Определение здоровых и больных областей листьев растений при помощи нейронных сетей

Автор: Смирнов А.В., Тищенко И.П.
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Искусственный интеллект и машинное обучение
Статья в выпуске: 3 (66) т.16, 2025 года.
Бесплатный доступ
В настоящей статье представлено исследование, направленное на разработку нейросетевого метода обнаружения здоровых и больных областей листьев растений по их изображениям с вычислением соотношения их площадей. В качестве нейросетевой модели использовалась базовая сеть архитектуры FPN с энкодером в виде архитектуры ResNet-34. Для обучения ИНС в качестве меток использовались бинарные маски целевых областей листьев растений, которые были получены программным путём без ручной разметки. Благодаря этому удалось достичь разумного компромисса между ресурсами, необходимыми для создания масок, и их точностью. При обучении нейросетевой модели была достигнута точность в 96.5% и 78.9% по метрике F1 для определения здоровых и больных областей соответственно. Далее был произведён инференс модели, в результате которого был рассчитан индекс «здоровья» для каждого из исследуемых изображений листьев. В контексте решаемых задач, индекс «здоровья» представляет собой разность между процентами долями здоровой и больной областей, который может быть использован при оценке тяжести заболевания, а также при мониторинге динамики развития болезни как индикатор эффективности используемых препаратов или методов ухода. Научная новизна представленного исследования заключается в создании метода автоматического определения соотношения площадей здоровых и больных участков листьев, который сочетает современные технологии компьютерного зрения, машинного обучения и практическую применимость для агрономии и растениеводства.
Нейросетевой анализ, индекс «здоровья», здоровая область листа, больная область листа, модель
Короткий адрес: https://sciup.org/143184623
IDR: 143184623 | УДК: 004.93'11 | DOI: 10.25209/2079-3316-2025-16-3-69-97
Identifying healthy and diseased areas of plant leaves using neural networks
This paper presents a study aimed at developing a neural network method for detecting healthy and diseased areas of plant leaves based on their images and calculating the ratio of their areas. The basic network of the FPN architecture with an encoder in the form of the ResNet-34 architecture was used as a neural network model. To train the ANN, binary masks of target areas of plant leaves were used as labels; they were obtained programmatically without manual marking. Due to this, it was possible to achieve a reasonable compromise between the resources required to create masks and their accuracy. When training the neural network model, the accuracy of 96.5% and 78.9% was achieved according to the F1 metric for determining healthy and diseased areas, respectively. Next, the model was inferred, as a result of which the "health" index was calculated for each of the studied leaf images. In the context of the problems being solved, the "health" index is the difference between the percentages of healthy and diseased areas, which can be used to assess the severity of the disease, as well as to monitor the dynamics of the disease as an indicator of the effectiveness of the drugs or care methods used. The scientific novelty of the presented study lies in the creation of a method for automatically determining the ratio of healthy and diseased leaf areas, which combines modern computer vision technologies, machine learning and practical applicability for agronomy and plant growing.
Текст научной статьи Определение здоровых и больных областей листьев растений при помощи нейронных сетей
В последние годы наблюдается тенденция к цифровизации агропромышленного комплекса, направленная на повышение производительности, снижение издержек и устойчивое управление природными ресурсами. Одной из актуальных задач современного сельского хозяйства является мониторинг состояния растений с целью своевременного выявления заболеваний и других негативных изменений, способных повлиять на урожайность. Особое внимание уделяется разработке и внедрению автоматизированных систем, способных выполнять визуальный анализ растений и оперативно выявлять признаки заболеваний.
Одним из наиболее перспективных направлений в области автоматизации ухода за растениями является использование методов искусственного интеллекта, в частности искусственных нейронных сетей (ИНС). ИНС позволяют выполнять анализ изображений и выделять сложные паттерны. Однако в контексте обработки изображений растений необходимо иметь релевантный набор обучающих данных. Так работа [1] посвящена сбору набора данных DiaMOS Plant, предназначенного специально для диагностики и мониторинга заболеваний растений. Представленный набор состоит из 3505 изображений плодов и листьев груши, пораженных четырьмя видами заболеваний. Хотя DiaMOS Plant предоставляет богатый источник данных, имеются и определенные ограничения. Во-первых, набор данных ограничен теми регионами, где проводились съемки, что может повлиять на универсальность модели. Во-вторых, некоторое число изображений может содержать артефакты или шумы, влияющие на качество результата.
