Платформа для исследования аргументации в научно-популярном дискурсе

Автор: Сидорова Е.А., Ахмадеева И.Р., Загорулько Ю.А., Серый А.С., Шестаков В.К.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Инжиниринг онтологий
Статья в выпуске: 4 (38) т.10, 2020 года.
Бесплатный доступ
Рассматривается программная система, предназначенная для поддержки исследования аргументации в русскоязычных научно-популярных текстах. Эта система базируется на онтологии, построенной на современных принципах моделирования аргументации. Данная онтология содержит формальные описания типовых схем рассуждений, на основе которых выполняется аннотирование текстов, анализ представленной в них аргументации и оценка её убедительности относительно заданной аудитории. Предлагается методика аргументативной разметки текста, которая обеспечивает выделение в нем утверждений и построение на их основе графа аргументации с использованием знаний о типовых схемах рассуждений. Описывается набор веб-инструментов, обеспечивающих создание тематических корпусов текстов, визуализацию используемой онтологии аргументации, построение графа аргументации, выделение в текстах индикаторов аргументации, а также поиск различных сущностей в корпусах текстов в терминах онтологии. Аналитические инструменты представлены средствами сбора статистической информации о встречаемости типовых элементов аргументации в корпусе текстов, средствами исследования индикаторов аргументации и средствами анализа убедительности аргументации. Представлена оригинальная методика исследования аргументации в научно-популярном дискурсе, базирующаяся на онтологии аргументации и поддержанная специализированной веб-платформой.
Научно-популярный дискурс, онтология аргументации, аргументативная разметка текста, схема аргументации, индикатор аргументации, убедительность аргументации
Короткий адрес: https://sciup.org/170178870
IDR: 170178870 | УДК: 004.82:004.89:519.816 | DOI: 10.18287/2223-9537-2020-10-4-489-502
Research platform for the study of argumentation in popular science discourse
The paper discusses a software system designed to support the study of argumentation in Russian-language popular science texts. This system is based on an ontology built on modern principles of argumentation modeling. In particular, this ontology contains formal descriptions of typical reasoning schemes that are used for annotating texts, analyzing the arguments presented in them, and assessment of its persuasiveness relative to a given audience. A method of argumentative marking of a text is proposed, which provides the allocation of statements and the construction on their basis of an argumentation graph using knowledge about typical reasoning schemes. The paper also describes a set of web tools that provide the creation of thematic corpora, visualization of the argumentation ontology used, the construction of the argumentation graph, the selection of argumentation indicators in the texts, as well as the search for various entities in the text corpora in ontology terms. Analytical tools are presented by means of collecting statistical information on the occurrence of typical elements of argumentation in the body of texts, by means of researching indicators of argumentation and by means of analyzing the persuasiveness of argumentation. The novelty of the work consists in the development of an original methodology for studying argumentation in popular science discourse, based on the ontology of argumentation and supported by a specialized web platform.
Текст научной статьи Платформа для исследования аргументации в научно-популярном дискурсе
В течение двух последних десятилетий роль Интернета как основной платформы для проведения споров и дебатов, распространения идей и обмена мнениями неуклонно возрастает. Этому способствуют онлайн-площадки и многочисленные Интернет-ресурсы, предоставляющие неограниченный доступ к различным источникам информации, в частности к научным и научно-популярным статьям. Потребителям этой информации хочется разобраться, насколько обоснованы высказываемые мнения и убедительны доводы авторов статей и участников споров и дебатов. Для решения этой задачи можно было бы привлечь методы и технологии обработки естественного языка, которые уже достигли впечатляющих результатов во многих областях. Однако, на данный момент эти технологии не предоставляют надёжных инструментов для выявления семантических связей между отдельными фрагментами текста. Например, они позволяют спрогнозировать, какого мнения будут придержи- ваться люди через несколько лет, но не могут ответить на вопрос, почему люди придерживаются (или не придерживаются) такого мнения сейчас.
Обоснование мнений или тезисов составляет область теории аргументации, изучающей употребление аргументов в текстах и устной речи (дискурсе) с философской, лингвистической, когнитивной и вычислительной точек зрения. Анализ аргументации, в частности, включает преобразование неструктурированного текста в «цепочки» или графы связанных структурированных аргументов, что позволяет не только оценить отдельные высказывания, но и выявить отношения между ними, направленные на поддержку или нивелирование главного тезиса, предлагаемого автором публикации.
Автоматизация извлечения аргументации из текстов стала одним из приоритетных направлений лишь несколько лет назад [1]. Одним из основных условий развития данной области является создание корпусов текстов с аргументативной разметкой. На данный момент известны несколько аннотированных корпусов, включающих преимущественно англоязычные монологические тексты. Самым известным ресурсом с разметкой аргументации является AIFdb , бывший корпус Araucaria [2], который содержит новостные статьи, записи парламентских и политических дебатов. Созданы также ресурсы для немецкого языка: корпус Университета Дармштадта, который включает подкорпусы студенческих сочинений [3], новостных текстов и научных статей; Потсдамский корпус, содержащий небольшой набор микротекстов на заданную тему, позднее переведённых на английский язык [4]. Существуют проекты для некоторых других языков: итальянского, греческого, китайского. Для русского языка таких ресурсов, насколько нам известно, пока не создано.
