Поддержка принятия решений при управлении программными проектами на основе нечёткой онтологии

Автор: Антонов В.В., Бармина О.В., Никулина Н.О.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Методы и технологии принятия решений
Статья в выпуске: 1 (35) т.10, 2020 года.
Бесплатный доступ
Рассмотрены вопросы управления знаниями при выполнении программных проектов и организации поддержки принятия решений для их участников. Актуальность исследований обоснована необходимостью снизить степень неопределённости при принятии решений и подтверждена статистикой выполнения проектов. Поддержку принятия решений предложено организовать на основе анализа прецедентов ранее происходивших проблемных ситуаций и поиска оптимального решения в текущей ситуации, для чего предложено использовать методы инженерии знаний, в частности, онтологического анализа предметной области. Разработана методика формирования нечёткой онтологии поддержки принятия решений при управлении программными проектами. Новизна модели поиска прецедентов заключается в сочетании различных механизмов логического вывода при принятии решений на базе всего комплекса знаний о предметной области. Большой объём информации не позволяет использовать простые поисковые запросы для оперативного поиска необходимой информации, созданной в процессе выполнения проекта. Предложен алгоритм формирования поискового запроса, учитывающего нечёткие свойства, нечёткие таксономические и ассоциативные отношения между классами объектов в онтологии. Эффективность предложенных решений подтверждена экспериментом на прототипе интеллектуальной системы поддержки принятия решений.
Управление проектами, нечёткая онтология, управление знаниями, поисковый запрос, поддержка принятия решений, прецедент проблемной ситуации
Короткий адрес: https://sciup.org/170178843
IDR: 170178843 | УДК: 004.89 | DOI: 10.18287/2223-9537-2020-10-1-121-140
Decision-making support in software project management based on fuzzy ontology
The article deals with knowledge management in software projects and decision-making support of its participants. The novelty of research is justified by the need to reduce the degree of uncertainty in decision-making and is confirmed by statistics indicating a sufficiently large number of unsuccessful projects. It is proposed to organize decision-making support based on the cases analysis of previously occurring problem situations. Also, it is proposed to use knowledge engineering methods, in particular, ontological analysis of the subject area. A formation of a fuzzy ontology method is developed for decision-making support in the software development. The novelty of the mathematical model lies in the combination of various inference mechanisms when making decisions on the basis of the entire complex of knowledge about the subject area. Increasing amount of information does not allow using simple searches for quick retrieval of the necessary information. Therefore, an algorithm is proposed for generating a search query that takes into account fuzzy properties, fuzzy taxonomic and associative relations between classes of objects in ontology. The effectiveness of the proposed solutions is confirmed by an experiment on the prototype of an intelligent decision-making support system.
Текст научной статьи Поддержка принятия решений при управлении программными проектами на основе нечёткой онтологии
Одним из направлений развития проектно-ориентированных ИТ-компаний является сосредоточение на извлечении уроков из успешных отраслевых проектов [1, 2]. Так, в Руководстве к своду знаний по управлению проектами активами организации, использование которых оказывает благоприятное влияние на достижение целей проекта, считаются: политики, правила и процедуры, а также корпоративная база знаний (БЗ) [3]. При этом «репозитории знаний организации, предназначенные для хранения и извлечения информации, включают в себя, среди прочего, репозитории данных по управлению проблемами, содержащие сведения о статусе проблем, информацию о контроле, данные о разрешении проблем, а также результаты предпринятых действий» [3, c.41]. Совокупность этих данных можно назвать прецеден- тами проблемных ситуаций (ПС) [4]. Такая информация должна быть зафиксирована и доступна всем участникам проекта в рамках их компетенции и полномочий.
Программные проекты (ПП) обладают рядом особенностей, среди которых - высокая степень уникальности конечного продукта, многообразие методов и средств, применяемых при разработке программного обеспечения (ПО), затрудняющее их выбор для реализации конкретного проекта, плохо формализуемые взаимодействия между участниками проекта, большая доля творческой составляющей в деятельности человека. Всё это диктует необходимость применения инструментов, позволяющих не только управлять разработкой ПО (своевременно отслеживать статус решаемых задач, процент их выполнения и объём затраченных ресурсов, вести журнал выявленных и исправленных ошибок), но и накапливать информацию для устранения ПС. Возникновение ПС в ПП часто связывают с [5, 6]: ■ неточным определением сроков и стоимости проекта - 62%;
-
■ нарушением взаимодействия между различными участниками проекта - 47%;
-
■ отсутствием интеграции между различными системами, использующимися при управлении ПП (системами календарно-ресурсного планирования, системами отслеживания ошибок, системами бюджетирования) - 38%;
-
■ отсутствием единого централизованного источника информации о проекте - 35%;
-
■ неудовлетворительным управлением ресурсами - 31%;
-
■ отсутствием видимости результатов в ещё не завершённых задачах - 21%.
Возможность использовать знания и опыт, накопленные при управлении ПП в различных ситуациях, позволяет быстрее и более качественно решать возникающие проблемы. Однако всего лишь 14% компаний применяют этот подход на практике, что связано со сложностью представления и формализации знаний в этой области, высокой неопределённостью в принятии решений [1, 5, 7].
1 Нечёткая онтология как модель представления знаний
Неопределённость и неточность могут рассматриваться как две противоположные точки зрения на неполноту информации. Информация, как правило, выражается в виде логического высказывания, содержащего предикаты, квантификаторы. Под БЗ понимается множество сведений, имеющихся у субъекта (группы субъектов) или содержащихся в информационной системе и относящихся к одной и той же предметной области (ПрО). Любое высказывание может рассматриваться как утверждение, относящееся к появлению некоторого события. Известны три эквивалентных способа анализа множества данных в зависимости от того, делается ли акцент на структуре (логическая точка зрения), содержании (теоретикомножественная точка зрения) этой информации или на её отношении к действительным фактам (событийная точка зрения) [8].
Информационную единицу знания можно представить в виде четвёрки:
-
(1) K =
,
где K - информационная единица знания ( knowledge ), O - объект ( object ), A - признак ( attribute ), V - значение ( value ), С - уверенность ( certainty ).
Под признаком понимается функция, задающая значение (множество значений) объекта или предмета, название которого упоминается в информационной единице знания. Значение соответствует некоторому предикату. Уверенность есть показатель надёжности информационной единицы знания. Принятие решения в большинстве случаев заключается в генерации возможных альтернативных решений, их оценке и выборе наилучшего варианта, иногда с привлечением экспертов или других способов информационной поддержки.