В другой работе [2] таже описывается формирование крупного набора данных Plant Disease Dataset (PDD). Набор PDD содержит 220592 изображения в 271 категории, каждая из которых отвечает за отдельный вид заболевания. Помимо обучающего набора данных, авторы также предлагают свой подход к реализации системы распознавания болезней растений, который основан на трёх принципах: Cluster-Based Region Reweighting, Training With Loss Reweighting и Weighted Feature Integration. Cluster-Based Region Reweighting позволяет обрабатывать небольшие участки изображений с очагами заболевания растения не пропуская их. Training With Loss Reweighting — усиливает влияние фрагментов изображения с болезнями, а Weighted Feature Integration служит для комплексного представления признаков для распознавания. В целом, авторам удалось улучшить точность распознавания болезней примерно на 5% по метрике Top-1 URL .
Исследования в работах [3] , [4] посвящены обзору существующих методов диагностики заболеваний растений с использованием технологий глубокого обучения (Deep Learning URL) . Большое внимание уделяется методам, основанным на анализе изображений, в частности рассматривается применение свёрточных нейронных сетей (CNN) [5] в качестве классификатора изображений, рекуррентных нейронных сетей (RNN) [6] для анализа временных рядов и изменения состояния растения со временем, и генеративно-состязательных сетей (GANs) [7] для создания искусственных образцов здоровых и больных растений, которыми можно расширить обучающий набор данных. Также проанализировано влияние трансферного обучения (Transfer Learning) [8] на итоговую точность распознавания заболеваний. Рассматриваются конкретные архитектуры нейронных сетей такие как U-Net [9] и Mask R-CNN [10] в контексте анализа изображений растений. В итоге, авторы приводят описание проблем использования глубокого обучения для анализа заболеваний растений и методов их решения.
В статье [11] авторы предлагают метод диагностики заболеваний растений на основе анализа цвета и текстурных признаков, извлекаемых из изображений листьев. Данный метод состоит из нескольких последовательных шагов, включая предварительную обработку изображений, сегментацию заражённых областей листьев и расчёт признаков на основе матрицы совпадений уровня серого (GLCM) [12] . В качестве классификатора использовались различные алгоритмы такие, как метод опорных векторов (SVM URL ) и искусственные нейронные сети (ИНС). В результате авторам удалось добиться точности классификации больных и здоровых растений в 91.40%, и точности определения вида заболевания в 82.47%.
Статья [13] предлагает легковесную нейросетевую архитектуру на основе механизмов свёрточных нейронных сетей и модели SSD URL для обнаружения и идентификация заболеваний листьев растений в режиме реального времени. Основной особенностью представленной архитектуры является то, что она способна работать на встраиваемом оборудовании таком, как Nvidia Jetson TX1 URL , с точностью классификации болезней составляет около 96%.
Следует отметить, что часть исследований направленны на идентификацию и анализ изображений отдельных групп или видов растений. Например, в работе [14] проводиться нейросетевая классификация лекарственных растений. В качестве классификатора авторы используют сеть VGG-19 [15]. Эксперимент был проведен с помощью набора данных Flavia U»L , который содержит 1907 изображения в 32 классах.
Другая работа [16] посвящена определению болезней на изображениях листьев яблони. Авторы предлагают собственную архитектуру свёрточной нейронной сети, состоящей из комбинации слоёв свёртки, пулинга и полносвязных слоёв. Для обучения авторы используют набор данных PlantVillage URL . В результате предложенная архитектура обеспечивает точность в 98% при классификации болезней яблони.
В статьях [17] , [18] рассматривается применение ИНС для распознавания болезней продовольственных растений, таких как томаты и томаты черри. Обсуждается выбор архитектуры сети и обучающего набора данных. Всего в представленных исследованиях были задействованы модели AlexNet [19] , SqueezeNet [20] , Faster R-CNN [21] и Mask R-CNN. Итоговая достигнутая точность составила 91.67% и 93.76% соответственно.
В последнее время стали появляется гибридные алгоритмы и отдельные фреймворки URL для классификации болезней растений. Для примера, в работе [22] предложена гибридная модель, включающая алгоритм опыления цветка (FPA) [23] и метод опорных векторов (SVM URL) , а также классификатор на базе свёрточной нейронной сети. Обучающий набор данных состоял из изображений листьев яблок, винограда и томатов, характерные признаки которых извлекались с помощью двумерного дискретного вейвлет-преобразования (2D-DWT URL) . Разработанная гибридная модель была встроена в комплект разработчика Nvidia Jetson Nano URL и протестирована с использованием БПЛА для классификации болезней растений в реальном времени. Полученные экспериментальные результаты показывают, что предложенная модель классифицирует указанные заболевания листьев растений с высокой точностью — более 90%.