В большинстве работ аргументативная разметка включает в себя сегментацию текста с выделением единиц аргументации, разметкой ролей (посылка, заключение) и отношений (поддержка / атака) без детализации структуры аргументов. Исключением являются корпуса, создаваемые с помощью системы OVA ( Online Visualisation of Argument - наследник Araucaria ) [5], где аннотация аргументативной структуры соотносится с конкретной схемой аргументации на основе теории Уолтона [6]. Исследование аргументации подразумевает её наглядное представление. Схемы аргументации формализуют определённые шаблонные конструкции, применяемые для убеждения целевой аудитории. При этом исследование статистики и контекстов использования той и иной схемы аргументации представляет больший интерес в рамках корпуса текстов, нежели в отдельно взятом тексте. Это подтверждается как быстрым развитием корпуса AIFdb [7], с которым уже объединены некоторые системы разметки аргументации [8-9], так и повышением интереса к задачам автоматического извлечения аргументации, где необходимы размеченные данные.
Для представления аргументации был разработан широкий спектр различных инструментов построения графов аргументации ( argumentation graph ). Они позволяют исследователям локализовать употребление аргументации в тексте и схематично представить аргумента-тивную структуру текста в виде графа. Большинство этих инструментов, таких как Araucaria [2], Rationale [10], OVA [8], Carneades [11] и DiGAT [12] ориентированы на английский, немецкий и другие западноевропейские языки. Кроме того, они позволяют только представлять структуру аргументации в тексте, оставляя за рамками исследование её качественных характеристик. Качество же аргументации в первую очередь определяется степенью прозрачности и убедительности аргументов, то есть обоснованностью выводов.
В данной статье представлена программная система для поддержки исследования аргументации в русскоязычных научно-популярных текстах. Эта система предоставляет средства для работы с корпусами текстов, для моделирования и извлечения аргументации из текстов, для выполнения аргументативной разметки текстов с использованием онтологического представления схем аргументации, а также для анализа используемых в текстах аргументативных стратегий и риторических приемов. Её особенностью является наличие средств моделирования и анализа убедительности аргументации. Такие средства необходимы для оценки качества аргументации, представленной в научно-популярных текстах, так как качество таких текстов, по нашему мнению, определяется не столько их литературными достоинствами, сколько качеством представленной в них аргументации.
1 Модель аргументации
Выявление в тексте типовых риторических приемов и рассуждений, убеждающих аудиторию в позиции автора, и их разметка является основой исследования аргументации, анализа её особенностей, проверки корректности и оценки убедительности относительно определённой аудитории.
Любая разметка текста опирается на модель, которая задаёт перечень сущностей, используемых при аннотировании, их типизацию, формат и интерпретацию. В работе в качестве такой модели используется расширенная версия онтологии аргументации ( AIF -онтологии) [13], базирующейся на формате AIF ( Argument Interchange Format ) [14]. Отличительной особенностью данной онтологии [15] является её ориентированность на графовое представление аргументации, наличие разветвлённой системы классов для метаописания типовых схем рассуждений и средств для моделирования и анализа убедительности аргументации.
На рисунке 1 приведён пример схемы аргументации Example_Inference и её метаописание, построенное по её онтологическому представлению. Данная схема позволяет связывать найденные в тексте утверждения — две посылки и заключение, в единую структуру. Одно и то же утверждение может входить в разные структуры, тем самым осуществляя связывание выявленных в тексте «минимальных» единиц рассуждения - аргументов в единую цепочку, а в общем случае - в граф аргументации.
DirectAdHominem_Inference Estabtehed Rulejnference Ethotic_Inference
Evidence!oHy pothesis_Inference Examplejnference . ExceptionalCase_Inference ” FalsificationOfHypothesis_Inference FearAppeal_Inference FullSlipperySlope_Inference Grad ualism_Inference Ignorance_Inference InconsistentCom mitment_Inference PopularOpinion_Inference PopularPradjce_Inference PrecedentSlipperySbpe_Inference
C as ePrope rty_Prem i se
Conclusion
TypicalObject_Premise
Найти примеры
Аргумент «Example Inference^
Тип утверждения
CaseProperty_Statement
G eneralP ro p erty_State m ent
Ту p ica IО bject_Statem ent
Описание утверждения
In this case, the individual a has property F and also property G
Generally, if х has property F then (usually, probably, typically) x also has property G a is typical of things that have F and may or may not have G

Рисунок 1 - Пример схемы аргументации Example inference и её метаописание
Несмотря на указанный богатый набор свойств онтологии аргументации, её одной недостаточно для проведения полноценного исследования аргументации, используемой в текстах.
