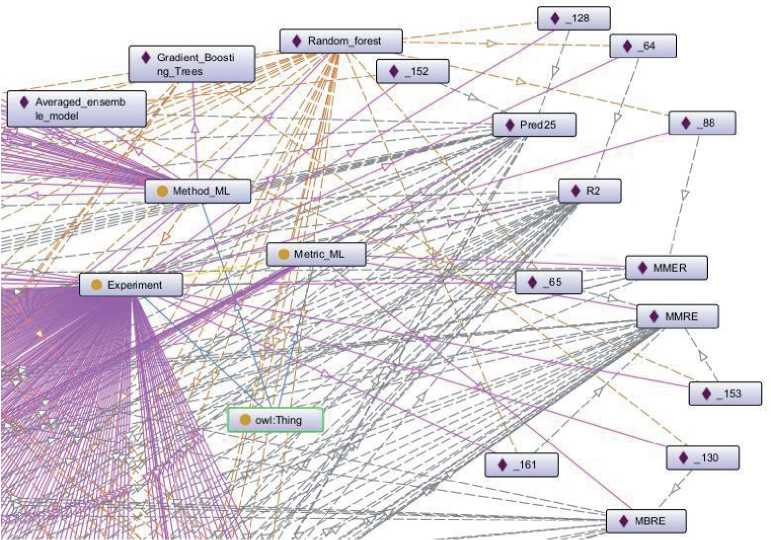
Рисунок 7 Фрагмент графовой схемы онтологии в Prot g
ё ё
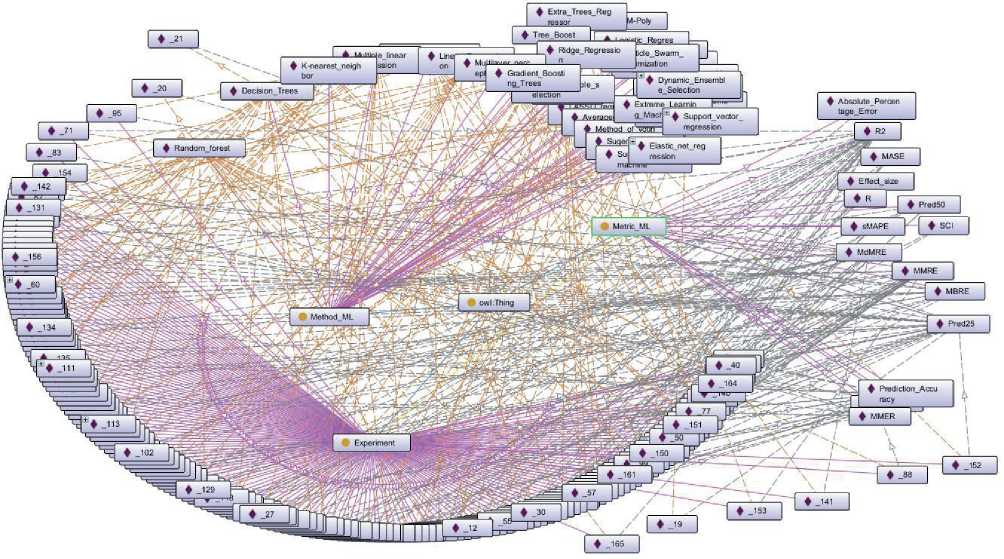
Рисунок 6 Общая графовая схема онтологии в Prot g
ё ё
Для возможности применения онтологии файл выложен в репозиторий githab:
3 Использование онтологии
В данной онтологии можно с помощью SPARQL -запроса найти интересующую информацию, например, в виде следующих запросов.
Какие методы, с какими метриками и их значениями, НД и ссылками на исследования представлены в онтологии? Пример запроса приведён на рисунке 8. В выводе запроса в первом столбце выведены все методы (на рисунке показана только видимая часть), во втором столбце– эксперименты. В других столбцах в соответствии с запросом, приведённом в верхней части рисунка, указаны все наименования столбцов, стоящие в запросе после ключевого слова WHERE : experiment, data_set, metric, value_str, reference .
Какой НД использован, какие метрики применялись, какие значения были получены со ссылкой на исследования? Пример такого запроса представлен на рисунке 9. Для получения информации по определённому методу в запросе добавляется ключевое слово FILTER , после которого указывается нужный для вывода метод (на рисунке 9 сделан фильтр по методу RF ).
Найти информацию с выводом всех экспериментов, в которых использована определённая метрика оценки результата работы ММО, и её значение находилось в заданном диапазоне. Пример запроса, где в качестве метрики оценки результата работы ММО использован R 2 со значением больше 0.90, с выводом используемого ММО, НД и ссылки на исследование, представлен на рисунке 10. Для получения данной информации с конкретной метрикой в запросе дважды указывается ключевое слово FILTER . После первого ключевого слова FILTER указывается необходимая для вывода метрика, после второго– диапазон величины метрики.