При выборе варианта приходится учитывать большое число неопределённых и противоречивых факторов [9, 10]. Неопределённость является неотъемлемой частью процессов принятия решений и может быть связана с:
-
■ неполнотой знаний о проблеме, по которой должно быть принято решение;
-
■ невозможностью полного учёта реакции окружающей среды на принимаемые решения;
-
■ непониманием лицом, принимающим решение (ЛПР), своих целей.
Противоречивость возникает из-за неоднозначности оценки ситуаций, ошибки в выборе приоритетов, что осложняет принятие решений. Исследования показывают, что ЛПР без дополнительной аналитической поддержки, как правило, использует упрощённые, а иногда и противоречивые правила выбора решения [9]. Кроме того, наличие разнородных источников информации также затрудняет процесс принятия решений. Основная проблема, возникающая при попытках повторного использования знаний и передового опыта, заключается в сложности выбора успешных решений, опыт которых применим к конкретной решаемой задаче. Эта проблема может быть решена путём систематизации знаний и моделирования ПрО с позиций методов, учитывающих нечёткость описаний модели исследуемого объекта [1113]. Снижению неопределённости способствует систематизация знаний о деятельности ЛПР, повышение интеграции источников знаний и создание единого информационного пространства, использование онтологий [14].
Онтологию можно представить в виде неструктурированного описания на естественном языке ( not formal ontology ), в виде полуструктурированного описания как графической схемы ( semi-formal ontology ), в виде структурированного описания на языке OWL , RDF (formal ontology ). Онтология предназначена для решения проблем семантического различия информации, поступающей из различных источников, предоставления возможностей автоматического вывода знаний и уменьшения неопределённости знаний в ПрО. Примеры применения онтологий в различных ПрО приведены в [14-16]. Онтологическая модель описания прецедентов ПС, встречающихся в ПП, подробно описана в [17]. Чаще всего онтологии используют для уменьшения неопределённости легко структурируемых знаний, примерами могут служить таксономии с чёткими концептами, а также знания, основанные на правилах. В случае трудно структурируемых знаний применяются онтологии, основанные на нечёткой логике, теории вероятностей и теории возможностей [8, 18].
Нечёткие знания характерны для многих ПрО, в том числе таких как интеллектуальный анализ информации, машинное обучение, которые оперируют неточными или неполными знаниями. Нечёткая онтология может быть представлена в виде:
-
(2) O =< C, I, P, T, N, A >,
где C - множество нечётких понятий (классов), каждое понятие является нечётким множеством в области экземпляров, такое, что C : I ^ [0, 1]; I - экземпляры (элементы классов). Множество объектов нечёткой онтологии определяется как E = Cu I ; P - множество нечётких свойств класса C ; T - множество нечётких таксономических отношений, такое что T : E ^ [0, 1]; N - множество нечётких не таксономических ассоциативных отношений N : E ^ [0, 1]; A - множество нечётких аксиом.
Нечёткая онтология может быть создана в редакторе онтологий Protege 5.2.0 [19] с использованием плагина FuzzyOWL , основные элементы которого представлены в таблице 1.
Синтаксис FuzzyOWL предполагает три формата алфавита: для представления нечётких классов ( fuzzy concepts ), нечётких отношений ( fuzzy roles ) и нечётких объектов классов онтологии (fuzzy individuals ), которые определяются свойством аннотации fuzzyLabel , хранящей параметры и значения функции принадлежности, соотносимые с конкретным классом, объектом, отношением внутри заданного нечёткого множества данных [18, 20].
Таблица 1‒ Основные элементы FuzzyOWL
Элемент
FuzzyOWL
Формат
Пример представления в нечёткой онтологии
FuzzyOWL в виде OWL/XML-разметки
Fuzzy ontologies -множество операторов нечётких множеств
Онтологические модели, в том числе нечёткие, позволяют выявлять взаимосвязи в процессах управления проектом. Нечёткая онтология ПрО разработана таким образом, чтобы отобразить множество классов ПС, связанных с решением различных задач, возникающих во время выполнения основных процессов управления ПП, а также структурировать БЗ. Разра- ботка нечёткой онтологии соответствует принципам FuzzyOWL и включает последовательность шагов, представленных на рисунке 1.
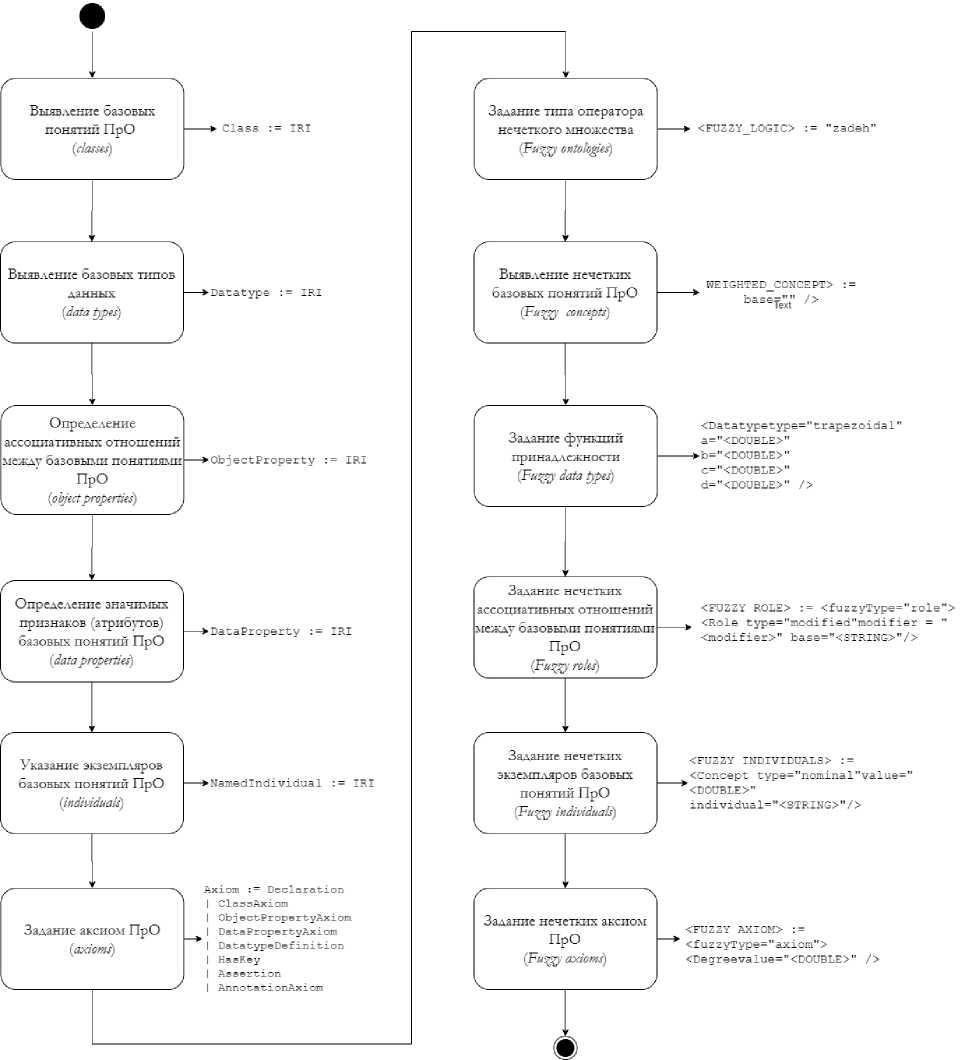
Рисунок 1 ‒ Последовательность построения нечёткой онтологии
После разработки онтологии для обмена и использования знаниями необходимо обеспечить поддержание в актуальном состоянии базы (репозитория) прецедентов. Данная деятельность представляет собой замкнутый цикл, состоящий из шести этапов:
-
1) поиск прецедентов под возникшую проблему;
-
2) ранжирование похожих прецедентов;
-
3) выбор наиболее похожих прецедентов;
-
4) повторное использование информации и знаний из найденного прецедента для решения возникшей проблемы;
-
5) оценка эффективности предложенного решения проблемы;
-
6) сохранение вновь возникшего успешного прецедента в БЗ для решения подобных проблем в будущем.