Во-первых, необходимо обеспечить не только представление и хранение аргументатив-ной разметки текстов, но и информации об источнике аргументации. Для этого требуется создать хранилище корпусов текстов и их аннотаций, сопряжённых с онтологией.
Во-вторых, необходимы средства для поддержки жанровых и лингвистических исследований особенностей текста.
В-третьих, требуются инструменты для комплексного анализа созданных графов аргументации.
2 Инструменты создания и аннотирования корпусов текстов
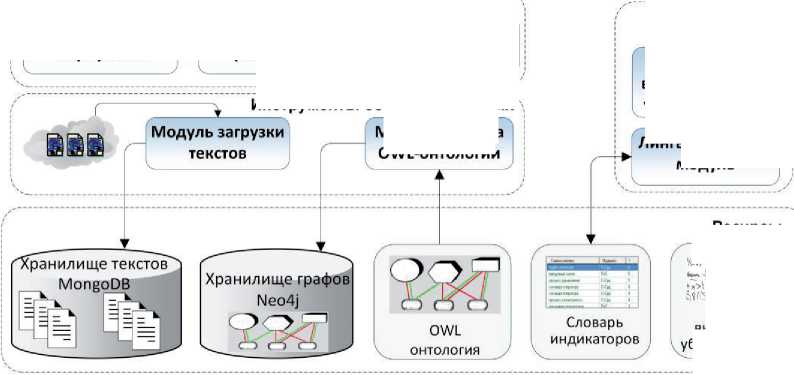
Для поддержки исследования аргументации были разработаны инструменты для создания корпусов с аргументативной разметкой и работы с ними. Инструменты интегрированы в единую веб-платформу и предоставляют всю необходимую функциональность для проведения корпусных исследований (рисунок 2).
Задачи


Пользовательские инструменты
Инструменты обработки данных
Лингвистический модуль
Аналитические инструменты
Модуль работы с корпусами
Модуль поиска по аннотациям
Модуль анализа OWL-онтологии
Модуль вычислителения убедительности
Модуль работы с разметкой
Ресурсы у,, weto- -
Модель вычисления
Рисунок 2 - Архитектура платформы для исследования аргументации
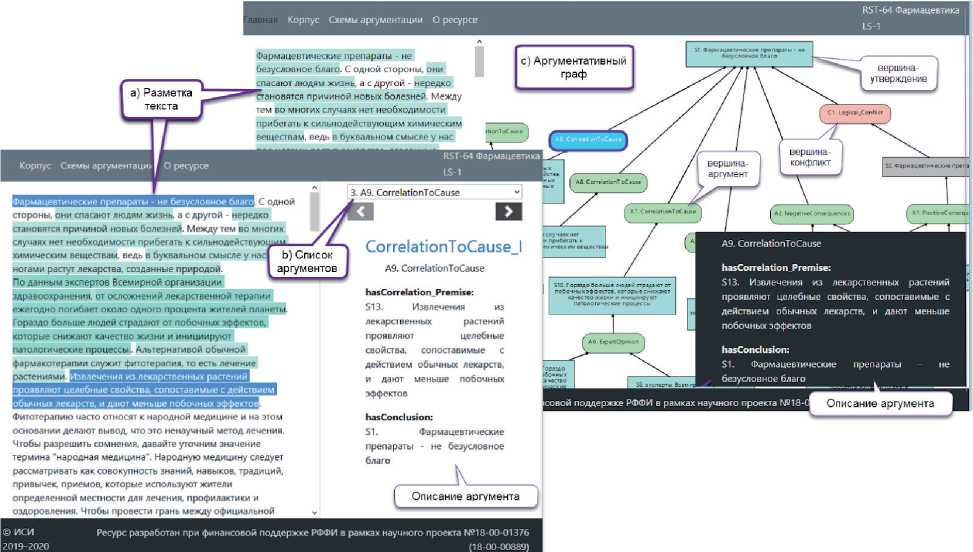
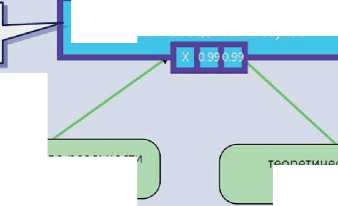
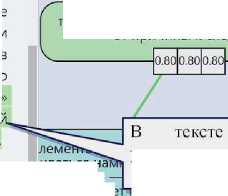
I^V/^/S ■ Платформа включает ресурсы, инструменты обработки данных, аналитические инструменты и пользовательские инструменты. Платформа поддерживает работу пользователей через веб-интерфейс, обеспечивая решение основных задач, возникающих в процессе построения и анализа аргументации. Платформа позволяет загружать тексты на ресурс, снабжать их необходимыми метаданными и формировать тематические корпусы текстов (см. рисунок 3), корпусы организуются в иерархию и также снабжаются метаданными. Основанием для объединения текстов в корпус может быть тематика, источник текста, автор текста, жанр и т.д. В рамках данной работы осуществляется сбор и аннотирование текстов научно-популярного жанра, а корпуса формируются на основе тематических журналов, использованных в качестве источников научно-популярных статей. Научно-популярный жанр в основном предназначен для предъявления широкой публике результатов научной деятельности и обоснования их состоятельности. Как правило, тексты, написанные в этом жанре, содержат большое количество аргументации, т.е. типовых рассуждений, поддерживающих или опровергающих какой-либо тезис. При этом научно -популярный текст имеет небольшой объём (от 500 до 1000 словоупотреблений), в нём, обычно отсутствуют специальная лексика и явно выраженная структуризация (при помощи глав и подзаголовков). Метаописание текста Автор Сергей Васильев Название Власть гласных Дата Изобретая название бренда или продукта, обращайте внимание на звучание гласных. В конечном итоге, именно они подскажут покупателям, какой продукт выбрать и почему. Представьте, что вы видите стол: вы называете его столом и знаете, что это такое и чего от него ожидать. Но когда вы сталкиваетесь с совершенно новым и неизвестным продуктом, всех этих ссылок и ассоциаций еще нет. Значение Название URL ▼ □. Naked Science * Власть гласных В Внимание билингвов оказалось бог = Дети в семимесячном возрасте от/ = До конца XXI века может исчезну! = Компьютер перевел свист дельфин = Предки коренных народов России 1 В Экономический рост приводит к ис ► и National Geographic ► И STRF ( Иерархия ' корпусов ► Антинаучные ^* ► I lj Дилетант ► | |« Земля. Хроники Жизни Главная Корпус Схемы аргументации О ресурсе Создать проект Проекты - Рисунок 3 – Создание корпуса текстов Для автоматизации процесса создания корпусов был разработан модуль загрузки текстов, который выполняет следующие задачи: ■ загрузка интернет-страниц из открытых источников по ссылкам; ■ выделение основного контента и очистка от ненужных элементов разметки; ■ анализ контента интернет-страницы и выделение в нём текста публикации, её названия, автора (авторов), даты и тематики (если имеется); ■ приведение текста к стандартным формату и кодировке, размещение его в БД системы (тексты снабжаются метаданными; при необходимости формируются новые корпусы). С помощью автоматизированных средств на текущий момент собрана коллекция научнопопулярных