Следующая статья [24] представляет фреймворк Agriculture Detection (AgriDet) для обнаружения болезней растений по изображениям. AgriDet включает в себя нейронную сеть Inception-Visual Geometry Group Network (INC-VGGN) [25] и глубинные сети Кохонена URL . Здесь предварительно обученная модель INC-VGGN представляет собой глубокую свёрточную нейронную сеть для прогнозирования заболеваний растений. Чтобы преодолеть проблему переобучения, вводится слой исключения, а глубокое обучение выполняется с использованием обучающего слоя Кохонена. В результате достигается лучшая точность, в сравнении с другими моделями.
Исходя из выполненного обзора схожих по тематике работ, можно сделать вывод о том, что решения по автоматизации определения заболеваний растений остаются востребованными. Современные технологии позволяют создавать программные средства, обеспечивающие визуальный анализ состояния растений с высокой точностью и минимальным участием человека. Это особенно важно для раннего выявления заболеваний, проявляющихся в изменениях формы, структуры и окраски листовых пластин. Традиционные методы, основанные на ручной диагностике, характеризуются высокой трудоёмкостью, субъективностью оценок и ограниченными возможностями масштабирования.
В настоящей статье рассматривается определение процентного соотношения здоровых и больных областей листьев растения. Несмотря на то, что в большинстве случаев достаточно зафиксировать сам факт заболевания растения для принятия каких-либо действий, определение процентного соотношения здоровых и больных областей может использоваться при оценке тяжести заболевания, а также при мониторинге динамики развития болезни, в качестве индикатора эффективности используемых препаратов или методов ухода.
Научная новизна представленного исследования заключается в разработке метода автоматического определения соотношения площадей здоровых и больных участков листьев растений, основанного на использовании современных технологий компьютерного зрения, машинного обучения, и имеющего практическую применимость для агрономии и растениеводства.
1. Цель и задачи исследования
Целью исследования, представленного в настоящей статье, является разработка и тестирование метода обнаружения здоровых и больных областей листовых пластин (далее листьев) растений путём анализа их изображений с использованием технологий ИНС. Определение отношения площадей здоровых и больных областей листа растения поможет установить степень его заболевания, а также позволит выявлять патологии на ранних стадиях развития и контролировать динамику состояния растения.
Среди задач выполненного исследования можно выделить следующие:
• Выбор и подготовка обучающего набора данных.
• Выбор, обучение и инференс модели нейронной сети для определения здоровых и больных областей листьев растений.
• Визуализация и анализ результатов. Подсчёт индекса «здоровья» листа — отношения площади его здоровой области к больной.
2. Подготовка набора данных
2.1. Описание обучающего набора данных
Достигнутые результаты могут быть использованы в качестве инструмента «обратной связи» с растением для автоматизированных систем ухода с визуальным контролем растительности. Будущие исследования будут направлены на доработку разработанного метода, заключающиеся в подборе оптимальной нейросетевой архитектуры и добавлении функционала распознавания болезней растений.
В качестве обучающего набора данных использовался датасет PlantVillage, содержащий в общей сложности 54305 изображений в 38 классах. Представленный набор данных содержит изображения листьев различных видов растений таких как: Яблоня (Apple), Вишня (Cherry), Черника (Blueberry), Виноград (Grape) и др. Среди заболеваний растений представлены такие как:
-
• парша (scab);
-
• гниль (rot);
-
• ржавчина (rust);
-
• мучнистая роса (powdery mildew);
-
• пятнистость листьев (spot, leaf blight);
-
• ожог листьев (leaf scorch);
-
• бактериальные пятна (bacterial spot);
-
• чёрная корь (black measles);
-
• вирус курчавости листьев (leaf curl virus).
В процессе поиска обучающего набора данных, были рассмотрены и другие датасеты, например, PDD271 URL , Crop Pest and Disease Detection URL и FieldPlant URL . Основными критериями отбора были следующие показатели:
-
• Наличие разнообразных классов заболеваний растений, а также изображений со здоровыми растениями.
-
• Единый формат изображений растений/листьев растений – единое разрешение у всех изображений и одинаковый метод съёмки листьев.
-
• Возможность загрузить полную версию набора данных, а те только примеры.
-
2.2. Формирование выборок и создание бинарных масок
Используемый набор PlantVillage удовлетворял всем вышеизложенным критериям. Данный набор состоит из изображений листьев растений с разрешением 256x256 пикселей. Съёмка листьев выполнялась на специальной подложке, цвет которой отличен от цвета листа растения. На рисунке 1 показан пример изображений из данного набора.