2 Алгоритм поиска ближайших прецедентов в нечёткой онтологии
Под прецедентом понимается описание ПС в совокупности с подробным указанием действий, предпринимаемых в данной ситуации для решения данной проблемы. Обобщённая модель прецедента имеет следующий вид [4, 21]:
-
(3) Case: Problem ^ Solution; Result,
где Case - прецедент; Problem - ПС, описывающая состояние процесса управления ПП, когда произошел прецедент; Solution - решение этой проблемы; Result - результат, который описывает состояние процесса управления ПП после произошедшей ПС.
Подробное описание признаков прецедента ПС, возникающих при управлении ПП, приведено в [17]. Одной из наиболее часто встречающихся проблем в проектноориентированных компаниях является распределение ресурсов (в том числе трудовых) между параллельно выполняющимися ПП, а успешность выполнения отдельного проекта может зависеть от того, насколько удачным окажется выбор участников команды проекта. Поэтому процесс поиска прецедента может быть ориентирован на достижение различных целей, например:
-
■ найти такой прецедент, чтобы распределение ресурсов между проектами оказалось наиболее надёжным, обеспечивающим достижение конечной цели проекта;
-
■ найти прецедент с таким распределением ресурсов в проекте, которое обеспечивает минимальное время исполнения;
-
■ найти прецедент, для которого время получения нового решения окажется минимальным (минимум модификаций);
-
■ найти прецедент, отражающий наиболее современный (поздний) опыт.
Онтологическая модель ПрО может быть представлена в виде графа. Такое представление семантической модели определяет способ построения запросов к ней, реализованный в языке SPARQL . Существующие алгоритмы поиска по прецедентам [22] не поддерживают нечёткие онтологии, поэтому разработан алгоритм поиска, позволяющий учитывать нечёткие свойства, нечёткие таксономические и ассоциативные отношения.
Поисковый запрос Qt определяется как совокупность множества типов атрибутов t,, наименований атрибутов п , , , значений атрибутов v , и типов операций сравнения о , :
-
(4) Q i = < tt, тц, v, оt >
Так как в онтологии задана модель данных прецедента ПС, то поисковый запрос Qt содержит конечное множество кортежей, соответствующих модели данных (рисунок 2).
Поисковый запрос пользователя к БЗ, как правило, не полностью отражает ПС, так как пользователь может не знать всех терминов и структуры данных. Использование меры близости для оценки найденных прецедентов в БЗ позволяет расширять запросы и ранжировать результаты поиска. При осуществлении поиска выполняется сравнение заданных параметров в поисковом запросе со значениями прецедентов - экземпляров в онтологии. На основании таксономической близости поисковый запрос расширяется схожими классами ПС, так что предварительная кластеризация прецедентов становится необязательной.
Схема алгоритма поиска прецедента в БЗ в случае использования нечёткой онтологии приведена на рисунке 3.
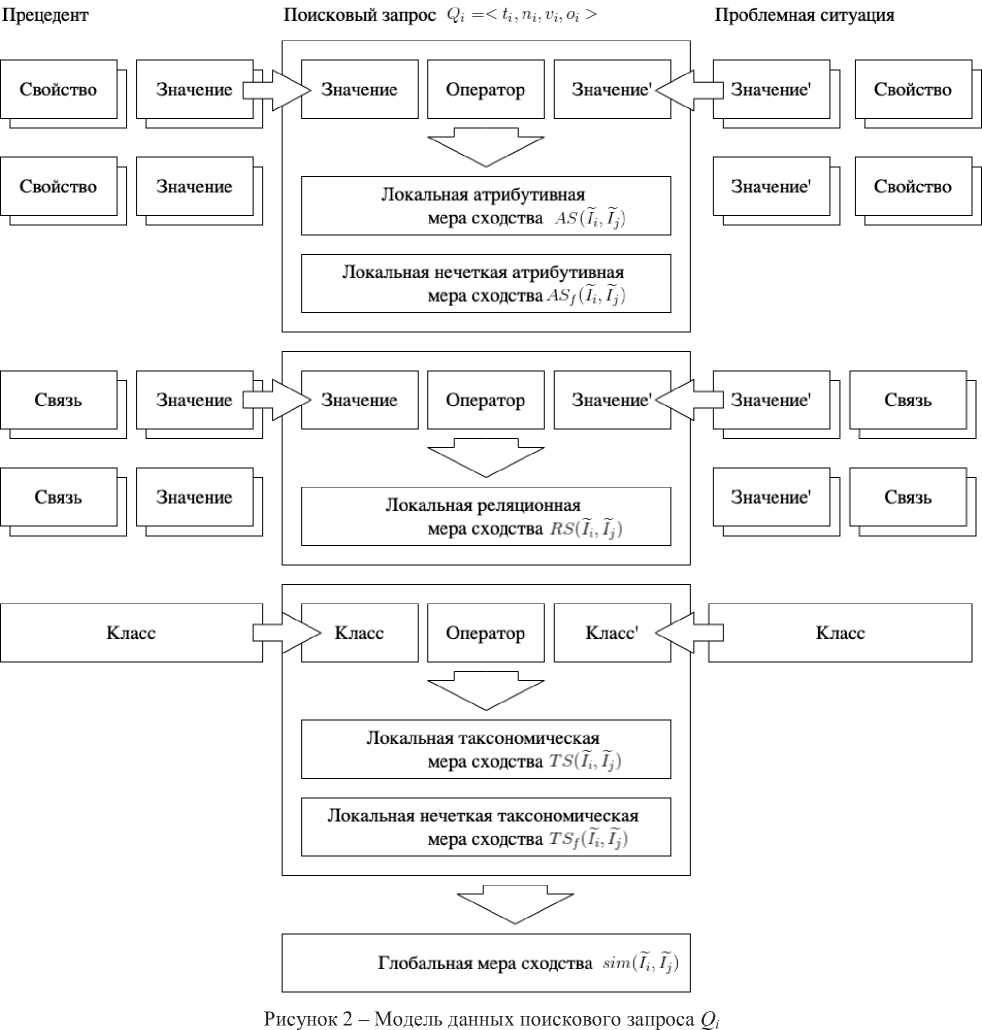
Определение меры сходства ПС и прецедента в БЗ состоит из следующих шагов.