текстов объёмом около 3500 статей, сгруппированных по 11 корпусам, которые регулярно пополняются. При размещении текста в БД системы из него удаляется всё форматирование, реализованное с помощью тэгов, за исключением перевода строки (символа абзаца). В дальнейшем текст редактироваться не может, что связано с особенностями представления аннотаций. Обеспечение аргументативной разметки (аннотирования) текста — самая трудоёмкая и значимая задача, реализуемая системой. Такая разметка в соответствии с концепцией AIF помимо средств для непосредственной работы с текстом требует инструментов для построения графов и обеспечения методической поддержки исследователя (эксперта), осуществляющего разметку. На рисунке 4 показаны три различных представления аннотированного текста: a) размеченный текст, b) список аргументов, c) аргументативный граф. Представление аргументации в размеченном тексте (a) демонстрирует множество размеченных утверждений в связном тексте и дополнительно позволяет в пошаговом режиме просмотреть выделенные аргументы. В этом режиме аргумент показывается выделением всех утверждений, входящих в его состав (посылки и заключение). Список аргументов (b) позволяет увидеть перечень всех размеченных в тексте аргументов и, в отличие от предыдущего представления, состав каждого аргумента, его схему и имплицитно представленные утверждения (данные утверждения отсутствуют в тексте, но восстанавливаются читателем из внешнего контекста). Совместно с текстовым данное представление даёт полный обзор размеченной аргументации и покрываемых ею фрагментов текста. Для создания и редактирования аргументации преимущественно используется графовое представление (c). В соответствии с данным представлением множество взаимосвязанных аргументов, размеченных в тексте, называют сетью аргументов или графом аргументации. Онтология AIF уже содержит понятия для графового представления аргументов — это класс Node и его потомки. На рисунке 4 утверждения (прямоугольные вершины) соответствуют экземплярам информационных вершин (I-Node), а аргументы (вершины со скруглёнными краями) — экземплярам S-Node. Рисунок 4 – Аргументативная разметка текста Сценарий работы пользователя включает основной этап, на котором осуществляется построение графа аргументации, и этап, на котором выполняется анализ аргументации. Основной этап включает следующие шаги: ■ сегментация текста с выделением в нём аргументативных дискурсивных единиц (АДЕ) и формирование на их основе утверждений (при формулировании утверждений должны сниматься неоднозначность, разрешаться анафора, восстанавливаться эллипсис и т.п.); ■ определение роли для каждой АДЕ (заключение или посылка) и построение направленных отношений — аргументов, связывающих аргументативные единицы; ■ детализация структуры аргументов на основе соответствующих схем аргументации; ■ выявление имплицитных и эквивалентных утверждений и обеспечение максимальной связности графа. Для перехода к следующему этапу — анализу и оценке аргументации — полученный граф полезно верифицировать, поскольку даже небольшое изменение в его структуре может повлечь существенные расхождения в итоговой оценке. Автоматическая верификация графа может включать такие процедуры как поиск циклов, анализ связности, учёт текстовых индикаторов аргументации, сравнительный анализ с другими разметками. На данный момент системой поддерживаются первые три возможности. Верификация, осуществляемая пользователями, может заключаться в согласовании мнений нескольких экспертов, а также в проведении сравнительного исследования аргументативных связей (например, анализ корреляции с риторической разметкой [16-17]). 