Рисунок 1. Пример изображений набора PlantVillage
Существует расширенная версия PlantVillage-Dataset URL набора данных PlantVillage. Данная версия помимо оригинальных изображений листьев растений также содержит те же изображения, но без фона (фон заменён на чёрный цвет), которые использовались в настоящем исследовании для подготовки обучающих данных. На рисунке 2 показан пример изображений листьев без фона.

фона
Так как для решения поставленных задач нет необходимости в определении конкретного заболевания растения, используемый набор данных был разделён на две выборки «здоровую» и «больную». В «здоровую» выборку вошли все изображения, классы которых имели пометку «healthy». В «больную» выборку вошли изображения во всех остальных классах. Таким образом, удалось сгруппировать изображения здоровых и больных листьев, тем самым обобщая их по цвету и текстуре. Объединение всех изображений в «здоровую» и «больную» выборки было сделано для того, чтобы полученное решение обладало большей инвариантностью и не зависело от конкретного растения или заболевания.
Обычно обучение ИНС происходит с использованием промаркированных входных данных, то есть таких данных, которые помимо самих изображений содержат файлы с описанием классов (аннотационные файлы) в формате txt или csv. В процессе обучения происходит сравнение предсказанного класса с целевым, описанном в аннотационном файле. Затем результат этого сравнения передаётся в архитектуру ИНС для выполнения коррекции весовых коэффициентов.
Набор данных PlantVillage уже содержит разделение изображений по классам, однако, в контексте решаемых задач требуется промаркировать определённые области на изображениях. Для этого используются так называемые бинарные маски, где белыми пикселями маркируются интересуемые области изображения. Соответственно для «здоровой» выборки интересуемыми областями были сами листья растения, а для «больной» — области, поражённые заболеванием, то есть очаги заболеваний. Для создания бинарных масок использовались изображения без фона, доступные в расширенной версии набора данных, что позволило упросить алгоритм создания масок и потенциально увеличить их точность, благодаря отсутствию необходимости в удалении фона.
-
2.3. Алгоритм создания бинарных масок для «здоровой» выборки
Считается, что наиболее точные бинарные маски можно получить методом ручной разметки, при которой эксперт-разметчик непосредственно выполняет разметку данных. Тем не менее, оценивая ресурсозатраты, необходимые на ручную разметку, а также учитывая специфику входных данных, было принято решение реализовать программное формирование бинарных масок.
Алгоритм создания масок для «здоровой» выборки состоял из следующих шагов:
-
(1 ) Перевод исходных изображений в цветовое пространство CIE Lab"L , определение диапазона значений для каналов L, а и b, и поканальная бинаризация.
-
(2) Контурный анализ полученного на предыдущем шаге изображения с поиском и закрашиванием описывающего контура.
-
2.4. Алгоритм создания бинарных масок для «больной» выборки
Цветовое пространство CIE Lab имеет ряд преимуществ таких как: независимость от устройств, более широкий цветовой охват и точное описание цвета, благодаря чему можно подобрать диапазон значений каналов для адекватного определения зелёного цвета и его оттенков, присутствующих на большинстве изображений здоровых листьев. Если цвет листа лежит в этом диапазоне, то он окрашивается в белый.
К сожалению, подобрать оптимальный диапазон значений каналов L, a и b, не представляется возможным, так как имеется вариативность в освещении листьев при съёмке, из-за которой цвет отдельных областей листа может меняться (засветка или тень). Этот факт приводит к появлению «пропусков» в бинарной маске. Чтобы убрать появившиеся «пропуски» в масках был применён контурный анализ. При контурном анализе с использованием маски, полученной на предыдущем шаге, выполняется поиск описывающего лист контура. Затем область под этим контуром окрашивается в белый цвет, тем самым формируя итоговую бинарную маску здорового листа. На рисунке 3 показан пример полученных бинарных масок.


Рисунок 3. Пример бинарных масок: левое изображение – исходное изображение, среднее – изображение после поканальной бинаризации с «пропусками», правое – итоговая бинарная маска
В итоге «здоровая» выборка содержала 13922 изображения здоровых листьев, каждому из которых соответствует своя бинарная маска. Для формирования выборки использовались оригинальные изображения, то есть те изображения, где присутствует фон.
Алгоритм формирования бинарных масок больных областей растений для соответствующей выборки частично схож с алгоритмом формирования масок здоровых областей, но имеет ряд отличий и состоит из следующих шагов:
-
(1 ) Перевод исходных изображений в цветовое пространство CIE Lab, определение диапазона значений для каналов а и b, и поканальная бинаризация. Диапазон значений каналов подбирался таким образом, чтобы фиксировался не только очаг заболевания, но и область листа, подверженная заболеванию и изменившая свой цвет.
-
(2) Применение морфологических операций «открытия» и «закрытия» со структурным элементом (ядром) эллиптической формы размера 5x5 (рисунок 4) .
-
2.5. Описание обучающих наборов данных