Шаг 1. Парное сравнение атрибутов прецедента и ПС на основе выбранного оператора сравнения для определения атрибутивной близости AS(I, I). Атрибутивной мерой сходства A S(I, I), где / i (%) = 1 и / i (%) = 1, считается определение подобия признаков описания ПС, где, в зависимости от типа данных атрибута, применяется соответствующий оператор сравнения. Так, для строковых типов может использоваться мера сходства - расстояние Ле-венштейна [23] или строгое посимвольное сравнение.
Шаг 2. Парное сравнение прецедента и ПС для определения нечёткой атрибутивной близости AS j (lv Т). В качестве нечёткой меры сходства используется мера сходства Заде для нечётких признаков Т(%к)и Т(хк), х £ Е [24]:
-
(5) ASf(Tv Т) = min (max (1 - ц т (х^ц т (хк)) ,mах( mt (х0,1 - ^ (хк)) ) ,к = 1,п
где ц т (хк ) — значение функции принадлежности нечёткого признака Т(хк ),
Ц Т (хк ) — значение функции принадлежности нечёткого признака Т(хк )
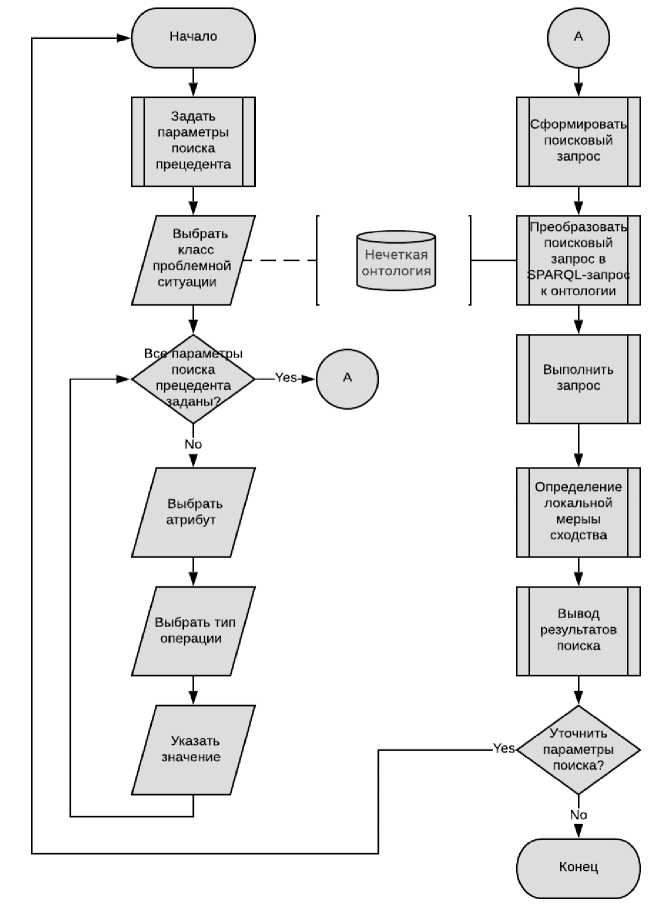
Рисунок 3 ‒ Схема алгоритма поиска прецедента в нечёткой онтологии поддержки принятия решений при управлении программными проектами
Термы лингвистической переменной и тип функции принадлежности задаются в виде аннотации fuzzyLabel к пользовательскому типу данных в онтологии (рисунок 4). Описание работы с редактором онтологий Protege 5.2.0 приведено в [19]. Определение нечёткого типа данных fuzzy data type в редакторе онтологий Protege 5.2.0 приведено на рисунке 4, а определение типа данных для свойства data property на рисунке 5. Domain range свойства data property содержит значения термов лингвистической переменной (5).
В таблице 2 приведён пример определения нечёткой атрибутивной близости для двух проектов Q и С2 к проекту P , в котором обнаружена ПС.