3 Инструменты поддержки исследования аргументации 3.1 Поисковый сервис Поддержка исследования аргументации на предлагаемой платформе обеспечивается следующим набором специализированных средств: поисковым сервисом, позволяющим ознакомиться с уже представленными в системе результатами работы экспертов; лингвистическим модулем, выполняющим предварительную обработку текста, в ходе которой фиксируются специальные языковые конструкции — индикаторы; вычислительным модулем, поддерживающим оценку убедительности представленных в тексте аргументов. Поисковый сервис позволяет ориентироваться в представленных корпусах и обеспечивает в них поиск в терминах онтологии аргументации. С его помощью исследователь может найти в аннотированных текстах примеры использования заданных схем аргументации или примеры утверждений, участвующих в аргументах в определённой роли. На рисунке 5 представлены результаты поиска всех утверждений, участвующих в аргументах, представляющих причинно-следственные связи в текстах (Causal_Statement). Результаты поиска отображаются в виде таблицы, в которой для каждого найденного утверждения даются ссылки на текстовый источник (Первоисточник) и аннотацию (Проект), в которых оно встречается, название аргумента (Аргумент), в котором оно участвует, и само утверждение с ближайшим окружением (Контекст). Таким образом, поисковый сервис позволяет пользователю ознакомиться с примерами употребления тех или иных схем аргументации или утверждений и статистикой их встречаемости в текстах корпуса. ^. BadConsequence_Statement ^. BadOtherConsequence_Statement BiasCondusion_Statement BiasConditionaLStatement Bia sed Classification Defin"ition_Statement Biased Person-Statement CaseOutcome_Statement CaseProperty_Statement Causal_Statement Chain Required-Statement ChainedCases_Statement ChainedlmpficationS-Statement Chainedlndisting uishable_Statement CharacterAttack_Statement CharacterRelevance_Statement Описание утверждения Схема аргументации Са u seToEffectJ nference Утверждение «Causal_Statement» Роли утверждения в аргументации A causes В Роль утверждения в схеме Causal_Premise Conclusion ClassificationProperty_Statement Com mitmentEvidence_Statement Com mitmentException_Statement Com mitmentInconsistency_Statement Com mitmentLinkage_Statement Com mitment_Statement Com mon KnowledgeBackU p_5tatement Conf6ctingGoals_Statement ConsequenceBackUpEvidence_Statement ContainsProperty_Statement Contin ueAction_Statement Corrdation_Statement CredibttyOfSou rce_Statement DifferencesU ndermineSimiarity_Statement Disj uction_Statement CorrelationToCauseJnference Найти примеры Первоисточник Проект Аргумент Контекст *Самые необычные звуки в языках мира ИльинаД- L от причины одну из песен ее народа — свадебную «Qongqothwane» — в Америке и Европе именуют «The Click Song», поскольку не могут произнести ее оригинальное название * Самые необычные звуки в языках ИльинаД-L от причины к с... в Америке и Европе именуют «The Click Song» *RST-Ling-43 IP-1 CorrelationToCa... мотивированность неофициальных именований лица может рассматриваться под разным углом зрения и с учетом разных факторов *RST-Ling-43 IP-1 CauseToEffect_l... Экстралингвистическая мотивированность Previous Р age 1 : of 43 10 rows - Next Рисунок 5 – Поиск утверждений по заданной роли в структуре аргументов 3.2 Анализ индикаторов аргументации Для привлечения внимания пользователя к аргументам, представленным в тексте явно, и оказания помощи в выделении в тексте границ АДЕ и в выборе схемы аргументации выполняется предварительная лингвистическая обработка текстов, которая позволяет обнаружить в тексте специфические подсказки в виде различного рода словесных клише. Эти клише являются индикаторами, указывающими на факт присутствия аргумента в тексте. Автоматический поиск индикаторов осуществляется с помощью шаблонных конструкций, описывающих классы языковых выражений, и учитывает возможные грамматические формы, их сочетаемость в многословных цепочках и пунктуацию [18]. Шаблоны формулируются экспертами на основе анализа текстов, содержащих аргументацию, после чего расширяются путём учёта вариантов методами построения образцов с переменными и итерационного поиска [19]. Можно выделить следующие типы соотношений между индикатором и сигнализируемыми им аспектами аргументации: 1) сила или убедительность аргумента; 2) степень уверенности автора в утверждении; 3) отношение вывода между двумя утверждениями (наличие аргументации); 4) тип аргументативного отношения (поддержка vs. конфликт); 5) роль утверждения в отношении вывода (посылка vs. заключение); 6) семантико-онтологическое отношение, на котором основана применяемая в данном случае типовая схема рассуждения; 7) структура аргументации (множественная vs. последовательная аргументация). Аспекты 2–3 и 5–6 соотносят индикатор не столько с аргументом, сколько