Рисунок 4. Демонстрация морфологических операций (слева направо): бинарная маска до применения морфологических операций; бинарная маска после операции «открытия»; бинарная маска после операции «закрытия»
Как и в случае создания масок здоровых областей растений, при генерации масок больных областей использовалось цветовое пространство CIE Lab. Однако, в данном случае, диапазон значений каналов был подобран из расчёта цвета поражённых/областей растений и очагов заболеваний. В свою очередь, применение морфологических операций помогло избавиться шума и «пропусков» в получившихся бинарных масках.
Объективно оценить «верность» полученных бинарных масок возможно только при использовании ручной разметки данных и расчёта индекса Жаккара . Ручная разметка такого объёма данных весьма трудоёмка, а из-за специфики данных (не всегда удаётся определить чёткие границы областей заболевания) требуется проводить валидацию размеченных данных по разметчикам. Очевидно, что при автоматизированном создании бинарных масок программным способом нельзя гарантировать их 100% точность. Однако, благодаря такому подходу удалось достичь компромисса между затраченными ресурсами (человеко-часы) и их достоверностью.
Таким образом, для всех изображений «больной» выборки, были сгенерированы бинарные маски с использованием алгоритма, описанного выше. Затем, в целях расширения обучающего набора данных, все оригинальные изображения были вертикально отражены, чтобы повторно пройти процедуру генерации бинарных масок. Итого «больная» выборка насчитывала 42731 изображение, каждому из которых соответствовала своя бинарная маска. Для формирования выборки использовались оригинальные изображения, то есть те изображения, где присутствует фон.
Используемые выборки данных («здоровая» и «больная») по сути являются самодостаточными наборами данных для определения здоровых и больных областей листьев соответственно. В связи с этим каждый из наборов был дополнительно разделён на обучающую, тестовую и вариационную выборки.
В таблице 1 показана статистика используемых наборов данных.
Таблица 1. Статистика для наборов данных с изображениями здоровых и больных листьев растений
|
Набор данных |
Обучающая выборка |
Тестовая выборка |
Валидационная выборка |
|
Изображения здоровых листьев растений |
11137 |
1392 |
1393 |
|
Изображения листьев растений с заболеваниями |
34184 |
4273 |
4274 |
На рисунке 5 и рисунке 6 показаны примеры изображений и масок из полученных обучающих наборов данных.
Общая логика работы с исходным набором данных была следующая:
(1) Формирование двух отдельных выборок - «здоровой» и «больной» из всех классов растений исходного набора.
(2) Создание бинарных масок для «здоровой» (п. 2.3) и «больной» (п. 2.4) выборок. Формирование отдельных наборов данных для определения здоровых и больных областей листьев растений, состоящих из промаркированных данных (полноценное RGB-изображение + маска).
(3) Формирование выборок для обучения теста и валидации из полученных на предыдущем шаге наборов данных.
3. Обучение нейронной сети
3.1. Архитектура модели