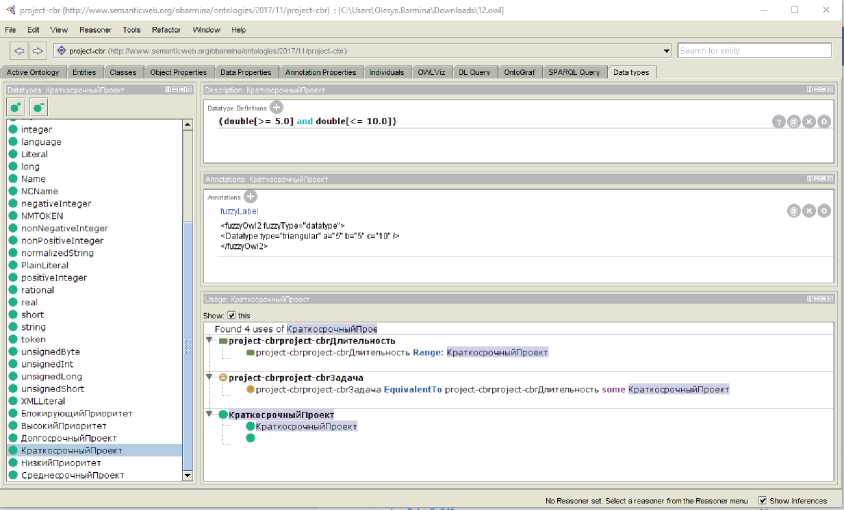
Рисунок 4 - Определение нечёткого типа данных fuzzy data type в редакторе онтологий Protege 5.2.0
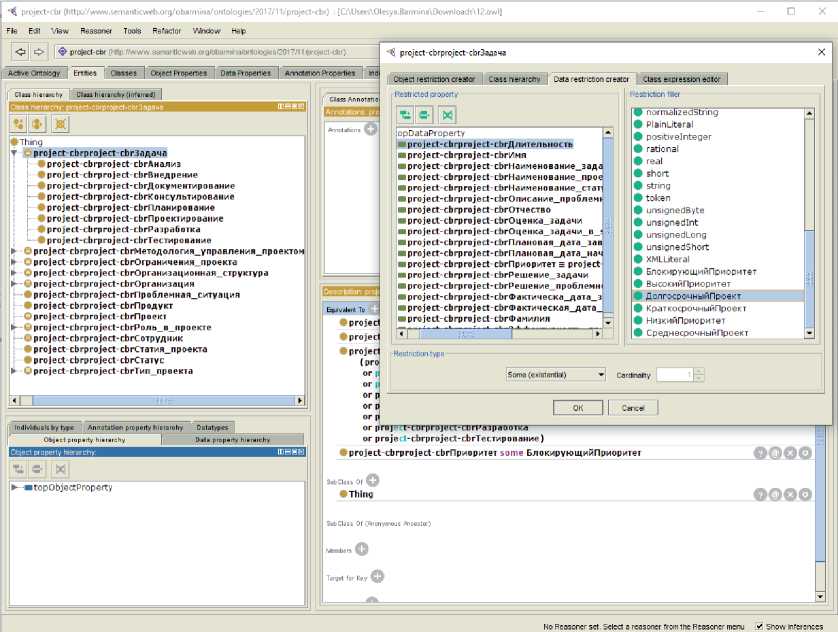
Рисунок 5 - Определение типа данных для свойства data property в редакторе онтологий Protege 5.2.0
Для определения нечёткой атрибутивной близости требуется провести фаззификацию (введение нечёткости), поскольку в онтологии все значения атрибутов хранятся в виде тер- мов лингвистической переменной. Фаззификация заключается в установке соответствия между численным значением входной переменной, представленной в виде критериев поискового запроса, и значением функции принадлежности соответствующего ей терма лингвистической переменной. На этапе фаззификации критериям поискового запроса ставятся в соответствие конкретные значения функций принадлежности соответствующих лингвистических термов (рисунок 6).
Таблица 2 - Пример определения нечёткой атрибутивной близости
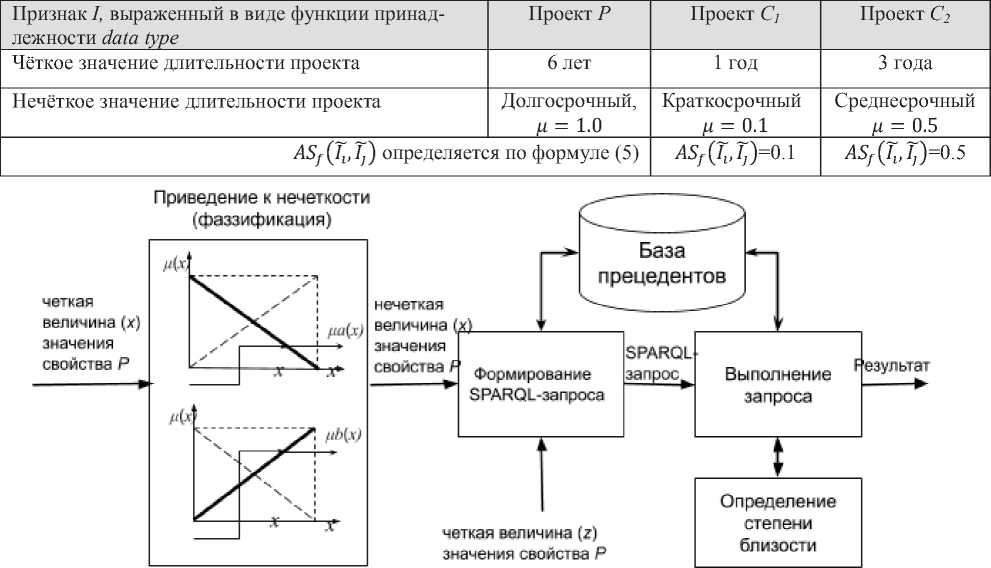
Рисунок 6 - Архитектурная схема поиска прецедента
Пусть переменная < Длительность проекта > может принимать любое значение из диапазона от нуля до бесконечности. Каждому значению длительности из указанного диапазона может быть поставлено в соответствие некоторое число от 0 до 1, которое определяет степень принадлежности данной длительности проекта к тому или иному терму лингвистической переменной < Длительность проекта >. Степень принадлежности определяется так называемой функцией принадлежности ц(%). Например, длительности в 1 год (рисунок 7, таблица 2) можно задать степень принадлежности к терму «краткосрочный» равную 0.1, а к терму «среднесрочный» - 0.0.
Шаг 3. Парное сравнение прецедента и ПС для определения реляционной близости RS (Т, Т) . Реляционная мера сходства RS (Т, ц) , где ц ц (х) = 1 и ц ц (х) = 1, основана на определении подобия ассоциативных отношений ПС.
Шаг 4. Парное сравнение прецедента и ПС для определения таксономической близости TS (ц, Т) , где цц(х) = 1 и ц ц (х) = 1 . Таксономическая близость между экземплярами ц и ц вычисляется с учётом положения соответствующих им понятий Ct и С , в таксономии
-
(6) Н: и С С Ct, нс= = {Н( С, С) V С = С},
где H C - таксономическая иерархия ; UC - вершина, так называемая «верхняя котопия» ( upwards cotopy - UC) [25]. Таким образом, можно определить таксономическую близость TS (Ц Т):
(т = и С ( сь Нс) пи С ( С;-,Н) ( 11 7 ) и с с сь нс) и и с с с, , нс)
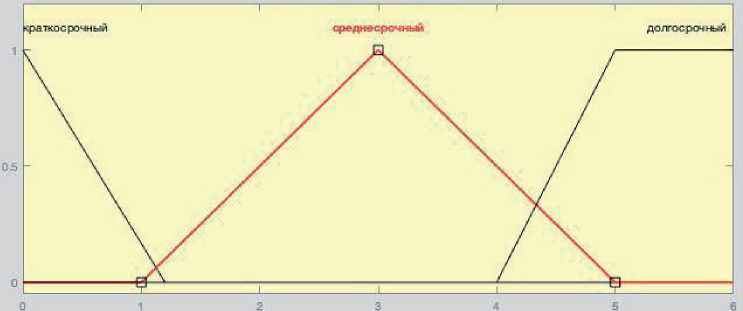
Рисунок 7 – Пример описания лингвистической переменной < Длительность проекта >
Шаг 5. Парное сравнение прецедента и ПС для определения нечёткой таксономической близости ТS f (1, Т)
В таблице 3 приведён пример определения нечёткой таксономической близости для двух проектов Q и С2 к проекту P , в котором обнаружена ПС.