с конкретным утверждением (или несколькими утверждениями) в структуре аргумента. Аспекты 1, 3 и 7 сигнализируют только о наличии аргументации, что в случае ручной разметки фокусирует внимание эксперта на соответствующих фрагментах текста, а при автоматической — требует наличия других показателей для более точного выявления класса аргумента. Аспекты 1 –2 влияют на оценку убедительности аргументации. Индикаторы, автоматически найденные в тексте, выделяются полужирным шрифтом (см. рисунок 6), привлекая внимание пользователя к фрагментам текста, потенциально содержащим аргументацию. При наведении курсора на индикатор отображается подсказка, где указано имя соответствующего шаблона. В некоторых случаях имя шаблона косвенно указывает на присутствие в тексте аргументов, соответствующих определённой схеме. На протяжении десятилетий ученые считали, что большинство приматов не может воспроизводить гласные, Фунд^ Подсказка c iQgo| прикА^^^^^ Однако теперь исследователи выяснил^, что гв обитающие в лесах и саваннах зала вчи I во experLopinion произносить (вернее, подвывать) пя Индикаторь торые являются се потому, что у льная анатомия. йские павианы, ки, могут в, очень И experL.opinionQ □ похожих на те, которыми пользуются люди, атьуйсследование привычную нам речь. Итоговый результат предполагает, что основные элементы разговорного языка начали развиваться намного раньше, чем считалось до этого - примерно 25 миллионов лет назад. □ □□ exoert _о р i п i оп_а ct_d i г □ opinion^Q □ _speech_activity0 □ _mental_stateQ □ JnteLactivityQ □ _act© □ sent actffl □ _prep_actQ 3.3 Оценка убедительности аргументации _opinion_act_inv _expert_opinion_3„begin opinioni^ Рисунок 6 – Поиск индикаторов аргументации В левой части рисунка 6 представлен фрагмент размеченного текста, в котором полужирным шрифтом выделены индикаторы, сигнализирующие о наличии аргументации «От эксперта», а в правой части - фрагмент иерархии шаблонов, в которой пользователь может выбрать те шаблоны, которые он хочет видеть в тексте. Таким образом, аннотация состоит из множества фрагментов текста, каждому из которых поставлено в соответствие утверждение или индикатор. Аргументы определяются как n-местные отношения над размеченными текстовыми фрагментами. Роль индикаторов заключается в фиксации свойств и границ аргументов и их структурных элементов. Чтобы оценить, насколько рассматриваемый текст успешен в донесении своих тезисов до читателя, требуется установить, какие в нём используются риторические приёмы и схемы рассуждений (т.е. аргументативные структуры), сравнить их с приемами и схемами, использованными в качественных, с точки зрения убедительности, научно-популярных текстах, а также определить убедительность аргументов исследуемого текста. Для этого необходимы методика оценивания убедительности аргументации и достаточно репрезентативный корпус текстов, содержащий максимально разнообразную аргументацию. Существуют различные модели численного представления и вычисления убедительности аргументов. Как правило, убедительность выводов, отстаиваемых при помощи аргументов, зависит от убедительности посылок и самих аргументов. Популярным подходом при измерении и вычислении убедительности является рассмотрение степени убедительности как вероятности утверждения оказаться истинным. Это значит, что степень убедительности (вес) выводов, посылок и аргументов представляется числом из интервала от 0 до 1. При создании веб-платформы применялся специально разработанный алгоритм, основанный на операциях нечёткой логики, в которой определена алгебра истинностных значений. Если рассматривать аргумент как имеющее определённую силу доказательство некоторого утверждения, то чем более обосновано утверждение, тем большей полагается степень его истинности. Упомянутый алгоритм по заданным экспертом весам посылок и аргументов вычисляет веса выводов, в том числе проводит вычисления по цепочке, когда вывод одного аргумента одновременно является посылкой для другого, как это показано на рисунке 7, или когда в графе помимо выводов содержатся и конфликтующие с ними тезисы. При этом очевидно, что цепочка рассуждений в графе не должна зацикливаться, так как в противном случае убедительность вывода будет зависеть в том