Рисунок 5. Пример изображений и бинарных масок набора

Рисунок 6. Пример изображений и бинарных масок набора данных для определения больных областей листа растения
В качестве нейронной сети была выбрана модель сегментации изображений на основе PyTorch — Segmentation Models Pytorch URL и фреймворка глубокого обучения для предварительной подготовки, настройки и развертывания моделей ИИ — PyTorch Lightning URL . Выбор данного инструментария был обусловлен тем, что библиотека Segmentation Models Pytorch является API высокого уровня и содержит 9 архитектур моделей для бинарной и многоклассовой сегментации, а также 124 энкодера. В свою очередь PyTorch Lightning предлагает широкие возможности по настройке и развёртыванию моделей нейронных сетей. Также преимуществом данных инструментов является наличие документации и поддержка сообщества.
Базовой нейронной сетью (backbone) для выбранной модели является архитектура FPN [26] , тогда как архитектура ResNet-34 [27] используется как энкодер. Структура используемой нейросетевой модели представлена на рисунке 7 .
|
Layer (type:depth-idx) |
Output Shape |
|
LeafModel |
[1, 1, 256, 256] |
|
FPN: 1-1 |
[1, 1, 256, 256] |
|
— ResNetEncoder: 2-1 |
[1, 3, 256, 256] |
|
— Conv2d: 3-1 |
[1, 64, 128, 128] |
|
— BatchNorm2d: 3-2 |
[1, 64, 128, 128] |
|
— Re LU: 3-3 |
[1, 64, 128, 128] |
|
— MaxPool2d: 3-4 |
[1, 64, 64, 64] |
|
— Sequential: 3-5 |
[1, 64, 64, 64] |
|
— Sequential: 3-6 |
[1, 128, 32, 32] |
|
— Sequential: 3-7 |
[1, 256, 16, 16] |
|
— Sequential: 3-8 |
[1, 512, 8, 8] |
|
— FPNDecoder: 2-2 |
[1, 128, 64, 64] |
|
— Conv2d: 3-9 |
[1, 256, 8, 8] |
|
— FPNBlock: 3-10 |
[1, 256, 16, 16] |
|
— FPNBlock: 3-11 |
[1, 256, 32, 32] |
|
— FPNBlock: 3-12 |
[1, 256, 64, 64] |
|
— ModuleList: 3-13 |
-- |
|
— MergeBlock: 3-14 |
[1, 128, 64, 64] |
|
— Dropout2d: 3-15 |
[1, 128, 64, 64] |
|
— SegmentationHead: 2-3 |
[1, 1, 256, 256] |
|
— Conv2d: 3-16 |
[1, 1, 64, 64] |
|
— UpsamplingBilinear2d: 3-17 |
[1, 1, 256, 256] |
|
— Activation: 3-18 |
[1, 1, 256, 256] |
Total params: 23,155,393
Trainable params: 23,155,393
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 6.86
Input size (MB): 0.79
Forward/backward pass size (MB): 105.15
Params size (MB): 92.62
Estimated Total Size (MB): 198.56
Рисунок 7. Структура используемой нейросетевой модели
-
3.2. Входные данные, обучение и тест модели
В данном случае применяется бинарная сегментация, то есть сегментация на два класса: фон и целевой объект. На вход ИНС подавались цветные, полноценные RGB-изображения с метками целевых областей (бинарными масками), то есть подавалось некоторое количество пар: изображение + маска. Количество одновременно поданных на вход пар задавалось параметром размера пакета/партии (batch_size) и составило 64 шт. Результатом работы нейросетевой модели также является бинарная маска, где чёрными пикселями обозначается фон, а белыми – целевые объекты. В зависимости от набора данных, целевым объектом является либо здоровая область листа, либо больная.
Стоит отметить, что обучение модели происходило отдельно для поиска здоровых и больных областей листовой пластины растения. В итоговом варианте применяются два набора весов для здоровых и больных областей соответственно. Решение об использовании одной модели с двумя наборами весов обусловлено тем, что так модель не будет сегментировать ничего кроме целевого класса (здоровые или больные области листа). Также упрощается сама задача сегментации, так как пространство признаков становиться меньше благодаря меньшей вариации текстур.
Обучение модели для поиска здоровых областей листьев происходило на протяжении 5 эпох, а для поиска больных – 15 эпох. Данное количество эпох обучения модели является результатом проведённых предварительных экспериментов, в процессе которых было выяснено, что дальнейшее увеличение количества эпох уже не ведёт к какому-либо значительному увеличению показателей метрик. В роли метрик точности используемой модели выступали показатели IoU URL и F1 URL . Метрики рассчитывались двумя способами:
-
• Суммирование истинно-положительных (TP), ложно-положительных (FP), ложно-отрицательных (FN) и истинно-отрицательных (TN) пикселей по всем изображениям и всем классам набора данных, а затем вычисление оценки.
-
• Вычисление оценки для каждого изображения и для каждого класса на этом изображении отдельно, затем вычисление средней оценки для каждого изображения по меткам и средней оценки изображений по набору данных.
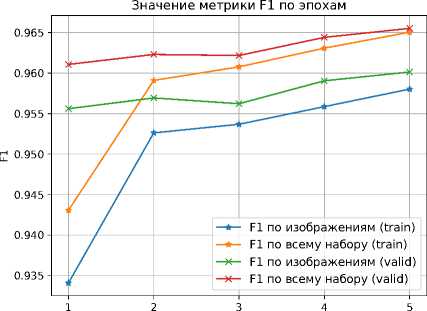
Полученные в процессе обучения графики изменения значений метрик IoU и F1 в задаче определения здоровых областей листьев растений, показаны на рисунках 8 и 9 .
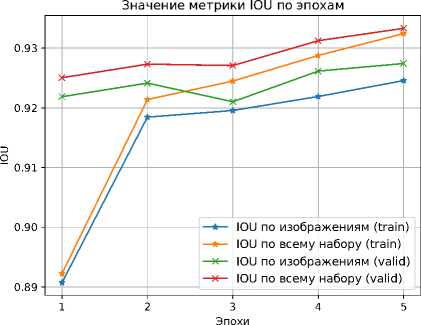
Рисунок 8. График изменения значений метрики IoU для определения здоровых областей листьев
Эпохи
Рисунок 9. График изменения значений метрики F1 для определения здоровых областей листьев
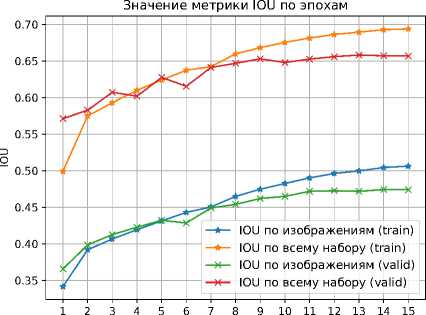
Графики тех же метрик только в задаче определения больных областей листьев растений, представлены на рисунках 10 и 11.
Эпохи
Рисунок 10. График изменения значений метрики IoU для определения больных областей листьев
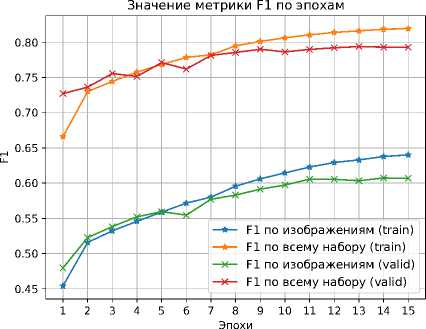
Рисунок 11. График изменения значений метрики F1 для определения больных областей листьев
По окончании обучения модели было выполнено её тестирование с использованием изображений из валидационной выборки. На рисунках 12 и 13 показаны примеры полученных и эталонных масок для здоровых и больных областей листьев соответственно.
Original image
Ground truth
Prediction