Таблица 3 ‒ Пример определения нечёткой таксономической близости
|
Класс проекта I |
Проект P |
Проект C 1 |
Проект C 2 |
TS f (Т, Т) |
TS f(Т, Т) |
|
Вид проекта |
Региональный |
Международный |
Региональный |
|
|
|
SS f (Т, Т) - 0.7 |
SSf (Т, Т) - 0.77 |
Нечёткая таксономическая мера сходства S S Г (Т, Т) определяется с использованием меры сходства Заде, где значение функции принадлежности нечёткого класса задаётся в аннотации fuzzyLabel в виде параметра fuzzy classes ( рисунок 8 ) .
Шаг 6. Вычисление глобальной метрики сходства после расчёта локальных контекстнозависимых метрик сходства.
Общая величина подобия s imT, Т) экземпляров Т и Т определяется формулой:
t х SS(! Т) + г х RSyТ, Т) + а х ASH, Т) + tf х TSfUL Т) + Of х ASf(Tl, Т) t + г + а + tf + ctf где t, г, а, tf, af - веса различных измерений сходства, которые могут быть подобраны с привлечением экспертных оценок в зависимости от важности учёта различных измерений.
Решение извлекается из найденного похожего прецедента, при необходимости адаптируется к текущей ПС по правилам, разрабатываемым специально для проектноориентированной компании в зависимости от условий ее функционирования или для определенных типов программных проектов. Онтологическая модель описания прецедентов ПС в ПП приведена в [17]. В случае, если похожий прецедент не найден, описание ПС сохраняется в онтологии. ЛПР находит решение самостоятельно или с помощью экспертов и вносит принятое решение в онтологию, формируя новый прецедент.
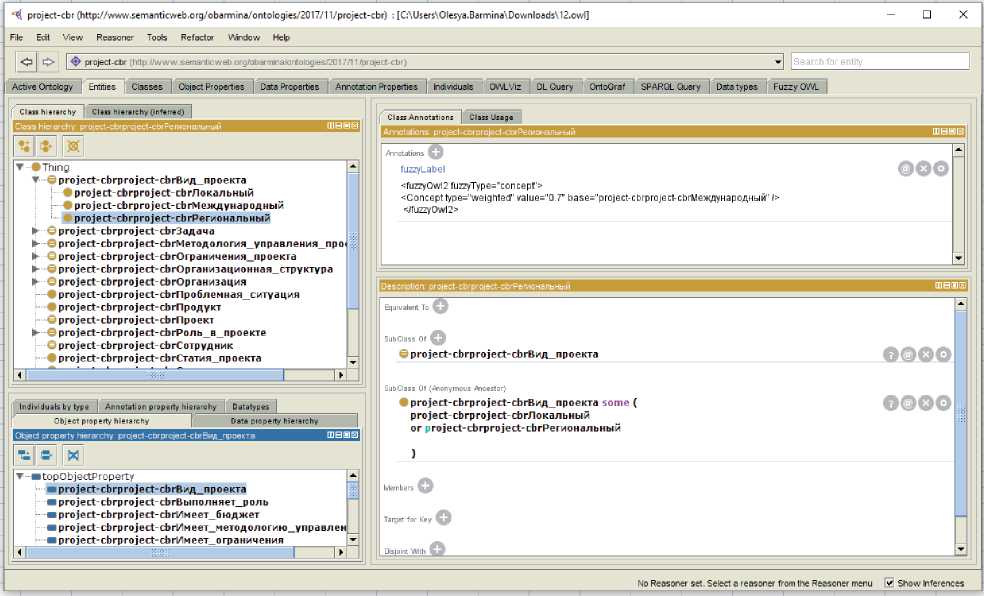
Рисунок 8 – Пример класса с указанной аннотацией fuzzyLabel
3 Программная реализация
Для интеллектуальной системы поддержки принятия решений в соответствии с предложенными моделями было разработано расширение к редактору онтологий Protege 5.2.0 Search-plugin [26]. Все расширения к редактору онтологий Protege 5.2.0 типа TabWidget реализуются с использованием OSGi -спецификации динамической модульной системы и сервисной платформы для разработки Java -приложений (рисунок 9).
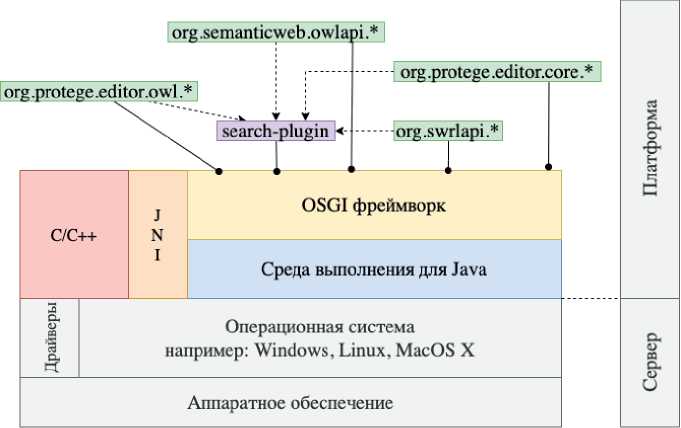
Рисунок 9 – Программная реализация плагина Search-plugin к Protege 5.2.0 для поиска прецедентов проблемных ситуаций
Особенность использования OSGi заключается в возможности динамически переинстал-лировать компоненты и составные части приложения без необходимости его остановки и перезапуска. Круг применений данной спецификации довольно широк: она изначально разрабатывалась для создания встроенных систем (в частности, для автомобилей BMW , также в разработке спецификации активно участвует Siemens ), но сейчас на базе OSGi строят многофункциональные автономные настольные приложения (например, Eclipse SDK ) и корпоративные системы. Модули (плагины, бандлы ( bundle )) взаимодействуют между собой посредством сервисов: объектов системы с заявленными реализованными интерфейсами. Модули регистрируют сервисы для предоставления определённой функциональности, механизма создания и обработки событий. Модуль OSGI ( OSGi bundle ) содержит java -классы и другие ресурсы, которые реализуют необходимые функции, а также предоставляют сервисы и пакеты другим модулям. На рисунке 10 представлена процедура запуска разработанного плагина.