числе от себя самой, и вычисление не будет корректным. Каждой вершине графа соответствуют три веса: начальный вес; вес, вычисленный без учёта конфликтных ситуаций (только выводы); вес, вычисленный с учётом атак со стороны конфликтующих утверждений (если таковые имеются). Следует заметить, что эксперты могут заранее задать каждой схеме аргументации так называемый априорный вес, учитывающий образ мышления и систему ценностей одной из трёх аудиторий: «широкая публика», «научная аудитория», «школьники». Априорный вес схемы аргументации по умолчанию используется в качестве начального веса всех построенных на её основе аргументов графа, если исследователь сам их не задал. Отсюда следует, что графы аргументации, построенные для разных аудиторий, могут не совпадать. В целом, каждый текст в корпусе может иметь произвольное количество независимых аннотаций. соответствуют Международному алфавиту, о чем гласным по фонетическом исследователи гласных звука в как «Вооуу». Соответственно, Выделенное на графе утверждение быстрой последовательности, которая звучит сообщают в журнале PLoS ONE. По их мнению, этого достаточно, чтобы поставить язык бабуинов в один ряд со многими человеческими языками, большинство из которых как раз имеют от 3 до 5 гласных звуков (хотя есть и те, в которых гласных звуков насчитывается аж 24). Кроме того, бабуины регулярно объединяют два «строительные блоки» для фундамента будущей языковой структуры определенно присутствуют. У бабуинов существует определенная система объединения звуков теоретический реальности • теоретический - устройство реальности - от части к целому них существует определенная система объединения звуков, которая, как объясняет Фагот, раньше считалась исключительно человеческим изобретением. 'азумеется, это означает, что бабуины полноценный язык в том котором его понимаем определенные «строительные блоки» для фундамента будущей языковой структуры определенно присутствуют. теоретический - устройство реальности - от причины к следствию составили смысле, в мы, А-Ргюп weight 0.986328 No-conflict weight тприм< иваться н ь до этого /1ллионов ле п одсвечива ются утверждения, поддерживающие выделенное. Weight 0.986328 I эбуины 'звуков, KI KnOL Рисунок 7 - Пример убедительности аргументации Заключение Предложенный в работе подход к исследованию аргументации в научно-популярных текстах включает два этапа: ■ этап аннотирования текстов и построения графов аргументации на основе знаний о типовых схемах рассуждений и примеров их употребления в корпусе, ■ анализ статистики употребления типовых схем рассуждений в исследуемом корпусе и оценку убедительности аргументации относительно различных аудиторий. Разработан набор инструментов для поддержки исследования аргументации, интегрированных в единую веб-платформу, которая позволяет создавать корпусы текстов, извлекать индикаторы аргументации, снабжать тексты аргументативной разметкой, осуществлять поиск в терминах онтологии и анализировать качество аргументации на основе реализованных в системе моделей вычисления убедительности. С помощью предложенной методики и разработанных инструментов было собрано 112 корпусов, включающих 2 360 текстов научно-популярного жанра, 109 из которых было размечено и для них построено 146 графов аргументации. Созданные корпусы планируется сделать открытыми для других исследователей. Одним из важнейших направлений развития предложенного инструментария является включение в него средств для расширения набора типовых схем аргументации, что будет способствовать развитию теории аргументации. Статья подготовлена по итогам исследования, проведённого в рамках проекта Российского фонда фундаментальных исследований № 18-00-01376 (18-00-00889).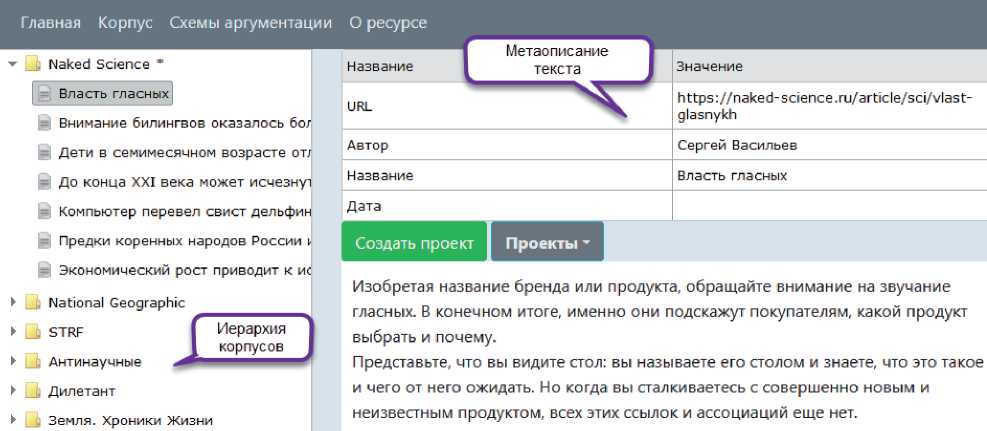
 поддерживает другую работу, в ходе которой ученые выяснили, что японские макаки тоже анатомически способны на
поддерживает другую работу, в ходе которой ученые выяснили, что японские макаки тоже анатомически способны на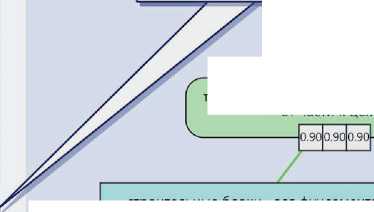

Список литературы Платформа для исследования аргументации в научно-популярном дискурсе
- Lawrence, J. Argument mining: A survey / J. Lawrence, C. Reed // Int. J. of Computational Linguistics. - 2019. -Vol. 45(4). - P.765-818.