Original image
Ground truth
Prediction

Рисунок 12. Образцы бинарных масок здоровых областей листьев: Ground truth – эталонная маска из набора данных; Prediction – полученная от модели маска
Original image
Ground truth
Prediction
Original image

Ground truth
Prediction
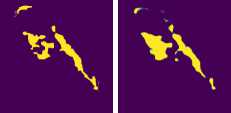
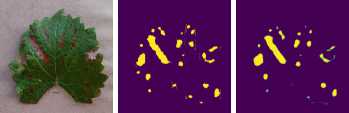
Рисунок 13. Образцы бинарных масок больных областей листьев: Ground truth – эталонная маска из набора данных; Prediction – полученная от модели маска
Итоговая точность определения здоровых областей листьев растений составила 93.2% по IoU и 96.5% по F1. Для больных областей листьев удалось достичь точности в 65.1% по IoU и 78.9% по F1.
Также были проведены эксперименты с обучением ИНС на конкретных видах растений из используемого набора данных. При обучении использовались изображения здоровых листьев растений, подготовка бинарных масок была выполнена в соответствии с п. 2.3 настоящей статьи для «здоровой» выборки. Архитектура сети и параметры обучения были идентичны тем, что использовались при обучении на «здоровой» выборке. В таблице 2 представлен результат обучения ИНС на разных видах растений.
Таблица 2. Значение метрик IoU и F1 на тестовых выборках различных растений после обучения ИНС
|
Растение |
IoU, % |
F1, % |
|
Apple |
87.8 |
93.5 |
|
Blueberry |
93.2 |
96.4 |
|
Cherry |
92.6 |
96.1 |
|
Grape |
88.8 |
94.1 |
|
Peach |
80.9 |
89.4 |
|
Pepper |
93.6 |
96.7 |
|
Potato |
86.8 |
92.9 |
|
Raspberry |
88.7 |
94.0 |
|
Soybean |
92.9 |
96.3 |
|
Strawberry |
91.6 |
95.6 |
|
Tomato |
91.7 |
95.6 |
|
Среднее |
89.8 |
94.6 |
Результаты проведённых экспериментов показали, что модель, обученная на «здоровой» выборке, превосходит по точности модели обученные на отдельных растениях в задаче определения здоровых областей листьев растений. Можно предположить, что для «больной» выборки был бы получен аналогичный результат, так как архитектура сети и параметры обучения остались неизменны.
4. Инференс модели и анализ результатов
После завершения процедур обучения и тестирования был выполнен инференс модели на тестовой выборке данных, результатом которого стали бинарные маски здоровых и больных областей листа растения. С их помощью можно рассчитать занимаемую ими площадь путём подсчёта количества принадлежащих им пикселей белого цвета. Сумма рассчитанных площадей в пикселях будет отражать общую площадь наблюдаемой листовой пластины растений. Таким образом, появляется возможность определить процентное отношение площадей, занимаемых здоровыми и больными областями относительно общей площади листа.
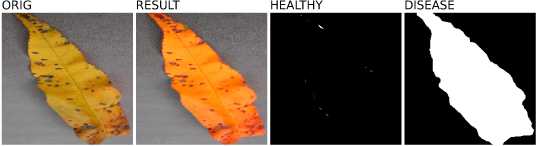
Далее определяется отношение процентных долей здоровой и больной области листа растения, которое по сути представляет собой разность между этими значениями. Для простоты восприятия полученная разность делиться на 100, чтобы в итоге диапазон значений лежал в пределах от 1.0 до -1.0. Дабы не оперировать понятием «разность между процентными долями здоровой и больной областей» было решено обозначить полученное значение как индекс «здоровья» (heal_index) листа. Значение индекса «здоровья», близкое к 1.0 (рисунок 14), характерно для практически