********************************************************************4
** Protege
*********************************************************************
----------------- Initialising and Starting the OSGi Framework -----
FrameworkFactory Class: org. apache. felix.framework.FrameworkFactory
The OSGi framework has been initialised
Starting Starting Starting Starting Starting Starting Starting Starting Starting Starting Starting
---------------------- Starting Bundles ------------------- bundle org.protege.common bundle org.eclipse.equinox.common bundle org .eclipse.equinox.supplement bundle org.protege.editor.core.application bundle org.eclipse.equinox.registry bundle log4j.over.slf4j bundle com.google.inject bundle jul.to.slflj bundle ch.qos.logback.core bundle slf4j.api bundle org.apache.commons.io
| Starting bundle search-plugin
Рисунок 10 - Запуск плагина Search-plugin в Protege 5.2.0
Под плагином понимается Java ™ Archive ( JAR ) - самодостаточный и самоопределяемый модуль. Самодостаточность означает, что модуль содержит в себе код и ресурсы, необходимые ему для работы. Самоопределяемость означает наличие информации о своей сущности, описание требований модуля к внешней среде и описание собственных возможностей для внешней среды. Плагин (модуль Search-plugin ) предназначен для поиска похожих прецедентов ПС, возникающих при разработке ПО, путём формирования SPARQL -запросов к нечёткой онтологии в диалоговом режиме [26]. Пример формирования запроса на поиск похожих прецедентов в нечёткой онтологии с использованием интерфейса разработанного плагина к редактору онтологии Protege 5.2.0 и листинг запроса представлены на рисунках 11 и 12 соответственно.
На запрос поиска прецедентов по ПС, возникшей в программном проекте при выполнении задачи со следующими параметрами: затронуты процессы < Разработка документации >, влияет на работу специалиста < Аналитик >, возможная причина проблемной ситуации состоит в < Неправильная оценка проекта > найдено 13 прецедентов (рисунок 11).
4 Оценка эффективности поиска ближайших прецедентов
Для оценки адекватности разработанных моделей, алгоритмов и ПО были проведены вычислительные эксперименты на основании данных о выполнении ПП (разработка системы электронного документооборота, системы управления финансами, аналитической системы) в различных ПрО для различных заказчиков. Программные проекты выполнялись в одной и той же ИТ-компании, данные для эксперимента собирались в течение 6 месяцев. План экспериментов приведён в таблице 4.
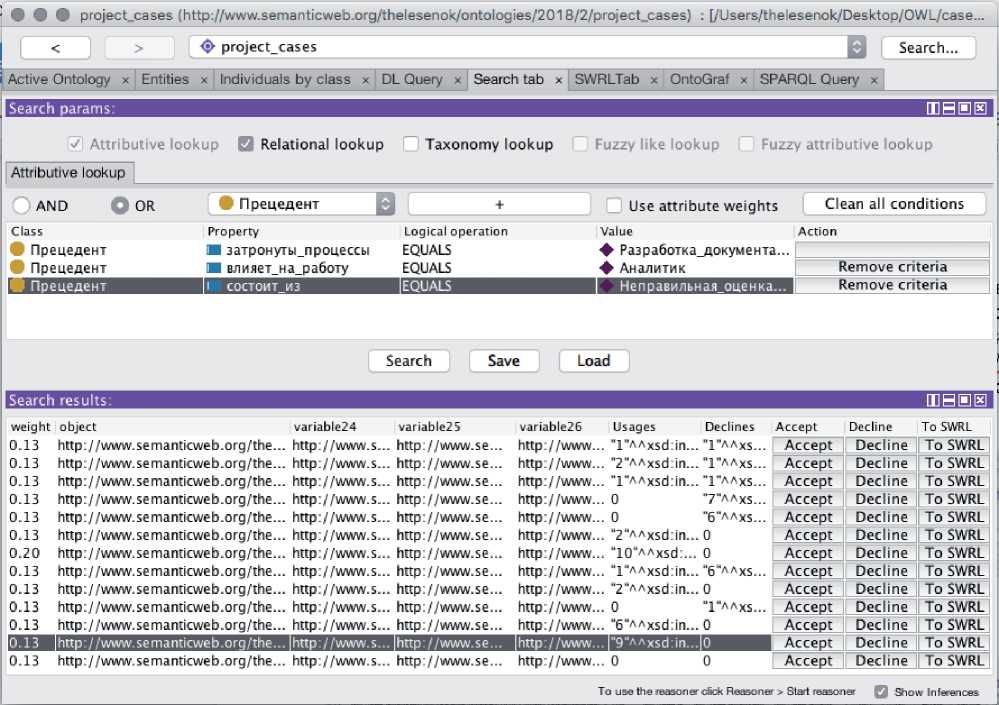
Рисунок 11 ‒ Плагин Search-plugin к редактору онтологий Protege 5.2.0
SELECT * WHERE {
?object a <Прецедент>.
?object prfx3:влияет_на_работу ?variable1.
?object prfx3:затронуты_процессы ?variable2.
?object prfx3:состоит_из ?variable2
(STR(?variable3) =
" cases#Неправильная оценка проекта"))}
Рисунок 12 ‒ Листинг SPARQL -запроса на поиск прецедентов
Таблица 4 ‒ План проведения экспериментов
|
№ п/п |
Наименование этапа |
|
1 |
Анализ инструментов поиска прецедентов ПС при выполнении ПП |
|
2 |
Выявление часто встречающихся поисковых запросов |
|
3 |
Создание и наполнение БЗ (разработка онтологий FuzzyOWL, Jcolibri , разработка базы данных MySQL ) |
|
4 |
Поиск прецедентов в БЗ, которая представлена в виде онтологии FuzzyOWL в Protege 5.2.0 |
|
5 |
Поиск прецедентов в БЗ, которая представлена в виде базы данных MySQL |
|
6 |
Поиск прецедентов в БЗ, которая представлена в виде онтологии OWL в JColibri |
|
7 |
Анализ выполненных экспериментов |
При проведении исследований оценивались: инструмент собственной разработки ( Search-plugin ), редактор построения SQL -запросов и готовое решение JColibri [27] - платформа для построения решений по прецедентам, основывающаяся на онтологиях с дескрип-ционной логикой. Результаты сравнения инструментов поиска ближайших прецедентов сведены в таблицу 5.