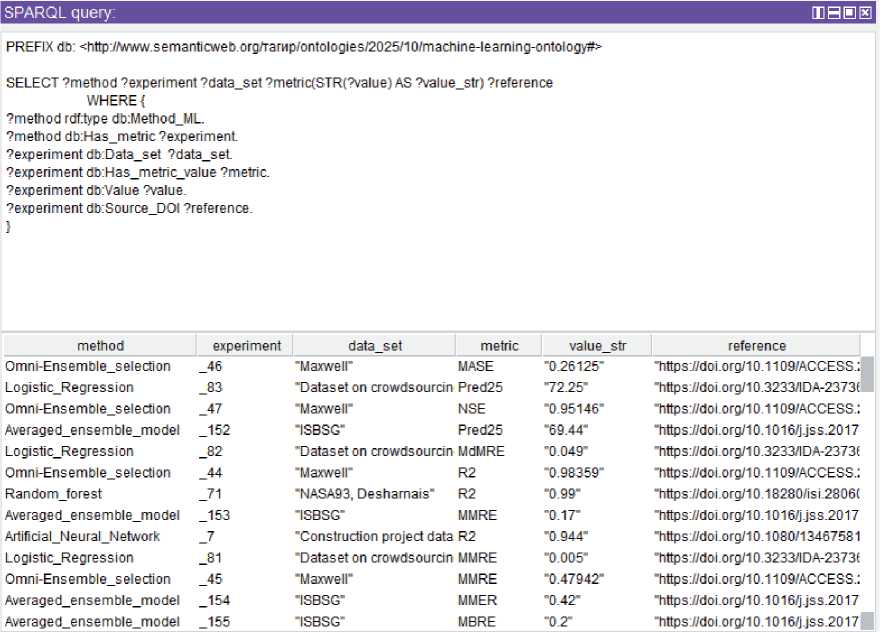
Рисунок 8– SPARQL -запрос в Protégé с выводом методов и экспериментов
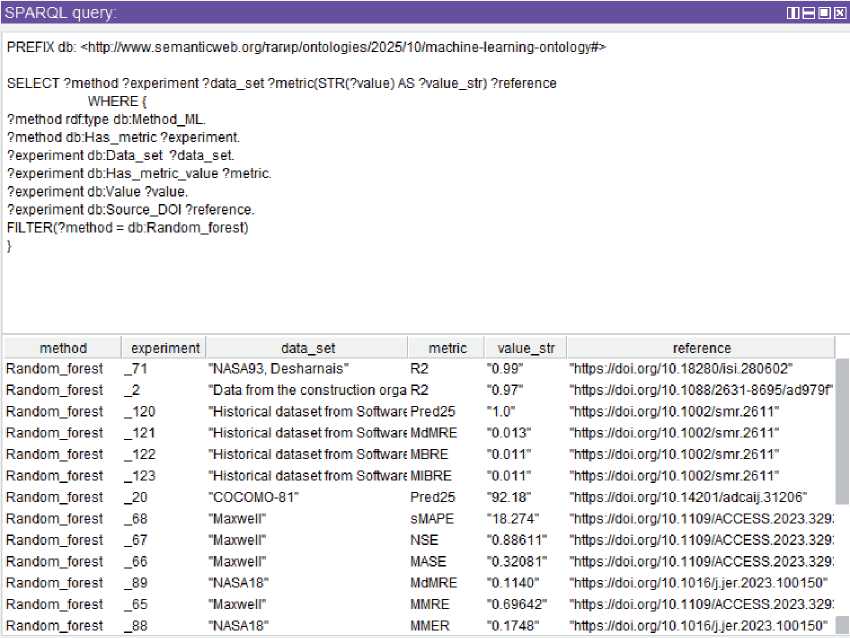
Рисунок 9– SPARQL -запрос в Protégé с выводом экспериментов при применении метода Random_forest
SPARQL query:
IBBE
PREFIX db:
SELECT ’method ?experiment ?data_set ?metric(STR(?value) AS ’value_str) ’reference
WHERE{
’method rdttype db:Method_ML.
’method db:Has_metric ’experiment
’experiment dbDataset ’data set.
’experiment db:Has_metric_value ’metric.
’experiment db:Value ?value.
FILTER(?metric = db:R2)
FILTER(?value > 0 9)
}
method | experiment ] data_set __| metric value_str reference Gradient_Boosting_Trees _8 'Construction project da R2 "0 935' "https://doiorg/10 1080/13467581 2023 Random_forest _71 'NASA93, Desharnais' R2 "0 99" '' Omni-Ensemble_selection _44 "Maxwell" R2 "0.98359' " 3 Linear_Regression _102 "NASA18" R2 "0.9972" " Extra_Trees_Regressor _41 "Project Control" R2 "0.96" " 3 Stacking_ensemble_model__31 "China" R2 "0.984" " eXtreme_Gradient_Boosting _43 "ProjectControl" R2 "0.96" " Particle_Swarm_Optimizatior_1 "Iraqi government consb R2 "0.9940" "' Linear_Regression _69 "NASA93, Desharnais* R2 "1.00" "" eXtreme_Gradient_Boosting _70 "NASA93, Desharnais" R2 "0.99" "" Dynamic_Ensemble_Selecti<_59 "Maxwell" R2 "0 9522" " 3 Random_forest _37 "Project Control" R2 "0 96" " 3 Support_vector_regression _9 "Construction project da R2 "0 931" "
Рисунок 10– SPARQL-запрос в Protégé с выводом экспериментов, в которых в качестве метрики оценки результата работы метода машинного обучения использован R2 > 0.90
Заключение
Для описания ПрО «Прогнозирование трудозатрат и сроков выполнения задач при УП» построена онтология, при разработке которой выполнен анализ и систематизированы различные методы прогнозирования. Разработанная онтология является основой для структурирования исследований, проводимых в области применения ММО, извлечения необходимых пользователям данных и их контекстуализации. Применение результатов исследования может позволить упростить процесс поиска необходимых методов для их использования при прогнозировании трудозатрат и сроков выполнения проектов на основе новых или общедоступных НД.
Разработанная онтология имеет ограничения: не все существующие исследования занесены в базу знаний; не учтены параметры НД, такие как размер данных, количество признаков, форматы признаков (категориальные и числовые); ограниченное количество метрик.