Соотношение здоровых и больных областей
Здоровая 100.00
Больная 0.00
0 20 40 60 80 100
Проценты
Рисунок 14. Пример здорового листа. Сверху: оригинальное изображение; сегментированное изображение; маска здоровой области; маска больной области. Снизу: столбец зелёного цвета – процентная доля здоровой области; красного цвета – процентная доля больной области полностью здоровых с визуальной точки зрения листьев растений. Противоположенное значение, близкое к -1.0 (рисунок 15) свидетельствует
heal_index: -0.907
Соотношение здоровых и больных областей
Здоровая 4.64
Больная 95.36
40 60
Проценты
Рисунок 15. Пример полностью больного листа о том, что наблюдаемый лист растения практически полностью поражён заболеванием.
Следует отметить то, что значения индекса «здоровья» меньше нуля как правило указывают на то, что площадь больной области листа растения в определённой степени преобладает над здоровой (рисунок 16) .
ORIG RESULT HEALTHY DISEASE
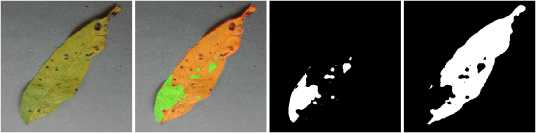
heal_index: -0.542
Соотношение здоровых и больных областей
Здоровая
Больная

Проценты
Рисунок 16. Пример больного листаи
Опытным путём было выяснено, что если значение индекса «здоровья» больше 0.9, то с визуальной точки зрения наблюдаемый лист растения можно считать относительно здоровым (рисунок 17) .
ORIG RESULT HEALTHY DISEASE

heal_index: 0.945
Со отношение здоровых и больных областей
Здоровая 97.24
Больная I 2.76
0 20 40 60 80 100
Проценты
Рисунок 17. Пример относительно здорового листа
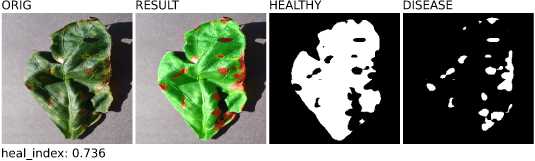
Если же значение индекса «здоровья» лежит в диапазоне от 0.9 до 0.5 (рисунок 18), то считается, что наблюдаемый лист уже имеет явные признаки заболевания, и чем ниже индекс, тем выше степень заболевания листа.
ORIG
RESULT
HEALTHY
DISEASE
heal_index: 0.88
Соотношение здоровых и больных областей
Здоровая
Больная

Проценты
Соотношение здоровых и больных областей
Здоровая
Больная

Проценты
Рисунок 18. Примеры листьев с разной степенью заболевания
Заключение
В результате проведённых исследований был получен метод нейросетевого определения здоровых и больных областей листьев растений с вычислением отношения их процентных долей — индекса «здоровья». Анализ полученных данных показал, что значение индекса «здоровья» в определённой мере отражает степень заболевания листа. Так, например, здоровые листья имеют значения индекса более 0.9. Если индекс лежит в диапазоне от 0.9 до 0.5, то это указывает на то, что лист растения имеет явные признаки заболевания и чем ниже значение индекса, тем больше степень заболевания, с визуальной точки зрения. В случаях дальнейшего уменьшения индекса, а также при его отрицательных значениях наблюдаемый лист растения уже имеет крайне высокую степень заболевания.
Благодаря использованию технологий нейронных сетей удалось сформировать собирательный образ здоровых и больных областей листьев растений в независимости от их цвета, текстуры и формы, что позволило анализировать различные виды растений и типы заболеваний.
Точность определения здоровых областей листовых платин растений, составила 96.5% по метрике F1. Относительно низкую точность в 78.9% по F1 удалось достичь при определении больных областей растений. Такая разница показателей точности объясняется различием в корректности/достоверности эталонных бинарных масок здоровых и больных областей. Для повышения достоверности бинарных масок необходимо использовать ручную разметку данных, или, по крайней мере, провести процедуру ручной корректировки масок. Однако, подход с автоматизированным формированием бинарных масок, используемый в настоящем исследовании, позволил существенно сократить время на их создание. Анализируя полученные результаты, можно сделать вывод о том, что создание бинарных масок без ручной разметки имеет место быть в задачах не требующих высоких показателей точности. Так, например, в рассматриваемой задаче по определению соотношения здоровой площади листа к больной, достаточно идентифицировать больную область листа, чтобы считать растение больным. В будущих работах планируется повысить точность определения больных областей листьев растений, а также добавить функционал определения типа заболевания.
Подводя итог, можно сказать, что в ходе выполнения исследования, представленного в настоящей статье, все постеленные задачи были успешно решены.