Таблица 5 ‒ Результаты сравнения инструментов поиска прецедентов
|
№ п/п |
Параметр |
Searchplugin |
SQL |
JColibri |
|
Используемые меры сходства |
||||
|
1 |
атрибутивная мера сходства |
+ |
+ |
- |
|
2 |
реляционная мера сходства |
+ |
+ |
+ |
|
3 |
таксономическая мера сходства |
+ |
- |
+ |
|
4 |
нечёткая атрибутивная мера сходства |
+ |
- |
- |
|
5 |
нечёткая таксономическая мера сходства |
+ |
- |
- |
|
6 |
атрибутивная мера сходства нечёткого значения атрибута |
+ |
- |
- |
|
База знаний |
||||
|
7 |
OWL |
+ |
- |
+ |
|
8 |
FuzzyOWL |
+ |
- |
- |
|
9 |
MySQL |
- |
+ |
+ |
|
Принятие решения в использовании прецедента |
||||
|
10 |
Учёт количества принятия/отказа в использовании прецедента |
+ |
- |
- |
Эксперимент заключается в последовательном выполнении поисковых запросов, ранжированных по частоте использования (выявленные на шаге 2 плана проведения эксперимента).
Для оценки эффективности выполнения поиска прецедентов использовались параметры: точность поиска, полнота поиска, F -мера Ван Ризбергена [28]. Показатель полноты поиска ( R ) характеризует способность системы находить нужные прецеденты ПС для ЛПР, но не учитывает количество нерелевантных прецедентов, выданных в результатах поиска. Показатель точности поиска ( P ) характеризует способность системы находить только релевантные прецеденты ПС. F -мера является интегральной метрикой, объединяющей полноту и точность поиска. Результаты проведённого эксперимента по сравнению эффективности поиска прецедентов приведены в таблице 6 и на рисунке 13. Использование предложенного алгоритма повышает интегральный показатель более чем на 40%.
Таблица 6 - Результаты проведения эксперимента
|
Параметр |
Search-plugin |
SQL |
JColibri |
|
Точность P |
0,78 |
0,33 |
0,51 |
|
Полнота R |
0,77 |
0,45 |
0,33 |
|
F -мера |
0,78 |
0,38 |
0,40 |
Для проведения экспериментов были выбраны типовые запросы (всего 10 видов), что позволило рассчитать средние значения величин, приведённых в таблице 6. Номер эксперимента - это факт выполнения типового запроса вида: «ПС произошла в ПП < Наименование проекта > при выполнении задачи типа < Разработка новой функциональности >, связанной с доработкой модуля < Название модуля > исполнителем < Разработчик >, что повлияло на процесс < Проведение приемочного тестирования > и затронуло изменение сроков проекта < Да >». Количество запросов в каждом ПП, которое позволило считать их типовыми, варьировалось от 20 до 224.
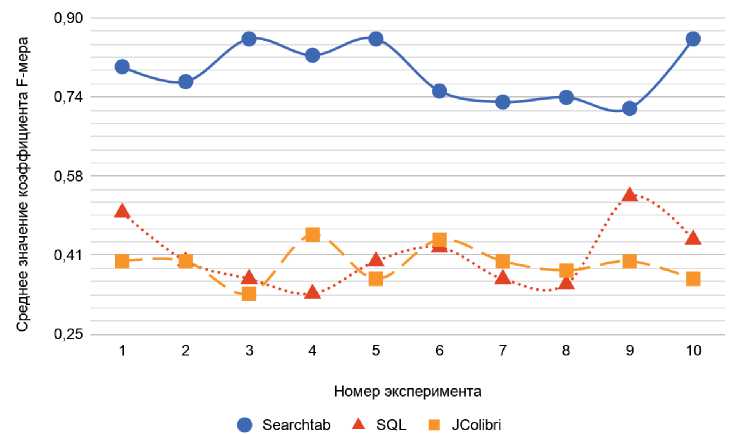
Рисунок 13 ‒ Результаты оценки F- меры поиска похожих прецедентов ПС (фрагмент эксперимента)
Применение предложенных методов и алгоритмов для управления ресурсами проекта в ПС позволило осуществить при выполнении вышеуказанных ПП оперативный поиск прецедентов ПС и снабжение ЛПР необходимой информацией. Использование нечётких свойств в онтологии в качестве критериев позволяет значительно повысить точность и полноту поиска за счёт последовательного сужения области поиска заранее заданными параметрами.
Заключение
Обоснована необходимость разработки нечёткой онтологии для описания процедур поддержки принятия решений в ходе управления ПП. Применение прецедентного подхода в процессе принятия решений позволяет использовать накопленный опыт решения схожих проблем. Разработка новых методов, повышающих эффективность повторного использования прецедентов, остаётся актуальной, особенно для проектов по созданию ПО, характеризующихся высокой степенью уникальности. Предложенный метод использования нечёткой онтологии основан на принципах FuzzyOWL и позволяет построить онтологию, отображающую множество классов ПС, требующих решения в ходе выполнения ПП, и структурировать БЗ.
Разработан алгоритм поиска, позволяющий учитывать нечёткие свойства, нечёткие таксономические и ассоциативные отношения. Эффективность алгоритма поиска ближайшего прецедента в нечёткой онтологии подтверждена на основании экспериментальных данных, полученных при тестировании прототипа интеллектуальной системы поддержки принятия решений на проектах по разработке ПО.
Исследования выполнены при финансовой поддержке Российского фонда фундаментальных исследований (грант № 19-08-00937 «Методы и модели поддержки принятия решений при управлении программными проектами в среде производственных предприятий»).
Список литературы Поддержка принятия решений при управлении программными проектами на основе нечёткой онтологии
- Тренды проектного управления // GANTBPM Управление проектами. - https://gantbpm.ru/trendy-proektnogo-upravleniya/.
- Черняховская, Л.Р. Разработка моделей и методов интеллектуальной поддержки принятия решений на основе онтологии организационного управления программными проектами / Л.Р. Черняховская, А.И. Малахова // Онтология проектирования. 2013. №4 (10). - С.42-52.
- A guide to the project management body of knowledge (PMBoK), Sixth ed. / Project Management Institute, Inc., 14 Campus Boulevard, Newton Square, Pennsylvania 19073-3299 USA, 2017, 756 p.
- Aamodt, A. Case-based reasoning: foundational issues, methodological variations, and system approaches / A. Aamodt, E. Plaza // AI Communications. IOS Press. Vol. 7: 1. 1994. - P.39-59.
- The Access Group: Inbox Insight Survey. - http://www.theaccessgroup.com/media/ 250643/5_project_lessons_to_take_into_2014__whitepaper_v2.pdf.