- Reed, C. Araucaria: Software for argument analysis, diagramming and representation / C. Reed, G. Rowe // Int. J. on Artificial Intelligence Tools. - 2004. - Vol. 13(4). - P.961-979.
- Stab, C. Identifying Argumentative Discourse Structures in Persuasive Essay / C. Stab, I. Gurevych // Empirical Methods in Natural Language Processing (EMNLP): Proc. of the Int. Conf. (Doha, Qatar). - 2014. - P.46-56.
- Peldszus, A. An annotated corpus of argumentative microtexts / A. Peldszus, M. Stede // Argumentation and Reasoned Action: Proc. of the 1st European Conference on Argumentation. - London: College Publications, 2016. -Vol. 2. - P.801-816.
- Bex, F. ArguBlogging: An application for the argument web / F. Bex, M. Snaith, J. Lawrence, C. Reed // Int. J. of Web Semantics: Science, Services and Agents on the World Wide Web. - 2014. - Vol. 25. - P.9-15.
- Walton, D. Argumentation schemes / D. Walton, C. Reed, F. Macagno. - Cambridge: Cambridge University Press, 2008. - 443 p.
- Корпус AIFdb. - http://corpora.aifdb.org/.
- Bex, F. Implementing the argument web / F. Bex, J. Lawrence, M. Snaith, C. Reed // Int. J. of Communications of the ACM. - 2013. - Vol. 56(10). - P.66-73.
- Bex, F. Dialogue templates for automatic argument processing / F. Bex, C. Reed // Computational Models of Argument: Proc. of the 4th Int. Conf. COMMA 2012 (Vienna). - IOS Press, 2012. - P.366-377.
- Van Gelder, T. The rationale for rationale / Tim van Gelder // Int. J. of Law, Probability and Risk. - 2007. -Vol. 6(1-4). - P.23-42.
- Gordon, T.F. The Carneades model of argument and burden of proof / T.F. Gordon, H. Prakken, D. Walton // Int. J. of Artificial Intelligence. - 2007. - Vol. 171(10). - P.875-896.
- Kirschner, C. Linking the thoughts: Analysis of argumentation structures in scientific publications / C. Kirschner, J. Eckle-Kohler, I. Gurevych // Argumentation Mining: Proc. of the 2nd Workshop. - Denver, CO. - 2015. - P.1-11.
- Rahwan, I. Representing and classifying arguments on the semantic web / I. Rahwan, B. Banihashemi, C. Reed, D. Walton, S. Abdallah // The Knowledge Engineering Review. - 2011. - Vol. 26(4). - P.487-511.
- Chesnevar, C.I. Towards an argument interchange format / C.I. Chesnevar, J. McGinnis, S. Modgil, I. Rahwan, C. Reed, G. Simari, M. South, G. Vreeswijk, S. Willmott // The knowledge engineering review. - 2006. -Vol. 21(4). - P.293-316.
- Загорулько, Ю.А. Моделирование аргументации в научно-популярном дискурсе с использованием онтоло-гий / Ю.А. Загорулько, Н.О. Гаранина, О.И. Боровикова, О.А. Доманов // Онтология проектирования. -2019. - Т. 9, № 4(34). - С.496-509. - DOI: 10.18287/2223-9537-2019-9-4-496-509.
- Musi, E. A Multi-layer Annotated Corpus of Argumentative Text: From Argument Schemes to Discourse Relations / E. Musi, T. Alhindi, M. Stede, L. Kriese, S. Muresan, A. Rocci A. // Language Resources and Evaluation (LREC'2018): Proc. of the 11th Int. Conf. (Miyazaki, Japan). - 2018. - P.1629-1636.
- Kononenko, I.S. Comparative analysis of rhetorical and argumentative structures in the study of popular science discourse / I.S. Kononenko, E.A. Sidorova, I.R. Akhmadeeva // Computational Linguistics and Intellectual Technologies: Proc. of the Int. Conf. "Dialogue". - 2020. - Vol. 19 (26). - P.432-444.
- Сидорова, Е.А. Подход к моделированию процесса извлечения информации из текста на основе онтологии / Е.А. Сидорова // Онтология проектирования. - 2018. - Т.8, №1(27). - С.134-151. - DOI: 10.18287/22239537-2018-8-1-134-151.
- Ахмадеева, И.Р. Подход к построению шаблонов индикаторов для извлечения аргументов из научно-популярных текстов / И.Р. Ахмадеева, И.С. Кононенко, Н.В. Саломатина, Е.А. Сидорова // Знания - Онтологии - Теории: Труды международной конф. (З0НТ-2019). - Институт математики им. С.Л. Соболева СО РАН, Новосибирский государственный университет, 2019. - С.24-32.
